こんにちわ、Pocolです。
今日は,
[Giegl 2007] Markus Giegl, Michael Wimmer, “Queried Virtual Shadow Maps”, I3D’07: Proceeding of the 2007 symposium on Interactive 3D graphics and games, pp.65-72, April 2007.
を見てみようと思います。いつもながら,誤字誤訳等があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けると有難いです。
あと,今回は論文の方を見ますが,ShaderX5にもQueried Virtual Shadow Mapの記載がありますので,興味がある方はそちらも参考にすると良いかと思います。あと時代的にコンピュートシェーダが無い時代の論文なので,セクション8のHardware Extensionに記述されている一部の内容は,現代ではコンピュートシェーダで実装できるかと思い al. ます。

Abstract
シャドウマップによるシャドウイングは、シャドウマップの解像度が低すぎるため、アンダーサンプリングによるアーチファクト、いわゆる透視投影エイリアシングが発生するという根本的な問題が長年に渡って存在していました。
本論文では、GPUハードウェアの限界を超えてシャドウマップの解像度を仮想的に高めることで、大規模なシーンのシャドウイングが可能な新しいリアルタイムシャドウマッピングアルゴリズムを提案します。
まず、シャドウマップ全体の解像度を一律に上げるブルートフォースアプローチから始めます。その後、GPUフレンドリーでありながら、実行時のパフォーマンスを大幅に向上させるスマートバージョンを導入します。このアルゴリズムには、簡単に使える性能/品質トレードオフ・パラメータが含まれており、幅広いグラフィックス・ハードウェアに対応できるようになっています。
1 Introduction
シャドウマッピングは、ラスタライズを採用してファーストヒットビジビリティ問題を解決し、この結果を利用してシーンの直射日光の影を計算する非常に魅力的なアプローチです。このエレガントなアプローチには、1つの基本的な問題があります。シャドウマップは、与えられたフレームバッファの解像度に対してサブピクセルの精度で可視性クエリーに答えられるように十分な情報を含んでいなければなりません。そうではない場合エイリアシングアーティファクトが目に付くことになります。この情報がシャドウマップに含まれていない場合、すべてのアルゴリズムができることは、例えばフィルタリングによって、これらのアーティファクトをマスクしようとすることです。
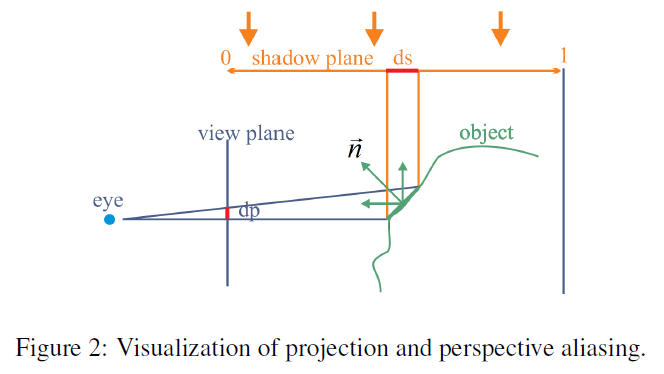
図2は、2種類のシャドウマップエイリアスの発生源を可視化したものです。
投影エイリアシングは、シャドウマップのテクセルが影を受ける面の広い範囲に投影されるほど強く、この場合、面の法線が光の方向に対して垂直であるほど、強くなります。
透視エイリアシングは、シャドウマップレシーバーが視点に近いほど、強くなります。これは、透視投影の性質上、オブジェクトが視点に近いほど、スクリーン上でより多くのピクセルを占有するためです。一方,シャドウマップリパラメータライゼーション技術(下記2章参照)は,シャドウマップにレンダリングされるジオメトリをグローバルに歪め,シャドウマップを参照するときに視点の近くでより多くの情報が利用可能になるようにするものです。変換がグローバルであるため,投影エイリアシングの局所的な効果に対して何もすることができません。
ユニフォームシャドウマップに含まれる情報量を増やすには、シャドウマップテクスチャの解像度を上げるのが正攻法です。これは、メモリ消費量が2次関数的に増加するため、非常に速く非現実的になります(現在のハードウェアでは、サポートされている最大テクスチャサイズ、通常は\(4096 \times 4096\)が、メモリを使い果たす前でも制限要因になります)。
本論文では、現在のグラフィックスハードウェア上で動作し、メモリ消費量の2次関数的な増加を回避しつつ、シーンの影付けに利用できる有効なシャドウマップ解像度を増加させるアルゴリズムを紹介します。これは適応的な方法で行われ、前のフレームからの情報を保存する必要なく、必要な場所でより多くのシャドウマップ解像度を作成します(完全に動的なシーンに適しています)。これにより、シャドウマップクエリに関してサブピクセル精度を保証し、投影エイリアシングと透視エイリアシングの両方を取り除くことができます。また、直感的に使用できる品質と速度のトレードオフ・パラメータを備えており、これを使用して、さまざまなグラフィックス・ハードウェアに対応させることができます。
このアルゴリズムは、シャドウマップリパラメータライゼーションなど、他の手法と直交しているため、組み合わせることが可能です。ライト空間透視シャドウマップ[Wimmer et al. 2004]に対して行いました。
2 Previous work
シャドウアルゴリズムの最も重要な2つのカテゴリは、シャドウボリューム [Crow 1977] とシャドウマッピング [Williams 1978]です。
