こんこよ~。Pocolです。
今日は…
[Giegl 2007] Markus Giegl, Michael Wimmer, “Fitted Virtual Shadow Maps”, Proceeding of Graphics Interface 2007, pp.159-168.
いつもながら、誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けるとありがたいです。

Abstract
シャドウマップの解像度が低すぎて、その結果生じるアンダーサンプリングアーティファクト、透視エイリアシングや投影エイリアシングは、シャドウマッピングでシーンをシャドウイングする際の基本的な問題でした。
GPUハードウェアの制限を超えてシャドウマップの解像度を仮想的に向上させる、新しいスマートなリアルタイムシャドウマッピングアルゴリズムを紹介します。まず、GPU上の観測点からシーンをサンプリングし、シーンのさまざまな部分で必要なシャドウマップの解像度を得ます。次に、得られたデータをCPU上で処理し、最終的に階層的なグリッド構造に到達します。このグリッド構造をkd-tree方式でトラバースし、必要に応じてシャドウマップタイルでシーンに影をつけます。
シャドウの品質は、通常のシャドウマッピングに至るまで、シーン全体で均一な品質低下を伴う、直感的パラメータを介して速度と引き換えにすることができます。これにより、アルゴリズムを幅広いハードウェアで使用できるようになります。
1 Introduction
シャドウマッピングは、ラスタライズを使用して最初にヒットした可視性の問題を解決し、この結果を使用してシーンの直接光のシャドウを計算する非常に魅力的なアプローチです。このエレガントなアプローチには、基本的な問題が1つだけあります。シャドウマップには、特定のフレームバッファ解像度のサブピクセル精度で可視性クエリに応答できるように十分な情報が含まれている必要があります。そうではない場合、エイリアシングアーティファクトが表示されます。この情報がシャドウマップに含まれていない場合、どのアルゴリズムでもできることは、フィルタリングなどによってこれらのアーチファクトをマスクしようとすることだけです。
シャドウマップエイリアシングの2つのタイプ、投影エイリアシングと透視エイリアシングの定義については、[8]の導入部を参照してください。
Ailaら[1]とJohnsonら[10]は、エイリアシングの問題をエレガントに回避していますが、リアルタイム性能のためにはハードウェアの拡張に依存しており、現在のところ利用できません。
ユニフォームシャドウマップに含まれる情報を増やす簡単な方法は、シャドウマップテクスチャの解像度を上げることです。これは、メモリ消費量が2次関数的に増加するため、非常に速く非現実的になります(現在のハードウェアでは、サポートされている最大テクスチャサイズ、通常は\(4096 \times 4096\)が、メモリを使い果たす前であっても、制限要因となります)。
本論文では、現在のグラフィックスハードウェア上で動作し、シーンに影を付けるために利用可能な有効シャドウマップ解像度を向上させ、同時にメモリ消費量の2次関数的増加を回避するアルゴリズムを紹介します。
実用的な観点からは、例えばゲーム開発者が一般的な再パラメータ化技術に抱く一般的な不満は、最良のケースと最悪のケースの間に大きな品質差があることです(Lloydら[12]も示しています)。提示されたアルゴリズムはこの批判に対処し、シャドウマップリパラメータライゼーション技術とシャドウマップフォーカシングに直交しながら、すべてのケースで同じシャドウ品質を可能にします。したがって、これらの技術と組み合わせることができ、我々は、シャドウマップフォーカシング[3]と一緒にライト空間透視シャドウマップ[19]についてそのようにしました。
1.1 Abbreviations
以下は本稿で使用した略語のリストです:
FVSMs: フィット仮想シャドウマップ,
LiSPSM: ライト空間透視シャドウマップ [19],
SM: シャドウマップ,
SMing: シャドウマッピング,
SM-Tile: シャドウマップタイル (セクション3を参照),
SMTMM: シャドウマップタイルマッピングマップ (セクション4を参照).
2 Previous Work
シャドウアルゴリズムの2つの最も重要なカテゴリーは、シャドウボリューム[5]とシャドウマッピング[18]です。
シャドウマッピングの公表文献のほとんどは、エイリアシング・アーティファクトの問題を解決しようとしています。近傍比率フィルタリング[15]は、シャドウマップをサンプリングすることで、再投影の問題を軽減します。分散シャドウマップでは,Donellyら[6]は,シャドウマップのサンプリング結果をさらに改善するために,深度値の分散を使用しています。透視視錐台投影に起因する透視エイリアシングを解決するために、多くの論文が試みられています。元々はStammingerとDrettakis [16]によって開拓され,彼はシャドウマップをビューワと同じ透視変換にかけることによって透視エイリアシングを除去しようとしましたが,このアイデアは後にMartinとTan [13]によって台形シャドウマップで,Wimmerら [19]によってライト空間透視シャドウマップで,Chongら [4]によってA Lixel for Every Pixelで洗練されました。しかし、すべてのシャドウマップリパラメータライゼーション手法は、透視エイリアシングにのみ対処します。例えば、投影エイリアシングを改善するために必要なシャドウマップの主解像度を上げることはできません。さらに、ライトと視界の方向が直交している場合にのみ有効です。これらの方向が平行である場合、シャドウマップのパラメータ化はスクリーン全体にわたって実行されるため、ユニフォームシャドウマッピングに戻さなければなりません。最近、Lloydら[12]は、リパラメータライゼーション技術とともに、ビューフラクタムの側面またはスライスに適用される複数のシャドウマップの使用を集中的に研究し、興味深い結果を得ました。この論文で紹介する研究は、視錐台の方向や、アーティファクトが透視エイリアシングによるものか投影エイリアシングによるものかに関係なく、シャドウマップの解像度を向上させることを目的としています。
エイリアシング問題を解決する別のアプローチは、Adaptive Shadow Map[7]です(Fitted Virtual Shadow Mapとの比較については、以下のセクション4.8も参照)。しかし、このアプローチは複数のリードバックを必要とし、現在のグラフィックスハードウェアにうまく対応しません。Lefohn[11]はGPUをより良く利用する拡張を提案しており、Arvo[2]はSMの解像度を上げるためにライトビューをスライスしています。
