こんにちわ、Pocolです。
今日は,
[Burns 2013] Christopher A. Burns, Warren A. Hunt, “The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading”, Journal of Compute Graphics Techniques, Vol.2, No.2, 2013
を読んでみることにします。
いつもながら,誤字・誤訳があるかと思いますので,ご指摘していただける場合は正しい翻訳例と共に指摘していただけるとありがたいです。
Abstract
フォワードレンダリングパイプラインは、三角形のサブミッション順にフラグメントをシェーディングします。その結果、目に見えないフラグメントが無駄にシェーディングされ、その後に覆い隠されてしまうことがよくあります。オーバーシェーディングを回避する一般的な方法は、フォワードパス中に各フラグメントのサーフェスアトリビュートのみを計算し、バッファに保存することです。ライティングは次のパスで実行され、アトリビュートバッファを消費します。この手法は一般的にディファードシェーディングとして知られています。
私たちは2つの顕著な欠陥を確認しています。第一に、ジオメトリサーフェイスアトリビュートのためのバッファ(G-バッファ)が大きく、可視化サンプルあたり20バイトを超えることがよくあります。大容量のGバッファの読み書きに必要な帯域幅は、モバイルGPUや統合GPUでは法外なものになることがあります。第二に、シェーディング作業と可視性の分離が不完全です。サーフェスアトリビュートは、オクルージョンされたフラグメントのフォワードパスでしきりに計算され、テクスチャの帯域幅と計算リソースを無駄にします。
これらの問題に対処するために、我々は Gバッファを、サンプルごとにトライアングルインデックスとインスタンス ID を格納するだけのシンプルな可視性バッファに置き換えることを提案します。これにより、ストレージと帯域幅の要件が大幅に削減されます。可視性バッファを生成することは、Gバッファを生成するよりも安価であり、テクスチャの読み込みやサーフェスマテリアル固有の計算を必要としません。ディファードシェーディングパスは、このインデックスを持つ三角形データにアクセスして、重心座標と補間された頂点データを計算します。可視化ソリューションのメモリフットプリントを最小化することで、ディファードレンダリングパイプラインの作業セットを削減します。これにより、特に高解像度のワークロードのために、帯域幅が限られたGPUプラットフォームでのパフォーマンスが向上します。
1. Introduction
ディファードシェーディング技術は、ライティングの作業負荷を可視フラグメントに制限するので魅力的です。shade-as-you-go ハードウェアでは、これは多くの場合、サーフェスアトリビュートのみを計算してバッファに保存するパスで可視性を解決することで達成されます。これらのサーフェイスフラグメントをライティングするためには、2回目のディファードパスが必要です。この手法は、ライティングをサーフェイスの可視性とシェーディングからきれいに分離することができ、また、閉塞したフラグメントをライティングする無駄な労力を避けることができるため、人気があります。その有効性にもかかわらず、この基本的なアプローチにはいくつかの基本的な問題があります。