ほとんどのシャドウマップの公表文献は、エイリアシング・アーティファクトの問題を解決しようとしています。近傍比率フィルタリング[Reevesら 1987]は、シャドウマップをサンプリングすることにより、再投影の問題を軽減します。分散シャドウマップでは、Donellyら[Dennelly and Lauritzen 2006]は、シャドウマップのサンプリング結果をさらに改善するために、深度値の分散を使用しています。多くの論文が、シャドウマップのリパラメータライゼーションによって、透視視錐台の投影から生じる透視エイリアシングを解決しようと試みています。もともとはStammingerとDrettakis [Stamminger and Drettakis 2002]によって開拓されたもので、彼はシャドウマップに観測者と同じ透視変換をかけることによって透視エイリアシングを除去しようとしました。このアイデアは後にMartianとTan [Martin and Tan 2004]によって台形シャドウマップで、Wimmerら[Wimmer et al. 2004]によってライト空間透視シャドウマップで、ChongらのA Lixel for Every Pixel[Chong and Gortler 2004]によって改良されました。しかし、すべてのシャドウマップリパラメータライゼーション法は、透視エイリアシングにのみ対処します。例えば、投影エイリアシングを改善するために必要なシャドウマップの主解像度を上げることはできません。さらに、ライトと視線の方向が直交している場合にのみうまく機能します。これらの方向が平行である場合、シャドウマップのパラメータ化はスクリーン全体にわたって実行されるため、ユニフォームシャドウマッピングに戻す必要があります。最近、Lloydら[Lloyd et al. 2006]は、リパラメータライゼーション技術とともに、視錐台の側面またはスライスに適用される複数のシャドウマップの使用を集中的に研究し、興味深い結果を得ました;しかし、これらのアプローチは、透視エイリアシングに対処できるだけで、投影エイリアシングを緩和することはできません。本論文では、視錐台の方向や、アーティファクトが透視エイリアシングか投影エイリアシングかに関係なく、シャドウマップの解像度を向上させることを目的とします。
Aila と Laine [Aila and Laine 2004] と Johnsonら [Johnson et al. 2005] は、エイリアシング問題をエレガントに完全に回避しますが、現在利用できないリアルタイム性能のためのハードウェア拡張に依存します。
エイリアシング問題を解決する別のアプローチとして,適応的シャドウマップ [Fernando et al. 2001] (Queried Virtual Shadow Mapsとの比較については,以下のセクション6も参照) があります。ここでは,異なるエイリアシングアーチファクトのために必要な部分に解像度を提供するために,階層的にShadow Mapが保存されます。しかし、このアプローチは、複数のリードバックを必要とし、現在のグラフィックスハードウェアにうまく対応しません。また,Lefohn [Lefohn et al. 2005] は GPU をより有効に活用するための拡張を提案し,Arvo [Arvo 2004] は SM の解像度を高めるためにライトビューをスライスします。
Second depth shadow mapping [Wang and Molnar 1994] は,深度量子化および自己オクルージョンによる問題を軽減するために使用することができます。Brabecら[Barabec et al. 2002]は,視錐台とシーンの交点にシャドウマップをフォーカスすることによって,ユニフォームシャドウマップ品質を向上させました。
シャドウマッピングとシャドウアルゴリズムの一般的な優れた概要は、Möller と Haines の Real-Time Rendering book [Möller and Haines 2002] や [Hasenfratz et al.2003]にもあります。
3 Virtual Tiled Shadow Mapping
まず、Virtual Tiled Shadow Mappingを紹介します。これは、ハードウェアがサポートする最大テクスチャサイズを超えてシャドウマップの解像度を上げるためのブルートフォースアプローチです。基本的なアルゴリズムは以下の通りです。
- GPU がサポートする最大のシャドウマップテクスチャを割り当てる。たとえば、4096 \(\times\) 4096。
- シャドウマップのx軸とy軸に沿って、\(n \times n\)(例えば\(16 \times 16\))の等しいサイズのタイルに分割する(各タイルは、フルシャドウマップテクスチャ解像度。例えば4096 \(\times\) 4096テクセル、すなわちこの例ではフルシャドウマップの有効解像度は(16 * 4096) \(\times\)(16 *4096)=65536 \(\times\) 65536を使用します)。
- (a) シャドウマップをシャドウマップテクスチャにレンダリングする(タイルのライトフラストレーションへのカリングを使用し、前のタイルのシャドウマップを上書きする)。
- (b) 現在のシャドウマップタイルで覆われているシーンの部分に影をつける(変調する)ために、即座に使用します。
各タイルに対して
タイル上のループを実装する方法として、マルチパスシャドウイングとディファードシャドウイングの2つがあります。
3.1 Multi-Pass Shadowing
