こんるるー。
Pocolです。
今日は…
[McLaren 2022] James McLaren, “Adventures with Deferred Texturing Horizon Forbidden West”, GDC 2022.
を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳と共に指摘していただけると有難いです。
断りが無い限り,図は[McLaren 2022]からの引用です。

“真の発見の航海は、新しい風景を求めることではなく、新しい目を持つことにある”
– Marcel Proust
“Horizon Forbidden West”では、アーロイは遠い異国の地で、たくさんの新しい風景とともに大冒険を繰り広げますが、そのいくつかを実現するためには、レンダリングパイプラインを新たに見直す必要がありました。

こんにちは。
私の名前は, James McLarenで,ゲリラのシニアプリンシパルテックプログラマーです。
この講演では、主にHorizon Forbidden Westのフォリッジを高速化するために作ったDeferred Texturingシステムの詳細について説明します。

まず、フォリッジのレンダリングの問題点についてお話しし、以前のシステムを見直した後、ディファードテクスチャリングとは何かについて少しお話しします。それから、我々のシステムのハイレベルな概要を説明し、その前に、いくつかの詳細に飛び込んで、可変レートシェーディングの実装について少しお話しし、最後にいくつかのパフォーマンス数値についてお話しします。

その前に、何も知らない人のために、Horizon Forbidden Westを紹介しましょう。
Horizon Forbidden Westは、Horizon Zero Dawnの続編として今年2月に発売されたPS4&PS5用のオープンワールドアドベンチャーゲームです。
このゲームでは、ノラ族の勇者アーロイを操作し、たくさんの危険な機械と戦いながら世界を救うことになります。
このトレイラーをご覧ください。

Horizonの世界には、森や緑豊かなジャングルなど、多様な環境がある可能性があります。
これらは通常、効率的にレンダリングするのが難しいです。ほとんどの植物はアルファテストされたジオメトリで構成されており、非常に大量のオーバードローが発生する可能性があります。
ジオメトリはアニメーションでもあり、TAAやモーションブラーに反映させるために正しいモーションベクトルを生成する必要があるため、簡単にカットできるわけではありません。

Horizon Zero Dawnでは、すでに高度に最適化されたフォリッジシステムがありましたが、Horizon Forbidden Westでは、アート部門がさらに高密度のアセットを望みました。
特にPS4をターゲットにする必要があったため、彼らがプロジェクトに求めているものをすべて詰め込むのは、本当に厳しいものになりそうでした。
念のために言っておくと、アート部門が我々にもっと多くのものを求めたときにどう見えたか気になる人もいるでしょう。
これはゲームでの劇的な再現です。

だから、何ができるか見てみたいという意欲はかなりありました。

フォリッジのレンダリングは高価です。
オーバードローが多く、アルファテストが行われる傾向があり、ハードウェアの初期Z最適化のいくつかが無効になる可能性があるため、さらに費用がかかります。
Horizon Zero Dawnでは、デプスプリパスを使用してアルファテストを行い、その後、アルファテストなしでジオメトリパスでフォリッジを再度レンダリングしますが、デプスイコールテストを使用して、目に見えるピクセルのみを確実にシェーディングすることで、これを回避しました。これは、G-Bufferのフォリッジピクセルに2回以上書き込まずに済むので、かなり良い解決策です。

しかし、この方法にはいくつかの問題があります。
すべてのジオメトリをGPUで2回変換しなければなりません。
このため、GPUがすべてを再度レンダリングするときに、頂点が変換されたにもかかわらず2回目のパスでピクセルワークを生成しないギャップがたくさん発生し、GPUがいっぱいになることもよくあります。
また、フォリッジに典型的な細かいディテールがある場合、このアプローチは大量のクアッドオーバードローに悩まされる可能性があります。

もしあなたがQuad overdrawについてよく知らないのであれば、非常に簡単な概要を説明しましょう。
GPUのピクセルシェーディングハードウェアは、正しいミップマップを選択し、テクスチャがサンプリングされたときに正しくフィルタリングできるように、自動的に微分を計算できる必要があります。
これを行うには、常に 2×2 quad でシェーディングします。
この方法では、あるレーンの UV 座標を別のレーンから差し引くために有限差分を使用し、テクスチャサンプリングに必要な導関数を計算することができます。
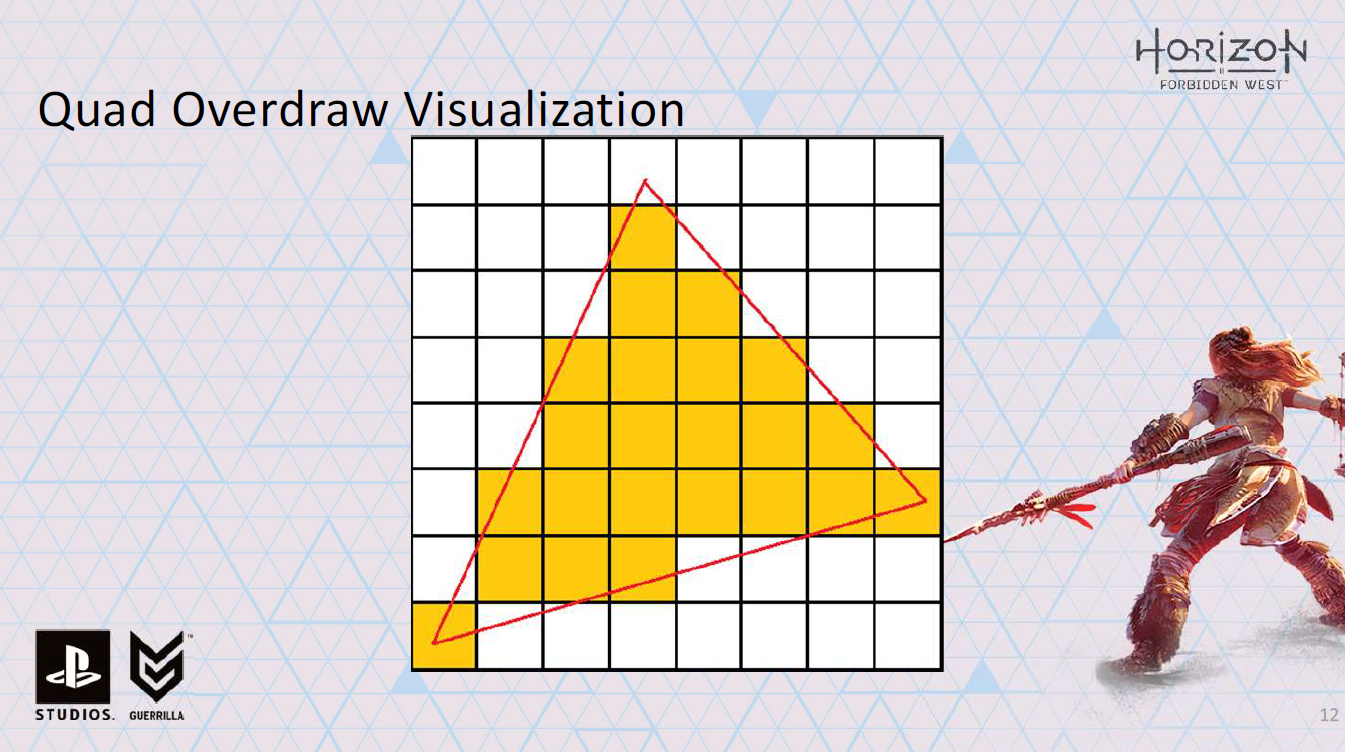
ちょっとイメージしてみましょう。ここに三角形を描きます。
ラスタライズしています。
黄色のピクセルはラスタライズの結果を示している。
残念ながら、HWはシェーディングするピクセルをスケジュールするのではなく、クワッドをスケジュールします。
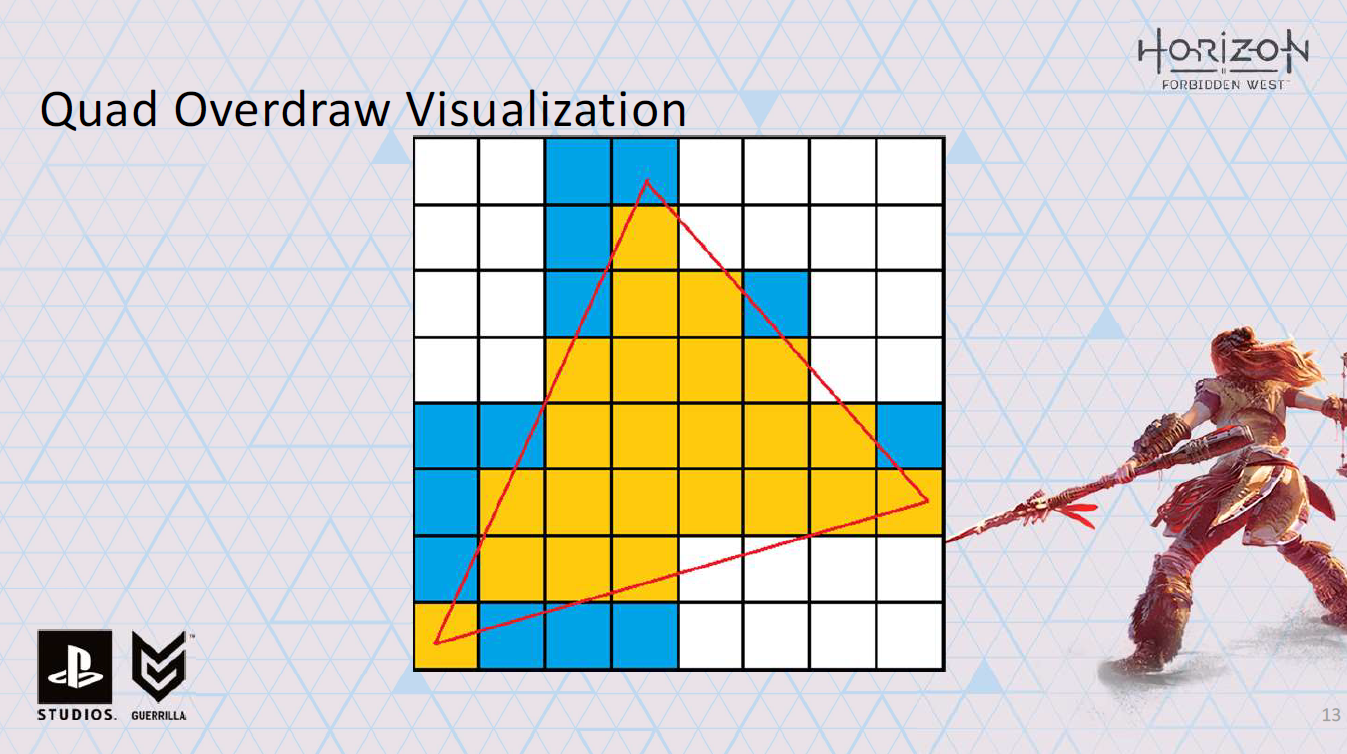
つまり、ここではすべての青いピクセルのシェーディング処理も行うことになります。
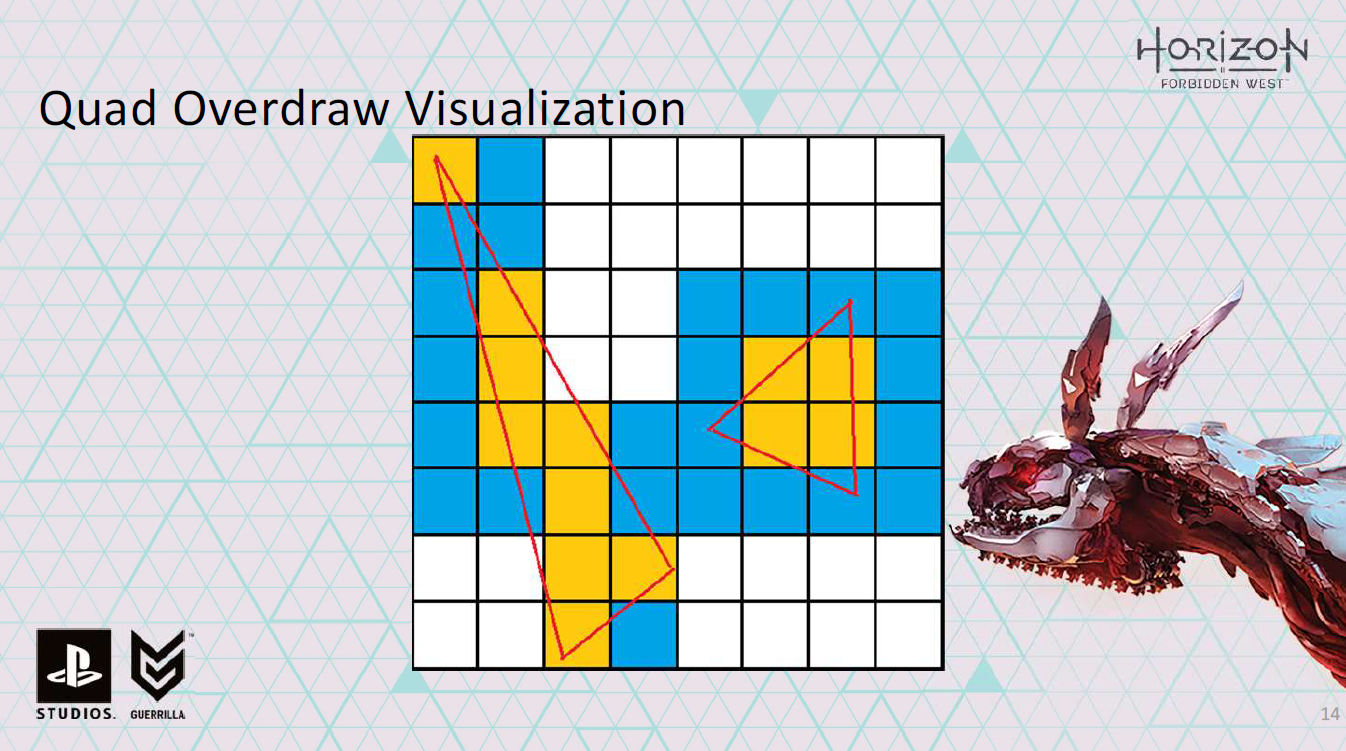
そして、小さな三角形になればなるほど、この問題は悪化します。
右の三角形は特に悲しい。出力は4ピクセルだが、微分を計算するために16ピクセルのシェーディング処理をしなければならなりませんでした。
これが、クワッドオーバードローについて話すときの意味です。
フォリッジの場合、大きな三角形で済むこともありますが、細かいディテールを模倣するために、通常はアルファテストを伴います。
この場合、ジオメトリパスでデプスイコールテストを行うときに、我々の古いシステムでまったく同じクワッドオーバードローの問題が発生しました。

この知識を手にして、我々はより良い解決策を探し求め、新たな冒険へと向かう準備が整いました。

これは冒険に向かうアーロイです。

我々が踏み出そうと決めた大冒険は、ディファードテクスチャリングを実装してみることでした。
ここでの基本的なアイデアは、不透明なジオメトリをレンダリングする前に、シーン上でプリパスを行い、Visibility Bufferを生成するというものです。
これは、追加のレンダーターゲットにPrimitive IDを書き込むことを除けば、深度プリパスと非常に似ています。
これが完了すると、Visibility Bufferには、各ピクセルの一番上の三角形のPrimitive IDが含まれます。
このバッファを分析し、Pimirive IDを使ってピクセルをシェーディングすることができます。

このアイデアは、もともとインテルの論文に記載されていたものです: The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading.
これは、フォワードレンダラーとディファードレンダラーの両方に適用できます。
HFWではディファードレンダラーを使用しているため、ピクセルをシェーディングするパスがGbufferを生成します。

そしてこれは、同じシーンを色分けして視覚化したもので、ビジビリティバッファに入れるすべてのprimitive IDを示しています。
おわかりのように、実際に有効なプprimitive IDを持つピクセルは一部だけで、黄色いピクセルはビジビリティバッファに含まれないピクセルです。

では、なぜこんなことをするのでしょうか?
ひとつには、見えるピクセルのみをシェーディングすることで、オーバードローを防ぐことができるからです。
理屈の上では、処理の仕方によっては、クアッドのオーバードローの問題からも解放されます。
また、すべてのジオメトリをもう一度変換する必要もありません。画面に表示されているものだけ、あるいは実装の仕方によってはまったく変換しないこともできます。
また、少なくとも素朴なディファード・ソリューションと比較すれば、帯域幅の節約にも役立ちます。
とはいえ、すべてが晴れやかでリセットされているわけではありません。
ハードウェアがクアッドを生成してくれないので、微分の生成に有限差分が使えなくなり、自分で計算しなければならなくなりました。
また、マテリアルを解決するために、ビジビリティバッファにあるすべてのピクセルを効率的にディスパッチまたは描画する方法を見つけ出すという重要なタスクが待ち受けています。
どんな優れたテクニックでもそうであるように、これはすでに様々な形で提供され始めています。

元の論文では、triangle IDとinstance IDを32ビット単位でエンコードしたシンプルなビジビリティバッファを出力しています。
そして、これを解析し、それぞれのユニークなマテリアルを含むスクリーンスペースタイルのセットを構築しています。
その後、間接ディスパッチを使ってコンピュートシェーダーを起動し、マテリアルごとに記録されたタイルのセットを処理します。
primitive IDが読み込まれ、頂点情報を読み込むために使用され、重心座標が計算され、あらゆる頂点変換処理がピクセル処理と一緒に行われます。
アトリビュートの導関数も、必要であれば、タンジェントフレームとともにタイルを処理するコンピュートシェーダで手動で計算されます。
最後に、シェーディングと照明の結果は、中間 Gbuffer なしで書き出されます。

これとは反対に、Dawnエンジンのようなものもあります。ここでは、似たようなアプローチを取っていますが、マテリアルを解決する際に、微分、重心座標、タンジェントフレームをバックエンドで計算する代わりに、その作業をフロントロードで行います。そのため、UV、微分、マテリアルID、タンジェントスペースは、レイダウン時に非常にファットなビジビリティバッファに詰め込まれます。
その後、ビジビリティバッファが分析され、material IDが16ビットの深度バッファにコピーされます。
その後、私が「深度バッファの創造的な乱用」と呼びたいものを使用して、各マテリアルをシェーディングします。
その後、material IDごとにデプスイコールテストを使って適切なピクセルを選択し、ピクセルシェーダーでシェーディングします。
そのマテリアルを使用するすべてのオブジェクトを囲むスクリーン空間のクアッドを描画し、クアッドの深度をmaterial IDと同じに設定します。

そして、その2つの間のどこかにある他の亜種があります。
Tomasz Stachowiak氏のdeferred materialシステムは、マテリアルごとにピクセルのリストを生成することで、重心座標をprimitive IDとコンピュートシェード内のシェードとともに書き出します。
最近ではNaniteがあり、Activision Naniteのジオメトリパイプラインは、圧縮されたソフトウェアラスタライズされたジオメトリクラスタで動作し、64ビットUINTに深度と共にパックされたクラスタと三角形の情報を含む比較的薄いビジビリティバッファを生成します。次に、クリエイティブ深度バッファー乱用トリックのバリエーションを使用して、マテリアルを解決するときにピクセルシェーダーを介してGBufferを書き出します。
ActivisionのGeometryパイプラインもジオメトリクラスタで動作し、ほとんどのジオメトリに対して薄いビジビリティバッファを書き出しますが、フォリッジの場合は、法線、テクスチャLOD、UVをエンコードするために、2つのレンダーターゲットに64ビットの情報を書き出します。これにより、マテリアルの複雑さを制限することで、マテリアルの解決ステップで必要な処理を最小限に抑えることができる。
* この話題に興味があれば、John Hableのブログ記事「Visibility Buffer Rendering With Material Graphs」をチェックすることもお勧めします。

