こんねね~。Pocolです。
今日は…
[Aaltonen 2023] Sebastian Aaltonen, “HypeHype Mobile Rendering Architecture”, SIGGRAPH 2023 Advances in Real-Time Rendering in Games course.
を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けるとありがたいです。
特に断りが無い限り,図は[Aaltonen 2023]からの引用となります。予めご認識ください。

こんにちは、私はSebastian Aaltonenです。グラフィック・プログラミングで20年以上の経験があります。過去にはUbisoftとUnityでクロスプラットフォームのレンダリング技術を構築していました。
私は1年前、彼らのモバイルレンダリング技術を書き直すというミッションを持ってHypeHypeに入社しました。今日はそのプロジェクトの最初のマイルストーンである、低レベルのグラフィックスAPIとプラットフォームのバックエンドの書き換えについて話すつもりです。

HypeHypeはモバイルゲーム開発プラットフォームです。タッチスクリーン上で直接ゲームを作成し、クラウドサーバーにアップロードします。
ゲーマーはTik Tokスタイルのフィードを使ってゲームを閲覧します。ゲームは即座にロードされます。これは大きな技術的挑戦です。ゲームのバイナリ・サイズとローディング・コードの両方を高度に最適化しなければなりません。最初のバイナリを小さくするために、データを高度に圧縮した形で保存し、ストリーミングにも傾注しています。
HypeHypeは最大8人までのマルチプレイが可能です。マルチプレイヤー機能とプレイヤー数は、クラウドゲームサーバーのインフラが導入されれば、将来的に増加する予定です。
モバイルアプリ内には本格的なゲームエディターがあります。ゲームロジックの記述にはビジュアルスクリプティングシステムを使用しています。プレイヤーはクリエイターがゲームを作っている様子を見ることができ、複数のクリエイターがリアルタイムでゲームを共同制作することも可能です。Googleドキュメントのようなものです。テストプレイは即座に行われ、観戦者全員がプレイヤーとしてマルチプレイヤーテストセッションに参加します。これにより、イテレーション時間が劇的に改善されます。
もちろん、チャット、リーダーボード、リプレイヤーなどのソーシャル機能も充実しています。
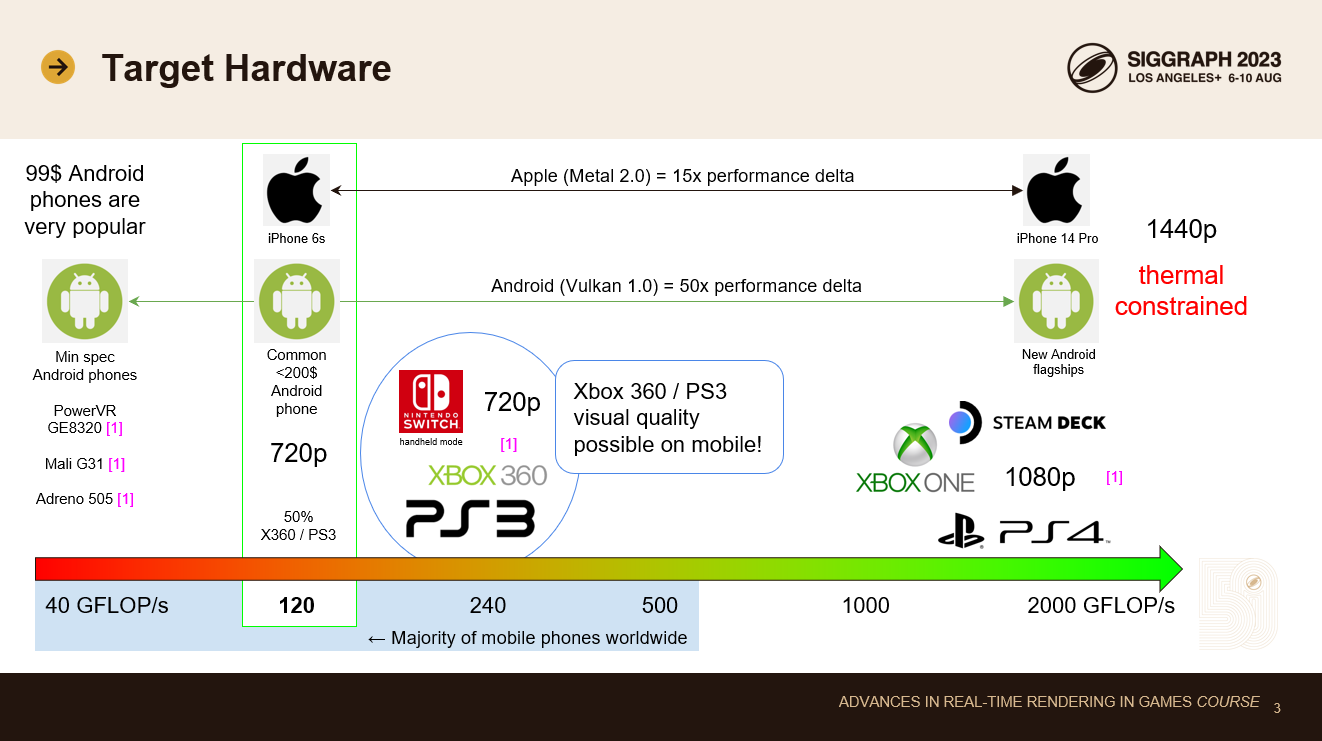
HypeHypeは主にモバイル機器とタブレットをターゲットにしています。しかし、ウェブクライアントやネイティブのPC/Macアプリケーションも用意しています。
私はユービーアイソフトでコンソールの開発をしていた経歴があるので、モバイルデバイスを過去のコンソール世代と比較してより深く理解するのが好きです。
Xbox 360やPS3のGPU性能は、今や中級以下のモバイル機器と同等だ。これらのコンソールは、これまでのコンソールの世代間で最大のビジュアルのジャンプを提供したため、これは素晴らしいニュースだ: 我々はHD出力解像度を手に入れ、適切なHDRライティング・パイプライン、物理ベースのマテリアル・モデル、画像の後処理を初めて実装することができた。そのすべてが、現在主流のモバイルデバイスで可能なのだ。そして、アップスケーリングによって、30fpsで最下層のデバイスにスケールダウンすることができます。
ハイエンドに目を向けると、最新の1000ドル以上のスマホはすでにXbox OneやPS4レベルの性能に達しています。しかし、これらの携帯電話はより高いネイティブ解像度で動作し、熱的制約があるため、現実のゲームでは、モバイルデバイスではまだその世代のビジュアル忠実度には到達できません。また、デバイスが熱くなり、バッテリーが数時間で消耗してしまうため、そうしたいとも思いません。

HypeHypeのゲームは、これまでシンプルなビジュアルに限られていました: スタイライズされたテクスチャのないオブジェクト、シンプルなガンマ空間の照明、短い視野距離の小さなシーン。これは、単純なハイパーカジュアルゲームには適しています。
しかし、これはプラットフォームにとって大きな制限であるため、私たちは1年前にゼロから新しいレンダラーを作り始めました。新しいレンダラーのビジュアル忠実度の目標は、Xbox 360やPS3のゲームに匹敵することです。最新のライティング、シャドウイング、ポストプロセッシング技術を備えたフルPBRパイプラインを導入する予定です。より多くのゲームジャンルをこのプラットフォーム上で適切に構築できるよう、より大きなゲームワールドとより長い描画距離を目標としています。
