こんちゃわ。
Pocolです。
今日は…
[Fatnassi 2023] Sammy Fatnassi, “Shadow Techniques from Final Fantasy XVI”, Technical Report, Square Enix, 2023, http://www.jp.square-enix.com/tech/publications.html.
を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘していただけると有難いです。
1 Introduction
ファイナルファンタジーは、驚異的なグラフィックとともに魅力的なストーリーが展開される有名なビデオゲーム・フランチャイズであり、そのたびに、何が可能かという期待を押し広げてきました。本稿では、『ファイナルファンタジーXVI』のリアルタイムレンダリングにおける高品質なシャドウ生成の実装詳細を紹介します。この文書では、共有できるほど斬新なテクニックの一部のみを取り上げています。どのようなゲームであれ、その制作は巨大なチームワークの賜物であり、これに関して、技術に言及する場合は「我々」、作者に言及する場合は「私」を使用します。
セクション2と3では、GPU計算コストを削減し、反復的に合成された高品質シャドウと組み合わせることで、以前のTiled Deferred Shadowの結果よりもキャラクタシャドウの品質を向上させる、我々のTiled Deferred Shadowレンダラーを紹介します。セクション4では、シャドウマップの使用に関連する問題を解決するために、Oriented Depth Biasと名付けられた新しい方法について説明します。このシンプルなアプローチは、セルフシャドウの問題(シャドウアクネ)を処理し、従来使用されてきたハードウェアデプスバイアスを置き換えるのに効果的です。セクション5では、シャドウの間接的な計算が他の方法で調査することを困難にする、結果の検査と問題の診断のためのビジュアライザーを紹介します。セクション6では、いくつかの結論を述べます。
2 Deferred Shadows
プログラマブルGPUシェーダーによって可能になったTiled Deferred Lightingテクニックは、リアルタイムレンダリングにパラダイムシフトをもたらしました。これは、ライティング計算からサーフェスパラメータ計算を分離することを可能にし、より高いメモリ使用量の代償としてパフォーマンスの向上につながりました。これは、最初のパスとしてサーフェスパラメータをジオメトリバッファ(GBufferとして知られる)に格納し、コストのかかるライティング計算を可視ピクセルに限定した2番目のパスに遅延することで達成されます。以来、ファイナルファンタジーXVIを含むほとんどのゲームのライティングソリューションに採用されています。
‘A Scalable Real-Time Many-Shadowed-Light Rendering System'[2]において、Li Boは’Tiled Deferred Shadow’テクニックを導入し、ライティング計算からシャドウをさらに分割し、ライティングパスのVGPR Pressureを削減することでパフォーマンスを向上させました。このテクニックを拡張し、Closeup Shadowmapテクニックを追加することで、オブジェクトとライトのペアで任意の数の高品質シャドウをサポートすることができます。Closeup Shadowmapを繰り返しレンダリングし、同じレンダーターゲットを再利用することで、シャドウマップの数に関係なく、メモリオーバーヘッドは低く保てます。
すでにTiled Deferred Lightingレンダラーを使用している場合、初歩的なTiled Deferred Shadowシステムの実装はほとんど必要ありません。それは、Tiled Deferred Lightingパスから新しいTiled Deferred Shadowパスに各ライトのピクセル毎の可視性計算を移動し、Tiled Deferred Lightingパスによって読み戻されるバッファに中間結果を保存することで実現できます。しかし、このナイーブなアプローチは、ピクセルごとに多くのライトのサポートを期待する場合、非現実的なレベルまでメモリバジェットを増加させます。このセクションでは、より良いパフォーマンスとメモリ削減を達成した、我々のTiled Deferred Shadow実装の詳細について説明します(概要については図1を参照)。最初のフェーズはCPU上で実行され、次のTiled Deferred ShadowフェーズのセパレートGPUディスパッチを開始します。
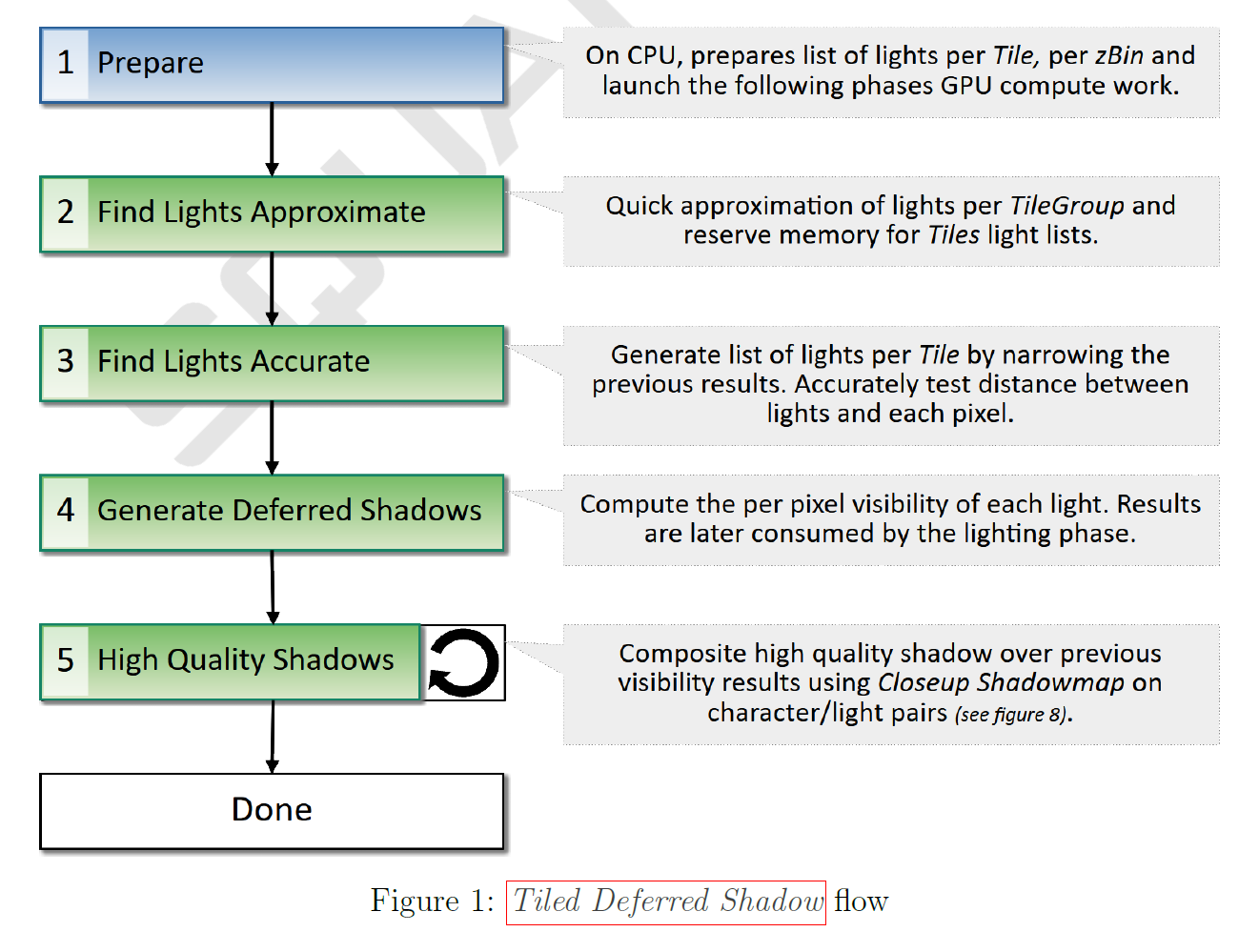
2.1 Phase: Prepare