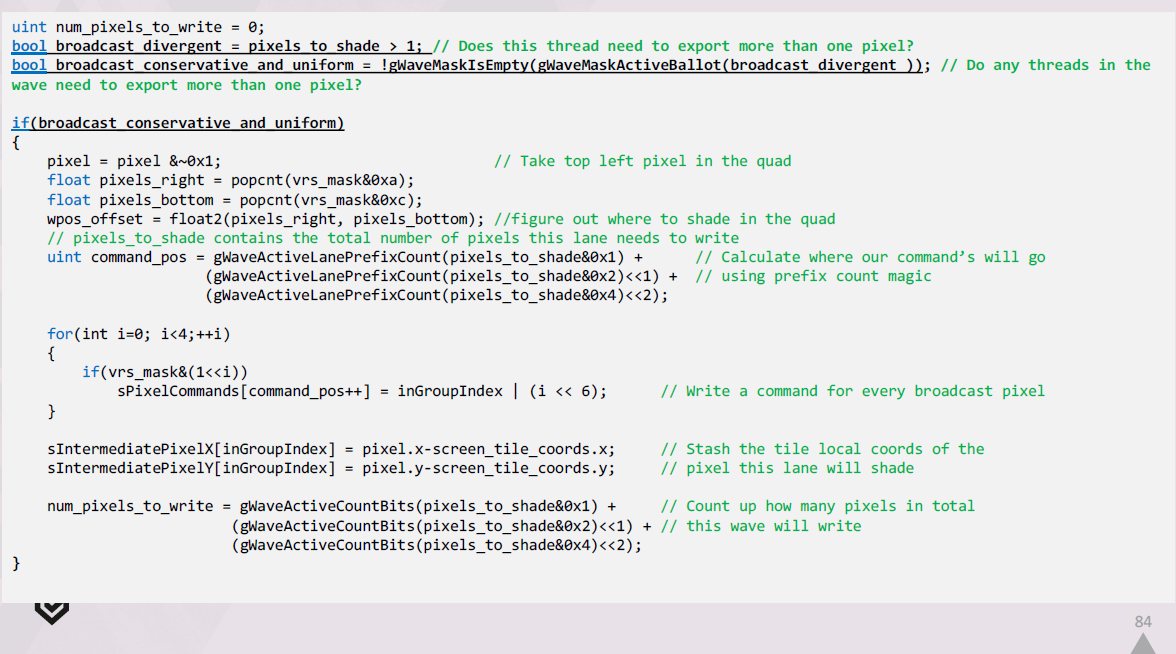
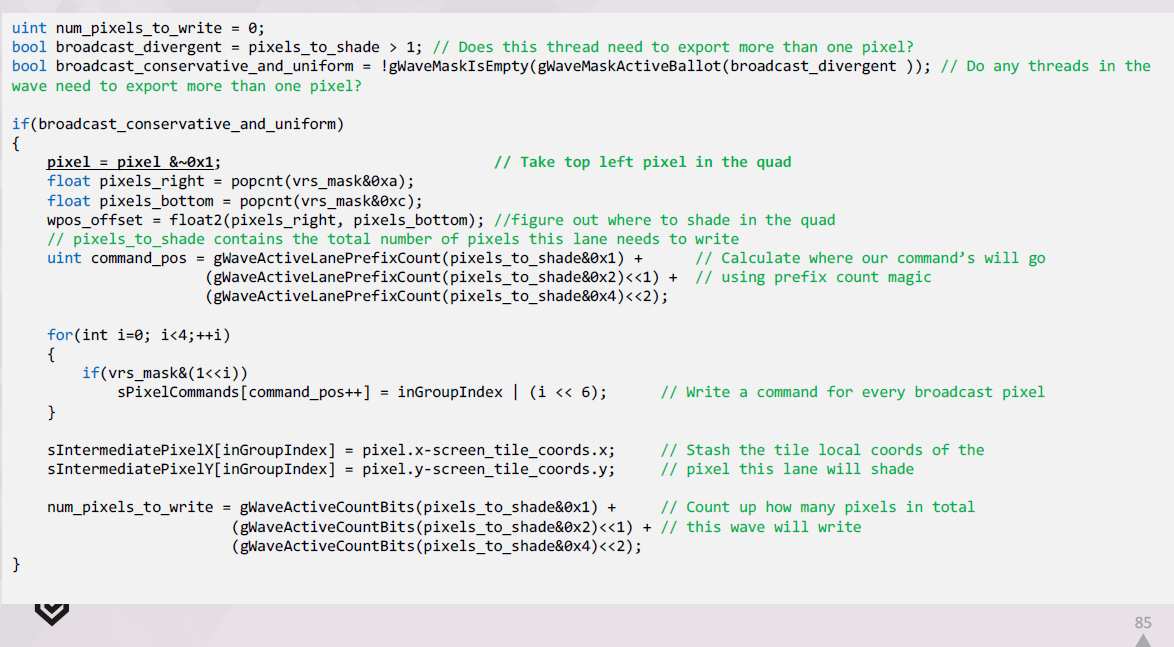
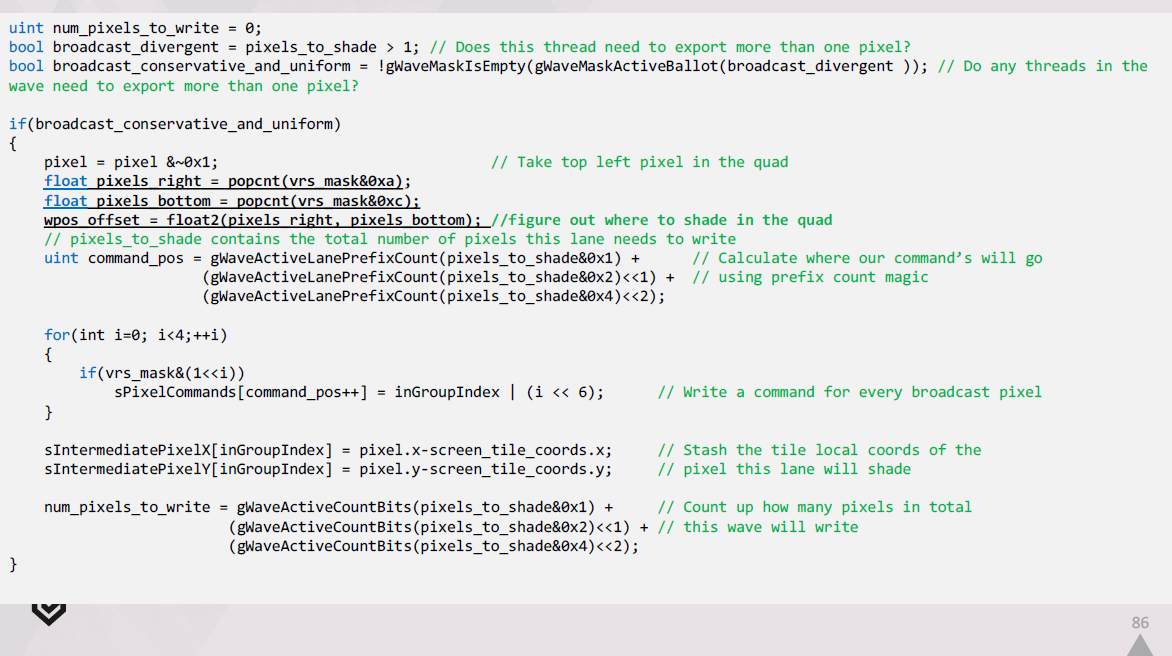
ディファードテクスチャリングシステムをセットアップするための可能性の範囲を考慮して、何をする必要があるかを検討し、要件に適合するものを見つけようとしました。
フォリッジはすべてアニメーションされているため、ダイナミックジオメトリのサポートは必須です。
また、異なる種類のフォリッジには複数の異なるマテリアルがあるので、それらの切り替えを効率的にサポートする必要があります。
PS4とPS5の両方で発売する予定だったので、このアプローチは両方で機能する必要がありました。
PS4で動作させる予定だったので、何をするにしてもメモリを非常に軽くする必要がありました。我々は100ではなく10のMbを買う余裕がありました。
また、通常、フォリッジには多くのオーバードローがあるため、ビジビリティバッファーのレイダウンは非常に安価である必要があります。できれば、単一の32ビット書き出しだけにしてください。
また、これを他の遅延されていないテクスチャジオメトリとうまく統合し、G-Bufferに出力したいと考えていました。

そうしているうちに、この作品がどこに収まるのか、フレームを検討し始めました。
私の最初のプロトタイプはピクセルシェーダーを使っていました。
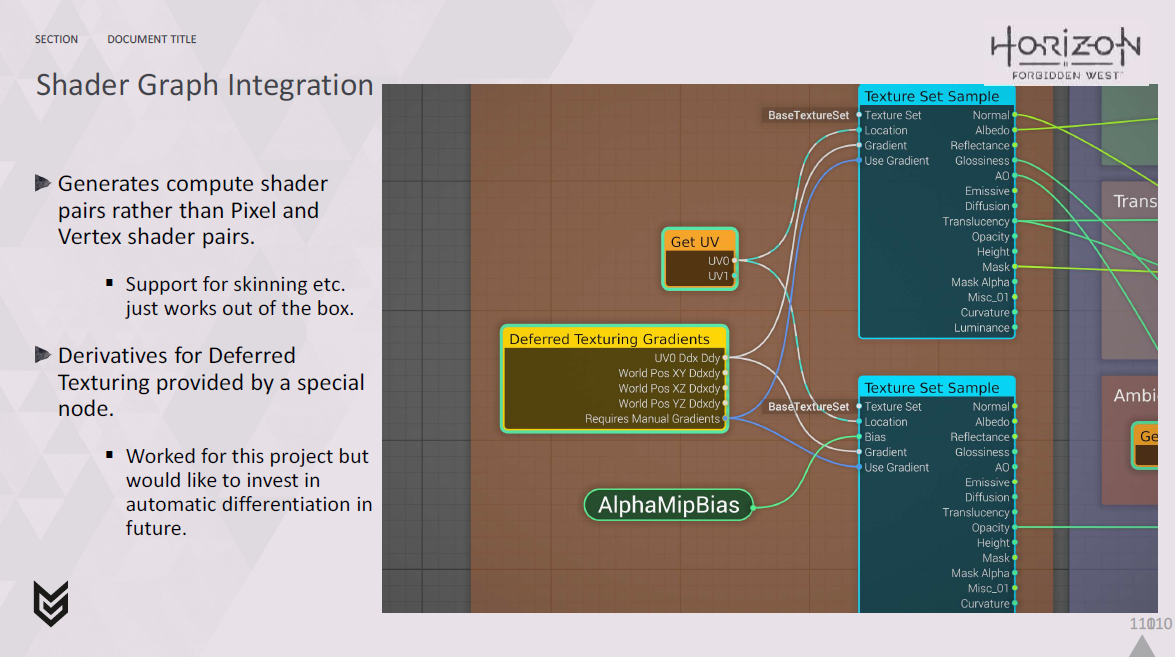
私は、Deferred Texturingを使用する場合、生成されたシェーダーのいくつかを手作業で修正することからこのプロセスを始めました。
それは有望でしたが、それが正しい方法だと完全に確信していたわけではありません。
とにかく、フレームを見始めたとき、私が見たのはこれでした。
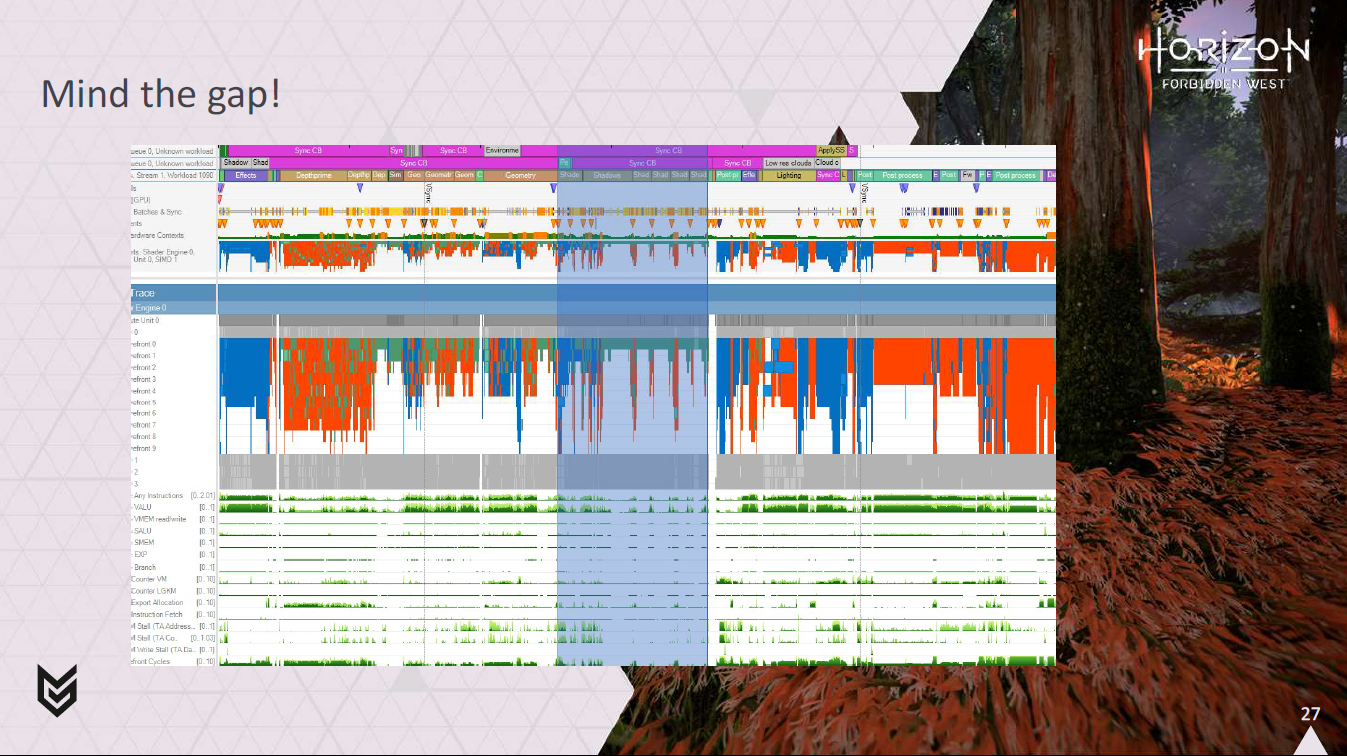
つまり、カスケードシャドウがレンダリングされる場所は、通常、頂点処理で埋め尽くされ、ピクセル処理で埋め尽くされることはあまりありません。
そこで、この隙間にフォリッジのマテリアルをシェーディングできないかと考え始めました。
しかし、これは、シェーディングを行うために非同期コンピュートパイプを使用し、G-Bufferを埋めるためにコンピュートシェーダを使用する必要があることを意味します。

そこで、このことを念頭に置いて、コンピュートでピクセルシェーディングをどのように行うかを考え始めました。
これは見た目ほど単純ではありません。
単純な素朴なアプローチは、少なくとも部分的に同じマテリアルをカバーする小さなタイルを識別し、タイルのリストをシェーディングするディスパッチ間接処理のセットを行うことです。
これは、元のビジビリティバッファの論文が行っていたことです。
しかし、HWが同じマテリアルの四つ組を識別し、我々のためにそれらをwaveにパックすることがなければ、各タイルにある大量のレーンが何の働きもしないことになるのは明らかです。
これは、ピクセルシェーダーが小さな三角形で抱える可能性のある未充填のクアッド問題のようなものですが、実際にはもっと悪いものです!

もうひとつの簡単な方法は、同じマテリアルのピクセルを識別し、シェーディングするピクセルのリストを作成することです。
これははるかに良い方法ですが、この方法にはまだいくつかの問題があります。
効果的にランダムな順序でマテリアルを処理するため、スクリーンスペースで多くのバウンドが発生します。
これは、同じマテリアルとバッチを持つピクセルの大きなグループを扱うのであれば、それほど問題にはなりませんが、フォリッジの場合は、同じスクリーンスペースにたくさんのバッチが混在することになります。
これは、シェーディングを行う際に、同じメモリをL2に何度も出し入れすることになる可能性があることを意味します。
もう1つの問題は、シェーダー、ユニフォーム、テクスチャの組み合わせがそれぞれ異なるバッチが多数ある場合、それぞれに個別のディスパッチが必要になることです(もちろん、ウェーブの分岐を許容したい場合を除きます)。
また、コンピュートパイプを使用している場合、これは法外に高価になる可能性があります。各ディスパッチは、GFXパイプで処理するよりもCPで処理する方がかなり時間がかかるため、CPUがかなり制限されることにつながります。


そのため冒険の精神で…
両方のアプローチを組み合わせてみることにしました。
我々は、タイルの優れた空間的な局所性と、ピクセルのリストのパッキングの柔軟性を求めていました。
そこで考え出したのが、私が「ルーズタイリング」と呼んでいるアプローチです。
基本的な考え方は、128×128ピクセルの大きなタイルで処理することです。
タイル内で、同じシェーダーを使用するピクセルを識別しますが、同じ定数やテクスチャを使用するとは限りません。
つまり、これらは異なるバッチから来る可能性があります。
そして、これらのピクセルを、同じ定数とテクスチャを持つ完全なwaveに分類します。
各ピクセルのコマンドに加えて、各waveに対して、処理中のタイル、処理中のバッチ、ピクセルコマンドの開始位置を示す”wave command”を保存します。