最近、Queried Virtual Shadow Map[8]は、GPUのオクルージョンクエリメカニズムを使用して、最後の絞り込みステップでシャドウが変化したピクセルの数をカウントすることに基づいて、クワッドツリー方式でシャドウマップを適応的に絞り込んでいます。
一般的なシャドウマッピングとシャドウアルゴリズムの優れた概要は、MöllerとHainesのReal-Time Rendering book [14]や[9]にも掲載されています。
3 Virtual Tiled Shadow Mapping
以下は、Fitted Virtual Shadow MappingのベースとなったVirtual Tiled Shadow Mappingの説明であり、[8]からの転載です。Virtual Tiled Shadow Mappingは、ハードウェアがサポートする最大テクスチャサイズを超えてシャドウマップの解像度を上げるための総当りアプローチです。基本的なアルゴリズムは次のように動作します:
- GPUがサポートする最大のシャドウマップテクスチャを割り当てる。たとえば \(4096^2\) です。
- シャドウマップをシャドウマップx軸とy軸に沿って\(n \times n\)(例えば\(16 \times 16\))の等しいサイズのSMタイルに分割します(各タイルは、例えば\(4096^2\)テクセルというフルシャドウマップテクスチャ解像度を使用します、つまり、この例ではフルシャドウマップの実効解像度は\((16*4096)^2=65536^2\)です)。
各タイルに対して- (a) シャドウマップをシャドウマップテクスチャにレンダリングする(前のタイルのシャドウマップを上書きする)。
- (b) 現在のシャドウマップタイルで覆われているシーンの一部にシャドウ(変調)をかけるために、中間的に使用する。
タイル上のループを実装するには、マルチパスシャドーイングと仮想ディファードシャドーイングの2つの方法があります。
3.1 Multi-Pass Shadowing
連続したシャドウマップタイルをシーンに適用する方法のひとつに、マルチパスレンダリングがあります。最初のパスでは、シーンは普通にレンダリングされ(フルシェーディングと深度書き込みが有効)、最初のシャドウマップタイルが適用されます。後続の各シャドウマップタイルについて、シーンは再度レンダリングされますが、関連するタイルを使用するシャドウマッピングのみがフレームバッファに適用されます。シャドウマップタイルの外側にあるピクセルは抑制されます。深度書き込みとシェーディングは無効化され、深度比較関数はこれらのパスでEQUALに設定されます(ドライバのサポートによっては、EQUALの代わりにLESSEQUALを使用することが理にかなっている場合があります)。
3.2 Deferred Shadowing
マルチパスシャドウイングは、実装は簡単ですが、シーン全体を何度もレンダリングするため、パフォーマンス上のオーバーヘッドが大きくなります。シーンへのシャドウマップタイルの適用を高速化するために、我々は「ディファードシャドウイング」と呼ぶディファードシェーディングのバリエーションを使用します。ディファードシャドウイングは、シーンのジオメトリを再ラスタライズする代わりに、シーンの線形深度バッファを使用して行われ、次のシャドウイングパス、すなわち次のシャドウマップタイルを行うために必要な情報は、パスの間にオンザフライで作成されます。シーンはまず、「Eye-Space Depth Buffer」と呼ばれる、視線空間の深度を保存するテクスチャにレンダリングされます。後続の各タイルシャドウイングパスは、このテクスチャを読み取り、スクリーン座標とEye-Space Depth Bufferに保存された深度を使用して、各ピクセルで可視サーフェイスのワールド空間位置を計算できます。そして、ワールド空間の位置は、前と同じようにシャドウマップタイルを使用してシャドウイングされます。Eye-Space Depth Bufferに修正されていない視線空間のz座標を保存することで、シャドウマップの参照が元のシーンオブジェクトに対してシャドウマッピングを使用した場合と同じ結果を生成することが保証されることに注意してください。これは、z値を取得する他の方法、例えば、ウィンドウ空間のz座標(これは非常に非線形です)を使用したり、固定精度のwバッファ(それが現在のハードウェアでまだサポートされていた場合)を使用したりすると、必然的に画像のアーチファクトにつながるため、重要です。詳しくは次のように動作します:
- 最初のパスでは、上記のようにシーンをレンダリングしますが、4コンポーネント32ビット浮動小数点レンダーターゲットにレンダリングします。ピクセルシェーダで、修正されていない視線空間の z 座標を\(\alpha\)成分に格納します。このコンポーネントは Eye-Space Depth Buffer を形成します(ただし、簡単のため、4 コンポーネントターゲット全体を Eye-Space Depth Buffer と呼びます)。このライトで照らされたときのオブジェクトの各ピクセルの色(シャドウイングは無視)が、RGBチャンネルに書き込まれます。
- 各シャドウマップタイルに対して
- (a) マルチパスシャドウマッピングのように、シャドウマップをシャドウマップテクスチャにレンダリングします。
- (b) シーン全体のジオメトリを再度レンダリングする代わりに、Eye-Space Depth Bufferをテクスチャとしてバインドしたフルスクリーンクアッドをレンダリングします。
- (c) 各フラグメントのピクセルシェーダで、Eye-Space Depth Bufferのアルファチャンネルでフラグメントの視線空間の深度を調べ、ワールド空間にアンプロジェクションします(下記参照)。アンプロジェクションされたフラグメントを使用して、シャドウイング項を計算します。次に、Eye-Space Depth BufferからすでにシェーディングされているRGB値を、シャドーイング項で変調します。
- (d) シェーディングされ、場合によってはシャドーイングされたフラグメントがフレームバッファに書き込まれます。
個々のパスにおけるピクセルシェーダー操作は、アンプロジェクト操作を除いて、非常に簡単です。ウィンドウの \((x_w, y_w, z_w)\) 座標から視線空間の\((x_e, y_e, z_e)\) 座標に変換する標準的なビューポートのアンプロジェクションとは異なり、このオペレーションは \((x_w, y_w)\) (テクスチャ座標として与えられ、つまり 0 から 1 まで実行されます) と \(z_e\) から視線空間の \((x_e, y_e, z_e)\) を推測する必要があります。これは、次の行列変換を使用して行うことができます:
\begin{eqnarray}
\begin{pmatrix} x_e \\ y_e \\ z_e \end{pmatrix} = z_e \cdot
\begin{pmatrix}