もちろん、これは素晴らしいことですが、これらの新しい改良のパフォーマンス・コストについては本当に注意しなければなりません。HypeHypeのゲームを中堅クラスの携帯電話で60fpsを維持したまま、デバイスをスロットリングさせることなくプレイしたいのです。これは私たちにとって大きな懸念であり、新しいレンダリングアーキテクチャでパフォーマンスに重点を置いている主な理由です。
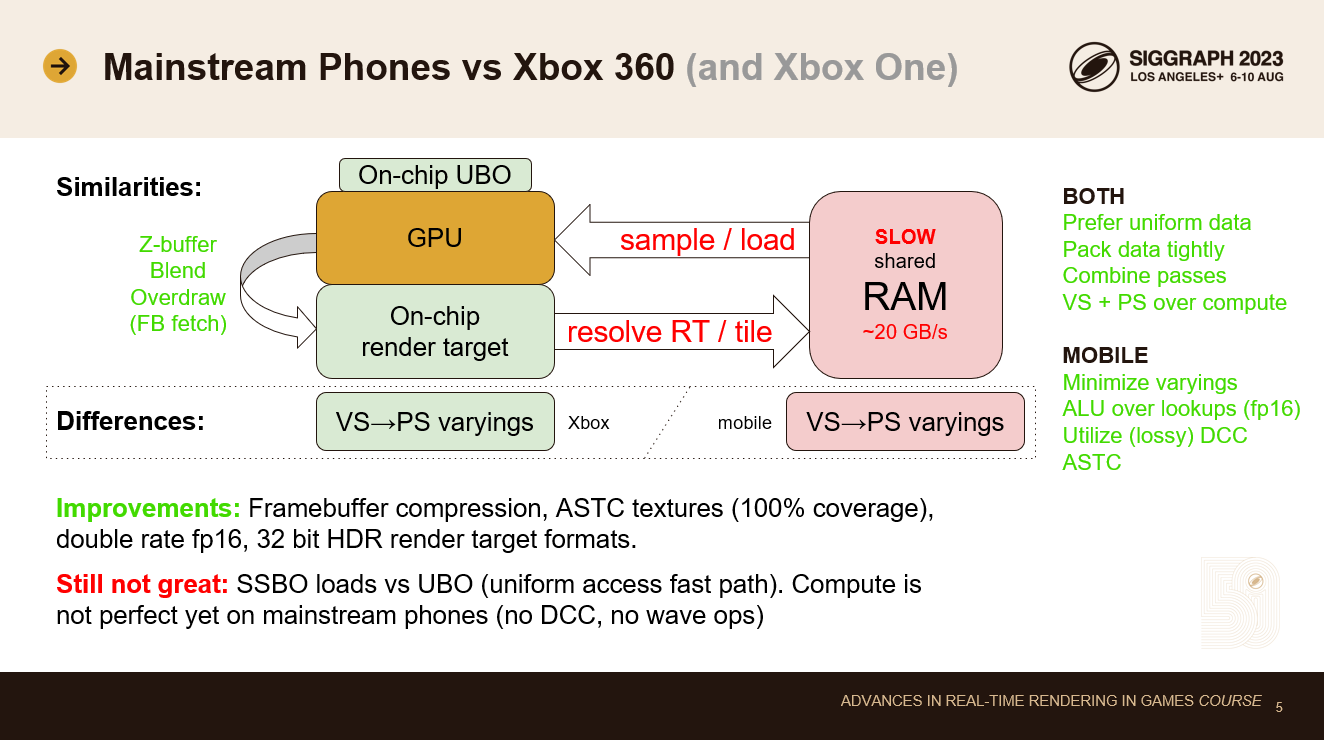
現在主流の携帯電話とXbox360を比較すると、多くの共通点があることに気づきます。
どちらも低速の共有メインメモリを搭載している。帯域幅が主な制限要因です。どちらの設計も、メモリ帯域幅の使用量を削減する技術も採用しています。最も重要なのは、レンダーターゲット用のオンチップストレージです。Xbox 360では、レンダーターゲット全体で10MBのEDRAMバッファを使用していました。携帯電話では、より小さなオンチップ・タイル・メモリがあります。どちらの技術も似たような問題を解決します。オーバードローは余分なメモリ帯域幅を必要とせず、Zバッファリングとブレンディングは完全にチップ上で行われます。携帯電話では、フレームバッファフェッチもあり、同じレンダーターゲットの位置から、メモリを往復することなく前のピクセルをロードし直すことができます。新しいXbox Oneコンソールにも、同様の最適化を可能にする読み書き可能なESRAMが搭載されました。
メインメモリは遅いので、レンダーターゲットのリゾルブはできるだけ避けたいです。レンダーパスは最小限にしたい。一度に複数のことを行うことが、良いパフォーマンスの鍵となります。最近の携帯電話にはフレームバッファ圧縮機能もあり、レンダーターゲットの解決とサンプリング帯域幅のコストを削減しています。これは良い追加機能ですが、問題を完全に解決するものではありません。ASTCテクスチャ圧縮も役に立ちます。昔のDXT5よりも品質が良く、フットプリントも小さくなっています。
携帯電話にはダブルレートのfp16演算もあります。帯域幅の乏しいデバイスでメモリルックアップに頼りたくないので、これは助けになります。また、より精度の低いHDRフレームバッファフォーマットが利用できるようになりました。
しかし、いくつかの古い制限はまだ残っています: モバイルGPUはまだユニフォームバッファを中心に設計されています。ダイナミック・アドレスからのSSBOロードはまだ遅いです。メモリアクセスパターンをスカラーライズできれば、パフォーマンスのスイートスポットに到達できます。そのため、効率的に実装できるアルゴリズムが限られてしまいます。また、多くの携帯電話では、頂点のバリエーションをメインメモリに書き込むため、貴重な帯域幅を大量に消費します。このようなデバイスで良好なパフォーマンスを得るには、変化量のサイズを最適化することが鍵となります。

GPU駆動レンダラについては、8年前のSIGGRAPHですでに話していて、クラスター化レンダリングや2パスオクルージョンカリングなど、今ではデファクトスタンダードとなったコアアイデアを発表しました。
最近では、EpicのNaniteがGPU駆動レンダリングを主流にしました。彼らはビジビリティバッファー、マテリアル分類、解析的微分、ソフトウェアラスタライザーを組み合わせることで、GPU駆動レンダリングを汎用エンジンに十分耐えうるものにしました。
しかし、メインストリームのモバイルGPUでのGPU駆動レンダリングには、まだ未解決のパフォーマンス問題がたくさんあります。
モバイルGPUは、SSBO負荷に対してまだ最適化されていません。AMDとNvidiaは、レイトレーシングを追加した数世代前にデータパスを最適化しましたた。レイトレーシングのアクセスパターンは動的であり、頂点属性用の小さなオンチップ・バッファに頼ることはもうできません。同様の最適化を施したモバイルGPUが主流になるのを待つ必要があります。
V-buffer では、頂点シェーダを 1 ピクセルにつき 3 回実行する必要があり、これにはこれら 3 頂点のすべての頂点アトリビュートのフェッチも含まれます。また、すべてのインスタンスデータとマテリア ルデータをダイナミックロケーションからフェッチする必要があります。これは、ピクセルシェーダーで20回以上の不均一なメモリ負荷になります。モバイルチップは、このようなメモリ負荷の高い作業用に単純に設計されているわけではありません。
現在のモバイルGPUは、コンピュートシェーダー書き込み用のフレームバッファ圧縮をサポートしていません。コンピュートシェーダは、ディファード V-Bufferシェーディングでフルスクリーンのマテリアルパスを実装する最も効率的な方法です。モバイルでそれを行うと、多くの帯域幅を浪費します。
