こんらみ。
Pocolです。
今日は,前回読んだ
[Li 2019] Bo Li, “A Scalable Real-Time Many-Shadowed-Light Rendering System”, SIGGRAPH 2019 Talks, https://sites.google.com/view/winningatgameproduction.
のプレゼン資料を見ていこうと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳と共に指摘していただけると有難いです。

多くのシャドウライトを効率的にレンダリングする方法についてお話しします。

写真撮影はご自由にどうぞ、

その動機は?現実の世界に影のないライトはありません。
ライティングアーティストは、良いパフォーマンスのために、何度ゲームに影のない光を入れなければならないのでしょうか?ゲームのPBRライティングがとてもリアルに見えるのに、まだ多くのシャドウのないライトを受け入れている場合、明らかに何かが間違っています。我々はこの壁を打ち破りたいのです。
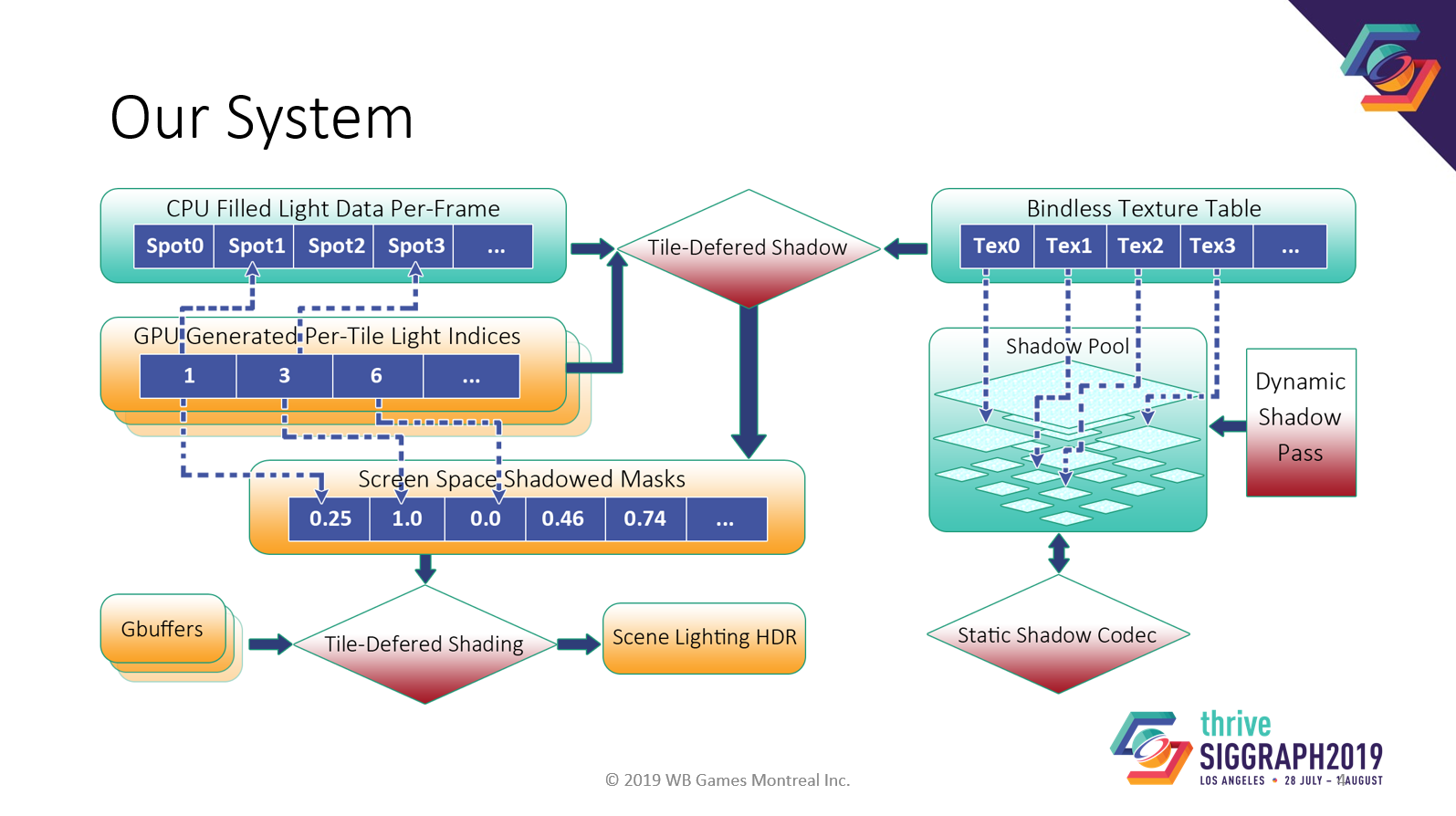
我々のシステム図です。主要な構成要素をひとつずつ見てきましょう。
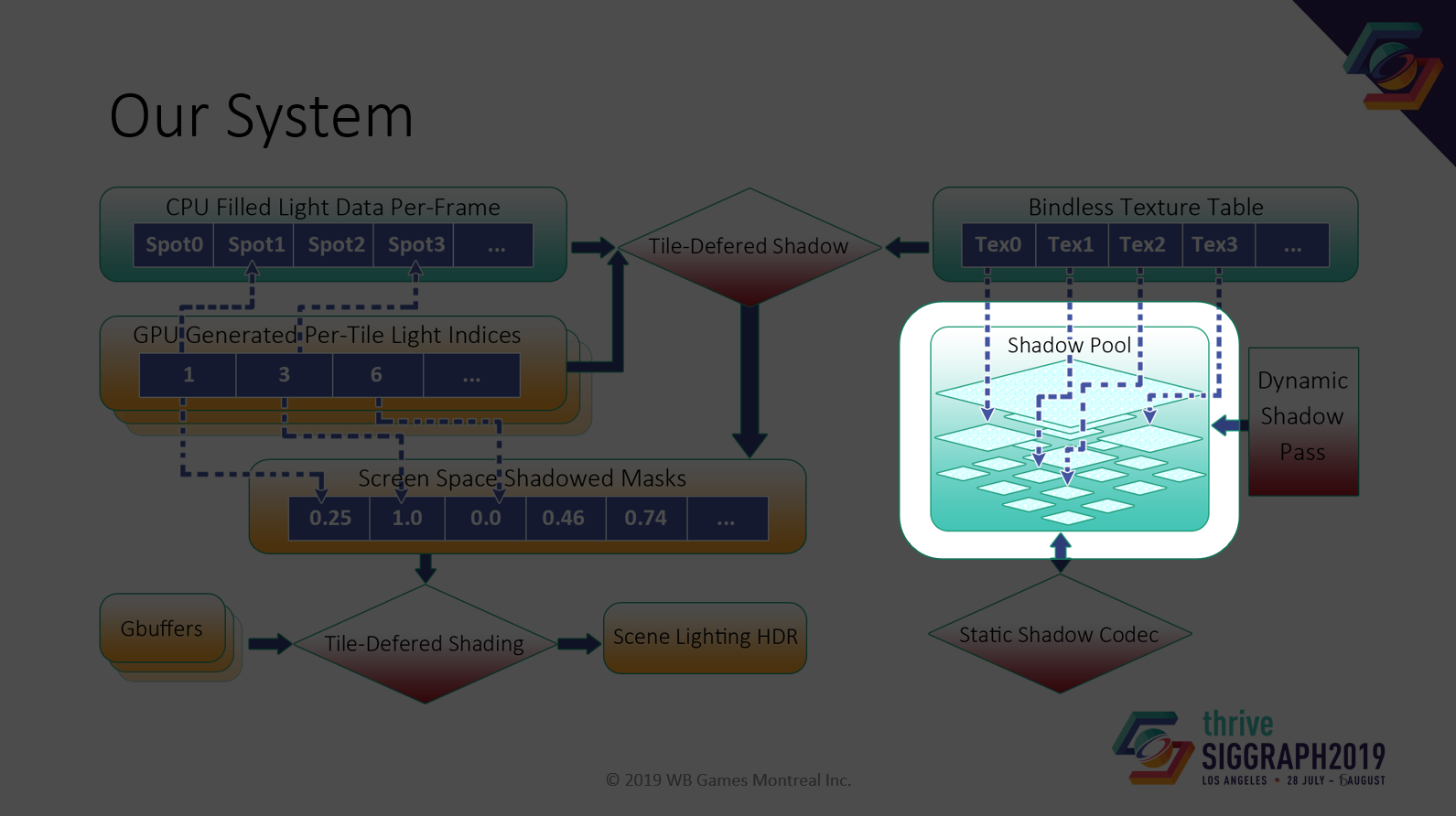
まずは最初にShadow Poolについて話しましょう。
Shadow Poolはランタイムストレージシステムです。
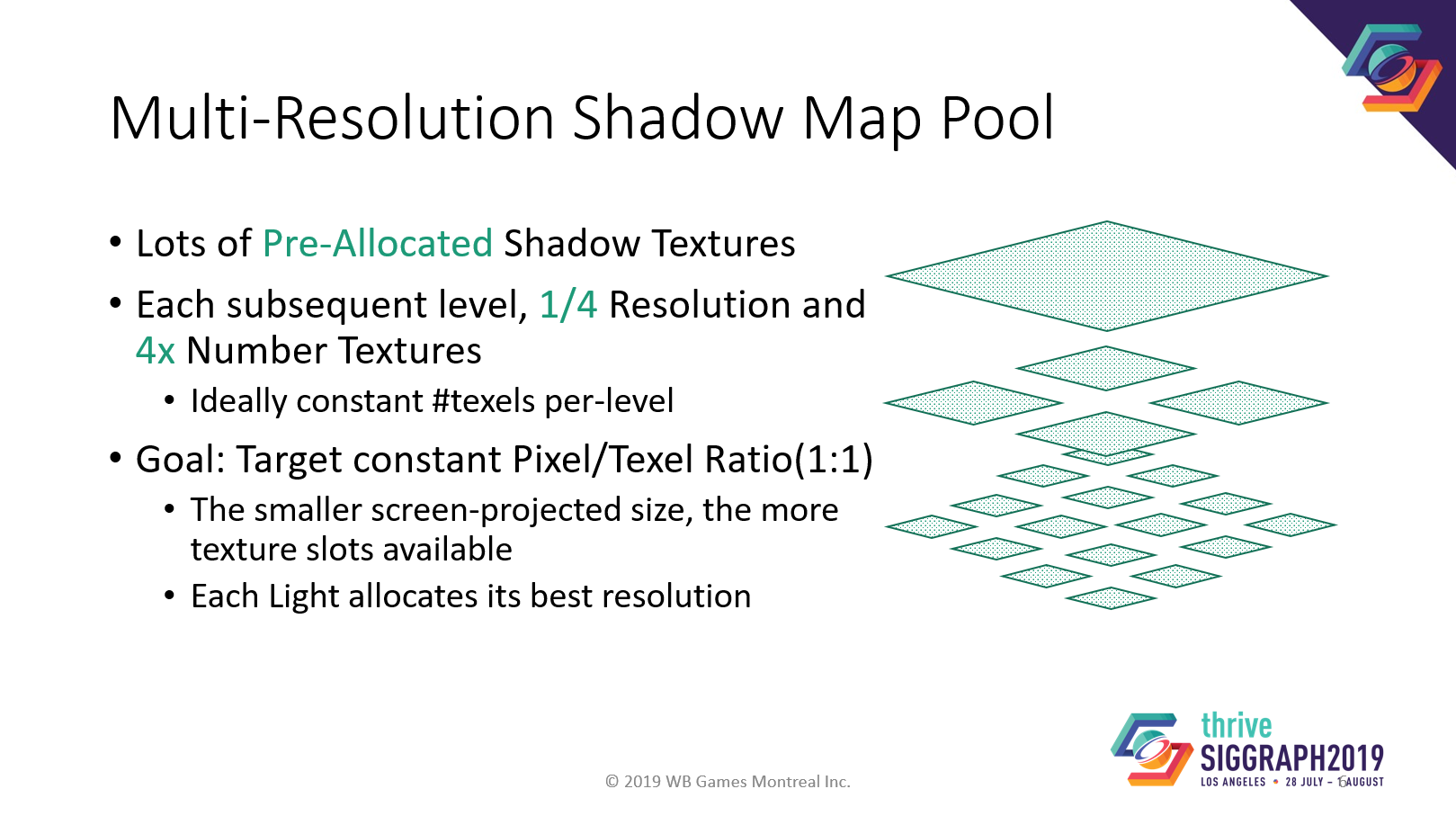
少なくとも数百の異なる解像度のテクスチャを持つ、事前に割り当てられたShadow Poolを使用します。各下層レベルには4倍のテクスチャがあり、それぞれに1クォーターサイズがあります。
なぜでしょうか?カメラのピクセル数は固定で、ピクセルとテクセルとの比率を1:1にするためです。ライトの密度が均一で、どの距離でも常に同じ画面全体を満たすと仮定すると、異なるサイズのライトでも同じテクセル数が必要になります。