この初期フェーズでは、CPU上で複数のライトのリストが生成され、次のフェーズでバッファ入力として使用され、シャドウ処理が高速化されます。これはGPUで処理されない唯一のステップです。
2.1.1 Output: zBin Buffer
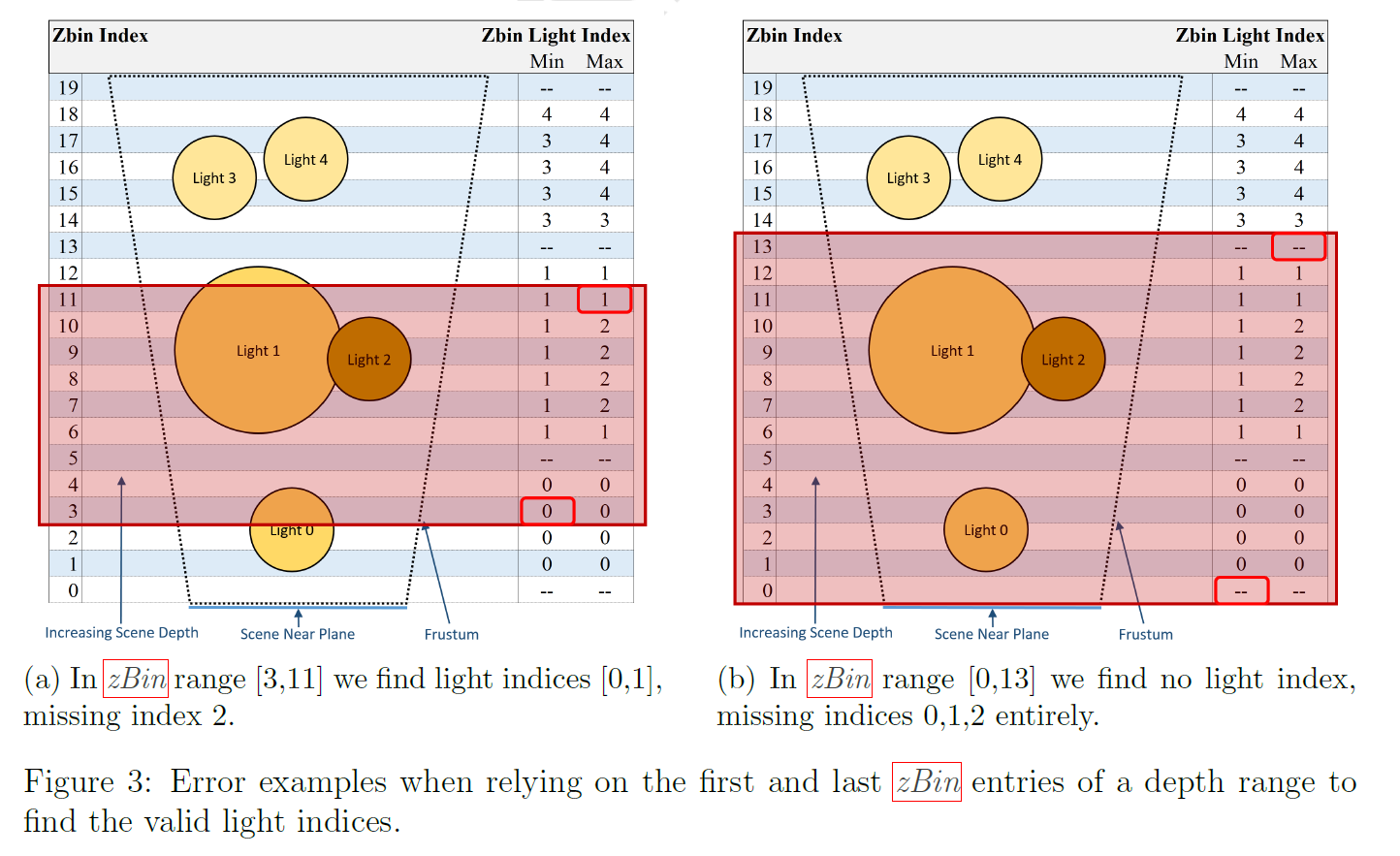
このバッファは、深度距離外のライトを素早く除去するために使用されます(詳しくは’Clustered Deferred and Forward Shading'[4]を参照)。zBinと呼ばれる1024の間隔でシーンビューの深度範囲を離散化し、それぞれの有効なリストを格納します。最初にシーンビューのニアプレーンに最も近い距離によってライトをソートすることによって、各zBinの最小と最大のライトインデックスを保持するだけで、ストレージ要件が大幅に削減されます(図2aを参照)。
図2aは、20のzビンに離散化されたシーンビューのサンプルを示しています。任意の1つの深度値に対して、関連するzBinが選択され、潜在的に有効なライトはminとmaxの間であることが分かります(含む)。例えば、zBin10の深度値では、1と2の間のライトインデックスが唯一の潜在的に有効なものであることがわかります。
zBinsの使用は、単一の深度値に対してはうまく機能しますが、深度範囲内のライトを見つけるために使用する場合は不十分です。最初と最後のzBinの最小と最大のライトインデックスを取るだけでは、有効な結果は保証されません(エラーの例については図3aと3bを参照)。深度範囲内のすべてのzBinsを反復することで、これは解決されますが、2回のルックアップだけで最小と最大のライトインデックスを見つけるというスピードの利点はありません。この解決策は、zBin (ranged)という名前の2番目のzBinデータセットを生成し、深度範囲を扱う値で埋めることです(図2b参照)。
- 各zBinの’min light index’に対して、現在のzBinと最後のzBinの間で最も低い値を保存します。
- 各zBinの’max light index’に対して、現在のzBinと最初のzBinの間で最も高い値を保存します。
zBin(範囲指定)の結果は、標準的なzBinの結果(より多くの偽陽性)よりも保守的であるため、両方のデータセットがzBinバッファに格納されます。1つまたは2つの連続したzBin内の深度値では、標準zBinバッファとzBin (ranged)バッファを使用します。

2.1.2 Output: The Light Mask Buffer
このバッファは、タイルの画面領域外のライトを素早く破棄するために使用されます。結果への予測可能な直接アクセスを維持しながら、タイルあたり1024個のライトをサポートするためのメモリ要件を削減するために、32バイトのビットフィールドが使用され、32個の連続した無効なライトのグループをスキップするための4バイトのビットフィールドが追加されています(図4参照)。

Tiled Deferred Shadowで使用されるShadow Tileサイズは\(8 \times 8\)ピクセルに設定されていますが、\(32 \times 32\)ピクセルの大きなタイルを使用することで、このバッファのCPU計算コストを抑えています(図5参照)。4K解像度の場合、これは8,100個のTilesを処理することになり、元の129,600個から減少しますが、その代償として次のフェーズで破棄される偽陽性がわずかに増加します(2.2セクション参照)。

2.2 Phase: Find Lights Approximate

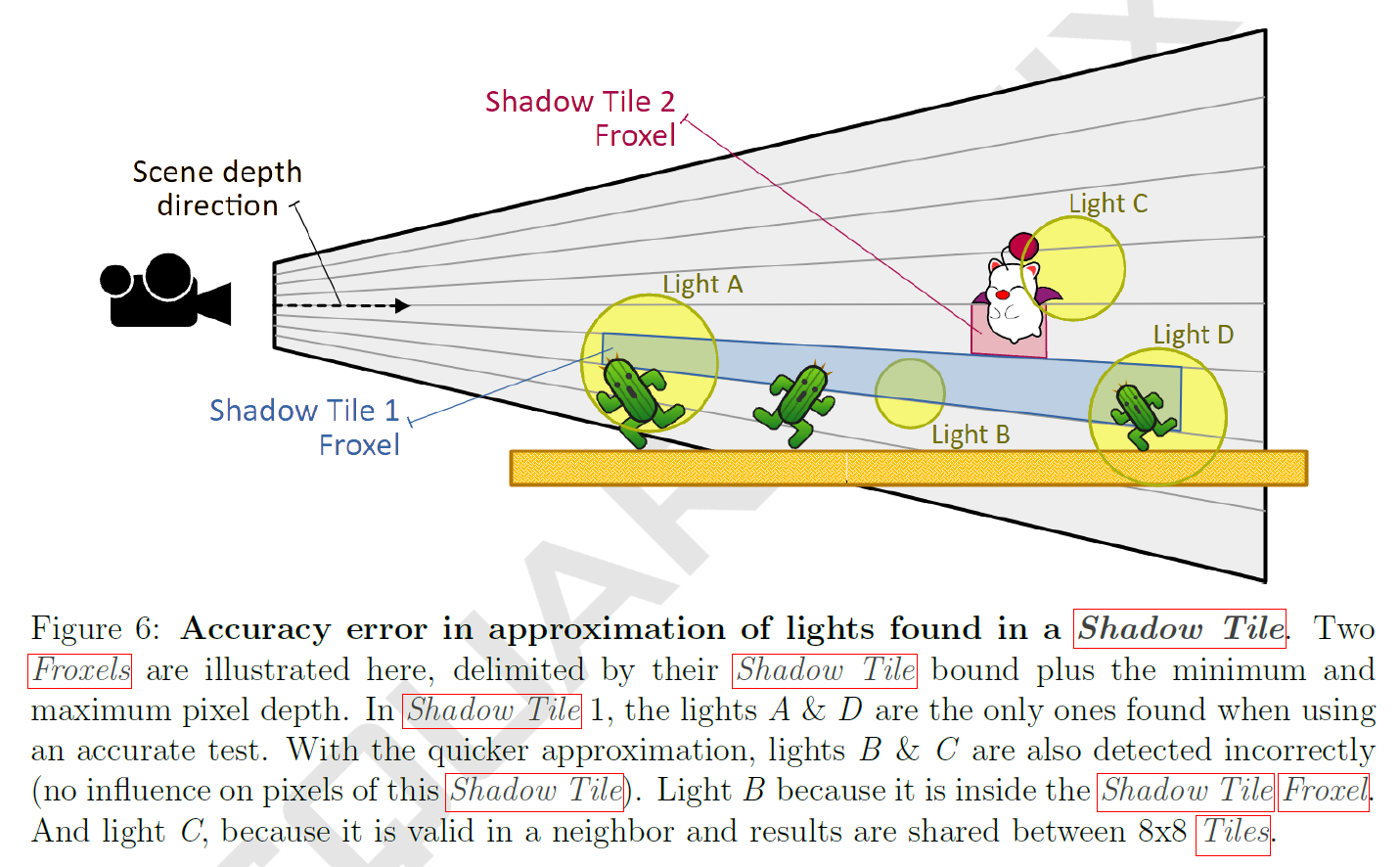
この第2フェーズには、Shadow Tileごとに有効な可能性のあるライトを見つけることと、次のフェーズで構築されたライトリストを保存するためのメモリーを確保することの2つの目的があります。我々は\(8 \times 8\)のCompute Work Unitで動作し、ピクセルごとの結果を処理する代わりに、スレッドごとに1シャドウタイルを評価することで、このフェーズを安価に保ちます。正確さよりもスピードを優先し、次フェーズでフィルタリングされる誤検出も想定しています。
最初に、各シャドウタイルの最小および最大シーン深度を階層的深度バッファーからフェッチして、画面座標と組み合わせてFroxelを生成します。次に、対応するTile Light Mask BufferとzBinバッファーエントリの両方に存在するライトを保持することによって、Froxelの有効なライトインデックスが検出されます。最後に、クイックな球体/球体テスト、記事’Cull That Cone!’ [1] から取得した円錐/球体テスト、およびボクセルをライトクリッピング空間に持ってくることによる軸平行バウンディングボックス (AABB) テストを使用して、Froxelとの境界交差を使用して各ライトを検査します (詳細については、リスト2を参照してください) 。
2.2.1 Output: Tile Group Light Mask Buffer
先に紹介したTile Light Mask Bufferと混同しないように、このバッファはタイルグループごとに有効なライト近似値を保存します。メモリ使用量を減らすために、図4で紹介したフォーマットを使用して、8×8のShadow Tileごとに1つのLight Mask Entryを使用します。4K解像度の場合、メモリ使用量は4.4MBから0.3MBになります。Tile Groupサイズに一致するCompute Work Unitを使用することで、スレッド間の遅いメモリ交換を避けるために、計算で高速なLane Operatorsを活用します。
2.2.2 Output: Tile Light SlotID Buffer
このバッファには、計算後の各シャドウタイルの Light SlotID が格納されます。多くのライトを含むShadow Tileは少なく、最大数を処理するためにすべてのShadow Tileに同じ固定量のメモリを割り当てるのは無駄です。その代わりに、各Shadow Tileが、おおよそのライト数を処理するのに十分なメモリを共有バッファに確保する柔軟なメモリアプローチが使用されます。これにより、次のフェーズで生成される2つのライトリストのメモリ消費を抑えながら、Shadwo Tileごとにより多くのライト数をサポートすることができます。このアプローチでは、関連するメモリ使用量は22.1MBから5.5MBに減少しました。
Shadow TileごとにLight SlotIDを割り当てるには、まず、1つのCompute Work Unitごとに1つのCompute Shader Threadが、Tile Group全体の有効なライトの数を合計します。次に、共有グローバルカウンターのシングルアトミックインクリメントで、これらのエントリーのメモリーを予約します。最後に、各スレッドは、アトミック値をタイルグループ内の前のタイルによって使用されたエントリ数でオフセットすることによって、それ自身のShadow TileのLight SlotIDを計算します。この計算では、隣接スレッドの値にアクセスするときにできるだけ速度を高めるために、lane operationsに委ねます。
Note:もし、フレキシブルメモリアプローチなしでデバッグモードをサポートし、代わりにShadow Tileごとに固定数のライトのためのスペースを割り当てることができれば便利です。Light SlotID値が予測可能になったので(Shadow Tileの座標以外に先験的なものは必要ありません)、次のステップで生成されるShadow Tileのライトリストの検査が簡単になります。


