こんにちわ。Pocolです。
今日は,先日発表された
[Karis 2021] Brian Karis, Rune Stubbe, Graham Wihlidal, “Nanite A Deep Dive”, SIGGRAPH 2021 Advances in Real-Time Rendering in Games Course.
の資料を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けるとありがたいです。
また,図はすべて[Karis 2021]から引用しています。

こんにちは、私はEpic Gamesのエンジニアリング・フェロー、Brian Karisです。
今日はUE5の新しい仮想ジオメトリシステムであるNaniteについて深く掘り下げてみたいと思います。

これまでに手がけたものを振り返ってみると、最も大きなインパクトがあったのは、アートの作り方を根本的に変えたものでした。
何年も前に、バーチャルテクスチャリングシステムがアートチームに与える影響を目の当たりにしました。
巨大なテクスチャを好きなように使えて、メモリの予算を気にする必要がないというのは、アーティストにとって非常に自由なことでした。
それ以来、私はジオメトリにも同じことができる日を夢見てきました。
そのインパクトはもっと大きいものになるでしょう。
ジオメトリに対するバジェットなくなるということは
懸念もなくなります。
ポリゴン数、ドローコール、メモリの心配がなくなります。
このような制限がなければ、アーティストは映画用のクオリティーの高いアセットをリアルタイムに最適化することなく、そのまま使用することができます。
アートコンテンツをフレームレートに合わせて最適化するために、どれだけの時間を無駄にしているかは馬鹿げています。
これは、セットドレッシングにも言えることです。
アーティストは以下のことができるはずです:
好きなだけのメッシュを好きなように配置することができます。
シーンをどのように構築するかは、アーティスト次第です。
そしてもちろん、これらはすべて、品質を損なうことなく実現されます。
速く実行するができても、アーティストが最初に作ったものと同じように見えなければ意味がありません。
——
Bonus:
ゲームが発売されると、アートチームは大量の作品をartstationに投稿しますが、投稿されたものの多くは、自慢のモデルのハイポリやオフラインレンダリング画像ですが、プレイヤーがそのような姿を見ることがないというのは、何とも悲しいことです。
数年前に、オフラインで映画を制作していたアーティストが、最後の短編映画のプロジェクトでリアルタイムレンダリングとUnrealを試していたという興味深い話を聞いたことがあります。
彼の話によると、レンダリング時間を何度も繰り返すことで膨大な時間を節約できたものの、アセットをリアルタイムに最適化するために余分な作業が必要となり、すべてが無駄になってしまったそうです。
制作現場では、最新の優れたレンダリング技術でピクセルを表現することよりも、お金と時間がクオリティを制限する要因となります。
アートをより効率的にし、アーティスティックなビジョンをより直接的に表現できるようにしたり、プロセスが難解な技術的なものでなくなることで、より多くのアートチームがより積極的に貢献できるようになれば、大きな利益を得ることができます。
私は、業界として、忠実度の高いゲームをいかに安く作るかにもっと取り組むべきだと思っています。

実際には、仮想テクスチャよりもはるかに困難な作業です。
単なるメモリ管理の問題ではないからです。
ジオメトリのディテールは、テクスチャとは異なり、レンダリングコストに直接影響します。
また、ジオメトリはテクスチャのように3次元的にフィルタリングできるわけではありません。

では、どのような選択肢があるのでしょうか?

ボクセルと陰影曲面には多くの潜在的な利点があり、この問題を解決するために最も議論されている方向性です。
これは2Mポリゴンの胸像です。
13MのナローボクセルとSDFボクセルにリサンプリングしたものです。
空のボクセルが保存されていないというスパース性をすでに考慮していますが、それでも6倍のデータ量では汚れているように見えます。
この理由は、ボクセル化はユニフォーム・リサンプリングの一形態であり、ユニフォーム・リサンプリングは損失を意味するからです。
これは、ベクターグラフィックスをピクセルグラフィックスに変換することに相当する3Dです。
この例のスカルプトされたスキンのように、有機的で均一にサンプリングされたメッシュの場合、リサンプリングはあまり破壊的ではありません。
一方、ハードサーフェスのモデリングでは、ご覧のように非常に多くのことができます。
つまり、ボクセルの最大の問題はデータサイズの問題です。
データサイズを小さくするためには、最大限のスパース性が必要ですが、そのためにレイキャスティングのパフォーマンスを犠牲にすることはできません。
そして、データ構造は、シャープなエッジを得るために極めて適応的である必要がありますが、滑らかなところでサンプルを無駄にしてはいけません。
このようにしても、保存されている最も細かい解像度は、オーサリングされたものではありません。
何をリサンプリングするにしてもです。
オリジナルのメッシュも保存しておいて、十分に近づいたらそれを描画する必要があるのでしょうか?

次のようなことも重要です;
我々は、すべてのCGワークフローを完全に変えることに興味はありません
どこかでオーサリングされたメッシュのインポートをサポートする必要があります。ジオメトリがどのようにオーサリングされるかについては、我々は制御できません。
それらのメッシュにはUVやタイリングのディテールマップがあります。
UVマッピングはアーティストには嫌われていますが、サーフェイスにプロシージャルなテクスチャリングを行うには非常に強力なツールです。
ボクセルカラーはその代わりにはなりませんし、トリプラナープロジェクションも使えません。
我々が求めているのはメッシュの置き換えであり、テクスチャやマテリアル、それらのオーサリングに関連するすべてのツールの置き換えではありません。
それを踏まえた上で
UV付きボクセル?
ありかもしれませんが、UVの継ぎ目をどうしますか?
などなど、数え切れないほどの問題を抱えています。
ボクセルよりも薄くなると符号付き距離フィールドとして消えてしまうフィーチャー
数ボクセル以下になると片側から反対側にアトリビュートがリークしたり
また、それらをどのようにアニメーション化するか
これらはすべて可能かもしれませんが
私の結論は、明示的なサーフェスを完全に置き換えるには、長年の研究と業界での経験の複合が必要だということでした。
私たちはまだそこに到達していませんし、仮に到達したとしても、それがより良いものになるかどうかは不明です。

細分割曲面はどうでしょうか?
無限に滑らかになりますよね?
サブディビジョンの定義は増幅のみ
近くで見る分にはいいですが
ベースケージより単純になりません
私はアーティストと話をして
ケージは典型的なゲームのローポリよりも高いことが非常に多いです。
映画では桁違いに悪いですね。
レンダリングコストから切り離されたアーティストのオーサリングの選択肢が必要です。

ディスプレイスメントマップはどうでしょうか?
現在の法線マップのように、ディスプレイスメントを捉えることができます。
ベクトル変位があれば、ローポリはさらに低くなりますよね?
場合によってはそうですね。
しかし、右の画像のようなチェーンの場合、ローポリはどれくらいになるでしょうか?
しかし、右の画像のようなチェーンのローポリはどうでしょうか?
置換ではサーフェスの種数を高めることができないので、実際にはできません。
つまり、球体を変位させてトーラスにすることはできないのです。
また、法線マップや変位マップへの投影は、均一なリサンプリングの一種です。
既に均一にサンプリングされている有機的な表面にはとても効果的です。
しかし、アーティストが慎重にコントロールしないと、硬い表面の特徴を破壊してしまうことがあります。
近づいて増幅するには最適ですが
一般的な単純化には適していません。
——
Bonus:
ジオメトリ画像は、基本的には他の面ではなく原点を基準としたベクトル変位マップのようなものです。
上記の問題はすべて同じです。
そもそもサーフェスが閉じていなければ、技術的には種数は何でもよいのです。
外周部を任意につなぎ合わせて異なる種数を作ることができます。これはGIMのオリジナル論文で使用されていますが、テクスチャが伸びてしまうため実用的ではありません。
また、これは実際には変更とはみなされません。

ポイントベースドレンダリングはどうでしょうか?
ポイントは超高速でスクリーンに吹き付けられます。
しかし、大量のオーバードローを受け入れない限り、ポイントは穴埋めを必要とします。
あるべき小さな隙間と、埋めるべき穴の違いをどうやって見分けるのでしょうか?
余分な接続データがなければ、確実に知ることはできません。三角メッシュのインデックスバッファとも呼ばれています。
——
Bonus:
この分野は、私が探求していた頃には今ほど普及していなかったMLに適しているようです。デノイジングは離散データの補間の一種であり、抽象的にはこの問題とよく似ています。
接続性を保証することはできませんが、訓練されたNNは、少なくとも最小化の文脈では、実際には十分に機能し、信頼できるでしょう。
しかし、接続性を必要とする最大化を解決することはできないので、少なくとも解の一部はメッシュである必要があります。

私は非常に長い時間をかけて他の選択肢を検討しましたが、我々の要求に応えるためには、トライアングルよりも高品質で高速なソリューションはありませんでした。
他の表現方法にも良い用途はありますが、三角形はNaniteの中核をなすものです。
これらの他の表現の美学に基づいてアートスタイルを構築し、その長所と短所を受け入れることができれば、非常に価値のあるものになりますが、Unreal はアートスタイルを押し付けることはできません。

三角形を扱うのであれば、最先端の三角形レンダリングパイプラインを構築するには何が必要でしょうか?
目新しさはありませんが、まずは最先端の技術を確立し、Unreal をそれに近づけていきましょう。
数年前に、Unreal のレンダラーはリテインドモード設計にリファクタリングされました。
私たちはこれを拡大してきました。
シーンの完全なバージョンがビデオメモリに保存され、フレームを超えて持続します。
物事が変わったときには,離散的に更新されます。
また、すべてのNaniteメッシュデータは単一の大きなリソースに格納されています。
つまり、そのためにバインディングレスのリソースを必要とせず、一度に任意のものに触れることができるのです。
これらは、GPU駆動のパイプラインに必要な構成要素です。
各ビューに対して、1回のディスパッチで可視化されたインスタンスを決定することができます。
そして、奥行きのみを描画する場合は、1つのDrawIndirectですべての三角形をラスタライズすることができます。

今ではGPU駆動のメリットをすべて享受していますが、見えない三角形のためにかなりの作業をしています。
そこで、トライアングルクラスターカリングを追加して、不要な作業を削減します。
そのためには、三角形をクラスターにまとめ、それぞれのクラスターに対してバウンディングボックスを作ります。
そして、その境界線に基づいてクラスタをカリングします。
——
Bonus:
クラスターカリングは[40]や[41]でよく知られていますが、このアイデアは、少なくとも1996年[37]にさかのぼります。

オクルージョンカリングだけでなく、フラスタムに対するカリングも行っています。
コーンベースのバックフェイスカリングは、ほとんどすべてのバックフェイスクラスターがオクルージョンカリングされているため、通常は意味がないことがわかりました。
オクルージョンカリングは、HZBと呼ばれる階層的なZバッファーに対して行われます。
バウンドからスクリーンの矩形を計算し、矩形が4×4ピクセルになる最低のミップを見つけ、オクルージョンかどうかをテストします。
——
Bonus:
このテストは[39]と同じです。
最も近い深度だけではなく,バウンディングボックスの深度勾配を使用することで改善が見られましたが,現在は使用していません.

OK、でもどうやってテスト用のHZBを手に入れるのでしょうか?
まだ何もレンダリングしていません。
いくつかのゲームでは、前のフレームのZ-Bufferを現在のフレームに再投影を試みます。
これは常に近似値であり、保守的なものではありません。

しかし、そこにある核となる仮定は良いものです。
前のフレームで見えていたものは、今回のフレームでも見えている可能性が高いです。
つまり、深度バッファで表現される前フレームの見えている面は、オクルーダーに適しているということです。
しかし、デプスバッファにレンダリングしたジオメトリを再投影できるのに、なぜデプスバッファを再投影しようとするのでしょうか?
そのため、我々は前のフレームで見えていたと判断したものを描画し、それを使って新しいものをオクルードします。
これは2パスのオクルージョンカリングです。
- 前のフレームで見えていたものを描画する。
- そこからHZBを作る。
- HZBをテストして、前のフレームでは見えなかったが今は見えているものを判断し、新しいものを描画する。
これで、最先端のトライアングル・レンダリング・パイプラインが完成したことになります。次は?
明らかに、深度オンリーパスよりも多くのレンダリングを行いたいと考えています。
——
Bonus:
私が知っている最初のGPU駆動のオクルージョンカリングは、「March of the Froblins」[38]です。
私が知っている最初の2つの過去のオクルージョンは、「Patch-based Occlusion Culling for Hardware Tessellation」[19]のものです。

深度だけを追求するのではなく、マテリアルもサポートしたいと考えた場合、多くの選択肢があります。
しかし、私たちは、視認性とマテリアルを切り離すオプションを希望します。
つまり、ピクセルごとに可視性を決定すること(深度バッファ付きラスタライズが行うこと)が、マテリアルの評価から切り離されるということです。
これらを満たす選択肢はいくつかあります。
オブジェクトスペースのシェーディングは、次のような形で行われます。
REYES あるいは
テクスチャ空間
しかし、どのような形のオブジェクト・スペース・ソリューションであっても、通常は4倍以上の大幅な差があります。
キャッシングによるオーバーシェードコストの解決は非常に魅力的でしたが
ビュー依存
アニメーション
そして 非UVベース
マテリアルがあまりにも普及しているため、それらに対応していないものでレンダリング基盤を構築することはできません。
もう一つの選択肢は、ディファードマテリアルです。

具体的に言うとビジビリティバッファの形式が我々にとって最良の選択でした。
ここでの基本的な考え方は
最小限のジオメトリデータを、深度、InstanceID、TriangleIDの形でスクリーンに書き込むこと。
次に、ピクセルごとにマテリアルシェーダを書き込みます。
ビジビリティバッファをロードする。
トライアングルデータを読み込む。
3つの頂点の位置をスクリーンに変換する。
それらを使って、このピクセルの重心座標を導出し
そしてその座標をもとに、頂点の属性を読み込み、補間します。
——
Bonus:
用語の説明ですが、ディファードマテリアルやディファードテクスチャの多くに「ビジビリティバッファ」という言葉を使っている人がいますが、個人的には、最小のデータフォーマットである「オブジェクトID」と「トライアングルID」の形式のみを「ビジビリティバッファ」と考えています。
ただ、三角形の重心座標を追加しても同じことだと、一つだけ譲歩するかもしれません。
UVや法線のような頂点の属性をスクリーンバッファに保存することは、もはやビジビリティバッファではありません。それらを私はディファードテクスチャリングと呼んでいます。

クレイジーなことに聞こえるかもしれません?
でも、思ったほど遅くはありません。
キャッシュがたくさんヒットします。
オーバードローやピクセルクワッドの非効率性もありません。
一般的にビジビリティバッファのアプローチは、マテリアルの評価とシェーディングを組み合わせたものです。
しかし、ここではG-Bufferに書き込んでいます。
これは、他のディファードシェーディングレンダラーと統合するためです。
遅延方式を採用する理由はまだありますが、ここでは触れません。
これで、すべての不透明なジオメトリを1回のドローコールで描画できるようになりました。
完全にGPU駆動です。
デプスプリパスだけに限りません。
CPUコストは、シーンやビュー内のオブジェクト数に依存しません。
マテリアルはシェーダーごとに描画されますが、オブジェクトに比べてはるかに少ない数です。
また、三角形のラスタライズがビューごとに1回で済むのも便利で、オーバードローを減らすための複数のラスタライズパスは必要ありません。

以前よりもはるかに高速になりましたが、インスタンス数とトライアングル数の両方にリニアにスケールするままです。
インスタンスのリニアスケールは、少なくとも、自分の周りにロードしたいレベルのスケールの制限内であれば大丈夫です。100万個のインスタンスを簡単に扱うことができます。
トライアングルのリニアスケーリングはOKではありません。リニアスケーリングでは、「どれだけ投げても動作する」という目標を達成できません。
レイトレーシングはLogNで、これはいいことですが、十分ではありません。
十分な速度でレンダリングできたとしても、これらのシーンのすべてのデータをメモリに収めることはできませんでした。仮想化されたジオメトリは、メモリに関する部分もあります。
しかし、レイトレーシングでは、たとえメモリに収まったとしても、我々のターゲットには十分な速度ではありません。
logN以上の速度が必要なのです。
——
Bonus:
O(log n)とO(1)の理論上の効率の違いは、実際には重要ではありません。10k個の三角形から1M個の三角形になると、ツリーのレベルが43%増加します。
問題は big O がメモリアクセスを無視していることです。仮に追加のALUコストが無料だったとしても、キャッシュミスは無料ではありません。
三角形がサブピクセルになると、レイは事実上インコヒーレントになり、レベルが上がるごとにキャッシュミスが発生します。
メモリの帯域幅は頼るには良いベクトルではありません。

逆に考えれば、画面上のピクセル数は限られています。なぜ、ピクセルよりも三角形を多く描かなければならないのでしょうか?
クラスターに関しては、オブジェクトの数や密集度に関わらず、毎フレーム同じ数のクラスターを描きたいと考えています。
完全であることは現実的ではありませんが、一般的に、ジオメトリのレンダリングコストは、シーンの複雑さではなく、スクリーンの解像度に応じて変化するべきです。
つまり、シーンの複雑さに応じて一定の時間がかかり、一定の時間は詳細度制御を意味します。
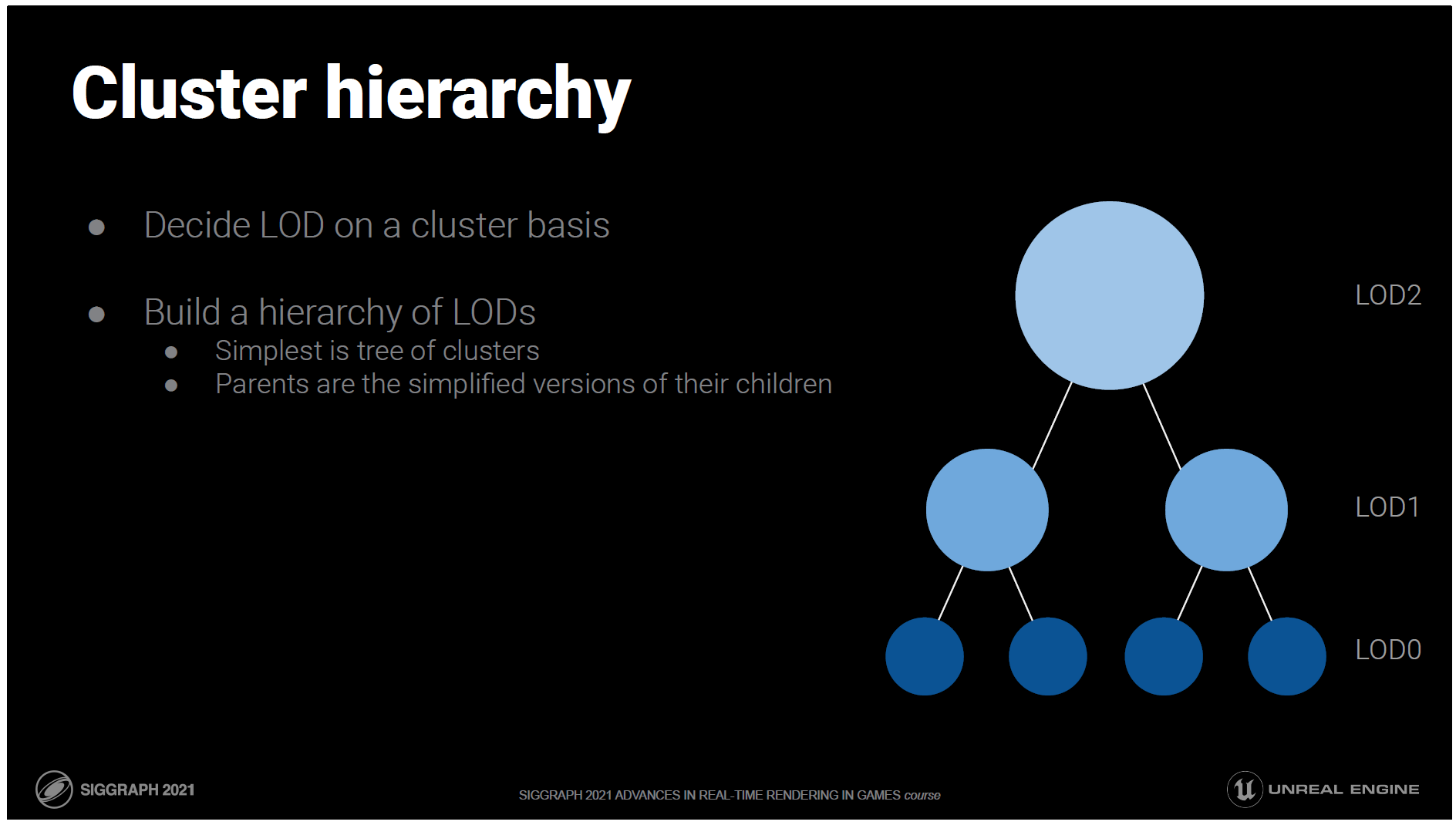
クラスターの階層を構築すれば、クラスターでも詳細度制御が可能です。
最も基本的な形としては、親が子の簡略化されたバージョンであるクラスターのツリーを想像してください。
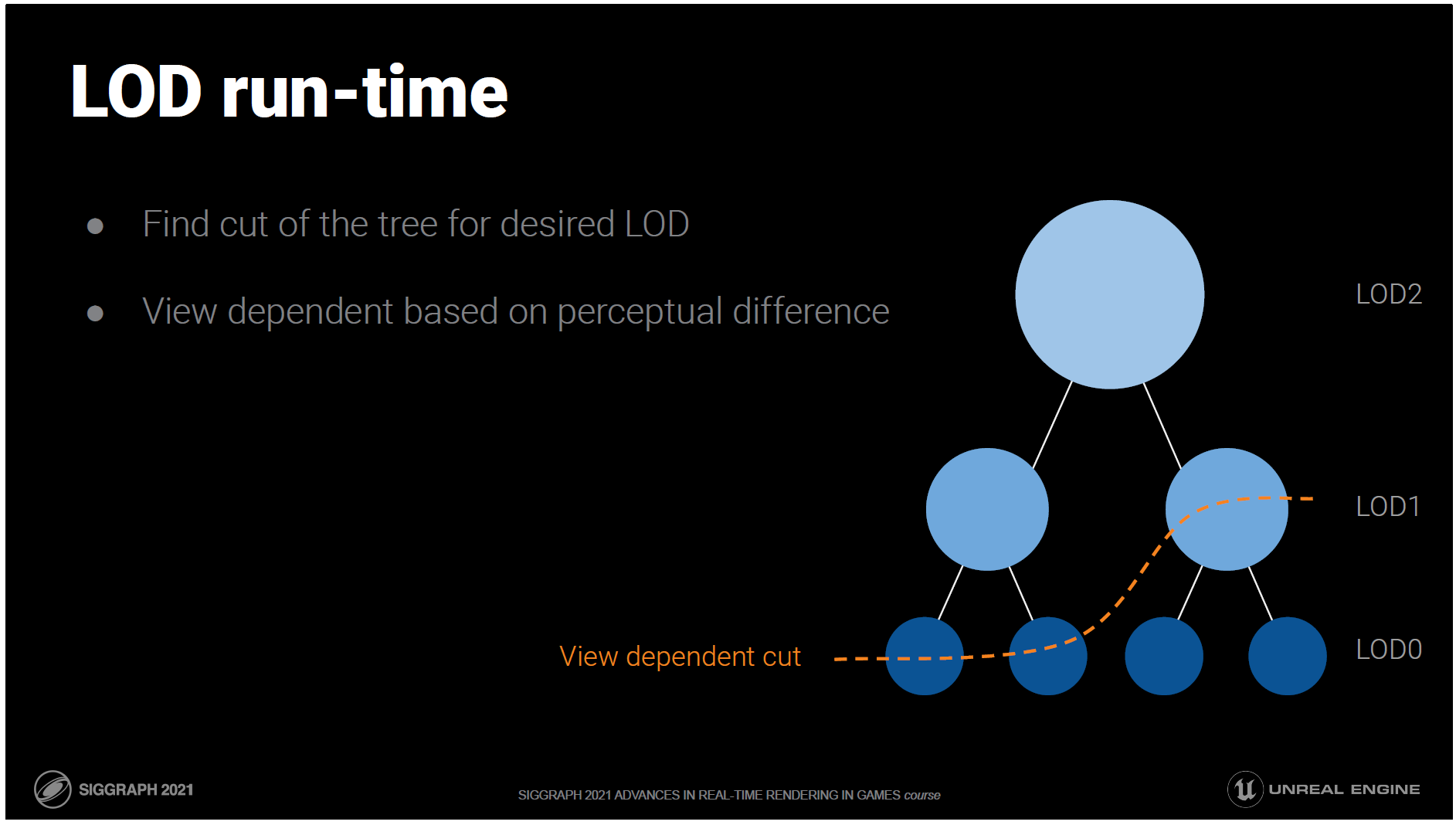
実行時には、希望のLODに合致するツリーのカットを見つけます。
つまり、同じメッシュでも、必要に応じて異なる詳細度レベルにすることができるのです。
これは、クラスターのスクリーンスペースの投影誤差に基づいて、ビューに依存した方法で行われます。
この視点から見て違いが分からないと判断された場合、親は子の代わりに描画されます。
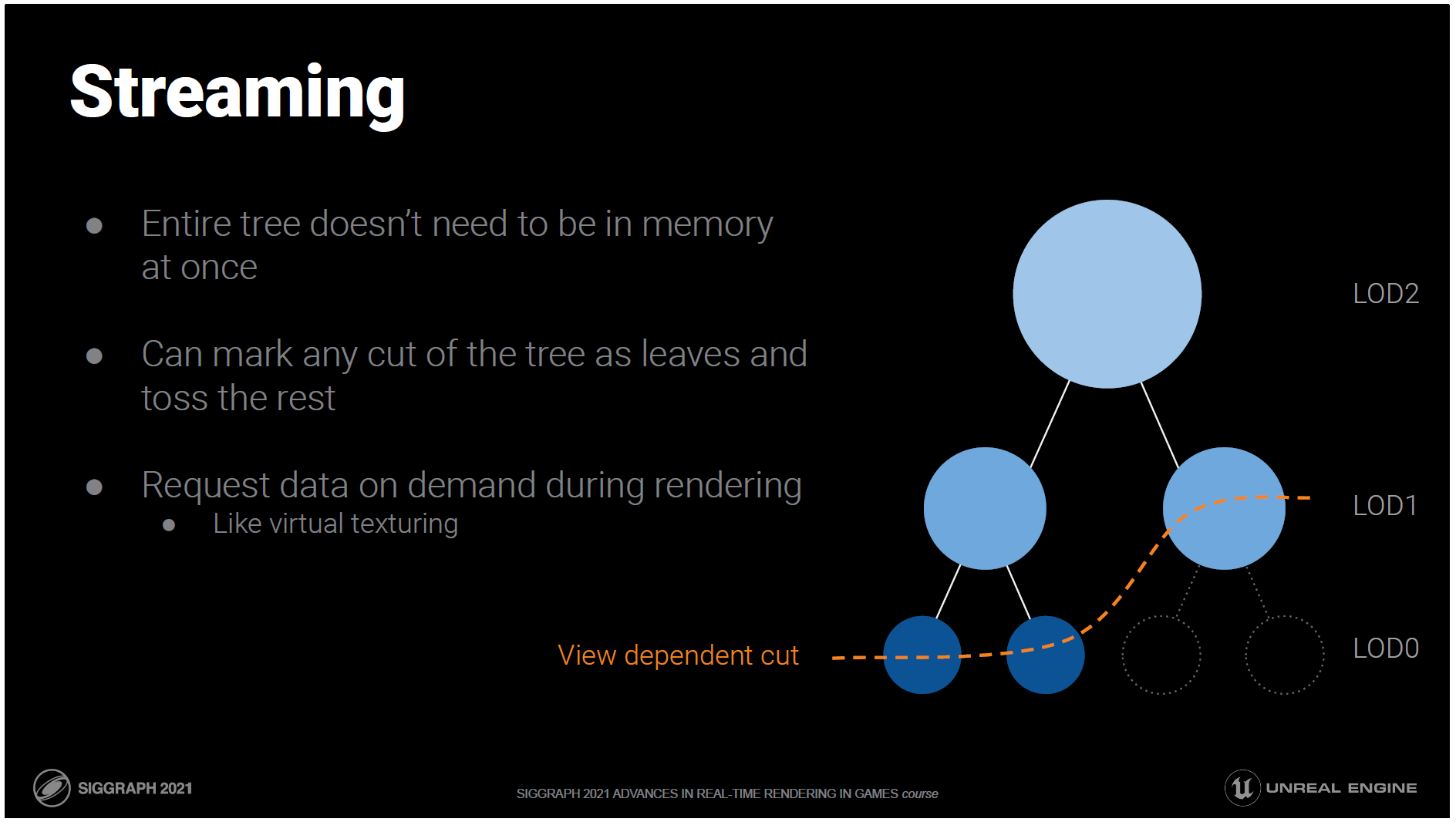
これで、仮想化ジオメトリの仮想化部分を実現するのに必要なものが揃いました。
ツリー全体を一度にメモリーに入れてレンダリングする必要はありません。
どの時点でも、木の一部分を葉としてマークし、それ以降の部分をRAMに保存しないことができます。
仮想テクスチャリングのように、必要に応じてデータを要求します。
子が常駐しておらず、欲しい場合はディスクからリクエストされます。
子が常駐しているが、しばらく引き出されていない場合は、それらを退避させることができます。