サーフェイスアトリビュートバッファ(Gバッファ)のサイズは、最適化された高品質のリアルタイムシステムでは、可視性サンプルあたり16~32バイトが一般的です。このバッファを書き込み、ライトパスごとに読み出す際に消費される DRAM バンド幅は、たとえ 1 回のライトパスであっても非常に大きなものとなります。例えば、4 メガピクセルのディスプレイを搭載したスクリーンで、ピクセルあたり 4 つの 24 バイトのサンプルを 60 Hz で使用する場合、非圧縮のGバッファの書き込みとその後の読み出しのためだけに、1 回のライトパスのみを想定した場合、46 GB/s の帯域幅を消費します。このように、実際には、経済的なハードウェアで高いフレームレートを維持するために、アンチエイリアシングまたはピクセル解像度(またはその両方)が犠牲になることがよくあります。低い可視性のサンプリングレートは、部分的に透明なサーフェス、エッジアンチエイリアシング、高次元ラスタライズを効率的にレンダリングするための単純なソリューションを混乱させるので、これはおそらくこの技術の最も深刻な問題です。
第2の問題は、可視性と陰影の不完全な分離です。Gバッファソリューションでは、可視性パスはGバッファを生成するのに十分なシェーディングを実行しなければなりません。したがって、すべてのシェーディング作業が遅延されるわけではなく、テクスチャサンプリングを含むその作業の一部は、隠れたサーフェス上で無駄に実行されます。さらに、ジオメトリはサーフェスマテリアルごとにバッチ処理されなければならず、可視化ワークロードをより効率的にスケジューリングする機会が失われてしまいます。最後に、非常に大きな DRAM バッファを介してシェーディング作業を 2 つのフェーズに分割することで、すべてのマテリアルサーフェイスアトリビュートは同じメモリフットプリントを慎重に構築しなければなりません。これはプログラマビリティを制約し、シェーダオーサリングプロセスに負担をかける可能性があります。
3番目によく知られている問題は、部分的に透明なジオメトリの正しいレンダリングに関するものです。G-bufferソリューションでは、可視性サンプルごとに1つの可視サーフェスを明示的に想定しています。実際には、透過ジオメトリは後のフォワードパスでレンダリングされ、フレームバッファに合成されます。
要約すると、G-bufferディファードシェーディングは、スケーラブルな方法でピクセル単位のシェーディングから可視性をきれいに分離することができません。可視性パスに書き込まれた可視性サンプルあたりのデータは、マテリアル プロパティを抽象化していません。データが大きすぎて、エイリアシングなどの長年の問題に対する高度なソリューションを実装する必要があるため、スケールでのマルチサンプリングを可能にしています。部分的に透明なジオメトリは、後続のフォワードレンダリングパスで個別にレンダリングする必要があります。
透明性以外の問題にも我々は対応しています。我々のパイプラインはGバッファを単純な可視性バッファに置き換えます。このバッファには、サンプルごとにトライアングルインデックスとインスタンスIDのみが格納されます。大規模なシーンやテッセレーションされたシーンの場合は 8 バイトで十分ですが、それ以外はサンプルあたり 4 バイトしか必要ありません。フルスクリーン一次可視化ソリューションを可能な限り小さなフットプリントで実現することで、マルチサンプルまたは高解像度フレームバッファ上での遅延シェーディングの帯域幅コストを大幅に削減しています。すべてのシェーディングは、可視頂点がロードされ、変換され、シェーディングされ、交差され、スクリーン空間に補間され、照明されるディファードパスで行われます。我々の結果は、大きなキャッシュを特徴とするGPUプラットフォーム上で大きなスピードアップを示しています。
1.1. Related Work
ほとんどのGPUハードウェアは、OpenGLやDirectXのような一般的なグラフィックスAPIによって指示されるロジックを持つ、sort-last、フォワードシェーディングレンダリングパイプラインを実装しています。フラグメントは、初期の Z/ステンシル テストに合格した場合、ラスタライザを抜けるときにシェーディングされます。したがって、可視性が最終的に解決されるまでシェーディングを遅延するスキームは、複数のレンダリングパスを使用してユーザー空間に実装する必要があります。
