こんらみ,Pocolです。
今日は,
[Wyman 2021] Chris Wyman, Alexey Panteleev, “Rearchitecting Spatiotemporal Resampling for Production”, High-Performance Graphics 2021.
を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けると有難いです。

Abstract
Bitterliら[BWP*20]による最近の研究では、重み付けされたレゼバーサンプリングを用いたリサンプルドインポータンスサンプリングをインタラクティブに適用することにより、数百万個のライトから動的な照明をレンダリングするリアルタイムな多光源アルゴリズムが紹介されました。リアルタイムで新しいレベルの複雑なライティングを可能にする一方で、総コストは最も計算量の多いゲームでも予算を超えるままでした。この方法を製品化する際に開発されたアルゴリズムの主要な改良点を紹介します。この改良点は、照明コストを最大7倍削減し、メモリコヒーレンスを劇的に改善し、必要なレイバジェットを縮小し、レンダリング品質を高め、品質とパフォーマンスを交換するためのパラメータを公開します。
1. Introduction
オフラインレンダラーでは、長い間モンテカルロレイトレーシングとパストレーシングを使用して、見事な効果を上げてきました(例えば、[BAC*18, FHL*18])。ハードウェアアクセラレーションによるレイトレーシング [Har20, KMSB18] の導入により、開発者はリアルタイムのモンテカルロ積分のために任意の可視性クエリを実行できるようになりました。しかし、最近のレイトレーシング・ハードウェアのスループットは、特にローエンド・デバイスをターゲットとする場合、制限されています。そのため、開発者はレイトレーシングを、一部のユーザーのためのオプションの目の保養として組み込むことが多いです。高速かつ低サンプルの再構成における最近の進歩(例えば、[SKW*17、SPD18])と組み合わせることで、最大グラフィックス設定でレンダリングされたゲームの画質を大幅に向上させることができました。
しかし、アセットやレンダリングパイプラインを再設計しなければ、多くの利点は得られません。例えば、多光源レンダリング技術は、アーティストのワークフローを簡素化し、複数の光源ごとのシャドウアルゴリズムを置き換え、アンビエントオクルージョンパスを削除することができます。しかし、新しいアルゴリズムが低性能のハードウェアやレガシーハードウェアでも動作する場合にのみ、改善がもたらされます。十分なスケーリングがなければ、レイトレーシングの長所は短所となり、アーティストは別のアセットバリエーションを調整しなければならず、開発者は別のコードパスを維持しなければなりません。
多光源サンプリングに関する最近の研究[BWP*20]の製品化が始まりました。しかし、彼らの研究プロトタイプは、ハイエンドのプロシューマーGPUでフレームあたり10~50ミリ秒のばらつきがあり、費用対性能比は紛れもなく素晴らしいですが、最小限のコストでもゲームのバジェットを超えてしまいます。しかし、ローレベルのパフォーマンス分析から、いくつかの興味深い見解が得られました。まず、レイトレーシングを活用する一方で、reservoir-based spatiotemporal importance resampling(ReSTIR)は、レイトレーシングに費やす時間が1/3以下であることが多いです。次に、ReSTIRのレイ以外の計算量は\(O(1)\)ですが、いくつかのコンポーネントのコストは、シーンごとに20倍以上変化します。
これらの課題を解決するために、ReSTIRを全面的に再構築し、品質と性能の両方を向上させました。その結果、以下のような成果を得ることができました:
- バイアスの原因やノイズとの関係を理解する; これはバイアスやノイズを減らすための簡単なヒューリスティックの使用を可能にします
- Resampled importance sampling (RIS) [Tal05, TCE05] を適用して計算を再形成し、インコヒーレントなメモリフェッチの大部分を内部ループから抽出します
- 品質に密接に関連すパラメータを注意深く分析する; これは1ピクセルあたりの最大レイバジェットを5本から2本への削減を可能にします。
- フレーム単位のグローバルバリアを削除する; テンポラルバッファから空間的なサンプルを選択することで、フレーム内の依存性を取り除くことができます
- シェーディングとサンプルの再利用を分離する; これは、リサンプリングで棄却されるサンプルをシェーディングすることによって、与えられたコストで品質を向上させます。
- 可視性を再利用することで、品質と性能をトレードする; 分離されたシェーディングでは、1ピクセルあたり2本の光線のうち1本はシェーディングにしか影響しません。そのレイを選択的にトレースすることで、品質は低下しますが、コストは削減されます。
データ構造の圧縮、中間データの削減、計算の重複排除といった従来の最適化により、Bitterliら[BW`*20]と比較して最大で7倍のコスト削減を実現しています。最大設定の1920×1080で、ReSTIRは1.5ms以下の計算とピクセルあたり2本の光線を使用し、RTX 3090で総コスト1.9~5.1ms(シーンによって異なる)です。設定を下げることで、両方のコストはさらに減少します。
2. Paper Overview
この論文では、複数の目標を掲げています。まず、Talbotら[TCE05]とBitterliら[BWP*20]はレンダリングのためのインポータンスリサンプリングと時空間再利用の使用を動機づけていますが、今日ではどちらも広く使われていないですし教科書でも議論されていません(例えば、[DBB06、MS18、PJH16])。セクション3では、基礎となる数学を解説し、基礎的な部分を一通りカバーすることで、より根本的な直感を補うことができるようになっています。