\frac{1}{a_x} & 0 & -\frac{b_x}{a_x} \\
0 & \frac{1}{a_y} & -\frac{b_y}{a_y} \\
0 & 0 & 1
\end{pmatrix} \cdot
\begin{pmatrix}
2 & 0 & 1 \\
0 & 2 & -1 \\
0 & 0 & 1
\end{pmatrix} \cdot
\begin{pmatrix}
x_w \\
y_w \\
1
\end{pmatrix} \tag{1}
\end{eqnarray}
ここで,最初の行列中のパラメータ\(a_x\), \(a_y\), \(b_x\), \(b_y\)はグラフィックスAPIによって供給される投影行列\(P\)から取得されます。
\begin{eqnarray}
P = \begin{pmatrix}
a_x & 0 & b_x & 0 \\
0 & a_y & b_y & 0 \\
0 & 0 & \cdots & \cdots \\
0 & 0 & 1 & 0
\end{pmatrix}
\end{eqnarray}
4 Fitted Virtual Shadow Mapping
4.1 Fitted Virtual Shadow Maps: Smart Refinement Where Necessary
クエリ仮想シャドウマップと同様、調和仮想シャドウマップは、必要な部分のみシャドウマップを改良することを目的としています。また、このアルゴリズムは、各フレームで完全な改良を行うのに十分な速度になるように設計されています。FVSMは、最後の改良化ステップで変更されたシャドウピクセルの数をカウントし、このメトリックを使用してSM-タイルを4つのサブタイルにさらに改良化するかどうかを決定する代わりに、シーンのどこでどのようなSM解像度が必要かを事前に識別しようとします。
以下にFVSMアルゴリズムの概要を示す(詳細は以下のセクションを参照):
- シーンのビュー空間リニアデプス情報をEye-Space Depth Bufferにレンダリングする。上記についてはVirtual Tiled Shadow Mappingの項を参照してください。
- フラグメントシェーダにバインドされたEye-Space Depth Bufferを使用して、「Shadow Map Tile Mapping Map」(「SMTMM」、図3参照)と呼ぶものを作成します。SMTMMはシーン内の各ピクセルについて、1)そのピクセルが影にあるかどうかを問い合わせるときにシャドウマップを問い合わせる位置、2)シャドウマップがシャドウマップ問い合わせに答えるときにサブピクセル精度を提供するために、この位置で各SM軸に沿ってどのような解像度を必要とするか、に関する情報を含んでいます。
- SMTMMをCPUメモリに転送し、それを処理して「Shadow Map Tile Grid」を作成する。シャドウマップタイルグリッドには、仮想の\(n \times n\)タイル型SMの各SMタイルが、シーンのシャドウに使用されるときにサブピクセル精度を提供するために、各SM軸に沿ってどのような解像度が必要かという情報が含まれています。
- シャドウマップタイルグリッドの上に「Shadow Map Tile Grid Pyramid」を構築し、各軸に沿って必要なSMタイルの最大解像度を引き上げます。
- シャドウマップタイルグリッド・ピラミッドをトップダウンで再帰的に走査し、SM-タイルの暗黙のkd-ツリーを構築する。このように作成されたSM-タイルの解像度要件が、GPUがサポートする寸法のSM-タイル-テクスチャで両方のSM軸に沿って満たすことができる場合、対応するSM-タイルのシャドウマップが作成され、上記の遅延シャドウイング(セクション3.2)のようにシーンのその部分をシャドウイングするために直ちに使用されます。
以下、ステップをより詳細に説明し、セクション4.10では基本アルゴリズムに対する重要な最適化を紹介します:
4.2 Virtual Shadow Mapping Preparation: Eye-Space Depth Buffer
まず、3.2で説明したように、シーンのビュー空間の深度情報をEye-Space Depth Bufferにレンダリングします。効率化のため、ここでも\(4 \times float\) RGBAバッファを使用し、同時にシーンの影のないRGBカラーをレンダリングします。 したがって、シーンをレンダリングする必要はありません(注意:アプリケーションが深度優先のレンダリングを使用している場合、つまりZのみのパスから開始する場合、ZのみのパスのEye-Space Depth Bufferには\(1 \times float\)バッファを使用し、従来の\(1/z\)深度バッファをアタッチする必要があります)。
4.3 Shadow Map Tile Mapping Map Createion
「Shadow Map Tile Mapping Map」(「SMTMM」)は\(4 \times\)バイトのバッファです。通常、フレームバッファよりも解像度が低く、SMTMMの各 “ピクセル “がカバーする領域でシーンが必要とするシャドウマップの解像度に関する情報を含んでいます。図3はSMTMMをグラフィカルに表したものです。
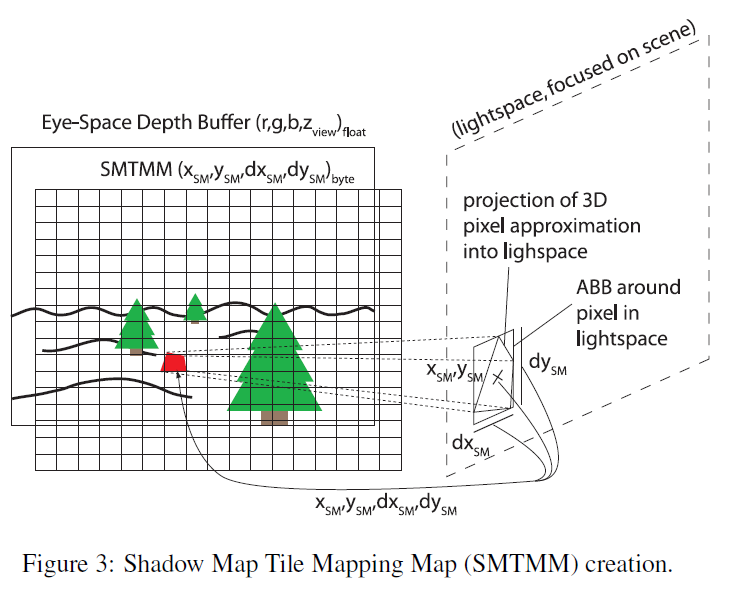
各SMTMMエントリ(”ピクセル”)の最初の2バイトの値は、フレームバッファの矩形の中心がシャドウマップを照会する位置に関する情報を含み、最後の2バイトのエントリは、シャドウマップ内の位置で各SM軸に沿って必要な解像度を表します。最後の2バイトのエントリは、シャドウマップ内の位置で各SM軸に沿って必要とされる解像度を表します。我々は、リードバック動作と次のステップでのCPU処理を高速に保つために、エントリにバイト値を使用しています;同じ理由で、SMTMMは通常フレームバッファよりも低い解像度を持つように選択されます(実用的な値の範囲については結果のセクションを参照)。シャドウマップにバイト値を使用することで、実際に必要なSM解像度の情報が得られます。\(4096^2\)のSM-タイル-テクスチャの場合、各SM軸に沿って16から32(すなわち、最大\(32 \times 32\) SM-タイル)の最大精細化により、大きなシーンでもサブピクセル精度が得られることがわかるからです。
シャドウマップ内の位置は、ピクセルシェーダ内で、ピクセルのスクリーン空間座標\((x_w, y_w)\)(テクスチャ座標としてピクセルシェーダに渡される)と、Eye-Space Depth Bufferから読み出されたEye-Space z(=深度)エントリ\(z_e\)を、3.2節で与えられた行列(式(1))を使用してEye-Space\((x_e, y_e, z_e)\)に変換することによって計算され、そこからシャドウマップのライト空間に変換されます。座標はすでに[0, 1]の範囲にあるので、単純に\(4 \times\)バイトのSMTMMサーフェスに出力すると、グラフィックスハードウェアによって自動的に[0, 255]バイトの範囲に変換されます。