64 ビットアトミックはソフトウェアラスタライザでよく使われます。Z値を上位ビットに、ペイロードを下位ビットにパックし、アトミックに最も近いサーフェスを解決させます。モバイルGPUでは64ビットアトミックがサポートされていません。SampleGradも遅いです。215Bレートかそれ以上遅い。そのため、解析的勾配を使った遅延テクスチャリングはかなりコストがかかります。また、Wave intrinsicsのサポートは不安定で、一部のローエンドデバイスでは、エミュレートされたグループ共有メモリさえあります。
その結果、現在主流の携帯電話では、従来のCPUベースのレンダリングが依然として最適なのです。その昔、Xbox 360では60fpsで10,000回のドローコールを行うことができました。今日のモバイルデバイスでその目標を達成するには、非常によく最適化されたレンダリングコードを書く必要があります。
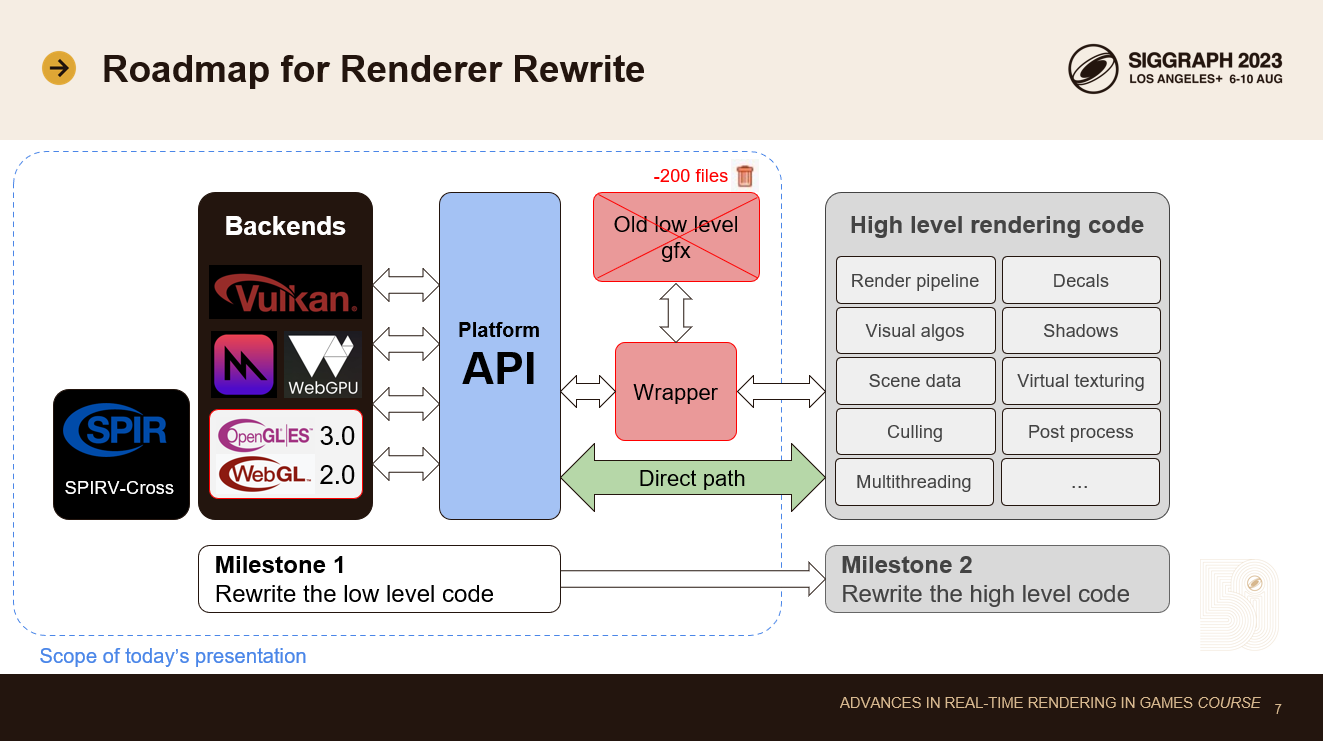
ロードマップについて話しましょう。
我々はレンダラーの書き換えを2つの段階に分けました。まず、低レベルのGfx APIとプラットフォーム固有のバックエンド・コードをすべて書き直しました。新旧両方のバックエンドを並行して実行するために、ifdefによる最小限のラッパーを導入し、古いレンダリングコードを出荷し続け、新旧を切り替えて比較できるようにしました。すでに200ファイルの古いレンダリングコードを削除し、最近ラッパーを取り壊し、新しいプラットフォームAPIへの直接呼び出しに置き換え始めました。
このプレゼンテーションでは、低レベルのプラットフォームAPIとバックエンドに焦点を当てます。新しい高レベルのレンダリングコードについては、後ほどお話しする予定です。我々の設計では、これらの部分を互いに完全に独立してリファクタリングすることができます。このトピックについては、プレゼンテーションの後半で触れる予定です。
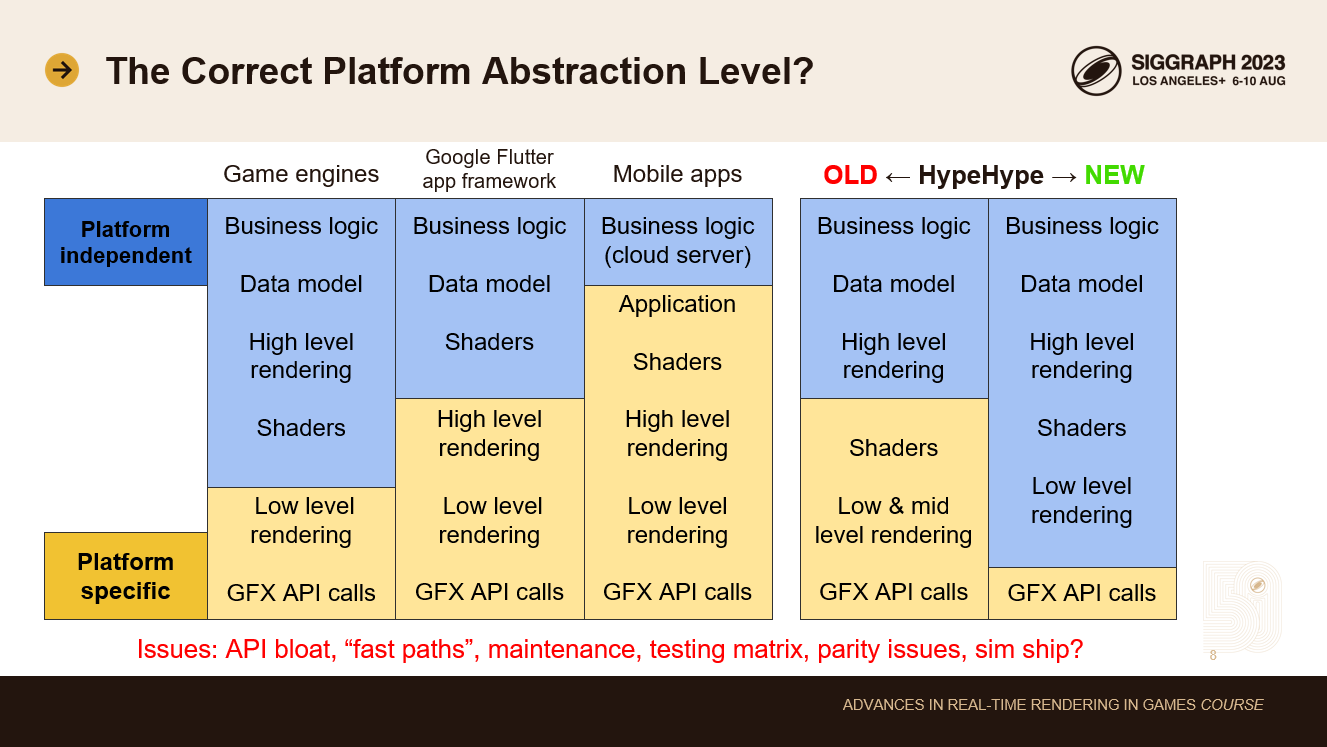
最初に決めなければならないのは、プラットフォームの抽象化レベルです。どのコードがプラットフォーム固有で、どのコードがプラットフォームに依存しないのか。
ゲームエンジンは一般的に、プラットフォーム固有のコードをスタックの最下層に限定します。こうすることで、プラットフォーム固有のコードを最小限に抑え、実装やメンテナンスのコストを削減します。しかし、一部のエンジンやレンダラー固有のコードは、最下層のプラットフォームコードに漏れる傾向があります。
モバイルアプリを見ると、プラットフォーム固有のコードは、スタックのもう少し上のレベルに達する傾向があります。例えば、人気のあるGoogle Flutterアプリフレームワークは、複数のプラットフォーム固有のチームによって開発されている。彼らは通常、新機能をモバイルで最初に出荷し、後でデスクトップに出荷する。AndroidとiOSも完全な機能パリティはありません。高レベルのレンダリングコードは、同じMetal APIを使用しているにもかかわらず、MacとiOSを含むデスクトップとモバイルのプラットフォームで異なっています。
多くのモバイルアプリでは、コードの分離がさらに進んでいます。iOSチームとAndroidチームがそれぞれ専用のコードベースを持ち、完全に分離していることが多い。このようなアプリのビジネスロジックのほとんどはクラウドサーバーで実行される傾向にあり、もちろんクラウドサーバーは第3のチームによって共有され、管理されています。
HypeHypeはリアルタイムのゲームエンジンなので、もちろんワールドの状態をすべてローカルで保持する必要があります。ゲームはすべてのデバイスで同じように動作し、クロスプレイはすべてのデバイスで動作しなければなりません。古いHypeHypeのGFXコードベースには、メタル用のシェーダーが重複しており、さらに高レベルのコードも重複していました。これはテストマトリックスを肥大化させ、メンテナンスコストを増加させ、新機能の追加を遅くしていました。これをまず解決したかった。目標は、プラットフォームAPIを既存のゲームエンジンと比べてさらに低レベルにすることでした。

プラットフォーム固有のコードはできるだけ少なくしたい。そのため、既存の低レベルGfx APIをタイトにラップする設計になっています。
設計作業は、Vulkan、Metal、WebGPUのドキュメントをクロスリファレンスすることから始まりました。私はすでにこれらのAPIすべてに精通していたので、作業が簡単でミスが少なかったです。