次に、Bitterliら[BWP*20]は、サンプルをアンバイアスに再利用する方法を導き出していますが、これは非直感的なままです。セクション4では、数学を再掲し、バイアスを視覚的に描写し、バイアスがどのように現れるかを議論し、バイアスを低減し除去する技術をレビューします。これにより、より懐疑的な読者に対して時空間再利用の健全性を検証することができます。
最後に、より高い効率を実現するための改善点(図2参照)に焦点を当て、理論的および経験的に動機づけられた変更点の両方を紹介します。基礎となる理論的な議論に興味のない読者は、セクション3と4を読み飛ばすことができます。
セクション5では、内側ループから実行とデータダイバージェンスを解除するために、どのように計算を再形成するかを示します。セクション6では、レイバジェット、サンプリングパラメータ、データフローに対する経験的に動機付けられた最適化について概説します。そしてセクション7ではサンプルの寿命を追跡し、以前に棄却された処理を取り除き、品質とパフォーマンスの向上につながることを示しています。
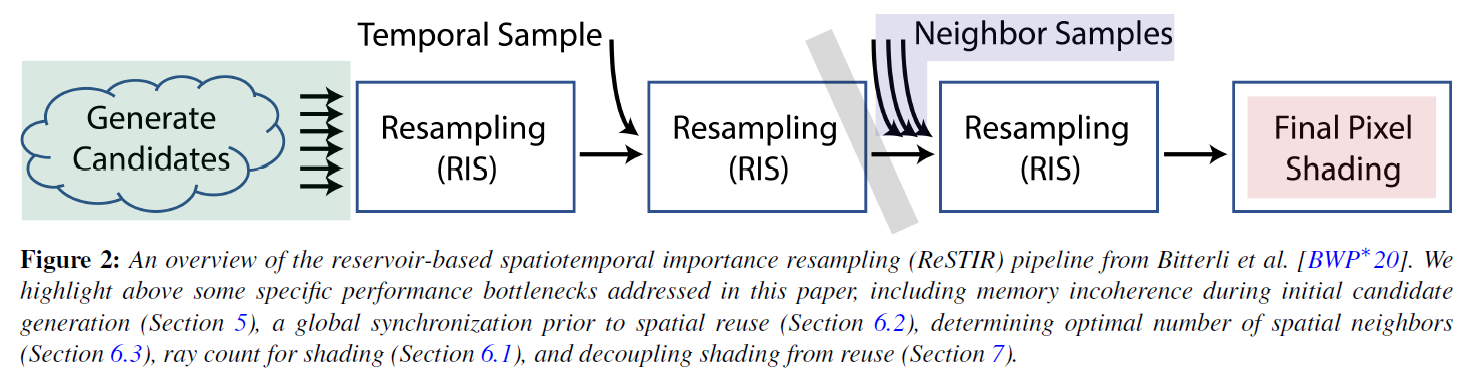
3. Background and Preliminaries
私たちの再設計されたリサンプリングを説明する前に、数学を復習し、ReSTIRがリアルタイムレンダリングにどのように役立つかを明らかにします。
リアルタイムレンダリングの基本的な課題は、ほとんどの現実的なシナリオで解析的な解を持たないレンダリング方程式[Kaj86]を効率的に近似することです:
\begin{eqnarray}
L({\mathbf x}, \omega_o) = \int_{\Omega} \rho({\mathbf x}, \omega, \omega_o) L({\mathbf x}, \omega) \langle {\vec n}_{\mathbf x} \cdot \omega \rangle d \omega \tag{1}
\end{eqnarray}
サーフェイス法線\({\vec n}_{\mathbf x}\)、BRDF \(\rho\)、入射放射輝度\(L({\mathbf x}, \omega)\)で、方向\(\omega_o\)から見た点\({\mathbf x}\)をシェーディングします。代わりに、レイトレーサーは通常、重点サンプリングされたモンテカルロ積分を用いてレンダリング方程式を近似します:
\begin{eqnarray}
F = \int_{\Omega} f(\omega) d\omega \approx \frac{1}{N} \sum_{i=1}^N \frac{f(\omega_i)}{p(\omega_i)} \tag{2}
\end{eqnarray}
つまり、1ピクセルあたり\(N\)個の方向\(\omega_i\)をサンプリングし、確率\(p(\omega_i)\)で\(\omega_i\)を選択することで式1を数値的に近似しています。
リアルタイムでは、レイの数\(N\)を最小化することが重要です。最適には、完全な重点サンプラーによって\(N\)を\(1\)に減らすことができますが、これには\(p(\omega) \propto f(\omega)\)が必要で、式2の総和でキャンセルが可能です。確率密度関数は積分して単位化しなければならないので、これは次を意味します:
\begin{eqnarray}
p(\omega) = \frac{f(\omega)}{\int f(\omega) d\omega} \tag{3}
\end{eqnarray}
しかし、\(F\)を先験的に知っている必要があります。入門書(例えば、[PJH16])では、式3を示し、完全なサンプリングは達成不可能と結論付けていることが多いです。しかし、完全な重点サンプリングは近似できるのでしょうか?近似するにはピクセルあたり\(N \gt 1\)のレイが必要かもしれませんが、一般的には\(N\)を最小にします。近似的に完全な重点サンプリングを提案するのは奇妙に思えますが、よく知られた統計手法に従えば、例えば、ほぼ正確なCDF逆変換法に関するDevroyeの [Dev86] セクションを見てください。
3.1. Resampled Importance Sampling
完全な重点サンプリングを近似するために、モンテカルロ積分を反復して適用します。正規化されていない目標関数\({\hat p}(\omega)\)に従ってサンプリングするために、正規化を近似的に行います:
\begin{eqnarray}
p(\omega) = \frac{ {\hat p}(\omega) }{ \int {\hat p}(\omega) d\omega } \approx \frac{{\hat p}(\omega)}{ \frac{1}{M} \sum_j \frac{{\hat p}(\omega_j)}{q(\omega_j)} } \tag{4}
\end{eqnarray}
ここで、\(q(\omega)\)はソースpdfです。基本的には、ソースpdf \(q\)から\(M\)個のサンプルを選択し、\(N\)個のサンプルがターゲットpdf \({\hat p}\)を最もよく近似するように導きます。式2に戻り、再整理すると次のようになります:
\begin{eqnarray}
F = \int_{\Omega} f(\omega) d\omega \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}(\omega_i)} \frac{1}{M} \sum_{j=1}^{M} \frac{{\hat p}(\omega_{ij}}{q(\omega_{ij})} \right] \equiv \langle F \rangle_{ris} \tag{5}
\end{eqnarray}
Talbotら[TCE05]によってグラフィックスに導入されたリサンプルドインポータンスサンプリング(RIS)推定量\(\langle F \rangle_{ris}\)です。RISは,\(M\)個の候補サンプルを\({\hat p}\)を用いて再評価あるいは,リサンプリングし,重み\(w_{ij} = {\hat p}(\omega_{ij}) / q(\omega_{ij})\)に比例するものをサンプル\(\omega_i\)として選択します。