各 SM 軸に沿って必要な解像度は、ピクセルシェーダで以下のように近似されます: まず、ピクセルシェーダに渡された現在のピクセルのテクスチャ座標から、\([0, 1]^2\)における\(x\)方向および\(y\)方向の隣接ピクセルの\((x,y)\)座標(すなわち、テクスチャ座標における左右および上下の隣接位置)を計算します。次に、これらのテクスチャ座標を使用して、Eye-Space Depth Buffer内の対応するビュー空間深度値を検索します; これらから、\(x\)軸と\(y\)軸に沿った絶対値\(\Delta z\)の小さい方、\(\Delta z_x\)と\(\Delta z_y\)を計算します。次に、これらの\(\Delta z\)値と隣接するピクセルの\(x\),\(y\)座標を使用して、空間内で現在のピクセルを表す近似矩形を構築します。そして、この矩形をSM空間に投影し、その周りにSM軸に整列したバウンディングボックスを計算します。そして、このバウンディングボックスの各範囲の半分の長さ\(\Delta_{sm\_axis}\)(\(sm\_axis={0,1}\))を、この点における各SM軸に沿った必要なSM解像度の基本尺度として使用します。
次に、SM軸に沿って必要なSM解像度をバイト値に量子化するために、以下の式を使用します:
\begin{eqnarray}
-{\rm log}_2 (round(\Delta_{sm\_axis} + {\rm float2}(0.5, 0.5))/ 256
\end{eqnarray}
(つまり、[0, 1]の範囲に正規化された対数値として出力し、グラフィックハードウェアはこれを再びバイト範囲に自動的に変換する。)
完全なSMTMM作成ピクセルシェーダは付録Aにあります。
4.4 Shadow Map Tile Grid Creation
「Shadow Map Tile Grid」(“SMTG”)を作成するために、SMTMMをCPUメモリに読み込みます。実際には、SMTMMの解像度がフレームバッファよりも低い、例えば\(256 \times 256\)であることが問題であり、これによって読み出しとCPUの処理が高速になります(この例では、SMTMMの寸法が256であることと、SMTMMのエントリの値が256個であることが等しいのは偶然であることに注意してください)。
我々が欲しいのは\(n \times n\)個のSMタイルのグリッド構造であり、各グリッドセルには各SM軸に沿った必要な解像度と、各SMタイルのスクリーン空間バウンディング矩形(SMタイルの影響を受けるスクリーン上のピクセルを軸方向に整列させた矩形)が含まれています。上記のブルートフォース\(n \times n\)仮想タイルシャドウマッピングと同様に、\(n\)は各SM軸に沿ったSMスライスの最大数で、典型的な\(n\)の値は16または32で、仮想タイルシャドウマップの256または1024のSMタイルに対応します。
CPUのランダム・メモリー・アクセス能力は、このタスクに適しています; SMTMMをリードバックした後、サーフェイスをロックし、各ピクセルのエントリーを処理します: SM-タイルの位置に関する保存された情報を使って、対応するSM-タイル-グリッドセルにアクセスし、1)各SM軸に沿って必要なSM解像度のエントリーを更新し(SMTMMのエントリーを用いて既存の値を最大化することで最小化します;詳細は後述します)、2)スクリーン空間バウンディング矩形を更新します(SMTMMの現在のピクセルの位置を囲むように拡張します)。
SMTMMは一般的にSM-タイル-グリッドよりもはるかに大きな分解能を持つように選択されるため、例えば軸あたり32エントリに対して256エントリなど、複数のSMTMMエントリからのデータが同じSM-タイル-グリッドセルに蓄積されることになります。
しかし、後で大きな解像度を必要とするごく少数のピクセル(例えば、スクリーン上の非常に小さな領域が、大きな投影エイリアシングを引き起こす方向性を持つことに起因する)を捨てることができるようにするために、ある解像度を必要とする各グリッドセル内のピクセル数を実際にカウントします。各SM-タイル-グリッド-セルに固定サイズの配列を使用し、ピクセル数の統計を保持します。固定サイズの配列を使用し、それらを小さく保つことを可能にするために、解像度\(\eta_0\)以下と閾値解像度\(\eta_1\)以上のピクセルの数をそれぞれ1つの配列エントリでカウントし、その中間の解像度を必要とするピクセルの数をそれぞれのエントリでカウントします; これはキャッシュのローカリティを高く保つためで、解像度の要求が非常に小さいピクセルの詳細な統計には興味がないからです。なぜかというと、これらは、明らかに実現が容易であり、実際には発生しない極めて高い解像度が要求されるピクセルを仮定したものだからです。\(\eta_0\)と\(\eta_1\)の実用的な値については結果のセクションを参照してください。
次の擬似コードは、シャドウマップ・タイル・グリッド作成の基本バージョンを示しています:
// smtg ... instance of the SMTG
// shift ... shift-convers from the SMTMM SM-coordinates
// entries to SMTG ones (e.g. [0,255] => [0, 31])
const int shift = 256/smtg.n
// smtmm ... instance of the SMTMM
// smtmm.n ... extent of SMTMM along both axes
for ix_smtmm = 0 to smtmm.n - 1
for iy_smtmm = 0 to smtmm.n - 1
SMTMM_Cell c_smtmm = smtmm(ix_smtmm, iy_smtmm)
SMTG_Cell c_smtg = smtg(smtmm.ix_sum >> shift, smtmm.iy_sm >> shift)
// Update the screen-space, axis aligned bounding box around the SM-tile
c_smtg.abb_screen.ExpandToIncludePoint(ix_smtmm/smtmm.n, iy_smtmm/smtmm.n)
// Update the maximum needed SM-resolution
c_smtg.sm_res_x = MAX(c_smtg.sm_res_x, c_smtmm.sm_res_x)
c_smtg.sm_res_y = MAX(c_smtg.sm_res_y, c_smtmm.sm_res_y)
.
