わしゃがな!Pocolです。
今日は,
[Andersson 2015] Magnus Andersson, Jon Hasselgren, Tomas Akenine-Möller, “Masked Depth Culling for Graphics Hardware”, ACM Transaction on Graphics 34, 6, 2015
を読んでみようかと思います。
いつもながら、誤字・誤訳があるかと思いますので,ご指摘いただける場合は正しい翻訳例と共に指摘していただけると幸いです。
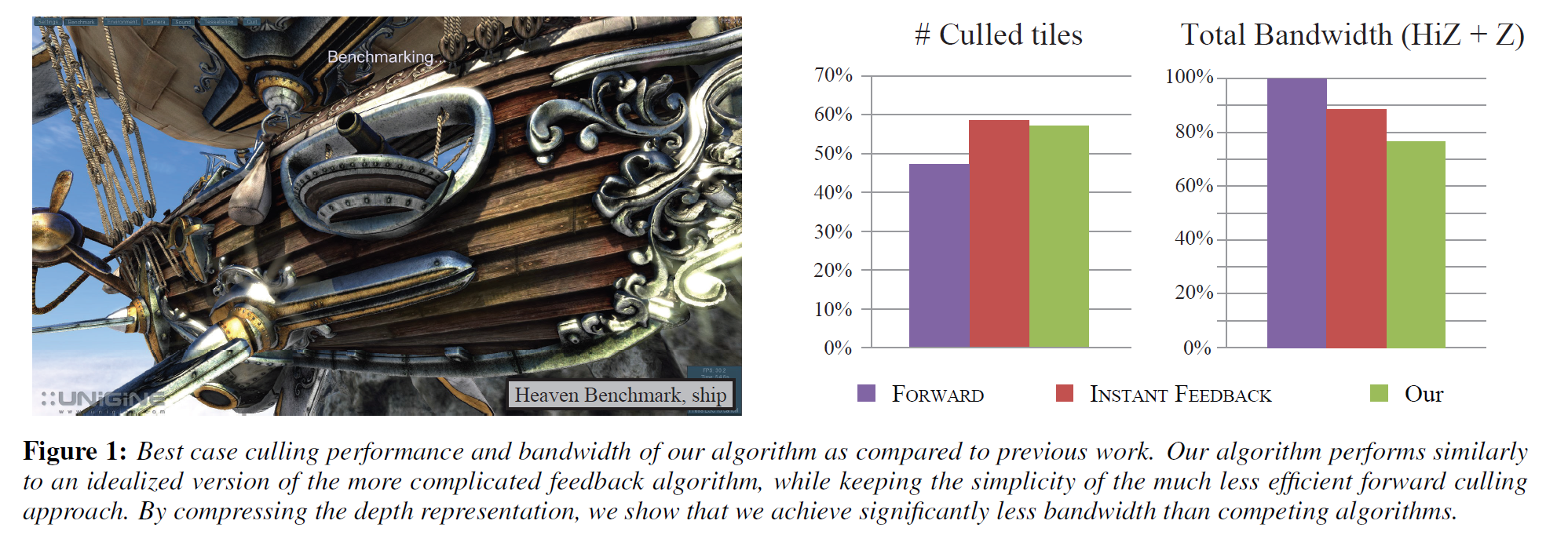
階層的な深度カリングは重要な最適化であり、最新の高性能グラフィックスプロセッサのすべてに存在しています。我々は、各サンプルがどの層に属しているかを示すサンプルごとのマスクを用いた層状の深度表現に基づいた新しいカリングアルゴリズムを提示します。我々のアルゴリズムは、遅延フィードバックループに依存する従来の研究とは対照的に、フィードフォワード型です。実装が簡単で、競合するアルゴリズムよりも制約が少なく、ハードウェアアーキテクチャのロードバランスを容易にします。以前の研究と比較して、我々のアルゴリズムは非常に優れた性能を発揮し、最適なカリングオラクルの効率の90%以上に達することが多い。さらに、階層的な深度バッファを圧縮することで、最大16%の帯域幅を削減することができます。
1 Introduction
2014年には、ノートPCとデスクトップ分野で4億個以上のグラフィックプロセッサが販売されました。これらのGPUのそれぞれには、タイル単位でオクルージョンカリング技術を用いた高度に最適化された固定機能階層型深度カリングユニットが存在します[Greene et al. 1993; Morein 200]。深度バッファへのメモリトラフィックを最小化するために、そのようなユニットの微調整には、かなりのエンジニアリング努力が費やされてきましたが、その結果、性能が向上し、消費電力が削減されました。オクルージョンカリングは、GPUに透過的に統合されており、つまり、ほとんどのユーザは、それが存在することを知らなくても、その利点を享受しています。毎年大量のユニットが出荷されていることと、階層的な深度カリングに伴う性能/電力の利点から、効率性を高めるだけでなく、実装をよりシンプルにし、さまざまなユースケースに対応できるようにすることが非常に重要になっています。
我々は、各サンプルをレイヤーに関連付ける選択マスクを用いたレイヤー化された深度表現を使用した新しいカリングアルゴリズムを提示します。我々のアルゴリズムでは、カリングと表示の更新は非常に安価で簡単であり、これまでの手法とは異なり、高価なフィードバックループ[Hasselgren and Akenine-Möller 2006]を必要とせずに正確な深度境界を計算します。さらに,バックエンドですべてのサンプルの深度値をスキャンする必要がないため,タイルサイズの選択の自由度が高くなっています.これにより,グラフィックスパイプラインのロードバランスが容易になります.我々のアルゴリズムのカリングの可能性の例については、図1を参照してください。
2 Previous Work
Greeneらは、各レベルで保守的な\(z_{\rm max}\)値を持つ完全な深度ピラミッドに基づくカリングシステムを発表しました[1993]。しかし、非常に影響力が高いとはいえ、深度ピラミッド全体を常に更新し続けることは現実的ではありません。Morein [2000]はより実用的なアプローチをとっており、最大深度\(z_{\rm max}\)をタイルごとに保存して計算してました。タイル内の三角形の保守的に推定された最小深度がタイルの\(z_{\rm max}\)よりも大きい場合、タイルと重なる三角形の部分を取り除くことができます。さらに、タイルの最小深度 \(z_{\rm min}\) を格納することも可能で、これは深度の読み取りを避けるために使用されます。三角形の保守的に推定された最大深度が \(z_{\rm min}\) [Akenine-Möller and Strom 2003]よりも小さい場合、三角形はタイルを(アルファ/ステンシルテストなどを行わないと仮定して)簡単に上書きすることができ、読み取り操作をスキップすることができます。文献[Hasselgren and Akenine-Möller 2006; Morein 2000]から、\(z_{\rm max}\)は一般的にタイルのサンプルあたりの深度から計算され、フィードバックループを使用して階層的深度テストに渡されなければならないことを推論します。理想的には、タイルの\(z_{\rm max}\)-値は、最大深度値を持つサンプルが上書きされるたびに再計算され、更新されるべきですが、計算量を減らすために更新頻度は一般的には低くなります。例えば、タイルが深度キャッシュから削除されたときに、\(z_{\rm max}\)が再計算されることがあります。