現行機での例ですが、トップレベルは2k×2k、最終レベルは32×32。合計156MBのメモリです。
このシャドウマッププールからの割り当ては、最初に完全一致を検索することで機能します。ベストマッチが見つからなかった場合は、空きが見つかるまで低解像度のレベルを検索します。シャドウがポッピングするより、低品質のシャドウの方がずっといいです。
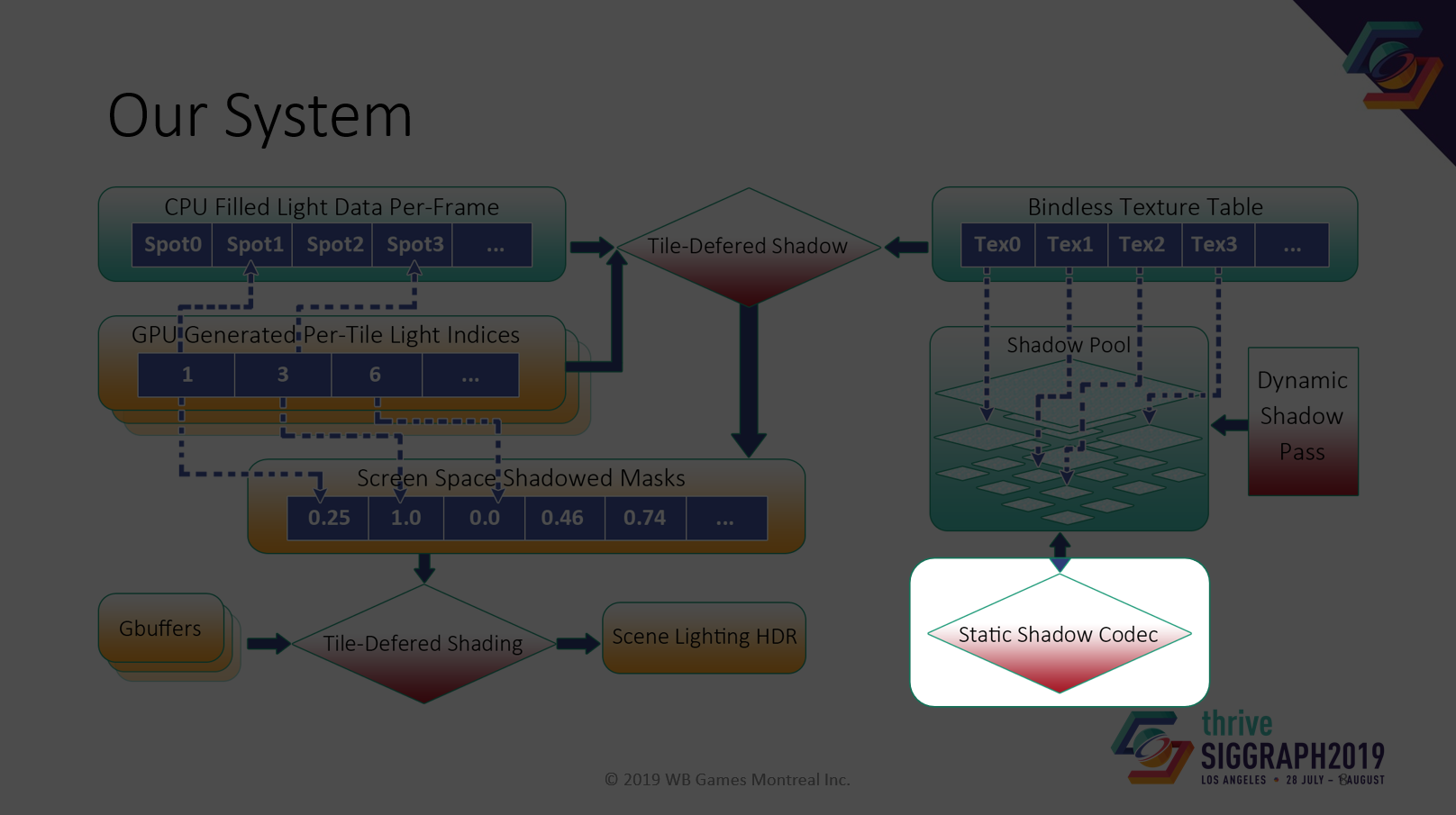
次に、静的なシャドウマップのレンダリングについて話させてください。