連続したシャドウマップタイルをシーンに適用する方法の1つに、マルチパスレンダリングがあります。最初のパスでは、シーンは通常通り(フルシェーディングと深度書き込みを有効にして)レンダリングされ、最初のシャドウマップタイルが適用されます。後続の各シャドウマップタイルに対して、シーンは再度レンダリングされますが、関連するタイルを使用するシャドウマッピングのみがフレームバッファに適用されます。シャドウマップタイルの外側に落ちるピクセルは抑制されます。深度書き込みとシェーディングは無効で、深度比較関数はこれらのパスで EQUAL に設定されます(ドライバのサポートによっては、EQUAL の代わりに LESSQUAL を使用することが理にかなっていることがあります)。
3.2 Deferred Shadowing
マルチパスシャドウイングは、実装は簡単ですが、シーン全体を何度もレンダリングするため、パフォーマンスのオーバーヘッドが大きくなります。シーンへのシャドウマップタイルの適用を高速化するために、我々は「ディファードシャドウイング」と呼ぶディファードシェーディングのバリエーションを使用しています。シャドウイングは、シーンジオメトリを再ラスタライズする代わりにシーンの線形深度バッファを使用して行われます。次のシャドウイングパス、すなわち、次のシャドウマップタイルを処理するのに必要な情報はパス間のその場で作成されます。シーンはまず、Eye-Space Depth Bufferと呼ばれる視線空間の深度を保存するテクスチャにレンダリングされます。その後の各タイルドシャドウイングパスは、このテクスチャを読み取り、スクリーン座標とEye-Space Depth Bufferに格納された深度を使用して、各ピクセルでの可視サーフェイスのワールド空間位置を計算することができます。そして、ワールド空間の位置は、前と同じようにシャドウマップタイルを使用してシャドウイングされます。Eye-Space Depth Buffer に修正されていない視線空間の z 座標を保存することで、シャドウマップの参照が、オリジナルのシーンオブジェクトがシャドウマッピングに使用された場合と同じ結果を生成することが保証されることに注意してください。例えばウィンドウ空間のz座標(これは非常に非線形です)や固定精度のwバッファ(現在のハードウェアでまだサポートされている場合)を使用してz値を取得する他の方法は、必然的に画像のアーティファクトにつながるので、これは重要です。具体的には、次のように動作します。
- 最初のパスでは、上記のようにシーンをレンダリングしますが、4コンポーネントの32ビット浮動小数点レンダーターゲットにレンダリングします。ピクセルシェーダで、修正されていない視線空間の z 座標を\(\alpha\)-コンポーネントに格納します。このコンポーネントが Eye-Space Depth Buffer を形成します(ただし、簡略化のため、4 コンポーネントターゲット全体を Eye-Space Depth Buffer と呼びます)。このライトによって照らされたときのオブジェクトの各ピクセルの色(シャドウイングを無視)が RGB チャンネルに書き込まれます。
- 各シャドウマップタイルについて
- (a) マルチパスシャドウマッピングと同様に、シャドウマップテクスチャにレンダリングします。
- (b) シーン全体のジオメトリを再度レンダリングする代わりに、Eye-Space Depth Bufferをテクスチャとしてバインドした全画面矩形をレンダリングします。
- (c) 各フラグメントのピクセルシェーダで、Eye-Space Depth Buffer のアルファチャンネルでフラグメントの視線方向の深さを調べ、ワールド空間にアンプロジェクションします(下図参照)。投影されていないフラグメントを使用して、シャドウイング項を計算します。次に、Eye-Space Depth BufferからすでにシェーディングされたRGB値をシャドウイング項と乗算します。
- (d) シェーディングされた,場合によってはシャドウされたフラグメントの結果がフレームバッファに書き込まれます。
個々のパスにおけるピクセルシェーダの演算は、アンプロジェクト演算を除いて、非常に単純なものです。ウィンドウ \((x_w, y_w, z_w)\) 座標から視空間 \((x_e, y_e, z_e)\) 座標に変換する標準的なビューポートのアンプロジェクションとは異なり、この操作は \((x_w, y_w)\) (テクスチャ座標として与えられる、すなわち、0 から 1 まで) と \(z_e\) からeyespace \((x_e, y_e, z_e)\) を推定しなければなりません。これは、以下の行列変換を使用して行うことができます。
\begin{eqnarray}
\begin{pmatrix} x_e \\ y_e \\ z_e \end{pmatrix} = z_e \cdot
\begin{pmatrix} \frac{1}{a_x} & 0 & -\frac{b_x}{a_x} \\ 0 & \frac{1}{x_y} & – \frac{b_y}{a_y} \\ 0 & 0 & 1 \end{pmatrix} \cdot
\begin{pmatrix} 2 & 0 & 1 \\ 0 & 2 & -1 \\ 0 & 0 & 1 \end{pmatrix} \cdot
\begin{pmatrix} x_w \\ y_w \\ 1 \end{pmatrix} \tag{1}
\end{eqnarray}
ここで,最初の行列のパラメータ \(a_x\), \(a_y\), \(b_x\), \(b_y\) は,グラフィックス API に供給された射影行列 \(P\) から取得する必要があります.