2.3 Phase: Find Lights Accurate

この第3のフェーズは、各Shadow Tileでより正確なピクセルごとのテストを使用して、Tile Group Light Mask Bufferからライトインデックスをフィルタリングします。以前の結果は複数のShadow Tileで共有され、Froxelテストは偽陽性を発生させるため(図6参照)、次のステップでシャドウを計算する前に可能な限り除去します。Shadow Tileごとのライトのリストは、Light SlotIDから計算された位置のEarly Light List Bufferに格納されます。この処理は、8×8 ピクセルのシャドウタイルサイズに一致するグループサイズを使用するコンピュートシェーダによって達成されます。各コンピュートスレッドが1ピクセルを処理し、シーン深度を読み、Tile Group Light Mask Bufferエントリで見つかったTile Groupライトを繰り返し処理します。Shadow Tileは、そのピクセルの少なくとも1つの範囲にあるとき、ライトを有効とみなします。
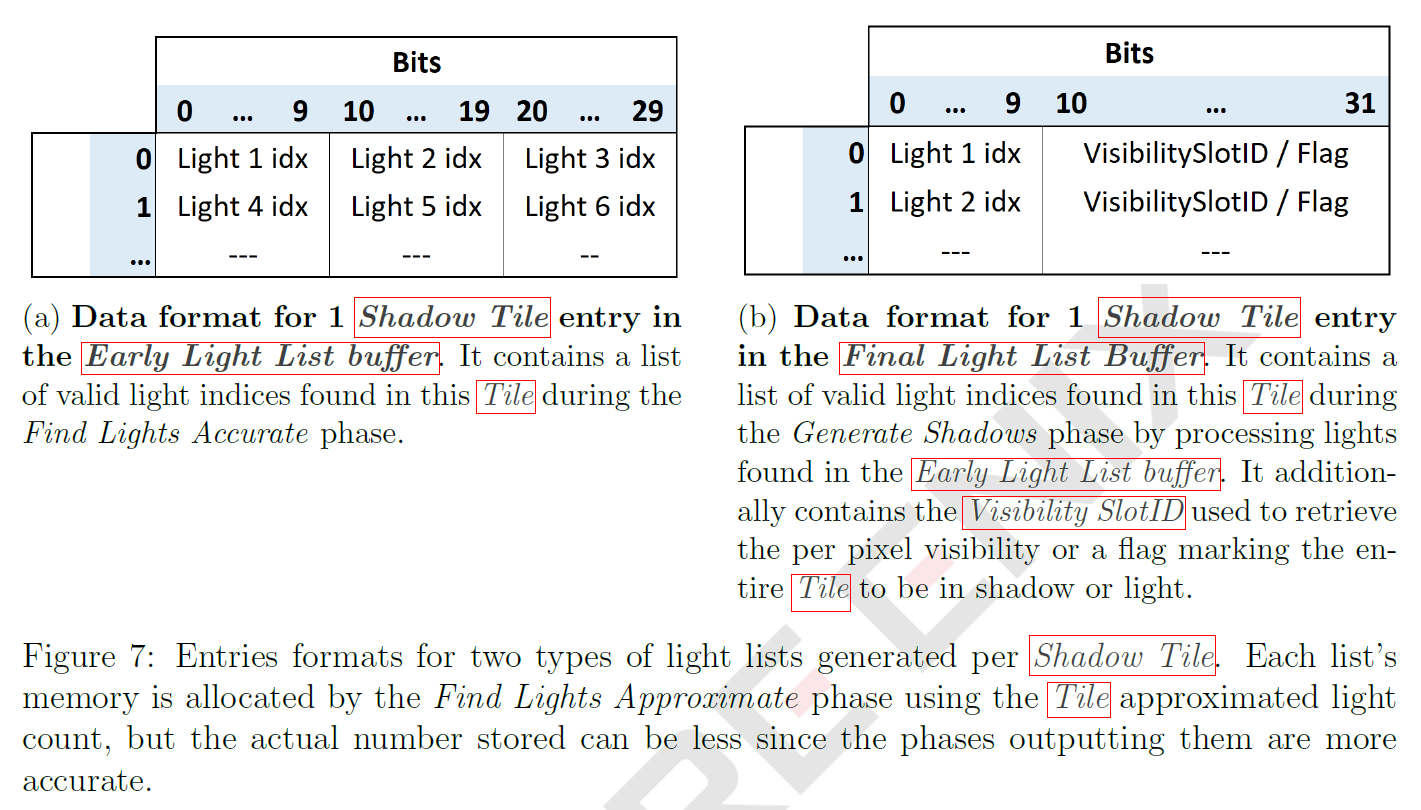
2.3.1 Output: Early Light List Buffer
このバッファには、各Shadow Tileにあるライトの情報が含まれています。メモリ使用量を最小化するため、4バイトごとに3つのインデックスを格納し、最大インデックス値1023に対して使用可能なビットを10ビットにしています(詳細は図7aを参照)。追加のバッファには、各Shadow Tileリスト内の有効なライトの数も書き込まれます。

2.4 Phase: Generate Deferred Shadows

第4フェーズでは、オリジナルのディファードライティングシェーダーからインポートしたコードで、各ライトのピクセル可視性を計算します。Early Light List BufferのShadow Tileエントリからライトのリストを使用して、それらを繰り返し、近傍比率ソフトシャドウを使用してシャドウを生成しますが、他のテクニックで代用することもできます。
シャドウ結果のメモリ使用量を削減するために、Shadow Tileごとにサポートされる最大数のライトごとに1つのフルスクリーンバッファを割り当てないように、再び柔軟なストレージアプローチを使用します。これにより、バッファサイズを~253MBから~64MBに減らすことができます。ライトの最大数を固定する代わりに、各Shadow Tileは共有バッファのストレージを使用して必要な数のライト結果を持ちます。我々は、ゲームの最悪のシナリオを処理するのに十分なバッファサイズを選択し、レベル内のライトの数に応じて動的に調整するように簡単に変更することができます。
ワークユニットごとに1つのシャドウタイルを処理し、各スレッドが1つのピクセルを処理するために、8×8のディスパッチグループサイズを使用します。Shadow Tileが完全に見えなくなると、それは無視され、決して出力されません。Shadow Tileが完全にライト内のときは、ライトインデックスとfully litフラグを出力します。この2つのケースでライト/ピクセル情報の保存を避けることで、大量のメモリを節約できます。Shadow Tileに部分的な影が含まれる場合、アトミック操作で共有グローバルカウンタから計算された Visibility SlotID を割り当てて、ピクセルごとの結果を保存します。ライトの視認率はピクセルごとに8ビットを使用するので、各視認性スロットのエントリは64バイトのメモリを必要とします。
2.4.1 Output: Final Light List Buffer
このバッファは、Shadow Tileごとのエントリを格納し、完全にシャドウになっていない可視ライトのインデックスを含む。各ライトのインデックスに沿って、fully litフラグ、または割り当てられたときの Visibility SlotID を格納します。ライトインデックスには10ビット、Visibility SlotIDには22ビットが使用され(図7b参照)、4k解像度のシャドウタイルあたり400万エントリ、または32個の部分的なシャドウライトに十分です。実際には、ライトとタイルのペアのほとんどはVisibility Slotを必要としないので、Visibility Bufferのサイズによって制限されるだけで、Shadow Tileあたりにより多くのライトをサポートすることができます。追加のバッファには、各Shadow Tileリストの有効なライトの数も書き込まれます。
2.4.2 Output: VisibilityBuffer
このバッファは、Shadow Tileのピクセルごとのライトの可視性を格納するために使用される8×8のメモリブロックを含んでいます。これは、ディファードシャドウシステムによって必要とされる最大の中間バッファであり、ライティングフェーズが完了すると、フレームの残りのために破棄することができます(他のバッファについても同様です)。各ピクセルはライトの可視性の割合を表すために8ビットを使用しますが、プロジェクトのニーズによっては4ビットで十分な品質かもしれません。