オクルージョンクエリは、深度テストに合格したフラグメントの数をカウントし、バウンディングボックスのような単純なプロキシジオメトリを使用して、オブジェクト全体をカリングするために使用することができます[Bittner et al.2004; Guthe et al.2006; Mattausch et al.2008; Staneker et al.2003]。動的オクルージョンカリングのためのシステムはAilaとMiettinen [2004]によって発表されており、ゲーム業界では、オクルージョンクエリをソフトウェアラスタライズに基づいてCPUとGPUの負荷バランスを良くすることが有用であることが証明されています[Collin 2011]。Zhangら[1997]はオクルージョンクエリに階層的なオクルージョンマップを使用することを提案しています。彼らはオクルージョンクエリを深度バッファに基づいて行うのではなく、フル解像度の階層的なカバレッジマップを使用し、深度を個別に低解像度の深度推定バッファに格納しています。
我々のアルゴリズムは、JouppiとChang [1999]の研究に触発されたオクルーダーマージを使用しています。彼らは, 低精度の深度平面方程式を格納することにより, 低コストでアンチエイリアシングと透明化を実現するアルゴリズムを提案しています。ピクセルごとに一定数の平面が格納され、オーバーフローはマージヒューリスティックを用いて処理されます。同様に、Beaudoin and Poulin [2004] は MSAA [Akeley 1993] を拡張し、タイルごとに色と深度値の小さなセットを参照するために階層的なインデックス構造を使用するようにしています。レイヤオーバーフローを処理するために、彼らは劣化を伴うマージヒューリスティックを使用するのではなく、サンプリングレートを下げることを選択しました。
Greene と Kass は,以前の研究 [Greene et al.1993] を拡張し,シェーダには区間演算を使用し,可視性の処理には四分木の細分化を使用した誤差境界を持つアンチエイリアシングを含めるようにしました [1994]。さらに,Greeneらl. [1996] は,効率的なアンチエイリアシングのために,カバレッジマスクのピラミッドを使用してシーンとスクリーン空間を階層的にトラバースするために BSP ツリーを使用しています。小さな三角形のためのピクセルシェーディング処理を節約するために、Fatahalianら[2010]は、アグリゲートカバレッジマスクを使用して、隣接する三角形からクワッドフラグメントを収集してマージしています。彼らのマスクの目的は,幾何学的な不連続性の上にシェーディングをマージしないようにするためにマスクを使用する点で我々とは異なります。
3 Overview of Currrent Architectures
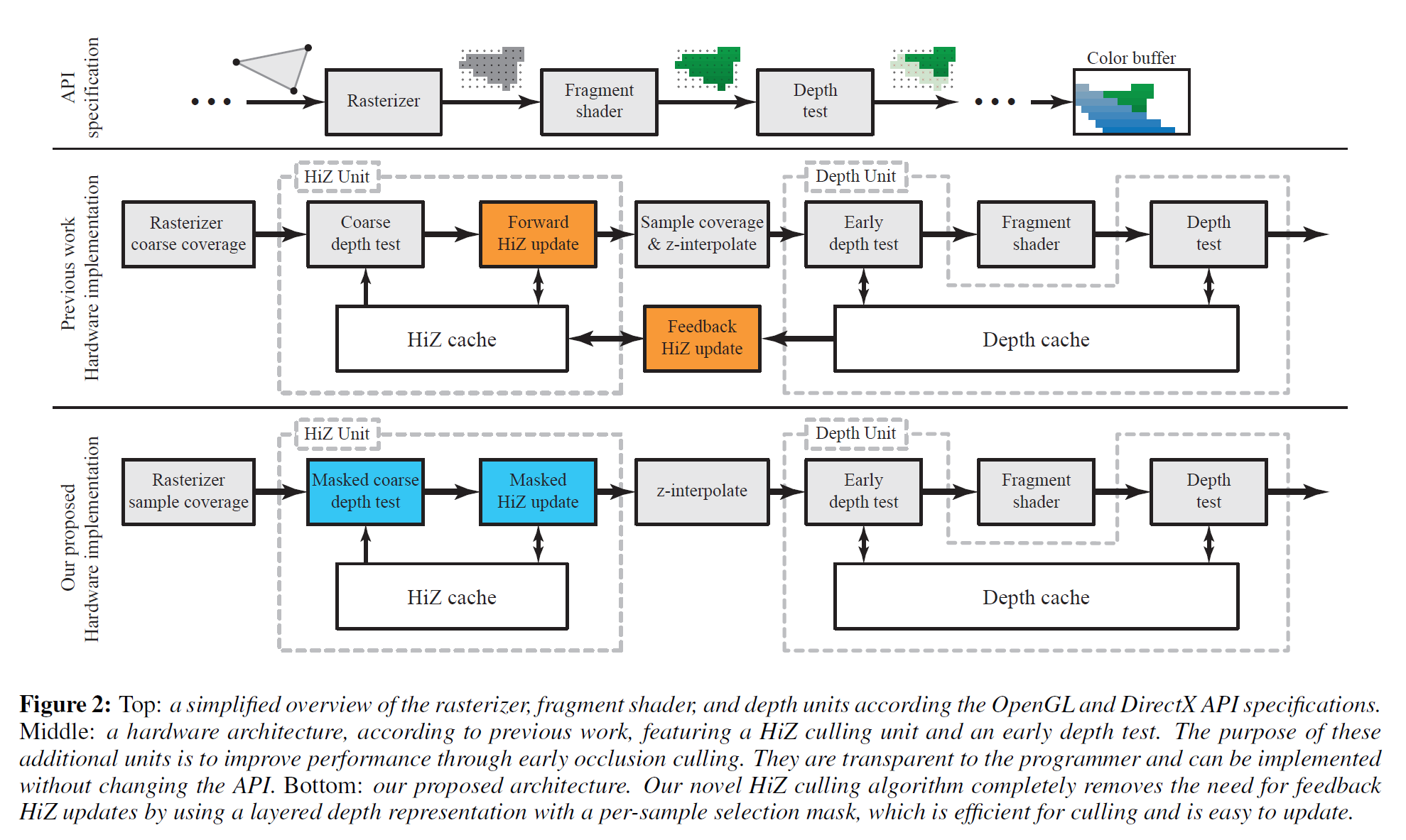
我々のアルゴリズムを文脈化するために、まず、以前の研究[Hasselegren and Akenine-Möller 2006]で提示されたGPUデプスパイプラインの典型的な実装を説明します。図2 の上段は、ほとんどの最新のグラフィックス API で規定されているように、機能的な観点からのパイプラインを示しています。深度とカラーバッファは、一連の三角形がレンダリングパイプラインを通過するにつれて徐々に更新されます。各サンプルについて、最も近い三角形の深度がその色とともに保存されます。実際のハードウェアパイプラインは通常、パフォーマンスの理由からAPIの仕様とは異なり,一般的な実装は図2の中段に示されています。以下では、説明を簡単にするために深度関数未満のものに限定しますが,この技術はおそらく,Vulkan APIでもそうでしょうし,DirectX、OpenGLなどの一般的なAPIで使用されているすべてのタイプの深度関数に一般化されます。
Rasterizer
グラフィックスプロセッサのジオメトリ処理部分を省略して、ラスタライザユニットでの説明をします。ラスタライザは、特定の三角形にどのサンプルが重なっているかを判断する役割を担っています。最適化として、最新のラスタライザは一般的にタイル(\(w \times h \times d\) サンプルのグループ)で動作します。各タイルに対して保守的なテストが行われ、それが完全に覆われているか、三角形の外側に完全にあるか、部分的に重なっているかが判断されます。サンプルごとのカバレッジテストは、部分的に三角形に重なっているタイルに対してのみ必要です。サンプル カバレッジが計算されると、各フラグメントはフラグメント シェーダを使用してシェーディングされ、その後、可視性を決定する深度テストが行われます。図2の中段に見られるように、一般的な最適化は、階層化された\(\rm z\)または\(HiZ\)ユニットの後にサンプルあたりのカバレッジテストを配置することです。これは、HiZがサンプルごとのカバレッジ・テストの前にタイルを削除したり、カリングしたりすることで、そのユニットのパフォーマンスを向上させることができるからです。
HiZ Unit
深度テストでは、かなりのメモリバンド幅と計算能力を消費する可能性があります [Ailaら 2003] この理由から、ハードウェアパイプラインは、一般的に、サンプルのグループ全体について深度テストの結果が明確に決定できる場合はいつでも、粗い深度テストを使用して迅速にタイルを廃棄(カリング)または受け入れることを目的としたHiZユニットを持っています。この目的のために、Hiユニットは、粗い深度バッファと呼ばれる保守的なバージョンの深度バッファを保持しており、これはタイルごとの深度境界\([z_{min}^{tile}, z_{max}^{tile}]\)を含んでいます。