最も単純な解決策の1つは、z-prepassとして知られています。すべてのシーンジオメトリは、最初にnullピクセルシェーダでラスタライズされ、最も近いサーフェス深度でzバッファをプライムします。実際のシェーダを使用した 2 回目の標準パスが実行され、z-test が等しくなるように設定されます。このアプローチの最新のバリアントは Forward+[Harada 2012]で、z-onlyパスからのデプスバッファを使用してタイル粒度のライトカリングを実行し、効率的なフォワードシェーディングパスを実現しています。よりシンプルなシーンには効果的ですが、幾何学的な複雑さに合わせてスケールが悪く、可視化されている可能性のあるすべてのジオメトリの再出力が必要となります。多くのハイエンドのプロダクションレンダリングシステムでは、再出力のコストは法外なものです[Andersson 2011]。そのため、可視性の計算を一度だけ実行するアプローチを模索しています。
ライトプリパスレンダリング(ディファードライティングと呼ばれることもある)は、放射照度計算とサーフェイスシェーディングを分離する方法でz-pre-passアプローチを修正しています[Engle 2008]。z のみのパスは、z に加えてシェーディング法線とスペキュラローブ値を出すように拡張されています。最後に,ジオメトリを再出力して,完全に評価されたサーフェスアトリビュートと放射照度を統合します。このアプローチでは、ライティングとサーフェスシェーディングをうまく分離していますが、ジオメトリのパスは2回必要です。
2回目の可視化パスの回避は、放射照度の計算に必要なものだけではなく、シェーディングに必要なすべてのサーフェスアトリビュートを書き込むように1回目のパスをさらに拡張することで達成されます。前述したように、このバッファは大きく、ほとんどのハードウェアでは解像度および/またはサンプルレートが制限されます。
Liktor と Dachsbacherは、モーションブラーと被写界深度を同時にサポートしながら、このバッファを圧縮するスキームを提示しています[Liktor and Dachsbacher 2012]。彼らの圧縮されたジオメトリバッファは、可視性のサンプリングレートよりもまばらに配置されたシェーディングサンプルのサーフェイスアトリビュートのみを格納しています。可視性サンプルは、これらのシェーディングサンプルへの参照を格納します。彼らのアプローチは、シェーディングレートが可視化レートよりも小さい場合には、完全にスーパーサンプリングされたGバッファと比較して保存コストを削減し、可視化サンプルとシェーディングサンプル間の任意の多対一マッピングを可能にします。彼らのアプローチは、ぼやけたジオメトリを解決するために確率的サンプリングを使用するアプリケーションでは有望ですが、従来のラスタライズパイプラインに対するメリットはあまりありません。また、GPUラスタライズパイプラインで効率的に実行するためには、追加のハードウェア(ピクセルシェーダからアクセス可能なオンチップキャッシュなど)が必要になるようです。
中間レンダリングターゲットのフットプリントを制限するもう一つの方法は、フレームバッファをオンチップキャッシュに収まるように小さいタイルに分割することです。この方法は、Intel の Larrabee [Seiler et al. 2008] グラフィックドライバで使用されています。しかし、アプリケーションレイヤでタイル化されたアプローチを使用することは問題があります。タイル化がない場合でも、ドローコールは最近のリアルタイムレンダリングシステムではボトルネックになることがよく指摘されています。