ラッパーを書くときは、まず共通の機能を見つけたい。これらはラップするのが簡単な場合が多いです。難しいのは、APIの設計に違いがある場合です。パフォーマンスを最適化する方法で、これらの違いを抽象化するために注意を払わなければならない。我々がMetal 2.0を使うことにしたのは、Metal 2.0がVulkanやWebGPUに近く、プレースメントヒープ、引数バッファ、マニュアルフェンスを提供しているため、Appleデバイスからももう少しパフォーマンスを引き出すことができるからです。クロスプラットフォーム開発を容易にするためにMoltenVKもサポートしていますが、Metal 2.0のバックエンドはCPUで約40%高速なので、出荷していません。
APIをよりコンパクトにするため、誰も使わなくなった非推奨のものをすべて切り捨てました。これらのものは、パフォーマンスに関して我々の期待に応えられなかった実験の失敗作です。頂点バッファは興味深いトピックです。ユービーアイソフトでは、GPU駆動のレンダラーではすでに8年前に頂点バッファを非推奨にしました。しかしHypeHypeでは、一部のモバイルGPUシェーダー・コンパイラーが頂点バッファに対してより良いコードを生成するため、今でも頂点バッファをサポートしています。また、WebGPUのカバレッジがまだ十分ではないため、WebクライアントではまだWebGL2を使っています。数年後にはAPIから頂点バッファを削除するつもりです。
シェーダーの単一セットは、技術アーティストの生産性にとって非常に重要です。私たちは、SPIRV-Crossのような最新のオープンソースツールを使用して、すべてのターゲットプラットフォームにシェーダーをクロスコンパイルしています。

この新しいプラットフォームAPIの設計目標について話しましょう。
まず、独立したライブラリにしたい。HypeHypeエンジンから独立して設計され、メンテナンスされます。頻繁に変更されない安定したAPIである必要があります。
私はこれまで多くのグラフィックス・プラットフォームの抽象化を見てきましたが、ほとんどの抽象化における問題は、ユーザー側の概念がハードウェアAPIに忍び込んでしまうことです。プラットフォームコードにメッシュとマテリアルを持つことは、最も一般的な問題です。メッシュとマテリアルはどちらも変化圧力を持っているので、これは問題です。メッシュレットとバインドレス・テクスチャは未来です。我々は、それらを表現する特定の方法にコミットしたくありません。メッシュは単純にインデックスバッファバインディング+N個の頂点バッファバインディングとして表現でき、マテリアルは複数のテクスチャ記述子と値データ用バッファを含むバインドグループとして表現できます。
ユニフォームハンドリングを自動化することは、最初のうちは良いアイデアだと感じるかもしれませんが、最終的にはジオメトリのインスタンス化のようなものを追加したくなり、データレイアウトを変更するためにバックエンドのコードをリファクタリングする必要が出てきます。あるいはさらに悪いことに、APIを複雑にするために新しい高速パスを追加することになる。そして最終的には、GPU駆動レンダリングのための新しい高速パスも追加することになり、APIはさらに肥大化します。我々のデザインでは、ユーザー側のコードがすべてのデータのセットアップを担当します!
余分なAPIのオーバーヘッドをゼロにすることも、我々にとって重要な設計の柱です。プラットフォーム・インターフェースは、大きなコストを追加すべきではありません。DX11と同じくらい使いやすく、しかし常に手書きで最適化されたDX12と同じくらい効率的でなければなりません。間違った解決策は、DX11のAPIをそのままコピーすることです。この方法では、コードベースでDX11ドライバーをエミュレートすることになり、NvidiaやAMDはあなたのチームよりもうまくこれを行うので安心してほしい。そのため、最新のバンクエンドはDX11よりも遅くなります。その理由は、入力の粒子が細かすぎること、レンダリングステートの粒子が細かすぎること、シャドウステートとデータコピーが多いことです。PSOとレンダリングステートのトラッキングとキャッシングはパフォーマンスを大きく低下させ、低速なソフトウェアコマンドバッファ設計は通常、コストに拍車をかけます。
ですから、私たちのAPIには非常に厳しい性能基準がありますが、同時にDX11と同じくらい使いやすいAPIにしたいと考えています。どうすればこれを達成できるでしょうか?
APIを設計するための良いプロセスが必要です。
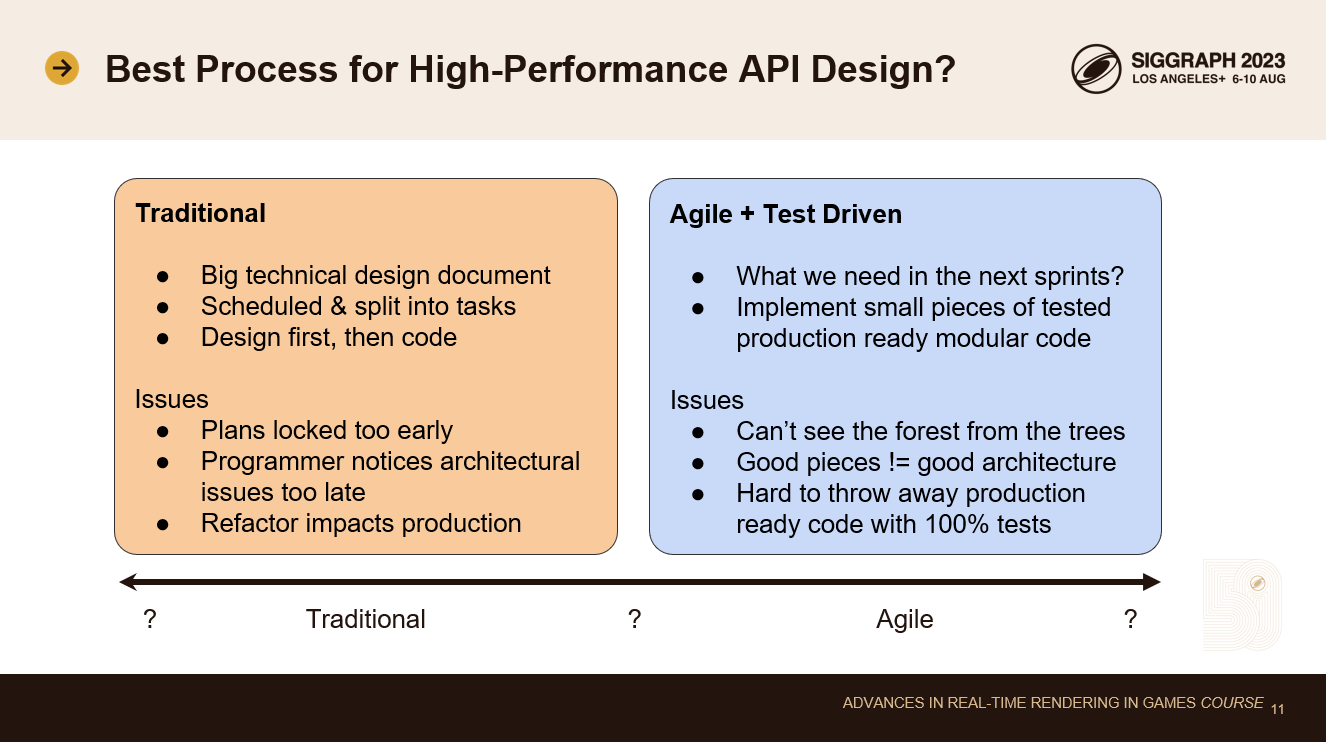
従来の方法であれば、APIのドキュメントを何ヶ月もかけて調査し、新しいAPIを詳細に記述した大きな技術設計書を書き、タスクに分割し、各バックエンドの各タスクの実装時間を見積もるというものです。