2.5 Phase: High Quality Shadows

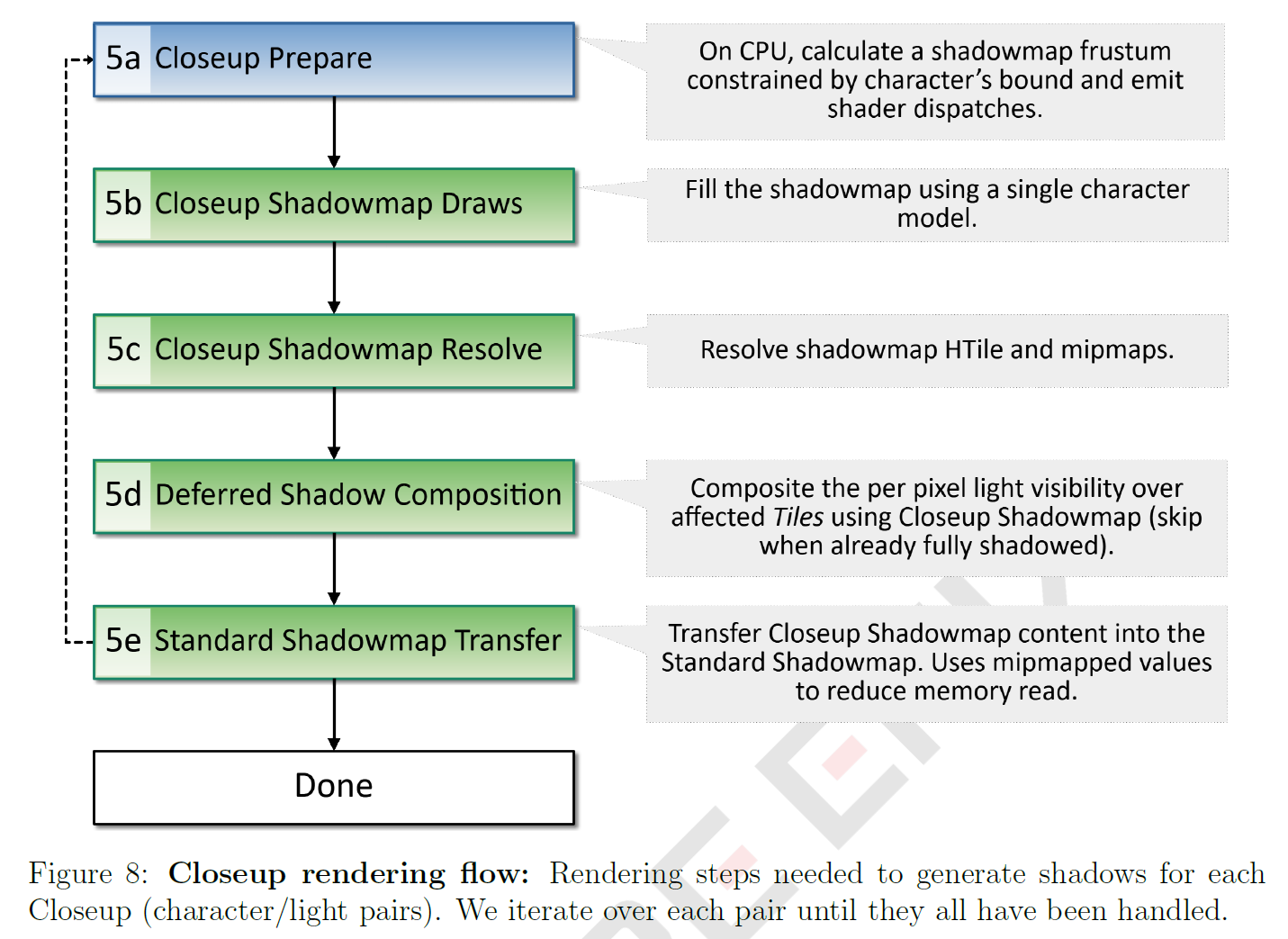
最後の第5フェーズでは、重要なキャラクターの影をより高品質に処理します。これらはStandard Shadowmapから除外され、代わりに専用のCloseup Shadowmapで描画されます。ライトではなくキャラクタに拘束されたカスタム視野を使用することで、ピクセルあたりの立体角が小さくなり、解像度が向上します。ライトとキャラクタのペアごとに1つのCloseup Shadowmapを割り当てることによる高いメモリオーバーヘッドを避けるために、完全な更新ループ(図8参照)を完了した後に同じものを再利用し、既存のVisibilityBufferにキャラクタのシャドウを合成します。このトピックの範囲を考慮して、セクション3で詳細な説明をします。
2.5.1 Output: Updated Final Light List Buffer
シャドウタイルが完全にライティングされている状態から部分的にライティングしている状態になった場合、Visibility Slotを割り当て、Visibility SlotIDを保存する必要があります。逆に、完全非ライティングになったシャドウタイルは、Visibility SlotIDをfully unlitフラグに置き換えることで知る必要があります。どちらの場合も、Final Light List BufferのShadow Tileエントリを更新することで処理されます。
2.5.2 Output: Updated VisibilityBuffer
ライトの視認性は、2.4.2節で紹介したのと同じ手法で計算されますが、影の生成にはCloseup Shadowmapを使用します。ライト/ピクセルの可視性が低下すると、VisibilityBufferの値が更新されます。
2.5.3 Output: Updated Standard Shadowmap
Standard Shadowmapをスキップし、Closeup Shadowmapでのみレンダリングすることで、High-Quality Shadowを持つキャラクターの描画数が増えるのを回避しています。しかし、フォーワードライティングオブジェクトはディファードライティングに頼ることができないため、Standard Shadowmapは各Closeup Shadowmapをそのコンテンツに合成する必要があります。これにより、キャラクタのシャドウがフォワードレンダラーで利用できるようになりますが、より高品質な利点はありません。
3 High Quality Shadow