Coarse depth buffer update
レンダリングが進むにつれて,粗い深度バッファは継続的に更新されます。以前の研究[Morein 2000; Akenine-Möller and Strom 2003]から、2つの異なるメカニズム、すなわち、粗い深度テストの直後に位置する前方更新と、深度ユニットとHiZユニットの間に位置するフィードバック更新を使用して、\(z_{min}^{tile}\)と\(z_{max}^{tile}\)がパイプライン内で別々に更新されることに注意してください。これは、図2の中段に示されています。
フォワード更新段階では、\(z_{min}^{tile} = {\rm min}(z_{min}^{tri}, z_min^{tile})\)として\(z_{min}^{tile}\)を効率的に計算することができます。ただし、\(z_{max}^{tile}\)値は、タイル内のすべてのサンプルが上書きされた場合にのみ更新されます。カバレッジマスクが完全に設定されている場合は、\(z_{max}^{tile} = {\rm min}(z_{max}^{tri}, z_{max}^{tile})\)となります。残念ながら、小さい三角形を使用している場合は、タイルが完全に重なる可能性が低いため、この更新のスケールは非常に悪くなります。フォワードステージのみを使用した場合の不規則なカバレッジの例を図9に示します。
フィードバック更新を使用して、より良い\(z_{max}^{tile}\)値が得られます。ここでは、図2に示されているように、深度サンプルのタイル全体の最大削減が深度ユニットで実行され、その結果である\(z_{max}^{feedback}\)がフィードバック機構を介してHiZユニットに送られます。実行される最大削減の数を減らすために、フィードバック更新は、通常、タイルが深度キャッシュから取り出されるたびに発生します。HiZユニットとデプスユニットがハードウェアパイプラインで数百サイクル分離されている場合があるため、フィードバックメカニズムは大きな遅延を発生させます。レンダリング状態によっては、更新が発生する前にフラグメントシェーダが実行され、タイルがキャッシュから取り出されるのを待つ必要がある場合もあります。その結果、\(z_{max}^{tile}\) の更新が遅れ、カリング率が低下することがあります。さらに、この遅延には、フィードバックメッセージが現在アクティブな状態とは異なる GPU 状態から発信された場合の保守的な処理方法など、目に見えない副作用があります。
Depth Unit
HiZユニットと同様に、深度ユニットは一般的にサンプルのタイルで動作しますが、単一のテストを実行するのではなく、各サンプルは深度バッファに保存された値に対して個別にテストされます。デプスユニット内のタイルのサイズは、一般的にキャッシュラインのサイズと相関しており、メモリとの間でどれだけのデータを効率的にストリーミングすることができるかによって決定されます。フィードバック機構は、HiZとデプスユニットのタイルサイズの間に制約を作成することに注意してください。max-reduction操作は、HiZバッファ内のタイルの粒度に対して実行される必要があります。したがって、操作に必要なすべてのデータがデプスユニットキャッシュに存在することが重要であり、これを保証する最も簡単な方法は、粗いデプスバッファと通常のデプスバッファのタイルサイズを結合することです。
デプスユニットの中で最もわかりやすい最適化は、多くの場合、深度テストがフラグメントシェーディングの前に実行できるという利点を生かした早期深度テストです。フラグメントシェーディングはコストが高く、ボトルネックになることが多いため、これは一般的にパフォーマンスを大幅に向上させます。ほとんどの場合、初期のデプステストを使用しても問題ありませんが、例えば、フラグメントシェーダがdiscard操作でカバレッジを変更したり、デプス値を出力したり、アンオーダードアクセスビュー(UAV)リソースに書き込みを行ったりする場合には、無効にする必要があります。
4 Algorithm
フィードバック機構に頼らずに、タイルの最大深度を正確に更新することは困難です。我々のアルゴリズムの重要な革新は、図2の下段に示されているように、フィードバック機構の必要性を完全に除去するフォワード更新のみを使用して粗い深度バッファを更新する効率的かつ正確な方法です。この更新は、ストリーミング方式で逐次的に実行され、現在の三角形に関する情報のみを使用します。トライアングルのバッファリングやレンダリング履歴は必要ありません。
一般性を損なうことなく、我々のアルゴリズムの表現は、タイルごとに2つの深度層のみに制限します。各タイルは1つの\(z_{min}\)値と2つの\(z_{max}^i\)値を持っています。さらに、サンプルごとに1ビットの選択マスクを格納し、各サンプルを2つの層のうちの1つである\(i\)に関連付けます。各 \(z_{max}^i\) は、そのレイヤに関連付けられたすべてのサンプルと同じかそれ以上でなければなりません。我々は、入力される三角形と層状表現の保守的なマージを使用してこれを達成する。以下では、粗い深度テストと更新について詳しく説明します。