3.1.1. Why Is Resampled Importance Sampling Valid?
鋭い読者なら、式4の右辺がpdfでないことにお気づきでしょう。特に、半球上で積分すると、単一性が得られない場合があります。これらは近似的でランダムな分布であることを忘れないでください。これらを理解するには、その集約的な振る舞いを信頼すること、つまり、期待値が我々の望む結果に収束することを検証することが必要です。そのために、関数\(W(\omega, z)\)を定義します:
\begin{eqnarray}
W(\omega, z) = \frac{1}{{\hat p}(\omega_z)} \left[ \frac{1}{M} \sum_{i=1}^M w_i(\omega_i) \right] \tag{6}
\end{eqnarray}
ここで、\(\omega_z\)は、明示的に、重み\(w_i = {\hat p}(\omega_i) / q(\omega_i)\)に比例して選択された\(\{\omega_1, \cdots, \omega_M \}\)からのランダムなサンプル、すなわち、確率\(w_z / \sum w_i\)を表します。これにより、式5を以下のように書き換えることができます:
\begin{eqnarray}
\langle F \rangle_{ris} = \frac{1}{N} \sum_{i=1}^N f(\omega_i) W(\omega, i) \tag{7}
\end{eqnarray}
であり、次の期待値である限りアンバイアスです:
\begin{eqnarray}
{\mathbb E}[ W(\omega, z) ] = \frac{1}{p(\omega_z)} = \frac{\int {\hat p}(\omega) d\omega }{ {\hat p}(\omega_z) } \tag{8}
\end{eqnarray}
これには基本的に\({\mathbb E}[ \frac{1}{M} \sum \frac{ {\hat p}(\omega_i) }{ q(\omega_i) } ] = \int {\hat p}(\omega) d \omega \)が必要で、これはモンテカルロ積分に過ぎません。しかし、この期待値が望ましい結果に収束し続けることを保証することは、再利用が複雑になるにつれて、つまり繰り返しリサンプリングするときに課題となります。このため、バイアスが発生する可能性があり、この点についてはセクション4でより深く検討します。
3.1.2. Degenerate Resampled Importance Sampling
RISのエッジケースを調べることで、そのサンプリング特性に関する洞察が得られ、後に紹介する性能向上の動機付けとなります。エッジケースの1つは、\(M=1\)および\(M \rightarrow \infty\)です:
\begin{eqnarray}
F &\approx& \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{q(\omega_i)} \right] \quad {\rm for} \quad M=1, {\rm and} \\
F &\approx& \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}(\omega_i)} \int_{\Omega} {\hat p}(\omega) d\omega) \right] \quad {\rm when} \quad M \rightarrow \infty \tag{9}
\end{eqnarray}
\(M=1\)の場合、RISはモンテカルロ積分となり,ソースPDF \(q\)をサンプリングします。\(M=\infty\)の場合、RISは正規化ターゲット関数\({\hat p}\)を完全にサンプリングします。エッジケースの間では、\(M\)が大きくなるにつれて、RISはターゲット\({\hat p}\)の分布に従ってより密接にサンプリングするようになり、(良い\({\hat p}\)の場合)全体の重点サンプリングはより良くなります。
式9は,より高品質なソースpdf \(q(\omega)\)を使用することの価値についての洞察を与えてくれます。\(M\)が小さい場合,\(q\)の品質は最終的な推定値に劇的に影響します。\(M \rightarrow \infty\)のように、\(q\)の品質は無関係です。RISとReSTIRでは、\(M\)が大きい領域では、\(q\)の改善はほとんど影響を与えず、\(M\)が小さい場合、\(q\)の改善は意味があります。
\({\hat p}(\omega) = q(\omega)\)を定義すると別の退化が生じます。この場合、式5は次のようになります:
\begin{eqnarray}
F & \approx & \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}(\omega_i)} \frac{1}{M} \sum_{j=1}^M \frac{ {\hat p}(\omega_{ij}) }{ q(\omega_{ij})} \right] \\
& = & \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{q(\omega_i)} \frac{1}{M} \sum_{j=1}^M 1 \right] = \frac{1}{N} \sum_{j=1}^N \left[ \frac{f(\omega_i)}{q(\omega_i)} \right] \tag{10}
\end{eqnarray}
これも標準的なモンテカルロ推定量を与えています。しかし、\(M=1\)とする式9とは異なり、この退化したRISは2段階になっています!アルゴリズム的には、潜在的なサンプルの領域から\(M\)個の要素のサブセットを選択し、モンテカルロ積分のためにこれらの要素の\(N\)個を選択します。重要な観察:どんなモンテカルロ推定量も、2ステップの退化したRIS推定量に置き換えることができます。
3.1.3. Resampled Importance Sampling as Stratification
最後のエッジケースは\({\hat p}(\omega) = f(\omega\)\)を定義し、ここで式5は次のようになります:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}(\omega_i)} \frac{1}{M} \sum_{j=1}^M \frac{ {\hat p}(\omega_{ij}) }{ q(\omega_{ij})} \right] = \frac{1}{N} \sum_{i=1}^N \left[ \frac{1}{M} \sum_{j=1}^M \frac{f(\omega_{ij})}{q(\omega_{ij})} \right] \tag{11}
\end{eqnarray}
これは、RISが固定集合に対する典型的な層別化ではなく、ランダムな部分集合に対する層別化の一形態として機能していることを示しています。すなわち、各ピクセルにおいて、\(M\)個のランダム候補\(w_{ij}\)の\(N\)組が生成されます:
\begin{eqnarray}
\{ \{ \omega_{11}, \cdots, \omega_{1M} \}, \{ \omega_{21}, \cdots, \omega_{2M} \}, \cdots, \{ \omega_{N1}, \cdots, \omega_{NM} \} \} \tag{12}
\end{eqnarray}
そして、\(N\)個の集合のそれぞれから1個のランダムサンプル\(\omega_i\)が選択されます(重み\(w_{ij}\)に比例する)。
式5を層別推定量とみなすことで、非層別RIS推定量も定義することができます。これは、\(M\)個の候補の同じセットから\(N\)個のサンプル\(\omega_i\)をすべて選択し、合計を独立させるものです:
\begin{eqnarray}
F = \int_{\Omega} f(\omega) d\omega \approx \left( \frac{1}{N} \sum_{i=1}^N \frac{f(\omega_i)}{{\hat p}(\omega_i)} \right) \left( \frac{1}{M} \sum_{j=1}^M \frac{{\hat p}(\omega_j)}{q(\omega_j)} \right) \tag{13}
\end{eqnarray}
RISをランダムな層別化として捉えることの有用性は不明確かもしれませんが、セクション5でRISを適用して計算を再構築する際に、この観察を再検討します。
3.2. Weighted Reservoir Sampling
レイの数を最小化するために、手頃な最大セット\(M\)からリサンプルを行うことを目指します。最良の結果を得るには\(M \gt 1000\)が必要ですが、先行するRIS法[TCE05, THE16]では、再サンプリングが完了するまで候補を保持するため、\(O(M)\)のストレージが必要となり、高いサンプル数を実現することは不可能でした。
Bitterliら[BWP*20]は、重み付けレゼバーサンプリング[Cha82, Vit85]を用いてRISを再定義し、候補をストリーム化することでストレージを\(O(N)\)、つまり選択したサンプル\(\omega_i\)のみがメモリに残るようにしました:

重みづけレゼバーサンプリングは、素直な帰納的アプローチをとります。ストリームが望ましい分布で部分的にサンプリングされていると仮定すると、新しい要素\(\omega_i\)を処理するには、現在のサンプル\({\mathcal R}.\omega\)を\(\omega_i\)に置き換えるかどうかを決定するだけでよいです。RISでは、関数weight(\(\omega_i\))を\(w_i={\hat p}(\omega_i) / q(\omega_i) \)とし、新しいサンプルを選択する確率を\(w_i / (\sum_{j \leq i} w_j)\)とします。