しかし、この単純化されたアイデアは、実際にはクラックのために機能しません。
クラックは、独立したクラスターが異なるLODを決定し、その境界のエッジが一致しなくなったときに発生します。
この問題に対するナイーブな解決策は、単純化の際にクラスター間で共有される境界エッジをロックすることです。
これにより、独立したクラスターの境界が常に一致するようになり、境界が変更されないようにすることができます。
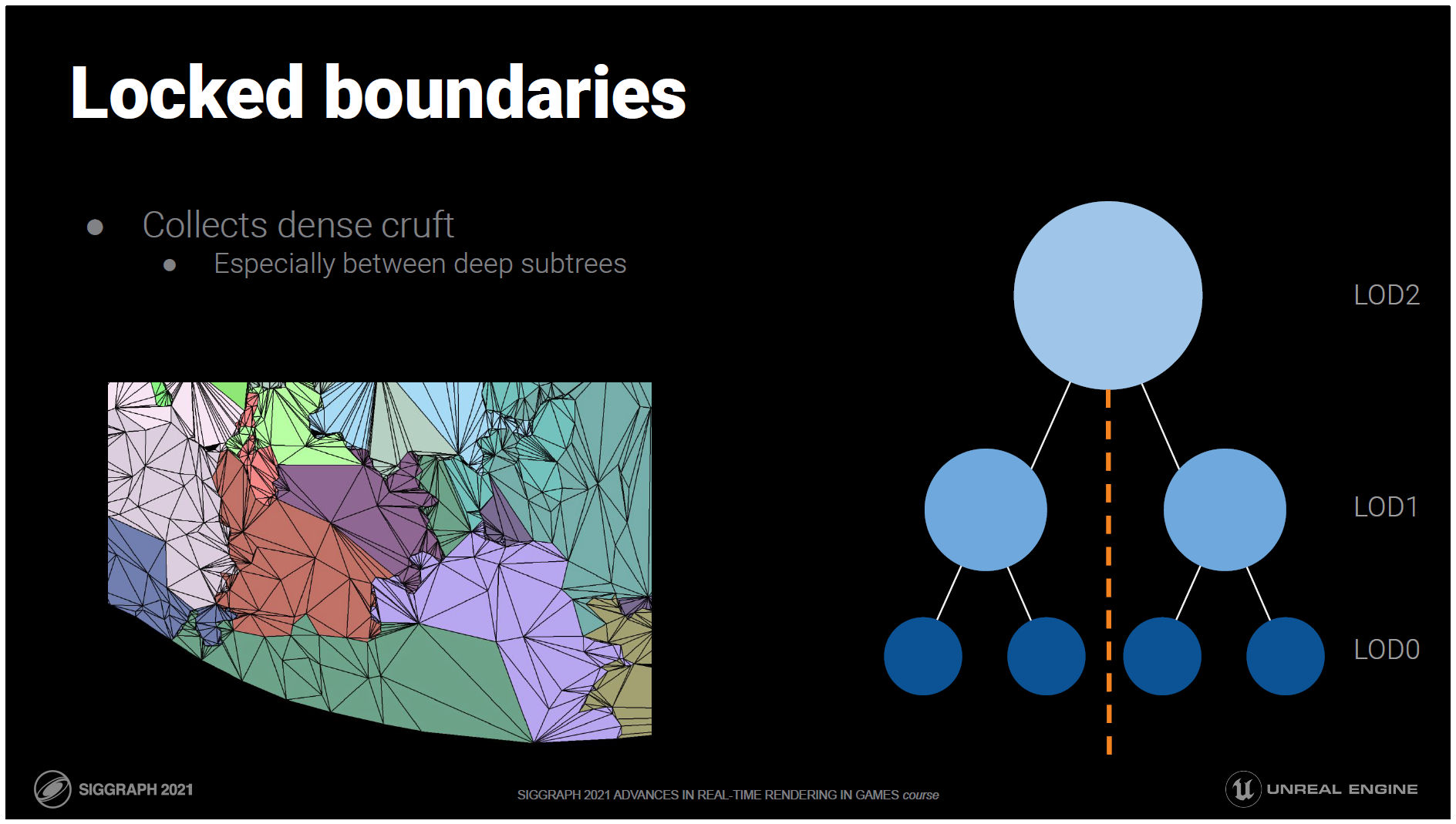
しかし、これでは同じ境界が何階層にもわたって続き、そこに三角形のひどい結果が密集してしまうため、うまく機能しません。
階層の多くのレベルでエッジを交差させずに線を引くことができれば、ロックされる境界を見つけたことになり、エッジを交差させないすべてのレベルで簡素化されることはありません。
バランスツリーでは、LOD0からルートまでの真ん中にこのような線を引くことができます。
しかし、サブツリー間の境界には多くのひどい結果があり、レベルごとにトライアングルを半分にすることもできず、完全に壊れてしまいます。
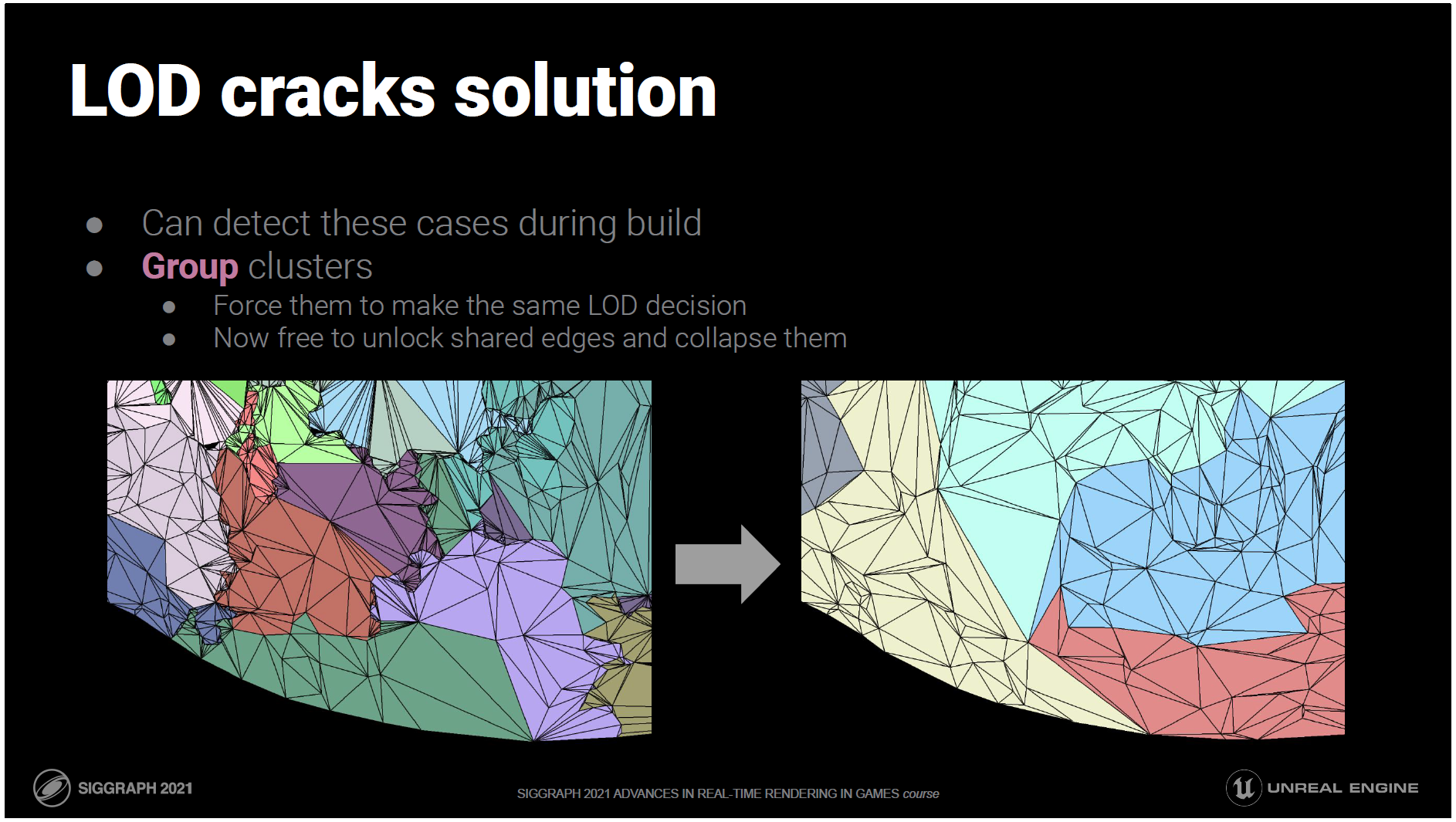
ありがたいことに、これらのケースはビルド中に検出できます。
クラスタをグループ化して、レベルのLODを同じように決定させることができます。
これにより、クラスターは独立した存在ではなくなります。
クラスタが常に同じLOD決定を下すのであれば、ミスマッチは起こりません。
クラックは隣接するクラスター間のレベル差から発生するので、レベル差がなければクラックが発生する可能性はありません。
これで、クラスター間で共有されているエッジを解除して、内部のエッジと同じように単純化の際に折りたたむことができるようになりました。
もちろん、1つのレベルですべてのクラスターをグループ化することはできませんし、昔のような離散的なLODに戻ってしまいます。そのため、必要な場所だけクラスターをグループ化する必要があります。

これは、複数のレベルでの概念的な視覚化です。
これらの線はグループの境界を表しており、グループの単純化の際にロックされるエッジを意味しています。
レベル0からの開始します。

重要なアイデアは、異なるクラスターをグループ化することで、グループの境界をレベルから交互に変更することです。

レベル1になりました。

あるレベルでは境界であるものが、次のレベルでは内部になります。

レベル2です。

つまり、境界線上でロックされたエッジは、同じ境界線ではないため、何段階にもわたってロックされたままにはなりません。
そのため、ひどい結果をを集めることができません。あるレベルではロックされ、次のレベルではロックが解除されます。

詳細を説明する前に、私はこのクラック問題の解決策として、他にも多くの可能性を考えました。
私の親友であるJimmy Shinは、新しい設計空間を開拓するときには、その領域のマップを作ってみることが有効だと教えてくれました。
可能性のある空間を、すべての選択肢が存在し、それらの選択肢が互いに関連してどこに存在しているのか、連続したものとして視覚化するのです。
たとえその選択肢がまだ自分の目に見えていなくても、自分が知っている選択肢の間の関係は、何かが存在しなければならないマップの穴を示しているかもしれません。
その結果、自分自身のアイデアが浮かんだり、研究の方向性が示されたりして、参照された論文を直接リンクすることでは見つけられなかった解決策が見つかるかもしれません。
これは、この問題を探る際に形成したマップをまとめたものです。仮想化されたジオメトリのマップ全体は、はるかに、はるかに、大きい。
直接的なVDPMの手法はすべて、個々のトライアングルやエッジに作用します。
その粒度でストリーミングを通信しています。その粒度での編集は、データサイズもかなり大きくなります。
細かい粒度とは、エラーのしきい値に達するまでのトライアングルの数が最適であることを意味しますが、それは究極のゴールではありません。
トライアングルのラスタライズはかなり高速に行うことができるので、レンダリングするための完璧なビュー依存メッシュを見つけるために時間やデータを費やしてしまうのは逆効果です。
スカートはテレインレンダリングの古典的な手法です。実際には、ボリューメトリックなデータ構造には穴がないので、ボリューメトリックなデータの代わりにB-REPを使うことができるという認識から生まれたものです。これにより、典型的な亀裂を伴わないT字型接続が可能になります。
ただし、任意のメッシュの場合は、あまり簡単ではありません。
まず、メッシュが体積演算できるような多様性と防水性を持っているかどうかは保証されていません。
第二に、たとえそうであったとしても、亀裂のないT字型接続は、異なる三角形分割が平面で終わる場合にのみ役立ちます。2.5次元地形の場合、タイルの角は固定されていますが、角と角の間のエッジに沿った頂点は、角から角へと続く垂直面から離れない限り、また角を越えない限り、自由に動けます。
3Dでは、拘束は平面になりますが、メッシュを切断しているボリュームのあるソリッド(ボックスや四面体など)の面内に拘束されるようになります。
キャップを最大分離のスカートだけにすることは、面内の複雑な2D境界問題となります。
これはすべてが複雑で、多くのクリッピングを必要とし、多くの余分な隠れたジオメトリを生成するため、境界のロックよりも効率が悪くなります。
[51],[58],[59],[60]

プログレッシブバッファやテトラパズルは、私が考える暗黙の依存関係のアプローチです。クラスタ間の依存関係は暗黙の了解であり、何らかの形で保存される必要はありません。
これは、ノードに関する何かが、その空間的な位置について暗黙的に知られていなければならないことを意味し、これが問題を引き起こします。
プログレッシブバッファの場合、ジオモーフィングは頂点ごとに計算されるため、1つのノードがあるレベルと別のレベルの両方に同時にマッチすることができます。
ジオモーフィングはデータと計算の両方にコストがかかるという事実を無視すると、1つのノード(クラスタ)がクラックなしに1LODにしか対応できないことになります。
これを保証するために、LODは常に厳密な距離バンドで適用され、ノードはその帯の幅よりも小さくなければならず、1つのノードが同時に2つ以上の帯に入ることはできません。
つまり、LODはノードの視覚的な誤差に基づくものではなく、適応的なものではないということです。
また、表面のある部分にLODが常駐していないと、バンドの要件に従えずに割れてしまうこともあります。
テトラパズルにはそのような問題はありませんが、他の問題があります。クラスタリングは純粋に空間的なものなので(どのテトラパズルに三角形が入るか)、クラスタあたりの三角形の数を制御することはできません。
1つの四面体に1つの三角形しか入らないということはあり得えるでしょうか?この制御の欠如によるラスタライザの無駄なレーンの量は、レンダリングの効率を非常に悪くしています。
一般的なメッシュにおける三角形の大きさや分布は均一ではありません。これは、あるレベルから次のレベルへの四面体のサイズが予想される体積単位でジャンプするからといって、それに対応する複数の三角形がそこに落ちるとは限らないということでもあります。
繰り返しになりますが、可能性は十分にあります。あるレベルのクラスターには、次のレベルでは新しい三角形が追加されないのに、2倍になることが期待されているのです。
[53], [56]
これは、私が取った方向性であり、私たちが主に築き上げた先行作品でもあります。
両者はある意味で表裏一体の関係にあり、私たちが行っていることは、この両者のハイブリッドであり、後ほど説明する追加的な洞察でもあります。
Batched Multi-triangulationは優れた理論的フレームワークですが、この論文は過度に抽象的で理論的であるため、非常に要約・理解しにくいと感じました。
QuickVDRを部分的に実装した後、何年か経ってからもう一度読み直してみたところ、複数のスキームのスーパーセットとしての洞察力の高さを実感しました。
このFedreico Ponchio氏の論文を読むことを強くお勧めします。https://d-nb.info/997062789/34 元の論文が最初は意味をなさない場合は
論文のスライドも参考になります。
http://vcg.isti.cnr.it/Publications/2005/CGGMPS05/Slide_BatchedMT_Vis05.pdf
構築ステップの内訳は、次にご紹介する基本的なものと同じですが、若干の調整が必要です。
先行する作業では、三角形をグループ化するので、グループごとに三角形の数が変わります。
しかし、私たちは128の倍数の三角形のグループを、ちょうど128のクラスターに分けられるようにしたいのです。
三角形ではなく、クラスターをグループ化することで、これが可能になります。