Coarse depth test
第3節で説明したように、三角形とそのカバレッジマスクはラスタライザによって提供され、これによって以前と同様に\(z_{min}^{tri}\)と\(z_{max}^{tri}\)を計算することができます。\(z_{min}\)/\(z_{max}\) カリングで粗い深度テストを行うのと同様に、図3に示すように、各レイヤーについて \([z_{min}^{tri}, z_{max}^{tri}]\) と \([z_{min}, z_{max}^i]\) の間の間隔オーバーラップテストを行います。サンプルごとのパスマスクとフェイルマスクは、三角形のカバレッジマスクと選択マスクから、簡単なビット演算を使って構築することができます。正確な深度テストは、パスマスクまたはフェイルマスクのいずれにも存在しないサンプルに対してのみ必要です。粗い深度テストがどのように実行されるかについての擬似コードは、付録のリスト1に記載されています。
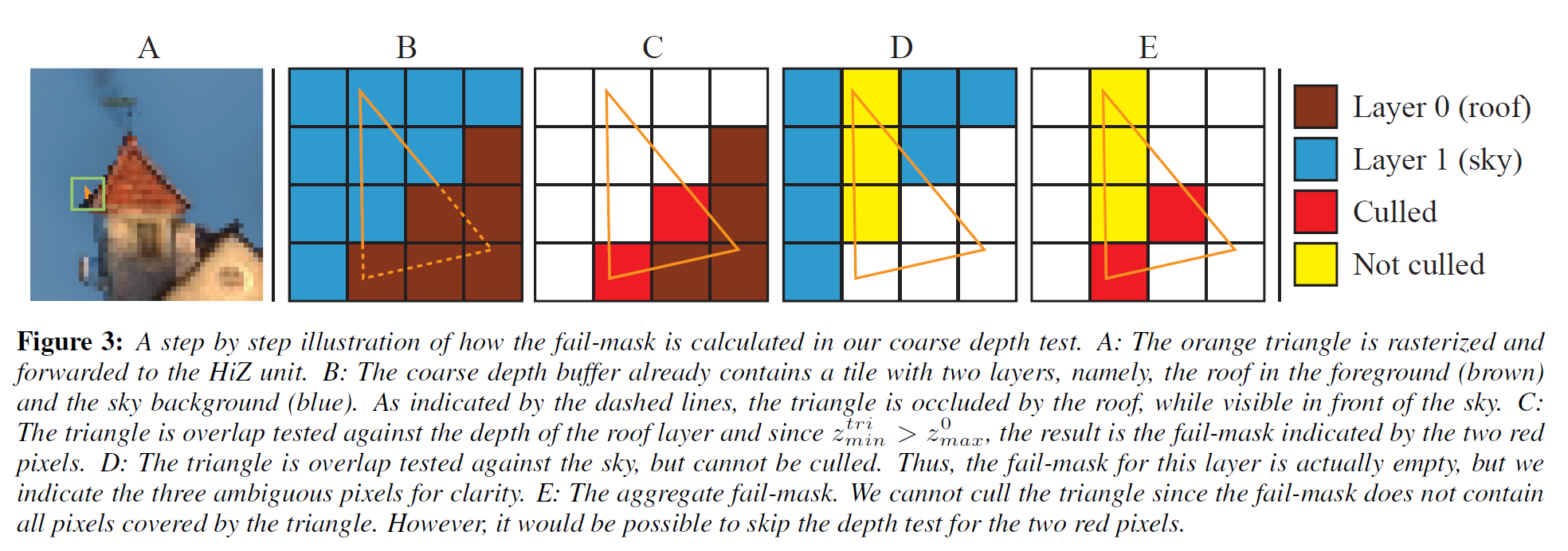
Coarse depth buffer update
すべてのサンプルが粗い深度テストでカリングされていない限り、粗い深度バッファの内容を保守的にバインドするような方法で、粗い深度バッファを更新しなければなりません。\(z_{min}\)-値の更新は、以前にセクション3で説明したように行われます。課題は \(z_{max}^i\) 値と選択マスクの更新にあります。入ってくる三角形は、すでにタイルを埋め尽くしている2つのレイヤーに加えて、3つ目の深度レイヤーを形成しています。図4に示すように、2つのレイヤーをヒューリスティックな方法で結合することで、レイヤーのオーバーフローを処理します。

まず、レイヤー\(i\)に属し、入力する三角形にも重なっていることがわかっている単一のサンプル\(S\)を考えてみます。less thanの深度テストを行うと、深度テスト後の\(S\)の深度は、最大でも\(z_{max}^i\)と\(z_{max}^{tri}\)の最小値(近い値)になることがわかります。この観察に基づいて、両方の \(z_{max}^i\) の値を \(z_{max}^{tri}\) と比較することによって、我々は各サンプルがどの層に属しているかを分類することができます – 前の層である \(i\)、または入ってくる三角形の層のどちらかです。このことから、図4のステップBが例示するように、3つの層、\(z_{max}^0\)、\(z_{max}^1\)、\(z_{max}^{tri}\)のうち、各サンプルがどの層に属しているかを示す3つの非重複サンプルマスクを構築します。
サンプルを分類した後、サンプルが関連付けられていないレイヤーがあれば(つまり、レイヤーのサンプルマスクが空であれば)、粗いバッファの更新は簡単です。結果として得られるレイヤの数は \(\leq 2\) なので、データは我々の表現に収まるので、単純に、埋められたレイヤを粗い深度バッファに書き込むことができます。3つのレイヤすべてにサンプルがある場合、どのレイヤをマージするかを選択するために、単純な距離ベースのヒューリスティックを使用します。基本的な前提として、同じ深度値を持つ三角形は、同じ表面の一部である可能性が高いということがあります。図4のステップCに示されているように、まず、すべてのレイヤー間の距離を次のように計算します。
\begin{eqnarray}
d_{T0} &=& | z_{max}^{tri} – z_{max}^{0} | , \\
d_{T1} &=& | z_{max}^{tri} – z_{max}^{1} | , \\
d_{01} &=& | z_{max}^0 – z_{max}^1 | .
\end{eqnarray}
次に、最短距離は、図4のステップDで描かれているように、どのマージ操作が実行されるかを決定するために使用されます。
1. \(d_{T0}\)が最も小さい場合は,\(z_{max}^0 = {\rm max}(z_{max}^{tri}, z_{max}^0)\)。
2. \(d_{T1}\)が最も小さい場合は,\(_z{max}^1 = {\rm max}(z_{max}^{tri}, z_{max}^1)\)。
3. 上記以外の場合,\(z_{max}^0 = {\rm max}(z_{max}^0, z_{max}^1)\) そして,\(z_{max}^1 = z_{max}^{tri}\) となります。
最も近い 2 つのレイヤーのサンプルマスクも (単純なビット演算を使って) マージされ、 新しい選択マスクが作成されます。更新とマージ関数の擬似コードは付録のリスト3とリスト4で見つかります。
Switching Depth Functions