\begin{eqnarray}
P = \begin{pmatrix} a_x & 0 & b_x & 0 \\
0 & a_y & b_y & 0 \\
0 & 0 & \cdots & \cdots \\
0 & 0 & 1 & 1 \end{pmatrix}
\end{eqnarray}
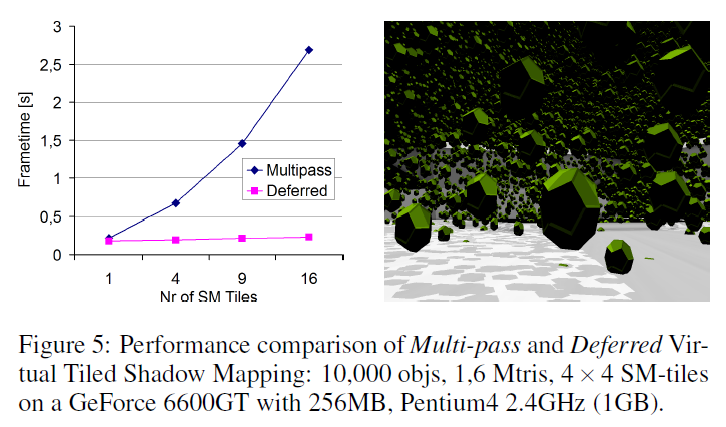
マルチパスとディファードシャドーの比較は図5をご覧ください。
4 Queried Virtual Shadow Mapping
4.1 Smart Refinement Perfered
Virtual Tiled Shadow Mapping は、シャドウマップテクスチャの解像度を 1 つ上げるのに必要なシャドウマップタイルの数が 2 次式に増加するため、ブルートフォースアプローチであり、実用性は限定的です。そこで、視点付近や投影エイリアシングの多い領域など、必要な部分のみシャドウマップを適応的に改良することを目指します。我々は、高レベル(\(n \geq 16\)、すなわち \(\geq 256\) シャドウマップタイル)に改善させたいと考えていますが、各フレームで実行できるように十分に速く、アルゴリズムのGPUフレンドリ性を壊すことなく実行します。一つの仮説として、次のような方法があります。シーンを直接シャドウ化せず、シャドウ化パスの結果をフレームバッファのサイズの余分な \(1 \time float\) テクスチャ(”shadow result texture”)に書き込みます。その後、シャドウマップをクワッドツリー方式で改善します。まず、1 つのシャドウマップタイルでシャドウ結果テクスチャ全体をシャドウします。タイルを\(2 \times 2\)のサブタイルに分割し、それぞれのサブタイルでシャドウ結果テクスチャをシャドウします。有効シャドウマップ解像度の増加により、各タイルのシャドウ結果テクスチャがどれだけ改善されるかは不明です。リファインメントによって達成された向上が十分に小さい場合、このタイル以上の処理を停止します。そうでない場合は、このタイルを再度\(2 \times 2\)のサブタイルに分割し、以下同様とします。ブルートフォースアプローチと比較して、これは必要なシャドウマップタイルの数を大幅に削減することにつながるでしょう。残念ながら、GPU はこのような「スマート」なアルゴリズムを効率的に実行する能力が非常に限られており、特に 4 分木のような中程度に複雑なデータ構造を使用するものには、その能力が不足しています。したがって、シャドウマップタイルをさらにリファインメントさせるかどうかの決定を、CPUに移行させる必要があります。必要な情報を CPU に渡す唯一の簡単な方法は、各リファインメントステップの後にシャドウ結果テクスチャ全体を読み返し、変更されたピクセルを数えることですが、これは法外なコストがかかります。
4.2 Queried Refinement: GPU Friendly & Smart
その代わりに、ピクセルシェーダから放出されるフラグメントの数をカウントする、GPU Occlusion Queryメカニズムの斬新な使い方を思いつきました。オクルージョンクエリは、画像空間境界ボリューム可視性テストをサポートするために導入され、今までのところ、グラフィックスハードウェアベンダーによってサポートされているメインストリームを見てきました。シャドウマップサブタイルをシャドウ結果テクスチャに適用するとき、結果のシャドウ値が前の絞り込みステップと異なる場合に のみフラグメントを生成するようにピクセルシェーダに指示します (これは、シェーダ内で前の絞り込みステップ(shadow result texture)に アクセスすることによって容易に行うことができます)。シャドウ結果テクスチャの変更されたピクセルの数と同じである、生成されたフラグメントの数\(\eta\)は、オクルージョンクエリで各シャドウマップタイルのアプリケーションをブラケットすることによって、見つけられます。そして、CPUは、対応するオクルージョンクエリが返す値を閾値\(\eta_{min}\)と比較することで、タイルをさらに絞り込むかどうかを決定することができます。\(\eta_{min}\) よりも大きなピクセル数が変化した場合,タイルは4つのサブタイルに分割され,そうでなければこのタイルの改善は停止されます.さらに、シャドウマップ軸ごとに許可されるタイルの最大数、\(\xi_{max}\)を2番目のリファインメント終了基準として使用します。このように、シャドウマップタイルをリファインするかどうかの決定は、フレームバッファのリードバックなしで行うことができ、これはアルゴリズム全体がリアルタイムでより大きな有効シャドウマップ解像度を生成することを可能にします。
5 Jump Optimizations
ハードウェアでサポートされる最大のシャドウマップテクスチャサイズを仮想シャドウマップテクスチャに使用することは、一般的に最良の選択ではありません。これは、満たされる必要がある仮想シャドウマップの最小数が\(1+4=5\)(初期シャドウマップと精密化ステップ)であることに由来します。以下の2つの最適化は、この観察を利用し、シャドウマップを分割する代わりにシャドウマップテクスチャサイズを増加させることでレンダリングを高速化します。