必要性はありません。
GPUベースのシャドウマップコンプレッサーを開発し、データストリーミングのサイズを最小限に抑えました。
非可逆圧縮を使用しているのは、入力がノイズであったとしても、常にサイズを縮小できるようにしたいからです。
そして、興味深い挑戦は、保守的なエラーが欲しいということです。つまり、誤差は常に1つの符号になる。そのため、圧縮シャドウマップに切り替えたときに、深度バイアスの設定を微調整する必要がありません。
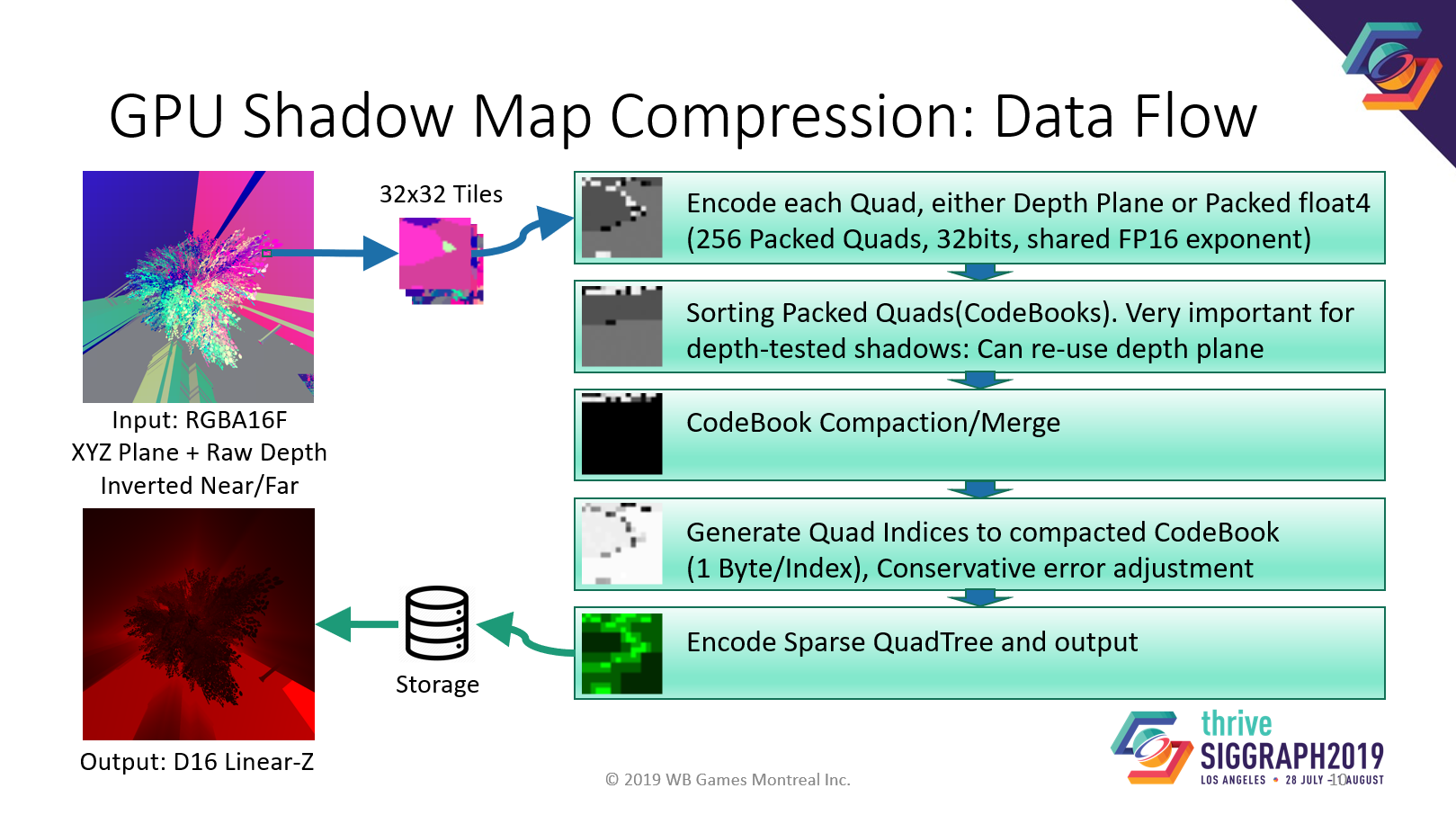
圧縮データの流れです。詳細は大まかにしか話せません。
圧縮の基本ブロックは32×32ピクセルで、コンピュートシェーダースレッドグループで行われます。
まず、2×2の四角形を32ビットのエントリーに圧縮します。同じ三角形に属する場合はxyz深度プレーンとして、またはfloat4としてパックします。
次に、パックされたエントリをソートしてコンパクトにし、重複するエントリを削除し、各四角形でマージされたエントリにインデックスを生成します。つまり、同じ三角形に属しているため、同じエントリーを指す四角形が多数存在することになります。
そして最後に、疎な四分木をsharememoryにエンコードし、バッファに出力します。

ここでの重要なアイデアは、アルファテスト済みのシャドウマップを念頭に置いて設計したことです。そのため、三角形上に穴があっても、インダイレクトを使って同じ三角形データを共有し、サイズを小さくすることができます。
結果:
平均圧縮率は約20:1またはそれ以上です。
100万テクセル解凍にかかる時間は、PS4ベースで0.048ミリ秒です。これはハードウェアのピクセルフィルレートにかなり近いです。