さて、ここではビルドの手順をご紹介します。
まず、リーフクラスターを構築する必要があります。
ここでは、128個の三角形が1つのクラスターです。
次にLODレベルごとに
- クラスターをグループ化して、共有する境界を綺麗にします。
- グループ内の三角点を共有リストにマージする
- 三角形の数が半分になるように単純化する
- 簡略化された三角形のリストをクラスターに分割します。
これを繰り返して、ルートに1つのクラスターが残るようにします。
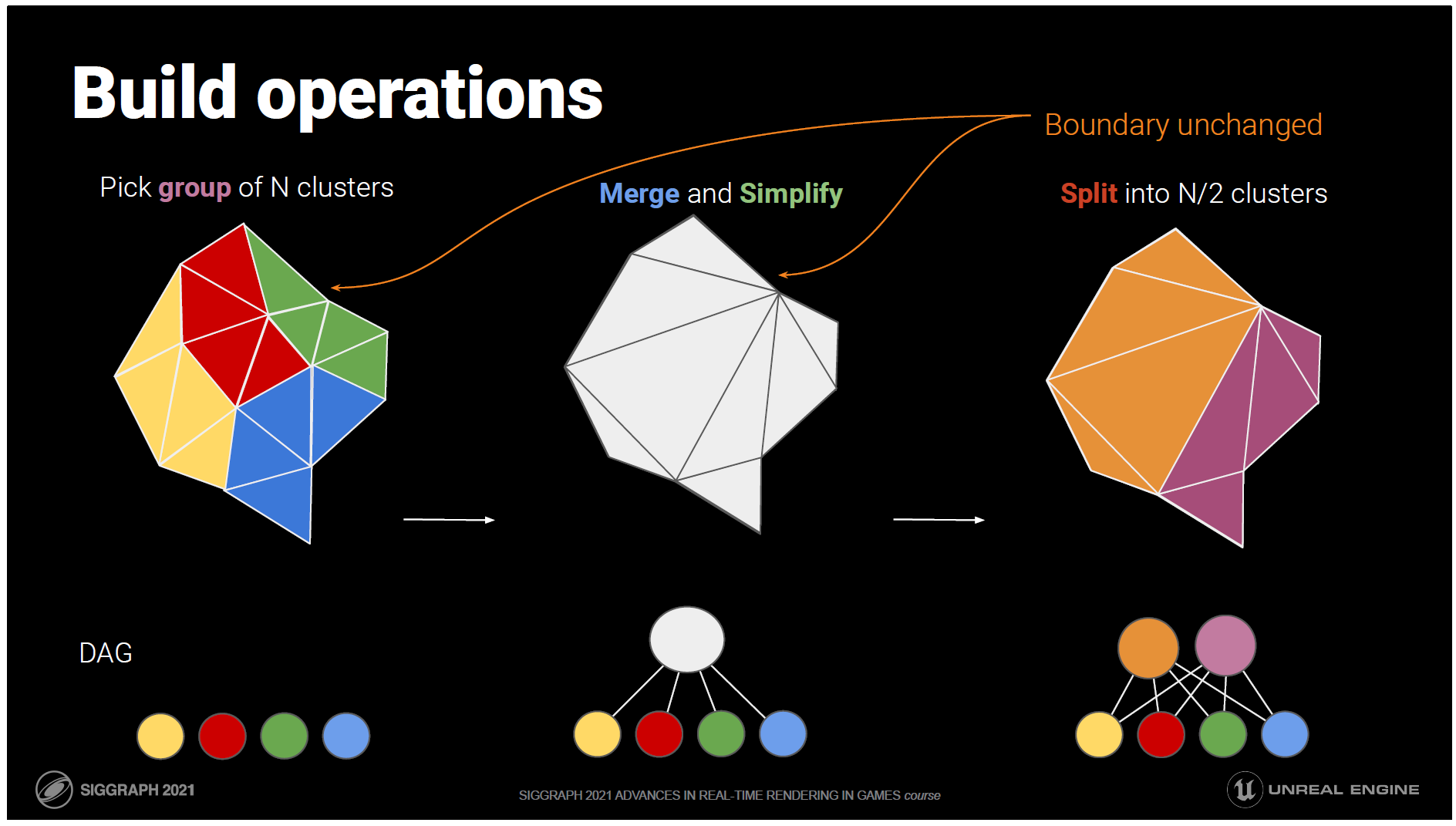
ここでは、その様子をイラストでご紹介します。
この例では、隣接する4つのクラスターをグループ化しています。
対応するDAGは一番下にあります。
次のステップでは、クラスターを統合し、三角形の数が半分になるように簡略化します。
DAGでは、4つのノードがこの新しい簡略化されたメッシュを親に持つことになります。
なお、境界はロックされているので、元のメッシュの隣接するクラスターとの間でクラックが発生することはありません。
最後に、簡略化されたトライアングルリストを2つの新しいクラスターに分割します。
DAGでは、これは親を2つに分割することに相当しますが、すべての子は両方の親に接続されたままです。
これで、4つの4-トライアングル・クラスターが2つの4-トライアングル・クラスターに減りました。
これらをプールに戻してグループ化し、DAGのルートにある1つのクラスタになるまで処理を続けます。
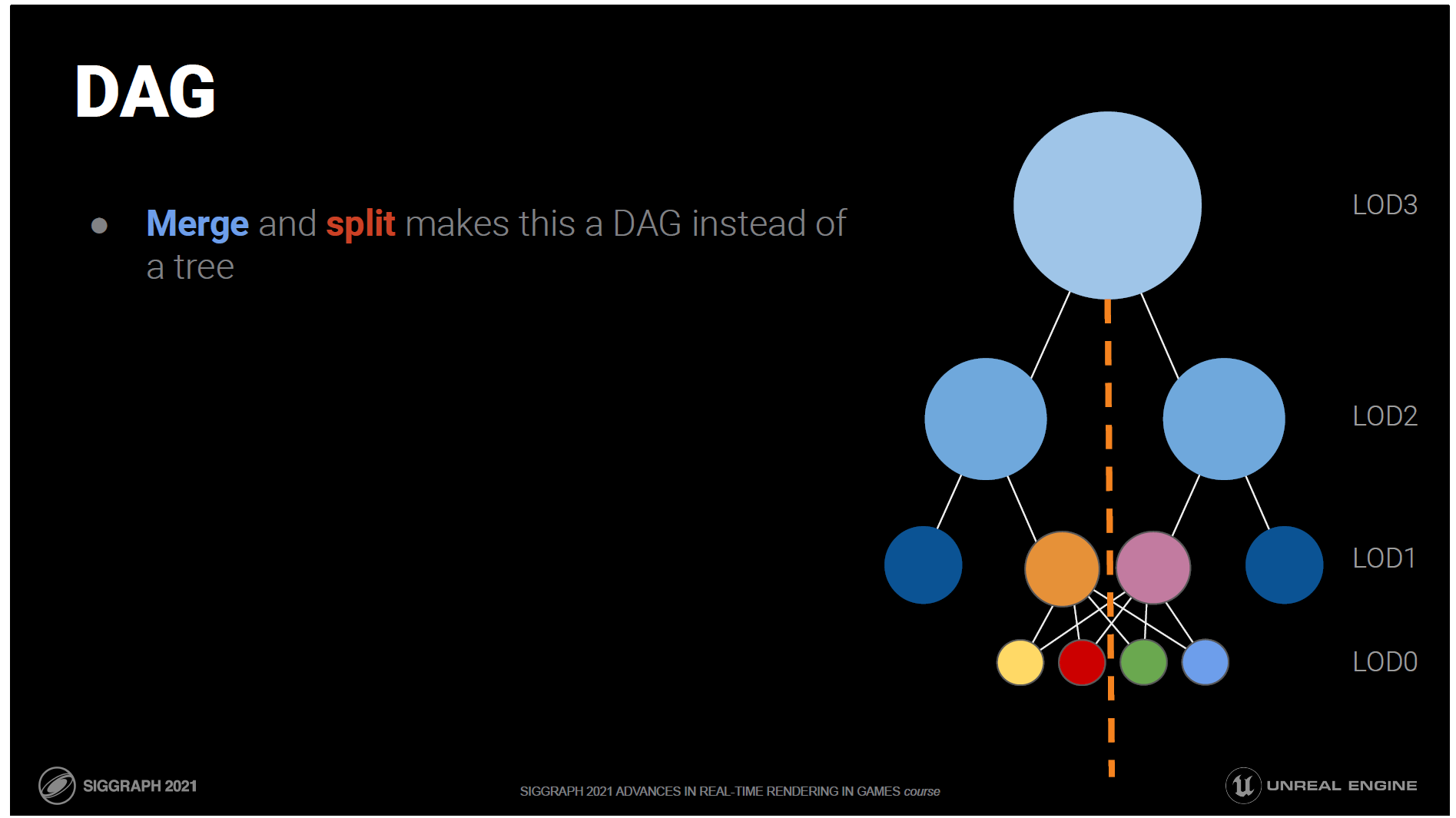
結合と分割のステップにより、これは木ではなくDAGになります。
これは良いことで、LOD0からルートまでエッジを越えずに線を引くことはできません。
つまり、ロックされたエッジがロックされたままで、ひどい結果を集めてしまうようなことがないということです。

それでは、ビルドの各ステップをご紹介します。
まず、どのクラスターをグループ化するかをどうやって決めるのでしょうか?
境界エッジが少ないほど、ロックされたエッジも少なくなるので、共有された境界エッジが多いものをグループ化します。
ロックされたエッジが少ない方が良いのは、ロックされたエッジが単純化装置による三角形の削減を制限するからです。
この問題はグラフパーティショニングと呼ばれ、計算科学の分野ではよく知られていますが、グラフィックスの分野ではあまり馴染みがないかもしれません。
グラフパーティショニングアルゴリズムは,グラフを指定された数のパーティションに分割し,あるパーティションから別のパーティションに渡るすべてのエッジの重みの合計(エッジカットコストと呼ばれる)が最小になるようにします。
ここでは、グラフのノードをクラスタとします。
グラフの辺は、隣接する三角形が直接つながっているクラスタをつなぎます。
グラフの辺の重みは、それらのクラスタ間で共有される三角形の辺の数です。
また、空間的に近いが接続されていないクラスタに対しては、追加のグラフエッジを追加して、恣意的にグループ化されてしまうようなグラフの島がないようにします。
このグラフの最小エッジカットは、このレベルのメッシュ全体でロックされたエッジの数が最も少なくなることに対応しており、基本的には理想的な最適化が行われます。
グラフのパーティショニングは非常に複雑な作業ですが、ありがたいことに、それを行うための既存のライブラリがあります。
私たちは、人気の高いMETISライブラリを使用しています。

しかし、このDAGの構築を始めるには、リーフクラスターが必要です。どうやって構築するのでしょうか?
残念ながら、これは多次元の最適化問題です。
- カリング効率化のために、クラスターの境界範囲を最小にしたい。
- ラスタライザで動作させるためには、クラスタあたりのトライアングル数を128以下にする必要があります。
- プリミティブシェーダーで動作させるためには、頂点の数が制限を超えることはできません。
- また、クラスター間の境界エッジの数を最小限にしたいと考えています。これも、単純化装置が仕事をするために、可能な限りロックされていないエッジを与えるためです。

すべての次元を同時に最適化することはできないので、2つの次元を選び、残りの次元は相関関係があるのでうまくいくことを期待します。
具体的には、境界辺の数とクラスタあたりの三角形の数を最適化します。
クラスタ間で共有されるエッジの数を最小化することは、クラスター・グループ化のときとまったく同じ問題です。
クラスターのグループ化の時もそうでしたが
もう一度、グラフパーティショニングを行います。
今回はグラフがメッシュの双対になっています。
1つの違いは、今回はパーティションサイズに厳密な上界があることです。
残念ながら、グラフパーティショニングアルゴリズムはこれを保証しません。
ごくまれに失敗することがあるので、少量のスラックとフォールバックを使って、なんとかそれを強要しています。
——
Bonus:
コスト指標に境界を考慮したカスタム・グラフ・パーティショニング・コードを使用すれば、より良い結果が得られるはずです。
ベスト・オブ・ブリードのグラフ・パーティショニング・アルゴリズムはかなり複雑で、独自に書くのは大仕事になります。

実はこのSplitステップは、最初のクラスタリングプロセスと同じものであることがわかりました。
三角形のリストを受け取り、128個のクラスターを作ります。

古いバージョンのNaniteは、これらとテトラパズルをミックスしたようなもので、グループ化はボロノイ分割に従っていますが、テトラパズルのように空間的な分割でした。
空間的には単純なWorleyノイズは不規則なボロノイ分割なので、レベルのグルーピングは、座標をそのレベルの解像度に合わせてスケールし、同じセルに入ったものをグループ化します。
テトラパズルのように空間を利用したグループ分け、特に形や大きさ、レベルとの対応が厳密なものでは、各グループに割り当てられる三角形の数が不揃いになるという問題があります。正四面体の中には1つの三角形(この場合は1つのクラスター)しか入らないので、どうすることもできません。
クラスター間の関係を構造化されていないグラフとして扱うことで、本当に重要な特性をより多く把握し、それらを直接最適化することができます。
Batched Multi-triangulationでは、グループ化、結合、単純化、分割という最も一般的なフレームワークで問題を解決し、グループ内のクラスターが分割後の三角形のクラスタリングと関係する必要がないようにしました。これは本当に素晴らしい特性で、実際に実装も簡単です。QuickVDRが同じことをしているかどうかは不明ですが、彼らはこのプリンシパルを明確に呼んだり説明したりしませんでした。
QuickVDRは、グループ化の目標を直接最適化できると考えました。二分木の構築に関しては、グラフ分割によって共有エッジを最小化することができると考えました。しかし、面白いことに、境界をロックするための解決策である依存性のあるノードを決定するために、彼らは優先キューを切断し、グラフパーティショニングによって二分木を構築した後、貪欲な最適化を行いました。
この2つの形式を組み合わせることで、最も一般的で最適なフレームワークになると考えています。グループ化は、不規則なボロノイ分割による確率的なものではなく、クラスターの関係を重み付けされたエッジを持つグラフとして表現することで、直接的に最適化されます。グループ化と階層化は、グラフで表現された統一された操作であり、グラフパーティショニングを用いて分割することができます。互いに依存しているノードは兄弟と変わらないので、その構造は実際にはDAGであることを意味します。扱う三角形の数は、常に一定の粒度の倍数であるため、128個の三角形のクラスタを正確に満たすことができます。個々の三角形でグループを形成することはありません。マージとスプリットの定式化は対称的に行われ、親と子の間で三角形からクラスタへの割り当てに関して対応や制約が必要ないことを明確に理解しています。すべての兄弟は、すべての親とつながっています。最終的に構築される構造は明らかにDAGであり、正しく推論することができます。

最後にご紹介するのは簡略化です。
これには典型的なedge collapsingデシメーションを使用します。
誤差はQuadric Error Metricを使って計算します。
新しい位置や属性での誤差が最小限になるように最適化します。
目新しさはありませんが、このコードは品質とスピードの点で現時点では非常に高度に洗練されており、私の知る限り、他の市販のオプションよりも優れています。
このコードは、単純化することで生じる誤差の見積もりを返しますが、これは最も難しい点でした。
この推定誤差は、どのLODを選択するかを決定するために、誤差のピクセル数に応じて画面上に表示されますが、これは品質と効率の両方の基礎となるものです。
ピクセル誤差の知覚的ヒューリスティックは、非常に効率的に評価でき、直接最適化できるものです。
ピクセル誤差の知覚的ヒューリスティックには膨大な時間を費やしてきました。
推測するに、おそらく1年分の努力が何らかの形でこの問題に費やされてきたのではないでしょうか。
現段階では、このメッシュにどのようなマテリアルが適用されるかわからないので、ある意味では不可能な作業です。
例えば、どのぐらい光るかそれを知るために正確な法線誤差の影響がわかりません。
テクスチャによってどの程度のUVエラーが発生するのか?
頂点カラーがあるとすれば、それが何に使われているのかもわかりません。
私たちが持っているものは完璧ではありませんし、目に見えるほどではありませんが、失敗することもあります。
しかし、人間の知覚に関するより多くの側面を考慮することで、より積極的になることができるでしょう。


——
Bonus:
位置と属性の誤差を混ぜることで見つけた、これまで発表されていない気づきやコツを解説します。
長い間、簡略化のために悩んでいた疑問があります。アトリビュートとポジションの重みのバランスがいつもおかしいのです。私が知りたいのは、単純化によって生じる誤差を感じさせないためには、カメラはどこまで必要なのかということです。ワールド空間のサイズをピクセル単位で投影する計算は簡単です。つまり、ワールド空間でどれだけの誤差が発生したかを知り、それをピクセル数に変換する必要があるのです。知覚とはもっと複雑なものですが、私はこのような枠組みで仕事をしています。位置偏差の誤差は、まさにこれを行うのに適した単位とフレームワークを持っています。法線の違いのような属性の誤差はそうではありません。これをどうすればいいのか、数え切れないほどの論文を見てきましたが、私が今まで行ってきたこと以上の解決策は見つかりませんでした。それは、位置偏差誤差と属性誤差を同じ単位のように混ぜ合わせ、それぞれが相対的にどれだけ重要であるかの重みをつけることです。同じものであるかのように混ぜてしまうのは、馬鹿げたヒューリスティックな方法です。実際にはそうではありませんが、それでも他に良い方法はありません。
さらに悪いことに、重みによって決定されるバランスは、スケールに依存しません。
属性の偏差(特にノーマル)はスケールに依存しません。法線の1度の変化はどのくらい知覚できるでしょうか?それが1マイル離れていたらどうでしょう?それは問題ではありません。重要なのは、そのエラーが何ピクセルをカバーしているかということです。一方、位置の偏差はスケールに依存します。1マイル先の1単位の位置のずれは、たとえそれがエンパイアステートビル全体が動いたとしても、知覚することはできません。
ちょっとした思考実験の時間です。立っている人の彫刻のメッシュと、100倍にスケールされていることを除けば同じメッシュがあったとして、法線と位置のバランスが異なることはないはずです。どちらも同じように単純化されるはずです。では、境界が同じになるようにリスケールするのでしょうか?これは文献的にも示唆されていることですし、私が以前やっていたことでもあります。すべてのメッシュは同じような広がりを持つようにスケールされています。2つのコピーが並んでいるメッシュがあったらどうしますか?今はどうでしょう?境界を正規化してもうまくいきません。同じ2つのコピーがあっても、それらが非常に離れていたらどうしますか?ジオメトリ的には同じですが、境界線が異なります。境界線の代わりに三角形の平均表面積を正規化することで、これを考慮することができます。2つのコピーメッシュのうち、1つのコピーがもう1つのコピーの肩の上に立つほど小さい場合はどうでしょうか?なぜ小さい方のコピーが大きい方のコピーと違った方法で単純化しなければならないのでしょうか?表面積であっても、グローバルなリスケールはもはや機能しません。どのような粒度が有効なのでしょうか?粒度がゼロから三角形までになると、限界までやる必要があるように感じます。しかし、それがどのように機能するのかはよくわかりません。もっと考える必要があります。おそらくこの操作は、エッジの崩壊した三角形の近傍で行われるべきだと思います。実際には、粒度を十分に低くしても問題ないでしょう。
私が単純化装置に渡すクラスターのグループは十分に小さいので、大きなコピーケースでも小さなコピーケースでも大体同じような動作が起こります。Naniteの構造では可能ですが、一般的な単純化装置には存在しないものです。両方とも同じようにクラスター化され、クラスターは同じようにグループ化されるはずです。LODを行う観点からすると、これらはほとんどの場合、スクリーン上で同じ平均トライアングルサイズに投影されます。そこで、三角形あたりの平均表面積を計算して、それが大体、私が位置と属性のバランスの良い組み合わせとして選んだ定数になるようにメッシュをリスケールします。これで、サブパーツまでスケールインバリアントになりました。
その大物の肩に乗っている小柄な人は、実は重要なケースなのです。つまり、あるメッシュが非常に遠くにあり、したがって非常に小さい場合、それは近くにある大きなメッシュの小さな部分と同じように単純化されるべきだということです。Nピクセルをカバーするクラスターは、Nピクセルをカバーする他のクラスターと同じように単純化し、その誤差を計算しなければなりません。
これを正しく行うことは、単なる理論的なコツではありません。この修正により、デモの中で描かれる三角形の数が、多少の変動はあっても基本的には一定になりました。例えば、彫像の部屋は、以前は洞窟のシーンの2〜3倍でした。この変更後は、どちらのシーンも同じ数の三角形がラスタライズされるようになりました。
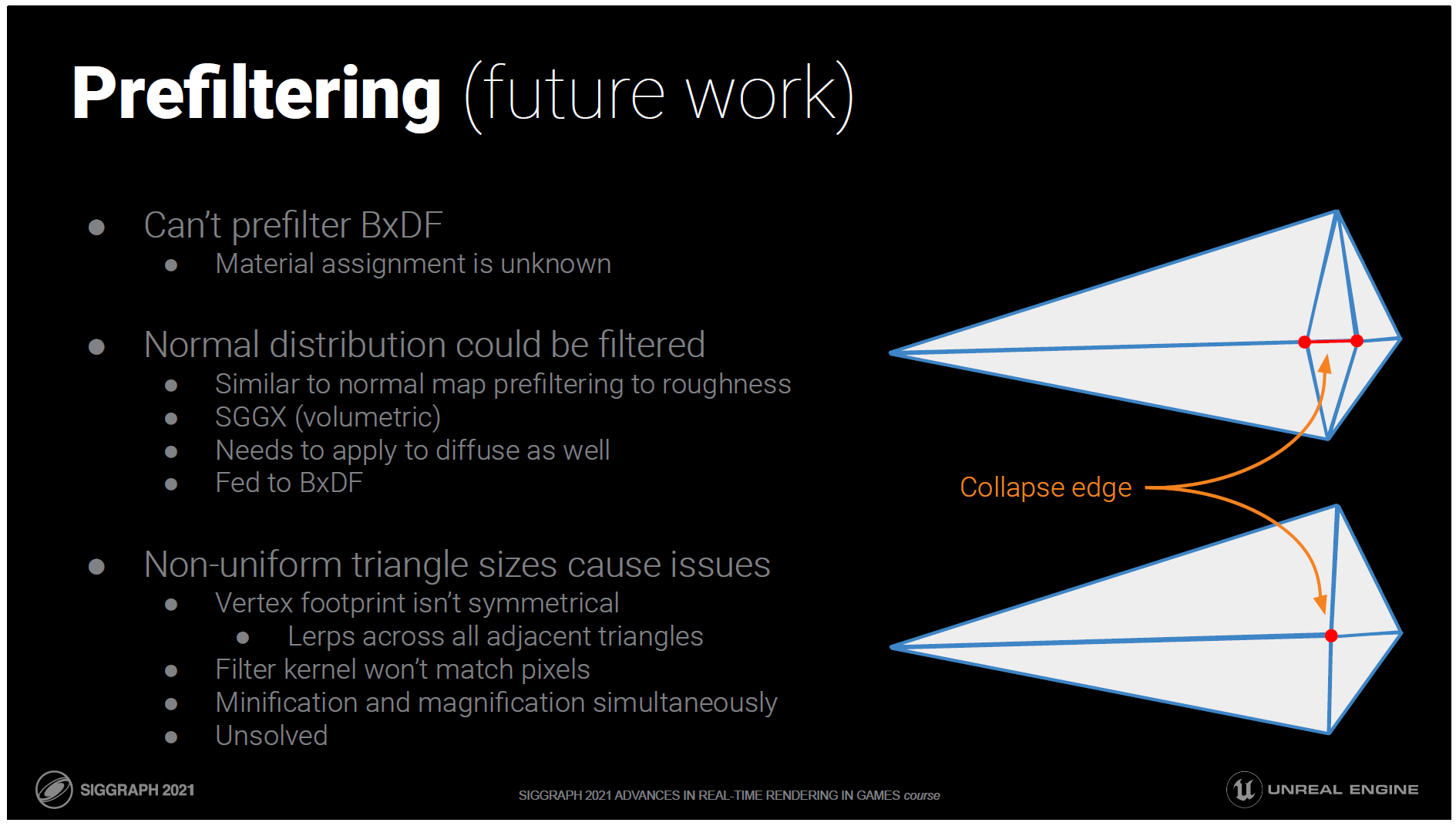