4.5 Shadow Map Tile Grid Pyramid Creation
SM-tile-gridにSMTMMからのデータを入力した後、その上にSMタイルグリッドのピラミッド(“Shadow Map Tile Grid Pyramid”, “SMTGP”)を構築することで進めます。このピラミッドでは、連続する各グリッドが先行グリッドの半分の寸法と必要な解像度を持ち、各SM軸が先行グリッドの対応する\(2 \times 2\)グリッドセルの最大値になります。つまり、\(2 \times 2\)のセルを、4つのセルのそれぞれの最大値と、4つすべてのバウンディング矩形の周りのスクリーン空間のバウンディング矩形を含む、次の小さいグリッドの1つのセルに置き換えることによって、各SM軸に沿って必要な解像度を引き上げます。
各SM軸に沿った必要な解像度は、サブピクセル精度でシーン全体に影を付けるために必要な、仮想的なフォーカスされたシャドウマップを指すことに注意してください; したがって、\(2 \times 2=4\) の値を、次の上位のシャドウマップタイルグリッドピラミッドレベルの親セルにおける最大値に置き換えることは、ヒューリスティックな操作ではなく、数学的に正確な操作です(\(1 \times 1\) の最上位レベルのグリッドには、現在のフレームバッファ寸法に対してサブピクセル精度を与える、この仮想的な単一シャドウマップに必要な解像度が含まれます);下の結果セクションでわかるように、解像度の要件は中規模のシーンでも131072以上になり、現在ハードウェアでサポートされている最大テクスチャ寸法8192よりも16倍大きくなります。保存には64 GB以上が必要になります) 。
擬似コードによるシャドウマップ・タイル・グリッド・ピラミッド作成:
// smtg ... instance of the initial SMTG
// smtg.n ... extent of SMTG along both axes
// i_pyramid ... SMTGP index
const int i_pyramid = log2(smtg.n)
while(i_pyramid > 0)
// smtgp ... instance of the SMTGP
smtgp(i_pyramid) = smtg
for ix = 0 to smtgp(i_pyramid).n - 1
for iy = 0 to smtgp(i_pyramid).n - 1
SMTGP_Grid_Cell c_curr = smtgp(i)(ix, iy)
SMTGP_Grid_Cell c_parent = smtgp(i-1)(ix >> 1, iy >> 1)
// Update the screen-space, axis aligned bounding box
// around the parent SM-tile
c_parent.abb_screen.ExpandToIncludeABB(c_curr.abb_screen)
// Update the maximum needed SM-resolution
c_parent.sm_res_x = MAX(c_parent.sm_res_x, c_curr.sm_res_x)
c_parent.sm_res_y = MAX(c_parent.sm_res_y, c_curr.sm_res_y)
i_pyramid = i_pyramid >> 1
.
4.6 Shadow Map Tile Grid Pyramid Traversal
最後に、グリッドピラミッドをトップダウンで走査し、再帰的に走査しながら暗黙のkd-treeを以下のように構築します:少なくとも1つの軸に沿ったSM-タイル-グリッドセルの解像度要件が、GPUがサポートする大きさのSM-タイル-テクスチャで満たされない場合(例えば、現在のGPUでは通常:必要なSMの大きさ > 4096)、我々はそれを2つまたは4つのサブセルに1つまたは両方のSM-軸に沿って対称的に分割します。片方の軸だけがSM解像度の要件を満たせない場合は2つのサブセルに分割し、そうでない場合は4つのサブセルに分割します。そうでない場合は、Deferred Shadowing(3.2節参照)を使用し、各軸に沿って必要な解像度を持つSM-tileを直ちに作成し、3.2節で説明したように、Eye-Space Depth Bufferを使用してシーンの深度値を取得し、それで”Shadow Result Texture”(次の段落参照)をシャドウします。
“Shadow Result Texture”は、フレームバッファと同じ大きさの\(1 \times\)バイトのテクスチャで、シャドウイングの結果のみを書き込みます。これは、1ピクセルあたり1バイトのエントリしかないサーフェスに書き込むので、SMタイルの適用を高速化します。また、SMタイルがわずかに重なっていても、後から適用されたタイルのシャドウイング結果が前の結果を上書きするだけなので、潜在的な問題を回避できます。(シャドウ結果テクスチャは、シャドウキャスターまでの距離に応じてスクリーン空間をぼかすなど、シャドウに後処理効果を適用するためにも使用できます)。
シャドウマップタイルグリッドピラミッドのトラバーサルの擬似コード:
// SMT ... SM-tile instance
// P ... SMTGP pos index + pyramid index
// smtq ... queue holding SMT
smtq.push(SMT(P(0,0), P(0,0)))
while(!smtq.empty())
SMT smt = smtq.pop()
int ip_x = smt.ip_x, int ip_y = smt.ip_y
int sx = max(0, ip_y - ip_x), int sy = max(0, ip_x - ip_y)
Rect rect(ix << sx, iy << sy, ((ix + 1) << sx) - 1, ((iy + 1) << sy) - 1)
// ex and ey are 0 for no further refinement, 1 otherwise
int ex = Refine(smtgp(MAX(ip_x, ip_y)).MaxSmResInRect(rect).sm_res_x, ip_x, framebuffer.nx)
int ey = Refine(smtgp(MAX(ip_x, ip_y)).MaxSmResInRect(rect).sm_res_y, ip_y, framebuffer.ny)
if(ex > 0 || ey > 0) // refine this SM-tile further
int ip_x_sum = smt.ix + ex, int ip_y_sub = smt.iy + ey
int ix_sub = smt.ix << ex, int iy_sub = smt.iy << ey
for diy = 0 to ey
for dix = 0 to ex
smtq.push(SMT(P(ix_sub + dix, ip_x_sub), P(iy_sub + diy, ip_y_sub)))
else // do not refine this SM-tile further
ShadowShadowResultTextureWithSmTile(smt)
ここで,
// sm ... SM-texture
Refine(sm_res_needed, i_refinement, frambuffer_nx_or_ny) {
log2(sm.n) - round(log2(framebuffer_nx_or_ny/smtmm.n) + 0.5)
}
.