ファイナルファンタジーXVIでは、会話中に登場人物のシネマチックなクローズアップを使用することに重点が置かれているため、ちらつきのあるアーティファクトがプレイヤーの気を散らすことなく、より高品質なシャドウを実現することが重要になります。これは、各キャラクター/ライトのペアに対して個別のCloseup Shadowmapを使用することで実現できます。我々は、数に比例した高いメモリオーバーヘッドを伴わずに、無制限のペアリングをサポートしたいと考えています。我々のTiled Deferred Shadowの実装をベースに、High-Quality Shadowシステムを構築し、各キャラクター/ライトのシャドウを1つの再利用されたCloseup Shadowmapでインクリメンタルに処理します。このフェーズには、以下のセクションで説明する5つのサブステップがあります。
3.1 Step: Prepare
CPU側では、キャラクタの境界とライトの境界の間の最小の視野によって制約される新しいカメラビューを計算します(図9参照)。別個のシャドウマップを使用しているため、その解像度はライトのStandard Shadowmapよりも高くすることができ、ピクセルあたりの立体角をさらに小さくすることでさらに品質を高めることができます。Closeup Shadowmapには2048×2048ピクセルが割り当てられていますが、各ハイクオリティシャドウはライトの推定スクリーンカバー率に基づいて使用する解像度を下げます。最後に、各High-Quality Shadowの開始時に、GPU上のCloseup Shadowmapをクリアするコマンドを送信します。
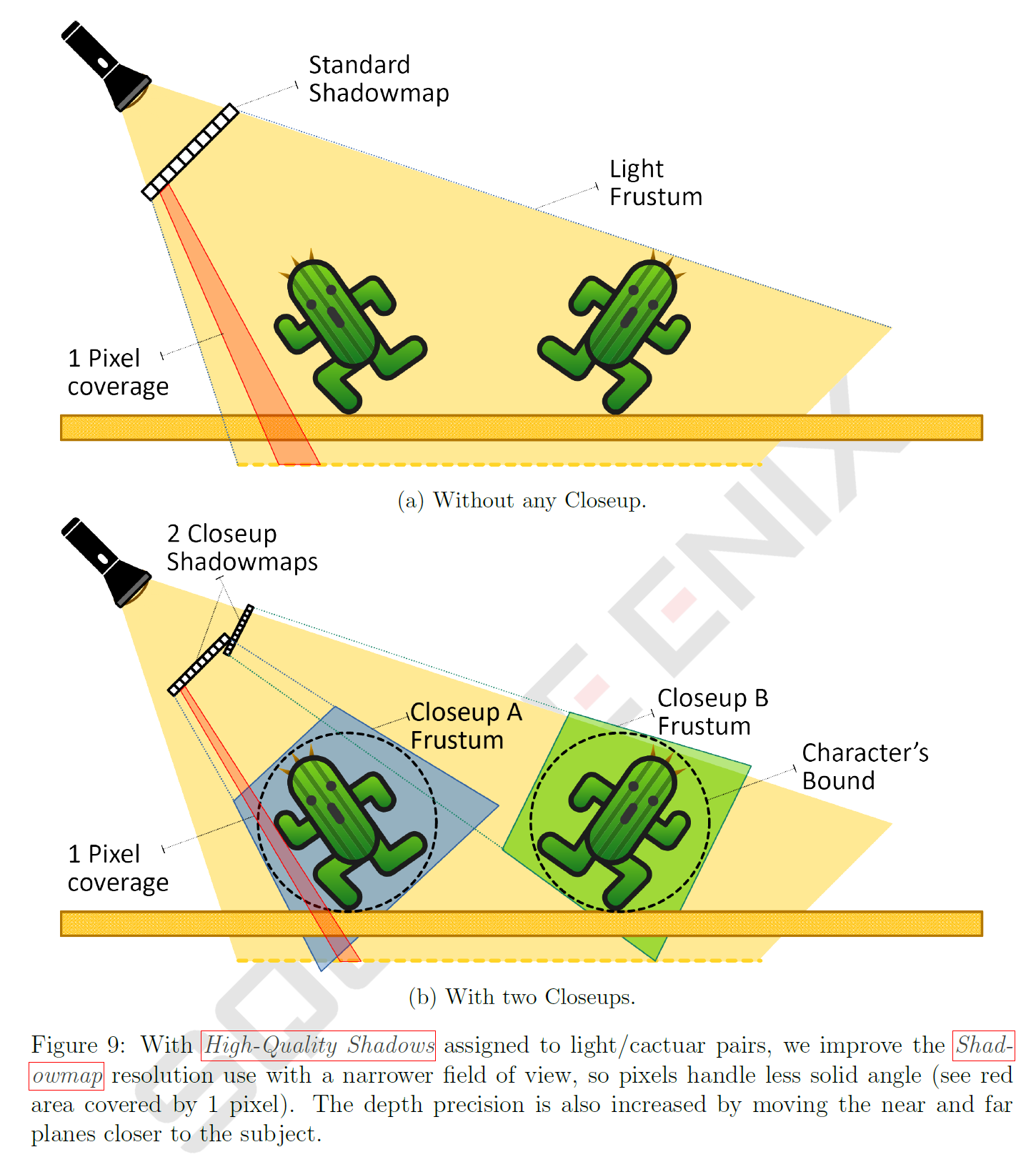
3.2 Step: Closeup Shadowmap Draws
キャラクタメッシュのドローコールをライトのStandard ShadowmapからHigh-Quality ShadowのCloseup Shadowmapにリダイレクトすることで、ライトごとにキャラクタメッシュを複数回描画することを回避しています。この方法は、各レンダリングエンジンの実装によって異なります。
3.3 Step: Closeup Shadowmap Resolve
Closeup Shadowmapの描画が完了したら、関連する階層的深度バッファを解決し、2×2ピクセルごとにライトに最も近い距離を保ちながら、シャドウマップのミップマップバージョンを生成します。
3.4 Step: Shadows Composition
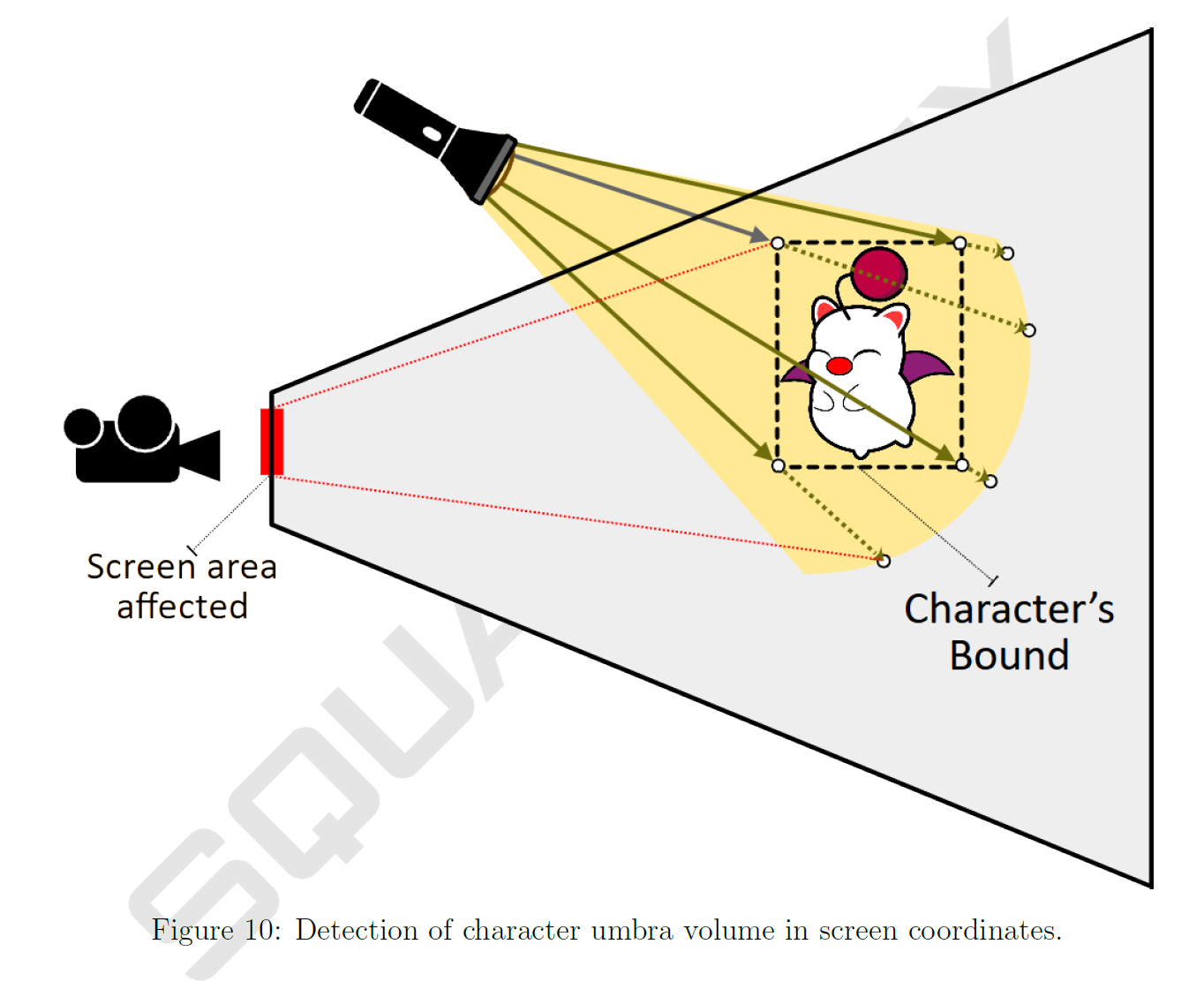
CPU上では、ライトの原点から各境界領域の位置まで、ライトの半径に達するまでレイを伸ばして、キャラクターの本影のボリュームを構築します。スクリーン座標に投影した後、影響を受けるShadow Tileに限定してcompute work unitを起動するための最小位置と最大位置を見つけます(図10参照)。
コンピュートシェーダでは、各ワークユニットは、そのFinal Light List Bbufferエントリで関連するライトインデックスを探します。見つからなかったり、完全に影になるフラグが立った場合は、そこで処理を停止します。そうでない場合は、各ピクセルのライトの可視性を評価し、Shadow Tile全体が完全にライティングされている場合は、ここで停止します。部分的な影が検出された場合、可視性スロットが割り当てられていることを確認し、2.4.2 で示した方法を使用して、新しく減少したライトの可視性を保存します。(