葉や草のような集合体のジオメトリでは、サブピクセルの部分的なカバレッジと事前フィルタリングが特に重要です。
このケースを解決することは、まだ未解決の問題です。

ランタイム部分に移ります。
このクラスター階層を構築した 毎フレーム、ビューに応じてどのクラスターを描画するかを選択する必要があります。
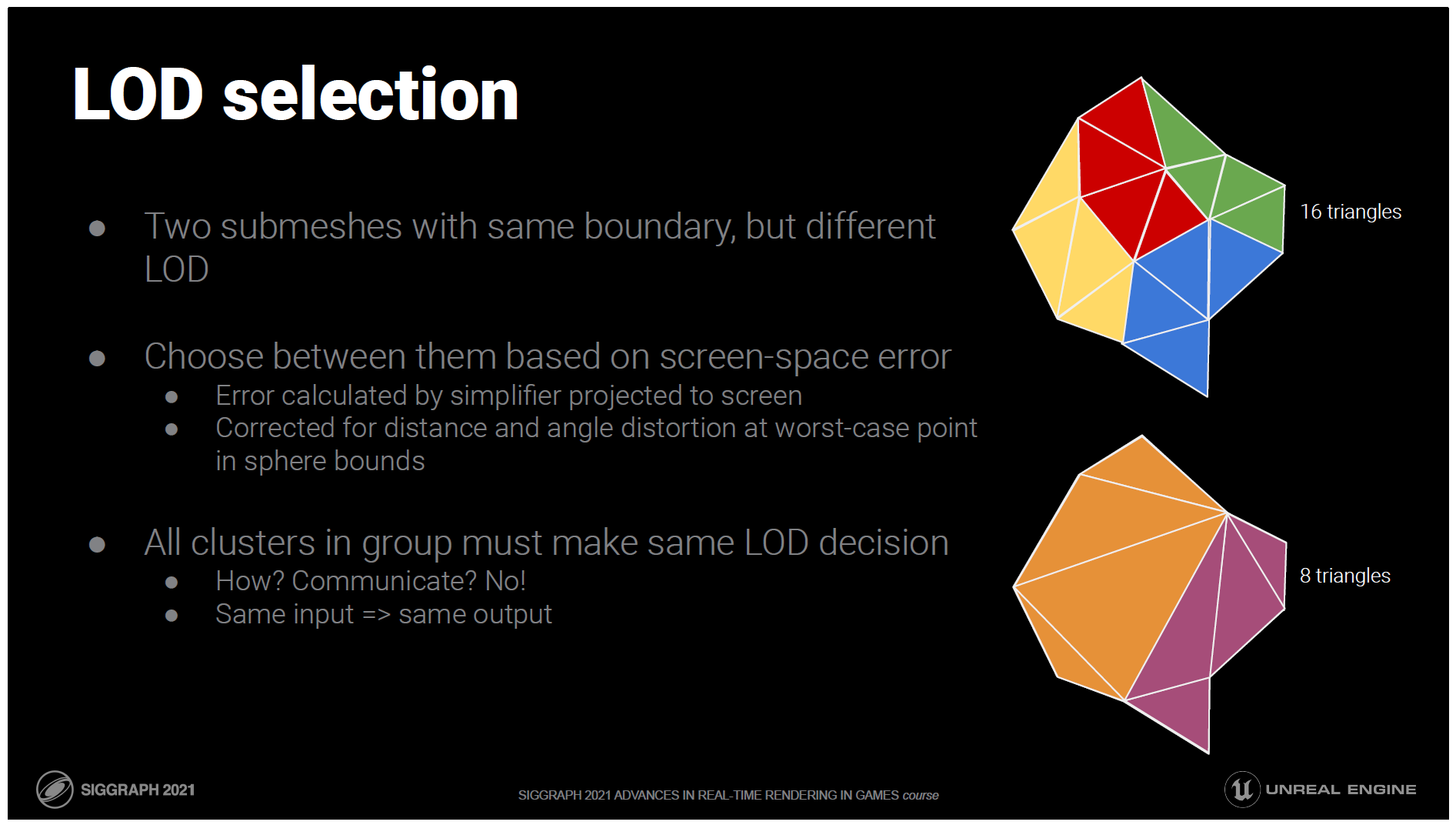
興味深いのは、構築作業を繰り返すたびに、三角形の数は異なるが、同じ境界線を持つ2つのクラスターのセットができたことです。
そのため、オリジナルのメッシュでは、クラックが発生することなく、入れ替えが可能です。
これが詳細度制御システムの真髄です。
ランタイムでは、スクリーン空間にどれだけの誤差があるかを考慮して、どちらかを選択します。
単純化装置で計算された誤差は、距離と投影角度の歪みを考慮してスクリーンに投影されます。
これは、クラスターの周囲の境界球内で投影された誤差が最大となる点で計算されます。
先に説明したように、グループ化されたクラスターは同じLOD決定をしなければなりません。
それを並列に行うにはどうすればいいのでしょうか?
1対多の展開?
相互に通信する?
いいえ、それはとても簡単です。
同じデータを使って決めれば、同じことを決めることができます。
同じ入力、同じ出力
つまり、グループ内のすべてのクラスターは、同じ結合されたエラー値と、そのエラーを画面に投影するために使用される球体の境界を保存しているのです。
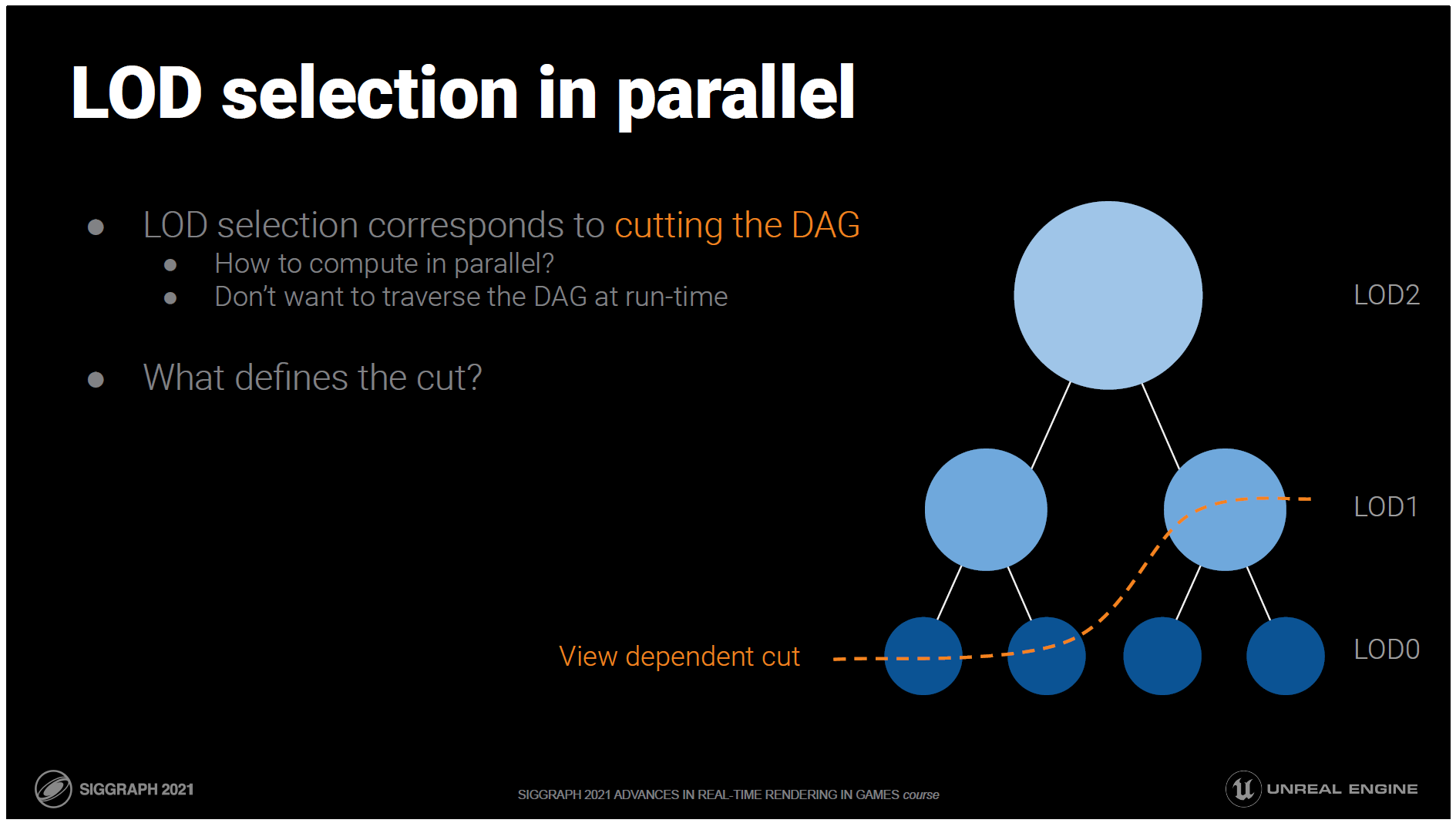
しかし、それは、このクラスターが描画できるほどの小さな誤差を持っているかどうかを示しています。
誤差の小さいクラスターをすべて描画したいわけではありません。誤差の少ないクラスターは、同じエリアであっても細部が異なるものが多いからです。
LODの選択には、ビューに依存した階層の切り口を見つける必要がありますが、それは実はDAGであることがわかっています。
これをGPUで決定したいのですが、カットを並列で効率よく計算するにはどうしたらいいでしょうか?
カットを定義するものを検討する価値があります。

親の誤差が大きすぎても、子の誤差が小さければ描画が有効になる、というところでカットが発生します。
親はノーと言うが、子はイエスと言う。
これは完全にローカルなもので、このノードまでのパス全体には依存しないため、並列に評価することができます。

しかし、それは1つのユニークなカットがあることを前提にしているだけです。もしないのであれば、パスを歩いて最初のカットを見つける必要があります。
ルートからリーフまでのすべてのパスの選択関数が、一度だけ「いいえ」から「はい」に切り替わり、二度と元に戻らない場合、一意のカットがあることになります。
私たちの選択関数は、ビュー依存のエラー関数のしきい値です。
パスに沿って単一の遷移を保証することは、すべてのパスのエラー関数を単調にすることと同じです。
複雑に聞こえるかもしれませんが、実際には、親の誤差計算を常に子と同じ大きさにする必要があります。
これはオフラインでのDAG構築の際に、親の保存された誤差とそれを投影するために使用される境界を修正することで強制されます。
どちらも子と同じ大きさにする必要があります。

つまり、各フレームで親か子のどちらかを選択することになります。
これでは、切り替わったときに目に見えてポップになりませんか?
ジオモーフィングやクロスフェードで遷移を滑らかにする必要があるのでしょうか?
それはレンダリング時にコストがかかります
膨大な追加データが必要になったり
またはその両方を必要とします。
しかし、誤差が1ピクセル以下のクラスターだけを描くと、知覚できないほどの違いがあり、一時的なアンチエイリアシングによって変化が滑らかになります。
TAAはサブピクセルの違いを時間とともにブレンドするように作られています。
誤差が1ピクセル以下であれば、TAAは私たちの仕事を代行してくれます。
これが、正確な誤差推定値を得ることが非常に重要である理由です。


説明したように、クラスター選択を完全に並列化することはできますが、規模が大きくなると非常に無駄が多いことがわかります。
大きなシーンでは、大部分のクラスターが細かすぎて選択できません。ほとんどのクラスターは検討すべきではありません。
素早く棄却するためには、階層が必要です。最も自然なのは、DAG構造をベースにすることです。
しかし、DAGのトラバースは思ったよりも複雑で、特に並行して行わなければならない場合はそうなります。
幸いなことに、先ほど示したように LODの判断は、クラスターのエラーと親のエラーだけでローカルに評価できるので、DAGを使う必要はありません。
これらのテストを高速化するために、好きなデータ構造を構築することができます。
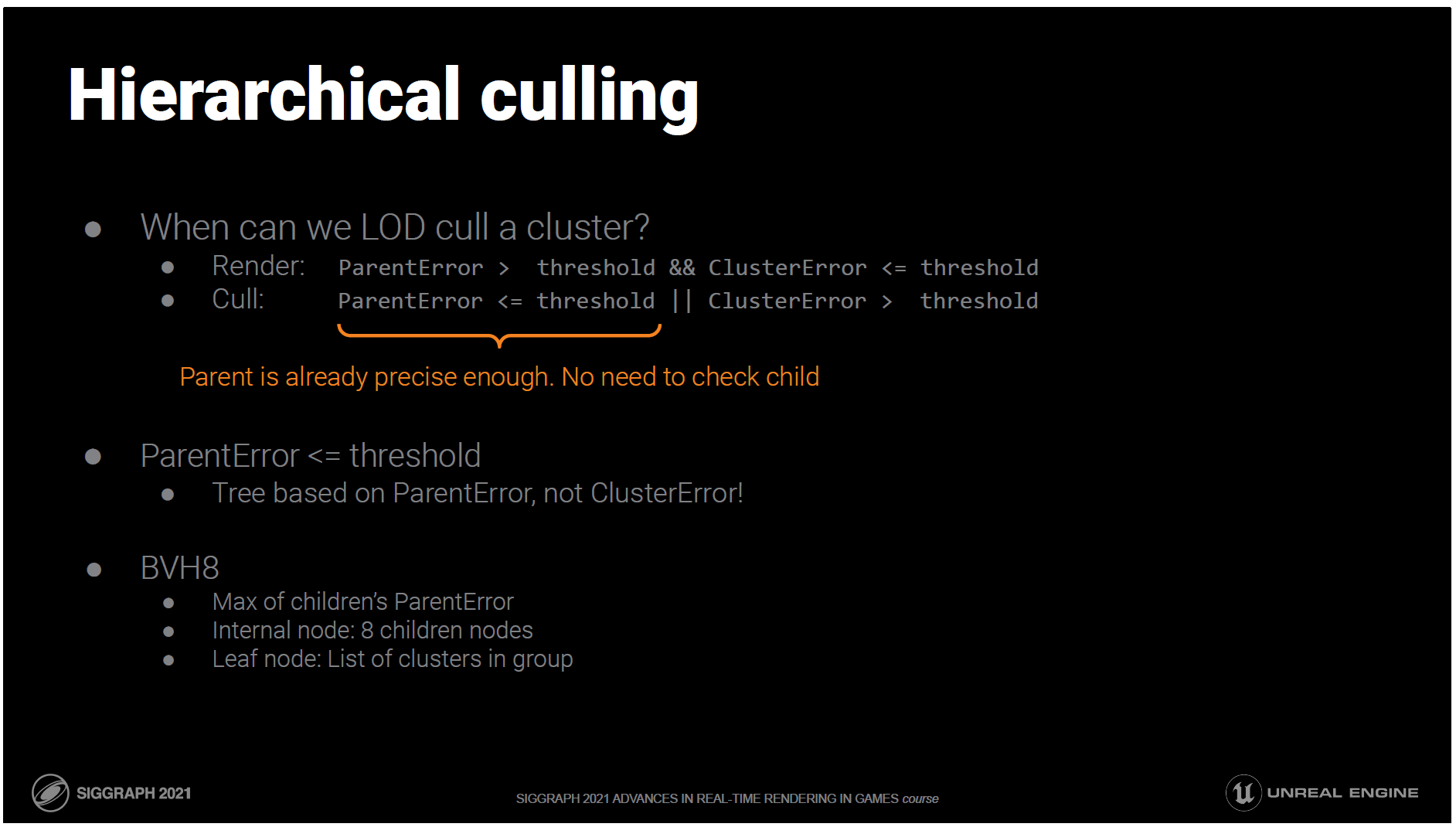
淘汰されるクラスターは、まさに先ほどのLOD選択テストに失敗したクラスターです。
ParentErrorがすでに十分に小さいクラスタはすべてcullすることができます。
興味深いことに、これはLOD淘汰のための加速構造はClusterError自体ではなく、ParentErrorに基づくべきだということです。
これにより、私たちはクラスターの上にBVHを構築します。
他のBVHと同様に、親は子を保守的に束縛しますが、この場合はParentErrorも含まれます。
親はグループで共有されているので、ツリーのリーフはグループサイズのクラスターのリストになります。
——
Bonus:
クラスタは、そのエラーが大きすぎる場合と、その親のエラーがすでに十分小さい場合の両方で淘汰されます。
一般的に、あるビューでは、十分に詳細でないクラスターよりも、詳細すぎるクラスターの方が桁違いに多く存在します。
私たちは、詳細すぎるクラスターのカリングを促進することに焦点を当てるべきです。それは、ParentErrorが閾値以下で十分に小さいクラスターのことです。

このツリーをトラバースすることは、古典的な並列拡張作業スケジューリング問題です。
素朴に実装すると次のようになります。多くのパスがあり、それぞれがツリーの1レベルを処理し、通過する子ノードをバッファに追加して次のパスで処理します。
各パスは前のパスに依存しているため、GPUはツリーのすべてのレベルで完全に消耗します。
CPUは再帰の深さを知らないので、最悪のケースをカバーするのに十分なディスパッチを発行しなければなりません。
つまり、何の処理もしない空のディスパッチが簡単にできてしまうのです。
この問題は、より高い分岐係数を選択することで多少軽減されますが、これも非効率になります。
——
Bonus:
小さくて遠い物体は、いくつかのクラスターをレンダリングするだけで済むかもしれませんが、常にすべての子を評価する必要があります。

本当は、このレベルの他のすべてのノードが終了するのを待つのではなく、親が通過したらすぐに子の処理を開始したいところです。
理想的には、computeから直接、子のための新しいスレッドを生成できることです。しかし、現在のところ、それを実現する方法はありません。
しかし、新しいスレッドを生成する代わりに、すでに持っているスレッドを再利用し、独自のジョブキューを使って作業を分配することができます。
これはパーシステント・スレッドと呼ばれ、基本的には自分自身のミニ・ジョブ・システムを書くようなものです。
GPUを満たすのに十分な数のワーカースレッドを生成し、それらのスレッドを再利用して、残りが無くなるまでキューから仕事を引き出します。

階層的なカリングの場合、これは次のことを意味します。
スレッドは、キューが空になるまで、キューからノードをポップし、それを処理し、テストに合格した子をプッシュバックするという作業を繰り返します。
現在では、単一のディスパッチです。
階層の数に制限はなく、GPUを何度も消耗する必要はありません。
パーシステント・スレッドのアプローチは、ナイーブなアプローチに比べて平均で25%高速です。
残念ながら、このようなブロッキングアルゴリズムは、D3DやHLSLで定義されていないスケジューリング動作に依存しています。
保証されるべき重要な特性は、スレッドグループが実行を開始し、したがってロックを取ることができたならば、そのスレッドグループはスケジュールされ続け、無期限に飢えることがないようにすることです。
未定義ではありますが、このアプローチはコンソールや、これまでにテストしたすべての関連GPUで動作します。
——
Bonus:
願わくば、PCのプログラミングモデルが追いついてきて、将来的にはこのような最適化をPCで自信を持って使えるようになってほしいですね。

ツリーのノードはParentErrorを表し、リーフはその親を共有するクラスターのリストとなります。
これらのクラスターは、ノードと同様のカリングチェックを受ける必要があります。
BVHトラバーサルは深くまで行くことができるので
また、ある時点でのアクティブなノードの数は、GPUの幅に比べて小さくなる可能性があります。
BVHのカリングフェーズは常にGPUを満たすことができないでしょう。
このような場合、いくつかの深いトラバーサルのレイテンシーがカリングの実行時間を支配することになります。
この問題を軽減するために、我々はクラスタカリングを永続的階層カリングシェーダに統合し、クラスタカリングを早期に開始してBVHカリングの穴を埋めることができるようにしました。
実際には、クラスター用の追加キューで実装されています。ワーカーがノードキューに新しいノードが現れるのを待っている間に、クラスターキューから既に見つかったクラスターを処理することができます。
発散を避けるために、これはバッチで行われます。
さて、このようにLODのためのカリングを行う一方で、視認性に基づいたカリングも行う必要があります。
しかし、先に説明した2パスオクルージョンの方法には問題があります。
以前に見えていたセットを追跡するのは複雑です。
フレームごとにLODの選択が異なる可能性があります。
前のフレームで見えていたクラスターは、ストリーミングのためにもうメモリにないかもしれません。
そこで、現在選択されているクラスターが最後のフレームに表示されていたかどうかをテストします。
そのために、以前の変換を使って、前のフレームのHZBに対して、その境界をテストします。
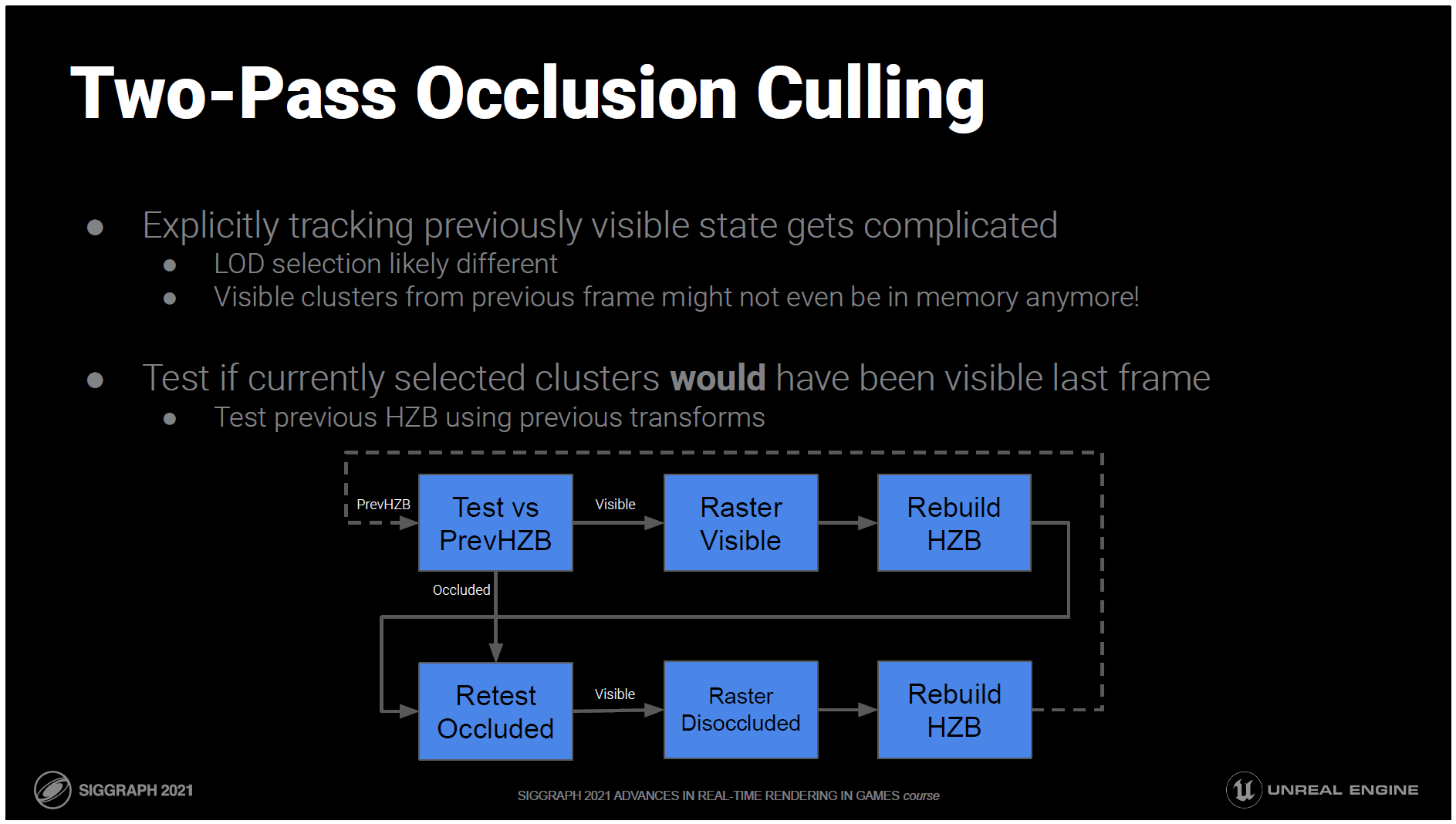
つまり、2パスのソリューションは次のようになります:
- 前のHZBを前のトランスフォームでテストする。
- 見えているものは描き、隠れているものは後回しにする。
- このフレームの初期HZBをデプスバッファから構築します。
- このHZBを使って、遮蔽されていると思っていたものをもう一度試してみる。
- 今は表示されているが、以前はオクルードされていたものを描画します。
- 最後に、次のフレームで使用するために、完成したデプスバッファから完全なHZBを構築します。
このため、Naniteパイプラインのほぼ全体を2回実行することになりますが、2回目の実行では、基本的に除外された領域をクリーンアップするだけです。
しかし、2回目の処理は通常、メインパスのごく一部であるため、これはそれほど悪いことではありません。
オクルージョンに関係のないカリングは一度だけ評価する必要があるので、フラスタムとLODのカリングは最初のパスでのみ行われます。
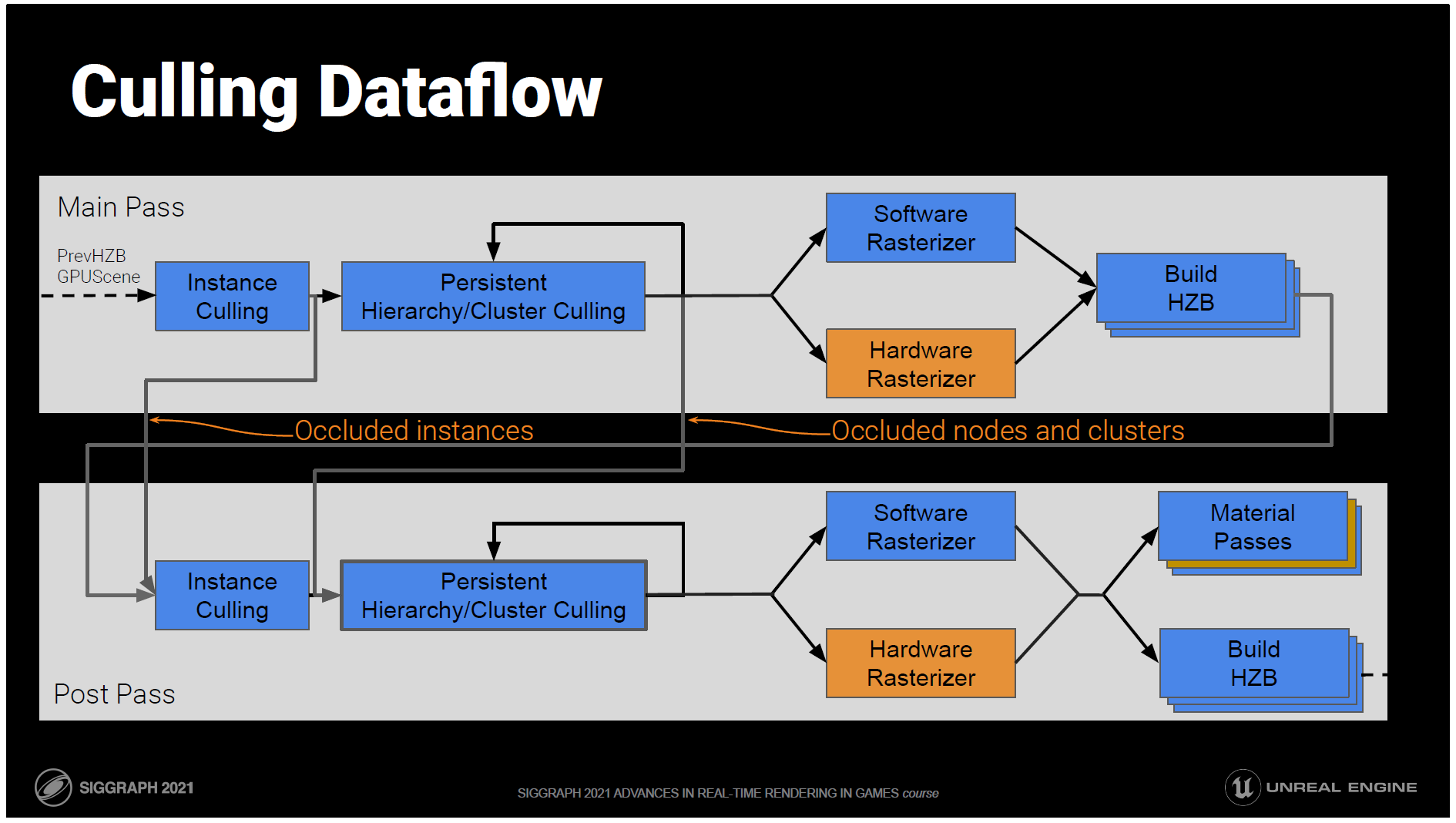
これらをまとめると、カリングフローはこのようになります。
最初のパスでは、前のフレームのHZBに対する変換テストを使ってオクルージョンを評価します。
GPUSceneのインスタンスから始まり、インスタンスごとに視認性を評価します。
可視性のあるインスタンスは、パーシステントスレッド階層クラスターカリングに進みます。これはLODと可視性の両方を行い、可視性のあるクラスターを出力します。
ビジビリティバッファにラスタライズされます。
HZBは、ラスタライズされたばかりのものに基づいて、現在のフレームのために構築されます。
その後、すべてのカリングステージが繰り返され、前のフレームの情報に基づいてオクルージョンされたインスタンス、ノード、クラスターが、現在のフレームのHZBと現在のフレームのトランスフォームで再テストされます。
そして、完全なビジビリティバッファを使って、次のフレームのHZBを構築し、ディファードマテリアルパスを適用します。