Imagination Technologies社のPowerVR製品群[Imagination Technologies Ltd. 2011]のような低消費電力GPUは、ドライバ層とハードウェア層で当社と同様の戦略を追求していることが知られています。これらのGPUは、アトリビュートを補間したりピクセルシェーダを実行したりする前にタイルの可視性を解決するタイルドレンダラーを実装しています。ラスタライズされた三角形への参照は、当社のフルスクリーン可視性バッファと同様に、タイルサイズのハードウェアタグバッファに格納されます。この技術は、DirectX 11 クラスの GPU をターゲットにした、この戦略のフルスクリーン・アプリケーション・レイヤー実装として見ることができます。私たちの知る限りでは、このような実装の解析は初めて公開されたものです。
2. The Visibility Buffer
従来のG-バッファソリューションと比較した我々のソリューションを図2に示します。すべてのジオメトリは可視性バッファにレンダリングされ、可視性サンプルごとに、トライアングル ID とインスタンス ID をエンコードする 4 バイトの整数が格納されます。このコンパクトなエンコーディングでは大きすぎるシーン(またはセクション 5.1 で説明したテッセレーションされたジオメトリ)では、サンプルごとに 8 バイトを使用することができます。
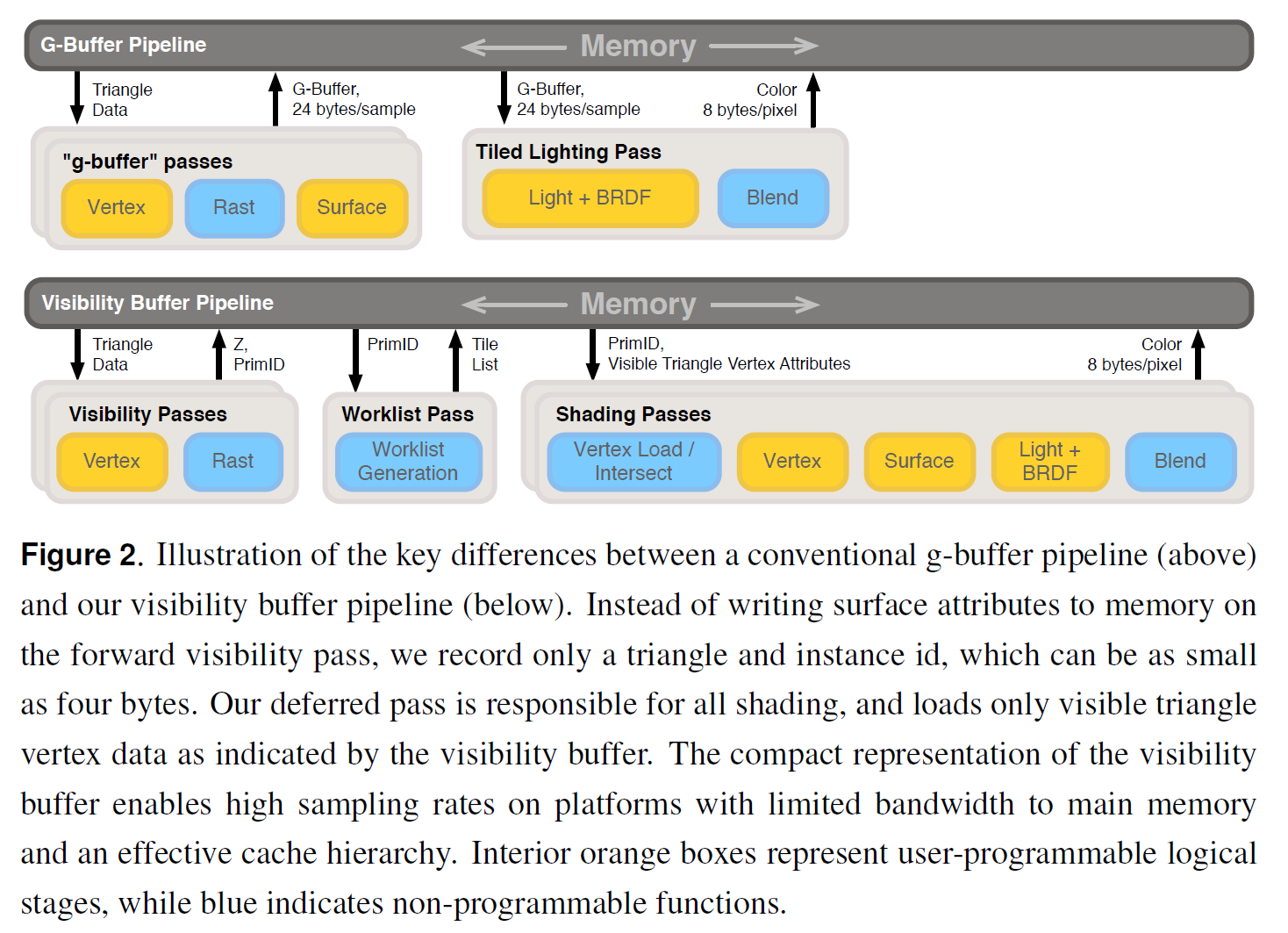
最後に、シェーディングカーネルは、シーン内の各ユニークなマテリアルに対してディスパッチされ、そのマテリアルの可視ジオメトリのサンプルが少なくとも1つ含まれていることが知られているタイルのリストの範囲内で実行されます。このカーネルは、頂点補間からライティングまでのすべてのシェーディングを実行し、ピクセルごとに単色を出力します。このカーネルの擬似コードを図3 に示します。

このアプローチの主な動機は、可視化パスの結果を格納するバッファのメモリフットプリント、つまり必要な帯域幅を削減することです。8倍サンプリングの1080pフレームの場合、我々のバッファは64MBであるのに対し、1サンプルあたり24バイトのG-バッファでは398MBとなります。これは、シェーディング中に可視化された三角形の三角形と頂点のデータをロードするというコストを犠牲にしています。しかし、この追加データは、マルチサンプリングされたG-バッファに比べればまだ小さいです(三角形ごとにほぼ1つのユニークな頂点と32バイトの頂点を仮定すると、200万のマイクロポリゴンの頂点とインデックスデータは約88MBを埋めることになります)。さらに重要なことは、これらのメモリアクセスはスクリーン空間内で非常にコヒーレントであり、キャッシュが総作業セットよりも著しく小さい場合でも、高いキャッシュヒット率が得られる可能性があるということです。
いくつかの量を計算し直すことで、ストレージの節約分を支払っています。これらのオーバーヘッドには、重心座標の生成、頂点アトリビュートの補間、テクスチャ座標の微分計算、ピクセル頻度での頂点シェーダの再計算が含まれます。非常に高帯域幅のディスクリート GPU プラットフォームを除けば、特に電力に敏感なマイクロアーキテクチャーでは、メインストリームのグラフィックスワークロードにとって帯域幅が制約となるリソースです。長期的な傾向としては、コンピュートバンド幅の比率が継続的に増加していることを示しています。したがって、これは賢明なトレードオフであると考えられます。最後に、どのシーンでも、シェーダに算術命令を追加してもフレームレートに影響を受けないことに注意してください。