このアプローチの問題点は、設計をあまりにも早い段階で固定してしまい、後で変更するのが難しくなることです。プラットフォーム固有のグラフィックス・コードでは、細かいディテールが非常に重要になります。コードを書かずに、すべてのコーナーケースのパフォーマンスの影響を本当に理解することはできません。実運用に耐えうるコードがたくさん書かれるようになれば、そのような問題に気づくでしょう。現時点では、計画やコードの全面的な書き換えを正当化するのは難しすぎます。
アジャイルテスト駆動開発には、逆の問題があります。あなたは次のスプリントで必要なことに集中しています。フルテストカバレッジを持つ小さな独立したコードの断片を実装します。これらの断片をまとめれば、良いアーキテクチャが出来上がるというのが前提です。しかし、あなたはアーキテクチャの設計さえしていない。断片が増えればインターフェースも増え、通信のオーバーヘッドも増える。このようなプログラミングのやり方では、最適なパフォーマンスに到達するのは難しいです。そして、パフォーマンス目標を達成するためにアーキテクチャを大きく見直す必要があることに気づいたら、フルテストカバレッジと多くのストーリーポイントを費やした、本番で使えるコードを捨てるのはもっと難しくなります。
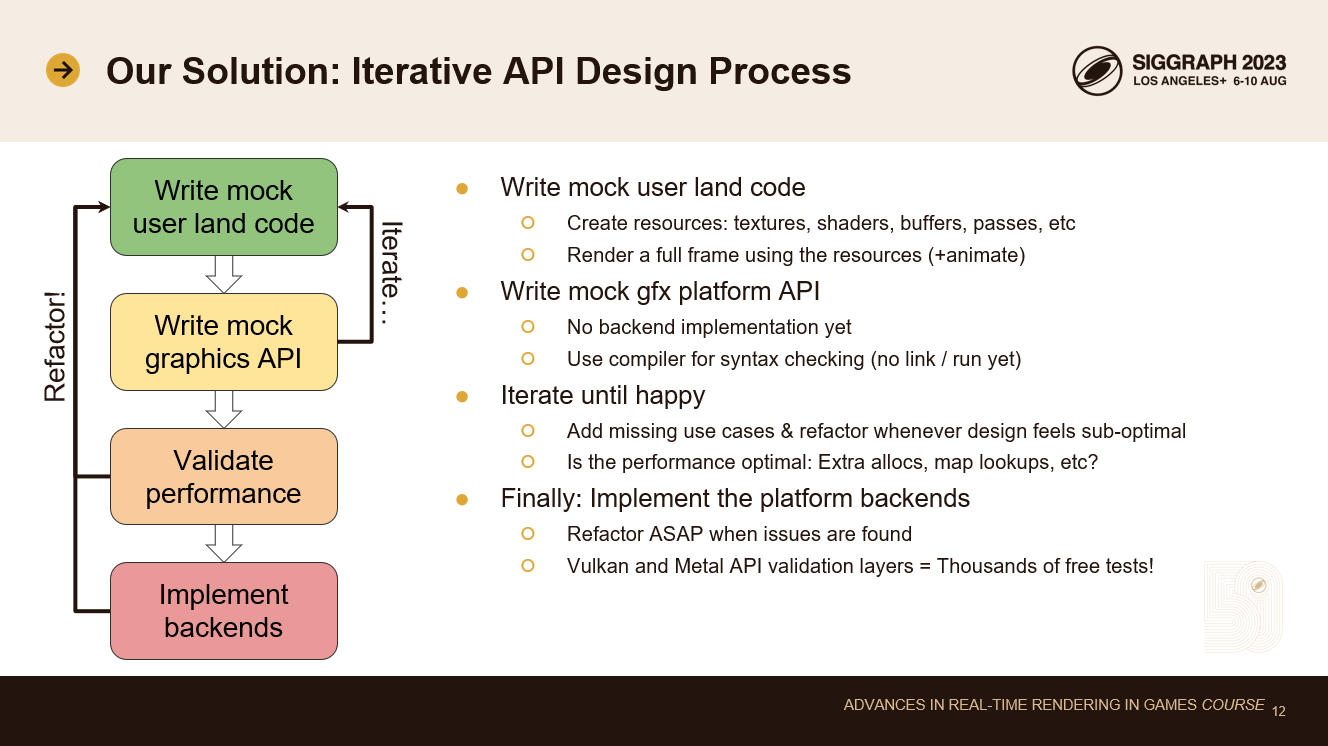
この問題に対する私たちの解決策は、高度に反復的なデザイン・プロセスを用いることです。
私はまず、モックのユーザー側コードを書くことから始めます。完璧なAPIがあると仮定して、これまでの専門知識を駆使し、夢のグラフィック・コードを書き始めます。そのAPIはまだ存在しないが、納得がいくまでモックコードを書き続けます。レンダリングに必要なすべてのリソース、テクスチャ、シェーダー、バッファなどを作成するコードを書き、これらのリソースを使って小さな描画ループを書く。描画ループは何度も呼び出され、いくつかのリソースはアニメーションを実装するために変更されます。動的なデータパスと静的なデータパスの両方を早めに設計することが重要です。
ユーザー側のコードの最初の反復に満足したら、そのためのモックプラットフォームAPIを書く。この時点では、これは単なる中空のAPIです。バックエンドの実装はありません。しかし、このAPIのおかげで、構文チェックとオートコンプリートのためにコンパイラーを使い始めることができる。これでAPIを実際に使ってみて、使い心地を確かめることができる。もちろん、少しでも必要性を感じたら、常にリファクタリングしていくつもりです。足りないモックのユースケースを追加したり、Vulkan、Metal、WebGPUのAPIドキュメントに目を通したりして、重要なことを見逃していないか確認します。
それから、すべてのユーザー側コードのパフォーマンスチェックをするつもりです。私はすべてのプラットフォームAPIがどのように動作するかをよく理解しているので、各APIコールがVulkanやMetal、WebGPUバックエンドでどのような実装を必要とするかを考えます。その実装が些細なものであれば問題ありません。もし実装に余分なデータコピー、ハッシュマップ・ルックアップ、メモリ割り当て、その他の高価な操作が必要なら、その設計を破棄し、APIのその部分をより効率的に書き直します。覚えているように、我々の目標は、あらゆるケースで手作業で最適化されたDX12と同じくらい速くすることです。我々のAPIが基礎となるハードウェアAPIに完全にマッピングされていなければ、それはできません。
モック・コードのパフォーマンスに満足したら、バックエンドの実装を始めます。もちろん、この過程で見落とした細かな点に気づき、モック・コードやモックAPIを即座にリファクタリングします。繰り返しの時間が遅くなるので、重いテスト・スイートはまだ書きません。その代わりに、VulkanとMetalの検証レイヤーが何千ものテストケースを無料で提供してくれることに頼っています。検証レイヤーのエラー・コールバックを自動テストにフックして、リファクタリングしてもコードが機能し続けるようにしています。
API設計に関する最後のトピックは、適切な頻度と粒度で物事を行うことです。
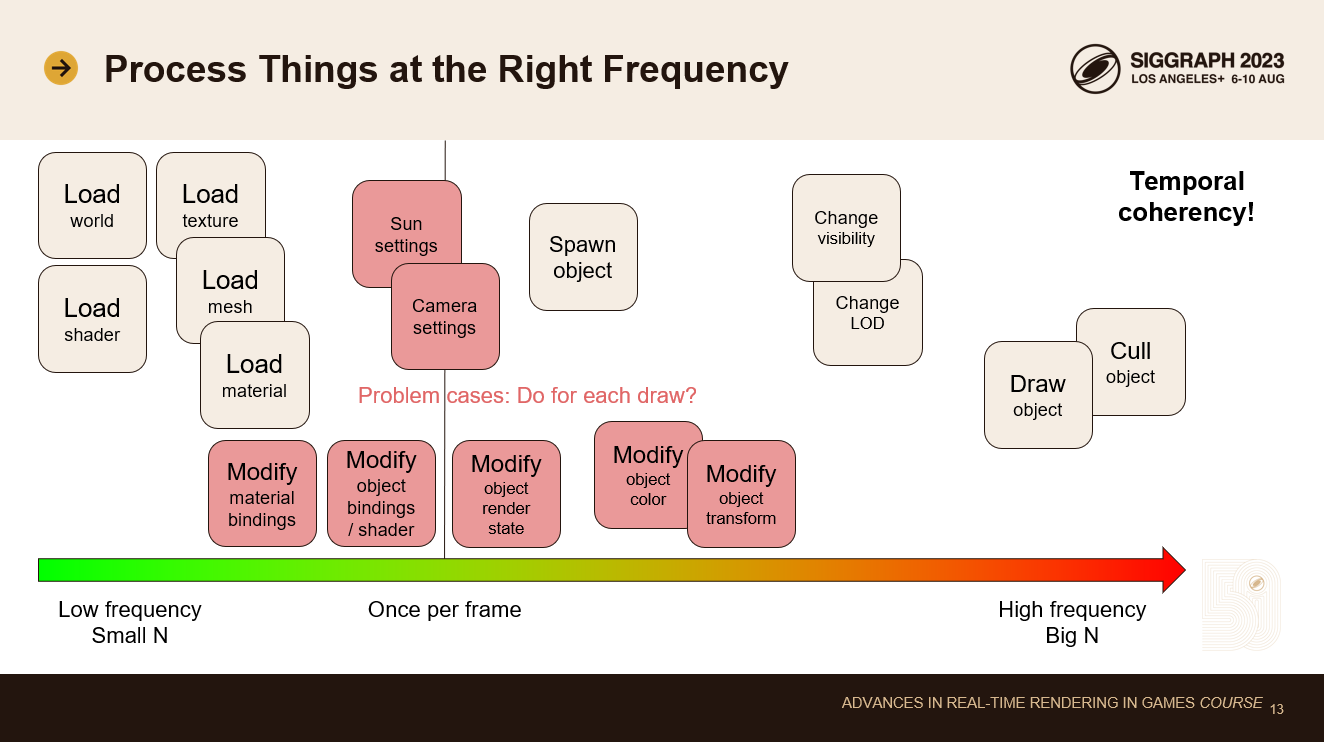
レンダリングコードの大きな問題は、高価な処理が高い頻度で行われることです。これはまた、ホットドローループにトラッキングコストを追加する傾向もあります。
ゲームには多くの時間的一貫性があります。ゲームの世界をロードし、フレームごとにゆっくりと変化させます。ほとんどのデータは同じままです。また、カメラはほとんどの場合、ゆっくりと動いています。人間の脳は滑らかな動きを見るために、フレーム間の時間的な一貫性を必要とします。これは我々にとって素晴らしいことです!これを利用したい!