5.1 Maximum Refinement Jump
この最適化は、最大タイル改善基準\(\xi_{max}\)(シャドウマップ軸あたりの最大許容タイル数)を利用します。タイル(サイズ \(s\))を分割する前に、まず、タイルを分割する代わりに、大きなシャドウマップテクスチャ(すなわち、より高いシャドウマップ解像度)に切り替えることによって、最大仮想シャドウマップ解像度\(\xi_{max} \cdot s\)にも1ステップで到達しうるかをテストします。\(\xi\) を現在のタイル改善度として、\(\xi_{max} \cdot s \geq s_{max} \cdot \xi\) であれば、ジャンプを行います。このタイルのユーザー定義の仮想シャドウマップ解像度が最大になることがわかっているので、このタイルをそれ以上絞り込むことはしないため、シャドウイングステップのクエリーをオフにします。
5.2 Opportunity Jump
好機ジャンプ最適化は、\(\eta\)(最後の改善ステップを通じて変化したシャドウ結果テクスチャのピクセル数)の今後の進展を予測するために、ヒューリスティック基準を使用します。予測は、\(\eta\) が「ジャンプ距離」(改善のステップ数)\(\frac{s_{max}}{s}\) 内で \(\eta_{min}\) より小さくなる場合、再びタイルを改善せず、代わりにシャドウマップテクスチャサイズを増加させます。\(\eta_{min}\)の近傍では、各リファインメントステップで\(\eta\)が少なくとも係数\(f_{\eta}\)で減少すると仮定します。\(f_{\eta}\)は定数係数で、この品質要求に応じてユーザーが設定することができる(\(f_{\eta}\)の意味のある値については、以下の結果セクションを参照のこと)。\(\eta \cdot (f_{\eta})^{ \frac{s_{max}}{s} } \geq \eta_{min}\) ならば、ジャンプを行います。
シャドウイングステップのクエリーを再びオフにし、それ以上の絞り込みを停止します。これは、万が一タイルが意図した解像度に達しない場合、\(s=s_{max}\)のシャドウマップを4つ使用しなければならないため、タイルをさらに分割するには不釣り合いにコストがかかるためです(\(s_{max} \times s_{max}\)シャドウマップを複数生成するコストのため、最初からシャドウマップタイルに\(s=s_{max}\)は使用しない前提となっている)。
6 Comparison with Adaptive Shadow Maps
我々のアルゴリズムは,”Adaptive shadow maps” [Fernando et al. 2001] とそのGPUベースの実装である “Dynamic Adaptive Shadow Maps on Graphics Hardware” [Lefohn et al. 2005] に精神的に似ており,シャドウマップを改善するために4分木方式も使用します(これは多かれ少なかれ当然の選択と言えるでしょう).しかし,各カメラピクセルのために必要なシャドウマップ解像度を予測しようとするのではなく,解像度が十分に高いことを発見したときに,単純に絞り込みを停止しています。このメカニズムの効率性により、各フレームに対して完全な改善手順を事前に実行することができます。これは、最高のパフォーマンスのために最近使用されたシャドウタイルをキャッシュする必要がある適応的シャドウマップとは対照的で、ダイナミックなシーンにはあまり適していないアプローチです(テストシーンは小さな四角形の上の単一の木だけから成るにもかかわらず、[Lefohn et al. 2005]) これはまた、キャッシュされたタイルのための永続的なビデオメモリが不要であることを意味します。
7 Results
図3は、本稿で使用したテストシーンを示したものです。このシーンには、多数の高周波シャドウキャスター(枝)があり、自己影化するとともに、シャドウレシーバーが近似できないため、不規則に影をレシーブしています。また、視点が、枝や木の幹などのシャドウレシーバーに近い位置にあることもあり、シャドウマッピングのアーティファクトを隠すことが難しくなっています。さらに、地面の丘陵構造は、投影エイリアシングを発生させます。

特に断りのない限り、すべての結果は512MBのRAMを搭載したTAI Radeon X1900XTXとPentium4 3.4GHz(2GB RAM)で作成されています。
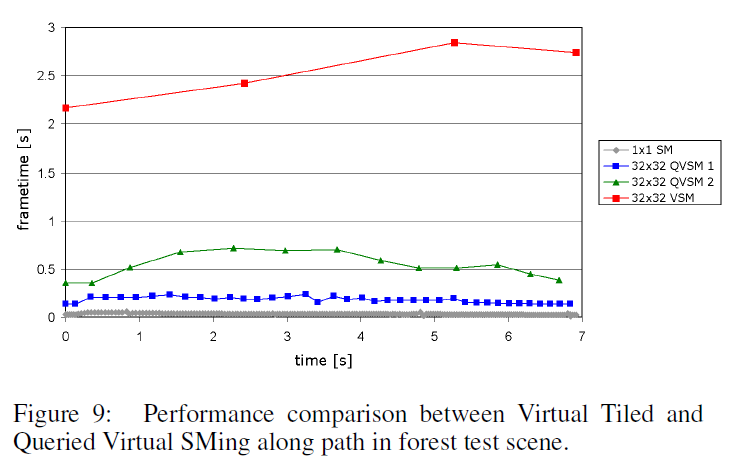