最後に発生するオーバーヘッドの一つは、各サーフェイスマテリアルのタイルワークリストを作成する必要があることです。G-バッファシステムでは、ラスタライズパスはサーフェイスアトリビュートを評価するピクセルシェーダプログラムに結合されます。これは、それぞれの異なるサーフェスに対して、最低でも1回の描画コールが発行されることを意味します。対照的に、ライティングステージのコードは、一般的にサーフェスに関して不変であり、1回のディスパッチでフレーム全体に適用することができます。このシステムでは、すべてのサーフェスシェーディングを第2フェーズに移動するので、状況は逆になります。固有のマテリアルごとにシェーダをディスパッチしなければならず、フレームの関連部分だけに適用したいので、各シェーダ用のタイルのリストを構築するための簡素なステージが必要になります。このステージは非常に迅速で、どのシーンでもフレーム時間の10%以下を占めることはありません。
3. Implementation
DirectX 11 のピクセルとコンピュートシェーダを適宜使用して、可視性バッファパイプラインと並行してリファレンス G-バッファディファードパイプラインを実装しました。図2は、論理的なレンダリングタスク(オレンジと青のボックス)を両方のパイプラインのパスにマッピングする方法を示しています。
分析のためにライトカリングは実施していません。深度バッファがあれば、タイルドライトカリングはかなりよく理解されており、ここで議論されている問題に意味のある影響を与えません。どちらのレンダラーも、カリングが実行されたかのように、タイル単位のライトリストからシェードするだけです。また、ディファードシェーディング システムで問題となることが知られている部分的に透明なサーフェスの問題にも対処していません。我々のパイプラインは、G-バッファパイプラインで部分的に透明なジオメトリをレンダリングするための従来のソリューションと互換性があることを主張します。
3.1. Reference G-Buffer Pipeline
私たちのリファレンスG-バッファパイプラインは、リスト1で説明されている24バイトのG-バッファフォーマットを使用します。法線はスフィアマップエンコーディングを使って圧縮されます。また、アンチエイリアシングスキームをサポートするために、可視性バッファパイプラインとまったく同じように、三角形のインスタンスIDのための4バイトを格納します(セクション3.3参照)。ライティングは、タイルごとのライトリストで \(16 \times 8\) ピクセルタイルを照らす単一の計算シェーダカーネルで実行されます。我々が選択したサイズは、グループ共有メモリ(アンチエイリアシングのために使用します)の利用可能性によって、ハイエンドでは制限されます。64ピクセルより小さいタイルサイズは、小規模なワークグループでは最新のGPUのサブスクライブが不足する傾向があるため、パフォーマンスが低下しています。

3.2. The Visibility Buffer Pipeline
我々のパイプラインは、図2に示すように、3つのフェーズで実装されています。最初のフェーズでは、可視性、深度の記録、プリミティブ ID をマルチサンプルバッファに分解します。他のデータは書き込まれず、計算もされません。
2 番目のフェーズでは、フェーズ 3 を駆動するためにタイルワークリストを構築しますが、これは 2 つの小さな部分に分かれています。最初の部分では、可視性バッファを読み込んでレコードのリストを構築し、それぞれがタイルシェーダペア(8バイト)で構成されています。2 番目の部分では、これらのレコードをシェーダごとにソートし、タイル ID のみをパックされたリストに記録します。オフセットの配列は、各シェーダがタイルリストのどこから始まるかを示します。このフェーズは、セクション4で説明するように比較的安価です。