3.3. Spatiotemporal Importance Resampling
重み付けレゼバーサンプリングにより、メモリ効率の良いRISが可能になりますが、計算量は\(O(M)\)のままです。完全な重点サンプリングに近づけるためには\(M\)を大きくする必要があるため、これは問題となります。
ReSTIR[BWP*20]は、有効サンプル数を大幅に増やすために、近傍と前のフレームサンプルを再利用し、候補サンプルコストを多くのピクセルで償却することを提案しました。これは,レンダリングが完了した後に色にポストフィルタをかける従来の再構成やノイズ除去の方法ではなく,pdfに事前フィルタをかけるものです。
重要な数学的洞察は、式4で示されるほぼ完全な重点サンプリングは、従来のモンテカルロ推定器を使用する必要がないことです。RIS推定器を使うことができるのです:
\begin{eqnarray}
p(\omega) = \frac{ {\hat p}_0(\omega) }{ \int {\hat p}_0(\omega) d\omega } \approx \frac{ {\hat p}_0(\omega) }{ \frac{1}{M} \sum_j \left[ \frac{ {\hat p}_0(\omega_j) }{ {\hat p}_1(\omega_j) } \frac{1}{M} \sum_k \frac{ {\hat p}_1(\omega_{jk}) }{ q(\omega_{jk}) } \right] } \tag{14}
\end{eqnarray}
これを式2に戻して再整理すると、式5と同様の2回繰り返しRIS推定器が得られます:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_j)}{ {\hat p}_0(\omega_i) } \frac{1}{M_0} \sum_{j=1}^{M_0} \left[ \frac{ {\hat p}_0(\omega_{ij})}{ {\hat p}_1(\omega_{ij}) } \frac{1}{M_1} \sum_{k=1}^{M_1} \frac{ {\hat p}_1(\omega_{ijk}) }{ q(\omega_{ijk}) } \right] \right] \tag{15}
\end{eqnarray}
任意の回数、すなわち式14の推定量として式15を使い、与えることを反復することができます:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{ {\hat p}_0(\omega_i) } \frac{1}{M_0} \sum_{j=1}^{M_0} \left[ \frac{{\hat p}_0(\omega_{ij})}{{\hat p}_1(\omega_{ij})} \frac{1}{M_1} \sum_{k=1}^{M_1} \left[ \frac{ {\hat p}_1(\omega_{ijk}) }{ {\hat p}_2(\omega_{ijk})} \cdots \right] \right] \right] \tag{16}
\end{eqnarray}
反復ごとのターゲット関数\({\hat p}_i(\omega)\)は、非常に柔軟性があります。空間的、時間的近傍、または現在のピクセルの分布を推定することができます。また、レンダリング方程式(可視性、入射照明、BRDF、余弦項など)の一部または全部を含めることができます。\(f(\omega) \gt 0\)であれば、\(q(\omega) \gt 0\)、\({\hat p}_i(\omega) \gt 0\)であれば、結果にバイアスを持たせることなく、バイアスドなターゲット関数やアドホックターゲット関数を使用することができます。
直感的に、式16を次のように読みます: \(M_0\)によって制御される品質で完全な重点サンプリングを近似するため、\(N\)は大きい必要はないです。しかし、\(M_0\)は\(M_1\)によって駆動される品質で(再び)重点サンプリングによって最小化されます。しかし、良いサンプリングのため、\(M_1\)は\(M_2\)に駆動されて大きくなくてよいです。我々は、1つの項\(M_i\)を必要とするか、または積\( \prod_i M_i \)が無限大に向かう傾向があるかのどちらかです。これを安価にするために、コストを償却します。サンプルを再利用することで、計算の費用は一度で済みますが、各サンプルは何千もの隣接の\(M_i\)値を増加させます。
3.4. Variance of Resampling Importance Sampling
もちろん、この直感的な解釈では、反復リサンプリングが分散を減らすと主張します。Talbotら[Tal05, TCE05]は、RISの理論的な分散分析を行い、詳細な理解を可能にしています。彼らは、我々のRIS推定量\(\langle F \rangle_{ris}\)の分散は、次のように書けることを示しています:
\begin{eqnarray}
Var(\langle F \rangle_{ris}) = \frac{1}{N} \left[ \frac{1}{M}(e_3 – e_2) + (e_2 – e_1) \right] \tag{17}
\end{eqnarray}
ここで,
\begin{eqnarray}
e_1 = {\mathbb E} \left[ \frac{f}{q} \right]^2 , \quad e_2 = {\mathbb E} \left[ \frac{f^2}{{\hat p}q} \right] {\mathbb E} \left[ \frac{{\hat p}}{q} \right] , \quad e_3 = {\mathbb E} \left[ \frac{f^2}{q^2} \right].
\end{eqnarray}
\(N\)と\(M\)はともに\(e_3 – e_2\)の分散を制御しますが、\(N\)のみが\(e_2 – e_1\)に影響を与えます。有益なコーナーケースとして、\({\hat p} \propto q\)なら\(e_3 – e_2=0\)、\({\hat p} \propto f\)なら\(e_2 – e_1 = 0\)です。
\(e_2 – e_1=0\)を確保するために\({\hat p} \propto f\)を選択する場合、式17を繰り返し適用すると、確かに\(1 / (N \prod_i M_i)\)に分散が比例します。しかし、実際には\({\hat p} \propto f\)は実現不可能であり、\(1/N\)、\(1/(NM_0)\)、\(1/(NM_0M_1)\)などの部分積に比例した残差となります。
Bitterliら[BWP*20]では、\({\hat p}\)が\(f\) の剰余の可視性に比例するため、\(N\)は視認性の分散を大きく制御します。時空間再利用の間、大きさ\(|e_2 – e_1|\)は再利用されたサンプルが現在のピクセルの値をどれだけ近似しているかに依存します。
ピクセルとその近傍が似ているような小さな残差の場合、分散は\(1/(N\prod_i M_i)\)項によって支配され、再利用による追加サンプルは品質を大きく向上させます。近隣のピクセルが大きく異なる場合(一般に様々な不連続面の近く)、\(|e_2 – e_1|\)は大きくなります。このような隣接ピクセルからの再利用は有害な場合があります。
3.5. Comments on Notation and Generalization
上記のわかりやすさを向上させるため、リサンプリング時に変化する可能性のあるすべての値に添え字を明示的につけることは避けました。具体的には,\(M\)個の値は\(i\)によって変化し,ソースpdf \(q\)はすべてのサンプル\(j\)について同じである必要はありません。すなわち,式5を書くことができます。
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}(\omega_i)} \frac{1}{M_i} \sum_{j=1}^{M_i} \frac{{\hat p}(\omega_{ij})}{ q_{ij} (\omega_{ij}) } \right]
\end{eqnarray}
これは,異なるサイズのランダムサブセット(サイズ\(M_i\))から\(N\)個のサンプルを選択するもので,各サンプル\({\omega}_{ij}\)はユニークなソースPDF \(q_{ij}\)を持つことができます。
表記の複雑さは多少軽減されるものの(例:式16)、バリエーションは頻繁に発生します。ReSTIRは異なるピクセル間でリサンプリングします。ターゲット関数\({\hat p}_1\)、\({\hat p}_2\)などは、どのピクセルが再利用されるかに応じてすべて変化します。そして、リサンプリングは、画面全体で異なる時間に起こるディスオクルージョンにおける\(M=0\)から新たに開始されます。
4. On Bias in Spatiotemporal Reuse
直感的には、RISとReSTIRは、真の完全なサンプリングの代わりに適用できる近似的に完全な重点サンプラーを提供します。しかし、それはあくまで近似的に完全なものであることを忘れないでください。セクション3.1.1で説明したように、実際にはランダム化アルゴリズムによって確率的にpdf \(p(\omega)\)を生成します(例えば、[MR95]を参照)。サンプルはフレーム間でランダムに変化するだけでなく、それらを選択するために使用されるpdfも同様に変化します!