画面上のすべてのタイルに対してこれを行えば、各シェーダーに対して、一度に多くのバッチを処理する単一の dispatchIndirect() 呼び出しで終わることができます。
また、各タイルのピクセルコマンドが一緒に保存されていることを保証するため、それらは互いに近い時間的局所性で処理される可能性が高く、Gbufferを埋めるためにメモリ要求を行うときに、メモリがまだL2にある可能性がより高くなるはずです。
また、同じ定数とテクスチャで完全なwaveを処理しているので、ダイバージェンスを心配する必要はありません。
特定のタイルに収まるようにピクセルコマンドを丸めなければならないので、”埋まらないwave “ができてしまうという若干の注意点があります。しかし、実際には、これは非常に小さな問題になりがちです。
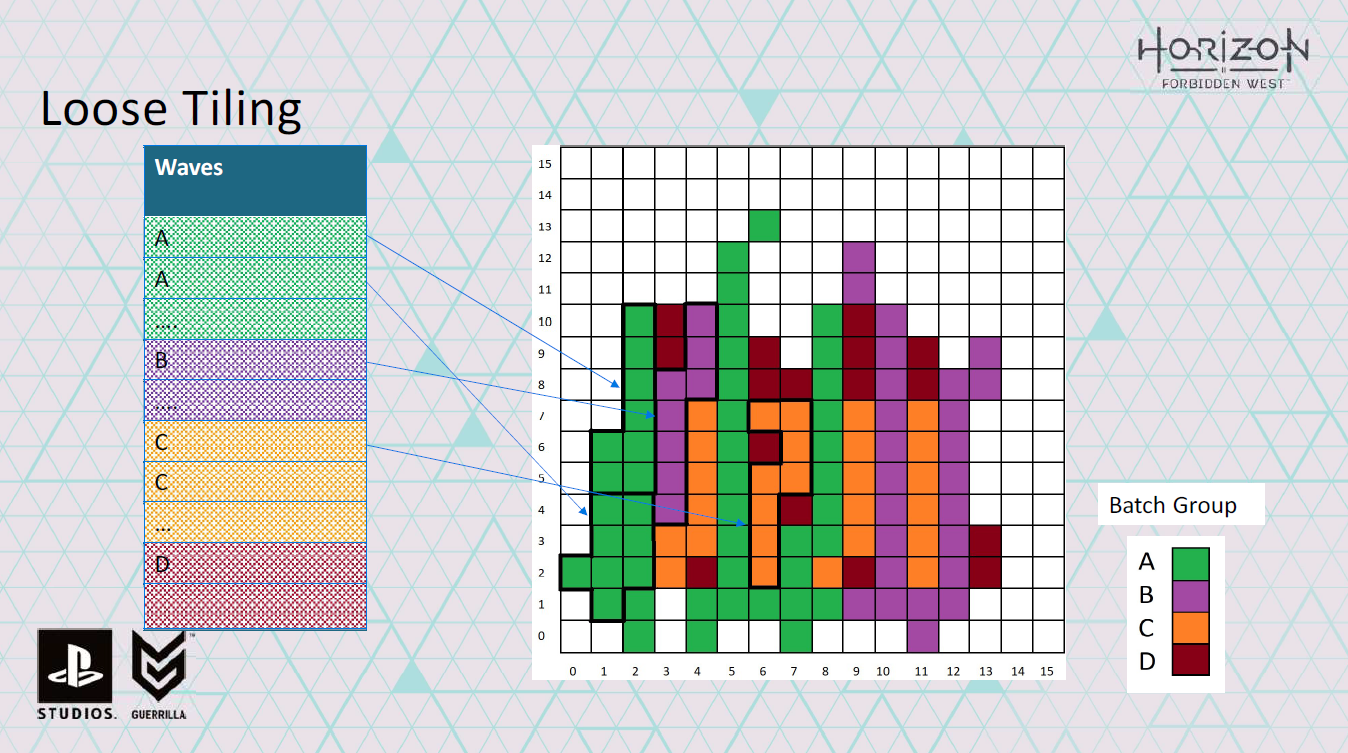
このルーズタイリングのアイデアを実際に使用した簡略化した例を以下に示します。
これがレンダリング中のシーンのタイルだと仮定しましょう。
128×128ではなく16×16ですが、これで十分です。
すべてのカラーピクセルは同じシェーダを使っています。
異なる色は、異なるバッチグループと呼ぶピクセルを表します。
バッチグループとは、同じシェーダ、テクスチャ、定数、ジオメトリを持つバッチの集合のことですが、そのグループ内のバッチは異なるインスタンスセットを持ちます。
….
この例では、ウェーブのサイズが8スレッドしかないGPUを使っていると仮定します。
これから行うのは、同じバッチグループのピクセルをまとめてwaveにすることです。
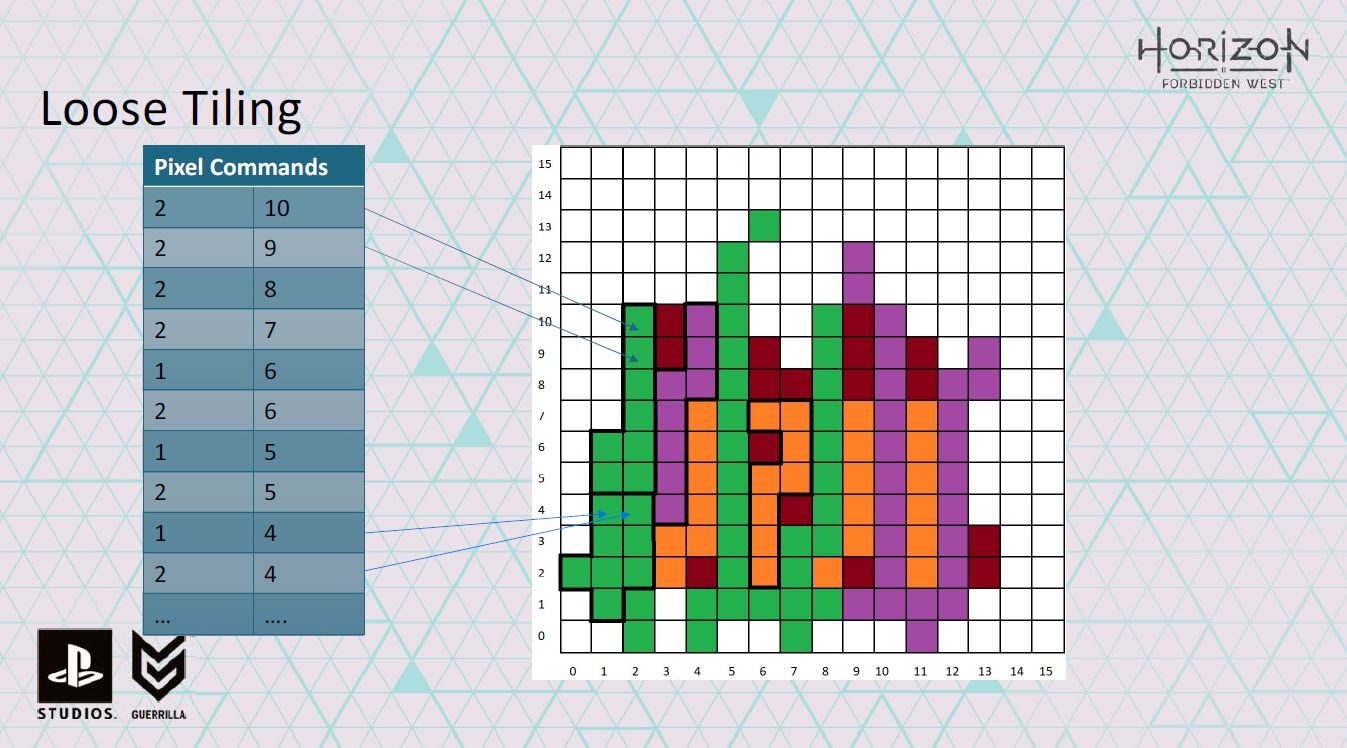
また、どのピクセルをシェーディングするかを示すピクセル・コマンドのリストも作成します。
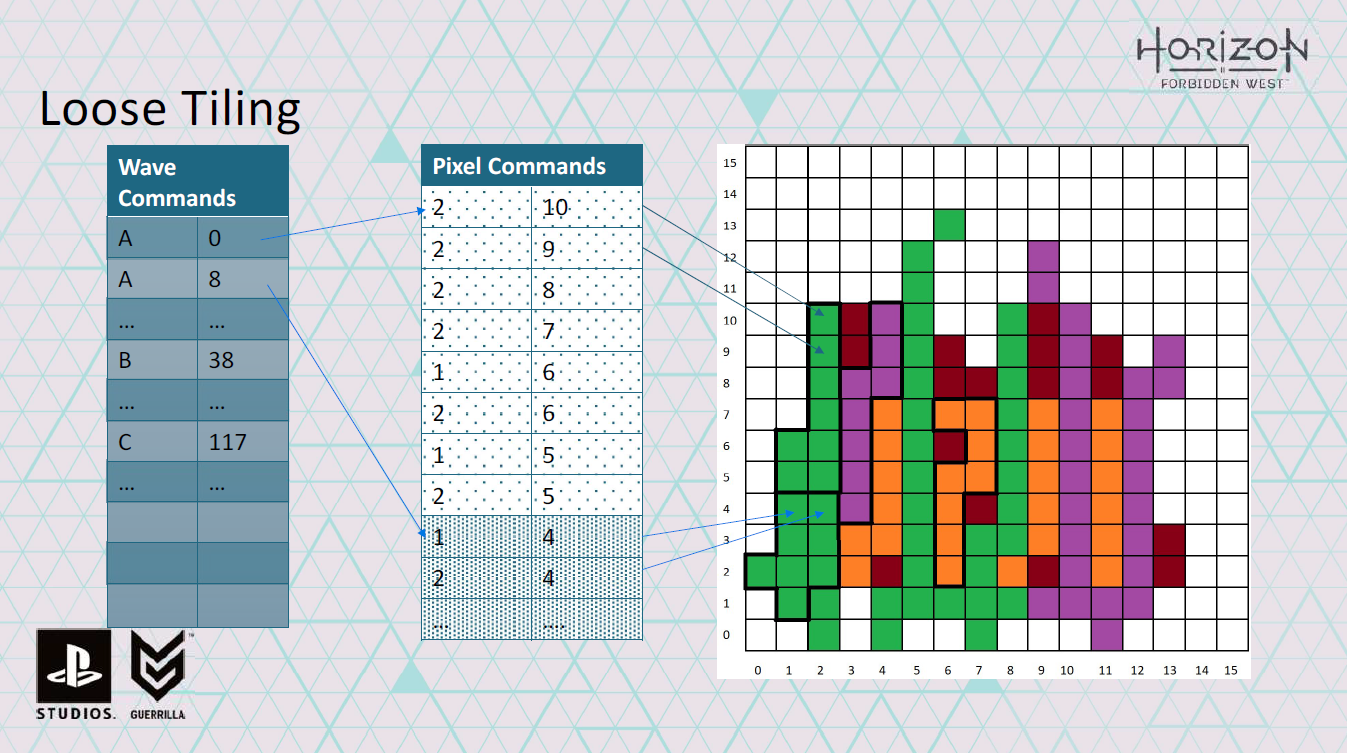
そして、wave commandのセットを生成し、waveが動作するバッチグループを定義し、pixel commandのセットも指すようにします。
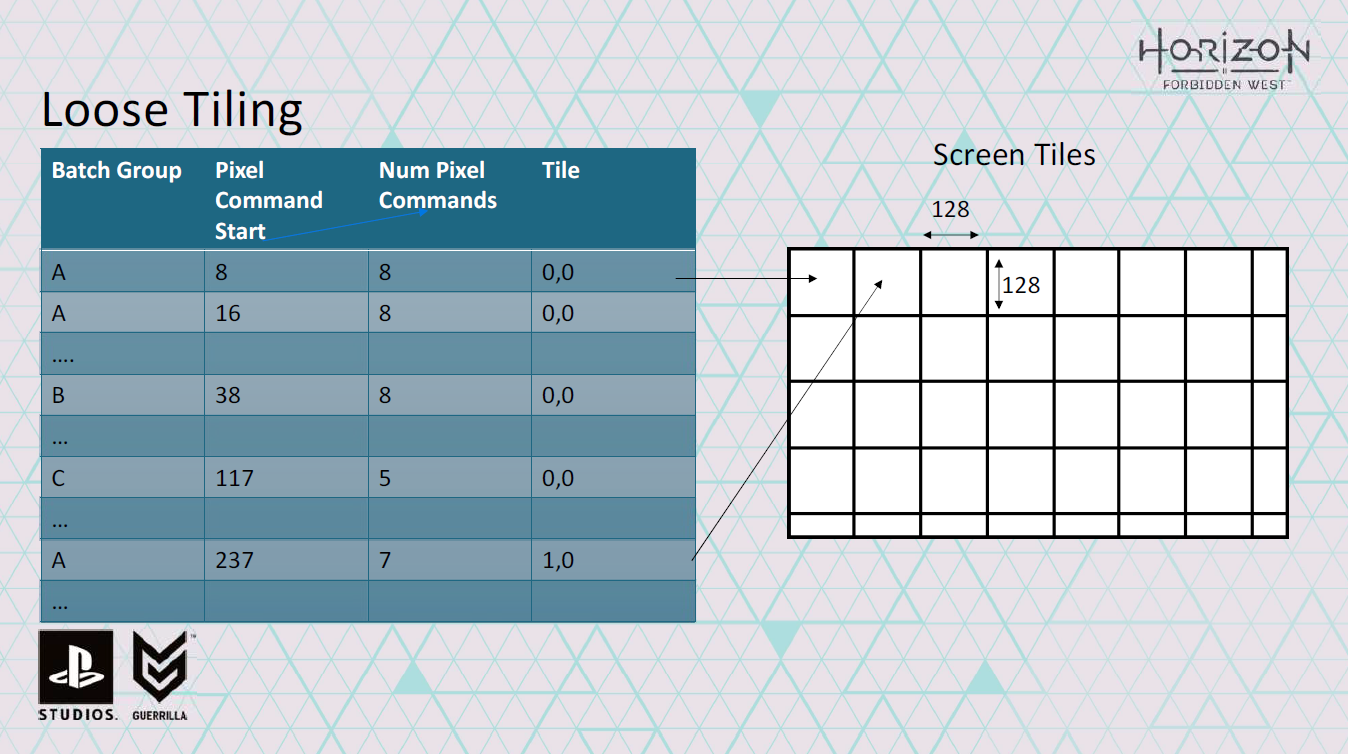
wave commandを詳しく見てみましょう。
wave commandは、どのタイルにあるか、waveが処理するピクセルコマンドの数も記録します。
そのため、このタイルの特定のシェーダーに対するすべてのwave commandとpixel commandを生成したら、次のタイルに対するコマンドの追加を開始できます。
このようにして、1つのシェーダーに対して、多数のバッチをシェーディングするwave commandとpixel commandのセットを構築できます。また、ダイバージェンスを回避し、L2キャッシュのパフォーマンスを向上させるために空間的な局所性を維持しようとします。
このスキームの優れた点は、128×128のタイルを使用しているため、ピクセルコマンドを保持するバッファーは16ビットのみで済むことです。
また、128×128のタイルサイズは慎重に選択されているため、必要に応じて、16ビットのうち12ビットを使用してピクセルクワッドをエンコードし、4ビットを使用してこれらのクワッド内に設定されているピクセルをエンコードできます。これは、後で可変レートシェーディングについて説明するときに重要になります。

これで、コンピュート上でピクセルを処理する方法はだいたいわかりました。では頂点はどうでしょう?
理論的には、元のIntelの論文のように、ピクセルをシェーディングするように変換することができます。
しかし、特にPS4ではまだ比較的大きな三角形を扱っているため、各ピクセルが3つの頂点をシェーディングしなければならず、大量の冗長な処理が発生する可能性があります。
Horizon Zero Dawnでは、オブジェクト空間の頂点位置のキャッシングシステムがあり、デプスイコールパスでの冗長な変換処理の多くを回避し、モーションベクトルのために最後のフレームからの頂点位置に簡単にアクセスできるようになっていました。また、モーションベクトルのために最後のフレームからの頂点位置に簡単にアクセスすることもできました。これをベースにすることもできましたが、キャッシュのサイズには限りがあり、オーバーフローする可能性がありました。

そこで、頂点キャッシュを利用しながら、別のコンピュートパイプ上のリングバッファに頂点を変換します。
このアプローチを機能させるためには、同じシェーダーを持つパスにバッチをソートし、パスの頂点を一度に変換する必要があります。
これを駆動し、シェーディングする頂点に関する情報を渡すために、頂点wave commandを生成する必要もあります。
これを実行している間、我々のピクセルのコンピュートシェーダは前のパスの頂点を消費することができます。
このように常にオーバーラップできるようにしたいので、1パスで処理する頂点の最大数をリングバッファのサイズの1/2に制限します。
このリングバッファはPS4では12MB、PS5では24MBになります。

では、システムの外観を簡単に説明します。
まず、バッチをマテリアルごとのパスに分類するために必要なCPU処理があります。
次に、薄い32ビットのビジビリティバッファーを埋めて、シェーディングする三角形に関する情報をエンコードします。
その後、ビジビリティバッファーを分析し、それに対していくつかの分類を行います。これにより、ピクセル側でシェーディングを実行するピクセルおよびpixel wave commandsと、ピクセル処理で使用される前にリングバッファーを使用してメモリをバウンスする別のコンピュートパイプで頂点の変換を実行するvertex wave commandsを生成します。
最後に、可変レートシェーディングマジックを少し追加して、より多くのものを絞り出そうとします。


その前に、Decimaエンジンからの入力を簡単に説明したいです。
Decimaでは、高度に最適化されたシーングラフを照会して、各フレームで描画する必要があるものを決定します。
シーングラフは、現在のフレームのオクルージョンカリングを行い、可視オブジェクトのインスタンスをバッチにまとめた可視リストを吐き出します。
シーングラフからのバッチは、通常、単一の描画呼び出しとしてレンダリングされるので、その中のすべてのインスタンスは、同じシェーダ、ジオメトリ、テクスチャを共有しますが、インスタンスごとのパラメータは異なる場合があります。
また、シーングラフのクエリ内部でバッチがマージされることもあります。
これは単純で明白なことのように思えるかもしれませんが、混乱を避けるためにやったことの詳細を説明する前に、ここで言っておく価値があると思います。

そこで、GPUでレンダリングを開始する前に、CPU上でシェーダーのハッシュ、バッチごとのデータ、および位置を量子化したモートンコードに基づいてバッチをソートし、パスに分割します。
しかし、このアプローチにはいくつかの問題がありました。
主なものは、我々がプロシージャルなフォリッジの配置システムを持っていて、ワールドにフォリッジのほとんどを配置していることです。
そのため、100個以上のインスタンスからなるバッチがしばしば生成されます。
これらのインスタンスがそれぞれ多数の頂点を使用している場合、リングバッファにすべての頂点を収めることができないどころか、その半分も収めることができないので、困ったことになります!

この問題に対処するため、まず、ジオメトリの個々のビットに16ビットのインデックスを使用し、最大64kプリミティブを使用することで、ジオメトリのサイズにある程度まともな制限を設けます。
これにより、ジオメトリの個々のビットがリングバッファの容量を必要としなくなります。次に、配置システムから受け取るバッチを、マイクロバッチと呼ぶ管理しやすい小片に分割する必要があります。
各マイクロバッチは最大64kトライアングルを持ち、1~64kインスタンスを含みます。
そして、バッチの代わりにマイクロバッチからパスを作成します。
そのため、バッチに含まれる頂点数が多すぎて収まらない場合は、複数のマイクロバッチに分割されます。
つまり、与えられたオリジナルのバッチは、複数のパスにわたって処理されることになります。
生成するマイクロバッチごとに、MicroBatchInfoTableテーブルと呼ぶものにエントリーを記入します。
このテーブルには、ジオメトリが使用する頂点の数、バッチのどのインスタンスから始まるか、どのパスに属するかなど、マイクロバッチに関する情報が含まれています。
これはGPUからアクセス可能なバッファに置かれ、シェーディング中に使用して、シェーディング中のマイクロバッチに関する情報を回復することができます。
<続ける前に、ボーナススライド108をご覧になってはいかがでしょうか...。>
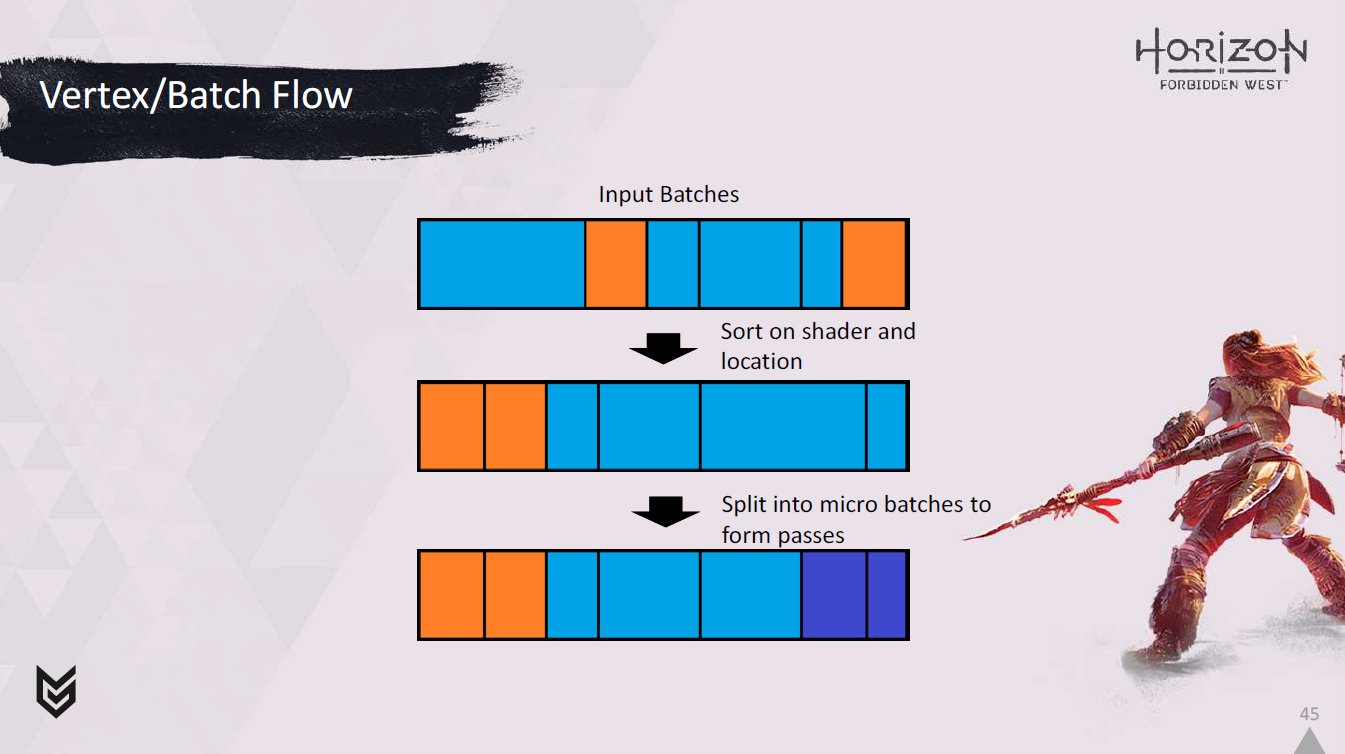
ここでバッチの大まかな流れをご覧ください。
シェーダー上でソートされ、
そしてマイクロバッチに分割され、パスが形成されます。
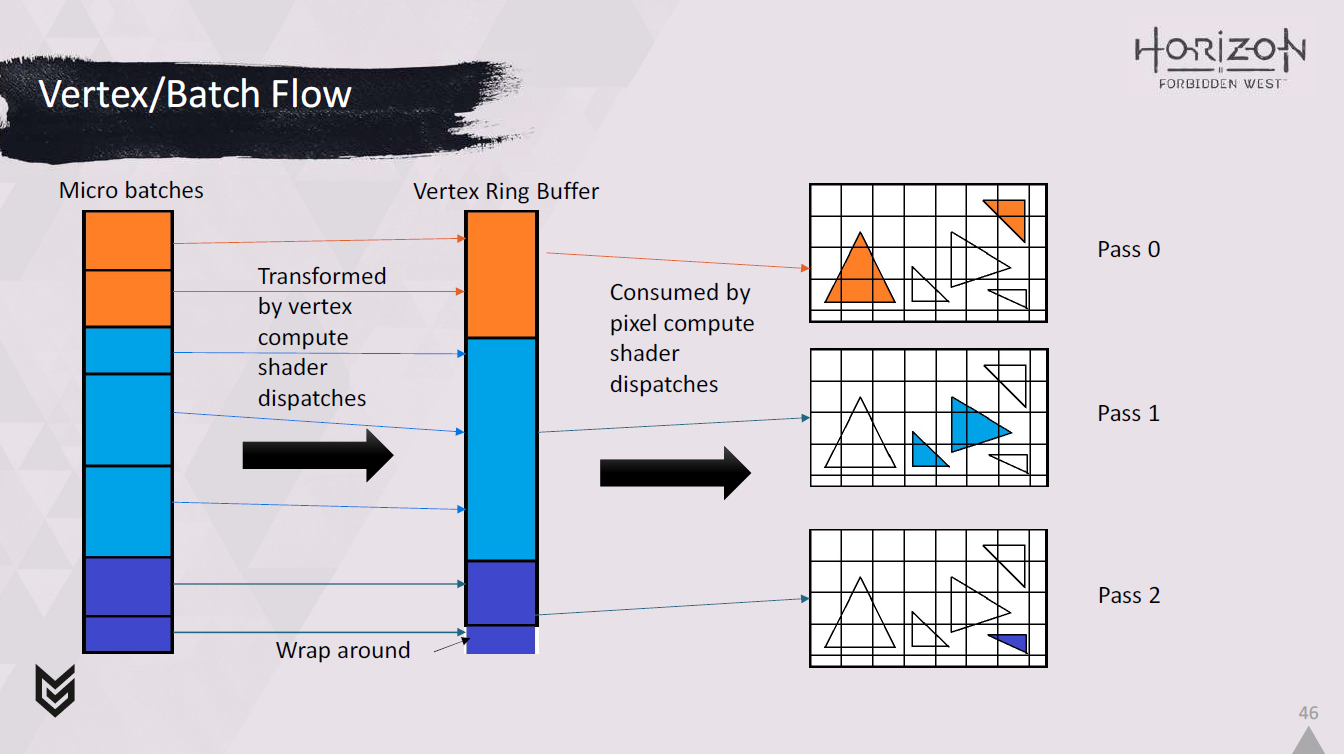
マイクロバッチはその後、頂点コンピュートシェーダーによってリングバッファに変換されます。
そして、これらの変換された頂点は、各パスに関連するピクセルコンピュートシェーダーによって消費されます。