レンダリング中の深度関数の切り替えを容易に処理できるようにしています。深度関数よりも大きい値の場合、タイルは2つの\(z_{min}^i\)値と1つの\(z_{max}\)値で表現されます。各粗い深度バッファタイルに対して、現在どの表現が使用されているかを示す1ビットを格納します。タイルが現在の深度関数と一致しない場合は、粗い深度バッファを更新する前に変換します。変換は、min値とmax値を保守的に入れ替えることで行われます。例えば、粗い深度バッファに格納されているタイルが2つの最大レイヤを持っているが、深度関数がそれよりも大きい値に変更されている場合、\(z_{max} = {\rm max}(z_{max}^0, z_{max}^1)\)と\(z_{min}^0 = z_{min}^1 = z_{min}\)を設定して選択マスクをクリアすることでタイルを変換します。この変換は非常に粗雑で、カリング情報の多くを失う可能性がありますが、ほとんどのシーンで深度関数の変更は頻繁ではないため、これが問題となったワークロードは見つかりませんでした。すべての標準的なOpenGL/DirectXの深度関数は、less thanまたは,greater than表現を使用して処理することができます。
Coarse depth test pipeline placement
図2の下段にあるように、我々の粗い深度テストはカバレッジマスクに基づいているため、サンプルごとのカバレッジテストはラスタライザブロックに移動しなければなりません。前述したように、サンプルごとのカバレッジテストをHiZユニットの後ろに配置すると、カバレッジテストをスキップして、カリングされたタイルの負荷を減らすことができるため、有益です。
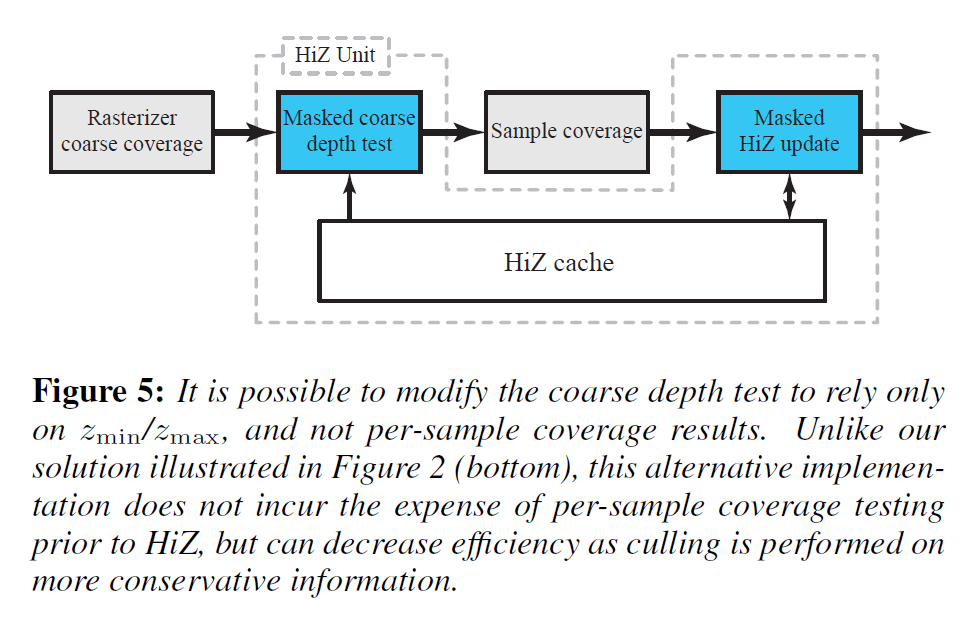
我々は、古典的なHiZテストと同様に、\([z_{min}^{tri}, z_{max}^{tri}]\)と\([z_{min}, {\rm max}(z_{max}^0, z_{max}^1)]\)間隔の間でオーバーラップテストを実行する、代替の粗い深度テストを使用して、同様の効果を達成することができます。図5に示すように、その後、粗い深度テストと更新の間にサンプルあたりのカバレッジテストを配置してもよく、これにより、前の作業と同様の負荷分散が得られます。このバージョンの粗い深度テストは精度が低いですが、我々のアルゴリズムの利点のほとんどは、正確な更新に由来しています。この代替アプローチの擬似コードは付録のリスト2にあります。セクション5で示された結果と比較すると、我々のアルゴリズムのカリング率は0.2~2.1%ポイント減少し、総帯域幅は0.7~1.4%ポイント増加します。粗いテストの両方のバージョンを実行することも可能で、正確なバージョンの利点を維持しながら、ほとんどのサンプルごとのカバレッジテストを効率的にフィルタリングできます。
4.1 Compression
粗い深度バッファの帯域幅を減らすために、我々は、エントリが粗い深度バッファから削除されるときに、通常の深度バッファ圧縮がどのように動作するかに似た単純な圧縮スキームを使用します[Hasselgren and Akenine-Möller 2006; Hasselgren et al.2012]。
我々の圧縮方式は、ウェーブレット係数のゼロツリー符号化 [Shapiro 1993] に触発されています。各タイルは,まず,\(b\)個のサンプルを含むブロックのセットに分割されます。各ブロックについて,そのサンプルが同じ層に属しているかどうかを示す1ビットを格納します。すべてのインデックスが同じであれば、ブロック全体をそのレイヤーに割り当てるために必要なビットは1つだけ追加されます。両方のレイヤへのインデックスを含むブロックは、明示的なマスク幅 \(b\) ビットを必要とします。この方式では、\(s\) 個のサンプルを含むタイルに対する圧縮された選択マスクのコスト \(c\) は \(c = 2 \frac{s}{b} + (b – 1)m\) であり、\(m\) は明示的に格納する必要があるブロックの数です。\(c \leq s\) の場合、選択マスクは損失なく圧縮することができます。興味深いことに、レンダリングされた画像にアーチファクトを導入することなく、非可逆圧縮を行うことで\(m\)を制限することができます。選択マスクのインデックスを変更して 2 つの \(z_{max}\)-値のうち遠い方の値を使うようにしても、粗い深度バッファ表現は有効です (すなわち、深度バッファと比較して保守的です)。これにより、いくつかのブロックでは、両方を混在させるのではなく、単一のレイヤーを使用するように強制することで、\(m\) の最大値を強制することができます。
さらに、\(z_{min}\)、\(z_{max}^i\)の精度を下げています。利用可能なビットバジェット、デプスバッファのターゲットフォーマット、およびデプスサンプルの予想される分布に応じて、様々な可能なオプションがあります。ここでは、指数ビットと仮数ビットの少ない単純な精度を減らしたfloatを使用することを選択しました。さらに、負の指数のみを使用し、符号ビットは使用せず、表現可能な範囲を[0, 1]に制限しています。
5 Results
異なるカリングアルゴリズムを比較する際には、メモリ帯域幅の使用量とスループットの2つの主要な量が注目されます。帯域幅は、デプスバッファを読み込んで更新するときにデプスユニットによって主に消費され、粗いデプスバッファを維持するためにHiZユニットによってより少ない範囲で消費されます。デプスユニットが実行しなければならないサンプルごとのテストの数は、粗い深度テストでカリングされた(失敗した)タイルの量に依存し、結果的にカリング率が高いほどスループットが向上します。システムと予想されるワークロードに応じて、これらの量は、最大のパフォーマンスのために互いにバランスを取らなければなりません。帯域幅とカリング率(すなわち、粗い深度テストでカリングされたタイルの割合)に関して、以下の5つの異なるパイプライン構成を評価しました。