セクション3.1.1では、期待値\({\mathbf E}[W(\omega, z)]\)は確かに\(1/p(\omega_z)\)の期待値に収束すると論じていますが、これはサンプルの領域が同一である場合にのみ成立します。ReSTIRでは、ターゲット関数\({\hat p}_i\)やソースpdf \(q_{ij}\)が我々のものと異なる可能性のあるピクセルを明示的に再利用することで、サンプルプールの多様性を拡大します。
しかし、この多様なサンプルの再利用は、バイアスを導入する可能性があります。Bitterliら[BWP*20]は、式5について、ソースpdfの\(q_{ij}\)がサンプルごとに任意に変化する場合、次のように示しています:
\begin{eqnarray}
{\mathbb E}[W(\omega, z)] = \frac{1}{p(\omega_z)} \frac{|Z(\omega_z)|}{M} \tag{18}
\end{eqnarray}
ここで、\(|Z(\omega_z)|\)は、\(q_j(\omega_z) \gt 0\)であるソースpdf \(q_j\)をカウントする、つまり
\begin{eqnarray}
Z(\omega) = \{ j \quad | \quad 1 \leq j \leq M \quad {\rm and} \quad q_j(\omega) \gt 0 \} \tag{19}
\end{eqnarray}
基本的に、すべてのpdfがサンプル\(\omega\)を生成できない場合(つまり,ある\(j\)について\(q_j(\omega) = 0\))、\(\omega\)を選択するとバイアスが発生します。しかし、式18は、バイアス除去が簡単であることを示唆しています:
\begin{eqnarray}
{\mathbb E} \left[ \frac{M}{|Z(\omega_z)|} W(\omega, z) \right] = \frac{1}{p(\omega_z)} \tag{20}
\end{eqnarray}
となり、式5のRIS推定値の不偏的なバリエーションとなります:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}(\omega_i)} \frac{1}{|Z(\omega_i)|} \sum_{j=1}^M \frac{ {\hat p}(\omega_{ij}) }{ q_{ij}(\omega_{ij}) } \right] \tag{21}
\end{eqnarray}
そして、式16を更新する不偏のReSTIR推定器は次のようになります:
\begin{eqnarray}
\frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}_0(\omega_i)} \frac{1}{|Z_i|} \sum_{j=1}^{M_0} \left[ \frac{{\hat p}(\omega_{ij})}{{\hat p}_1(\omega_{ij})} \frac{1}{|Z_{ij}|} \sum_{k=1}^{M_1} \left[ \frac{{\hat p}_1(\omega_{ijk})}{ {\hat p}_2(\omega_{ijk}) } \cdots \right] \right] \right] \tag{22}
\end{eqnarray}
ここで、\(|Z_i|\)は\(\omega_i\)において非ゼロである\({\hat p}_1\) pdfの数をカウントし、\(|Z_{ij}|\)は\(\omega_{ij}\)においてどのぐらいの多くの\({\hat p}_2\) pdfが非ゼロであるかをカウントする,等です。
4.1. Intuitively Understanding Bias
式21は再利用が不偏であることを示しますが、\(|Z(\omega_i)|\)の評価にはコストがかかります。増加したコストに対して十分に補うための忠実度を向上させるバイアス除去する際に,どのぐらいバイアスが生じるかを知ることで決定を助けます。コストのかかる\(|Z|\)項がない場合、推定値は不偏性を保証します:
- 重点サンプリング(式2), if \(p(\omega) \gt 0\) when \(f(\omega) \gt 0\).
- RIS (式5), if \({\hat p}(\omega) \gt 0 \) and \(q_j(\omega) \gt 0\) when \(f(\omega) \gt 0\).
- ReSTIR (式16), if \({\hat p}_i(\omega) \gt 0\) and \(q_j(\omega) \gt 0\) when \(f(\omega) \gt 0\).
これらは、すべての\(|Z(\omega)|\)項が対応する\(M\)項と等しく、式18の余分な因子がキャンセルされたときの条件を再表現したものです。
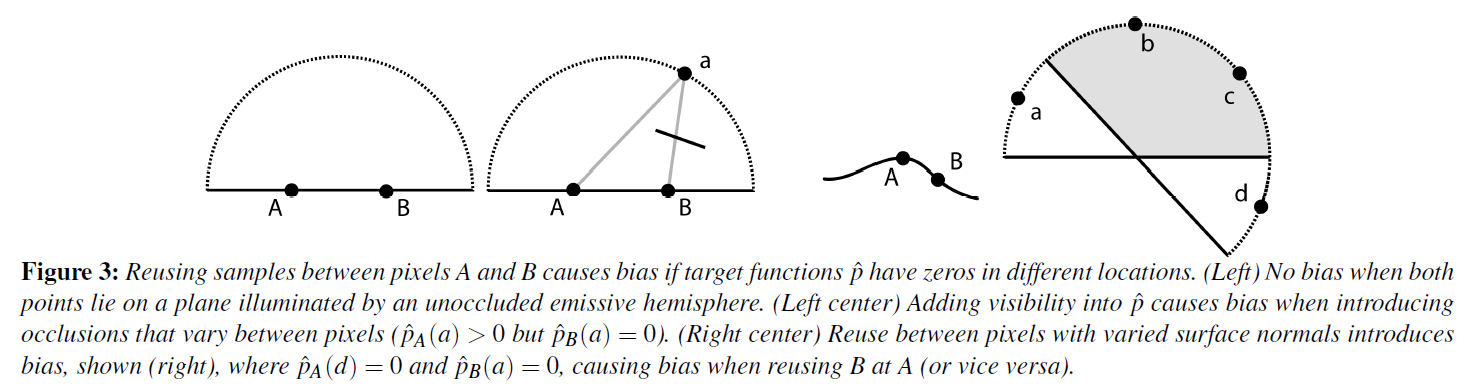
図3は、RIS(およびReSTIR)において、これらの保証が破綻する場合を示しています。平面上の2点は、遠くの影のない光で照らされているため、偏りのない方法でサンプルを再利用することができます。しかし、オクルージョンを招いたり、異なるサーフェイス方向間で共有したりすると、確率が0値になってしまいます。具体的には、以下のような場合にバイアスが発生します:
- \(B\)のターゲット関数,\({\hat p}(\omega)\),が変化する可視性を持つ(\(A\)から\(B\)へと)
- \(B\)のターゲット関数,\({\hat p}(\omega)\),は\(A\)における半球をカバーしない
- \(B\)のソースpdf,\(q(\omega)\),は\(A\)において半球をカバーしない
このリストを列挙するのは簡単で、反射光が現在のピクセルではゼロではないけど、再利用される近隣のピクセルではゼロである場合を考えてみましょう。これらはバイアスをもたらします。複雑な環境では、他のソースからバイアスを追加することができます。例えば、方向的に変化する発光や、可視半球の反射率がゼロになるBRDFなどです。
すべてのバイアスタイプは式21と式22の推定値で処理されますが、\(|Z(\omega)|\)を計算するためのコストは大きく変化する可能性があります。例えば、法線の変化による水平線より下のサンプルのゼロを特定するには、数個の内積が必要です。しかし、視界の変化を見つけるには、新しいレイを発射する必要があります。