さて、これでCPUのセットアップ作業を大まかに理解していただけたと思います。それでは、ビジビリティバッファをどのように構築するかについて説明しましょう。

Decimaにはすでにデプスプリパスがあったので、深度バッファだけでなくビジビリティバッファも書き込む深度とビジビリティの追加パスでこれを補強しました。
各ピクセルについて、このパスは三角形、インスタンス、バッチに関する情報を32ビットのプリミティブIDとして書き出す必要があります。
理論的には、PS4 ProやPS5に搭載されている専用ハードウェアを使用することもできますが、残念ながらPS4 Baseはジオメトリシェーダを使用せずにprimitive IDを取得する適切な方法がないため、これでは冷遇されてしまいます。

当初の計画では、三角形のインデックスの上位16ビットでprimitiveIDをエンコードし、ピクセルシェーダーで誘発頂点を読み取り、頂点シェーダーからprimitive IDを渡すだけでしたが、開発の初期段階で、頂点を回転させるハードウェアに問題が発生しました。
現在は回避策があると思いますが、この問題を完全に回避するソリューションを使用することになりました。
XORを使用すると、3つの頂点のそれぞれにエンコードする3つの値からプリミティブIDを一意に再構成できます。
このスキームでは、頂点の順序は気にせず、ペイロードの組み合わせのみを考慮します。
* これはまた、加算インデックスを導入する必要がありますが、挑発的な頂点スキームで必要とされた以上のものではありません。
そのため、メッシュを前処理するときに、エンコードするprimitive IDと、他のインデックスに既にエンコードされているデータに基づいて、誘発頂点インデックスに格納するデータを決定します。
すべてのインデックスのデータがすでに決定されている場合は、新しいインデックスを追加する必要があります。
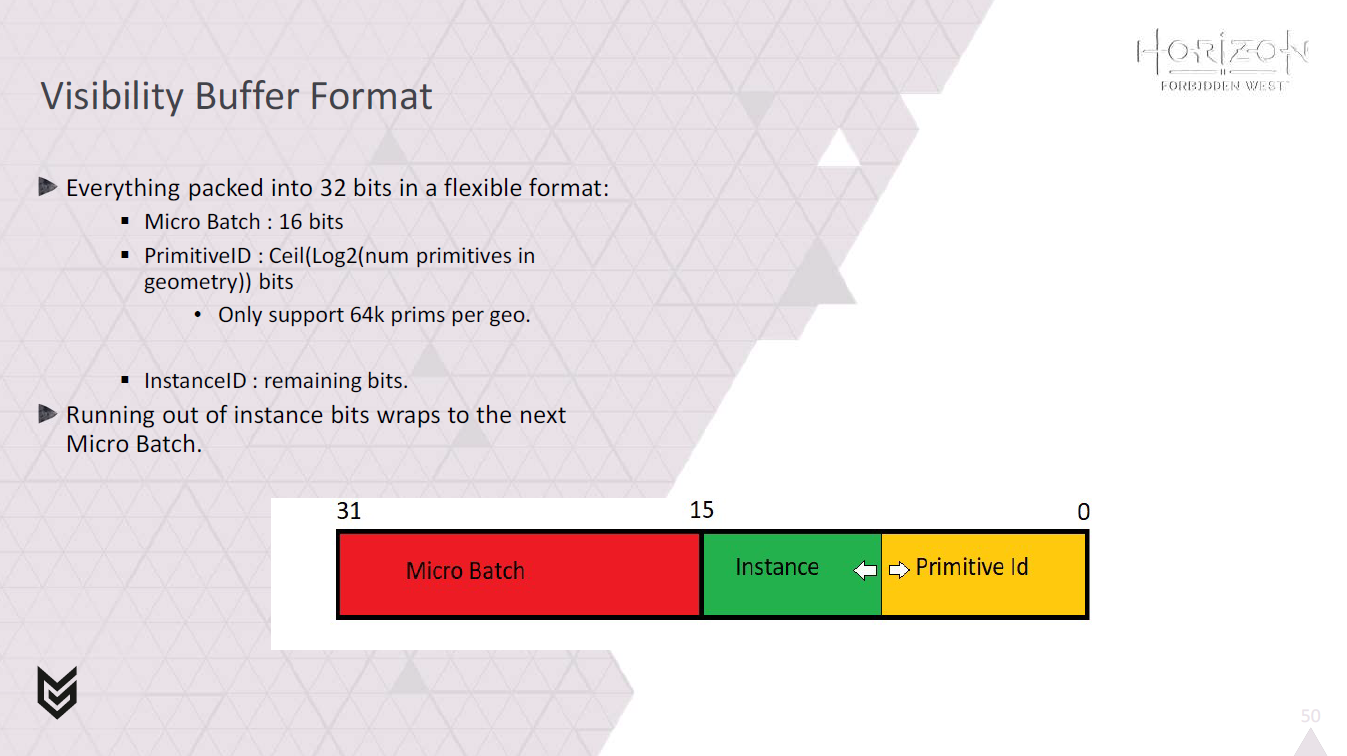
ピクセルシェーダでは、再構成したPrimitive IDをMicro Batch IDおよびInstance IDと組み合わせて、ビジビリティバッファを生成できます。
上位16ビットがmicro batch IDをエンコードします。
primitive IDのエンコードには、レンダリングするジオメトリのプリミティブ数に応じて可変ビット数を使用します。
残りのビットはinstance IDに使用されます。

OK、これでVisibility Bufferが完成しました。
次に、どの頂点とピクセルに陰影をつける必要があるのか、分類する必要があります。

分類を3つのフェーズに分けました。
レイダウンファイナライゼーション、中間分類、分類の出力です。
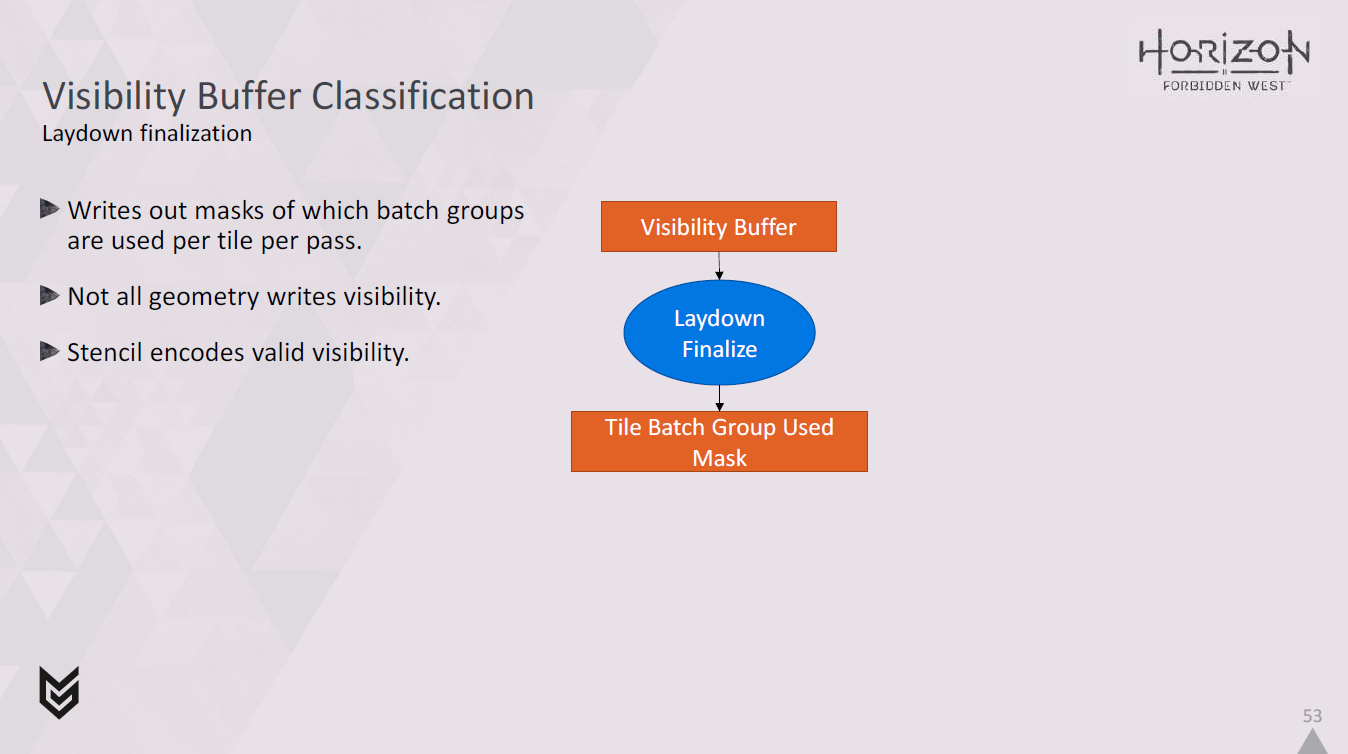
まずは、レイダウンファイナライゼーションと呼ばれるものです。
これはビジビリティバッファを読み込み、パスごとに各タイルでどのバッチグループが使用されているかのマスクを書き出します。
ここで注意しなければならないのは、すべてがビジビリティバッファに書き込まれるわけではないということです。
その後に実行されるジオメトリパスがあり、通常のディファードジオメトリでGbufferを埋めます。
これらすべてのシェーダに Visibility Buffer を書き込むために別のエクスポートを追加する必要はありません。
そこで、ステンシルバッファのビットを使用して、Visibility Buffer の内容が有効かどうかを示します。
Visibility Buffer を敷設するときにこのステンシルビットを書き込むと、オーバードローの量によって、取るに足らないコストが発生します。
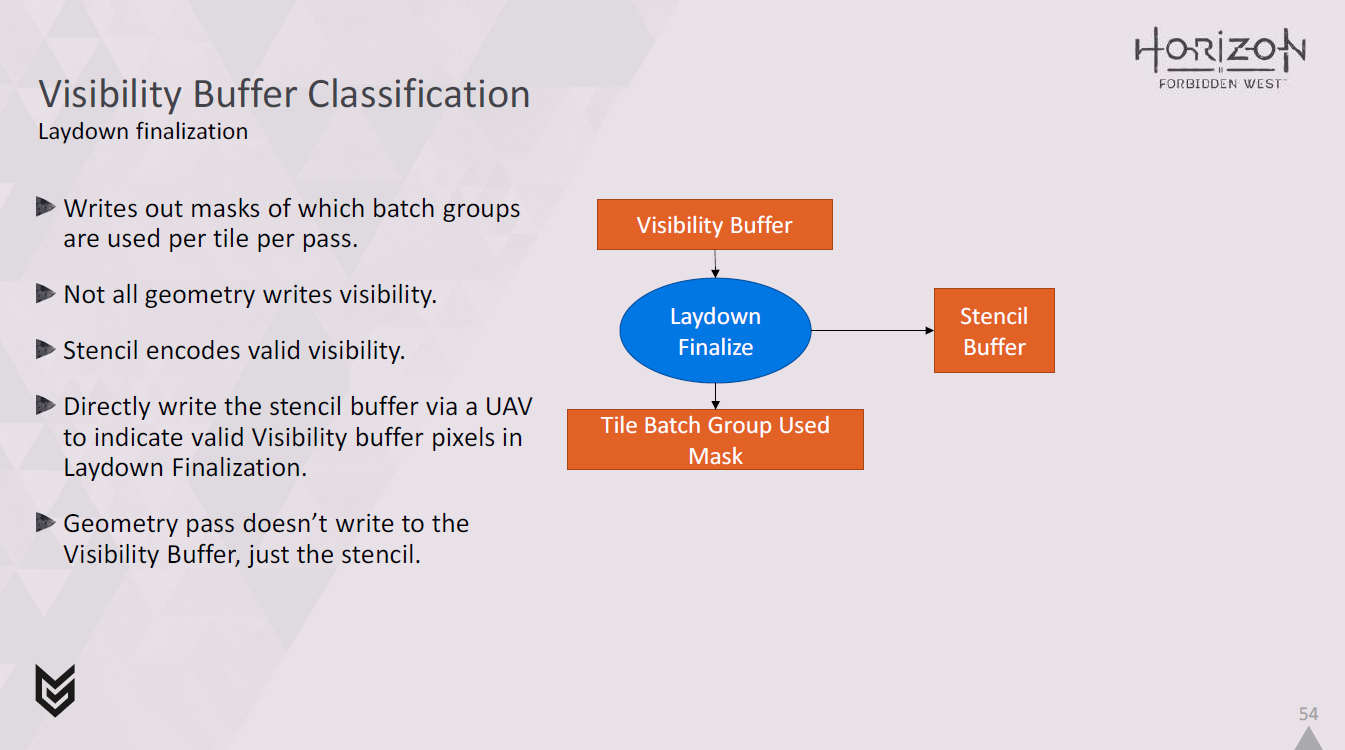
そこで、代わりに、レイダウンファイナライズシェーダを実行するときに、UAV を使ってこれを書き込みます。
ジオメトリパスのバッチは、このステンシルビットを上書きします。
ジオメトリパスが完了すると、ステンシルビットがセットされたピクセルのみが有効なビジビリティバッファ情報を含みます。
そこで代わりに、レイダウンファイナライズシェーダーを実行するときに、UAVを介してこれを書き込みます。
その後、ジオメトリパスのバッチがこのステンシルビットを上書きします。
ジオメトリパスが完了すると、ステンシルビットが設定されたピクセルのみが有効なビジビリティバッファ情報を含みます。
<なお、1パスあたり32バッチグループという制限を理解するために、このスライドの前にあるボーナススライド108を読む価値があるかもしれません。>
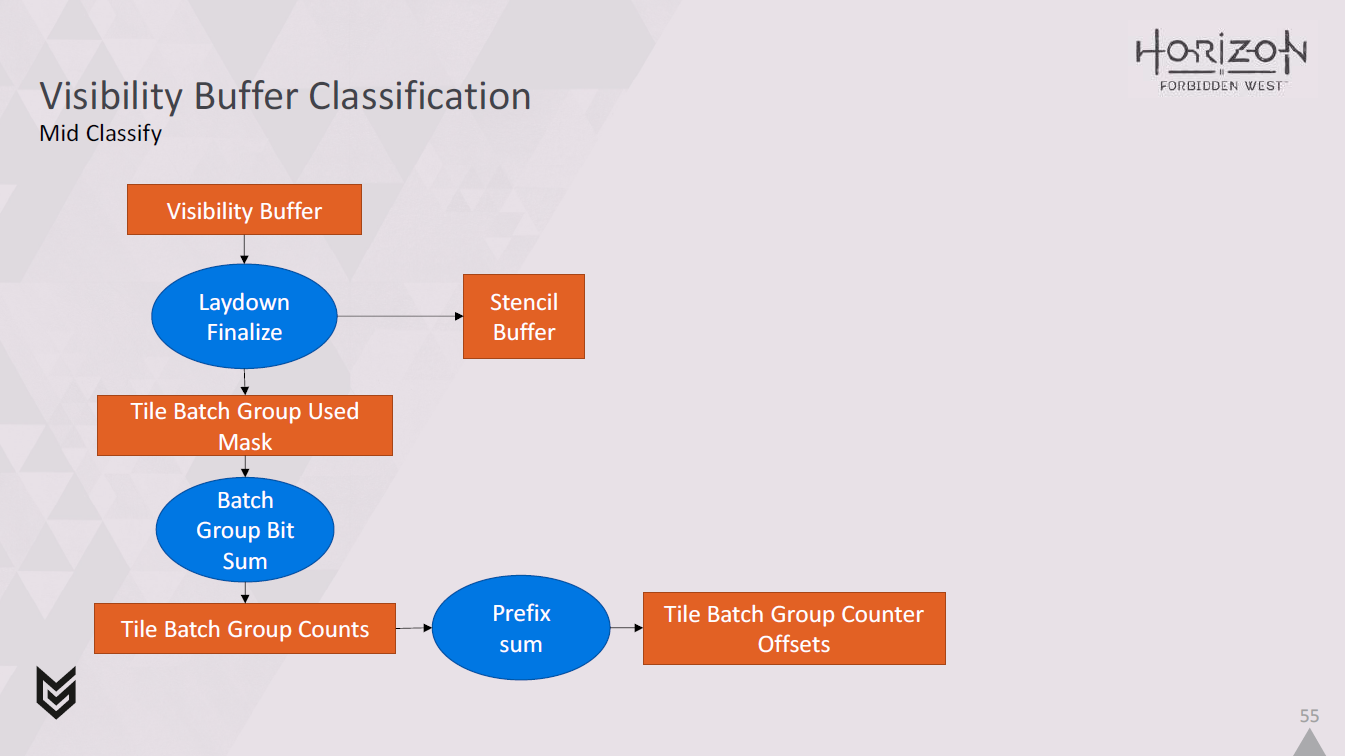
次にミッドクラシファイのフェーズです。
これはジオメトリーパスと並行して行うことができる。
バッチグループはすでにマスクとして使用されており、レイダウンファイナライゼーションでステンシルバッファを埋めています。
次に、使用済みマスクを取得し、popcountを使用してビットを合計し、各パスで各タイルにいくつのバッチグループが使用されたかのカウントを取得します。
そして、カウンターのオフセットを取得するために、プリフィックスサムを行います。
くれはすべて、パスごとに各タイルに32個のバッチグループカウンターのフルセットを持つ必要がないようにするためです。4Kで256パス(これが現在サポートしている最大値です)をそうするためには、カウンターのために16MBのスペースが必要になるからです。
しかし、ほとんどのバッチグループはすべてのタイルで使用されるわけではないので、実際に使用されるカウンターのセットを計算し、それらへのオフセットをグローバルカウンターバッファに格納することで、かなり少ない容量で済ませることができます。
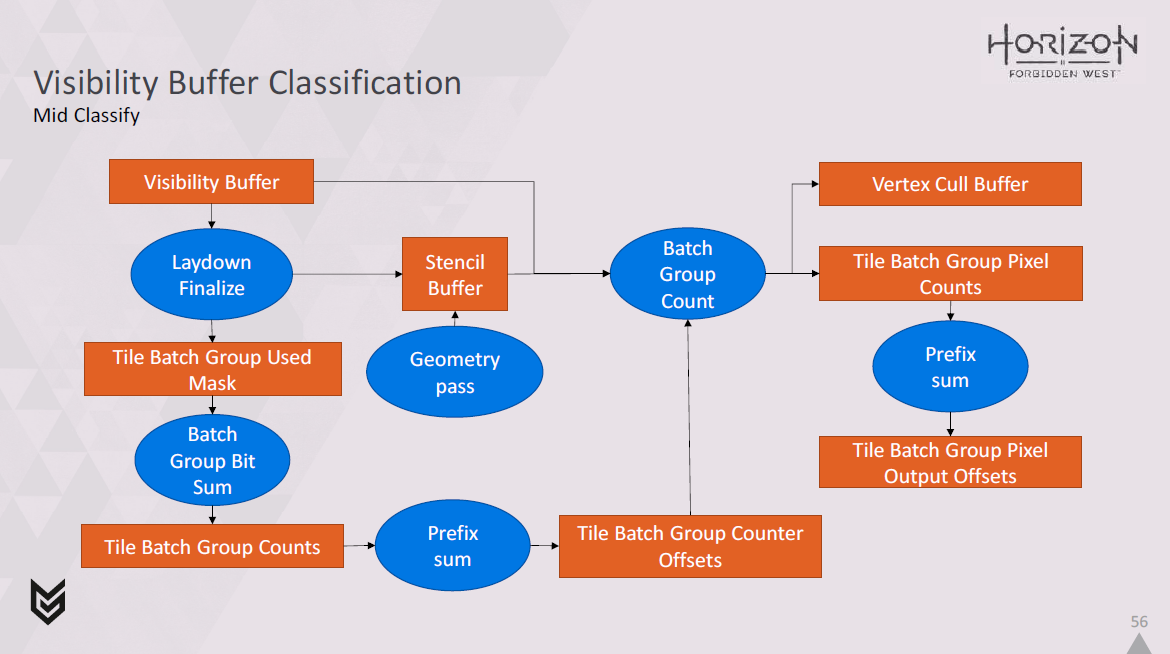
この作業が行われている間も、ジオメトリパスは実行され、ステンシルバッファを更新しています。
次に、ステンシルバッファ、ビジビリティバッファ、タイルバッチグループカウンタオフセットを読み取り、各パスの各タイルの各バッチグループ内のピクセル数をカウントアップします。
同時に、primitive IDを使用して、どの頂点が使用されているかをデコードし,vertex cull bufferに記録します。
現在のところ、64頂点チャンクの粒度でのみこの処理を行っていますが、これは物事をシンプルに保つためと、シーンによっては1千万単位の頂点が存在する可能性があるため、スペースを節約するためです。
次に、タイルバッチグループのピクセルカウントを取得し、それに対してプリフィックスサムを実行し、パスごとにタイルごとにバッチグループごとにピクセルコマンドの記録を開始するオフセットのセットを吐き出します。
ジオメトリパスがまだ実行中である間は、この処理をすべて実行できるため、各バッチグループに必要なピクセルコマンドの数を見積もりすぎる可能性があることを覚えておくことが重要です。