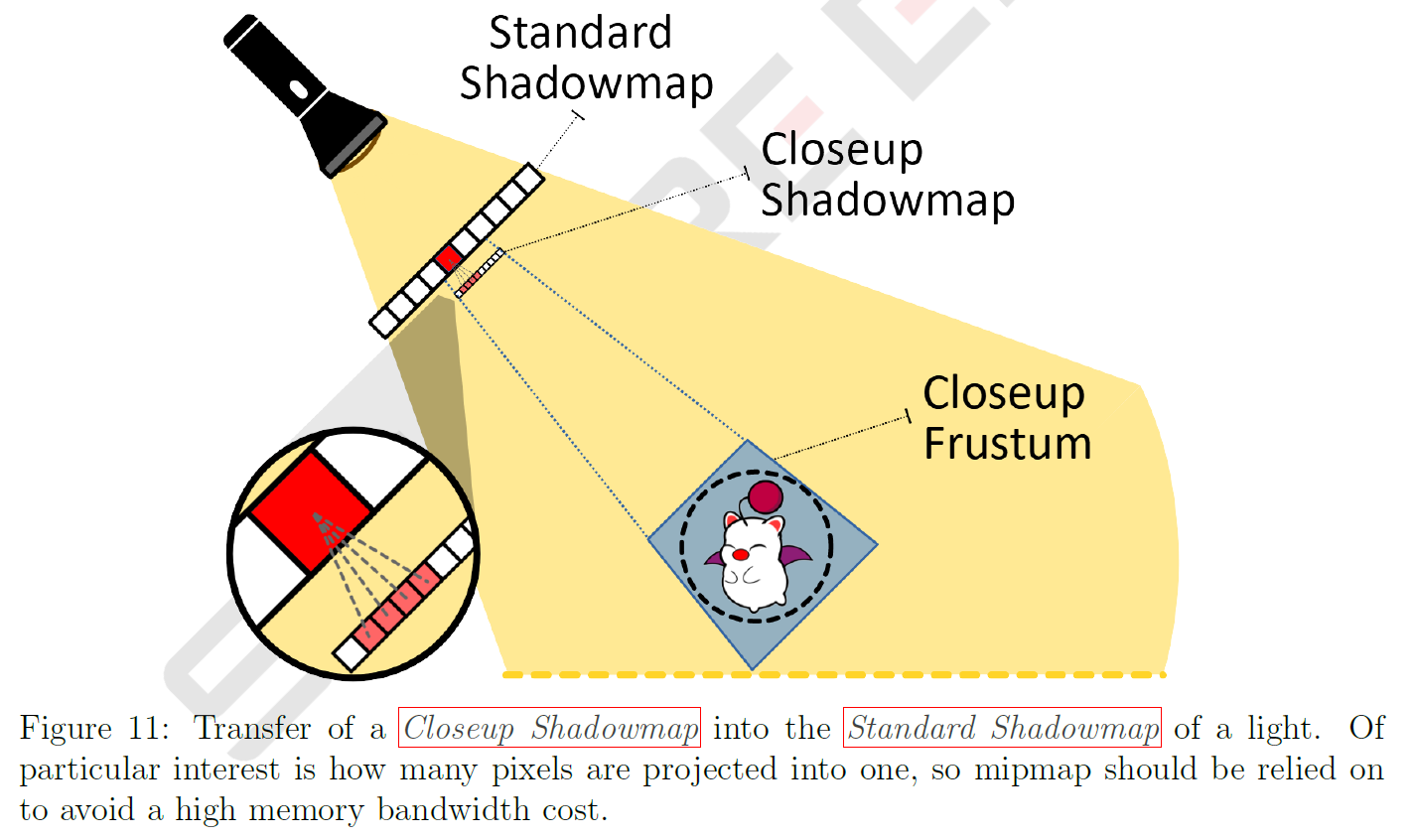
3.5 Step: Standard Shadowmap Transfer
各High-Quality Sahdowは、共有されたCloseup Shadowmapレンダリングターゲットを使用して個別に処理されます。これは、メモリのオーバーヘッドが固定であるため、計算コストが唯一の制限要因であるという利点があります。ただし、シャドウマップのコンテンツは、各キャラクタとライトのペアの間で破棄されるため、フォワードレンダラーでは使用できません。High-Quality Shadowを持つキャラクタは描画されないため、各Closeup Shadowmapの結果を関連するStandard Shadowmapに戻します。
これは、Closeup ShadowmapのニアプレーンクワッドをライトのStandard Shadowmapの座標に投影することで実現します。1つのStandard Shadowmapピクセルは多くのCloseup Shadowmapピクセルを含んでおり、それぞれのピクセルを読み取るには法外なコストがかかります(図11参照)。この高帯域幅の問題は、Closeup Shadowmapのミップマップバージョン(セクション3.3参照)を使用し、各ピクセルが領域の最小XY次元をカバーするために2つのサンプルを必要とするミップマップレベルを選択することで解決されます。そして、全領域がカバーされるまで、ミップマップされたCloseup Shadowmap値を繰り返し読み出します。例えば、Closeup Shadowmapの15×37ピクセルの領域に投影されるピクセルは、ミップマップレベル3を選択します。
\begin{eqnarray}
MipLevel = Ceiling ({\rm log}_2(min(width, height)/2))
\end{eqnarray}
3.6 Results
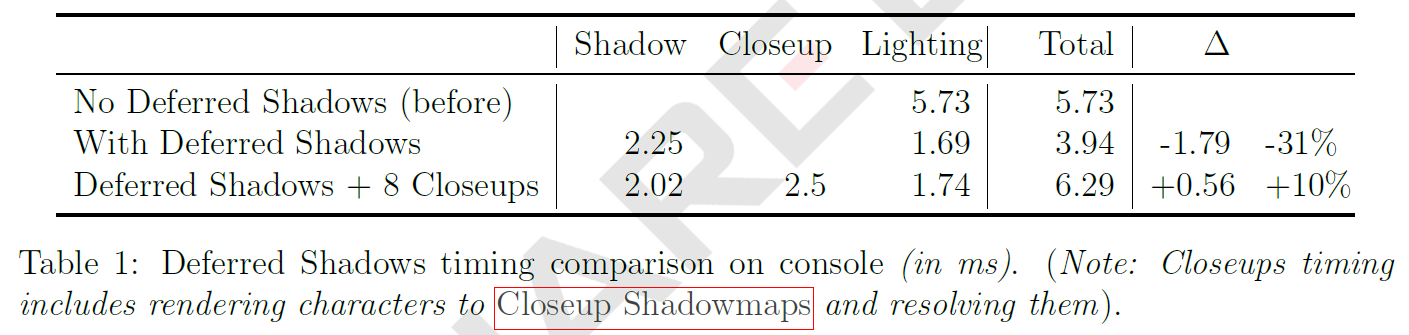
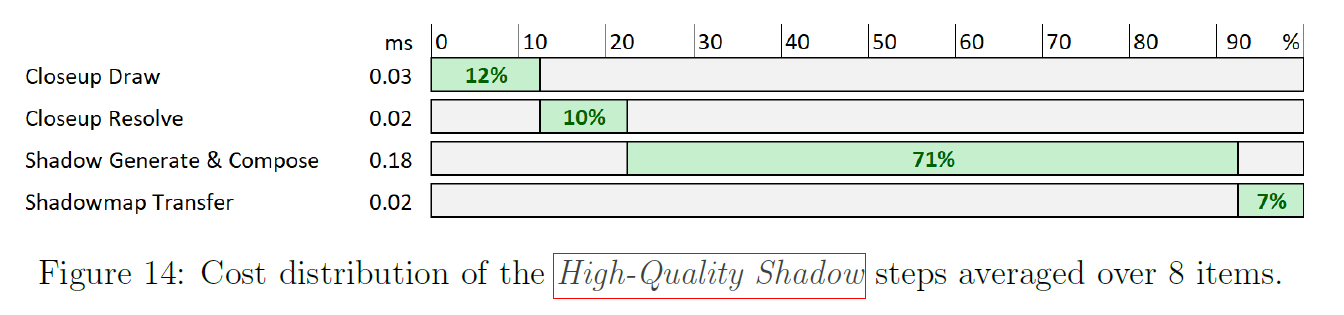
表1は、我々のマルチフェーズアプローチのコスト分布を示す図13と共に、Tiled Deferred Shadowを使用することによって達成される性能向上があることを示しています。また、図14は各段階のコスト分布を示し、High-Quality Shadowにはコストがかかることを示しています。これは、許容されるキャラクターとライトのペアの数を調整することで管理できます。さらなる削減のために、複数の High-Quality Shadows を同時に解決することや、(セクション3.5で説明したように)結果を転送する代わりに Standard Shadowmap のドローコールを通常通り発行することなどが残されています。




4 Light leak reduction
シャドウマップテクニックの導入は、リアルタイムシャドウ生成への私たちのアプローチを変革し、現在ではほとんどのゲームで使用されていますが、いくつかの問題があります(’common techniques to improve shadow depth maps'[5]を参照)。限られた深度値の精度と、テクスチャに保存されたときのシャドウビューの離散化は、サーフェスが誤ってそれ自体に影を落とすセルフシャドウの問題(一般にシャドウアクネと呼ばれる)を引き起こします(図17参照)。これを軽減する必要があり、従来のHardware Depth Biasに代わる、Oriented Depth Biasという新しいアプローチを導入します。

4.1 Hardware Depth Bias
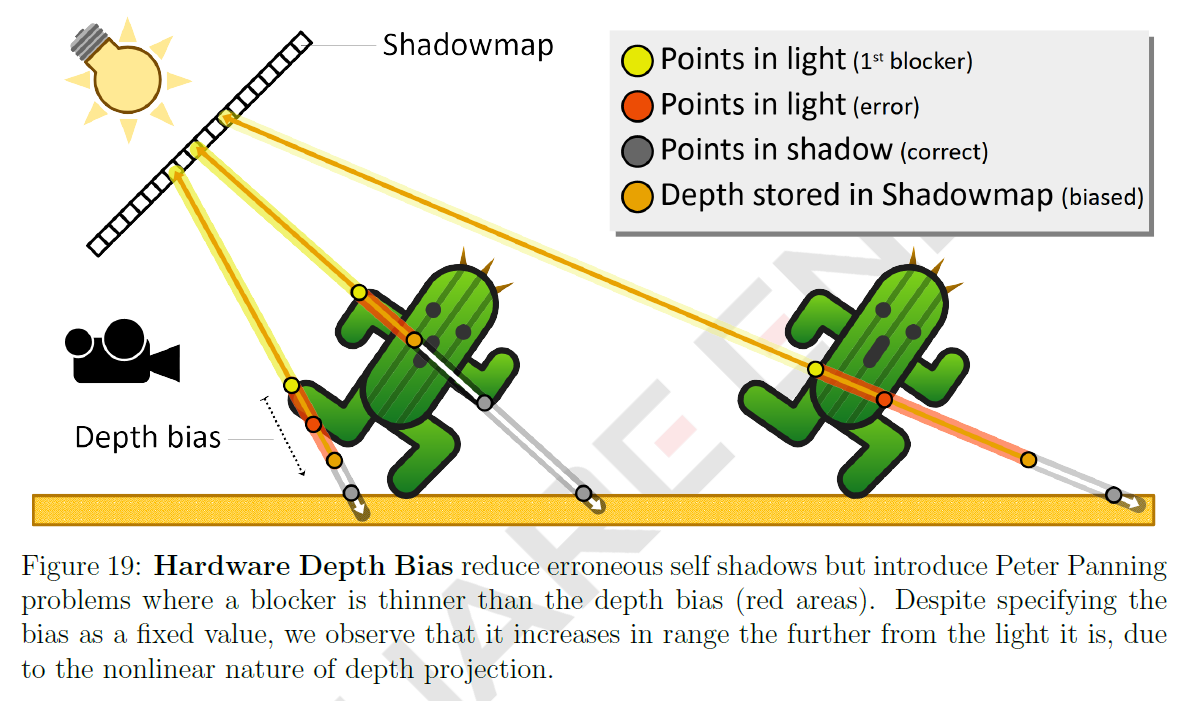
シャドウアクネを減らすために、GPUはDepth BiasとSlope Bias設定を使ってシャドウマップレンダリングターゲットに書き出される深度をオフセットすることができます。ただし、オフセットが高すぎると、影がそれ自身から遠すぎるときにオブジェクトが地面の上に浮いているように見える、Peter Panningと呼ばれる2つ目の視覚的な問題が発生します(図18参照)。この問題に対処するには、メッシュを厚くし、バイアス値を微調整して、2つの問題の間で絶妙なバランスをとる必要があります。これをさらに複雑にしているのは、シャドウマップの深度が非線形であることで、(Nathan Reedによる’Depth Precision Visualized'[3]を参照)すべての深度距離に対して適切なバイアス値を選ぶことは不可能です。図19は、ハードウェアデプスバイアスの使用の背後にある問題を示しています。