オリジナルのシャドウマップです。

圧縮されたものです。
このシャドウマップは、ライトがアルファテストされた木の真上にあるため、圧縮するのが非常に難しいことに注意してください。それでも圧縮率はそこそこです。
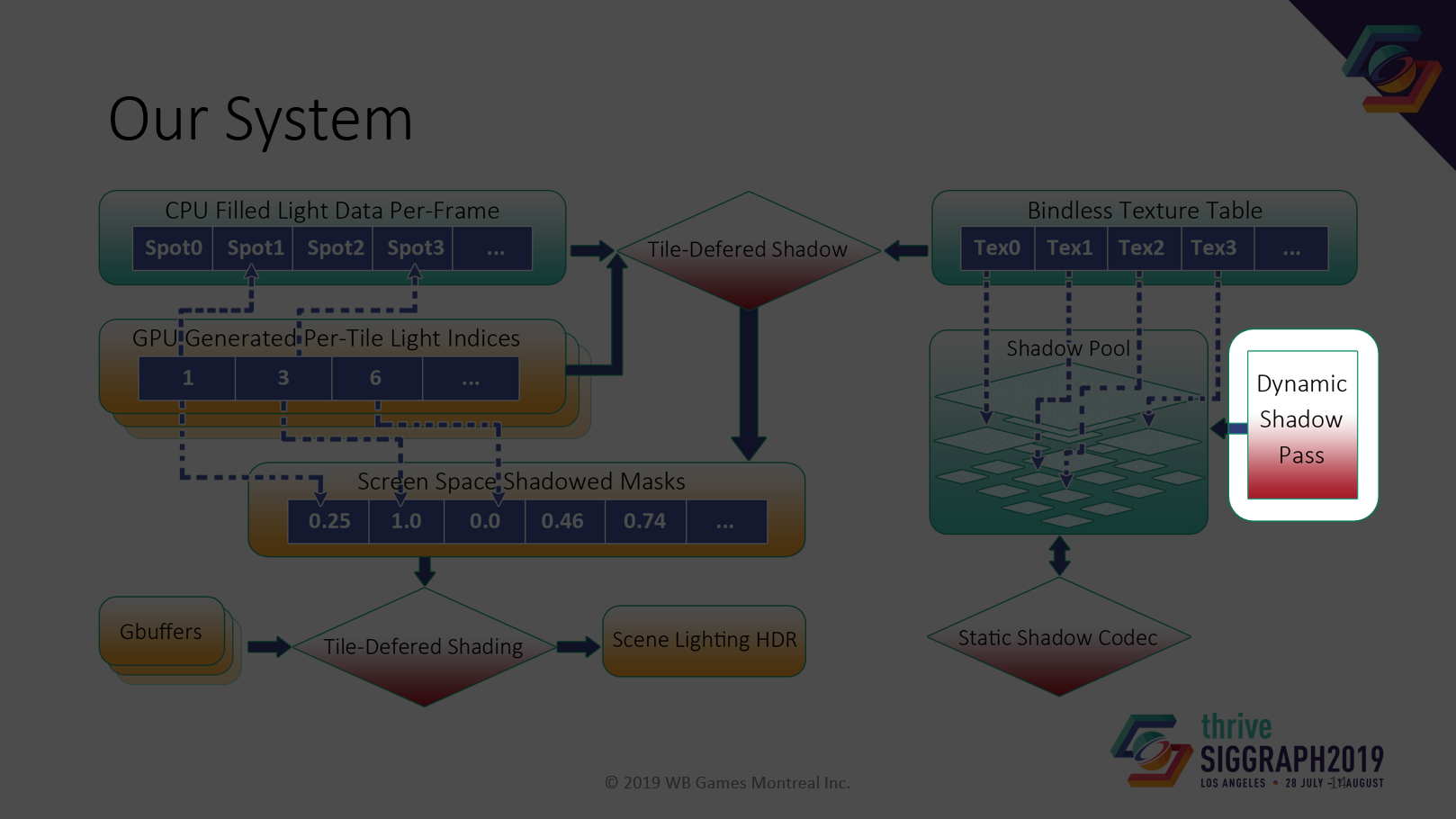
次は動的シャドウパスです。

静的なシャドウをキャッシュしているので、通常は、静的なシャドウマップを新しいRTにコピーして、その上に動的なシャドウをレンダリングしなければなりません。これは効率的ではありません。ライトの前で小さな物体が動いているとします。小さなオブジェクトをレンダリングするためだけに、シャドウマップ全体をコピーしなければなりません。コピーにかかるコストは、レンダリングにかかるコストよりもはるかに高いです。オーバーヘッドを最小限に抑えるのが目的です。

シングルライトに対して分離されたシャドウマップを使用します。左から静的シャドウマップ、動的マスク、動的シャドウマップ。一番右は、従来のゲームエンジンで混合されたシャドウマップです。
それぞれのシャドウマップは異なる解像度を持つことができます。より良いキャラクタの品質のために、より高い解像度の動的シャドウマップを使用することができます。

影の投影とフィルタリングは、まず動的マスクをチェックすることで行われます。もしマスクが真であれば、動的シャドウマップと静的シャドウマップの両方をフィルタリングしなければなりません。偽の場合は、静的なものだけをフィルタリングします。
そのため、動的マスクはコンサバティブにラスタライズされなければなりません。動的マスクは、動的オブジェクトとフィルターカーネルサイズをカバーしなければならないからです。

では、どのようにしてコンサバティブな動的マスクを生成するのでしょうか?通常の深度バッファに加えてUAVをバインドし、クアッド中心からカーネル半径だけ拡大した位置をマスクに出力します。
コンソールの場合、UAVのフォーマットは8ビットでよく、これはUAV型ロードの最小サイズです。