4.7 Apply Shadow to Scene
最後のステップでは、Eye-Space Depth BufferからのシーンRGBをShadow Result Textureで変調し、その結果得られる影付きシーンをフレームバッファに書き込みます。
このアルゴリズム全体は、総当たり的なアプローチと比較して、作成する必要のあるSMタイルの数を大幅に減らすだけでなく、より遠くにあるSMタイルに対して、より小さく長方形のSMタイル・テクスチャを使用します。したがって、リアルタイムではるかに高品質なシャドウマップが可能になります。定量的な比較については、結果のセクションをご覧ください。
4.8 Comparison with Adaptive Shadow Maps
我々のアプローチに似ているシャドウマッピング技法として、”Adaptive Shadow Maps”[7]と、そのGPUベースの実装である”Dynamic Adaptive Shadow Maps on Graphics Hardware”[11]が以前に発表されています。Adaptive Shadow Mapsとは対照的に、我々のアルゴリズムは、各フレームに対して完全な洗練手順を実行することで構築されており、動的なシーンに適しています。一方、Adaptive Shadow Mapは、最良のパフォーマンスを得るために、最近使用されたシャドウ・タイルを作成しなければなりません。これは、ライトの方向が変わろうが、シーン内のオブジェクトが動こうが、必ずキャッシュされたシャドウ・マップが無効になってしまうため、動的なシーンには適さないアプローチです([11]では、テスト・シーンが小さな四角形上の1本の木だけであるにもかかわらず、このケースでパフォーマンスが大きく低下しています)。これはまた、キャッシュされたタイルのためにビデオメモリを必要としないことを意味します。我々のアルゴリズムには、シャドウマップを各フレームでシーンの関連部分に「フォーカス」[3]できるという利点もあります。
4.9 Quality vs Performance Parameter
Fitted Virtual Shadow Mapは、非常に直感的な品質対性能のパラメーター\(\xi\)を導入することができます: SMタイルをさらに改良化するかどうかを決定する際に、SMTMMから得られる対数の解像度要求値から整数値\(\xi\)を引くことで、シーンにおける結果として得られる影の品質に直感的に影響を与えることができます;\(\xi\)が大きいほど、作成されるタイルが少なくなり、パフォーマンスが向上します。これにより、アルゴリズムを幅広いハードウェアにチューニングすることが可能です。全体の影の質に同じように影響するという意味で、パラメータの影響はスムーズであることに注意してください。\(\xi\)が十分に大きく選ばれ、SMタイルが1つしか作成されない場合、Fitted Virtual Shadow Mappingの影の品質は通常のシャドウマッピングと同じになります。
4.10 Shadow Map Tile Texture Size Optimization
基本的なFVSMアルゴリズムは、各SM軸に沿った各SMタイルに必要な解像度が十分に小さくなり、GPUが処理できる最大SMテクスチャサイズで満足できるようになるまで、シャドウマップを調整します。実際には、両方のSMタイル軸に沿った解像度のニーズは、最大解像度の2次SMテクスチャを必要とすることはほとんどありません。これは、シーンには常に遠近法の短縮があるという事実から理解することができます。つまり、視点から離れたピクセルは常に少ないSM解像度(SMがタイルに分割されているため、SMのリパラメータライゼーション技術とは異なり、ライト方向に対するビュー方向に関係なく、より離れたタイルでは常にこのようになります。これは、ビュー方向に平行または反平行ではないライト方向の遠近短縮からのみ利益を得ることができます)を必要とします。投影エイリアシングは通常、両方のSM軸に同時に影響を与えることはありません。これは、すべてのSMタイルに2次最大サイズのテクスチャを使用する代わりに、各軸に沿った解像度要件に従って矩形のSMを作成するという最適化につながります。これを行うには3つの異なる方法があります:
- 同じ2次元テクスチャのサブ矩形(最大サイズ)に描画する。
- 一連の2のべき乗のシャドウマップテクスチャのサブ矩形に描画します。この場合、シリーズ内の各テクスチャの寸法は、前のテクスチャと比較して半分になります。
- 各SM軸に沿って必要な寸法(=解像度)のシャドウマップテクスチャに描画する。
4つの異なるアプローチのメモリ要件は次のとおりです(\(t_{max}\)は最大テクスチャ寸法、\(w\)と\(h\)はSMタイル解像度の要件を満たすために必要な最小幅と高さのSMテクスチャ寸法です):
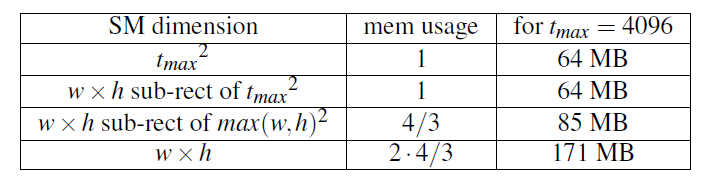
このことは、最適化2において、必要とされるSMテクスチャが寸法を持っていることを見ればわかります:\(\{ {t_{max}}^2, (\frac{1}{2} t_{max})^2, (\frac{1}{4} t_{max})^2, \cdots \}\) は(\({t_{max}}^2\)を抜いた)数列\(\sum 1 + \frac{1}{4} + \frac{1}{16} + \cdots = \sum_{n=0} (\frac{1}{4})^2 \leq \frac{1}{1 – \frac{1}{4}} = \frac{4}{3}\)となります。