3 番目の最後のフェーズは、シーン内の各サーフェイスシェーダのためのコンピュートカーネルディスパッチで構成されています。これらのカーネルは可視性バッファを消費し、頂点収集、頂点シェーダ、アトリビュート補間、サーフェスシェーディング、イルミネーション、マルチサンプルブレンディング、そしてカラーバッファへの最終書き込みを担当します。このカーネルの擬似コードを図3に示します。セクション2で説明したように、頂点ギャザリング、交差、補間、シェーディングは、コンパクトな可視性バッファのために支払う計算量です。スレッドが与えられたシェーディングサンプルの補間された頂点を計算すると(図 3 の 25 行目)、カーネルはリファレンス G-バッファパイプラインのライティングフェーズとほぼ同じように進行します。また、同じ \(16 \times 8\) のタイルサイズを使用しています。
3.3. Anti-Aliasing
アンチエイリアシングは、あらゆるディファードシェーディングスキームでGPUハードウェアを効率的にサポートするための挑戦的な機能です。ハードウェアMSAAはラスタライザを通過するフォワードパスでのみ利用可能であり、ディファードパスやコンピュートモードで駆動されるパスは独自に動かすことを余儀なくされます。MLAA [Reshetov 2009]から始まった一連の研究により、費用対効果は高いですが品質が低い一連の技術が生み出されてきました。これらは主にマルチサンプリングの費用を回避するために使用されていますが、これは我々が直接対処しています。効率的で視認性の高いサンプリングレートが我々のアプローチの重要な利点であるため、我々の手法を正直に評価するには、スーパーサンプリングよりも「スマートな」何かを行う必要があります。すべての可視性サンプルをシェーディングすると、シェーディングコストを総フレーム時間の一部として過剰に表現してしまい、パフォーマンス結果が歪んでしまいます。
ほとんどのマルチサンプルディファードアンチエイリアシングアルゴリズムは、次のような形式をとります。
1. 便利なサーフェイスアトリビュート(Z、法線など)のスーパーサンプリングバッファを生成します。
2. 遮光が必要なサンプルを決定するためにいくつかの処理をします。
3. シェーディング処理をスケジュールします
我々のアンチエイリアシングのアプローチは、最初のパスで生成された可視性バッファを使用して、ピクセル内のどのサンプルがシェーディングを必要とするかを判断します。ピクセル内のサンプルを繰り返し処理し、各ユニークな可視性サンプルに対して1つのシェーディングサンプルレコード(グループの共有メモリに格納されている)を作成します。これらのサンプルは、ピクセル内での出現回数に比例して重み付けされます。各シェーディングレコードには、スレッドグループ内のスレッドが割り当てられ、シェーディングされ、シェーディングレコードに記録された色が記録されます。最後に、色がブレンドされ、各ピクセルに対して1つの色が書き込まれます。レコードをパッキングしてスレッドに再分配することで、SIMDの効率が保たれます。
我々のアプローチは、高度にエキゾチックだったり斬新なものではなく、どちらのパイプラインでも同じように実装できる合理的な設計の選択を表しています。これにより、1ピクセル、1トライアングルあたり1つのシェーディングサンプルが得られます。我々は,ステンシルバッファを使用して,スーパーサンプリングが必要かどうかをピクセルにマークする,よりシンプルなアプローチで実験を行いました[Lauritzen 2010]が,上記のアプローチは,テストしたほとんどの GPU プラットフォームで,我々のシーンでは中程度の性能を発揮することがわかりました.しかし、これらのトレードオフはワークロード特性やマイクロアーキテクチャーの問題に非常に敏感であるため、この主張を誇張してはいけません。
4. Results
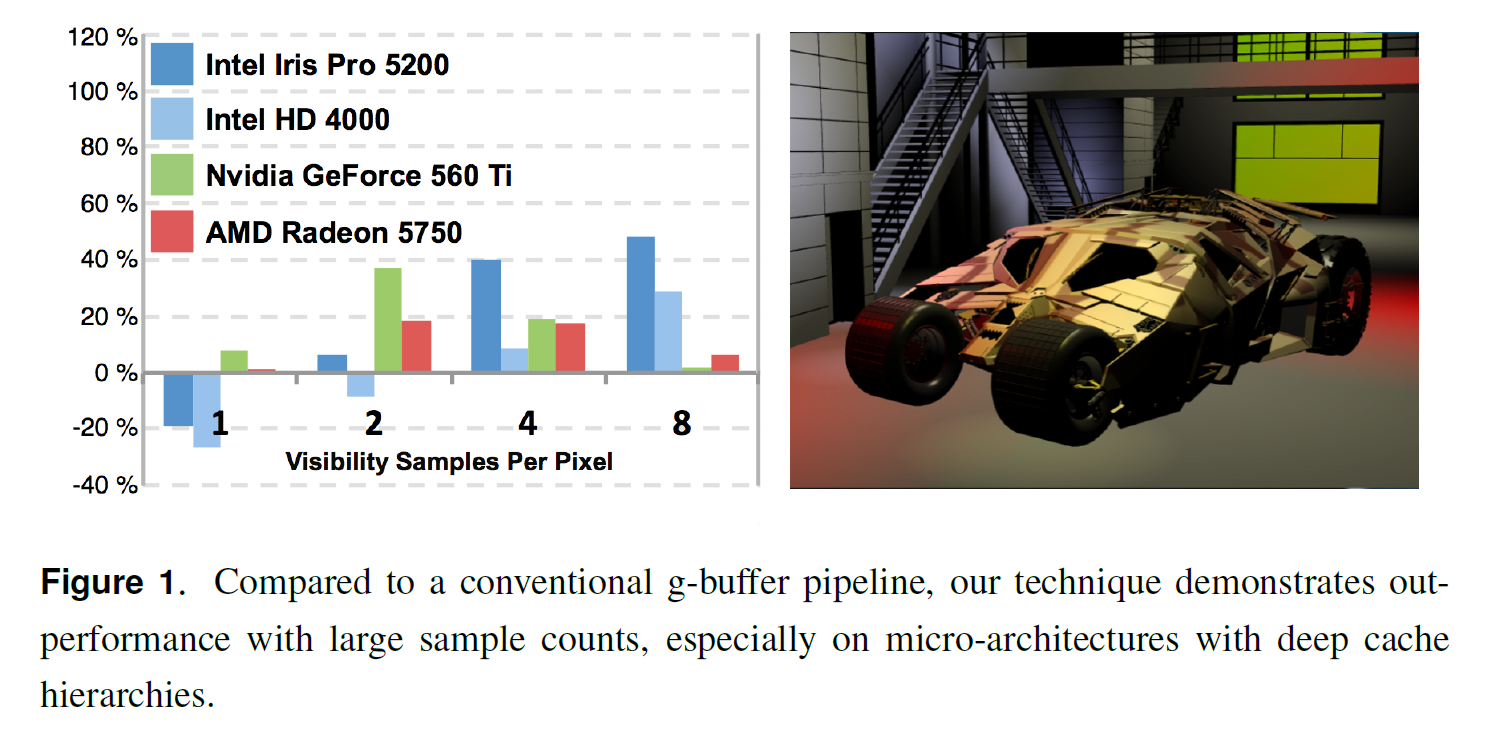
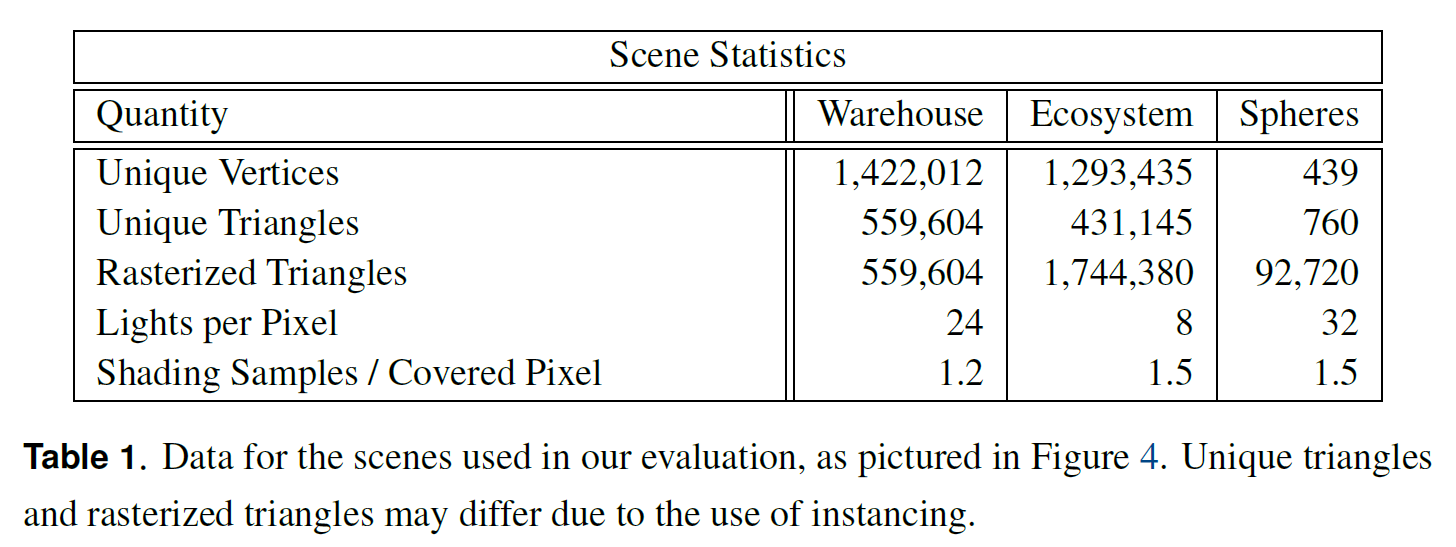
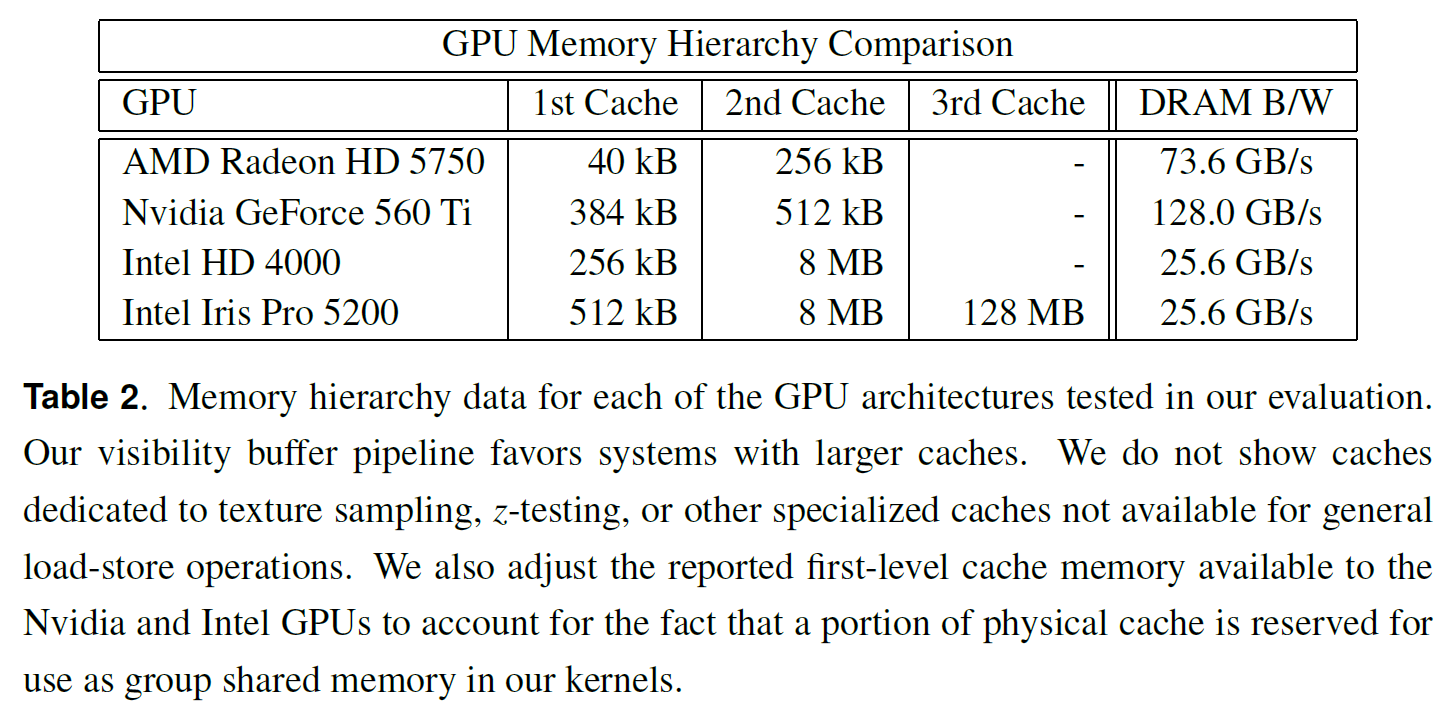