図9は、\(5 \times 10^6\)トライアングルを\(1024 \times 1024\)フレームバッファにレンダリングした森林シーンのフレーム時間曲線を示しています。QVSM1 と QVSM2 は、\(2048^2\) の SM タイルを使用したQueried Virtual Shadow Mappingを示しています、 QVSM1とQVSM2は、それぞれ\(\eta_{min}=2500\)と\(\eta_{min}=0\)を使用して\(4096^2\)に\(32 \times 32\)の最大改善とジャンプ最適化を行ったものです。シャドウマップカーブは、現在ハードウェアでサポートされている最大\(4096^2\)のシャドウマップテクスチャを使用した従来のシャドウマッピングのフレーム時間を示しています(シャドウの品質が大幅に低下します)。すべてのシャドウマップレンダリングでLiSPSM [Wimmer et al. 2004]がアクティブです \(\eta_{min}=0\)、つまりまったく同じシャドウイング品質では、Queried Virtual Shadow Mapsはブルートフォースバーチャルタイルシャドウマッピングより4倍以上高速であることがわかります。\(\eta_{min}=2500\)では、それでも優れたシャドウ品質が得られ、Queried Virtual Shadow Mapは15倍近く高速です。シーンのシャドウに使用される有効な仮想シャドウマップの解像度は、従来のシャドウマッピングの4096と比較して、\(32 \times 2048=65536\)です。図7は、従来のシャドウマッピングとQueried Virtual Shadow Mappingの視覚的品質を比較した、パスに沿ったスクリーンショットです。

図10に、同じ林道で\(\eta_{min}\)(シャドウタイル改善ステップでタイルをさらに改善するために変更する必要がある最小のピクセル数)のいくつかの値に対するフレームタイムを示します。\(\eta_{min}\)が小さいほどフレームタイムの変動が大きいことがわかります。これは、\(\eta_{min}\)を小さくすると、シーン(eye position、ライトの方向など)の変化に対してアルゴリズムがより敏感になり、作成されるシャドウマップタイルの数がより多く変動するためです。
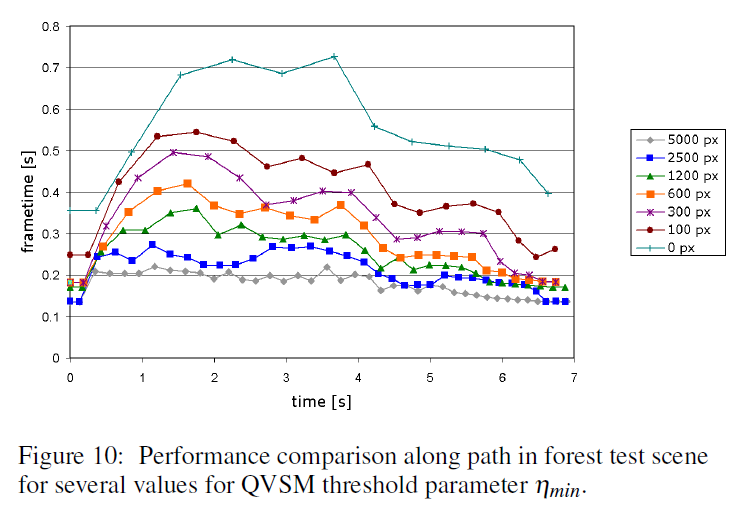
図11は、\(f_{\eta} = \frac{1}{4}\)でジャンプ最適化した場合のフレームタイムの比較です。一般に、好機ジャンプの方が大きな効果があることがわかります。また、この曲線からわかるのは、好機ジャンプは最大フレームタイムに非常に有益な影響を与え、フレームタイムのスパイクをカットし、スムーズなフレームレートに貢献していることです。\(\eta_{min}\) の近傍で \(\eta\) の挙動を観察した結果、\(f_{\eta}\) は \(f_{\eta}=\frac{1}{2}\) から \(\frac{1}{8}\) の間にあるように選択されるべきです。
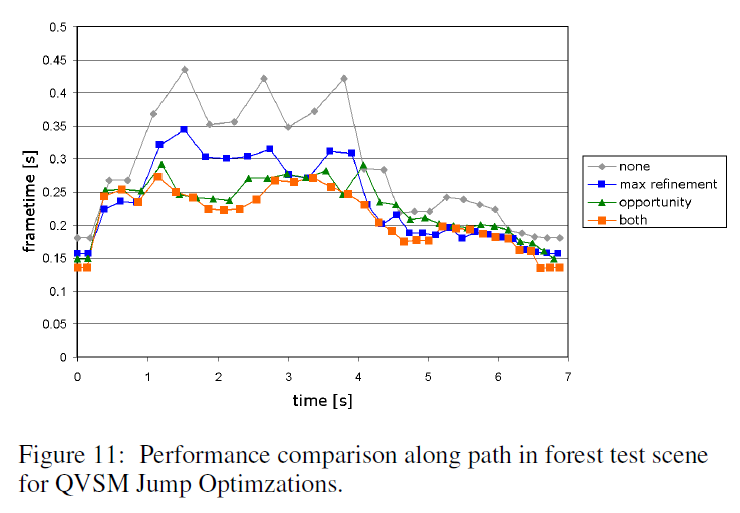
\(f_{\eta} = \frac{1}{2}\)は非常に保守的な仮定ですが、\(f_{\eta} = \frac{1}{8}\)はかなり積極的で、タイルが望ましい品質まで改善されていない場合、小さなアーティファクトを引き起こす可能性があります。一般に、\(f_{\eta}=\frac{1}{4}\)が実際のところ良い妥協点です。
図4は、LiSPSMを使用したにもかかわらず、前景の木に典型的なアンダーサンプリングアーティファクトが発生していることを示しています。QVSM(右図)は、19個のシャドウマップタイル(\(17 \times 2048^2\)および\(2 \times 4096^2\);後者は最適化ジャンプによる)を使用して、シーンをサブピクセル精度でシャドウし、有効シャドウマップ解像度\(65536^2\)を実現しました。図6は、セルフシャドウイングにより、右側に強い投影エイリアシングが発生していることを示しています。左のQVSMは、投影エイリアシングをほぼ完全に除去しています。結果として得られる影の精度が高いため、三角形の性質が示され、基本的なジオメトリの性質が明らかになることに注意してください – シーンの地形が木よりもはるかに粗いことが分かります。


アルゴリズムによって生成されるシャドウマップタイルの数は、\(\xi_{max}\)、\(\eta_{min}\)、\(s_{max}\)の選択とフレームバッファのサイズに依存します。シャドウマップタイルの4分割の場合、アルゴリズムによって生成されるシャドウマップタイルの数は\(1 + 4 \cdot k + l_{jump-opt}\)、すなわち\(\{1,5,9,13,17\} + l_{jump-opt}\)です。ここで,\(l_{jump-opt}\)はジャンプ最適化によって生成されるタイルの数です。実際には、我々のテストシーンとフレームバッファのサイズでは、典型的なケースは\(k=4\)、\(l_{jump-opt}=2\)であり、19個のシャドウマップタイルになることがわかりました。シャドウマップタイルが6枚であることは、実際には下限であることに注意してください。なぜなら、必要な最初の改善ステップである1から4までのシャドウマップタイルは、すでに全体として5枚のシャドウマップタイルの生成につながるからです;これがジャンプ最適化改良に続くと、5+1=6個のシャドウマップタイルになります(シャドウマップタイルが少ないということは、\(2 \times 2\)のシャドウマップタイルに総当たり改良する方が良い選択ということになります)。実際には、最初の改良ステップの後に、少なくとも1回のさらなる改良ステップとジャンプ最適化改良が行われ、全体として(\(k=2\), \(l_{jump-opt}=1\))10 枚のシャドウマップタイルが作成されます。