ビューに依存した細かいLODがあり、ほとんどが画面解像度に合わせてスケーリングされている今、どれだけのトライアングルを描く必要があるのでしょうか?
ディテールの知覚的損失をゼロにしたいことを忘れないでください。
誤差が1ピクセル以下で、事実上ロスレスになるようにするには、トライアングルをどれだけ小さくする必要があるでしょうか?
ピクセルよりも大きな三角形でそれを実現することはできるのでしょうか?
多くの場合、それは可能です。トライアングルは適応性があり、必要とされる場所に行くことができます。
しかし、一般的にはできません。ピクセルサイズの特徴を目に見えるエラーなく表現するには、ピクセルサイズのトライアングルが必要です。

それは実用的でしょうか?
小さな三角形は、HWラスタライザを含めた一般的なラスタライザには酷です。
一般的なワークロードでは、三角形ではなくピクセルで高度に並列化するように設計されています。
最近のGPUは最大で1クロックに4つのトライアングルを設定しますが、ビジビリティバッファーに必要なプリミティブIDを出力することで、これはさらに悪化します。
プリミティブシェーダやメッシュシェーダはより高速になりますが、それでもボトルネックであり、このために設計されたものではありません/。
ソフトウェアのラスタライザでハードウェアに勝てる可能性はあるでしょうか?

はい!
私たちはもっと良いことができる 最速のプリミティブ・シェーダー実装と比較して、ハードウェアよりも平均で3倍高速です。純粋なマイクロポリのケースではさらに速く、旧来のVS/PSパスと比較してもかなりの速度が出ます。

なぜ、どうやって?
私はハードウェアエンジニアではありませんが、一般的なラスタライザが行うすべての操作を見てみましょう。
その中には、今回のケースには当てはまらないものや、小さな三角形のためには非常に非効率的なものもたくさんあります。
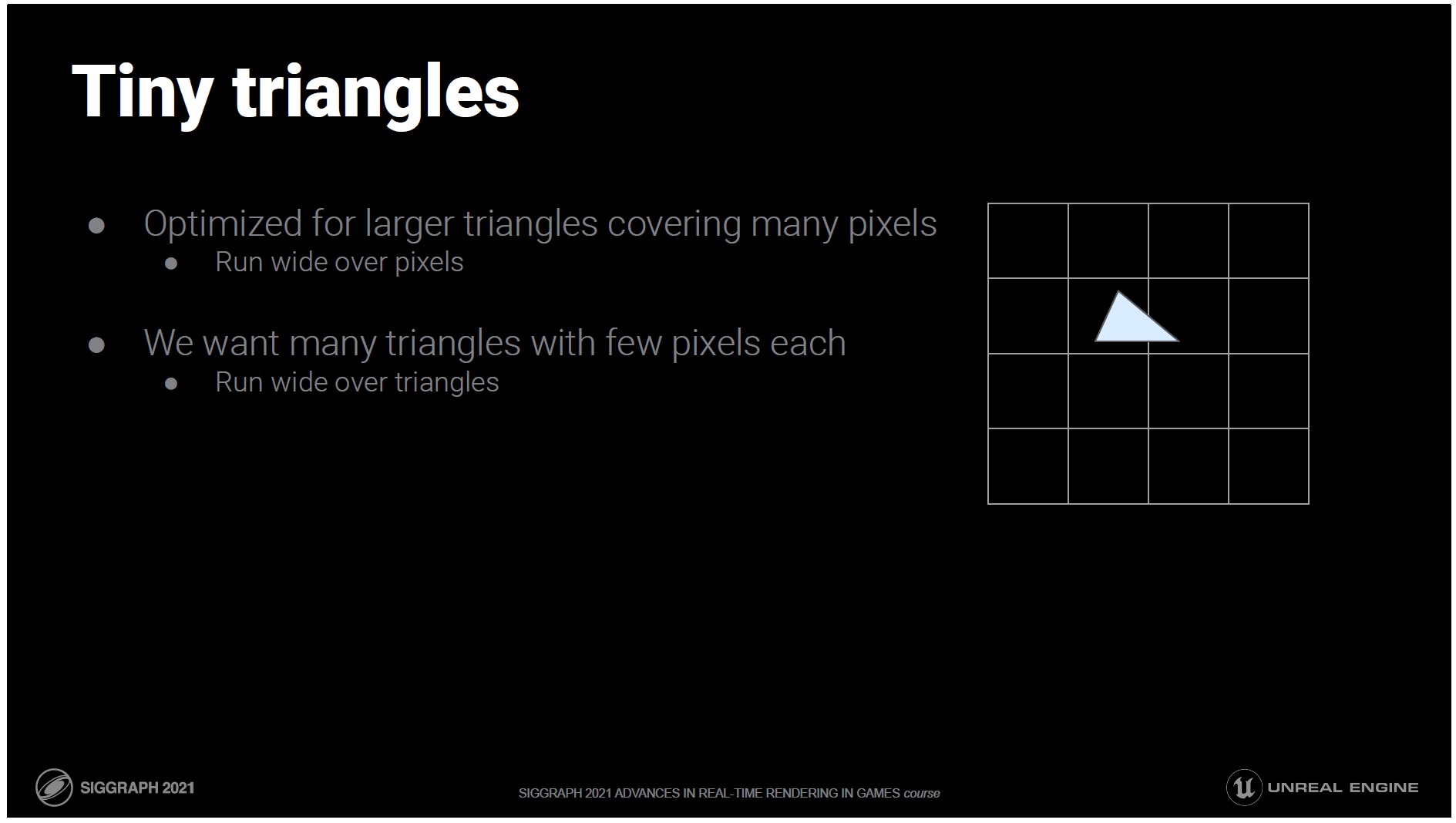
これらは、多くのピクセルをカバーする大きな三角形に最適化されています。
並列化する上で重要なのは、ピクセルをまたいで実行することです。
数ピクセルしかカバーしていない三角形がたくさんあります。
ピクセル単位ではなく、三角形単位で並列化したいのです。
確かに、我々よりも低消費電力でこれを実行するハードウェアを構築することは可能ですが、それがトランジスタの最良の利用法であるかどうかは疑問ですし、この問題やその他の問題に使用できるより一般的なコンピュートユニットを提供することにもなります。
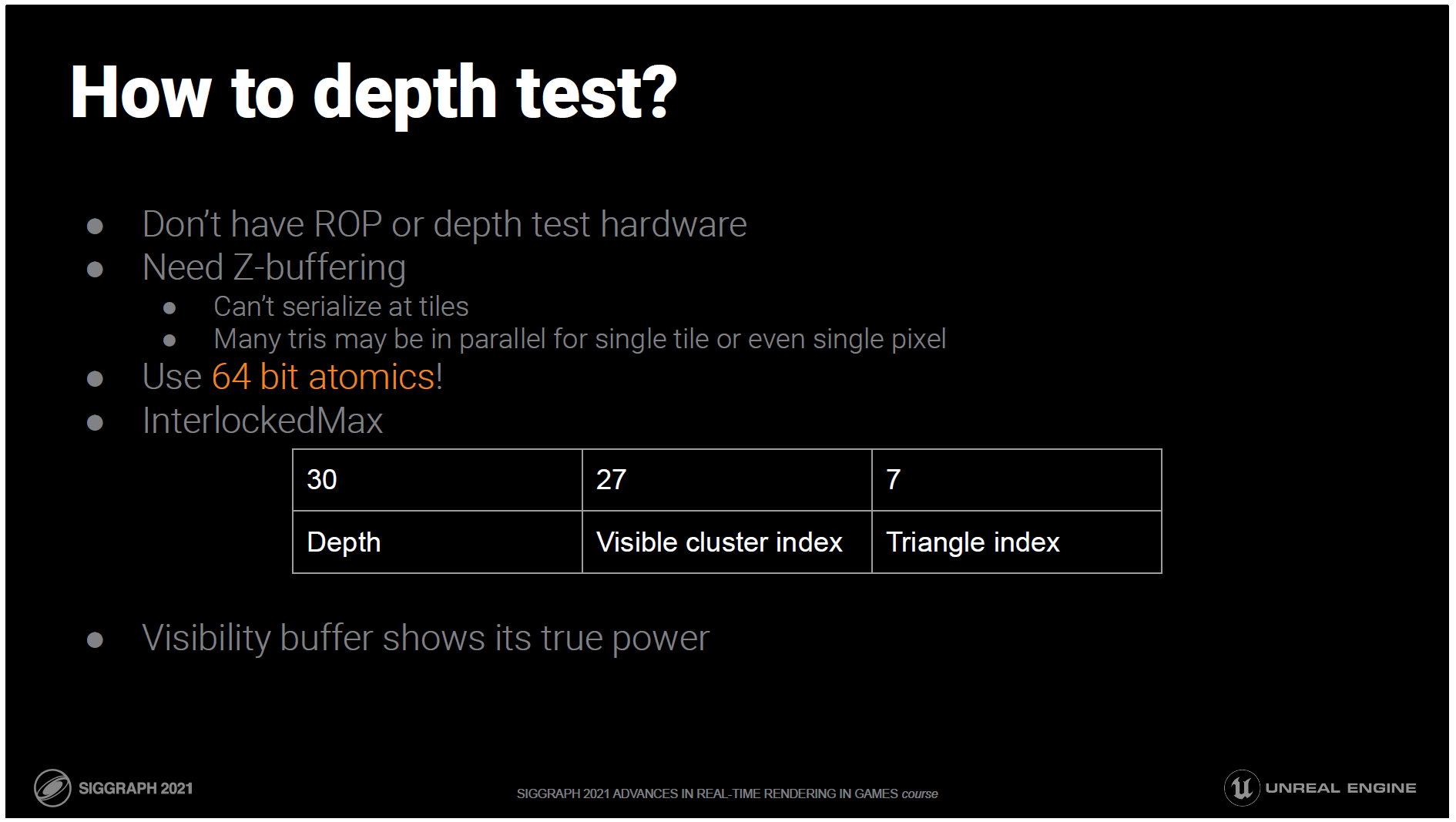
ハードウェアラスタライズを偽造すると、ROPと深度テストのハードウェアも失うことになりますが、それでもZバッファは必要です。
SWのラスタライザのようにタイルをロックしたくはありません。
多くのトライアングルが、一度に1つのタイル、あるいは1つのピクセルに書き込もうとして飛行しているかもしれません。
私たちは本当にロックをしたくありません。
その代わりに64bアトミックを使います。
具体的には、グローバルイメージInterlockedMaxをビジビリティバッファに設定します。
この64bの整数は
深度テストを行うために、上位ビットに深度があります。
そして低ビットにはペイロードを持ちます。
今回の例では、ペイロードは可視クラスタのインデックスとトライアングルのインデックスです。
ディテールを伴うビジビリティバッファーは、その真価を発揮します。ペイロードは、34ビット以下に収まるように小さくする必要があります。
これがなければ、ソフトウェアによる高速なラスタライズはできません。

マイクロポリソフトウェアのラスタライザの基本的な構成をご紹介します。
階層的なタイリングやスタンプなどの機能はすべて捨ててあります。
残ったのは、命令レベルでマイクロ最適化された、超基本的な半空間ラスタライザーです。
これは、メッシュシェーダに似た構造をしています。
ポストトランスフォームキャッシュを必要とせず、頂点作業を共有します。
スレッドグループのサイズは128です。
最初のフェーズでは、スレッドがクラスタの頂点バッファから頂点にマッピングされます。
頂点の位置をフェッチし、それを変換してgroupsharedに格納します。
128個以上の頂点がある場合は、クラスタあたり最大256個までサポートするために、別の頂点をフェッチして変換します。
その後、第2フェーズでは、各三角形にマップされたスレッドに切り替え、クラスタあたり最大128個の三角形をサポートします。
このトライアングルのインデックスを取得します。
このインデックスを使用して、groupshared から変換された位置を取得します。
三角形のエッジ方程式と深度グラデーションを計算します。
次に、三角形を囲む長方形の内側にあるすべてのピクセルについて計算します。
三角形の内側にあるかどうかをテストし、内側にある場合はそのピクセルを書き込みます。
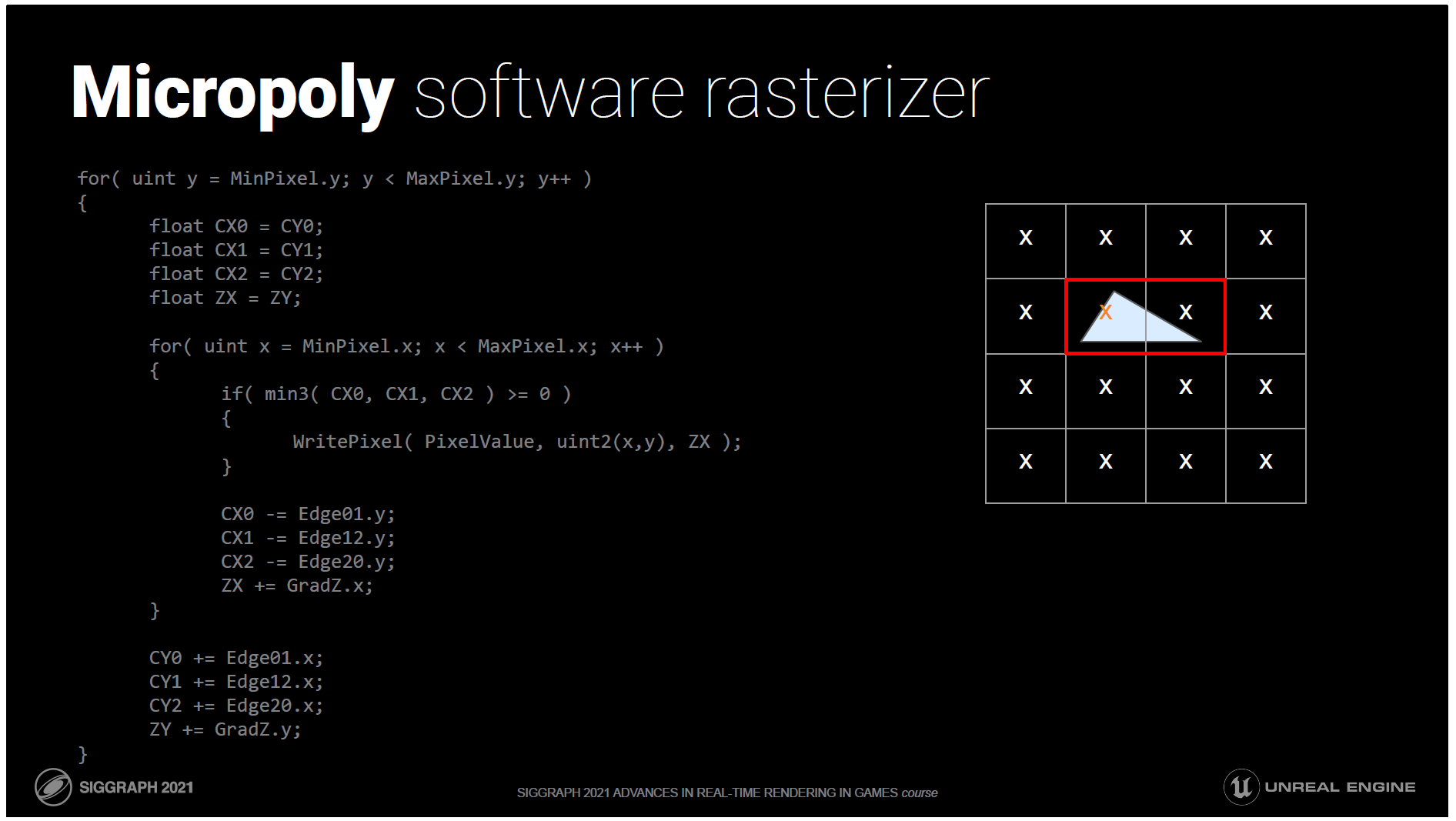
以下は、最適化されていない状態のインナーループです。
このループでは、境界線上のピクセルを繰り返し処理し、中心が 3 つのエッジの内側にあるかどうかをテストします。
中心が3つのエッジの内側にあるかどうかをテストし、内側にある場合はピクセルを書き込みます。このピクセルは単純に深さをペイロードでパックし、atomic maxでスクリーンに表示します。
このループの繰り返しは非常に少ないと思われるので、これを減らすために固定のオーバーヘッドを加えるべきではありません。
——
Bonus:
リアルタイムのREYES[72]の文脈で以前から検討されていました。
64bのアトミックトリックやビジビリティバッファを使いませんでした。
彼らはカバレッジテストで三角形をペアにすることを提唱し、そうすることでパフォーマンスが向上すると主張していますが、実際にはそうではありませんでした。
ハードウェアでの実装も提案されています[73]。