重要なのは、\(|Z(\omega)|\)項によるバイアス除去を行う場合、一度に1つの反復のみを考慮することです。式22で変化した\({\hat p}_2\)は\({\hat p}_1\)を近似する際にバイアスを加える可能性がありますが、補正することで特定のピクセルにおける\({\hat p}_1\)のバイアスのない推定値を得ることができます。これらのバイアスのない\({\hat p}_1\) pdfは、\({\hat p}_0\)を推定するために(再)使用することができます。しかし、\({\hat p}_1\)を近隣から借用することで、不偏の\({\hat p}_0\)を得るために考慮すべき新たな差異が発生する可能性があります。
バイアス除去は一度に一つの反復しか考慮しませんが、コスト削減のためにデバイアスをスキップする場合、バイアスは反復的に合成することを理解することが重要です。バイアスの爆発を避けるために、注意が必要です。
4.2. Manifestation of Bias
セクション4.1でバイアスが発生する理由を説明しましたが、バイアスがどのように現れるかは不明でしょう。図4はその具体例で、法線が異なるピクセルからのサンプルを再利用しています。バイアスは、両方のピクセルからサンプリングできないサンプルを選択する場合(例えば、丸で囲んだ青いもの)、コーナーケースで発生します。このようなケースでは、慎重に正規化を行う必要があります。

正規化とは、積分をばらばらに分割することです。図4では、両半球をカバーする領域を\(M_{A+B}\)個の有効サンプルで積分しています。一方、\(A\)の半球で覆われた領域は、\(M_A\)個の有効サンプルで積分されています。直感的には、これが式21と式22の\(|Z(\omega)|\)項の役割です。
式20の\(M/|Z(\omega)|\)項が無視されることによって生じるバイアスを理解すれば、その外観を説明することが容易になります。最も一般的なのは、ターゲット関数がゼロになることを考慮せずに、常にすべての近傍サンプルを使用することでバイアスが発生することです。
図4では、\(M_{A+B}\)しか寄与しない領域でも、\(M_A\)の有効サンプルを想定して再利用しています。RISの正規化項について:
\begin{eqnarray}
\frac{1}{M_i} \sum_{k=1}^{M_i} \left[ \frac{{\hat p}_i(\omega_k)}{{\hat p}_{i+1}(\omega_k)} \cdots \right] \tag{23}
\end{eqnarray}
\(M_i\)は大きくなりすぎてしまいます(つまり、\(M_A\)ではなく\(M_{A
+B}\)になってしまいます)。そのため、正規化項が小さくなり、ダーケニングが発生します。部分的に関連するpdfを持つより多くの近傍を再利用する場合、ダーケニングは悪化します。したがって,大きな深度,法線,影の境界付近では,バイアスが増加します。
4.3. Heuristics for Reducing Bias
Bitterliら[BWP*20]は、\(|Z(\omega)|\)を計算することなく、バイアスを減らすのに役立つ簡単なヒューリスティックを適用することを提案しています。数学的には、これは式5のRIS推定量にヒューリスティック関数\(H\)を導入します:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_i)}{{\hat p}(\omega_i)} \frac{1}{{\mathbb H}} \sum_{j=1}^M \left( H(i, j) \frac{{\hat p}(\omega_{ij})}{q(\omega_{ij})} \right) \right] \tag{24}
\end{eqnarray}
ここで,\(H(i, j) \in \{0, 1\}\)は,経験則的な結果に基づくものです。\({\mathbb H}\)は\(M\)を再解釈し、ヒューリスティックが通過したサンプル、すなわち\({\mathbb H}=\sum H(i, j)\)をカウントします。ヒューリスティックは、フィルタリングにおけるエッジストップ機能のような働きをします。境界を越えるバイアスを止め、近傍のバイアスを閾値(ヒューリスティックパラメータで制御可能)以下に保つことができます。
Bitterliら[BWP*20]は、iとjの法線が同じ方向を向いているか(つまり, \(\langle {\vec n}_i \cdot {\vec n}_j \rangle \gt \tau \))、ピクセルの深度が似ているか(つまり,\({\rm abs}[(z_i – z_j)/z_i] \lt \epsilon\))をチェックする、標準的なヒューリスティックを使用しています。
図5は、ヒューリスティックがどのように役立つかを示したものです。時空間再利用では、ターゲット機能の重なりが小さくなるにつれて、バイアスが大きくなります。重なりが小さい場合、再利用はバイアスを大きく増加させますが、新しいサンプルはほとんど追加されません。マッチングの悪い近傍を無視することで、品質にほとんど影響を与えずにバイアスを低減することができます。
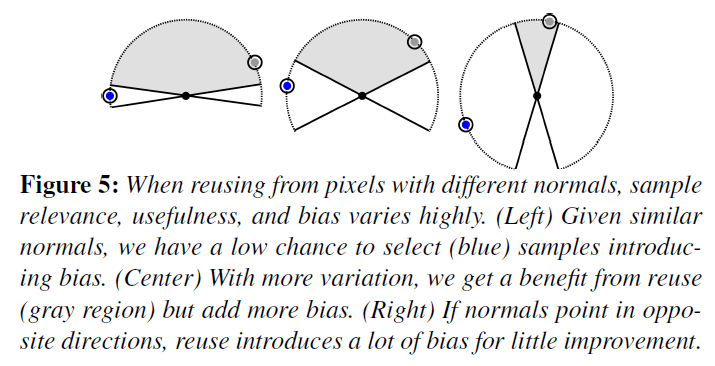
図4と図5は、法線を変化させた場合の再利用を示していますが、可視性を変化させると、近傍ターゲット関数\({\hat p}\)がゼロになる領域も定義されます。深度の差が大きい場合の再利用は、サンプルの見え方が変わることが多いので、深度ヒューリスティックはこのようなサンプルを棄却するのに役立ちます。
他のヒューリスティックも可能ですが、サンプルの重みやpdfの\({\hat p}(\omega_{ij})\)や\(q(\omega_{ij})\)を調べるヒューリスティックは、一般的に式24の\(H(i, j)\)に条件付き確率を追加します。我々のリサンプリング理論はまだこのような条件付き確率を扱っていないので、これらのヒューリスティックは近傍を過剰に棄却する傾向があります。これにより、式23の\(M_i\)が縮小され、ライトニングバイアスが発生します。
4.4. Multiple Importance Sampling For Sample Reuse
式21は、サンプルの選択に貢献した近傍に基づき、サンプルを正しく正規化します。セクション4.3のヒューリスティックは、有益である可能性が高いサンプルに関する知識を用いて、カテゴリー別に棄却します。しかし、どちらのアプローチも、近傍を再利用するか、棄却するかの二者択一で判断します。もしある近傍が他の近傍よりも良い推定値を提供したらどうでしょうか?近傍の重み付けを変えることはできないでしょうか?