どんなことが起きているのか見てみましょう: ゲームワールドとすべてのシェーダーPSOのロードは最初に行われます。大きなレベルであれば、移動時にテクスチャ、メッシュ、マテリアルもロードします。ほとんどのオブジェクトは最初にスポーンされますが、ストリーミング中にレベルの一部がスポーンされることもあります。敵、戦利品、発射体などは一般的にゲーム中にスポーンされますが、毎フレームそれほど多くはありません。本当に頻度の高い操作は、すべてのオブジェクトのカリングと可視オブジェクトの描画だけです。カリングループと描画ループは、コードベース全体の中で最も時間のかかるループです。
問題ケースを赤で強調しました。人々は、ホットな描画ループの中で、これらに関連する処理を行う傾向があります。
マテリアルのバインディングを変更することは一般的ではありません。すでにロードされているマテリアルの法線マップをどれくらいの頻度で置き換えますか?オブジェクトのレンダリングに使用するシェーダーを変更する頻度は?オブジェクトのレンダリングに使用されるレンダリングステートを変更する頻度は?一部の特殊効果を除いて、ほとんどありません。オブジェクトの色のアニメーションやオブジェクトの変形は、より一般的な操作です。ごく一部のオブジェクトは、毎フレームアニメーションします。我々は、このようなことが起こったときだけ、その費用を支払いたいのです。すべての描画呼び出しに対してではありません。

この問題に対する我々の解決策は、すべてのデータの修正と描画を完全に分離することです。すべてのデータは描画ループの前に準備されています。
パイプラインステートオブジェクト(PSO)は、アプリケーション起動時またはレベルロード時にビルドする必要があります。実行時に PSO を構築すると、スタッタリングが発生します。我々の哲学では、シェーダーバリアントはコーダーとテックアーティストによって作成され、手作業で最適化されます。その数は限られています。これはid-Softwareが行っていることと似ており、非常に優れたパフォーマンスを提供します。
PSOハンドルを各オブジェクトのビジュアルコンポーネントに直接保存します。フレームごとにハッシュマップを参照する必要はありません。
すべてのバインドグループ(ディスクリプターセット)を事前に作成します。マテリアルディスクリプターセットには、すべてのテクスチャと値データのバッファが含まれています。マテリアル・バインド・グループ・ハンドルをオブジェクトのビジュアル・コンポーネントに格納します。これにより、ハッシュマップルックアップを回避し、単一のVulkan、Metal、WebGPUコマンドでマテリアルのバインドを効率的に変更できるようになります。
永続データと動的データを分けることは重要です。永続的なデータは起動時にアップロードされ、変更されるとデルタ更新されます。私は2年前のREAC2011でこのトピックについて講演しました。このトピックについてもっと知りたい場合は、そのプレゼンテーションを参照してください。
ダイナミックデータは、描画コールごとにmap/unmapを使用する代わりに、パスごとに1回バッチアップロードされるべきです。グローバルデータは、無駄な帯域幅コストを最小化するために、描画ごとのデータから分離されるべきです。
リソースの同期は、多くのエンジンで大きなCPUコストとなっています。現在のソリューションはシンプルです: レンダーパスが始まると、レンダーターゲットを書き込み可能なレイアウトに移行します。レンダーパスが終了すると、レンダーターゲットをサンプリングテクスチャレイアウトに戻します。こうすることで、すべてのテクスチャ(スタティックとダイナミックの両方)が常にサンプラー読み取り可能レイアウトになります。ドローコールごとのリソーストラッキングを行う必要はまったくありません。これにより、CPUサイクルが大幅に節約されます。

そして今、実装の詳細について話す準備ができました。
レンダラーには、テクスチャ、バッファ、シェーダー、その他いくつかのリソース・オブジェクトが必要です。これらのオブジェクトを保存し、安全に使用できるようにする良い方法が必要です。
最近のC++では、スマート・ポインタ、参照カウント、RAII(リソース取得は初期化)を使うのが一般的です。
率直に言って、これらは我々にとっては遅すぎる。参照カウントスマートポインターは、参照の寿命とバッキングメモリを結びつけます。その結果、小さなメモリ割り当てが大量に発生します。現在の高度にマルチスレッド化されたシステムでは、メモリ割り当てにはコストがかかります。また、割り当てがシステムメモリ上にランダムに散在するため、データアクセスパターンが悪化し、キャッシュミスが増加する。参照カウントされたスマート・ポインターをコピーするには、2つのアトミック(add, sub)が必要となります。所有権はスレッド間で共有できます。
安全性の問題もあります。参照カウントはオブジェクトの寿命を曖昧にします。推論が難しいです。どのスレッドでも死ぬ可能性があります。リスナーのようなRAIIオブジェクトはデストラクターに副作用をもたらします。例:オブジェクトのリフカウントが別のスレッドで実行され、リスナーのデストラクタが配列から登録を解除します。別のスレッドがその配列をイタレーションしています。クラッシュ! このクラッシュを回避するには、デストラクタの一部をミューテックスで保護する必要があります。つまり、オブジェクトを削除するたびにミューテックスロックが必要になる。これは非常にコストがかかります。HypeHypeはフィードでゲームを高速にロードしたりアンロードしたりしています。ローディングやコードの削除に時間をかける余裕はありません!
この問題(そして他のほとんどの問題も)の解決策は、配列を使うことです!