図8は、異なるシャドウマッピングアプローチと最大改良レベル\(\xi_{max}\)の比較を示しています。LiSPSMに代表されるサンプル再分配法では、このビュー方向に対して有効なシャドウマップの解像度を十分に高めることができないことがわかります。

改善パラメータ\(s_{max}\)については、256MBのRAMを搭載したNVidia GeForce 6600 GTでは、\(1024 \times 1024\)のシャドウマップテクスチャと\(s_{max}=2048\)の組み合わせが効率的であることがわかり、一方、512MBのRAMを搭載したATI Readeon 1900XTXでは、\(2048 \times 2048\)と\(s_{max}=4096\)の組み合わせが良い選択であることがわかりました(どちらのグラフィックカードも、\(4096 \times 4096\)の最大テクスチャ解像度をサポートしています)。
図5は、マルチパスとディファードバーチャルタイルドシャドウマッピングの性能比較です。高い変換ロードを持つシーンでは、ディファードシャドウイングは期待通りのほぼ一定のフレーム時間を与えることがわかります。
実際に起こりうる問題としては、精度の問題から、出来上がったシャドウにシャドウマップタイルの境界が見えてしまうことでしょう。我々の実装ではそのような問題は見られませんでしたが、万が一このような問題が発生した場合、シャドウマップタイルの重なりをわずかな量にするだけで、非常に簡単に修正できるはずです。シャドウマップタイルを重ねることは、シャドウイング結果を既存のシャドウ結果のテクスチャ値と組み合わせる必要がなく、以前の結果を上書きするため、アーティファクトを引き起こしません。さらに、より高度に改善されたシャドウマップは、より改善されたものよりも後に生成されるため、小さなオーバーラップ領域における品質の潜在的な低下もありません。
シャドウマッピングとそのアーティファクト(またはその有無)は、動きの中で観察するのがベストなので、http://www.cg.tuwien.ac.at/research/vr/vsm で,いくつかのデモビデオをご参照ください。
この論文の非科学的バージョンは、ShaderX book series の ShaderX 5([Giegl and Wimmer 2007]) に記事として掲載されています;実行ファイルとソースコードのサンプルは、この本に付属するCD-ROMにあります。
7.1 Extension and Optimizations
以下に、アルゴリズムに適用可能な更なる最適化とその結果を示します:
- 各シャドウタイルを常に\(2 \times 2\)のサブタイルに分割する代わりに(4分割)、各シャドウマップ軸に沿って交互に分割することもできます(2分割)。理論的には、これにより、必要とされるシャドウマップ解像度が2つのシャドウマップ軸間で異なるシナリオに対して、アルゴリズムをより適応させることができます。我々はこの拡張を実装し、一般的に4分割の場合よりもフレーム時間が長くなることを確認しました。作成されたシャドウマップタイルを分析すると、問題は2つあることがわかます: まず、多くの場合、各シャドウマップ軸に沿って必要なシャドウマップ分解能に十分な差がありません。これは、最終的にバイナリ分割は4分割を行いますが、4分割をすぐに行えば\(2 \times 2=4\)で済むところを、\(2+2 \times 2=6\)タイル世代(最初にタイルをそれぞれ2つのサブタイルに分割)のコストがかかることを意味します。第二に、バイナリ分割は、各リファインメントステップにおいて、1つのシャドウマップ軸に沿ったリファインメントステータスに関する情報しか与えません。そのため、これが必要ない場合でも、多くの場合、アルゴリズムは、タイルの解像度が両方のシャドウマップ軸に沿って適切であることを確認するために、「もう1つの分割」を行う必要があります。さらに、バイナリ分割はジャンプ最適化と効率的に組み合わせることが難しく、これも各改善ステップで利用可能なのは単一のシャドウマップ軸に関する情報のみであるという事実のためです。バイナリ分割のコストは、実用的なアプリケーションではその利点を上回ると結論づけました。
- もう1つのアイデアは、\(2 \times 2\)に分割するのではなく、\(n_{sub} \times n_{sub} (n_{sub} =3, 4, \cdots)\)のサブタイルに分割して、何段階かのリファインメントを行うことです。我々はこれをアルゴリズムに組み込みましたが、やはり、これはすべてのテストシーンでフレーム時間を悪化させることになりました。これは、たとえ1つのタイルが2回改善されたとしても、生成されるシャドウマップタイルの数が非常に大きくなるためです(これは、単にeye-point付近の透視エイリアシングのため、典型的なケースです): \(3 \times 3\)分割の場合でも、\(n_{sub}=2\)の場合は9タイル(\(1+2 \times4\))であるのに対し、\(1+2 \times (3 \times 3)=19\)タイル(初期タイル、サブタイル、サブサブタイル)となります。