多重点サンプリング(MIS)[VG95]は、まさにこのような再重みづけを可能にします。リサンプリングでは、各隣接は現在のピクセルをサンプリングするために使用する異なる推定量です。Bitterliら[BWP*20]は、式6の重み関数\(W(\omega, z)\)を任意の重み\(m(\omega_z)\)で再定義することで、MISの簡単な応用例を示しています:
\begin{eqnarray}
W(\omega, z) = \frac{1}{{\hat p}(\omega_z)} \left[ m(\omega_z) \sum_{i=1}^M w_i(\omega_i) \right] \tag{25}
\end{eqnarray}
この新しい\(W(\omega, z)\)で期待値を再計算すると、次のようになります:
\begin{eqnarray}
{\mathbb E}[W(\omega, z)] = \frac{1}{p(\omega_z)} \sum_{i \in Z(\omega_z)} m(\omega_i) \tag{26}
\end{eqnarray}
は、総和\(\sum_{i \in Z(\omega)} m(\omega_i) = 1\)となるような \(m(\omega_z)\) を定義すれば、いつでも不偏の再利用を可能にします。これは、式21で使用される\(m(\omega_z) = 1 / |Z(\omega_z)|\)について些細なことです。しかし、この些細な\(m(\omega_z)\)を標準的なバランスヒューリスティックで置き換えることができます:
\begin{eqnarray}
m(\omega_z) = \frac{q_z(\omega_z)}{\sum_{i=1}^M q_i(\omega_z)} \tag{27}
\end{eqnarray}
これを、わかりやすくするために、次のように書くこともあります:
\begin{eqnarray}
m(\omega_z) = \frac{q_z(\omega_z)}{\sum_{i \in Z(\omega_z)} q_i(\omega_z) } \tag{28}
\end{eqnarray}
上記として、時空間再利用時にpdfの\(q_i(\omega_z)\)がゼロになることがあります。式5を修正することで、我々のRIS推定器の不偏、MIS確率変数が得られます:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_{zi})}{{\hat p}(\omega_{zi})} m(\omega_{zi}) \sum_{j=1}^M \frac{{\hat p}(\omega_{ij})}{q_j (\omega_{ij})} \right] \tag{29}
\end{eqnarray}
とし、式27からバランス・ヒューリスティックを挿入します:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_{zi})}{{\hat p}(\omega_{zi})} \frac{q_{zi}(\omega_{zi})}{\sum_{k=1}^M q_k(\omega_{zi})} \sum_{j=1}^M \frac{{\hat p}(\omega_{ij})}{q_j(\omega_{ij})} \right] \tag{30}
\end{eqnarray}
ここで、表記をわかりやすくするために、\(\omega_{zi}\)をRISが再利用するために選択した集合\(\{\omega_{i1}, \cdots, \omega_{iM}\}\)のサンプル、\(q_{zi}\)をそのサンプルの対応するソースPDF \(q_j\)と定義しています。
4.5. Interesting MIS Observations
Bitterliら[BWP*20]は、\(m(\omega_i)\)の和が単一になることで不偏性が得られることを導き出し(式26)、MISの標準的なバランスヒューリスティックを再利用できると直接推論しています。しかし、私たちはもっとありふれた、しかしまだ役に立つ観察をすることができます。
例えば、\(M=4\)(4つの近傍から再利用する)の場合、\(m(\omega_z)=0.25\)と定義することができます。あるいは、より有用な方法として、4つの近傍が\(2 \times 2\)ブロックにある場合、\(m(\omega_z)\)をバイリニア重みのセットとして定義することができます。
レゼバーは離散的なサンプルで構成されており、明確な補間演算がないため、補間は意味をなしません。しかし、式26を用いれば、関数\(m(\omega_z)\)に直接バイリニアウェイトを組み込むことができ、同様の効果が得られます。時間的再利用の際、このような重みは、バックプロジェクションされたピクセルの4つの時間的近傍から比例的に再利用する1つのメカニズムを提供します。
4.6. Combining Heuristics and Multiple Importance Sampling
式30または反復変形(式22のようなもの)の多重点サンプリングには、2つの問題が残っています:
- MISは、貧弱なpdfを使用すると分散が大きくなることがあります。
- バイアスを除去するためにコストを払う必要はありませんが、バイアスを軽減したい場合もあります。
基本的には、セクション4.3とセクション4.4のヒューリスティックとMISが相互に排他的でないことを望みます。おそらく開発者が、サーフェイスの法線の違いによるバイアスを除去するためにMISの内積を追加する余裕があっても、視認性のバイアスを除去するためのレイを追加するのはコストがかかりすぎます。
また、MISは理論的には2つの極端に異なる推定量を正しく組み合わせていますが(例えば、図5右)、おそらく現実的には悪い考えだと思います。ヒューリスティックを使って、既知の悪い推定量をMISに渡さないようにし、結果として分散を減らすことができます。
幸い、式24のヒューリスティック推定器は、式29のMIS推定器に似ています。実際、ヒューリスティックはMISの重み付けの一形態と考えることができ、すなわち、集合\({\mathcal Z}(i, \omega)\)を定義することができます:
\begin{eqnarray}
{\mathcal Z}(i, \omega) = \{j \quad | \quad i \leq j \leq M \quad {\rm and} \quad q_j(\omega) \gt 0 \quad {\rm and} \quad H(i, j) = 1 \} \tag{31}
\end{eqnarray}