同じ型のすべてのオブジェクトを含む大きな割り当てが1つあります。配列のインデックスは、驚くほど素晴らしいデータハンドルです。テクスチャの配列があれば、単純にインデックス4のテクスチャに問い合わせることができる。インデックスはPODデータです。コピーするのは簡単です。ワーカースレッドにも安全に渡せます。そのスレッドが配列にアクセスしない限り、インデックスで危険なことは何もできない。これによって、カリングやドローストリーム生成タスクを安全性の心配なしに書くことができます。これらのスレッドは、ある場所から配列のインデックスを受け取り、それらを組み合わせて描画コールを形成するだけです。データ配列へのアクセスはまったく必要ない。
しかし、重大な欠陥がある。配列インデックスはオブジェクトの寿命を保証しません。もちろん、データ配列のスロットは再利用します。データが死んでスロットが再利用される可能性もあります…。
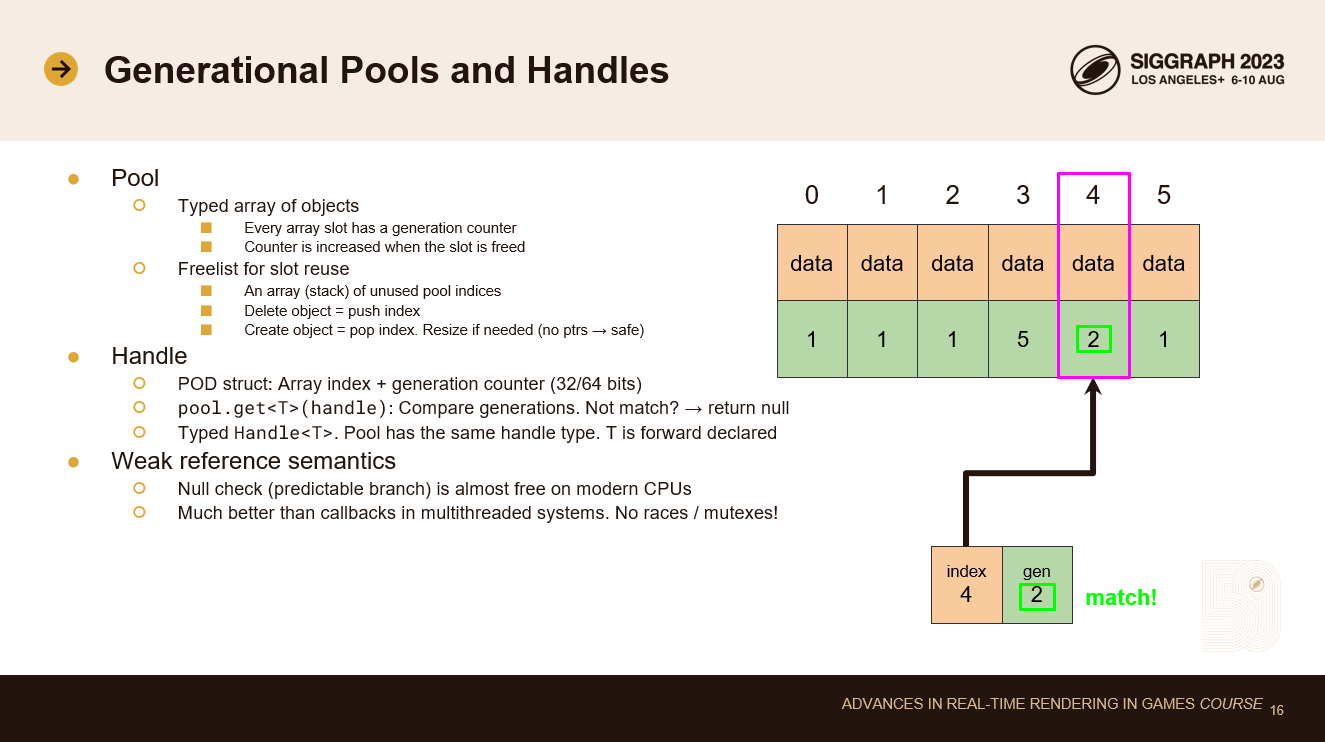
この問題を解決するには、配列のインデックスを世代別ハンドルに置き換える必要があります。この意味を説明しましょう。
プールはデータ配列に似ています。オブジェクトの型付き配列ですが、世代カウンターの配列も追加されています。世代カウンターは、スロットが何回再利用されたかを示します。カウンターは、そのスロットの現在のデータが解放されたときに増加します。
プールにはフリーリストもあります。フリーリストは、単純に各フリースロットのインデックスを含む線形配列です。これはスタックセマンティクスを持ちます。新しいオブジェクトを確保するときは、空きインデックスを先頭からポップします。オブジェクトを削除するときは、解放されたスロットのインデックスをフリーリストの先頭にプッシュします。これらはどちらもO(1)の高速処理です。フリーリストがなくなったら、プールのサイズを2倍にします。配列内のデータへの直接のポインタ参照は許されないので、これは安全です。すべての参照はハンドルを使って行われます。
ハンドルは単なるPOD構造体です。前のスライドと同じように配列のインデックスが格納されていますが、今回はその隣に世代カウンタもあります。これは全部で32ビット(例えば16+16ビット分割)または64ビット(32+32ビット)で、同時にアクティブになるリソースの数やオブジェクトの寿命の短さに応じて使い分けます。HypeHypeでは、すべてのグラフィックリソースに32ビット(16+16)のハンドルを使用しています。
プールはゲッターAPIを提供し、ハンドルをパラメータとして受け取ります。ハンドルのインデックスでプールの世代カウンタ配列を読み取り、ハンドルの世代カウンタと比較します。それらが一致すれば、データを取得します。一致しなければヌルポインタを得ます。
これは弱い参照セマンティクスになります。古くなったハンドルを使ってもまったく問題ありません。ヌルポインターが返ってくるだけです。ヌルチェックは予測可能な分岐であり、最近のCPUではほとんどフリーです。ハンドルが削除されると、分岐予測は一度失敗します。その時点で自分もきれいになります。弱い参照は、コールバックを必要としないコーディングの結果です。コールバックは、マルチスレッドシステムでの競合状態を避けるために、バッファリングやミューテックスを必要とします。
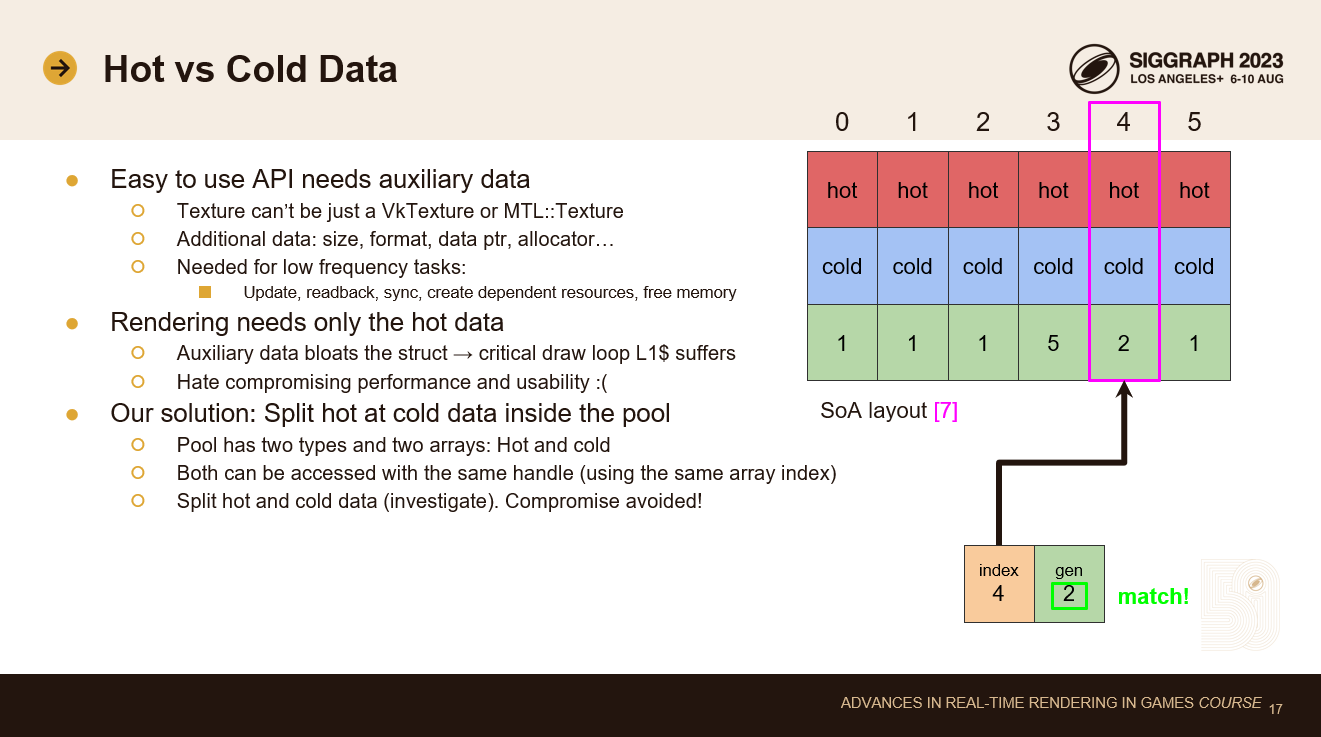
我々の主な目標の1つは、APIをDX11と同じくらい使いやすくすることでした。そのためには、プール内のデータ構造体に補助データをバンドルする必要があります。Vulkanでは、VkTextureハンドルはそれ自身について何も知らないので、純粋なVulkanでレンダリングコードを書こうとすると厄介です。テクスチャ構造体には、サイズ、フォーマット、書き込み用のデータポインタ、削除用のアロケータなどを知っていてほしいのです。
この補助データは、リソースを変更したり、リソースを削除したりするような低頻度のタスクに必要です。我々の設計原則はリソースの変更と描画を分離することなので、我々はリソースが変更または削除されたときだけこのデータにアクセスします。つまり、補助データをホットドローループで必要なデータと同じ構造体に置くことは、キャッシュ効率が悪いということです。描画ループは、使用されていないデータをL1$にロードします。パフォーマンスと使い勝手のトレードオフは嫌いです。
この問題に対する我々の解決策は、プール内部でSoAレイアウトを使用することです。ホットドローループで毎フレーム必要なデータを特定し、そのデータを1つの構造体に、残りの低頻度の補助データを別の構造体に入れます。これで、プールは1つではなく2つのデータ配列を持つことになります。ハンドルの同じ配列インデックスを使用して、どちらかのデータ配列(または両方)にアクセスできます。こうすることで、パフォーマンスが重要なドローループでホットデータをキャッシュにロードするだけでよくなります。補助データ構造体は低頻度でのみロードされ、L1$キャッシュ使用率に関するパフォーマンスの問題を解決します。

これで、グラフィックス・リソースを保存し、参照する良い方法ができました。次のトピックは、リソースの作成です。
VulkanとDX12でのグラフィックスリソースの作成は面倒です。他の大きな構造体を含む大きな構造体を埋める必要があります。これらの構造体の一部には、構造体の配列へのポインタも含まれています。そのため、一時的なオブジェクトのライフタイムで足元をすくわれる可能性があります。
この問題に対する既存の最も一般的な解決策は、リソース記述子にビルダーパターンを使用することです: ビルダーオブジェクトは、ディスクリプタの優れたデフォルト状態を含んでいます。builderオブジェクトは、変更したいすべてのフィールドを設定するために自身を変異させるAPIを提供します。準備ができたら、build関数を呼び出して最終的なディスクリプタ構造体を取得します。これは使いやすいですが、codegen、特にデバッグモードでは完璧とは言い難い。HypeHypeでは開発中にデバッグモードをよく使うので、デバッグモードも高速であってほしいのです。