我々は、コンソールの部分的な深度解凍に動的マスクを使用しています。通常、深度解凍は GPU の固定コストです。オーバーヘッドを低減するため、動的マスクが触れるH tileのみを解凍し、大幅なスピードアップを達成しました。PS4では2k×2kのシャドウマップを、バッファクリア、レンダリング、デプス解凍を含めて0.05msでレンダリングできます。

ロバストな深度バイアスについて話させてください。シャドウマップの解像度には非常に多くの可能性があるため、すべてのケースで機能する非常にロバストなシャドウバイアスが必要です。我々のシャドウバイアスは非常に堅牢なので、エディタからシャドウバイアス設定を削除しました。

我々は、数値の丸め誤差を修正するために、絶対に最小限のUniform Depthバイアスのみを使用します。シャドーアクネのほとんどは深度の傾斜から生じたものです。
多くのゲームエンジンはこれを間違えていました。どちらの2ビットエンジンも、私はどちらとは言いませんが、アーティストが各ライトにもっともらしいシャドウバイアスを入力するためには、2つの問題があります:
1: アーティストの負担が増える
2:コンタクトシャドウとシャドウアクネを同時に修正できない可能性があります。左の図を見れば一目瞭然ですが、どちらか一方、あるいは両方が失敗しているのです。
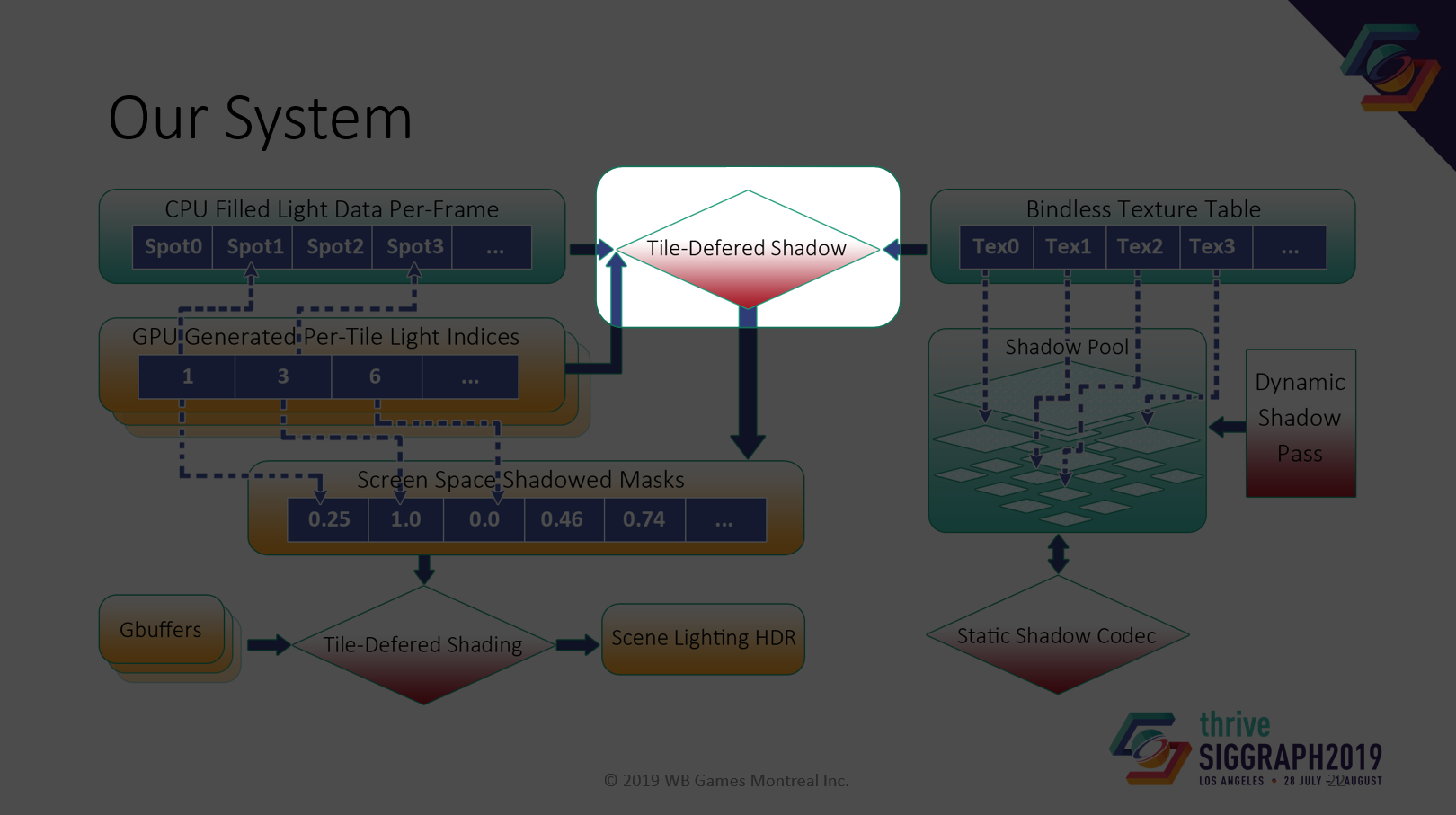
今度は,ディファードシャドウです。

なぜディファードシャドウを選ぶのでしょうか?
占有率のためです。
ディファードシャドウだけでなく、ディファードスポットライトやディファードポイントライトを採用し、占有率とキャッシュ性能をさらに向上させています。
バインドレステクスチャ空間を使用して、すべてのシャドウマップを一度にバインドし、すべてのプラットフォームでインダイレクトにディスパッチします。