図4に示すように、ジオメトリとシェーディングの複雑さが異なる3つのシーンでパイプラインをテストしました。これらのシーンの特性を表1に示します。すべてのシーンは、表2に記載されている4つの異なるGPUプラットフォーム上で1080pの解像度でレンダリングされました。これらのプラットフォームは、顕著に異なるメモリサブシステムを示しています。ディスクリートGPUは、高いDRAM帯域幅と適度な量の汎用キャッシュのみを特徴とする傾向があります。対照的に、統合されたIntel GPU部品は、CPUのようなメモリ階層を採用している。特に、Intel Iris Pro 5200 “Haswell “統合GPUは、高帯域幅128MBキャッシュとして機能するオフダイ組み込みDRAMの追加レベルを特徴としています。

私たちの結果を図5に示します。予想通り、我々のパイプラインでは、わずか200万個の可視性サンプルでは、正味の利益はほとんど得られませんでした。パフォーマンスの優位性は、特に帯域幅に制約のあるインテル・プラットフォームにおいて、より高いサンプル・レートで得られます。
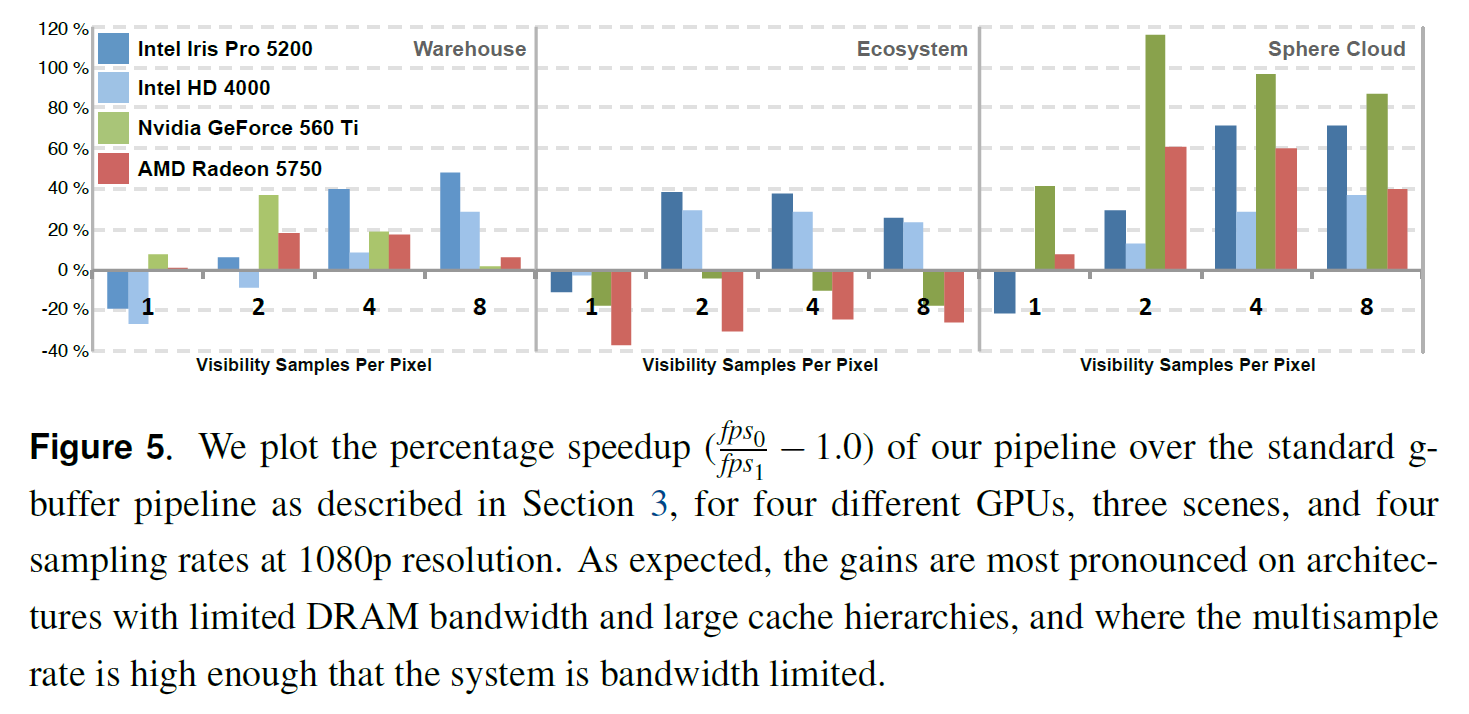
倉庫のシーンでは、三角形のサイズやマテリアルが豊富に用意されています。我々の可視性バッファ・パイプラインは、サンプルレートではG-バッファ・パイプラインよりもはるかに優れており、特にIntel Iris Proを使用している場合はそのようになります。エコシステムシーンには小さな三角形が多く、シェーディングフェーズの間に可視化されたジオメトリの空間的な位置に依存するため、我々のアプローチに挑戦しています。このシーンでは、最小のキャッシュを持つプラットフォームは我々のアプローチの恩恵を受けることはありませんが、統合された部品は依然として良好なパフォーマンスを発揮しています。
spehre-cloudシーンには、200回インスタンス化された1つの球体メッシュが含まれています。メッシュデータは、すべてのプラットフォーム上の小さなキャッシュ内にも完全に収まります。これが、このシーンでテストされたすべてのハードウェア上で、私たちのパイプラインが優れた性能を発揮する理由であることを示唆しています。非現実的ではありますが、これは幾何学的な作業セットサイズが我々のアルゴリズムに与える影響を示しています。
図 6 は、\(8 \times\) マルチサンプルの場合の各パイプラインの主要フェーズのコストを示したものである。図示されていないのは、バッファクリア、バックバッファスワップ、利用率の小さなギャップの(マイナーな)コストです。我々のパイプラインの可視化パスは、z-prepassと同様に、g-bufferパイプラインよりもはるかに安価であることに注意してください。場合によっては、我々のシェーディングは、計算オーバーヘッドにもかかわらず、g-bufferパイプラインの対応するライティングパスを上回ります。Radeon 5750は、ワークリスト(黒いセグメント)の構築においてIntelパーツよりも効率的ですが、Intelパーツのように我々のパイプラインのシェーディングパスは実行されません。これは、追加のメモリ帯域幅では、効果的なキャッシュ階層の不足を補えないためだと考えています。これら2つのGPUは、演算ピークスループットでは同等であり、メモリ階層がレンダリング性能にどのように影響するかについての合理的なケーススタディとなっています。

5. Discussion
この研究は、3つの重要な理由から重要だと考えています。第一に、レンダリングとはサンプリングのことです。サンプルレートが高いほど、レンダリングのあらゆる側面の品質が向上します。一次可視性については、より高いサンプリング密度は、幾何学的なエイリアシングだけでなく、モーションブラーや被写界深度[McGuire et al. 2010]、次数に依存しない透明度[Enderton et al. 2010]、その他の効果を実装するために使用することができます。我々の技術は、フォワードシェーディングや複数の可視性パスに頼ることなく、より高いサンプルレートを効率的に可能にします。