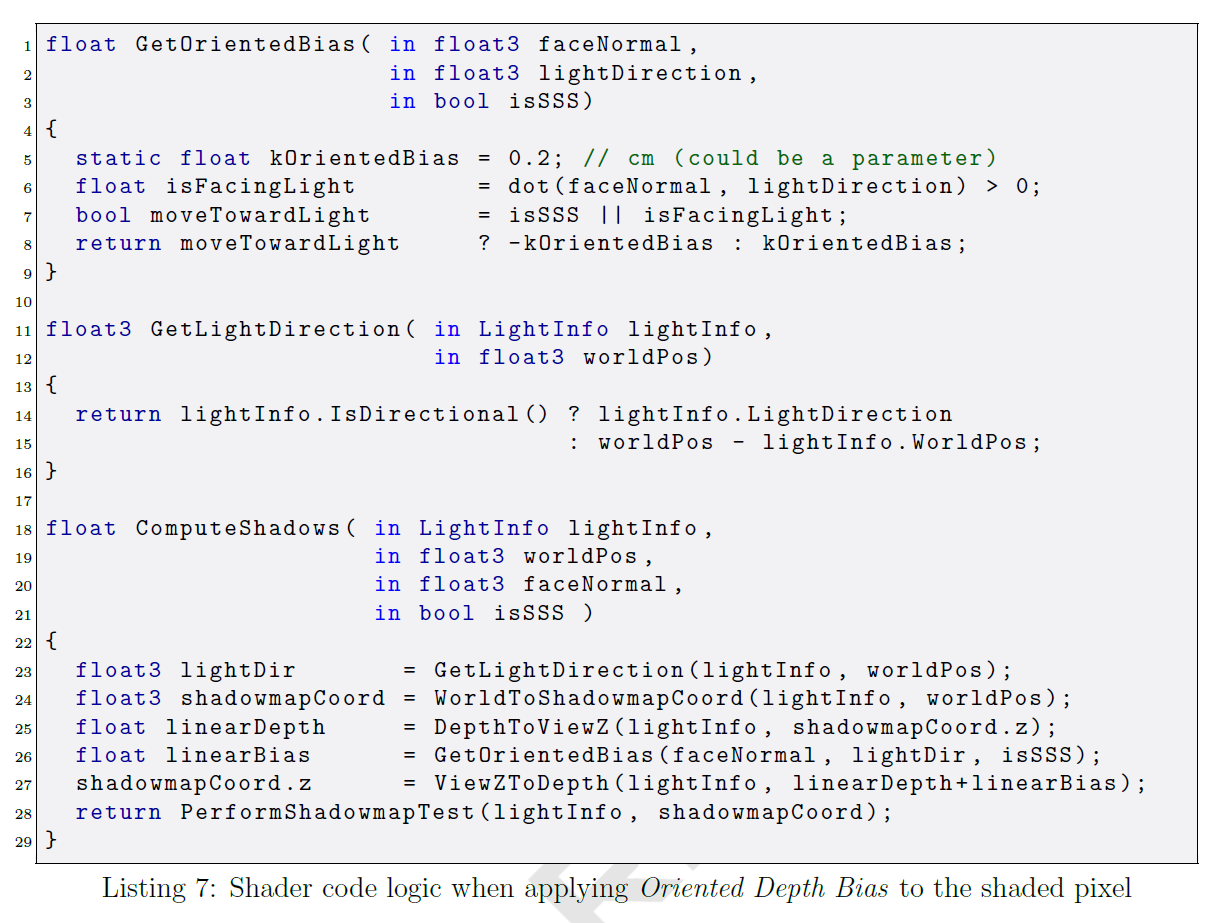
4.2 Oriented Depth Bias
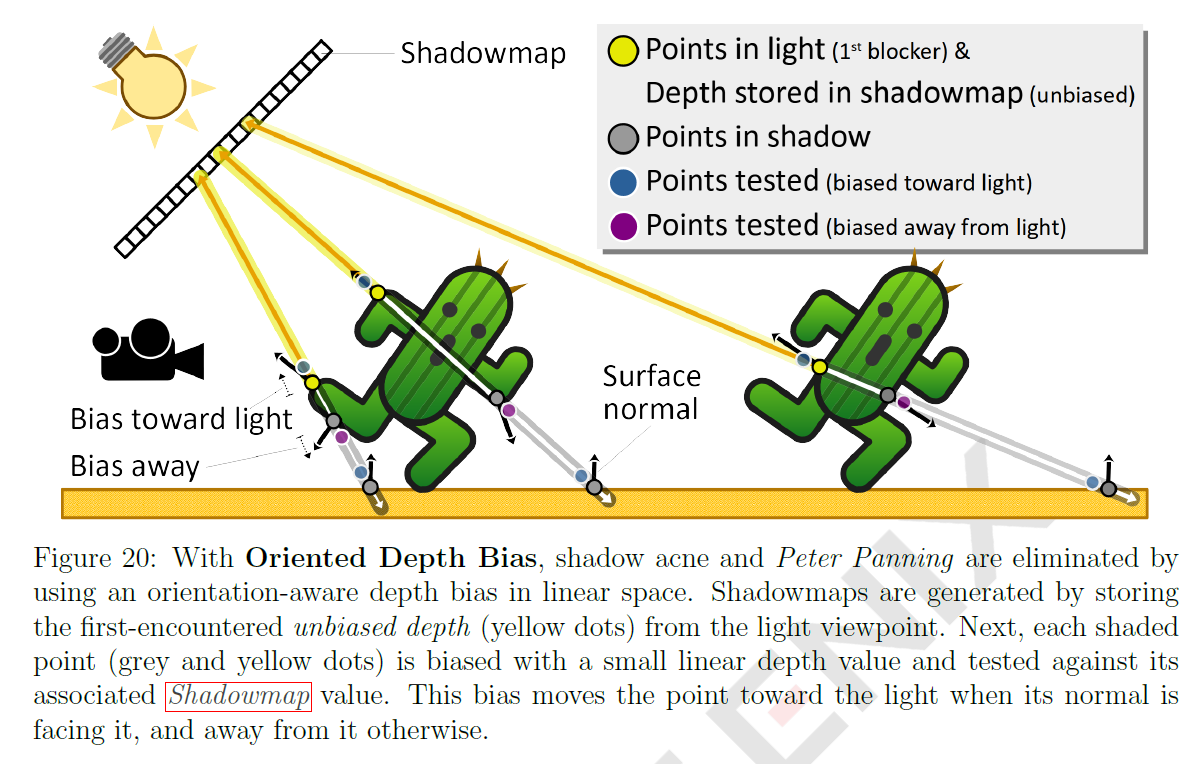
GPUのオーバーヘッドが少なく、これらの問題を解決する新しいシンプルなテクニックを紹介します。シャドウマップはまず、ハードウェアの深度バイアスなしで生成され、可能な限り実際のサーフェスに近い状態を保ちます。我々は、関連するシャドウマップ値と比較する前に、テストされた深度に対してorientation aware biasを加算し,それで置き換えます。ある点が影になっているかどうかを評価するとき、その点の面の向きに基づいて、その点をライトに近づけたり遠ざけたりします。ライトに面している場合は、シャドウアクネを減らし、ライトに向かって移動し、障害になる確率を下げるのを望みます。ライトに背を向けているときは、Peter Panningを減らしてライトから遠ざけ、セルフシャドウの確率を高めます。図20とリスト7は、これら2つの可能性のロジックを示しています。この解決策は、使用する深度バイアスを2mmに下げ、厚みのない両面ポリゴンに信頼できる影を作り出します。
我々は、表面下散乱(SSS)テクニックを使って、あるサーフェイス位置からメッシュに入った光がメッシュ内部で数回バウンドし、別の位置に存在する様子をシミュレートしています。ライトの前にあるオブジェクトを見ると、その内部の色合いに基づいて拡散色が発色します。肉厚の薄い部分や木の葉、一部のプラスチックなどで観察できます。SSSは、その効果を妨げるセルフシャドウを除去するための特別な処理が必要で、シャドウマップで描画する際に、SSSを持つメッシュの前面を省略することで実現できます。この場合、Oriented Depth Biasテクニックがうまく機能しすぎて、予防措置にもかかわらず影ができてしまいます。シャドウ生成時にこのテクニックの動作を微調整することで、この問題を解決します。SSSが有効なピクセルを処理するときは、常にライトに向かって移動するようにアルゴリズムを変更し、シャドウマップのシングルフェース描画と組み合わせたときにセルフシャドウが発生する可能性をなくしました。シャドウマップへの正面描画を維持したい場合は、ライトに向かって移動するときに高い深度バイアス量を使用するようにロジックを変更します。
4.3 Results


5 Visualizer
シャドウ生成に複数のステップと間接性を導入することは、実装中に必ず発生する問題の診断に困難をもたらします。そのため、様々なデバッグビジュアライザにアクセスすることが不可欠となり、各ステップへの詳細な洞察を与え、GPUフレームキャプチャのピクセルピッキングによるシェーダデバッグ機能を保持します。ビジュアライザは、ゲーム上でリアルタイムに結果を表示するためと、GPUフレームキャプチャで後で分析するために一時的なレンダーターゲットに出力するために使用されます。