最適化3では、(\({t_{max}}^2\)を再び抜いた)\(\sum (1 \cdot 1 + \frac{1}{2} \cdot 1 + 1 \cdot \frac{1}{2}) + (\frac{1}{2} \cdot \frac{1}{2} + (\frac{1}{2} \cdot \frac{1}{2}) \cdot \frac{1}{2} + \frac{1}{2} \cdot (\frac{1}{2} \cdot \frac{1}{2})) + \cdots = 2 \cdot \sum 1 + \frac{1}{4} + \frac{1}{16} + \cdots = 2 \cdot \frac{4}{3}\)の数列に帰着します。
\(t_{max}=4096\)の場合の実効メモリ消費量は、\(1\times float\) SMテクスチャの場合です。
我あれが求めているのは、小さなGPUメモリ消費と優れたパフォーマンスの組み合わせであることは明らかです。さまざまなアプローチのパフォーマンス比較と、結果としてどの最適化バリエーションを実際に使用するかの推奨事項については、以下の 「結果」 セクションを参照してください。
4.11 Handling Semitransparent Objects
ディファード・シャドウイングを使用する場合、最前面の不透明ピクセルの深度エントリのみがEye-Space Depth Bufferに保存されるため、半透明オブジェクトは別々に扱わなければなりません。
簡単な解決策は、半透明のオブジェクトをシャドウせずにシーンをシャドウした後でレンダリングすることです。これにより、許容できる場合とできない場合がある (わずかな) グロー効果がもたらされます。
もう1つの方法は、シーンに影をつけた後に半透明のオブジェクトをもう一度レンダリングし、従来のシャドウマッピングで影をつける(つまり、1つのシャドウマップを使う)ことです。実際には、半透明のオブジェクトが含まれる場合、シャドウイングの問題が複雑になるため、半透明のオブジェクトは通常、影を受けるだけで、影を落とさないように実装されます。この場合、セルフシャドウイングが発生しないという事実が、このアプローチを実用的なものにしています。また、オブジェクトが透明であればあるほど、影(ひいてはアーチファクト)は見えにくくなります。
あまり実用的ではありませんが、より正確な解決策は、半透明オブジェクトを別のバッファにレンダリングし、色とリニア深度を保存することです。このバッファを後で使用して、最前面の半透明オブジェクトを正しくシャドウすることもできます。この場合も、SMTMM内のエントリを2倍にする必要があることに注意してください。
最後に、完全に異なるアプローチとして、ディファードシャドウイングを使用せずに、マルチパスシャドウイング(3.1節参照)を使用してSMタイルをシーンに適用し、レンダリングする必要があるシーンの部分を各SMタイルのシーン画面領域範囲 (上記4.5を参照に制限することで速度を上げます。この場合、半透明のオブジェクトは、使用を開始する1つのシャドウマップと同様に、 (SMタイルで) レンダリングおよびシャドウできます。
5 Results
特に断りのない限り、すべての結果はNVidia GeForece 8800 GTS、640 MBのRAM、Pentium4 3.4 GHz(2 GB RAM)で作成されました。
我あれの研究の目的は、大規模から中規模のシーンに適用した場合のダイナミックシャドウマップシャドウの適用可能性を研究し、品質を向上させることです。実際には、現在ハードウェアでサポートされているシャドウマップの解像度は、特にシャドウマップのリパラメータライゼーションと組み合わせた場合に、影響範囲が小さい光源(広がり角が小さい地面近くのスポットライト、小さな部屋を照らす点光源など)の影を作成するのに十分です。さらに、FVSM のようなアルゴリズムのレンダリングコストは、ブルートフォースの仮想タイルドシャドウマッピングよりもはるかに高速ですが、現在のところ、複数の光源に適用するには高すぎます(フレームタイムの比較は図 4 を参照)。
丘陵地帯の広葉樹のシーンを選びました: これは中程度の大きさの屋外シーンであり、屋外シーンを高品質で動的にシャドウイングすることは困難であるため、実用的なシーンです。多くの場合、太陽によって照らされます。つまり、指向性ライトや遠距離のスポットライトによってモデル化できる単一の光源であり、単一のシャドウマップ(できれば非常に高解像度)を使って影をつけることができます。また、アルファテクスチャジオメトリを使用して効率的にモデル化およびレンダリングすることができるため、シャドウボリュームなどでシャドウすることはできません。我々の場合、フェンスと木の葉はアルファ・テクスチャの矩形です(これは、例えばビルボードやビルボード雲を遠くの木に使うように拡張できます)。さらに、太陽光の方向をアニメーション化することで、シャドウイングという観点から完全に動的なシーンになります(シーン自体が完全に静的であっても、光の位置や方向などが変わると、キャッシュされたシャドウマップ情報が無効になるため、前のフレームからのシャドウマップ情報をキャッシュして効率的に動作させるアルゴリズムには適さないことに注意してください)。
図1は、テストシーンのスクリーンショットです。通常のシャドウマッピング(4096^2シャドウマップ)とFitted Virtual Shadow Map(ライト空間透視シャドウマップ(LiSPSM))の品質を比較しています。