大きなトライアングルはどうでしょうか?
HWラスタライザを使用します。それが得意です。
他にもクリッピングなど、高速化できない場合は同じようにします。
クラスタごとにSWとHWのどちらが速いかを判断して選択しています。デモでは大半がSWラスタライズされています。
当初はSWとHWのクラスター間のクラックに神経質になっていましたが、ありがたいことに、DirectXにはラスタライズのルールについて非常に厳しい仕様があります。これに従うことで、HWと正確に一致させることができ、ピクセルのクラックは発生しません。
HWのラスタにデプステスト用のハードウェアを使用することもできますが、その場合、UAVバージョンとレンダリングターゲットバージョンをマージしなければならず、非同期でオーバーラップさせることができませんでした。
その代わり、HWラスタライザはカラーターゲットやデプスターゲットをバインドせず、SWラスタと全く同じようにUAVにアトミックに書き込みます。
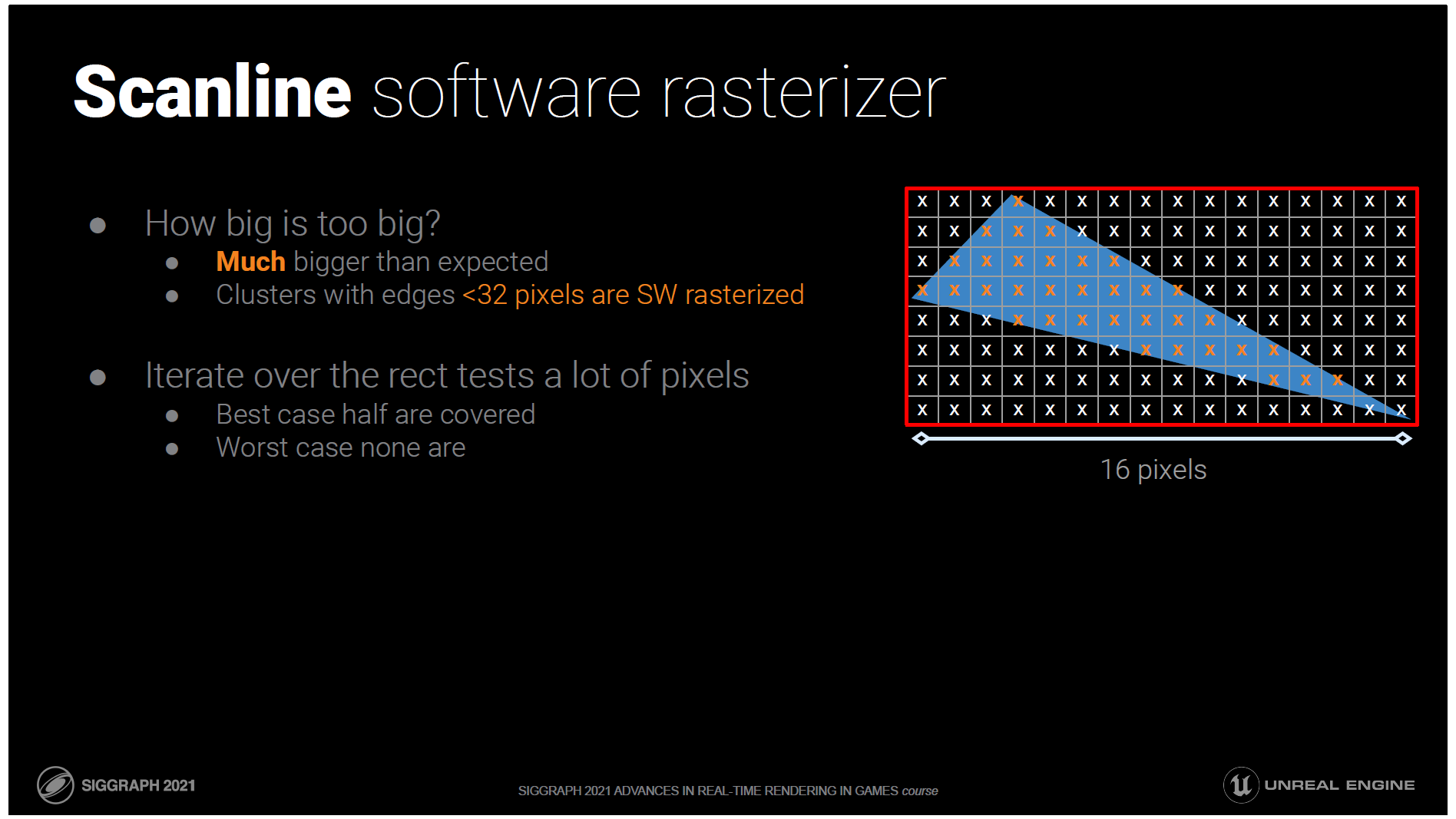
どのくらいの大きさの三角形ならいいのでしょうか?
マイクロポリをはるかに超える、予想以上に大きな三角形でハードウェアを打ち負かすことができることがわかりました。
三角形の長さが32ピクセル以下のクラスターは、ソフトウェアでラスタライズします。
そうすると、反復処理するための矩形内のピクセル数が多くなってしまいます。
最良の場合、半分しかカバーされません
最悪の場合、1つもカバーされません
きっとこの両極端の間に何かできることがあるはずです。
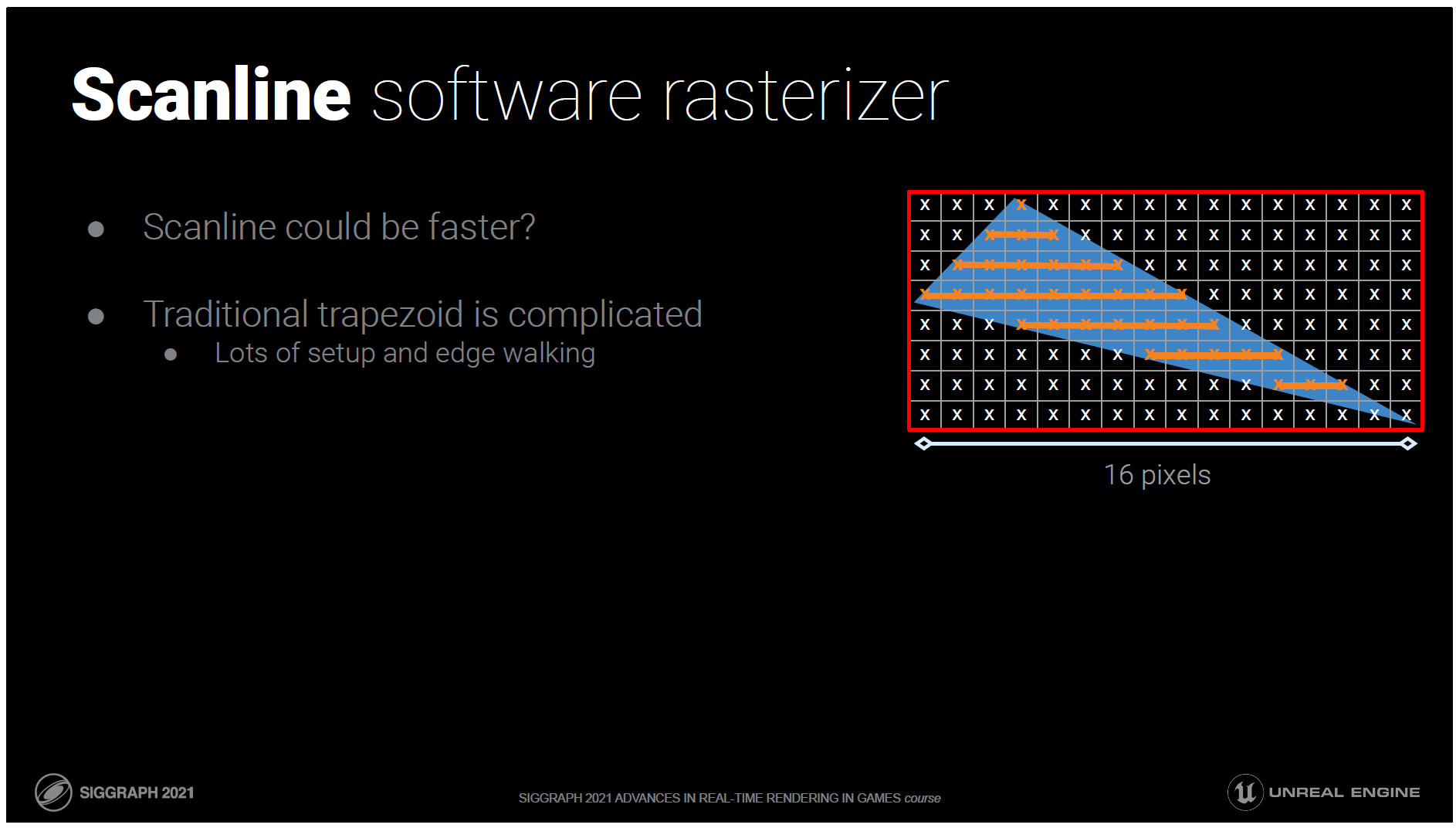
スキャンラインの方が速いのでは?
従来の台形のアプローチでは、エッジウォーキングなどがあり複雑です。無茶をするのはやめましょう…。
我々は意図的に内側のループをシンプルにして、余分な三角形のセットアップコストを削減しようとしています。
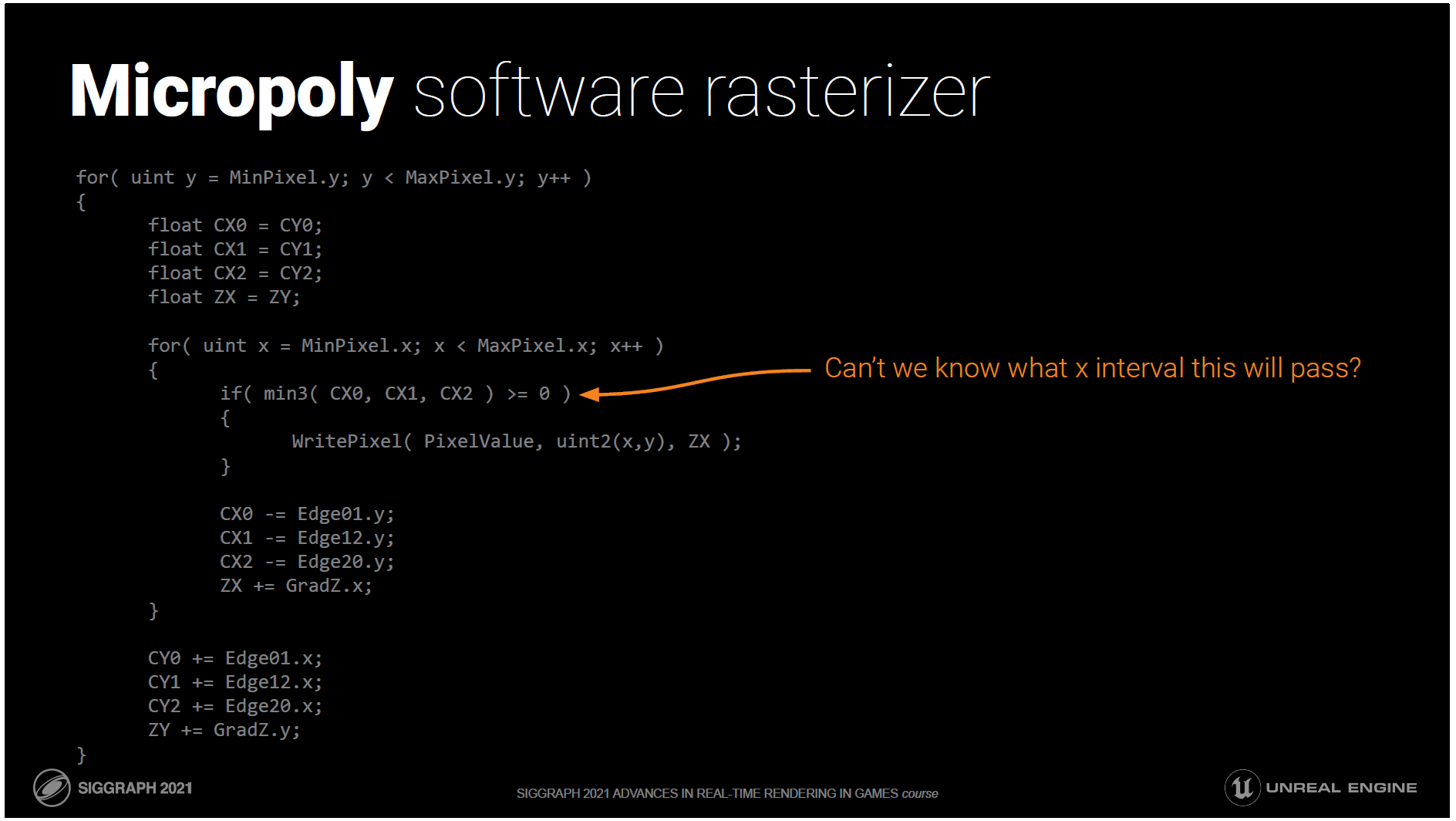
もう一度、そのコードを見てみましょう。
なぜ、各ピクセルがカバーされているかどうかを個別にテストする必要があるのでしょうか?
テストが合格するX間隔を知ることはできないのでしょうか?
簡単です,Xを解けばいいのです.
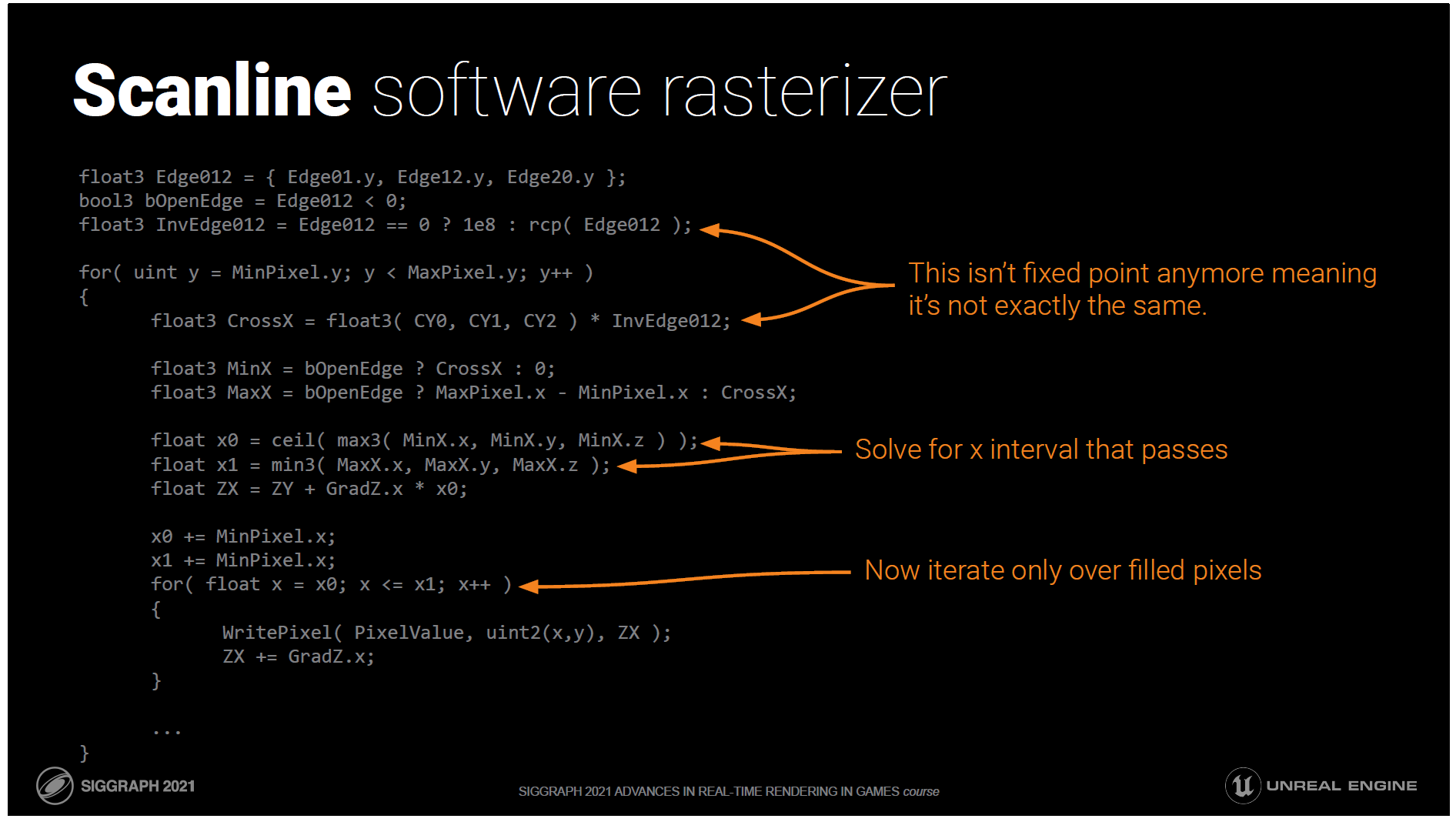
さて、これがスキャンライン・ラスタライザです。
内側のループがrectのminからmaxまで反復して、このピクセルがinかoutかをテストする代わりに、通過するx間隔を解決して、それらの上でのみ反復します。
分割により正確な固定小数点演算ではなくなってしまいましたが、実際には何の問題もありません。
ウェーブ中のどの三角形でも、Xループが4ピクセル以上の場合は、スキャンラインバージョンを選択します。
——
Bonus:
[71]でも同じようなアプローチをしていますが、当時は気付きませんでした。
より大きな三角形のピクセル書き込みのための何らかの作業配分が、私たちが持っているものよりも速くなる可能性は十分にあります。私たちのスキャンライン・ラスタライザが勝つ範囲で速くなるか、SWラスタを選択するための閾値を高くするかのどちらかです。
疑いもなく、ウェーブには、早く出てくる後ろ向きの三角形、数ピクセルしかカバーしない小さな三角形、スキャンライン・ラスタライザを起動させる可能性のある大きな三角形があり、かなりの量の分岐があります。
作業を均等に分散させることで、そのためのオーバーヘッドが少なければ、非常に大きな利益を得ることができます。残念ながら、三角形のセットアップ状態は非常に大きなデータ量になります。
レジスタ数としては小さいですが、グループ共有としては大きいです。
また、内側のループはほとんど何もせず、ALU命令とatomic maxを数回実行するだけであることを覚えておく必要があります。
潜在的にインパクトのある、しかし未検証の将来の仕事。
これを書いてから実際にテストしてみましたが、私のテストでは勝てませんでした。三角形が大きくなって作業を分散させた方が速くなる点では、HWラスタライザの方がまだ速い。
基本的にこの2つの間には中間点がありません。可能性がないわけではありませんし、ハードウェアアーキテクチャーによって変わる可能性もあります。ただ、この問題に関する私の最新のテスト結果を報告するだけです。
我々のアプローチをdepth cullハードウェアで計算するのは興味深いことです。
ラスタライズ時にマテリアルシェーダーを実行しないので、マテリアルシェーダーに関係するものは無視してください。マテリアルについては次に説明します。
心配するような高価なピクセルシェーダーはありませんが、マイクロポリの場合、トライアングルはピクセルワークのようなものです。
トライアングルごとのカリングはありませんが、これはハードウェアのEarlyZがないのと同じです。
通常は問題になりませんが、この画像のホットスポットのように、サーフェスがクラスタ境界のサイズよりも近くでオーバーラップしている場合があります。
この画像のホットスポットのように、クラスタ境界の大きさよりも近くで重なっていたり、小さな穴があったりする場合は、効率的なカリングを行うために、より細かい粒度でカリングを行う必要があります。
穴だらけは、コンテンツの問題のように聞こえますが、実際には葉や草のようなほとんどの集合体の形状のケースを表しています。
オーバードローは、Naniteがこれらの問題にうまく対応できない多くの理由のひとつです。
また、クラスタ単位でのHZBカリングはありますが、ハードウェアHiZもありません。
緻密なメッシュの場合、クラスターはHiZタイルと同じような大きさになる傾向があるので、この例えは正しいと思います。
あたかもHiZだけでカリングを行っているかのように考えることができます。
これまでは三角形の作業についてのみ説明してきましたが、ピクセルフィルにもコストがかかります。
メッシュは必ずしも高密度ではありません。三角が大きければクラスターも大きいです。
クラスターが大きければ大きいほど、カリングの粒度はピクセル単位で粗くなります。
つまり、トライアングルが大きくなると、ピクセルのオーバードローが増えます。
興味深いことに、三角形をたくさん描いた方が実際には速いという状況もあります。
——
Bonus:
三角形ごとのオクルージョンカリングは、2パスのオクルージョンを行うために行われません。
オクルージョンカリングされた三角形を持つクラスターは、評価とラスタライズを再度行う必要があり、せっかくの節約効果が失われてしまいます。
また、トライアングルごとに1つのスレッドをマッピングしているため、ダイバージェンスの問題もあります。
ウェーブ内のすべてのトライアングルがカリングされるか、最も長いスレッドを大幅に減らすことができなければ、大きな節約にはなりません。
ハードウェアHiZと同様に、HZBに保存されている平面方程式などのデータを増やすことで、カリング率が向上することがわかりました。
多くの小さな三角形がそのタイルに寄与していると仮定すべきなので、三角形の平面方程式を利用することはできません。
このため、HiZデータをストリーミングで構築することは非常に難しく、効果的に使用するにはオクルーダーの融合が必要になります。
現在は、前フレームのHZBを利用しているので、ストリーミングする必要はありません。
デプスプレーンなど、必要に応じてフィットさせることができます。
しかし、ここで説明した問題を改善しようと思ったら、何らかの形でHiZデータをストリーミングする必要があります。
オクルージョンカリングを前フレームの深度に依存していることは、Naniteの最大の欠陥の一つです。

小さな三角形には最適化しましたが、小さなインスタンスではどうでしょうか?
メッシュ全体が数ピクセルしかカバーしていない場合はどうなるのでしょうか?
クラスタの階層化はそこまでしかできません。128個の三角形からなる1つのルートクラスタで終わります。
この時点で、コストは解像度に比例しなくなります。スケーリングを完全に止めてしまいます。
しかし、それは本当に小さいことで、小さくなったときにインスタンスをカリングすることができます。
ただし、それが構造的なビルディングブロック、例えば遠くから見た建物の壁の部分であれば別です。
小さなインスタンスをカリングすると、ビル全体が消えてしまう可能性があります。
これはどのくらいの頻度で起こるのでしょうか?これに対処する価値はあるのでしょうか?
Naniteを手にして以来、私たちのアーティストはポリゴン数と同じくらい、いやそれ以上にインスタンス数を増やしてきました。
オフィスでは、インスタンスは新しい三角形だと言われています。
このことは私たちが改善しようとしている多くの事柄に影響を与えていますが、小さなインスタンスは絶対に問題でした。

いずれはマージする必要があるでしょう。明らかに遠く離れた領域は、いずれ安価なプロキシにストリームアウトする必要があります。
インスタンスのレンダリングコストを完全にスケールアップできたとしても、それを保存するためのメモリはスケールアップできません。
トランスフォーム自体も、ある時点で負担が大きくなります。
将来的には階層型インスタンスをサポートしてこの方程式を変えたいと考えていますが、すべてのケースに当てはまるわけではありません。
そのためには、汎用的なマージが必要ですが、それにはユニークなデータが必要です。
高解像度のユニークなデータは、あっという間にコントロールできなくなります。
ワールドスケールでメガテクスチャーやメガジオメトリのような制限をかけたくはありません。
理想的なジオメトリは、すべての距離でロスを感じさせないピクセルパーフェクトです。
ですから、マージされたプロキシは可能な限り遠ざける必要があり、その前に解決策が必要なのです。

私たちの現在の解決策は、ビジビリティバッファー・インポスターです。
これは基本的な静的インポスターで、色やgbuffer属性を保存しないという小さな工夫がされています。
それらはルートクラスタからの深度とトライアングルIDを保存します。
これは、スクリーンの可視性バッファに直接注入することができ、マテリアルのリマッピングをサポートします。
不均一なスケールやその他すべてのNaniteのサポートにも対応しています。
場合によっては品質の低下が見られることもありますが、これに切り替えると、時には、ポップが気づくこともあります。
通常は、同じメッシュが隣り合っている場合にのみ発生します。例えば、壁の部分が繰り返されているような場合には、一括して変更され、比較するものが直接隣り合っているため、切り替えが顕著になります。
ほとんどの場合、うまく機能しています。
これを、同じくらい高速で、メモリ消費量が少なく、真の意味でシームレスなものに置き換えたいと思っています。

では、次にマテリアルについて説明します。

これは、以前に取り上げたものと同じですが、Naniteに関連してより詳細に説明しています。
ビジビリティバッファをデコードした後は、基本的にピクセルシェーダが通常実行しなければならないものがすべて揃います。
つまり、画面を覆う四角形を描き、ビジビリティバッファをデコードして、ラスタライズ時にバインドされたようにマテリアルピクセルシェーダを評価することができます。