さて、この中間分類ステップでは、各パスでどのような頂点処理が必要かを教えてくれるvertex wave commandを生成する処理も必要です。
この計算の主な入力は、以前に作成したvertex cull bufferです。
このバッファには、頂点チャンクごとにバイトセットがあり、可視か非可視かを示します。
このプレゼンテーションでは、時間の都合上、vertex commandがどのように作成されるかをカバーするつもりはありませんが、もし興味があれば、このプレゼンテーションの最後にあるボーナススライドに、それに関するスライドがあります。

つまり、中間分類は完了し、ジオメトリパスが終了した後、ビジビリティバッファ上で実行される分類出力フェーズがあります。
ジオメトリパスで更新されるステンシルバッファは、Visibility Bufferのどのエントリが実際に有効かを示すために使用されます。
これにより、様々なコマンドを書き出すことができます。
これらは、タイル内のピクセルXとYを含むpixel commandsです。
また、タイル座標、バッチグループID、ピクセルコマンドのオフセットと数をエンコードするpixel wave comandも書き込みます。
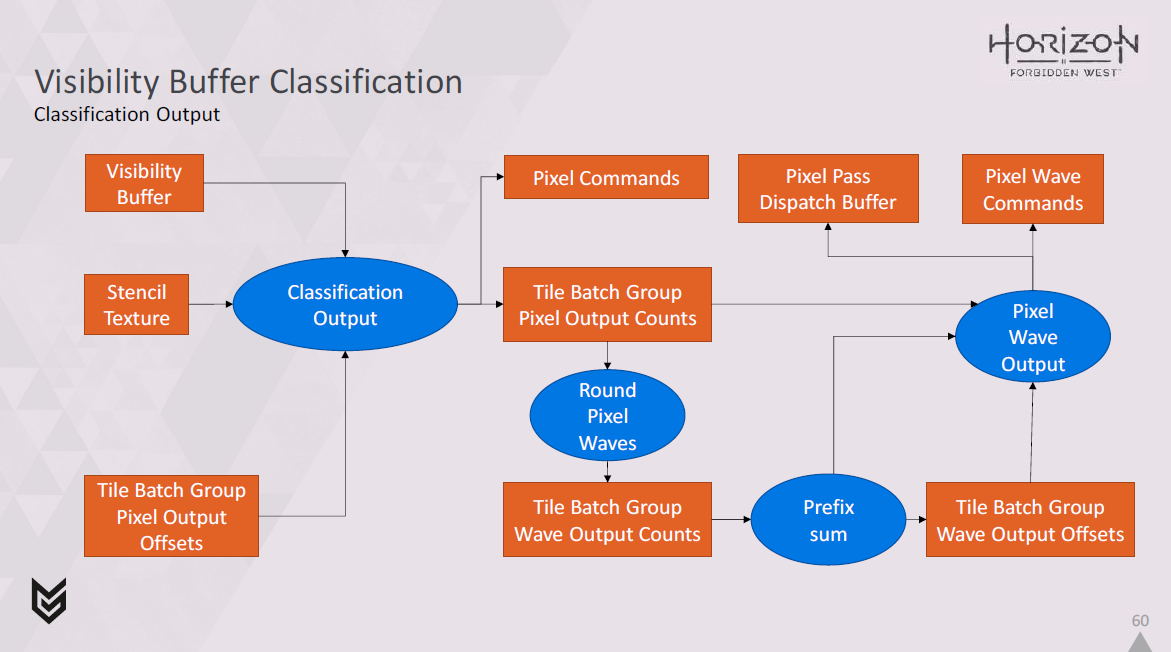
では、このステップをもう少し詳しく見てみましょう。
ここでは、ビジビリティバッファ、ステンシルバッファ、および以前に計算したタイルバッチグループピクセル出力オフセットを受け取り、分類出力シェーダで各ピクセルを処理するのがわかります。
これにより、pixel commandsと、各バッチグループで何ピクセルが使用されているかの最終的なカウントが、各パスの各タイルについて出力されます。
次に、これらのカウントをウェーブアライメントに丸め、パスごとにタイルごとにバッチグループごとに必要なウェーブ数を計算するために使用します。
その後、プリフィックスサムを実行し、pixel wave commandsを出力する必要がある場所を特定することができます。
最後に、すべてのパスとタイルに対してディスパッチを行い、wave commandsとピクセルパスに使用するディスパッチバッファの両方を出力することができます。
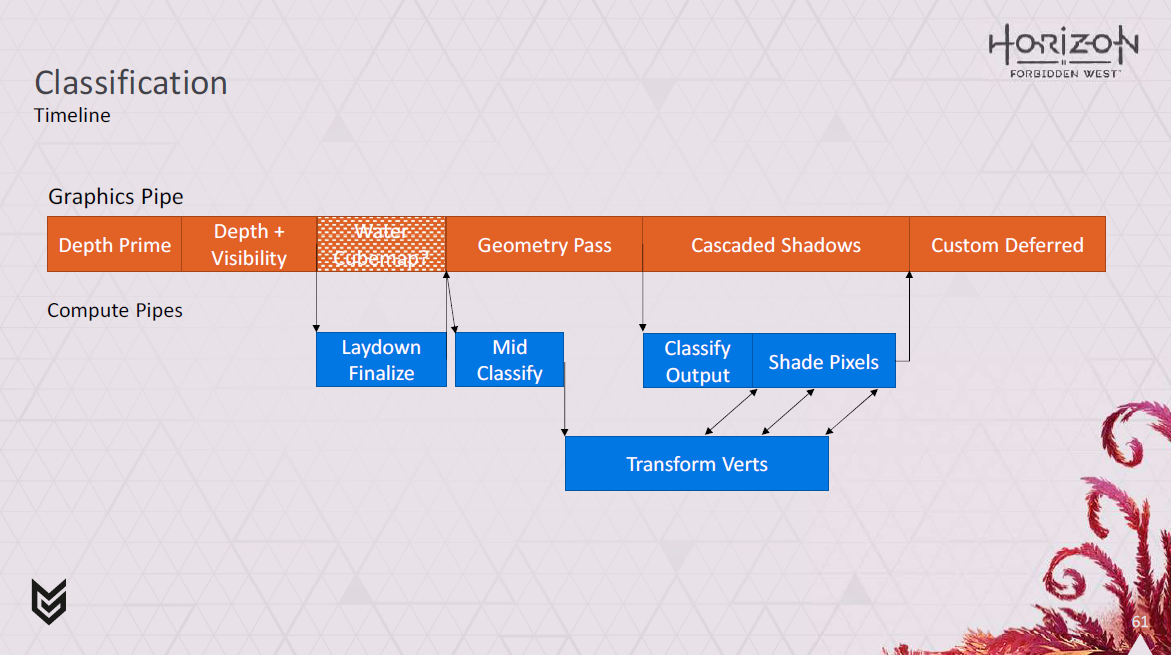
これがGPUのタイムラインにどのように合致するかを見てみましょう。
ご覧の通り、DepthとVisibilityパスの直後にレイアウ ンの最終化を開始しています。
運がよければ、これはウォーターキューブマップの面のレンダリングと並行して実行できます。
その後、ジオメトリパスが開始され、中間分類ステップを開始できます。
これらは、最終的な分類出力ステップの準備を整えるだけでなく、頂点のカリングやvertex wave commandsの出力も行います。
ジオメトリーパスがグラフィックスパイプ上で実行されている間に中間分類が行われるため、得られる結果の一部は保守的なものとなります。
そのため、オクルードされている頂点を変換してしまう可能性があります。
しかし、主要なオクルーダーのほとんどは深度プライムパスの中にあるため、一般的には、ジオメトリパスの後で正確な結果を待つよりも、ジオメトリパスと並行してこの処理を実行する方がよいことがわかります。
また、ジオメトリパスが終了する前に、ディファードテクスチャリングパスのために頂点の変換を開始することもできます。
ジオメトリパスが終了したら、最終的な分類を行い、pixel commandとwave commandを出力し、シャドウをレンダリングしながらピクセルのシェーディングを開始します。
これは、すでに書き込まれた Gbuffer 値を変更できるデカールなどに使用します。
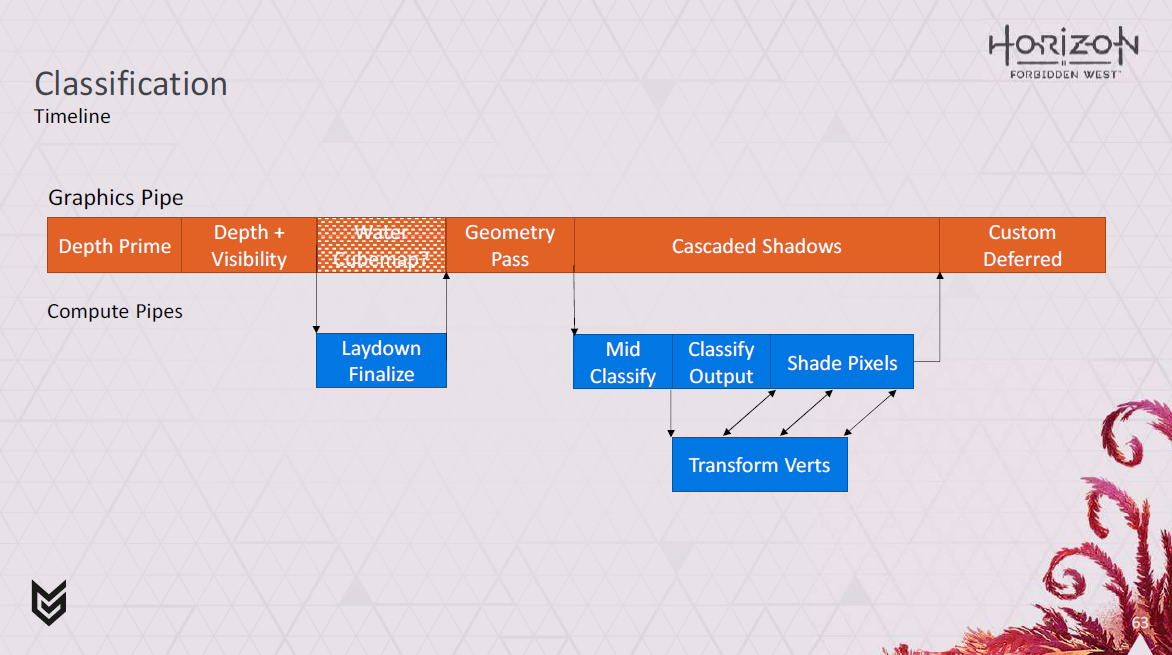
中間分類をジオメトリーパスの最後に移動させる代替モードでシステムを稼働させることも可能です。
これは、ジオメトリパスと並行してより少ない作業を、より高い頂点カリングレートと交換するもので、ジオメトリ密度がより高いPS5で実験しています。

なので、リングバッファの頂点がどのようにエンコードされるかについて少し説明しましょう。
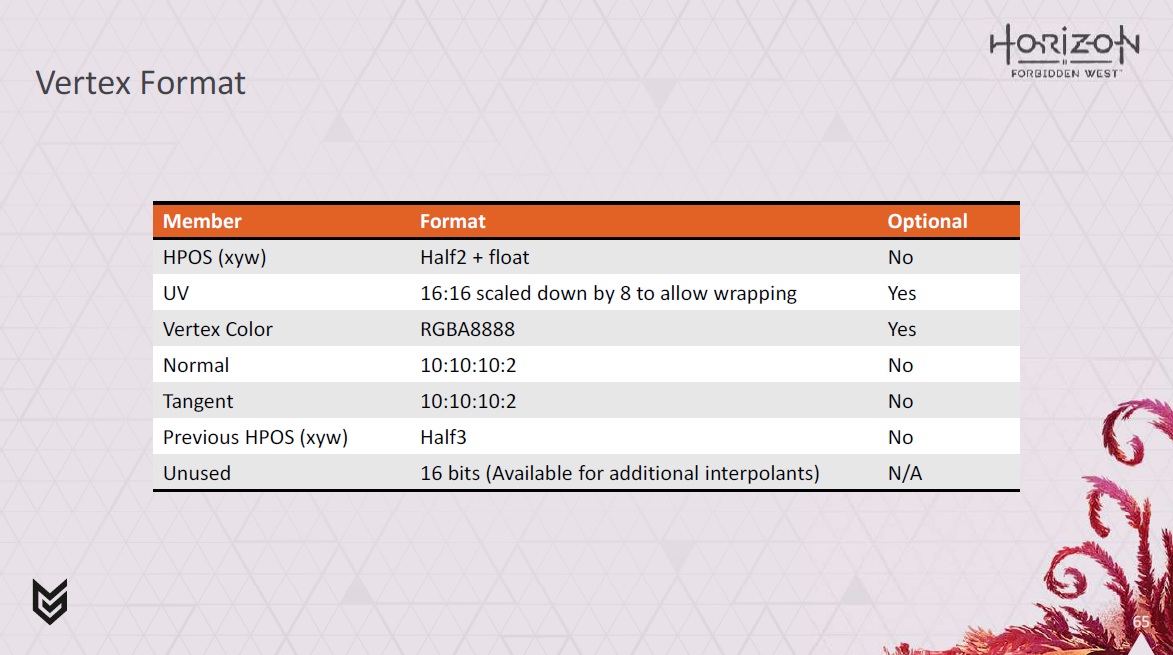
これが我々が使っているフォーマットです。全部で32バイトです。
HPOSでは、xとyを半分の浮動小数点数としてエンコードしていますが、精度の観点からwを浮動小数点数として保持する必要があることがわかりました。
UVは16:16の固定小数点として格納しますが、UVのラップをサポートするために8倍縮小します。
また、頂点カラー、法線、接線、以前のHPOSのためのスペースがあり、モーションベクトルを構築できます。

そのため、これは完全に固定された形式ではありません。一部のシェーダーでは、特に最適化のために一部のピクセル処理を頂点シェーダーに移動する場合に、追加の補間が必要になります。
UVと頂点カラーはアニメーション化しませんが、通常は頂点プログラムで読み取って頂点形式に配置し、ピクセルあたりのバッファー読み取り回数を減らす方が効率的です。
ただし、余分な補間を考慮するために、UVと頂点カラーを修正形式から除外し、それらのデータバッファーを直接読み取ることができます。次に、それらの空間を追加の内挿のために再利用します。
この方式を用いて、最大5×16ビットの追加補間スロットをサポートできます。
現時点では、スロットはhalf float、2チャネルのsquare rooted 8 bit unorm for color値のいずれかで埋めることができます。これは、貧乏人のsRGBのようなものと考えることができます。
さて、システムのコアに関する情報は以上です。
うまくいけば、これがどのように機能するのか、いくつかのヒントを得たことでしょう。
かなりのスピードでいくつかの新しい概念を導入したことを自覚しています。
だから、それが多かったと思っているなら、私を信じてください。

… わかっていますよ!私だって、半分も頭に入っていないですよ…。

だから、アーロイの森で少し落ち着いて、それが何のためにあるのかを理解しましょう。
… Ok、みんな一息つけましたか?