・ORACLE – HiZユニットは、正確な深度バッファを複製し、サンプルごとの深度テストを実行します。各サンプルについて、曖昧な結果はなく、合否のみです。タイルは、深度テストの合格と不合格の両方のサンプルが含まれている場合にのみ、曖昧な結果に分類されます。このパイプラインは、可能なカリング率の上限を得るためにのみ使用されます。
・FORWARD – \(z_{min}/z_{max}\)カリングの順方向更新単位のみ有効です。無限の遅延を持つフィードバックユニットは、順方向のみのパイプラインとして動作します。この構成は、このようなデザインが達成できるカリング率の下限を設定しています。
・INSTANT FEEDBACK – \(z_{max}\)-更新は、デプスバッファの更新(すなわち、できるだけ早く、できるだけ頻繁に)で直接トリガされ、フィードバックの遅延がないため、フォワード/フィードバック設計がどれくらいの性能を発揮できるかの上限(非現実的ではありますが)を与えてくれます。
・ZMASK – 提案するフィードフォワードアルゴリズム
・PACKED ZMASK – 帯域幅を最小化するために調整された我々のアルゴリズム。この異形は、セクション4.1で説明されているように、追加のポストHiZキャッシュ圧縮ステージを必要とします。
本研究では、機能レベルでシステムをモデル化したC++ハードウェアシミュレータを使用しています。32kBの深度キャッシュと16kBのHiZキャッシュを使用しており,どちらも64Bのキャッシュラインサイズを使用しています(特に記載がない限り).図6に示されている主な結果については、FOWARD、INSTANT FEEDBACK、およびZMASK構成のために、深度サンプルあたり4ビットのオーバーヘッドに相当する粗い深度バッファを割り当てます。このストレージを使用すると、FORWARD と INSTANT FEEDBACK では、16 サンプルの粒度で \(z_{min}^{tile}\) と \(z_{max}^{tile}\) をそれぞれ32 ビッ ト形式で保持できます(これは、シングルサンプル ターゲットの\(4 \times 4\) ピクセル タイルと4xマルチサンプル ターゲットの \(2 \times 2\) ピクセルに対応します)。ZMASKについては、各エントリに32ビットを使用して、1つの\(z_{min}\)と2つの\(z_{max}^{i}\)を32サンプルの粒度で格納し、サンプルごとに32ビットの選択マスクを格納します(これは、シングルサンプルターゲットの\(8 \times 4\)ピクセルタイルと\(4 \times\)MSAAターゲットの\(4 \times 2\)ピクセルタイルに対応します)。すべての構成は、異なるアルゴリズムがクリア値をどのように扱うかによって結果が偏らないように、共通の高速クリア[Morein 2000]最適化を使用しています。
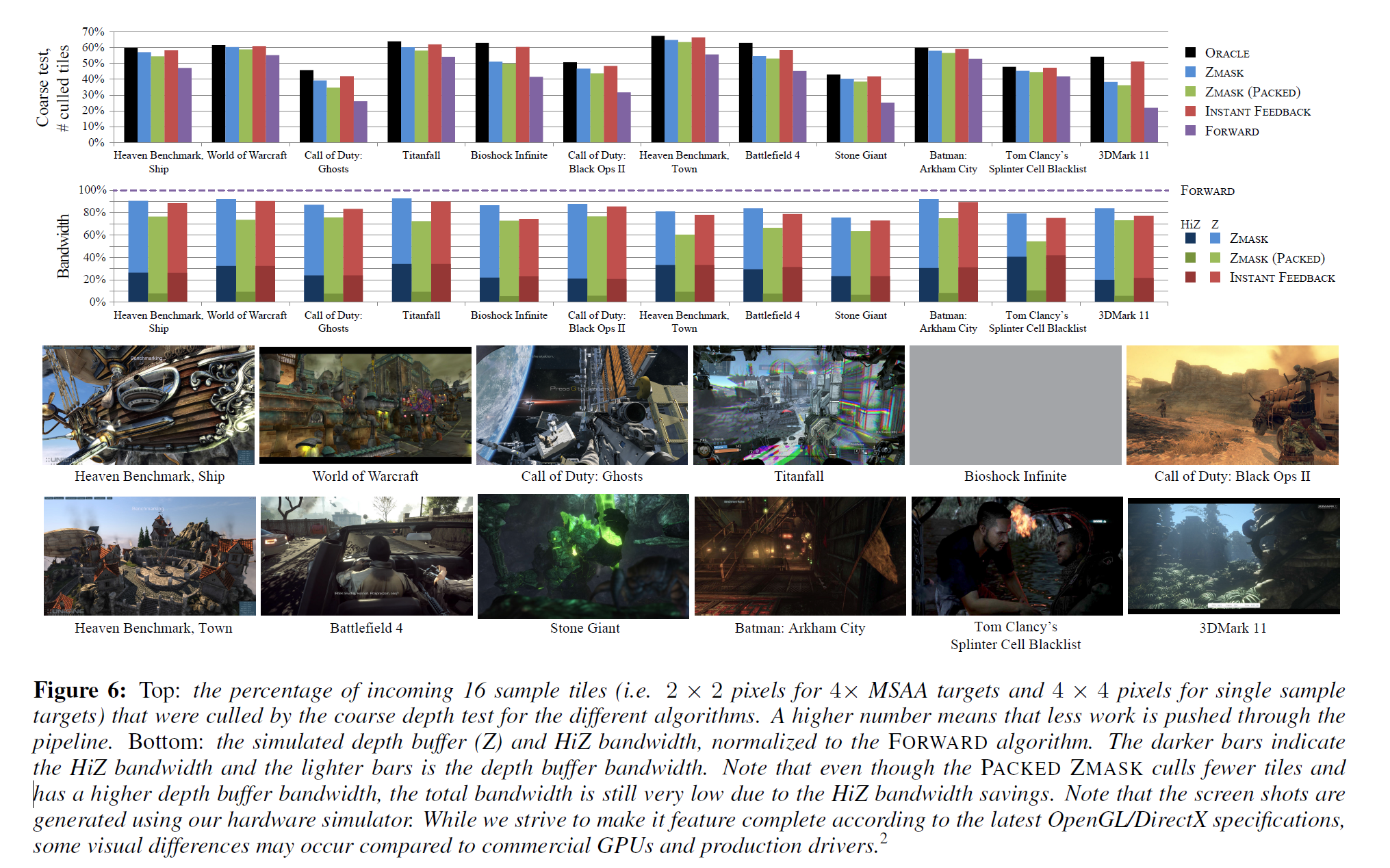
PACKED ZMASKはZMASKアルゴリズムに似ていますが、より大きなタイル(シングルターゲット用に\(16 \times 8\)ピクセル、\(4 \times\)MSAAターゲット用に\(8 \times 4\)ピクセルのタイル)を使用し、HiZキャッシュから取り出されたタイルを圧縮します。キャッシュでは、各タイルは\(128+3 \cdot 32=224b\)、つまり28Bのメモリを占有します。64Bのメモリトランザクションサイズを変更したくないので、4つのタイルを112Bの共通キャッシュラインにグループ化し、退避時に64Bに圧縮します。このレベルの圧縮を実現するために、\(z_{min}\)と\(z_{max}^i\)の値に4つの指数ビットと11の仮数ビットを持つ低精度フロートフォーマットを使用し、1ビットはテスト方向を符号化し(セクション4参照)、残りの82ビットはセクション4.1で説明した圧縮フォーマットを使用して選択マスクを格納するために費やされます。したがって、PACKED ZMASK パイプラインを使用する場合、各タイルはキャッシュ内ではサンプルあたり 1.75 ビットを占有し、メモリからのタイルの読み書きにはサンプルあたり 1 ビットの帯域幅を使用します。タイルサイズは、 図8 に示すように、デプスバッファーの帯域幅とHiZ の帯域幅の間の最適なバランスを見出すことで経験的に選択されました。