タイルドディファードシェーディングの古典的な問題は、ライトのカリングのための深度の複雑さです。ディファードシャドウは深度の複雑さに対してより敏感です。
このトピックについては多くの議論がありますが、我々はシンプルな解決策を選びました。タイル内の特別なサンプリングパターンを使って、バウンディングボックステストの後に、ライトが本当にサンプルに触れているかどうかをテストします。このパターンは、各行と列が少なくとも1つのサンプルを持つように構築されているので、シーン内の非常に薄い特徴をキャプチャすることができます。
理論的には、非常に小さなライトを見逃すかもしれませんがが、実際には、非常に小さなライトをフェードアウトさせたので、アーティファクトは見られません。
選択的サンプルテストのコストは、わずか0.1msから0.3msです。

これがその例です。真ん中がバウンディングボックスのライトカリングで、偽陽性がはっきりとわかります。そして右側は、選択的サンプルテストの結果です。はるかにクリーンです。
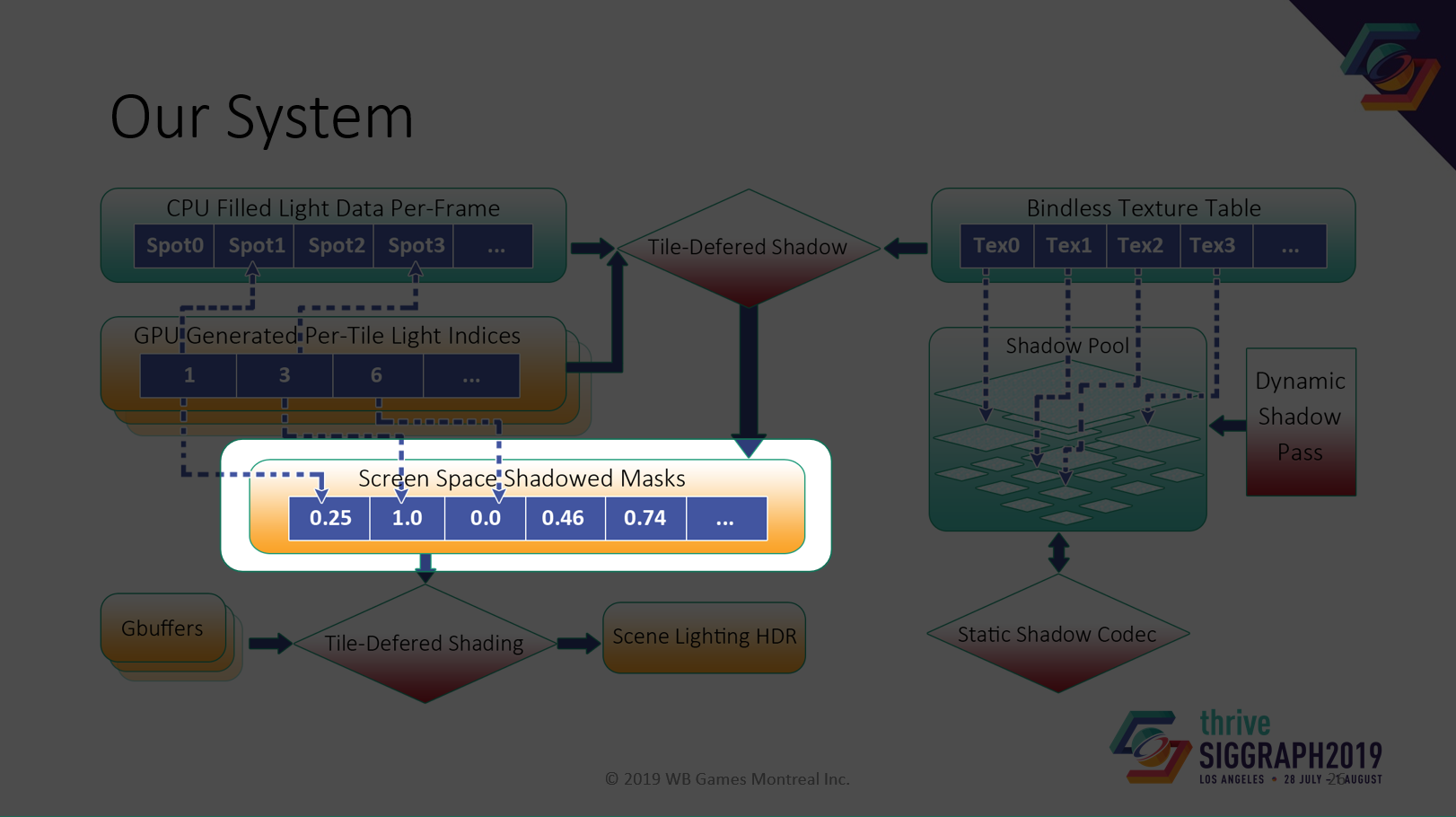
最後に、ピクセル単位のシャドウ・マスクについて話させてください。

ディファード・シャドウの問題点の1つは、ディファードシャドウからディファードシェーディングに大量のデータを渡さなければならないことです。
4Kネイティブ解像度、ピクセルあたり16個のライトの場合、ライトマスクに128MBが必要です。
チャンネルあたりのビット数を減らすことはできますが、品質は犠牲になります。
しかし、我々は良い品質でさらにサイズを小さくできる新しいソリューションを持っています。

アイデアはベクトル量子化です。大きなコードブックを使って、入力ブロックの最適なマッチングを見つけます。
ブロック全体のインデックスを保存するだけでよいです。
デコードは非常に高速で,キャッシュからのメモリコピーだけです。

ピクセルごとに何千ものブロックを検索できるのでしょうか?実際、それは可能です。
まず、O(log(n))のフルバランスサーチツリーを使用します。
ブロックマッチングにはMsad4があります。
ブロックマッチングにはMsad4、スレッド間のデータ同期にはlaneswizzleがあります。

以下にベクトル量子化圧縮コードの例を示します。説明する時間はありませんが、すべてそこに書いてあります。
この関数はピクセルごとの周波数で実行されるので、最も効率的というわけではなく、非常に使いやすい。