そこで、プロジェクトの終盤に、システムからもう少しパフォーマンスを引き出そうと追加した、可変レートのシェーディングサポートについて少しお話ししようと思います。

ここまで説明したことはかなり効率的なのですが、もっと速くできないかと考えました。
我々がレンダリングするフォリッジの多くは、緑色のさまざまなシェーダーで終わるので、常にフルレートでのシェーディングの恩恵を受けられるわけではありません。
我々はROPを経由するのではなく、ピクセルエクスポートを効果的に自分たちで管理しているため、ネイティブにサポートしていないハードウェアでも可変レートシェーディングをサポートするように我々のスキームを変更することができました。
理論的には、我々はスクリーン空間のシェーディングレートテクスチャを介してこれを駆動することをサポートすることができますが、今のところ、我々は単に頂点シェーダからこれを駆動することを選択しました。
我々はすべての DirectX Tier 1 VRS シェーディングレートを サポートしています。
これは PS4 Base でのみ有効であり、その利得はシーンに大きく依存します。

ここでは素敵な森の風景を見ることができます。

そして、これは静止しているときのVRSの標準設定で、距離に応じて1×1、2×1~2×2をブレンドします。
このシーンでは、ディファードテクスチャリングがオーバーラップしていない場合、これは約0.2msを取り戻します。

ただし、シェーディングレートを駆動するために、頂点シェーダ内の頂点のスクリーン空間速度を使用します。
このシーンでは、ほぼ0.5msでシェーディングできるので、時間をかける価値があります。

我々の分類出力ステージは、このシェーディング率情報を読み取り、QuadSwizzleを使用して、一緒にシェーディングできるピクセルを素早く決定することができます。
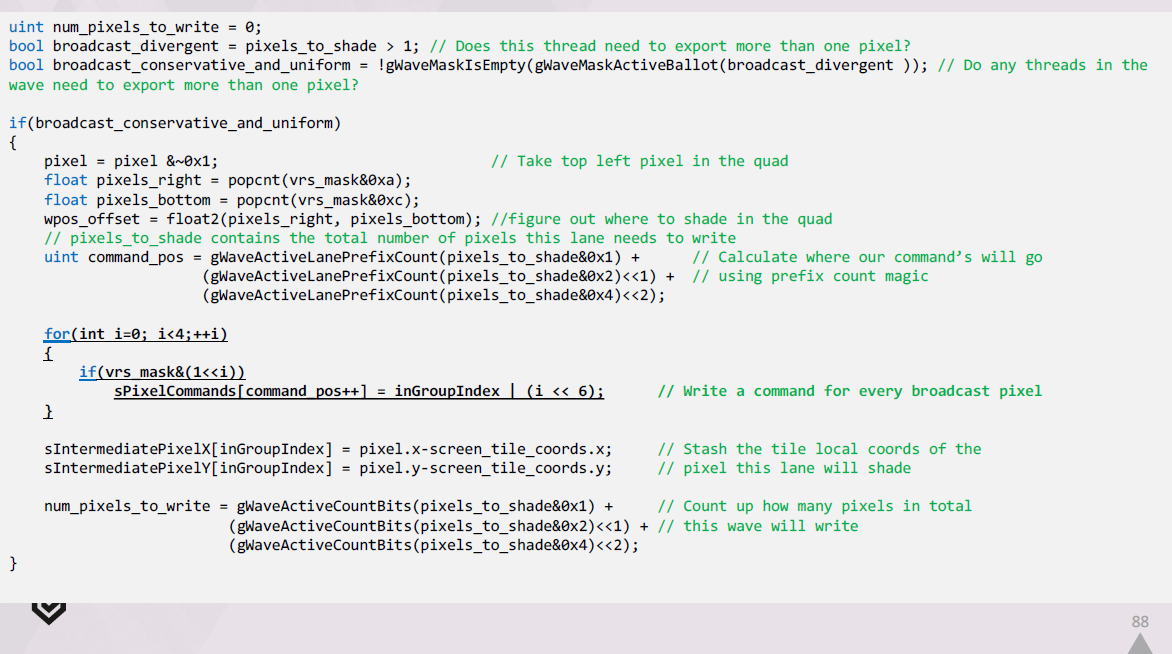
先に言及したように、我々はpixel commandsも変更し、128×128タイルでシェーディングする特定のクワッドを12ビットで識別できるようにします。
コマンドの上位4ビットは、クワッド内のどのピクセルにブロードキャストする必要があるかを特定するために使われます。

マテリアルの出力を行う生成シェーダでは、waveの可変レートサンプルの結果をブロードキャストする必要があります。
各スレッドがブロードキャストすべきサンプルをループするだけで、素朴にこれを行うことは可能ですが、これはあまりメモリに優しくなく、パフォーマンスもあまり良くありません。
その代わりに必要なのは、各waveの中での作業拡張です。
すべてのサンプルを取得し、LDSで拡張されたピクセルコマンドのリストを作成します。
これはシェーダの開始時に行われ、ウェーブ内のピクセルコマン ドのいずれかがブロードキャストする必要がある場合に行われます。
シェーダの最後に、G-Buffer内の各 UAV に対して、ブロードキャストを行うためにこの拡張されたワークリストを使用します。
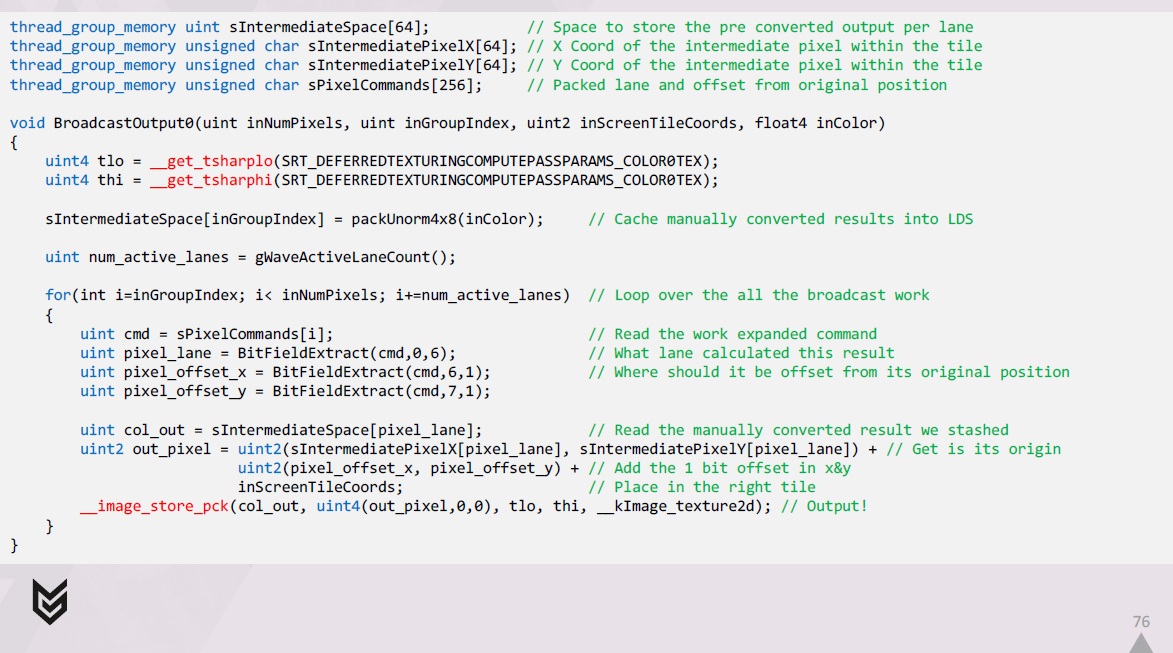
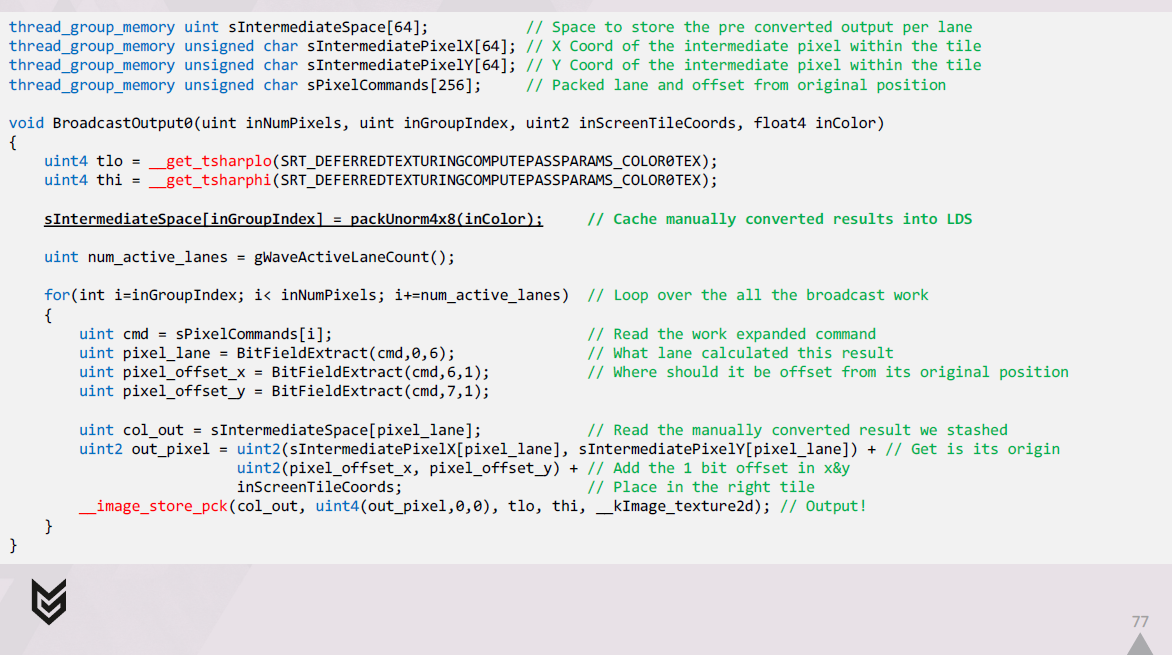
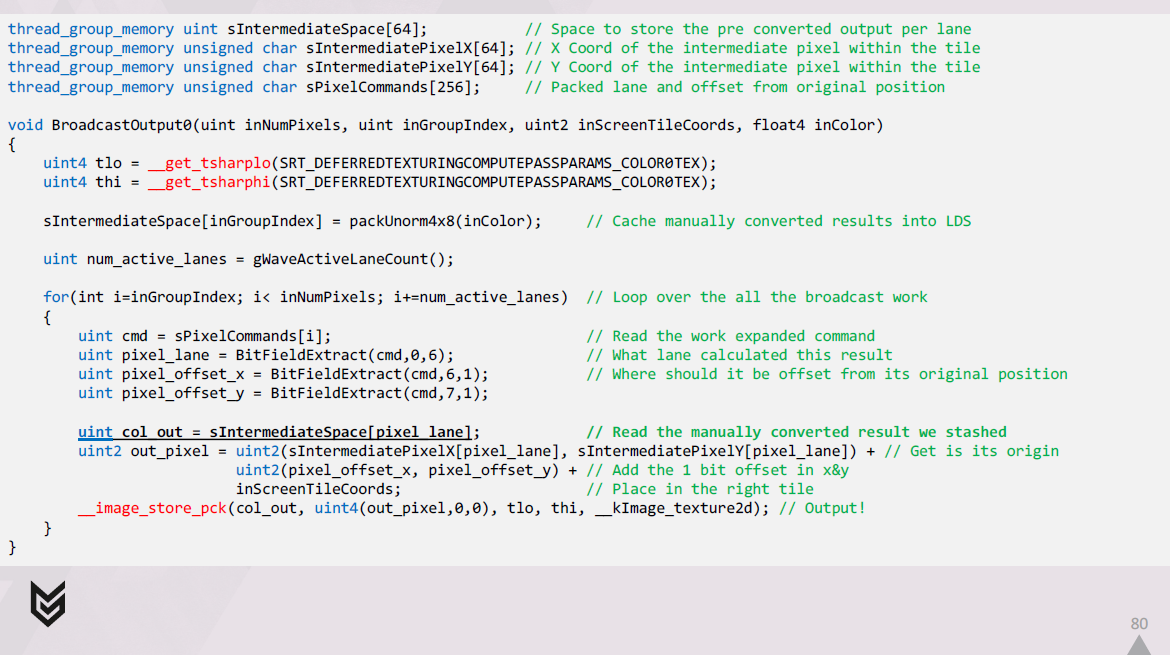
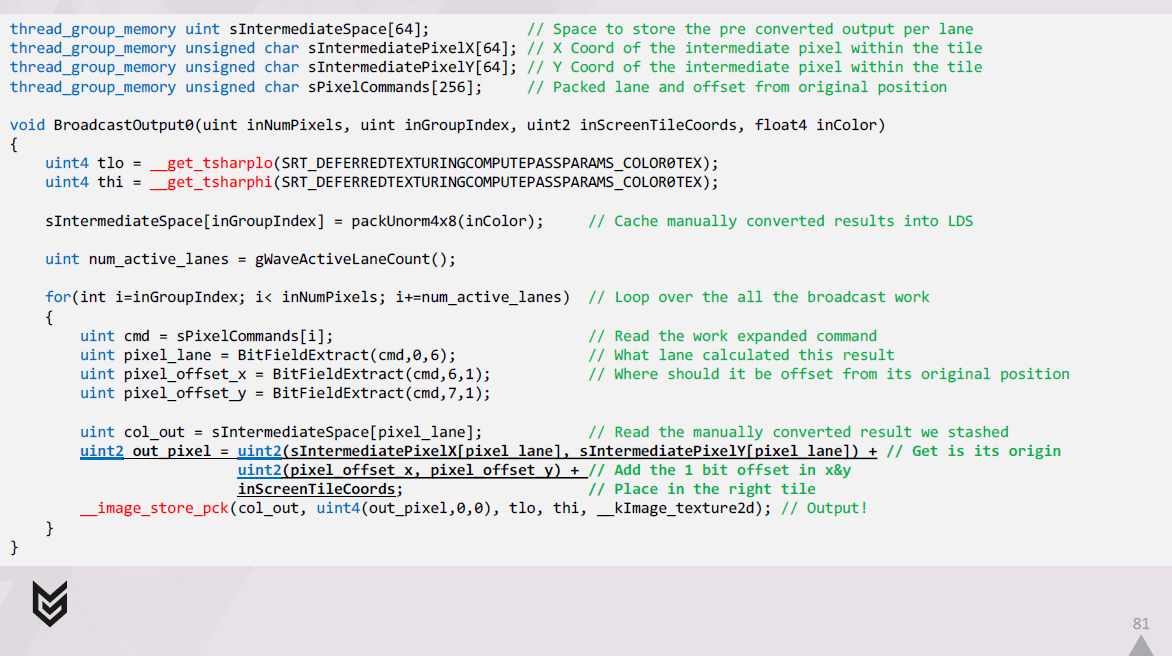
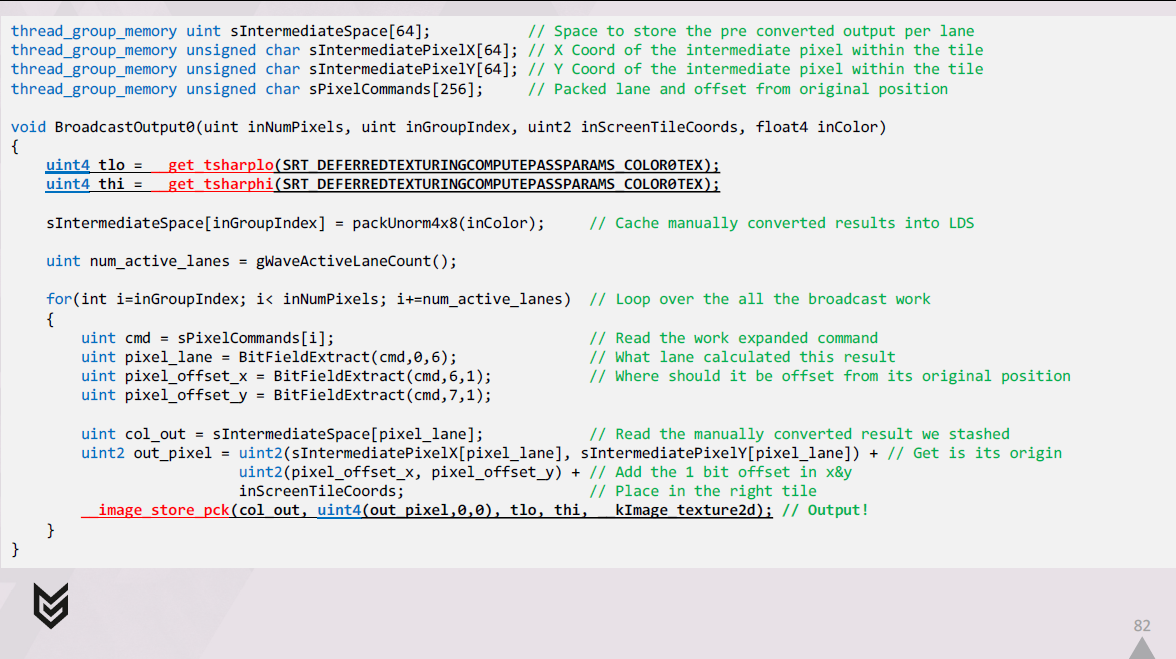
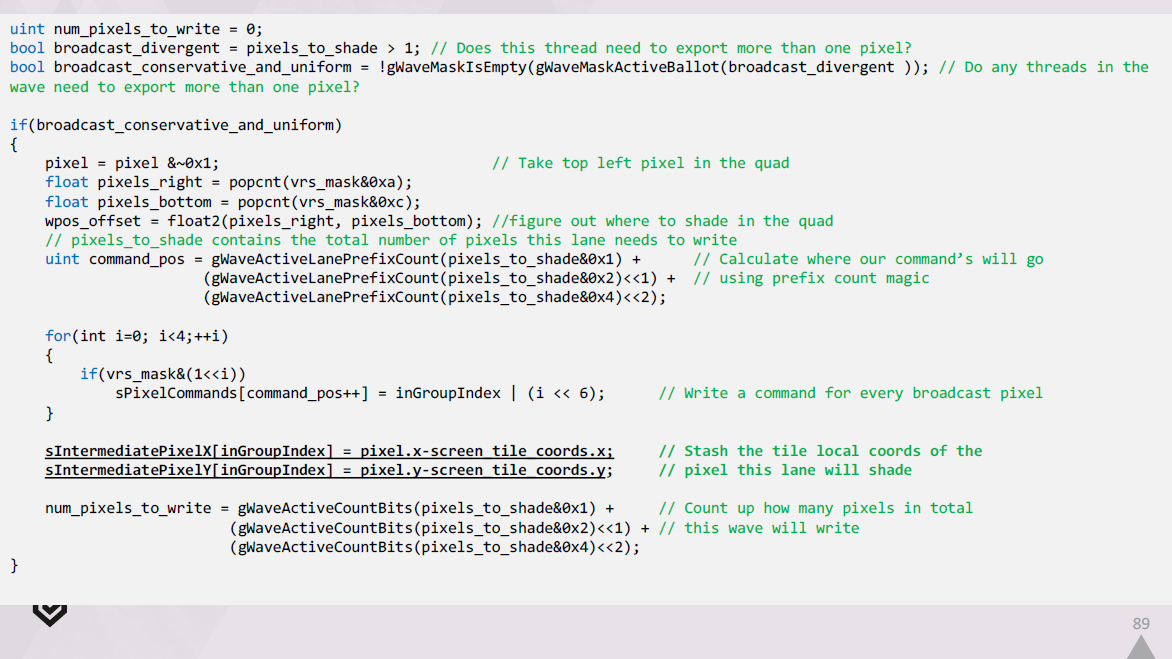
出力を1つのUAVにブロードキャストするコードは、次のようになります。
まず、シェーディングされた結果をメモリ内の最終的なraw形式に手動で変換し、結果をLDSにキャッシュします。
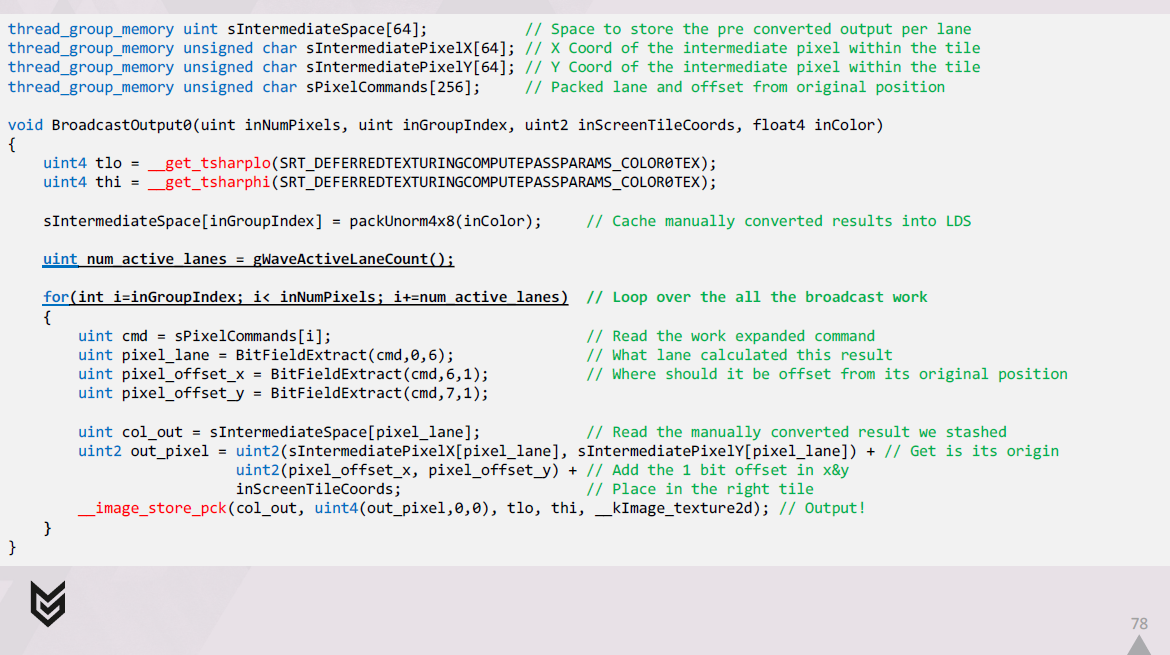
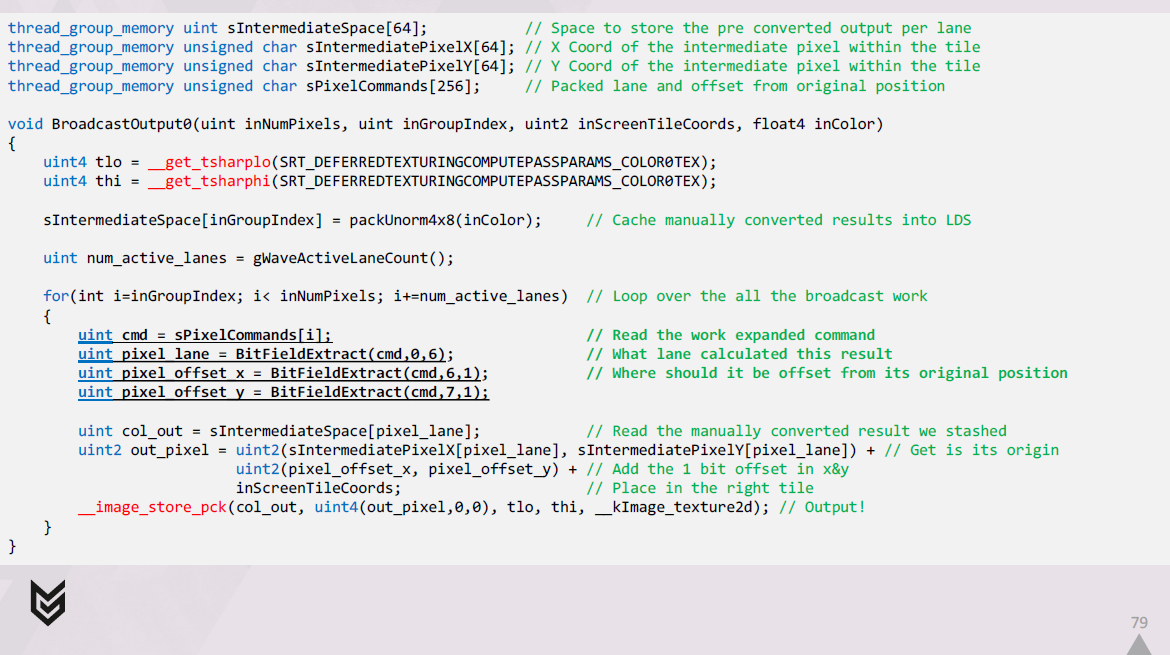
次に、展開されたコマンドのセットをループ処理し、それらをデコードし、それぞれに関連するLDSに格納した結果を取得します。
最後に、各レーンは出力先を正確に把握し、パックされたimage store intrinsicを介して出力します。
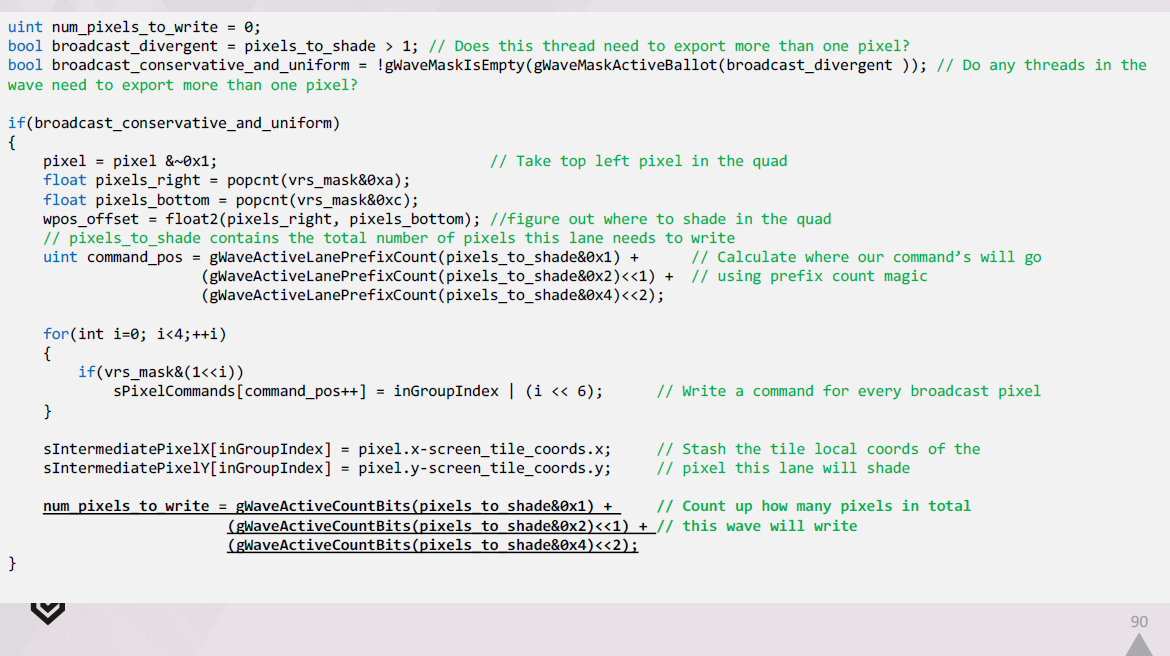
以下は、生成したシェーダーの先頭付近に挿入する必要があるコードの抜粋です。
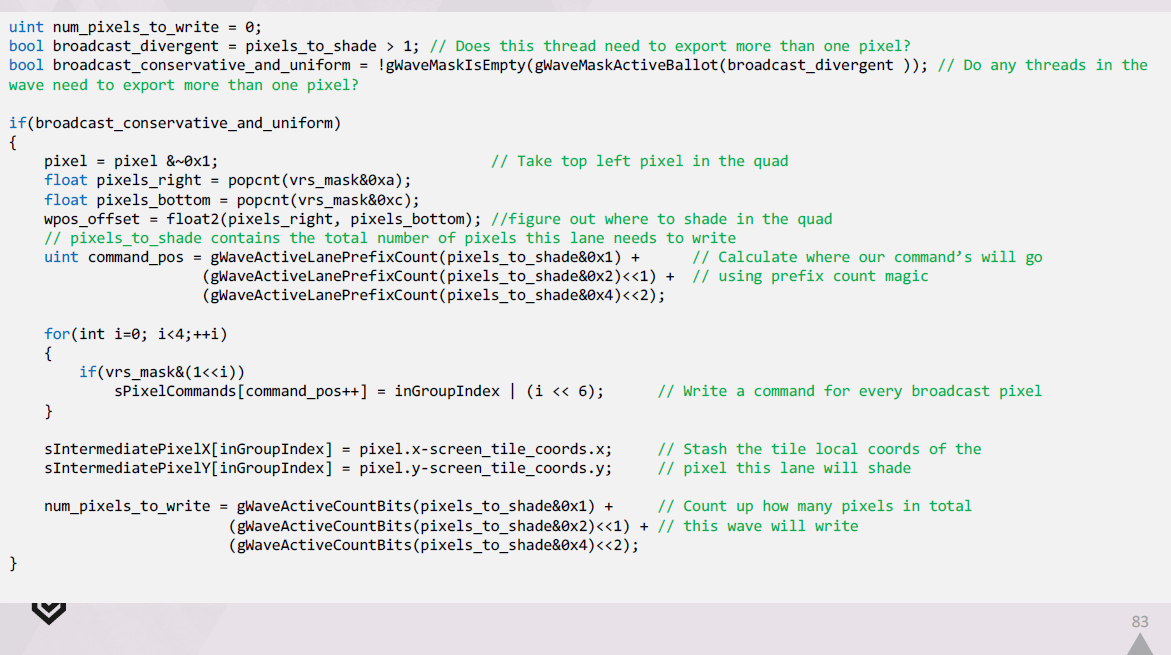
この拡張されたpixel commandsのリストを LDS で作成するには、次のようにします。
wave内のどのlaneでもブロードキャストが必要な場合は、これらの拡張コマンドを生成する必要があります。
それぞれのlaneについて、クワッド内の左上のピクセルと、シェーディングサンプルを計算すべき場所を特定します。
その後、このlaneのコマンドがLDSのどこで始まるべきかを把握し、それらを出力し、タイル内のクワッドの相対位置を記録します。
最後に、このwaveが合計でいくつのピクセルを出力する必要があるかを計算します。
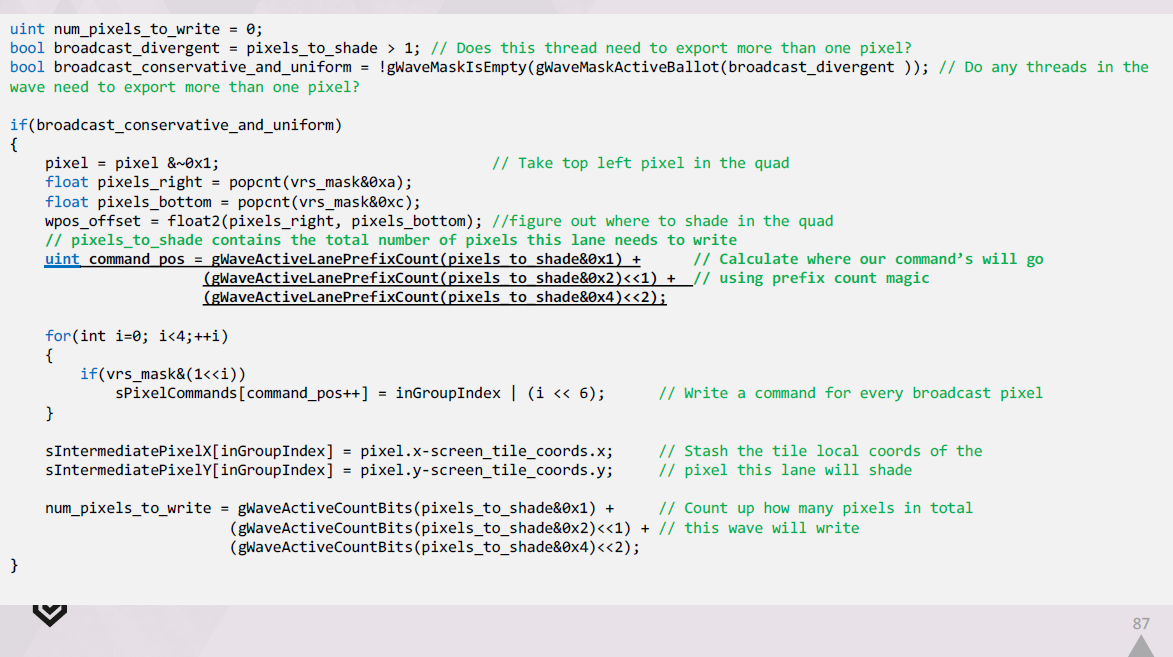
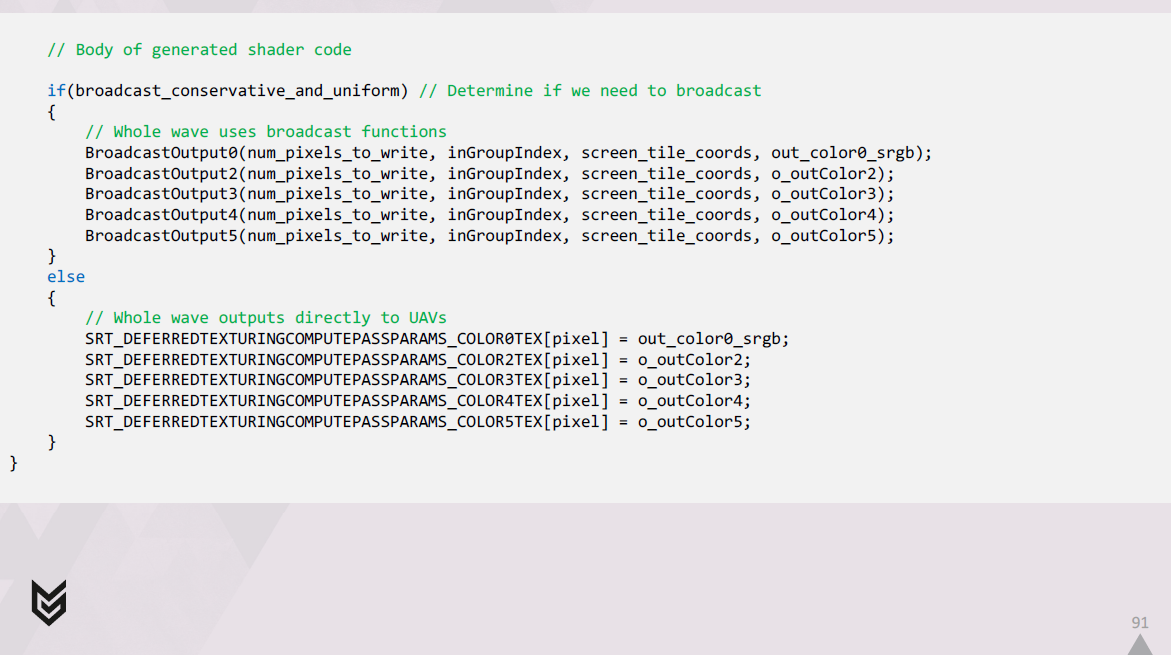
そしてシェーダーの最後に、通常出力用の高速パスとブロードキャスト出力パスを選択します。