- シャドウマップタイルをさらに改良するかどうかを決めるには、絶対値\(\eta_{abs} \lt n_{pixels-changed-in-tile}\)の代わりに相対メトリック\{\eta_{rel} \lt \frac{n_{pixels-changed-in-tile}}{n_{pixels-in-tile}} \)を使う方がよい選択かもしれません。ここでの問題はn_{pixel-in-tile}を得ることです:
- 1つの可能な方法は、シャドウマップタイルをEye-Space Depth Bufferに再適用し(もちろん、シャドウマップルックアップなし)、再びOcclusionQueryでブラケットを付けますが、現在のタイル内にある場合は常にピクセルシェーダーでフラグメントを出力します。OcclusionQueryの結果は\(n_{pixels-in-tile}\)になります。我々はこれを試しましたが、残念ながらこの操作の実用的なコストは非常に高く、潜在的な利点を上回っていました。\(\eta_{ref}\)を取得するさらに良い方法については、下記の “ハードウェア拡張 “を参照してください。
- ディファード・シャドウイングのもう1つのアプローチは、各ポイントのxyz座標をfloatレンダー・ターゲット(RT)に書き込み、マルチプルRT(MRT)機能を使って色を2番目のRTに書き込むことです: なぜなら、最近のグラフィックカードでさえ、同じビット深度のMRTしかサポートしていないことが多いからです。1.で与えられた変換は、ただ1つの4x float RTのアルファチャンネルに便利に格納することができる1つの線形深度エントリを使用して同じ結果を達成するので、遅延シャドウイングを実装するためにこのアプローチを選択しました。
より正確ではないですが、より高速な方法は、シーンの地面へのシャドウマップタイルの投影(スクリーン空間座標に切り取られた台形)におけるスクリーン空間のピクセル数を計算し、これを\(n_{pixels-in-tile}\)の近似値として使用することです。もちろん、この近似がうまくいくかどうかはシーンの特性に依存します。
8 Hardware Extension
ハードウェア・オクルージョン・クエリー・メカニズムを、GPUからCPUへ効率的に情報を戻すためのカウンターとして使用します。このメカニズムは小さな抜け穴のようなもので、1つのレンダリングパスにつき1つの値しか渡すことができず、カウンタを増やすことはピクセルシェーダからカラー値を出すことに連動しています(幸いなことに、私たちの場合、とにかくこれがやりたいことなのです)。このGPU機能を拡張して、オクルージョン・クエリ・フラグメント・カウンタのような、インクリメント/デクリメントが可能で(任意の量だけ可能)、アトミックな最小/最大演算をサポートするレジスタをいくつか含めれば、さらに多くのスマートで適応的なアルゴリズムを高速GPUレンダリングと組み合わせることができると確信しています。これらの演算は実行順序に依存しないため(デクリメント/サブトラクションの場合のオーバーフローを除く)、最新のGPUの高度に並列なベクトル・プロセッサ設計と互換性があります。カウンタレジスタを1つ追加するだけで、例えば、現在のシャドウマップタイルに対応するピクセルの総数に加え、最後の精密化ステップで変更されたピクセルの数をカウントすることができ、異なる改良化メトリックを採用することができます。min/maxをサポートする4つの追加レジスタにより、シャドウマップタイルの影響を受ける領域のスクリーン空間境界ボックスを見つけることができ、シャドウマップタイルをシーンに適用する際に触れる必要のあるピクセルの数を減らすことができます。
9 Conclusion
我々は、バーチャルタイルドシャドウマップを導入することで、それぞれのメモリコストを発生させることなく、最大テクスチャサイズの制限を回避して、シャドウマップの有効解像度を向上させる新しいアプローチを提示した。このブルートフォースアプローチから始めて、GPUのオクルージョンクエリメカニズムを採用して、シャドウマップタイル改良ステップの効果に関する情報をCPUにフィードバックすることで、1桁高速化できることを示しました。この情報は、CPUがリファインメントプロセスをガイドするために使用することができます。リファインメントメトリックは、シャドウマップタイルのリファインメントによってシーン内で変化したピクセル数に直接相関しており、このアルゴリズムによってパースペクティブエイリアシングやプロジェクションエイリアシングを低減、あるいは除去することができます。
また、既存のハードウェア・アーキテクチャとうまく統合できるようなハードウェア拡張も提案しており、これを利用することでアルゴリズムの効率をさらに向上させ、GPUのパワーとCPUの汎用性を組み合わせた他のスマートなアルゴリズムを可能にすることができる。
Acknowledgements
本研究は、EUのGame-Tools Project () (IST-2-00363)の支援を受けて実施された。 Tools Project (www.gametools.org) (IST-2-004363) の支援を受けています。
References