第二に、より高いサンプルレートを可能にすることに加えて、私たちのパイプラインは、ある重要な意味でG-バッファパイプラインよりも「遅延」されています。Gバッファパイプラインでは、シェーディング属性は最初のパスで計算されます。これがライティングに比べて安価であるとしても、ジオメトリが可視化パスの間にサーフェスマテリアルでソートされ、シェーダ/テクスチャ/定数がバッチ間でスワップアウトされる必要があります。この順序が可視性パスに最適であるとは考えにくいですが、可視性アルゴリズムの革新の機会を提供します。例えば、カリングへのよりスマートなアプローチが可能になるかもしれません。
第三に、電力効率は当面の間、最も重要な関心事であり、メモリとのデータのやり取りは最も電力を消費する操作の一つです。メモリトラフィックを削減するために追加の計算を実行するアルゴリズムは、ほとんどの場合、この指標によって優位に立つことができ、遠くのリソースへの帯域幅を厳密に制限するマシンでは優れたパフォーマンスを発揮します。将来のアーキテクチャでは、現在よりも大幅に多くのメモリ帯域幅を持つようになるかもしれませんが、計算リソースのスケーリングが速くなる可能性が高いため、メモリ帯域幅の相対的なコストが増加し続けることになります。
5.1. Tessellation
テッセレーションされた三角形は、パイプラインの前半分で生成され、消費されます。これらは保存されていないので、我々のシステムのディファードステージではロードすることができません。このため、テッセレーションされたジオメトリのディファードステージは、非テッセレーションされたジオメトリの場合とは少し異なる動作をする必要があります。我々の実装は現在テッセレーションをサポートしていませんが、ここではどのように動作するかを考慮しています。
トライアングルIDとインスタンスIDを32ビットで記録する代わりに、パッチUV座標(それぞれ16ビットのfloat)、パッチID、インスタンスIDを8バイトで記録します。次に、ディファードパスは、各シェーディングサンプルについて、パッチ制御点をロードし、サーフェスシェーディングを進める前に、各サンプルのドメインシェーダを再計算しなければなりません。シーンによっては、これはかなりの計算オーバーヘッドを伴うかもしれませんが、2 回目のパスでは可視ジオメトリのみが処理されることを覚えておくことが重要です。テッセレーションは2回実行されず、ハルシェーディングとドメインシェーディングのみ、可視シェーディングのサンプルでのみ実行されます。可視バッファのサイズは2倍になりますが、それでもマルチサンプルのG-バッファよりはかなり小さくなります。
6. Conclusion
通常は可視化パスの間に保存されるはずのデータをディファードパスで再計算する、新しいリアルタイムレンダリングパイプラインを実装しました。これにより、キャッシュ階層をより有効に活用し、DRAMへのトラフィックを最小限に抑えるために、ディファードパス中の有効な作業セットのサイズを大幅に削減しました。また、可視化パスとシェーディングパスを完全に分離し、単純な z-prepass のようにパイプラインフロントエンドを経由して 2 回目の動作を必要としないようにしました。この結果は,DRAM の帯域幅は限られていますが,有用なキャッシュ階層を持つ GPU アーキテ クチャにおいて,我々のパイプラインの性能上の優位性を示しています。これらの技術革新が、電力が常に懸念される将来のSoCプラットフォームをターゲットとしたレンダリングシステムを設計するための最善の方法について、さらなる研究に拍車をかけることを期待しています。
Acknowledgements
和訳省略。