VRSについて話す時間はこれで全部です。では、システム全体のパフォーマンスを少し見てみましょう。
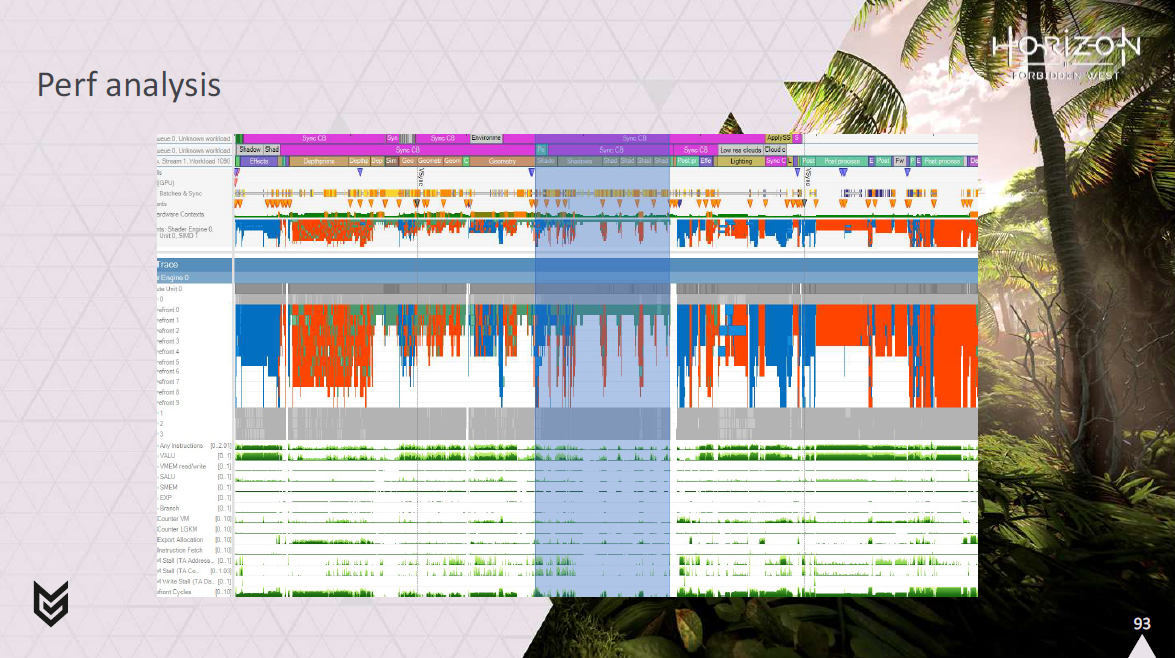
プレゼンテーションの冒頭から、大きなシャドーキャップのあるフレームを見てみましょう。
ご覧のように、シャドウと重なってかなり強固なコンピュートワークのブロックがあるように見えます。
これは実際には、頂点をリングバッファに変換し、それを消費して画面上のピクセルをシェーディングするための10回以上のパスです。
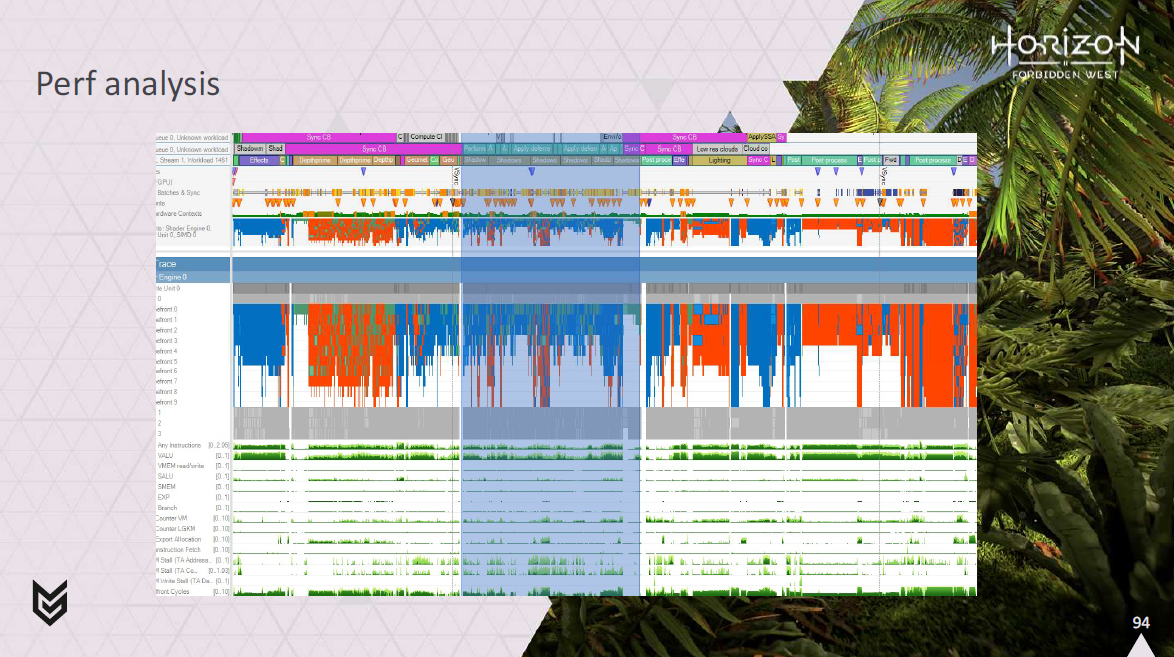