頂点変換はNaniteの固定機能かもしれませんが、アーティストが作成したピクセルシェーダーを完全にサポートしたいと考えています。
そのため、すべてのピクセルに1つのマテリアルだけを使用することはできません。
このピクセルがどのマテリアルを持っているのか、どうやって知ることができますか?
ビジビリティバッファからも導出できます。
呼び出し可能なシェーダーを使えば、理論的にはこの方法で1回のパスですべてのマテリアルを適用することができますが、そこには複雑さと非効率性があります。

その代わりに、ユニークなマテリアルごとにフルスクリーンの矩形を描くことができます。
そして、このマテリアルIDに一致しないピクセルをスキップします。
残念ながら、カリングはすべてGPUで行われるため、CPUはどのマテリアルが表示されているかを認識していません。
マテリアルのドローコールは、それに関係なく発行されなければなりません。
すべてのマテリアルに対してすべてのピクセルをテストするのは、非常に非効率的です。

大量のピクセルをカリングして、生き残ったピクセルを効率的にウェーブに詰め込むハードウェアがあります。
ステンシルが一番近いと思いますが、マテリアルごとにテストをやり直したくはありません。
そこで、深度テスト用のハードウェアを利用することにしました。
マテリアルIDが深度の値になります。
コンソールでは、メモリをエイリアスしてレイアウトを把握することができるので、これを効率的に行うことができます。
コンピュートシェーダでは、後のパスで使用するマテリアルデプスとスタンダードデプスの両方を出力します。
深度バッファに加えて、HTILEも出力されるので、HiZアクセラレーションが得られます。
すべてのマテリアルについて、フルスクリーンの四角形を描き、その四角形のZ値をマテリアルの深度とします。
深度テストはequalsに設定されているので、一致するIDのピクセルのみを描画します。
——
Bonus:
ディファードマテリアルに対してdepth equalsテストを使用するというアイデアは、Dawn engine[50]から来ています。
このテストでは、マテリアルのスクリーン矩形を使用するオブジェクトの最小/最大の原子によって、スクリーン矩形でカバーされるピクセルを減らします。
これらの画像を見るとわかるように、同じマテリアルが画面の反対側のオブジェクトに割り当てられることは非常によくあることなので、今回のケースではあまり効果的ではありません。
次のスライドで説明するタイルアプローチでは、この問題はありません。
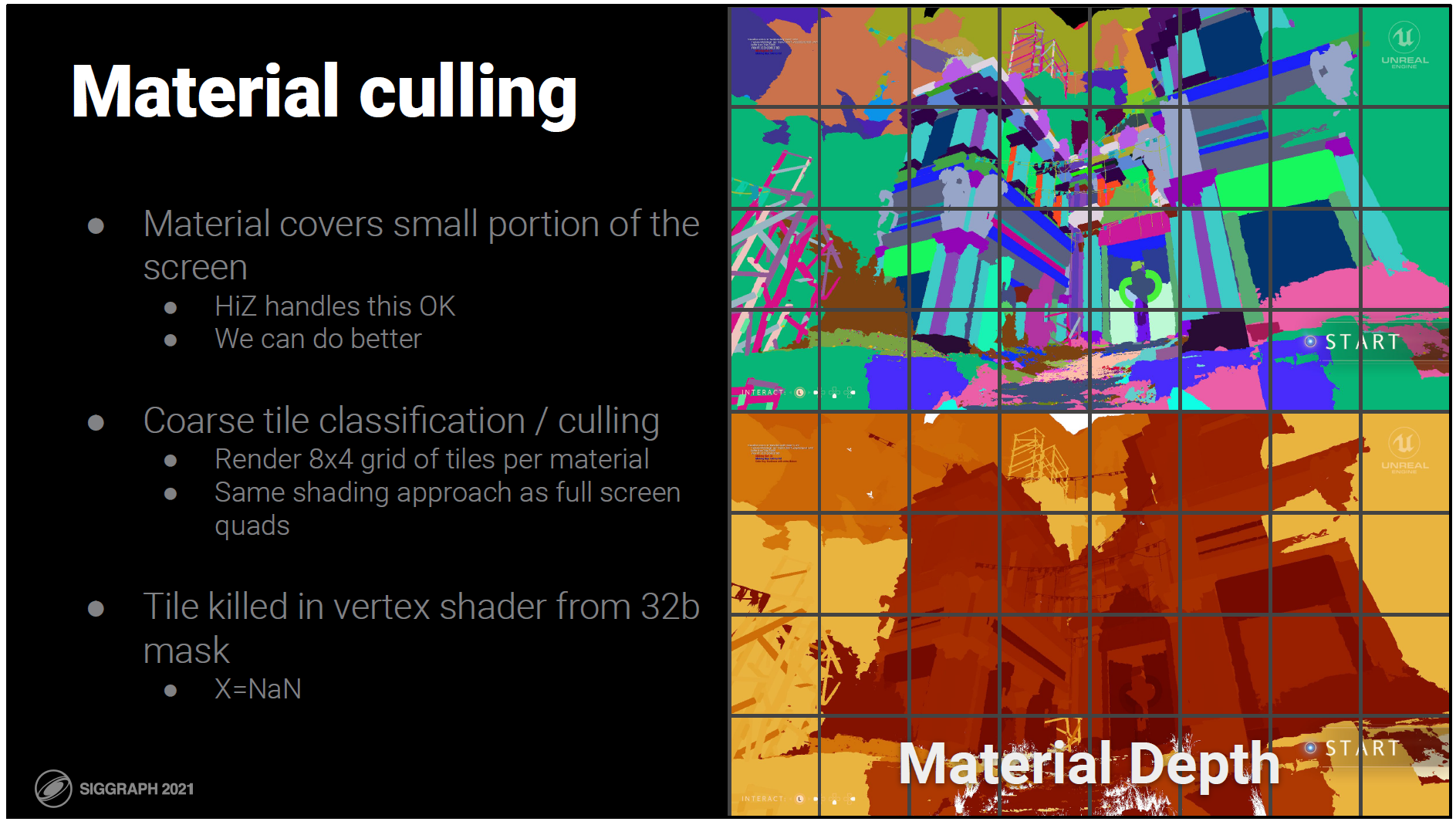
ほとんどのマテリアルは、画面のほんの一部しかカバーしていません。
HiZ cullsでは粗いカリングをかなり行っていますが、もっとうまくできるはずです。
フルスクリーンの四角形の代わりに、タイルのグリッドを描きます。このタイルは、マテリアルの深さを変更したときに作成された32bのマスクに従ってカリングされます。
これは現在、大幅に作り直されている部分で、将来的には完全に計算できるようにしたいと考えています。
ここまで説明したのは、今回紹介した2つのデモでのコンソールパスの仕組みです。
——
Bonus:
カリング用にマークされたタイルは、バーテックスシェーダでXをNaNにスナップして殺され、ピクセルシェーダのウェーブがスピンするのを防ぎます。
可能であれば、矩形プリミティブを使用して、対角線のオーバーシェードの非効率性を回避します。
残念ながら(そして驚くべきことに)、PCのAPIはまだエレガントで一貫したサポートをしていませんが、コンソールではこれを利用しています。
タイルグリッドの解像度は、wave intrinsicsが利用可能かどうかによって異なります。
Wave Opsがサポートされている場合、マテリアルごとに8×4のグリッドを作成し、32ビットのマスクで表現します。各ビットはこれらのタイルの1つに対応します。
ポータブル(wave intrinsic無し)バージョンでは、64×64のグリッドがあり、64ビットのマテリアルのマスクを計算します。このスキームはビンをエイリアスすることができるので、敗北する可能性がありますが、すべてのことを考慮すると、意外とうまくいっています。エイリアシングはカリングの効率を少し落とすことになりますが、それでも少なくとも深度でカリングしていることには変わりありません。

マテリアルはまだコヒーレントなピクセルシェーダなので、テクスチャフィルタリングに使用する有限差分ベースの微分があります。
従来のラスタライズとは異なり、ピクセルクアッドはトライアングルにまたがっています。
これは非常に良いことです。小さなトライアングルでは、クワッドのオーバードローはすぐに手に負えなくなります。
しかし、クォードは深度の不連続性、UVシーム、さらには異なるオブジェクトにも及びます。
これはよくありません。
不連続部分の有限差分は無意味であり、しばしば巨大なものとなり、この画像のアーティファクトのように高いミップレベルが使用されることになります。

その代わりに、三角形の属性の解析的な微分を計算します。
この導関数は、アーティストが作成したノード・グラフに連鎖則を用いて自動的に伝搬されます。
解析的に微分できない操作が発生した場合は、有限差分法に戻ります。
その代わりにレイディファレンシャルのようなものに頼ってもいいのですが、今のところ問題はありません。
すべてのSampleの呼び出しは、我々の勾配を使用してSampleGradに置き換えられます。
このようなことをすると、かなりのコストがかかるように見えますが、私たちのマテリアルではオーバーヘッドは2%以下と測定されています。
これが小さい理由は、追加作業がテクスチャのサンプリングに影響を与える作業だけだからです。
また、すべての仮想テクスチャサンプルは、すでにSampleGradを使用してタイルの不連続性を処理しています。
——
Bonus:
Unrealにはアーティストが作成したマテリアルシェーダーがあるので、これらを普及させるための体系的なアプローチが必要です。
数学的には、各操作に連鎖則を適用するという単純な問題です。
理想的には、OSLのようなシェーダーコンパイラーの一部となるでしょう。
代りとして、ノードグラフをHLSLに変換する時点で行われます。
[77], [78]

これで、プライマリビューのレンダリングパイプラインの最初から最後までを網羅することができました。
それぞれの段階でどのような数字が出てくるのかを見てみましょう。
UE4 の標準的なレンダリング パスを使用してこのフレームをレンダリングした場合、10 億個以上のトライアングルをラスタライズする必要があります。
一方、Naniteでは、インテリジェントなLOD処理とカリングにより、2,500万個のトライアングルをラスタライズしています。
この25Mという数字は、シーンがどれほど複雑であっても、デモ全体を通して一貫しています。
しかも、この作業を非常に高速に行うことができます。

このデモでは、ダイナミックな解像度と4Kへの時間的なアップサンプリングを使用しています。アップサンプル前の平均フレームは約1400pで推移しています。
すべてのジオメトリのカリングとラスタライズを行っています。
GPUシーンとビューからラスタライズされたビジビリティバッファの完成まで、平均で2.5msかかります。
これはすべてGPUによるものなので、CPUコストはごくわずかです。
マテリアルの適用とビジビリティバッファのGBufferへの変換には、平均2msかかります。
これには、マテリアルごとに1回の描画を行うため、わずかなCPUコストしかかかりません。
60hzのゲームであれば、十分に予算内です。

ジオメトリを描く必要があるのは、プライマリビューだけではありません。影も必要です。
セカンダリービューにマイクロポリレベルのディテールが本当に必要なのでしょうか?

間接照明ではないかもしれませんが、影にはディテールが必要です。
実際、実際のジオメトリとノーマルマップの間の最大の視覚的な違いは、ほとんどの場合、詳細なセルフシャドウイングから生まれます。

レイトレースは可能でしょうか?
残念ながら、1ピクセルあたり平均して1つ以上の光が存在するため、プライマリレイよりもシャドウレイの方が多いです。
少なくとも、プライマリ用にあるものと同じくらいの速度が必要です。
たとえトレーシングが十分に高速であったとしても、ハードウェアのレイトレーシングAPIは、現在のところ、以下のように十分な柔軟性がありません。
- 複雑なLODロジックを評価する。
- それらの特殊な三角形のフォーマットに合わせて、メモリを大量に肥大化させないためです。
- また、BVHを部分的にアップデートする機能がないため、一から百万単位の高価なBVHを作る必要がありません。
将来的にはレイトレーシングのNaniteについても検討する予定ですが、今は他の作業を活用するためにラスターソリューションが必要です。
1ピクセルあたりの光の数は、本当に真剣に考えなければなりません。
影のせいでNaniteのコストが暴走しないようにすることが非常に重要です。
ありがたいことに、ほとんどのライトと、そこから影を落とすほとんどのジオメトリは動きません。
この作業をキャッシュすることができれば、この問題を抑えられる可能性があります。
——
Bonus:
予測ですが、レイトレーシングのコヒーレントなレイに対する優位性は、無関係な作業をカリングすることにあります。
従来のラスターパイプラインと比較して、レイトレーシングは、もはや共有できない重要な作業を補うために、かなり少ないトライアングルを処理することができます。
このカリングの優位性は、Naniteに対しては劇的に減少し、コヒーレントレイに対するトレーシングの速度が低下することはほぼ確実と思われます。
もちろん、試してみるしかありません。
HWのトライアングルフォーマット+BLASは、属性を含んだメモリーフォーマットの3〜7倍のサイズになります。属性なしで直接比較すると、その比率は60%ほど悪くなります。
圧縮された三角形とBVH構造の開発は本当に重要です。

Naniteは通常のシャドウマップ描画に対応していますが、この新しいアーキテクチャにより、これまで実用的ではなかった新しい手法が可能になりました。
これにより、効率的な仮想シャドウマップを実装することができました。
現在では、すべてに16kシャドウマップを使用しています。
ライトの種類によっては、1つまたは複数のシャドウマップがあります。
シャドウマップにラスタライズされる解像度は、それらのトライアングルがキャストされるスクリーンピクセルと一致するように作られています。
シャドウマップの領域がスクリーン上の何にもキャストされない場合、そこには描画しません。
シャドウレンダリングを最適化するための一般的なアプローチと比較して。
ラスタライズ作業をカリングしているだけでなく、サンプリングしないシャドウマップ空間にメモリを割り当てることもありません。

これらの16kシャドウマップは、仮想化されており、スパースになっています。
ページサイズは128なので、mip0は128×128ページです。
フレームごとの仮想メモリの割り当ては非常に簡単です。
- 画面の各ピクセルごとに
- このピクセルに影響を与えるすべてのライトについて
- 位置をシャドウマップ空間に投影
- 1テクセルが1画面のピクセルサイズに一致するミップレベルを選ぶ
- 必要に応じて、そのレベルでそのページをマークします。
キャッシングにも対応しているので、前のフレームですでにカバーしたシャドウマップのどこかを描くことは避けています。
つまり、各フレームで更新されるシャドウマップの領域は、ほとんどの場合、オブジェクトが動いている部分や、カメラの移動に伴うフラスタムのエッジのみです。
——
Bonus:
テクセルサイズの計算では、パースペクティブワープのみを考慮しており、プロジェクション(拘束されない)は考慮していません。
これは、シャドウマップの投影に対する表面の傾きを使用しないためです。
これは通常、ミップマップレベルの計算のために行われますが、少なくとも、これまでにテストしたコンテンツでは、実際にはノイズが多すぎます。
境界がないので、クランプする必要があり、このようなごつごつした岩は、すべてのページ選択を限界まで押し上げるので、基本的に限界はグローバルミップバイアスになります。
もしほとんどの表面が滑らかであれば、それは良いアイデアかもしれません。
ミップセレクションではプロジェクション・ワープを考慮していないため、プロジェクション・エイリアシングが発生します。

すべてのメッシュの仮想シャドウマップへのレンダリングをサポートしていますが、Naniteとの組み合わせは、まさにその真価を発揮します。
しかし、その前に、Naniteのレンダリングを効率化するために、いくつかの修正を加える必要がありました。
そのため、各ライトに対して一度のように
さらに悪いことに
ミップレベルごとに
シャドウマップごとに
それぞれのライトに対して
Naniteのレンダリングを何度も呼び出さないようにしています。
その代わり、Naniteにマルチビュー対応をしました。
Naniteのパイプラインは、1つのビューではなく、複数のビューの配列を取得してレンダリングします。
これにより、Naniteは依存性のあるディスパッチ・インダイレクトの単一のチェーンでシーン全体を描画できるだけでなく。シーン内のすべてのライトのすべてのシャドウマップを、仮想化されたミップマップのすべてに一度にレンダリングできます。
極端なケースでは、個別の呼び出しに比べて100倍ものスピードアップが見られます。

シャドウマップのマッピングされていない領域に描画するワークを選別するために、通常はHZBに対してバウンディング・レクトをテストする場所の隣に、追加のテストを挿入しました。
シャドウでは、必要なページマスクに対してもテストを行います。
インスタンスまたはクラスターが必要なページと重ならない場合は、カリングされます。
書き込んでいる物理的なテクスチャは、仮想空間では連続していません。
つまり、複数のページに重なっているクラスターは、ピクセルのアドレッシングが直接行われることを期待できません。
これを処理するために複数のアプローチがあります。
ソフトウェアラスタライザでは、内部ループをできるだけシンプルにすることが望ましいです。
我々は、内部ループのたった1つの追加シフトでも測定可能であることを発見しました。
そこで、オーバーラップしたページごとに1つの可視クラスタをラスタライザに送信し、クラスタに対して1回のページ変換を行い、ページピクセルに対してシザーを行うようにしました。
SWのクラスターは小さく、ほとんどが1ページに重なっています。
ハードウェアのクラスターは大きく、複数のページに重なることが多く、頂点やトライアングルのコストを重複させることは意味がありません。
その代わり、ピクセルごとに仮想から物理へのページテーブル変換を行います。
アトミックなUAV書き込みを行っているので、HWパスであっても、自由にスキャッターすることができます。

Naniteの細やかなカリングは、効率的な仮想シャドウマップに大いに役立ちますが、ディテールのレベルも同様です。
プライマリービューと同様に、Naniteは1ピクセルの誤差に合わせてLODを選択します。
シャドウの場合、これはラスタライズ先のミップレベルのピクセルを意味します。
ミップレベルは、1テクセル=1ピクセルとなるように選択されています。
これにより、シーンの複雑さではなく、スクリーンの解像度に応じてコストがほぼスケーリングされるという特性が維持されます。
ただし、シャドウマップに描画されるトライアングルが、プライマリビューに描画されるトライアングルとまったく同じであるということではありません。
その不一致は、正しくないセルフシャドウイングの原因となります。私たちは、両者が異なる可能性のあるゾーンにまたがるように、短いスクリーンスペースのトレースでその不一致に対処します。
——
Bonus:
実際には、シャドウレンダリングに対してNaniteのLODバイアスを適用し、プライマリに対するシャドウレイの乗数を考慮しています。デフォルトでは2ピクセルの誤差があります。
プライマリビュートライアングルとシャドウマップトライアングル間のミスマッチをスクリーントレースで処理する必要がすでにあるため、このディテールの減少はほとんど目立たず、節約する価値があります。
ジオメトリの仮想メモリのアナロジーは、概念的には仮想テクスチャリングと非常によく似ていますが、詳細は異なりますし、いくつかのユニークな課題もあります。
GPUが品質不足と判断したデータを要求し、CPUがディスクからデータを読み込むことで非同期的にその要求を満たすという点が似ています。
しかし、データをロードしたりアンロードしたりする際には、データが常にDAG全体の有効なカットであることを確認する必要があり、ジオメトリにクラックが生じないようにするという点で異なります。

では、何をストリームするか?ストリーミング可能な最小単位は何でしょうか?
単純化はグループレベルで行われることを思い出してください。
構造上、クラスタグループはその親で正確に置き換えられます。
逆に親は、子の完全なグループでしか置き換えられません。
つまり、グループ内のすべての兄弟が読み込まれる前にクラスタのレンダリングを開始することはできず、そうでなければ完全な置き換えにはなりません。
したがって、グループよりも細かい粒度でストリームを行う理由はありません。そんなことをしたら、間違ったレンダリングになってしまうかもしれません
仮想テクスチャリングとのもう一つの違いは、圧縮前であってもジオメトリのサイズが可変であることです。クラスタは、頂点数、アトリビュート数などが変化します。
メモリの断片化を避けるためには、固定サイズのページを使用したいところですが、これは同時に、ページあたりのジオメトリのサイズが可変であることを意味します。

そこで、固定されたサイズのページをクラスター・グループで埋め尽くします。
どのグループを同一ページに配置するかを決める際には、空間的な位置関係とDAG内のレベルの両方を考慮します。
これは、実行時に必要となる可能性のあるページ数を最小限にするために行っています。
最初のページであるルートページは常に常駐しており、1ページに収まるだけのDAGの先頭部分を含んでいます。
ルートページが常にあるということは、何があっても、常にレンダリングするものがあるということです。
常駐ページは、GPU上の1つの大きなByteAddressBufferに格納されます。

残念なことに、グループ全体でページを埋めると、グループが非常に大きくなることがあるため、多くのスラックが発生してしまいます。
8~32個のクラスターがあり、各クラスターは最大で約2KBになります。
我々の解決策は概念的にシンプルです。グループをクラスターの粒度で複数のパーツに分割します。
前述のように、クラスターはその兄弟がすべて読み込まれる前には描画できないため、分割されたグループはそのパーツがすべて読み込まれたときにのみアクティブとみなされます。
グループではなく、クラスター粒度でページを埋めることで、約1%の無駄しか発生しません。
——
Bonus:
便宜上、これらのパーツは常に連続したページに割り当てられ、グループのページを常に1つのページ範囲として要求できるようになっています。
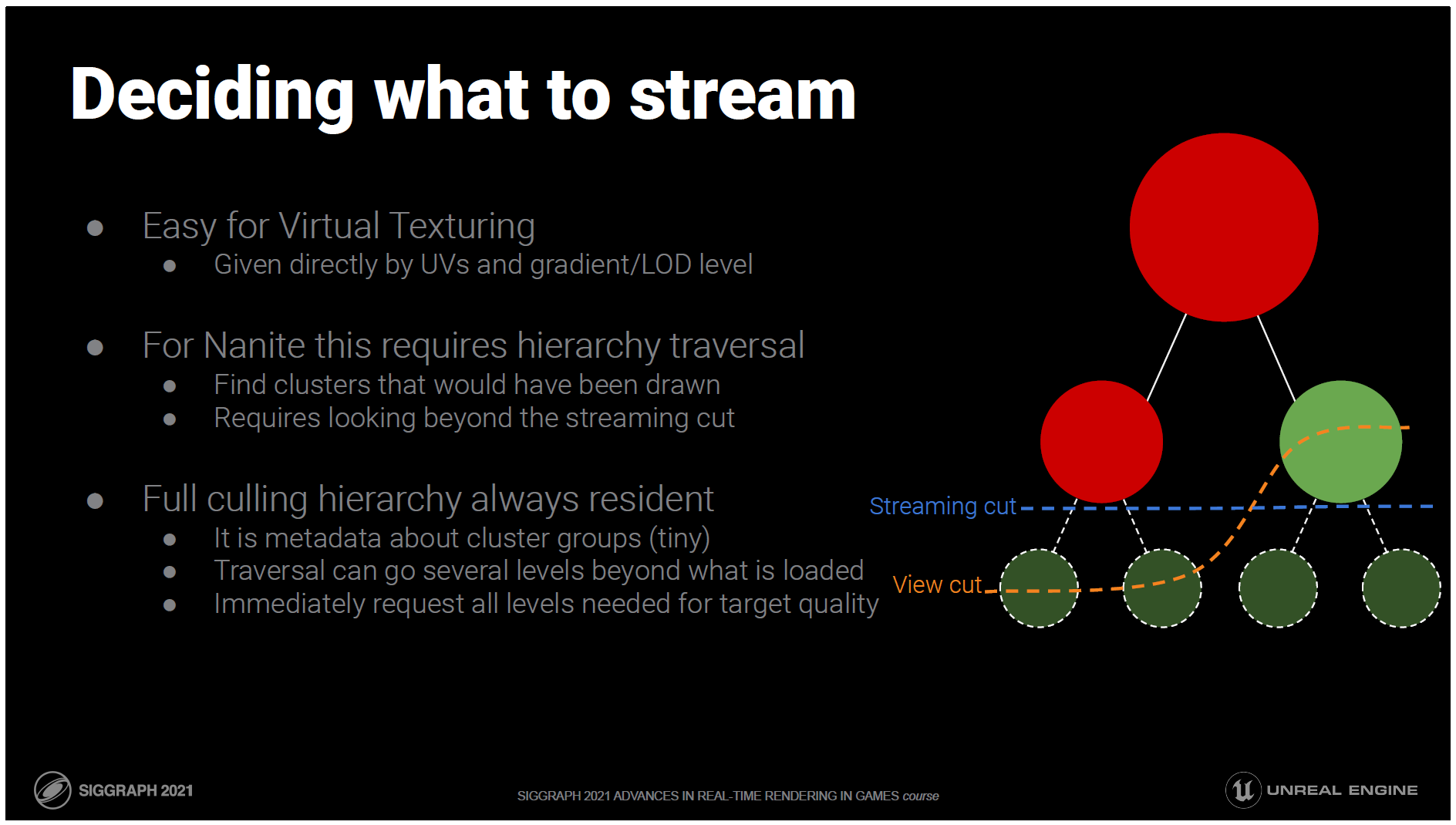
では、どうやってロードするものを決めるのでしょうか?
仮想テクスチャーの場合は簡単です。読み込むべきデータは、UV座標と選択されたLODレベルまたはUVグラデーションから直接決定できます。
Nainteの場合は、クエリの位置とLODエラーから直接データを見つけることができないので、階層をたどってデータを見つけなければなりません。
その際、現在のストリーミングカットの先にあるノードを見て、もしそれらが常駐していたら描いていたかどうかを判断しなければなりません。
つまり、カリングの階層は、現在ストリーミングされているものよりも多くをカバーする必要があります。クラスタグループの頻度に関するメタ情報しか含まれていないため、階層は小さく、簡単にするために、常に完全な階層を常駐させています。
これには、トラバーサルが現在のストリーミングカットに依存せず、その先の数レベルにまで及ぶことができるという利点があります。
新しいオブジェクトは、目標とする品質に必要なすべてのレベルのデータをすぐに要求することができます。
階層自体もストリーミングされていたら、数フレームに渡ってレベルごとに行わなければなりません。
IOレイテンシーは、オフになっているレベルの数だけ乗算され、より目に見える形でポップインすることになります。