主な結果を図6に示し、粗いカリング率と各パイプラインで消費される帯域幅を示しています。カリングレートは,比較を簡単にするために,ZMASKとPACKED ZMASKアルゴリズムの16サンプルタイルに正規化されています.粗い深度テストの合格率はアルゴリズム間で非常に似ているので、スループットの指標として、カリングされたタイルの数(すなわち、深度テストが明確に失敗したタイル)のみに焦点を当てています。このテストスイートには、さまざまなレンダリング状態の組み合わせを持つ最新のゲームからの多数のトレースが含まれており、1~4倍のMSAAバッファとシャドウマップなどの補助的なターゲットが含まれています。結果から分かるように、我々のアルゴリズムはカリング効率の点でORACLEに近いものとなっています。FORWARDパイプラインは、すべての代替案よりも常にかなり効率が悪いです。我々の平均では、ORACLE パイプラインの 90% の拒絶率を維持していますが、より困難なケースは、アルファテストされたジオメトリの量が多いシーンや、フラグメントシェーダで深度を出力するシーンが一般的です。ZMASKはFORWARDと比較して総帯域幅の使用量が約14%少ないのに対し、INSTANT FEEDBACKはFORWARDと比較して約18%少ないことに注意してください。ただし、INSTANT FEEDBACKは理想化されており、実装するには非現実的であることに注意してください。このセクションで後述するように、パイプラインの遅延を増加させると、フィードバックアルゴリズムの弱点が明らかになります。タイルサイズを大きくし、PACKED ZMASK コンフィギュレーションを使用して圧縮を有効にすると、カリングされたタイルの数が減り、結果としてデプスバッファの帯域幅が増加します。しかし、HiZの帯域幅が減少するため、総帯域消費量は平均して約30%減となり、大幅な削減となります。
ORACLEアルゴリズムで提示されたカリング数には、フラグメントシェーダによってカバレッジが変更されたタイルが含まれています。アルファテストされたビルボードは、例として、フラグメントシェーダで破棄される大きくて完全に透明な部分を持つことができます。
Feedback Delay
前述したように、フィードバックアルゴリズムの性能は、パイプラインでどれだけ長い遅延が期待できるかに依存します。我々は、キャッシュを追い出すのではなく、深度バッファ更新でフィードバック機構を実装することを選択し、メッセージをフィードバックする際にFIFO-キューを導入することで遅延をシミュレートしました。これにより、任意の数の処理済みタイルでメッセージを遅延させ、遅延の増加がシステム性能にどのように影響するかを研究することができます。
図7は、カリングされたタイルの数と総シミュレートされた深度バッファの帯域幅(粗い深度バッファと正確な深度バッファの両方)が、ZMASKアプローチと比較して遅延が増加した場合に影響を受けることを示しています。予想通り、カリングされたタイルの数は遅延の増加とともに減少します。同様に、総帯域幅の使用量は、遅延が大きくなると著しく増加します。遅延が十分に大きくなると、フィードバックメッセージが受信される前に、粗い深度バッファのエントリはすでにHiZキャッシュから取り除かれている可能性があります。その結果、フィードバック更新を実行するためにデータをキャッシュに読み戻さなければならず、HiZとフィードバックメカニズムは、どのデータがキャッシュに留まるべきかを競うことになります。したがって、システムの予想される遅延に基づいて、HiZキャッシュと深度単位キャッシュのサイズのバランスをとることが重要です。あるいは、HiZキャッシュに常駐していないタイルのフィードバック更新は廃棄される可能性があり、これは、カリング率をさらに低下させる代償として、スラッシングを回避することができます。
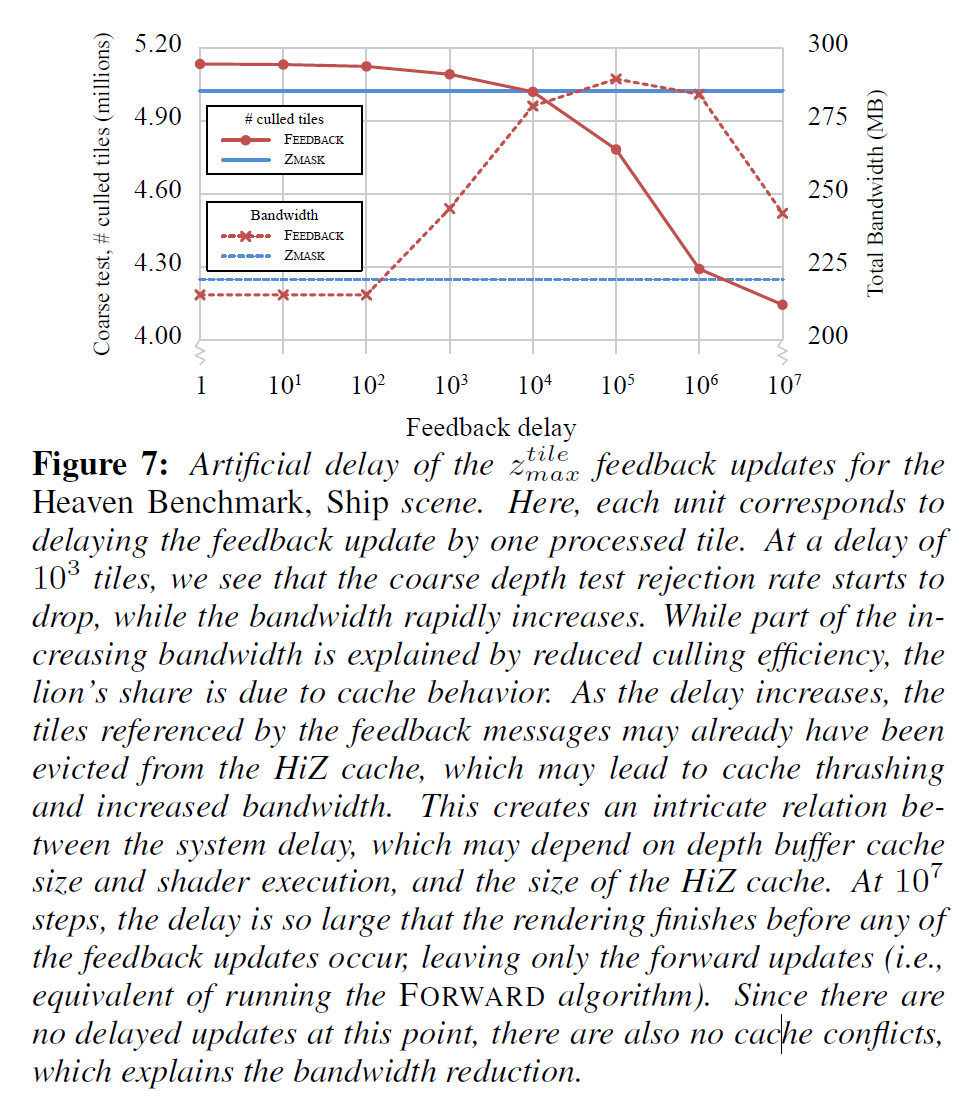
実際のシステムにおけるパイプライン、シェーディング、およびキャッシングの遅延は、カリング効率と帯域幅をはるかに複雑な方法でスケーリングする原因となり、図7はその傾向を示すものとしてしか見られないことに注意する必要があります。私たちのシステムでは、evictベースのフィードバック戦略を使用した場合、帯域幅に大きな影響があることがわかります。深度キャッシュを一定に保ちながら、HiZキャッシュサイズを半分の8kBにすると、シーンに応じてHiZの帯域幅が約10%から45%増加します。
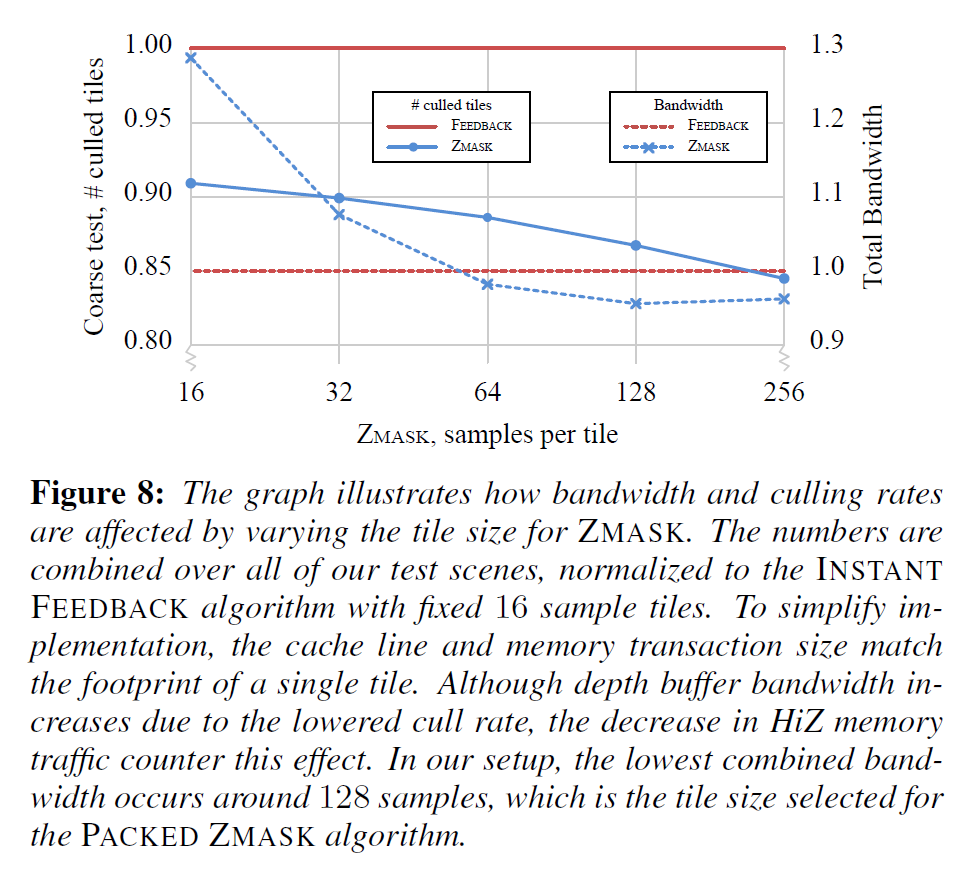
Tile size
我々のアルゴリズムはフィードフォワードの性質を持っているため、粗い深度バッファと正確な深度バッファのタイルサイズを簡単に切り離すことができ、これにより、カリング効率と粗い深度バッファの帯域幅の間の最良のトレードオフを与えるタイルサイズを柔軟に選択することができます。図8では、タイルサイズを変化させたときに、アルゴリズムがどのようにスケーリングするかを示しています。参考として、INSTANT FEEDBACK パイプラインのベースライン結果も掲載しています。
Multiple depth layers
我々のアルゴリズムは、より多くの深度層を使用するために拡張することができ、図9に示すように、3つまたは4つの層を使用した場合のカリング率のいくつかの改善が観察されています。しかし、この改善は、追加の複雑さを動機づけるほどの有意なものではないと感じています。レイヤの数を増やすと、追加の\(z_{max}^i\)値を格納する必要があり、選択マスクを格納するためにサンプルごとにより多くのビットを使用しなければならないため、より粗い深度バッファの格納が必要になります。また、レイヤーをマージする方法の数が \({\mathcal O}(n^2)\) 倍になるため、レイヤーのマージも複雑になります。

Stochastic motion blur