図4は、1024×1024のフレームバッファに\(10^5\)のトライアングルをレンダリングし、森林のシーンを通過する経路のフレーム時間曲線を示しています(経路に沿って飛行するビデオは、http:///www.cg.tuwien.ac.at/research/vr/fvsmからダウンロード可能です)。一番上の曲線は、\(16 \times 16\)の\(4096^2\)のシャドウマップを使用した、総当たりによる仮想タイルドシャドウマッピングを表しています;FVSMは、Adaptive SM-tile Shadow Mapテクスチャサイズ、最大\(32 \times 32\)リファインメントのFitted Virtual SMを表示します。\(1 \times 1\)のSMカーブは、最終的に\(4096^2\)のシャドウマップテクスチャを使用する従来のシャドウマッピングのフレーム時間を示します (シャドウの品質が大幅に低下します) 。すべてのレンダリングでLiSPSM [19]が有効です。図2は、森のシーンを通るパスの終点でのスクリーンショットです(フルパスは、添付メディアの「Winter Forest Frametime Curve Path」フォルダで見ることができます)。

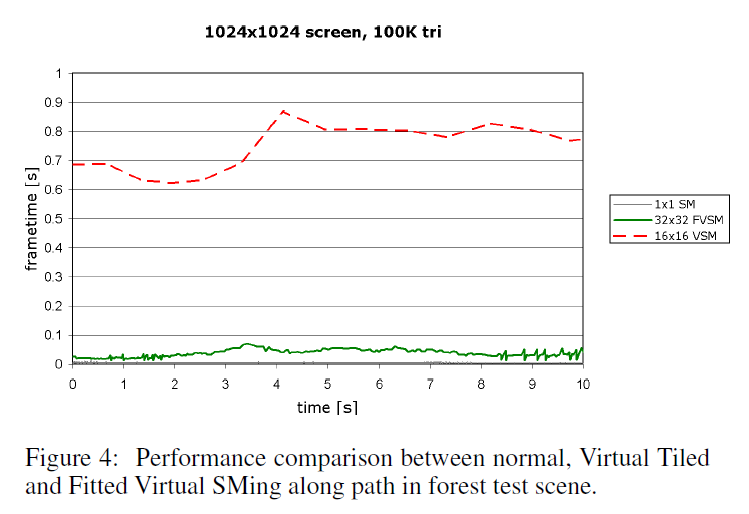
図5は、異なるFVSM SMタイル作成モード(4.10節参照)の性能比較(シーン内の同じパスに沿って)を示しています。重要なことは、この最適化によってフレームタイムのピークが滑らかになること、つまりアルゴリズムのワーストケースの性能が向上することです。また、各SMタイル作成モードがその前のモードよりも高速であることもわかります。最初の2つのスキームに対する3番目のスキームのメモリ消費量は4/3であるため(つまり、1/3だけ多くのメモリを消費する)、実際には、一連の2乗シャドウマップテクスチャのサブ矩形にレンダリングすることが、ほとんどの場合、パフォーマンスとメモリ消費量の間の最良の妥協点です。
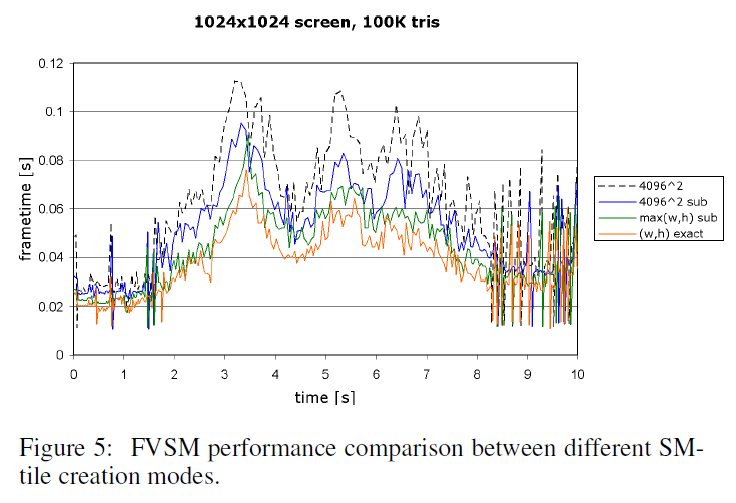
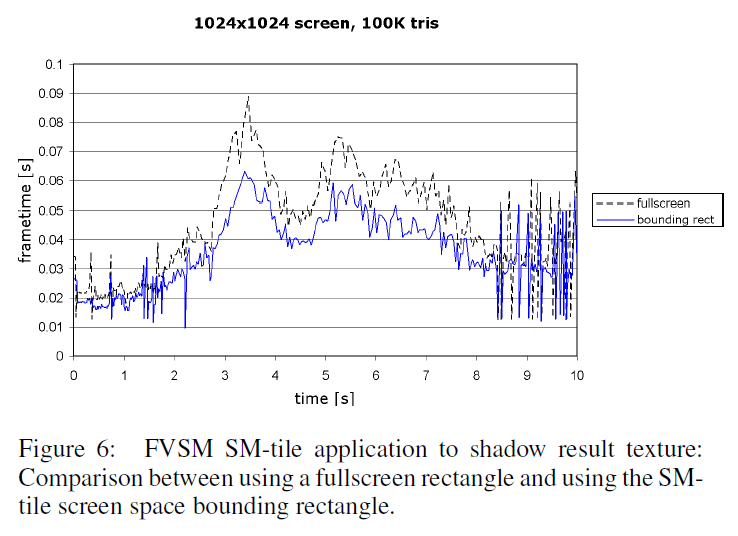
図6は、フルスクリーンクアッドまたは各SMタイル(セクション4.5を参照)を囲むスクリーン空間のバウンディング矩形を使用して、シャドウ結果のテクスチャにSMタイルを適用した場合のパフォーマンスを比較したものです。4.5秒付近のフレームタイムピークが再び平滑化され、アルゴ リズムのワーストケースのパフォーマンスが約25%改善されていることに注意してください。
\(1024^2\)のフレームバッファの場合、\(256^2\)のSMTMMが良い結果をもたらし、同時にSMTMMの作成と処理のオーバーヘッドを低く保つことがわかりました。
詳細なSM-tile-required-resolution-statisticsパラメータ\(\eta_0\)と\(\eta_1\)については、\(\eta_0=17\)と\(\eta_1=22\)が実際にうまく機能することがわかりました。
図7は、\(\xi=0, \cdots, 5\)の場合の品質対性能パラメータ\(\xi\)の影響を示しており、\(\xi=5\)は通常のシャドウマッピングと同等のシャドウ品質を与えます。シャドウの品質がシーン全体で均一でなくなっているのがわかります。

また、精度の問題に起因する、結果として得られる影にSMタイルの境界が見えるという実装上の問題にも対処したいです(SMタイルはサブピクセル精度を提供するようにアルゴリズムによって生成されるため、目に見える境界の原因は他にないことに注意):これは、SMタイルを少しオーバーラップさせることで簡単に修正できます。シャドウイング結果は、シーンカラーと合成される前に、まずシャドウ結果テクスチャに蓄積されるため、他のSMタイルから以前のシャドウ値を上書きしても問題ないことに注意してください。
フォーカシングでシャドウマッピングを使用した場合のアンダーサンプリングアーティファクトの有無は、動きの中で見るのが一番わかりやすいので、http://www.cg.tuwien.ac.at/research/vr/fvsm にある添付のビデオとスクリーンショットをご覧ください。
6 Conclusion
我々は、シャドウマップのフォーカシングやシャドウマップのリパラメータライゼーション技術など、これまでのシャドウマップの改良を活用すると同時に、アンダーサンプリングアーティファクトを発生させることなく、大規模なシーンの効率的なシャドウイングを可能にする新しいスマートシャドウマップアルゴリズムであるFitted Virtual Shadow Mapを導入しました。仮想シャドウマッピングは、現在のGPUのメモリコストとテクスチャサイズの制限をバイパスするアルゴリズムを可能にします。ブルートフォース仮想タイルシャドウマッピングの代わりに、Fitted Virtual Shadow Mapは、シャドウマップのどこにどのような解像度が必要であるかについての情報を含むマップを作成するためにGPUとCPU処理の組み合わせを採用しています。これにより、ブルートフォース・アプローチと比較して、少なくとも1桁の性能向上が実現され、なおかつパースペクティブや投影エイリアシングを大幅に削減または除去することができます。このアルゴリズムは、シーンの品質要件に応じて、いくつかのパラメータで調整することができます;最も重要なのは、非常に直感的なquality-vs-speedパラメータを使用して、シャドウの品質を均一に通常のシャドウマッピングまで下げることができることです。
References

A Appendix: SMTMM Creation Pixel Shader