5.1 Shadows
これは最もよく使われるビジュアライザーで、選択したライトの影を表示します。第一のモードは、以前に計算されたTiled Deferred Shadowを表示し、第二のモードは、ライトのカリングプロセスを完全に無視してシャドウを再評価します。この最後のモードは、GPUキャプチャの特定のピクセルのシャドウ生成アルゴリズム(PCSSのような)のデバッグに特に役立ちます。

5.2 Visibility Slot
このビジュアライザーは、Shadow Tileごとに割り当てられたVisibility Slotの数を表示し、メモリバジェット分析に役立ちます。

5.3 Light Culling
このビジュアライザーは、各ライトのカリングステップの結果と、ライトがどのリストの一部であるかをプレビューします。これは、2つのライトリスト(Early Light List bufferとFinal Light List Buffer)の生成で多くの問題が発生する可能性があるため、診断に役立つ貴重な表示です。便利な機能は、シャドウ タイルのピクセルが範囲内にあるかどうかをチェックし、その結果が実行されたカリング テストと一致するかどうかを確認することによって、誤ってカリングされたライトを検出する機能です。

5.4 Light Count
アーティストにもプログラマーにも便利なこのビジュアライザーは、様々なTiled Deferred Shadowフェーズにおいて、Shadow Tileごとに検出されたライトの数を表示します。特に、近似(セクション2.2)と正確(セクション2.3)フェーズの間のライトカウントの差を表示するモードは、それが最も弱い場所を強調表示します。

6 Conclusion
我々はTiled Deferred Shadowシステムを実装し、標準的なシャドウのパフォーマンスを向上させました。また、使用可能な予算に基づいて数を制限することによって管理される追加コストで、キャラクターのHigh-Quality SHadowをサポートすることができます。次に、シャドウマップのセルフシャドウの問題を簡単に処理するためのOriented Depth Biasテクニックを紹介しました。最後に、Tiled Deferred Shadow問題の診断に役立つビジュアライザーを紹介しました。
7 Acknowledgements
この規模のゲームの開発には、多くの熱心な個人の協力が必要です。開発中に頼りになったレンダリングコードと知識の基盤を提供してくれた本多圭さんに感謝します。また、マネジメントをサポートしてくれた春日秀行氏、新機能の検討を許可してくれたビジネスユニット3チーム、このドキュメントに対する建設的なフィードバックをくれた先進技術部門のグラフィックスメンバーにも感謝します。最後に、この貴重な芸術的フィードバックをくれたLouis-Philippe Sanshagrinと、彼女のドキュメント編集をしてくれたHeather Lee Millsに感謝したいです。
References
[1] W. Bart. Cull that cone! Improved cone/spotlight visibility tests for tiled and clustered lighting. Apr. 2017. url:https://bartwronski.com/2017/04/13/cull- that- cone (visited on 06/01/2023).
[2] Bo Li. “A Scalable Real-Time Many-Shadowed-Light Rendering System”. In: ACM SIGGRAPH 2019 Talks. SIGGRAPH ’19. Los Angeles, California: Association for Computing Machinery, 2019. isbn: 9781450363174. doi: 10.1145/3306307.3328167. url: https://doi.org/10.1145/3306307.3328167.
[3] R. Nathan. Depth Precision Visualized. NVidia. July 2015. url: https://developer. nvidia.com/content/depth-precision-visualized (visited on 06/02/2023).
[4] Ola Olsson, Markus Billeter, and Ulf Assarsson. “Clustered Deferred and Forward Shading”. In: Proceedings of the Fourth ACM SIGGRAPH / Eurographics Conference on High-Performance Graphics. EGGH-HPG’12. Paris, France: Eurographics Association, 2012, 87–96. isbn: 9783905674415.
[5] W. Steven et al. Common Techniques to Improve Shadow Depth Maps. Microsoft. Sept. 2020. url: https : / / learn . microsoft . com / en – us / windows / win32 / dxtecharts / common-techniques-to-improve-shadow-depth-maps (visited on 06/02/2023).
Glossary
Closeup Shadowmap
高品質シャドウ技術で使用されるシャドウマップ。通常のシャドウマップと同様に動作しますが、より優れた解像度の精度を得るために、ビューはライトの視野全体ではなく、1つの対象物に再構築されます。
Compute Work Unit
GPUの速度は、複数のデータに対して一連の命令をロックステップで並列実行することで得られます。コンソールでは、64スレッドが並列に実行され、互いに素早くデータを交換することができます。
Early Light List buffer
シャドウタイルごとに有効なライトのリストを格納するGPUバッファ。ライトは、シャドウテストを実行せずに、ライトの範囲内にピクセルがあるときに追加されます(エントリフォーマットについては図7aを参照)。
Final Light List Buffer
シャドウタイルごとに有効なライトのリストを格納するGPUバッファ。ライトは、ライトの範囲にピクセルがあるときに追加され、タイル全体が影になっている場合は除外されます(入力フォーマットについては図7bを参照してください)。
Froxel
タイル座標と近距離/遠距離の深度位置を使用してフルスタムのサブセクションを定義するフルスタムボクセルに与えられる名前。
Hiearachical Depth Buffer
GPUがアクセラレーションのために使用する特別な深度バッファ。ペアデプスバッファの1/8の解像度を持ち、関連する8×8ピクセルの最小および最大深度を含みます。
High-Quality Shadow
特定のオブジェクト(通常はキャラクター)に高品質な影を描くテクニック。クローズアップシャドウマップは、関心のあるオブジェクトのみに焦点を当てます。
Lane Operator
Compute Work Unitのスレッド間で高速なデータ共有を可能にするGPU命令。
Light Group
32個の連続したライトのグループ。ライト・マスク・エントリーで使用され、有効なライトのないグループを素早く破棄し、処理時間とメモリ読み込みを削減します(図4参照)。
Light Mask Entry
1024 個のライトと 32 個のライト・グループの有効性を保存するために使用される 132 バイトのメモリ・ブロックで、エントリごとに 1 ビットを使用します(図 4 を参照)。
Light SlotID
メモリバッファ内のタイルのライトリストの開始位置を計算するために使用されます。識別子は、初期ライト リスト バッファと最終ライト リスト バッファの両方で有効です。
Oriented Depth Bias
セクション4.2で紹介した新しい深度バイアス技法は、顔の向きを使ってテストされた深度にオフセットを適用します。
Percentage Closer Soft Shadows
シャドウテクニックは、シャドウマップの使用を拡大し、ライトのの半影を模倣したソフトシャドウを可能にします。ライトを遮るジオメトリの距離が長くなるにつれて、影はより拡散していきます。
Peter Panning
シャドウマップに大きな深度バイアスがかかっているため、オブジェクトが影から切り離されたように見えるアーティファクト(図18参照)。
Shadow Tile
Tiled Deferred Shadowの処理に使用されるタイル。コンソールのGPUの64スレッドのCompute Work Unitサイズを考慮して、タイルのサイズは8×8ピクセルです。
Shadowmap
光源から見た最も近い奥行きを記憶するテクスチャ。リアルタイムレンダリングで最も一般的な影のテクニックで使用されます。
Standard Shadowmap
ライトの影を生成するときに使用される従来のシャドウマップ。
Tile
GPUでのコンピュートシェーダー処理用にグループ化された2D連続ピクセル。
Tile Group
GPUでのコンピュートシェーダー処理用にグループ化された2D連続タイル。より高速な結果を得るためにタイルごとのライトの近似検索で使用され、ストレージスペースを削減するためにタイルグループライトマスクバッファで使用されます。コンソールの GPU の 64 スレッド Compute Work Unit サイズを考慮して、8×8 Tiles のグループを使用します。
Tile Group Light Mask Buffer
近似フェーズ後の各タイルグループのライトの可視性を格納するGPUバッファ(エントリ形式は図4を参照)。
Tile Light Mask Buffer
各タイルのライトの可視性を格納するGPUバッファ。8×8ピクセルのシャドウタイルとは異なり、これらのタイルは32×32ピクセルで、バッファに入力する際のCPU負荷を軽減しています(図4と図5を参照)。
Tile Light SlotID Buffer
近似フェーズで割り当てられた後の各シャドウタイルのライトSlotIDを格納するGPUバッファ。
Tiled Deferred Lighting
ライティング計算とサーフェスマテリアル計算を分離したレンダリング技術。これは、GBuffersと呼ばれる中間テクスチャにマテリアルパラメータを格納し、Tilesワークユニットでライティングを処理することで行われます。
Tiled Deferred Shadow
ライティングからシャドウの計算をさらに削除し、シャドウタイルワークユニットで処理することで、Tiled Deferred Lightingを拡張するレンダリング技術。
VGPR Pressure
シェーダーは、計算の複雑さが最も重くなるポイントに対応するために、十分なレジスタを確保する必要があります。この数値を下げることで、実行を待つCompute Work Unitの数を増やします。これにより、メモリロードを待つ際に保留タスクに切り替えることで、メモリアクセスレイテンシを隠すことができます。
Visibility Slot
シャドウタイルの各ピクセルの1つのライトの可視性を格納するメモリブロック。ピクセルあたり8ビットを使用して、ライトの半影にシャドウグラデーションをつけます。
Visibility Buffer
特定のライトに対するシャドウタイルの各ピクセルのライトの可視性を格納するGPUバッファ。ライトが完全にライティングされるまたはライティングされない場合、このバッファにエントリは割り当てられません。
zBin
錐台は1024の均一な深度範囲に分割され、それに交差する最初と最後のライトインデックスを保存するzBinが作成されます(図2a参照)。
zBin (ranged)
連続するzビンの特定の範囲と交差する最初と最後のライトインデックスを含む(図2b参照)。
zBin Buffer
zBinとzBin(ranged)のエントリを格納するGPUバッファ。