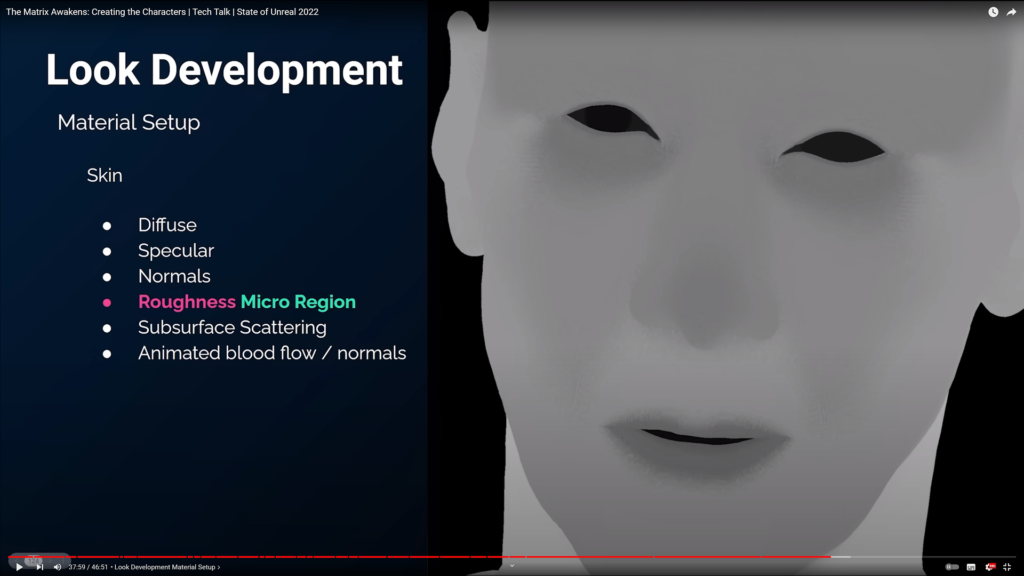
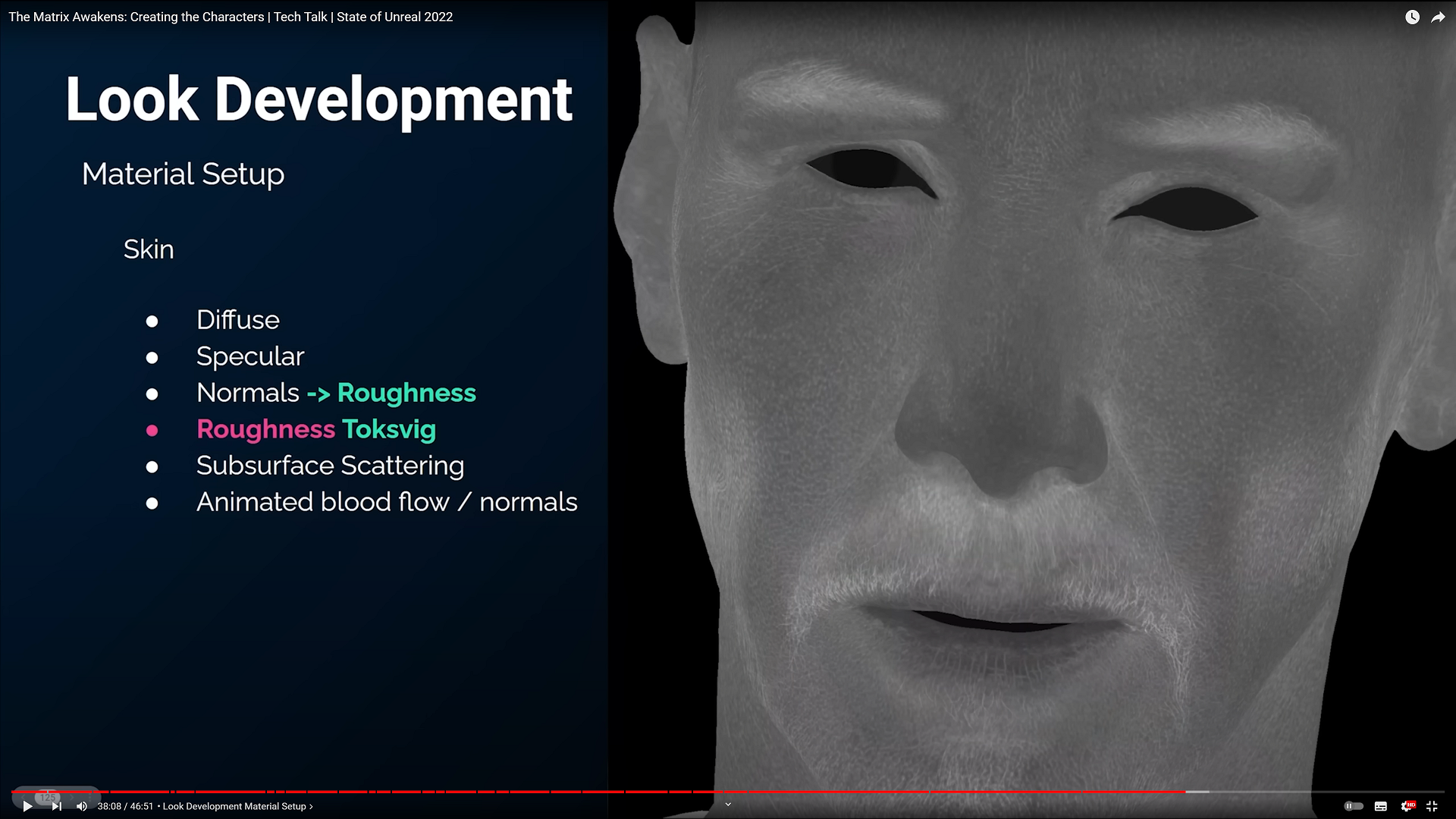
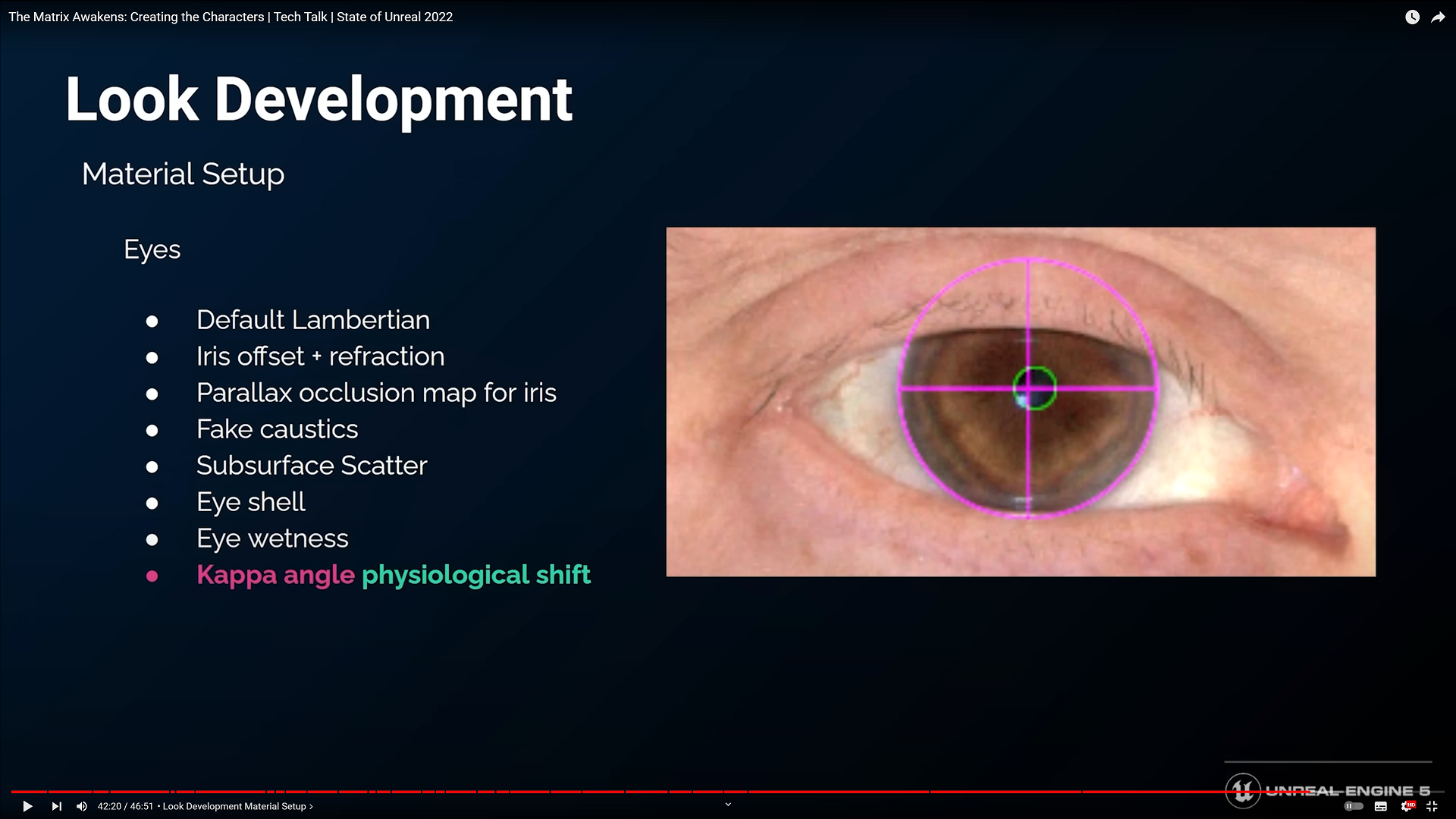
こんばんわ、Pocolです。
仕事が忙しすぎて、全然最近論文が読めていないです。
年末・年始の時間を使って、今年の論文を見ておきたいなーと思ったので,メモを随時追加しておくことにします。
SIGGRAPH 2025
・Spherical Lighting with Spherical Harmonics Hessian
岩崎先生と土橋先生のやつ。
・Bernstein Bounds for Caustics
コースティクスが気になったので…。
・WishGI: Lightweight Static Global Illumination Baking vis Spherical Harmonics Fitting
メモリ削減がかなりできるらしい。
・Segment Based Light Transport Simulation
蜂須賀先生が共同著者にいるやつ。頂点ベースではなくセグメントベースで光輸送を計算する新しいレンダリング手法っぽい。
・Histogram Stratification for Spatio-Temporal Reservoir Sampling
画像をみる感じだと良さげ。
Eurographics 2025
・Fast Sphere Tracing of Procedural Volumetric Noise for Very Large and Detailed Scenes
スフィアトレーシングの高速化の話っぽいので,雲とかのレンダリングの高速化に使えるかも。
・Physically Based Real-Time Rendering of Eclipses
日食の物理ベースレンダリングで、画像がかっこいい。大気の話も含んでいるかもしれないので、あとで確認。
・Dynamic Voxel-Based Global Illumination
あまり良くはなさそうだが、アイデアがもらえるかもしれないので見る。
I3D 2025
・Aokana:A GPU-Driven Voxel Rendering Framework for Open World games
メモリ使用量が従来の1/9で,レンダリング速度が最大4.8倍速くなるらしいので、要チェック。