シャドウと重ならないようにして、ピクセルシェーディングをグラフィックスパイプで実行し、頂点シェーディングを計算パイプで実行すれば、すべてがうまくインターリーブされているのがわかるでしょう。
この図では、緑のwavefrontがピクセル処理で、灰色のwavefrontが頂点処理です。

バッチに基づくカラーリングに切り替えると、同じパイプ上のすべての異なるバッチがきれいにインターリーブしているのがわかります。

では、いくつかのシーンでどのようなパフォーマンスが発揮されるのか、数字でご覧いただきましょう。
まずは森のシーン。
PS5では4Kで約1.4msとそれなりに向上していることがわかりますが、真の勝者はPS4だ。
ベースとなるPS4では、シャドウとのオーバーラップにより、ほぼ2.5msを取り戻すことができました。
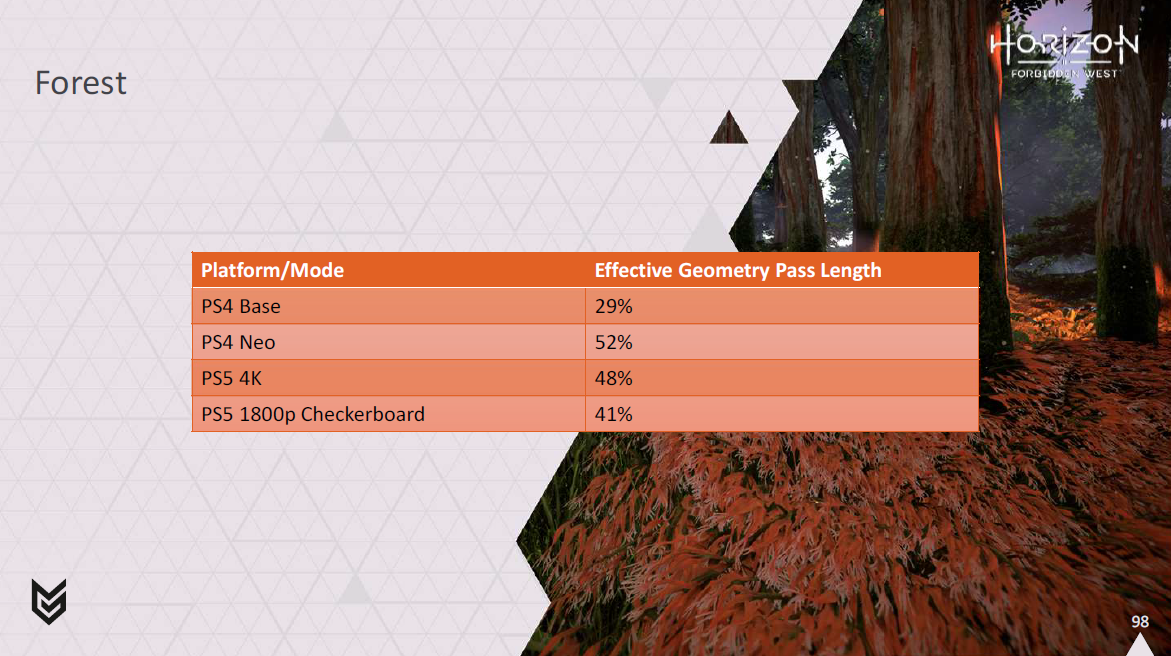
また、フォリッジのシェーディングのためにジオメトリパスで行っていた処理を分離し、その処理がディファードテクスチャリングによって解決され、シャドウとオーバーラップするようになったことで、フレーム内で実質的にどれだけの時間がかかるようになったかを見てみると、かなり健全な利益を得ていることがわかります。
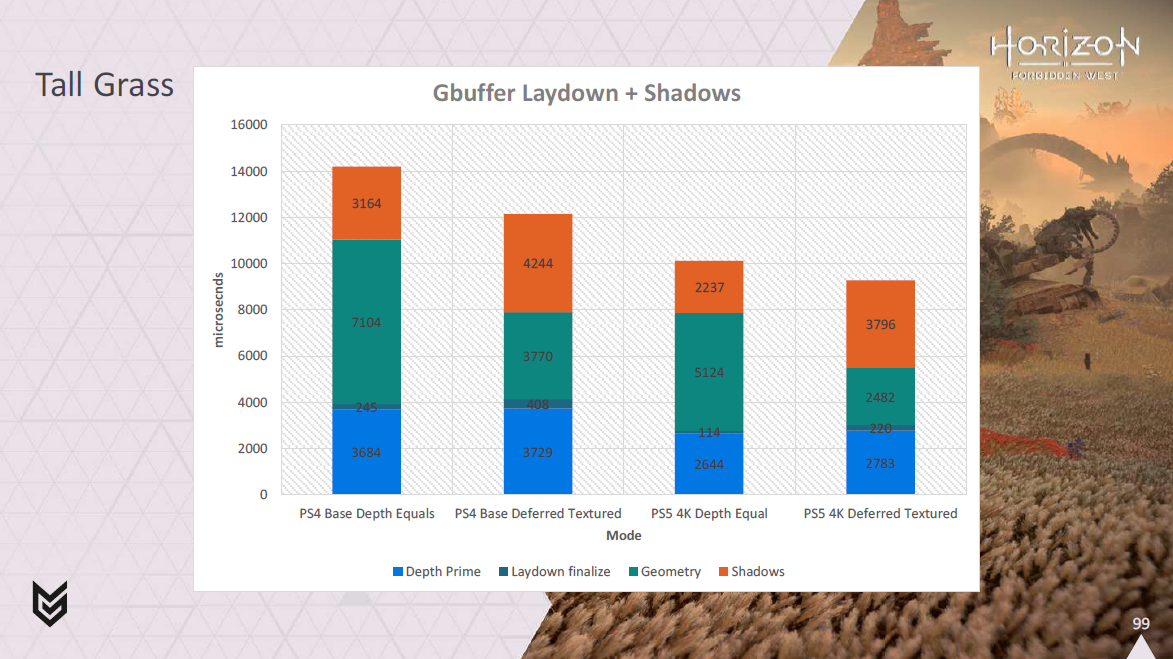
この草原のシーンでは、森ほどではないにせよ、良いゲインが得られているのがわかるでしょう。
ここでもPS4が大勝していますが、PS5も恩恵を受けています。
このシーンは頂点処理が多く、カリングの効果が低いため、やや難易度が高いです。
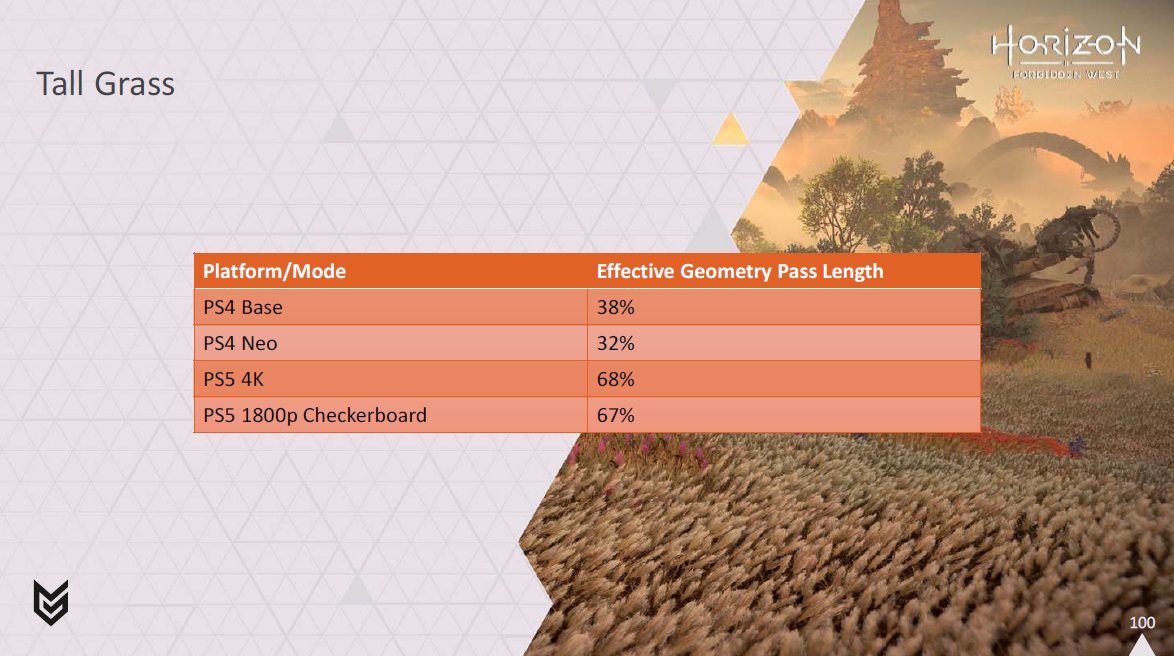
また、以前はジオメトリパスで行っていたディファードテクスチャリングの有効処理時間を見ると、我々はまだ良い利益を上げていることがわかります。
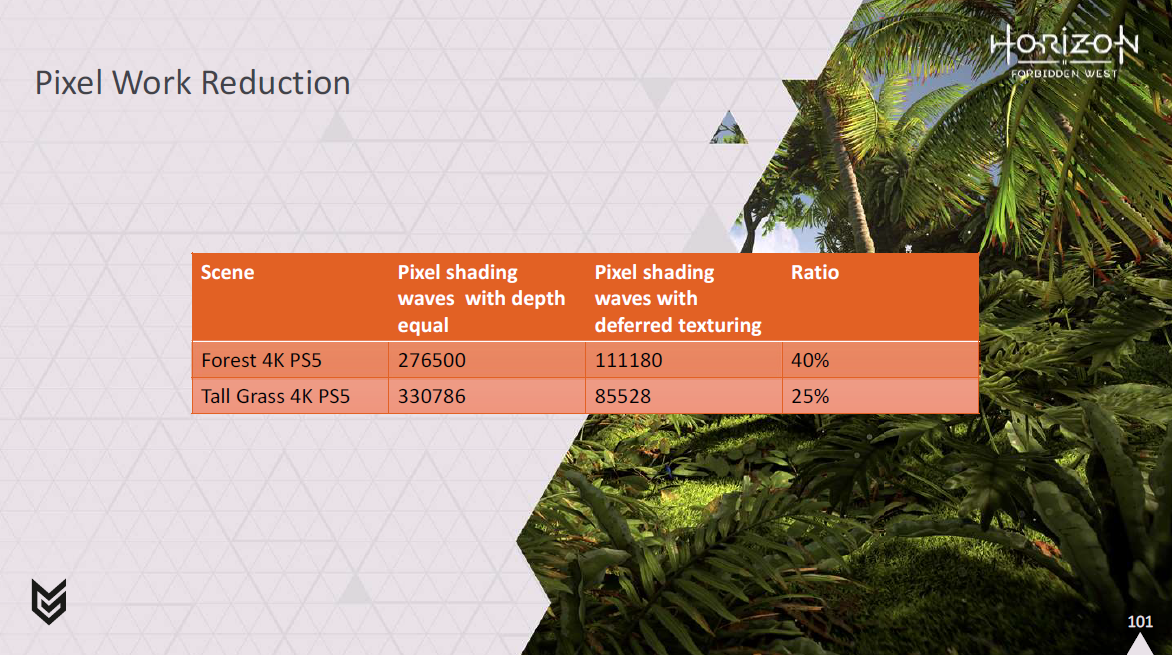
最後に、ピクセルワークでオーバーシェーディングをどの程度削減できているかも確認できます。
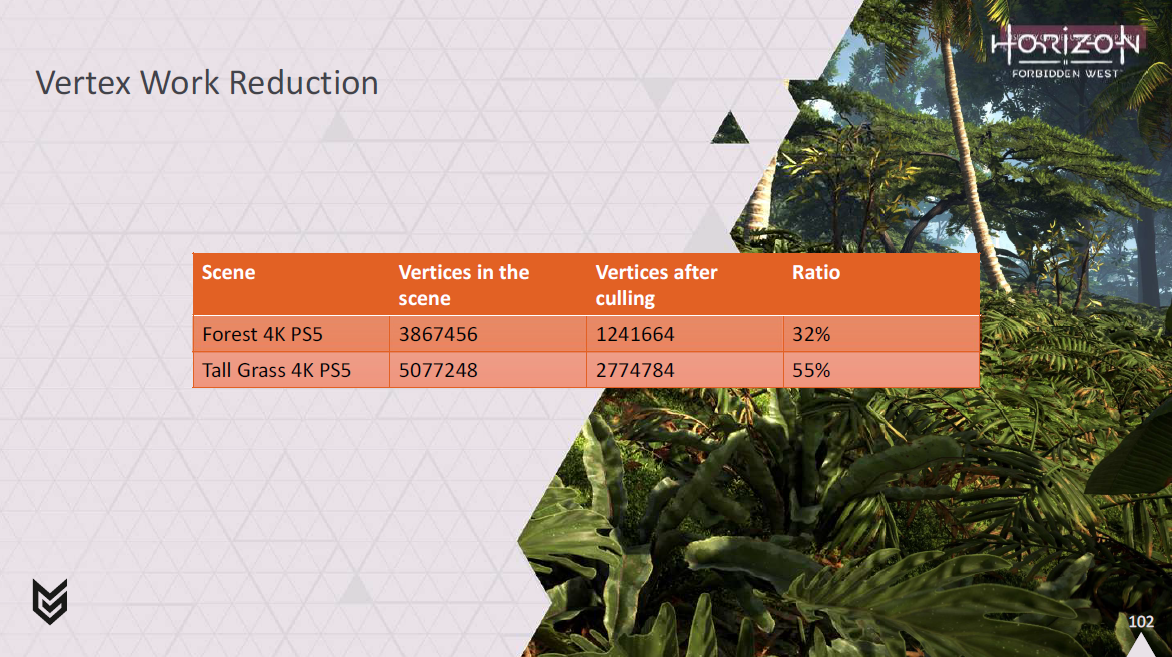
また、我々がやっている頂点カリングがどれだけの処理をを削っているかということも。

これで私の話は終わりです。
この冒険の旅を楽しんでいただけたでしょうか?新しい目でフォリッジのシェーディングを見てみました。ピクセルは開始時とほぼ同じように見えますが、草が少しだけ青々としているように見えます…少なくともフレームレートの観点からは。



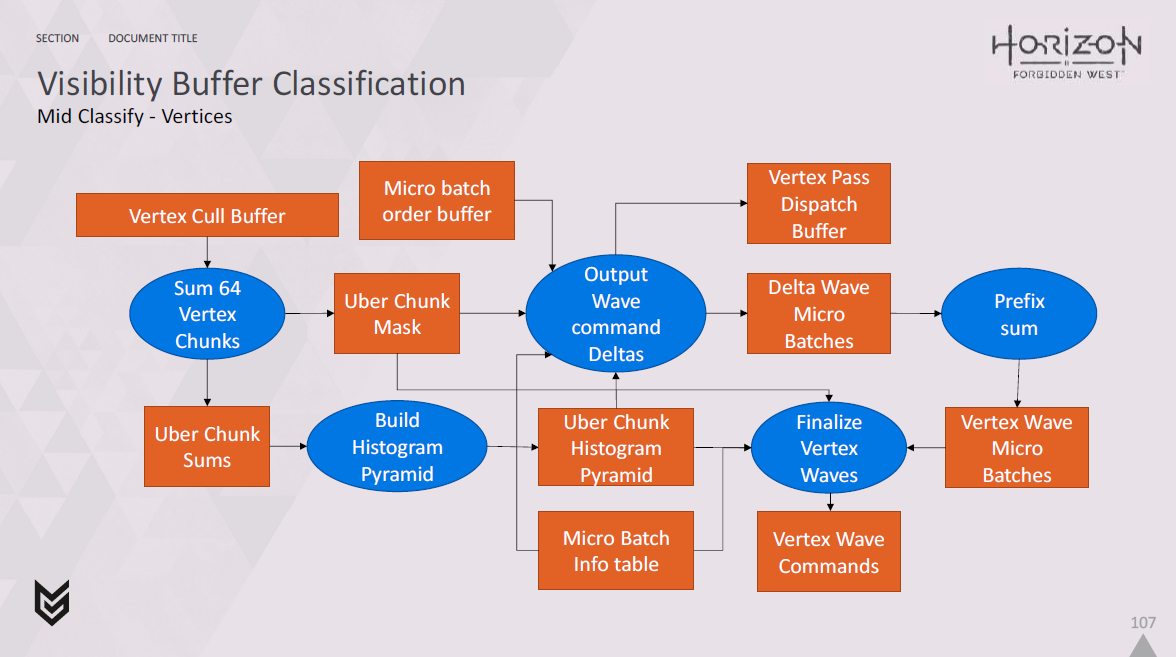
そこで、vertex cull bufferを取り出し、uberチャンク(64個の頂点の64個のチャンクの集合)と呼ぶものに、いくつのvertexチャンクが見えるかを合計する。
また、uberチャンクごとに64ビットのマスクを吐き出し、どのチャンクがセットされているかを知らせます。
これにより、ワークアイテムのリニアインデックスからuberチャンクとその中の子vertexチャンクのサブインデックスに簡単にマッピングできるようになります。
uberチャンクごとに構築した64ビットのマスクを使えば、この子vertexチャンクのインデックスを頂点チャンクのグローバルインデックスに簡単に戻すことができます。
すべてのマイクロバッチのディスパッチを行い、マイクロバッチ情報テーブルを読み、先ほど説明したマッピングを使って、各パスに必要なvertex wave数を割り出す。
CPUにセットアップしたマイクロバッチオーダーバッファを読み込み、マイクロバッチの処理順序を記述します。
これは、vertex wave commandsストリームのマイクロバッチIDが変更される各位置に、マイクロバッチIDのデルタを自動的に書き込むために使用されます。
その後、プレフィックスサムを使用して、デルタから実際のマイクロバッチIDに変換します。
その後、すべてのvertex wave commandsに対して間接ディスパッチを行って終了します。
ヒストグラムのピラミッドとマスクをマイクロバッチ情報テーブルと一緒に読み込んで、各wave commandがどのvertexチャンクを変換すべきかを調べ、すでに記録されているマイクロバッチと一緒にこの情報をコマンドに追加します。

<このスライドは(おそらく愚かにも)カットされ、以前はスライド44の直後に存在していました>
各パスで最大32のバッチグループをサポートします。
バッチグループとは、同じシェーダとバッチごとのデータを持つが、異なるインスタンスを持つバッチの集合です。
理想的には、この32の制限を設けたくないのですが、現在のところ、Visibility Bufferの分類処理の一部がどのように構成されているかの結果となっています。

我々のシェーディング処理は、シャドウと並行して実行されます。理想的には、計算処理の実行時間がシャドウにかかる時間とほぼ一致するようにしたいのです。
こうすることで、2つのワークロードが最適にミックスされることが期待できます。
どちらか一方が他方より著しく長く実行されると、非効率につながります。
この理想的なバランスを実現するために、パフォーマンスカウンターを使用して、それぞれが最後のフレームでかかった時間を把握します。
そして、これを使用して、SetComputeShderControl()のパラメータを徐々に調整し、計算処理のwavefrontが生成される速度を変更できるようにします。
通常、シャドウパスの終わりには深度圧縮があり、あまりきれいに重ならない傾向があるため、計算処理にかかる時間はシャドウ時間の90%程度を目標にしています。
また、コンピュートワークが可能な限りすべてのwavefrontを使用しないように調整されているにもかかわらず、長時間実行されるような状況は避けたいです。これは通常、シャドウが長くなるよりもずっと悪い状況です。