この問題の解決策は、C++20 の指定構造体初期化子と C++11 の構造体集約初期化子を組み合わせて使用することです。この 2 つの機能を組み合わせることで、些細な方法で各構造体にデフォルト値を設定できるようになります。下のコード例のボックスを見てください。これらのデフォルト値のいずれかをオーバーライドする場合は、指定構造体イニシャライザ構文を使用して名前付きフィールドの値をオーバーライドします。この構文は非常にクリーンで、codegenは完璧です。
配列データをきれいに解決するには、独自のspanクラスを書く必要があります。C++20の組み込みスパンクラスはイニシャライザーリストをサポートしていません。なぜなら、初期化リストの寿命は非常に短いからです。一般的なケースでは、スパンの中にイニシャライザーリストを入れるのは危険すぎます。しかし、私たちは特殊なケースでのみこれを使用します: C++のconst &&関数パラメータは、一時的な無名オブジェクトしか受け付けません。C++は、関数パラメータ・リスト内の一時オブジェクトが、関数呼び出しが終了するまで十分生きることを保証しています。これにより、リソース記述子構造体のスパン内にイニシャライザー・リストを安全に格納するのに十分な保証が得られます。

そして、これが実際の見え方です。
まずは左側から: まず、頂点バッファとテクスチャを作成します。ここでの構文は適切で、構造体のデフォルト値と異なるフィールドのみを宣言しています。
左下を見ると、マテリアルを宣言しています。これはバインドグループです。バインドグループには、アルベド、法線、プロパティのテクスチャの配列があります。ここではイニシャライザーリストを使って配列を提供しています。これにより、構文が非常にすっきりします。また、この配列はヒープ割り当てを必要としないことも注目に値します。イニシャライザー・リストと記述子構造体全体はスタックに存在します。コピーされることはありません。リソース作成関数の呼び出しで、その参照を渡すだけです。これは、生のDX12や生のVulkanと同じくらい高速です。
右側では、より複雑なリソースを初期化しています。これは少しjsonに似ています。名前付きフィールド、配列、フィールドと配列が適切なインデントで互いの中にあります。これは、生のDX12やVulkanと比べると、はるかに書きやすく、読みやすくなっています。それでも、ランタイム・コストは発生しません。メモリ割り当てやデータコピーもありません。すべてが純粋なスタックデータです。

リソースを作成して保存する良い方法ができたので、GPUメモリを割り当てる必要があります。
私は可能な限り一時メモリを使うことを好みます。一時メモリはメモリプールを分断せず、割り当てはカウンタに数値を追加するのと同じくらい簡単です。
バンプ・アロケーターでは128MBのメモリー・ヒープを使っています。ヒープはリングに格納されている。バンプ・アロケータが末尾に達すると、新しいヒープ・ブロックを割り当てます。安定状態に達すれば、ヒープの割り当ては一切行われません。作成するGPUヒープごとに、プラットフォーム固有のバッファハンドルを作成します。このバッファ・ハンドルはヒープ全体をマッピングします。こうすることで、実行時にプ ラットフォーム固有のバッファ・オブジェクトを作成する必要がなくなります。バッファ構造体には、ヒープインデックスとオフセットが含まれます。実行時にこれらを構築してユーザーに渡すのは超効率的です。
さらなる最適化として、具体的なバンプ・アロケーター・オブジェクトをユーザーに提供します。これはNバイトをアロケートする関数を持っています。この関数は呼び出し元に対して完全にインライン化されています。単にカウンターをインクリメントし、そのカウンターがヒープブロック境界を越えているかどうかをテストします。このチェックは予測可能な分岐です。ブロックがなくなったら、gfx APIの仮想関数を呼び出して新しいテンポラリ・アロケータ・ブロックを取得します。これは 128MB のデータに対して一度しか起こらないため、非常に効率的です。
WebGPUはまだ100%のカバレッジを持っていないので、プロジェクト中にWebGL2のサポートを追加する必要がありました。WebGL2でも同じテンポラリ・アロケータ抽象化を使用しています。ユーザー側のコードは、返されたポインタがCPUポインタなのかGPUポインタなのかを知る必要はありません。WebGL2 では、8MB の CPU 側のテンポラリバッファを使用し、各レンダーパスの開始時に 1 つの glBufferSubData を使用してこれらのバッファをコピーします。これは、データ更新のコストを償却し、描画呼び出しごとに map/unmap を呼び出すよりも大きなパフォーマンス向上となります。
永続的なアロケーションは常に一時的なものよりずっと遅いからです。
私は2レベル分離フィットアルゴリズムを実装しました。これはO(1)ハードリアルタイムアロケータです。ビンを見つけるのに、2レベルのビットフィールドと2つのlzcnt命令を使います。ビンのサイズクラスは浮動小数点分布に従います。これは、サイズクラスに依存せず、オーバーヘッドの割合が常に小さいことを保証します。削除操作はアロケートと似ています。しかし、両側の隣接ポインタをチェックし、空のメモリ領域をマージする。これもO(1)です。
我々はVulkanとMetal 2.0の両方で同じアロケータを使っています(placement heaps)。私はオフセット・アロケータをオープンソース化しました。これは、GPUヒープやバッファのサブアロケートに使用でき、一般的に、要素の連続した範囲を必要とするものなら何でも使用できます(そして、埋め込みメタデータのためにCPUメモリのバッキングを必要としません)。