概念の証明として ZMASKアルゴリズムを既存のフレームワークにプラグインしました。これは、モーションブラーを含む画像をレンダリングするために、ハードウェア上で確率的なラスタライズパイプラインをシミュレートするものです。このフレームワークは、Munkbergらに従い[2011],より一般的な\(tz\)-ピラミッド[Boulos et al. 2010]の最も帯域幅効率の高いバリアントである\(z_{max}\)-カリングを実行するためにTZSLICEアルゴリズム[Akenine-Möller et al. 2007]を使用します。粗い深度バッファへの更新は、INSTANT FEEDBACKアルゴリズムと同じ方法で行われます。TZSLICEでは、\(4 \times 4 \times 1 (w \times h \times time)\)サンプルの各スライスに対して1つの32ビットのfloat\(z_{max}\)-値を使用しました。ZMASKでは、2つのレイヤーで\(4 \times 4 \times 4\)タイル(64サンプル)を使用しました。したがって、これらの構成はいずれもHiZデータのサンプルあたり2ビットのオーバーヘッドを使用しています。図10に示すように、アルゴリズムを変更しなくても、ZMASKはTZSLICEと非常によく比較されます。これらは初期の実験であり、この分野ではさらに多くの改善の可能性があると考えています。

Limitations
我々のアルゴリズムは複雑なジオメトリも非常によく処理しますが、フィードバックアプローチと比較した場合の主な欠点は、アルファテスト、ピクセルシェーダの破棄、ピクセルシェーダの深度書き込みを正確に処理できないことです。これは極端なケースでは問題になるかもしれませんが、私たちのテストアプリケーションでは、メインオクルーダーにアルファテスト済みのジオメトリを使用しているようには見えません(アルファテストを使用している例は豊富にありますが)。フィードバックアプローチは、シェーダが実行されるまでフィードバックの更新を延期することを意味するため、アルファテストの影響も受けます。また、我々のアルゴリズムはフィードバック更新と組み合わせて使用することができることにも注意しなければなりません。
6 Conclusions
我々は、新しい\(z_{min}/z_{max}\)カリングアルゴリズムを提案しました。これは、従来のフィードバック更新メカニズムに代わる興味深い代替手段であり、競争力があると考えられます。我々のアルゴリズムは、理想的なフィードバックアーキテクチャ(遅延なし)と同様の性能を持ちながら、厳格なフィードフォワードパイプラインの利点を保持しています。これは、フィードバック遅延から発生する可能性のある危険を考慮したり、処理したりする必要がないため、実装と検証が簡素化されていることを意味します。さらに、粗い深度バッファと通常の深度バッファのタイルサイズを切り離すことで、粗い深度バッファエントリのタイルサイズとビットレイアウトを自由に選択できるようになります。これにより、ハードウェアシステムのロードバランスを容易にし、メモリバス幅またはキャッシュラインサイズが変更された場合の再設計サイクルを簡素化することができる。このように、私たちのアプローチは、現在および将来のGPUに適したコスト効率の高い柔軟なソリューションであると考えています。
Acknowledgements
匿名のレビュアーの方からのご意見に感謝したいと思います。また、本研究を支援してくださったDavid Blythe氏とMike Dwyer氏にも感謝します。Tomas Akenine-Möllerは、スウェーデン王立科学アカデミーの研究員で、クヌート&アリス・ワレンベルグ財団からの助成金を受けています。本論文のスクリーンショットの許可に協力してくださった以下の方々に感謝します:UNIGINE Corp.のBeth Thomas氏、ActivisionのChrister Ericson氏、Respawn EnterimainentのAbbie氏、2K GamesのNaty Hoffman氏、EA Digital Illusions CEのMartin Lindell氏とJohan Andersson氏、BitsquidのTobias Persson氏、WB Games Montreal Inc.のKelly Ekins氏、Rocksteady StudiosのGuy Perkins氏、UbisoftのHeather Steele氏、FuturemarkのJames Gallagher氏。
Appendix
Coarser depth test
粗い深度テストでは、合格マスクと不合格マスクの2つのサンプルごとのマスクが生成されます。残りのサンプルは、通常のサンプルごとの深度テストを使用して試験しなければなりません。

粗いテストの代替バージョンが、サンプルあたりのカバレッジテストの前に実行されてもよいです。上記のバージョンとは対照的に、このテストはカバレッジを考慮しません。正確な更新が我々のアルゴリズムのパフォーマンスの鍵となるため、我々は依然として良好なカリング率を観察しています。

Updating the coarse buffer
粗いバッファは、いずれかのレイヤが上書きされると簡単に更新され、複雑なマルチレイヤの状況を解決するためにヒューリスティックベースのマージ関数が呼び出されます。

Merging depth layers
マージ機能は、3つのレイヤーを2つに減らし、選択マスクを更新します。