実際には、ストリーミングリクエストは、階層的なクラスタカリングのトラバーサルの一部として生成されます。
リクエストは、LODエラーに基づく優先度を持つページの範囲で構成されます。
リクエストはプライマリビューだけでなく、アクティブなシャドウビューに対しても生成されますが、これらは優先度が低いと考えられます。
また、リクエストは、優先度を更新するために常駐しているページに対しても発行されることに注意してください。
リクエストはCPUによって非同期的に読み返されます。CPUは不足しているDAGの依存関係を追加し、最も優先度の高いページに対してIOリクエストを発行します。
また、優先度の低いページを退避させてメモリに空きを作ります。
最後に、IOリクエストの準備が整うと、ページデータがGPUにインストールされ、GPU側の日付構造が更新されます。
これには,ロード/アンロードされたページのポインタの修正も含まれます.
完成した、または完成していない分割グループのポインターを修正します。
また、クラスターをリーフとしてマークしたり、マークを外したりすることも含まれます。

最後に紹介するのは圧縮です。

Naniteでは、実際に2つの圧縮ジオメトリフォーマットを用意しています。
これらは同じデータを表していますが、異なる目的のために最適化されています。
メモリ表現は、ラスタライズ時やディファードマテリアルパスなど、レンダリングコードで直接使用されるものです。
これはデコードがほぼ瞬時にでき、任意のトライアングルが可視性バッファのルックアップから要求されるため、ランダムアクセスである必要があります。
ここでの目標は、ストリーミングプールに必要なメモリを少なくすることです。
仮にメモリに余裕があったとしても、より多くのデータをキャッシュに収めることでキャッシュミスが減り、IOやポップインの変更が少なくなります。
データがストリーム入力されると、メモリ表現にトランスコードされる別のディスク表現があります。
このフォーマットはランダムアクセスを必要とせず、ストリーミングはレンダリングよりも低い頻度で行われるため、ここではより高度な技術を使う余裕があります。
ディスク上のデータは、ある種のバイトベースのLZアルゴリズムによって圧縮されると想定しています。
つまり、この表現の目的は、圧縮後のディスクフットプリントを最小にすることです。

メモリ表現では、まず、アーティストによる明示的な制御とヒューリスティックな手法を組み合わせて、位置と様々な属性をグローバルに量子化します。
クラスタは、これらの量子化された値を、クラスタ内の値の最小/最大範囲に対するローカル座標に格納します。
値は、そのコンポーネントの値の範囲を表現するのに必要な最小数のビットを使用して保存されます。
つまり、メッシュ全体やすべてのクラスターで固定の頂点フォーマットを使用するのではなく、すべてのクラスターが、その範囲内の値に基づいて必要なものだけに特化した頂点フォーマットを使用することになります。
各頂点は、固定長のビット列に過ぎません。アライメントの必要はありません(バイト単位でも可)。
クラスタ内のサイズは固定幅のままなので、ランダムアクセスにも対応し、デコードも比較的簡単ですが、ビットの意味を理解するためにコンパクトな頂点宣言をフェッチする必要があります。
——
Bonus:
これについて、デコード側の注意点をいくつか。
これはレンダリングに直接使用されるフォーマットなので、GPU上のビットストリームリーダーでデコードする必要があります。
読み込みのたびにビットストリームの再充填が必要かどうかをチェックする必要がないように、読み込みごとのビットサイズのコンパイル時の上限値を指定しています。
蓄積されたコンパイル時の上限値がオーバーフローした場合にのみ、ビットストリームのビット数が不足する可能性があり、その場合にのみビットを補充する必要があることがわかっています。
特に分岐したレーンでは、これは結果的に大きな節約になります。

量子化を行う際には、特に位置に注意しなければなりません。不整合があると、ジオメトリに目に見えるクラックが生じてしまいます。
これは、単一のオブジェクトだけを考えれば何とかなりますが、実際には、オブジェクト間に生じるクラックにも対処しなければなりません。
これは、レベルのジオメトリがモジュラーピースで構成されている場合によく見られる問題で、非常に多くのインスタンス数をサポートしているため、Naniteでは推奨しています。
ジオメトリを構築する際に、メッシュがレベルのどこに配置されているかという情報がないため、オブジェクト間のネゴシエーションができないのです。
実際には、オブジェクトを同じグローバルグリッドに合わせて量子化する必要があります。
そこで、オブジェクトの原点を中心に、ユーザーが選択可能なステップサイズの累乗を用いて、オブジェクト空間で量子化を行うことで実現しています。
このステップサイズは、オブジェクトの境界で正規化されていないこと、または他の方法でオブジェクトの次元に結び付けられていないことが重要です。
すべての問題を解決するわけではありませんが、この種の量子化は、オブジェクトが同じ量子化レベル、同じスケールを使用し、それらの間の変換もステップサイズの倍数である限り、それらは同じグリッドに量子化され、それらの頂点は完全に整列することが保証されます。これは、90度の倍数の回転であれば、回転にも有効です。
これで、実際に気になるほとんどのケースをカバーすることができます。
残念ながら、これは階層のリーフレベルでしか通用しません。それ以上のLODでは、共有された境界線に沿って単純化器が異なる決定をした可能性があり、ランタイムではLODの決定は完全には同期されません。
しかし、実際には、リーフのデータのみを間近で観察することができ、LODレベルが高くなると、ピクセルの誤差がほとんどなくなるため、この方法はかなり有効です。

三角形のインデックスは回転するので、三角形の最初のインデックスは最も低いインデックスになります。
これは、クラスタに必要な最小ビット数(通常は7)を使用して保存されます。
残りの2つのインデックスは、最初のインデックスからの正の5ビットの差分として格納されます。
これは、ビルダーが三角形が32個以上のインデックスウィンドウにまたがらないことを保証していることに由来します。
UVデータでは継ぎ目が一般的なので、範囲内の最大の隙間を除外したエンコーディングを使用し、事実上、1つのコンポーネントにつき2つの範囲としています。
法線は、八面体座標に基づいたエンコーディングを使用しています。
接線は全く保存されません。三角形のUVグラデーションからピクセルごとに暗黙的に導き出されます。
これは、Naniteでよく使用される非常に高度なテッセレーションが施されたジオメトリの場合に特に有効ですが、必要な場合には明示的な接線もサポートすることを計画しています。

明示的なタンジェントフレームを保存したり補間したりする代わりに、ランタイムにそれを導き出します。
接線と従法線は結局のところ、法線平面上のUとVの方向に過ぎません。
これは、Morten Mikkelsenらが提案したスクリーン空間由来の接線空間と非常によく似ています。
ただし、実際にはスクリーン空間の導関数は使用しません。代わりに、マテリアルパスでの重心座標補間とテクスチャLOD計算のために、すでに計算する必要のある三角形のデルタを使用します。
この方法は、明示的な接線空間と比較して、連続性の問題がある可能性があります。
しかし、ハイポリモデルの場合は、一般的にはあまり問題になりません。将来的には、明示的な接線もサポートする予定です。
——
Bonus:
具体的には、Schlüler[84]からの導出に基づいています。
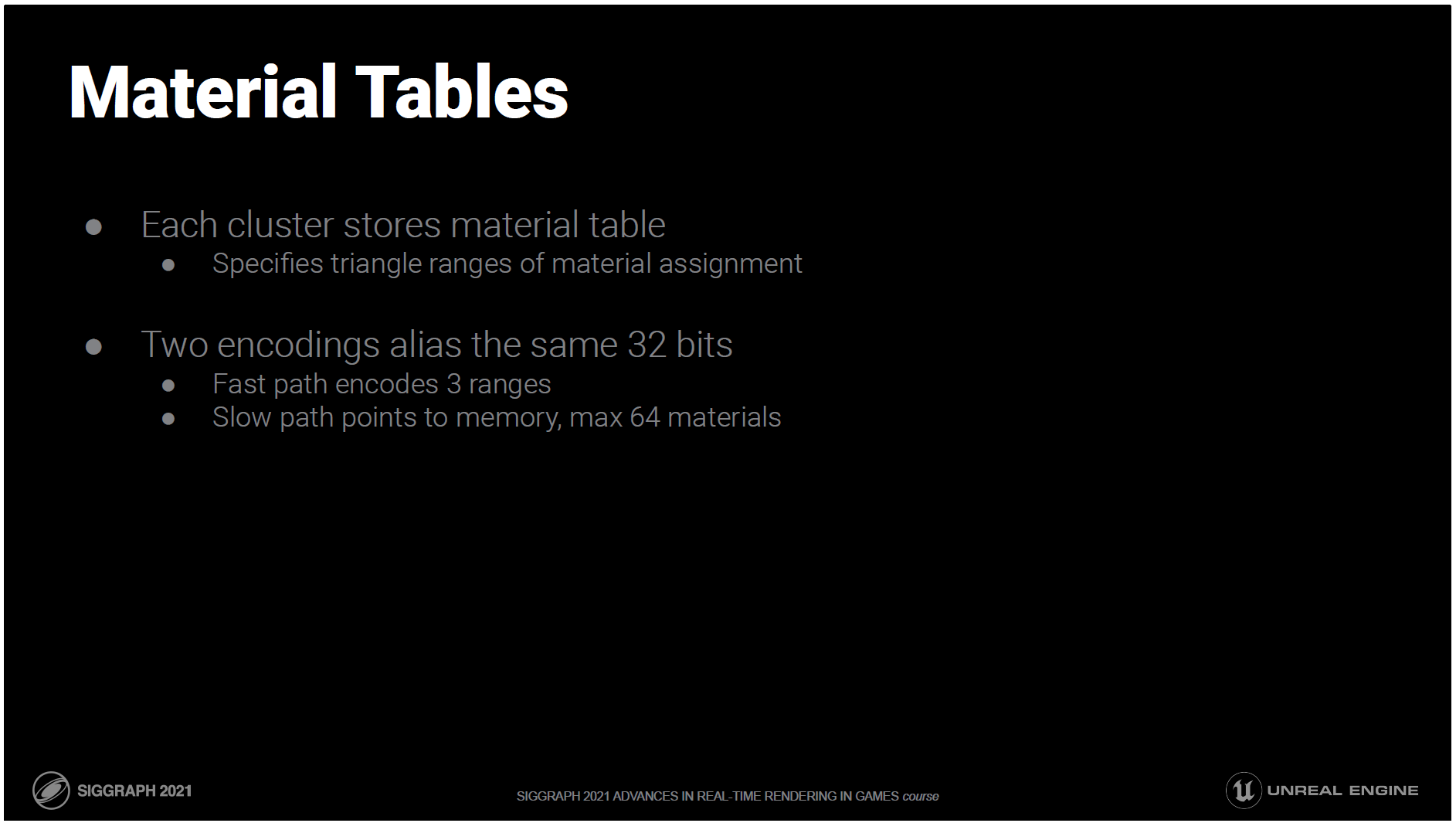
1つのメッシュには複数のマテリアルを割り当てることができます。
どのトライアングルがどのマテリアルに割り当てられているかを保存する必要があります。
これを小さくするために、クラスターには1つのマテリアルしか割り当てられないようにして、基本的には別のメッシュのように扱うこともできました。
これは単純化するには制限が多すぎますし、ビルドプロセスの亀裂という観点からは非常に複雑な処理となります。
クラスタのトライアングルデータごとに設定するのがベストです。
これを小さくするために、トライアングルはマテリアルごとに保存され、各マテリアルに関連するレンジが保存されます。
ほとんどのクラスターには3つ以下の材料が割り当てられており、テーブルは32ビットに収まります。
3つ以上の材料を持つクラスターは、最大64個の材料に対応する可変サイズのテーブルへのインダイレクトをたどります。
いずれの場合も、問題のトライアングルインデックスを含む範囲が検索されます。

ディスクの表現には、ハードウェアLZ展開をサポートするプラットフォームを利用しています。
現在、コンソールではすでに利用可能で、PCではDirectStroageで間もなく利用可能になる予定です。
ハードウェアLZ展開は、基本的にエントロピーコーディングとストリップ重複排除を行うことで、他の追随を許さない速さを実現しています。
今後、ハードウェア展開が主流になっていくことが予想されますので、それに対応したフォーマットを設計していきたいと考えています。
独自のカスタムエントロピーコーディングバックエンドを使用する新しいフォーマットを設計することは、現時点では時間の無駄だと感じています。
そこで、特別な目的を持った圧縮機を作るのではなく、データにドメイン固有の変換を適用することで、データを圧縮機に特化させ、LZ圧縮では捕捉されない冗長性に焦点を当て、LZの動作に合わせてデータをメッセージ化しています。

LZが処理するエントロピー符号化と文字列照合は本来シリアルであるため、GPUで圧縮処理を行う方がはるかに実用的です。
並列であれば、CPUで行うよりもはるかに高度な変換が可能になります。
特に、非同期計算で実行される場合は、まだ時間がなく、その必要性もありませんが。
私たちの現在のトランスコード方式は、かなり最適化されていないコードで、PS5上ですでに約50GB/sで動作しています。
また、Naniteの場合、GPUでのトランスコーディングは、GPUトランスコーダがすでに常駐しているページの親データを参照することができるので、CPUに追加のコピーを保持する必要がないという利点もあります。
——
Bonus:
また、GPUでトランスコードを行うことで、将来的にはCPUを介さずに、ドライブからGPUメモリに直接データをストリーミングできる可能性があります。
一般的に、ハードウェアによる展開とGPUによるトランスコーディングの組み合わせは強力であり、今世代ではますます多くのパターンが見られるようになると考えています。

では、LZの仕組みに合わせて、どのようにデータを加工していくのでしょうか?
LZ圧縮はバイトベースですが、完全にアラインドされていないビットストリームデータには適していません。
データをバイトアライメントまでパディングすることで、LZはより良いマッチングを見つけることができます。そうしないと、たまたま同じビットアライメントを持つ文字列しかマッチングできないからです。
これにより、圧縮前のサイズは大きくなりますが、圧縮後のサイズは大幅に改善されます。
また、パディングはエントロピーコーディングにも有効で、アラインメントされていないデータがあると、バイトの統計情報がおかしくなってしまいます。
一般的には、同じタイプのデータを近くに並べることで、マッチオフセットを最小限に抑えるようにします。
また、バイトの統計ができるだけ歪まないように、小さいバイト値を選ぶようにしています。
統計が歪めば歪むほど、エントロピーコーディングの効果は高まります。

そして次に、よりドメインに特化した変換を行います。
データをクラスタリングしてクラスタ階層を生成するプロセスでは、多くの冗長性が発生してしまいます。
メッシュを独立したクラスタに分割すると、共有されているすべてのエッジに沿って重複した頂点が生成されます。
また、単純化の際には、影響を受けない頂点があることも珍しくなく、子のソース頂点と同じになってしまいます。
このようなタイプの冗長性は、重複する頂点が他のクラスタで異なるエンコーディングを持つ可能性が高いため、一般的にLZ圧縮では認識されません。
親ページの参照の場合、データはGPUページプールでしか利用できないため、LZでは確認できません。
重複する頂点を冗長に保存する代わりに、参照が保存されます。
ストリーミングのため、どのページデータでも参照できると考えることはできませんが、ロードされたデータがDAGの有効なカットであることがレンダリングですでに要求されているため、親ページがロードされていることに依存することができます。
そのため、現在のページ内のクラスターとその親ページの両方からデータを参照することができます。
通常、クラスタ内の頂点の約30%が参照としてエンコードできます。
親データは基本的に子データの簡略化されたものに過ぎないため、この種のメカニズムを単なる完全一致ではなく予測にまで拡張することで、大きな勝利を収めることができると期待しています。
——
Bonus:
複数のレベルが一度にストリーミングされると、ストリーマーはトポロジーソートのようなものを行い、子供よりも親が先にインストールされるようにしなければなりません。
参照がデコードされると、頂点のビットストリームがデコードされ、現在のクラスターのフォーマットに再エンコードされる必要があります。

最後に、ディスクエンコーディングでは、よりコンパクトなトポロジーエンコーディングも採用しています。
トライアングルごとに3つのインデックスを保存する代わりに、いくつかのトライアングルストリップに再配置されます。
三角形ストリップは、最初の三角形に3つのインデックスを必要としますが、ストリップ内の後続の三角形には1つの新しいインデックスしか必要ありません。
ストリップが長くなるほど、平均して必要なインデックスの数は少なくなります。
ここでは、一般化されたトライストリップを使用していますが、これは左と右を交互に選択するのではなく、すべてのステップで左と右を明示的に選択することができます。
これにより、より長いストリップを形成することができ、トライアングルごとに左右を選択する必要があるとしても、結果的には純然たる利益となることがわかりました。
また、頂点は最初に使用された順に並べ替えられるので、最初に参照される頂点のインデックスは、常にそれまでに見られた頂点の総数となり、明示的に保存する必要はありません。
すでに見たことのある頂点への参照は、まだ明示的に格納する必要がありますが、ここでもビルダーは、これらの頂点が、最も見たことのある頂点から5ビット以上のオフセットにならないことを保証しています。
結果として得られる構造は、ストリップをリセットするタイミング、左または右に進むタイミング、どの参照が明示的であるかを示す、いくつかのビットマスクです。
5ビット/triのこのエンコーディングは、17ビット/triのメモリエンコーディングよりもはるかにコンパクトになります。
——
Bonus:
bitscanとpopcountを使用したこの構造は、ランダムアクセスをサポートしているため、任意のトライアングルを一定時間でデコードすることができます。
このエンコーディングは元々ランタイムメモリ形式を想定していましたが、デコードの速度が十分ではなかったため、トランスコーディングの段階に移行し、十分な速度を得ることができました。
そのため、どちらかというとトレードオフの関係になってしまうのです。
すでに期待できそうなアイデアがいくつかあります。

そして、具体的な結果です。”Lumen in the Land of Nanite “のデモでは、4億3300万個のソーストライアングルがありました。
クラスタの階層構造のため、最終的には約2倍のNaniteトライアングルが生成されました。
位置、法線、UVを浮動小数点数、インデックスをバイト数で保存し、暗黙の接線を使用した場合、圧縮されていない生のデータは約26GBになります。半精度の座標を使用すると、これは半分に近くなりますが、それでもメモリ表現で得られる7.7GBを大幅に上回ります。
これを圧縮して直接ディスクに保存した場合は、約10%しか小さくなりません。
全く同じデータをディスク形式で表現すると、さらに大幅に圧縮されて4.6GBになります。
これは、必要なクラスタと階層のメタデータを含めて、Naniteトライアングル1個あたり約5.6バイトのフットプリントです。
また、ソーストライアングルに換算すると、1トライアングルあたり約11.4バイトになります。
これらはすべて、アーリーアクセスビルドから改良された最新のコードによる数値です。
今後も圧縮には力を入れていきます。まだまだ絞り込めるものがたくさんあると信じています。
——
Bonus:
圧縮サイズは、バックエンドのLZコンプレッサーとしてKrakenをCompression Level 5で使用したPC上のものです。

Naniteは今日から使えるようになりました。ソースコードの全文はUE5のアーリーアクセスリリースに掲載されています。
初期の仮想化されたジオメトリの夢のすべての側面を完璧に実現することはまだできませんが、かなり近づいています。
しかし、私たちはまだ終わっていません。
私たちは、Nanite の最初のバージョンでサポートしたいものを意識的に制限しました。
ほとんどのシーンの大部分を占め、最も簡単にサポートできるリジッドジオメトリを最初に取り上げました。
サポートマトリックスには、まだカバーしていない大きな部分があります。
Naniteは以下をサポートしていません。
半透明またはマスクされたマテリアルや
静止画でもアニメーションでも、非リジッドな変形。
また、我々のソリューションがうまく機能しないジオメトリの種類もあります。
画面の解像度に応じてコストをスケーリングするという特性は、草や葉のような集合体には当てはまりません。

これは、私たちがこれから進みたい方向性のほんの一部です。
最終的には、すべてをNaniteにして、何がNaniteで、何がNaniteでないかという概念がエンジンにないようにしたいと考えています。それはジオメトリのレンダリング方法に過ぎません。
それに加えて、この技術の側面を持ち込むことで、現在は実用化されていないことを実現できるエキサイティングな場所がたくさんあると考えています。
我々のコア・レイトレーシング
マイクロポリゴンテッセレーション
ピクセルスケールのディスプレイスメントマッピング
フラクタルインスタンシング
この考え方や学んだことを、フォリッジやアニメーション、地形などに応用することで何ができるのか、興味があります。
これからどうなっていくのか、とても楽しみです。

Naniteの共著者に感謝したい。RuneとGrahamです。
仮想シャドウマップの作者であるOlasとAndrew。
この技術をサポートしてくれた UE5 レンダリング チームのメンバー
この技術を使って美しいものを作ってくれたアーティストたち
そして最後に、私のこの夢を実現する機会を与えてくれた Epic。