品質比較。参考品質として、4ビット/ライトチャンネル+TAAを掲載します。

2bit/light チャンネル

1bit/light チャンネルでは、かなりノイズが多くなります。

そして、これが我々の0.75bit ベクトル量子化圧縮です。

比較のため、もう一度4ビットに戻します。

パフォーマンスはどうでしょうか?これは大量のメッシュ、NPCの発砲、2500個のシャドウライトがある内部テストレベルのGPUキャプチャーです。
このキャプチャでは、シャドウの使用時間はフレーム全体で1ms未満です。
もちろん、ボリューメトリックフォグなどの他のエフェクトがシャドウデータを使用する場合、それらはここには含まれませんが、コストは同じオーダーになるはずです。
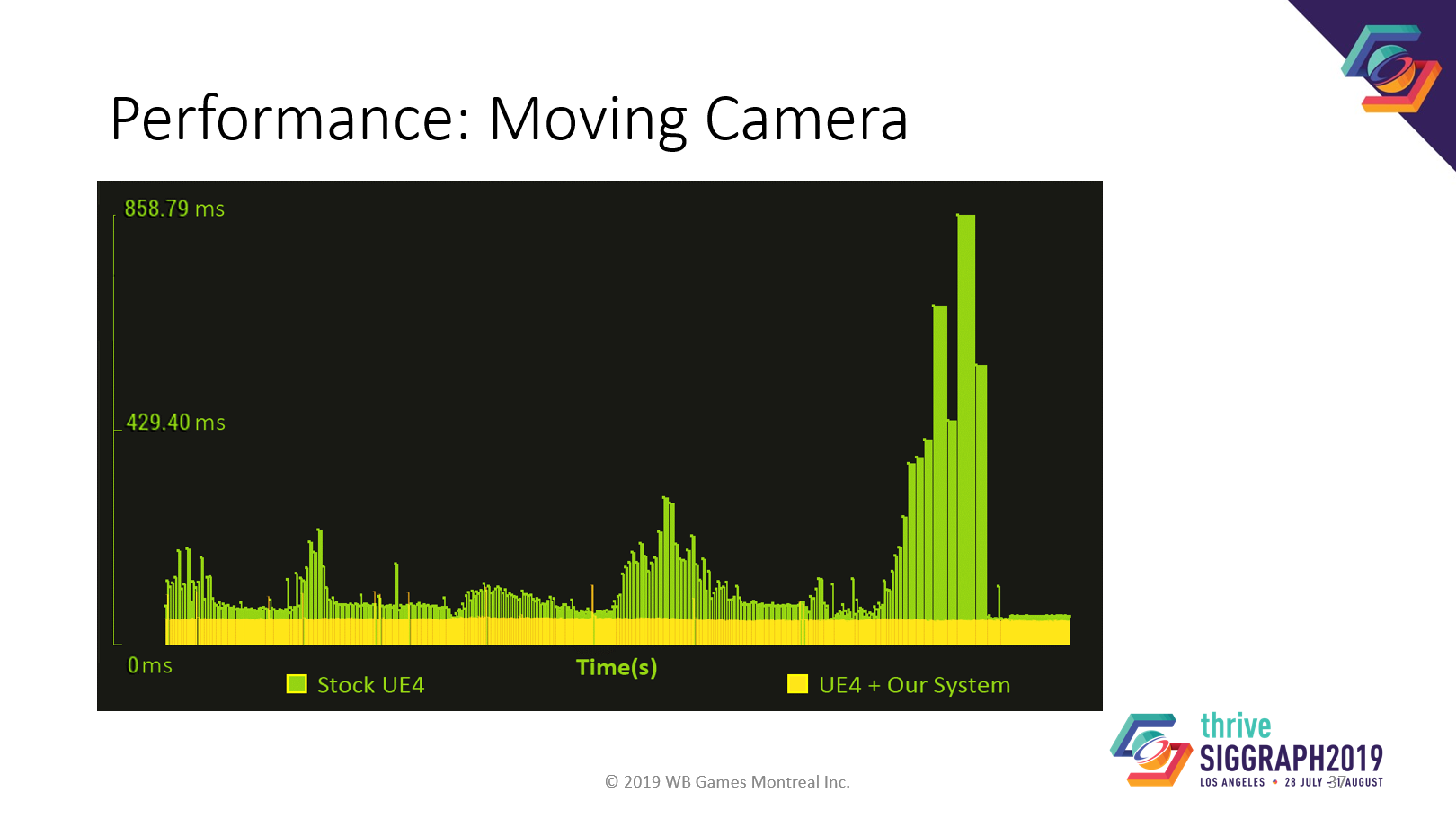
我々のシステムは、動くカメラで実力を発揮します。これは、あるカットシーンテストで、カメラが常に動いている状態でのフレームタイム記録です。
黄色が我々の修正したUE4エンジン、緑が平凡なUE4エンジンです。
ノーマルのUE4エンジンと比較して、フレームレートが大幅に安定しています。10%から1500%のパフォーマンス向上を達成しました。

ワールドのダイナミックな木々をどう扱うかが課題の一つです。それらは頂点アニメーションを持つ静的メッシュです。キャッシュすれば静的に見えるし、レンダリングすれば膨大な数のドローコールが発生します。我々は、樹木に近づいたときに動的にレンダリングするようにしています。しかし、テクスチャ空間のステートレスアニメーションは将来的に面白いかもしれません。

ワーナーブラザーズゲームモントリオールのおかげでこのようなことが可能になりました。ボリューメトリックフォグのアイデアを提供してくれたSebとGabrielに感謝します。

また、質問があれば、バックグランドでビデオを流すつもりです。
https://youtu.be/lyYpFVB_-fI