上記は、MISとヒューリスティックの両方を使用することができ、式21のようなものです:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_{zi})}{{\hat p}(\omega_{zi})} \frac{1}{|{\mathcal Z}(i, \omega)|} \sum_{j \in {\mathcal Z}(i, \omega)} \frac{{\hat p}(\omega_{ij})}{q_j(\omega_{ij})} \right] \tag{32}
\end{eqnarray}
となり、式30へ:
\begin{eqnarray}
F \approx \frac{1}{N} \sum_{i=1}^N \left[ \frac{f(\omega_{zi})}{{\hat p}(\omega_{zi})} \frac{q_{zi}(\omega_{zi})}{ \sum_{k \in {\mathcal Z}(i, \omega)} q_k(\omega_{zi})} \sum_{j \in {\mathcal Z}(i, \omega)} \frac{{\hat p}(\omega_{ij})}{q_j(\omega_{ij})} \right] \tag{33}
\end{eqnarray}
これにより、RISとReSTIRをバイアスドな形で適用する、ヒューリスティックで適用する、MISで偏りをなくす、MISとヒューリスティックの両方で適用する、といった選択肢が可能になりました。
式33を用いると、最高品質のバイアスモードと非バイアスモードの違いは、単にMISウェイト\(q_{zi}(\omega_{zi})/\sum q_k(\omega_{zi})\)でシャドウレイを発射するかどうかということになります。アンバイアスドなモードでは、近傍ごとに(つまり、\(q_k\)ごとに)1本のレイを発射し、バイアスドなモードでは、各クエリが除外されていないと仮定してレイのトレースをスキップします。
どちらのバージョンでも、MISは法線が変化した近傍再利用によるバイアスを補正し、ヒューリスティックはバイアスとノイズの両方をもたらす可能性のある近傍を棄却します。唯一の違いは、時空間的な視認性の変化に起因するバイアスがあるかどうかです。
図5に示すように、大きなバイアスをかけると、ノイズも大きくなってしまうことが重要なポイントです。ヒューリスティックは、このような近傍を棄却するのに役立ち、MISを使用する際にも役に立ちます。図6は、MISとヒューリスティックの様々な組み合わせによる効果を示しています。

5. Reshaping Resampling for Improved Memory Coherency
RISとReSTIR推定量の理論的な導出と、リサンプリング時にどのようにバイアスが発生するかについての深い理解が得られたので、次はボトルネックの除去や最適なパフォーマンスを得るためのアルゴリズムの再設計などの実用的な問題焦点を当てることにします。
ReSTIRの魅力は、一定時間の計算の複雑さです。各ピクセルはソースPDF \(p(\omega)\)から小さな初期候補のセットを選択し、現在と前のフレームからのいくつかのレゼバーと結合します。Bitterliら[BWP*20]は、32個の候補、1個のテンポラルレゼバー、およびそれぞれ5個の近傍を持つ2ラウンドの空間再利用を使用しています。レゼバーは4つのサンプルを保存するため、ピクセルはちょうど72個のライトに触れます。
しかし、ReSTIRをテストしたところ、性能が一定でないことがわかりました。実際、プロファイルされたコンポーネントのコストは、シーン間で最大20倍まで変化しました。明らかに、固定された計算とメモリの使用量(つまり72回のルックアップ)とパフォーマンスの変化は、異なるキャッシュの動作を意味します。GPUベンダーや世代によって変化するキャッシュベースのパフォーマンスの崖をアーティストが管理しなければならないため、採用が制限されます。
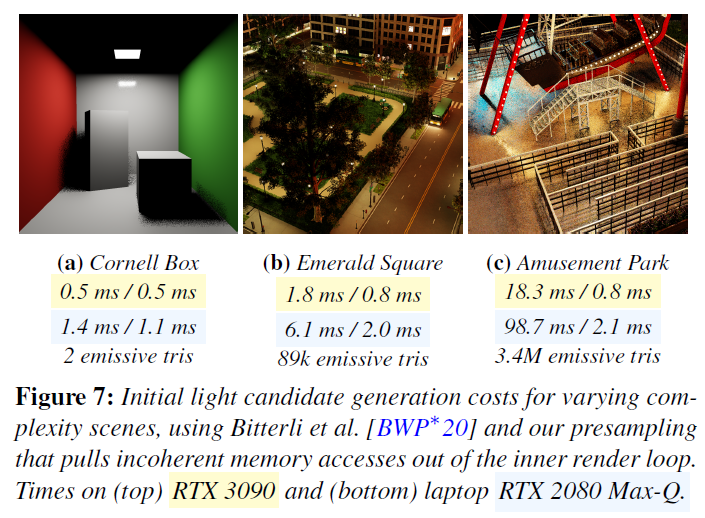
このキャッシュスラッシングは、ライト候補の独立したサンプリングによって発生します。コーネルボックス(図7参照)では、ピクセルが1つの光に対して32個のサンプルを選び、メモリをコヒーレントに使用します。アミューズメントパークでは、ピクセルは300万個の光の中からランダムに32個を選びますが、これはランダムにメモリを歩き回り、キャッシュミスのためにDRAMに移動することがよくあります。
興味深いことに、層別サンプリングは性能向上に役立ちます。例えば、ジッタードサンプリング [Coo86]では、スレッドがライトリストのサブセットをコヒーレントに歩き、キャッシュスラッシュの可能性を低減します。しかし、これはワープ内の非整合を減らすだけであり、別々のワープがキャッシュラインを奪い合うことに変わりはありません。しかし、セクション3.1.3では、RISがランダムなサブセットに対して層別化することを示しています。これでコヒーレンシを改善できるのでしょうか?
5.1. Reshaping Computation Using Degenerate RIS Steps
退化したRIS推定量には2つの利点があることを忘れないでください。ランダムな層別を提供し、サンプリングを2つのステップに分解してくれます。重要な観察:分解されたサンプリングステップは、異なる時間に発生することができます。最初のステップである\(M\)-サイズのライトサブセットの作成は、最もインコヒーレントなメモリアクセスを含んでいるため、内側のレンダーループから削除することでパフォーマンスが大幅に向上します(図7参照)。
ランダムなメモリ検索は非干渉性の原因となるため、ライトリストをプリサンプリングまたはプリランダム化することで、内側のレンダーループ中にキャッシュに残るより小さなライトサブセットを使用できるようになれば、非干渉性は軽減されます。図 8 は,Bitterli ら [BWP*20] のピクセル単位のサンプリングの擬似コードと,2 つのプレランダム化のバリエーションを比較したものです。

最も単純な因数分解(図8b)は,シーンライト\(L\)のサブセット\(S\)をフレームごとに1回選択し,ピクセルがSからサンプリングして,その(\(N=32\))ライト候補を選択するものです。\(S=L\)の場合は、ピクセルごとの独立したサンプリングに戻ります。\(|S|=N\)であれば,すべてのピクセルが同じ候補を使用します。いずれにせよ,隣接するピクセルがすべて同じ候補から選択するため,式13のように非層化RISが得られます。
より複雑なアプローチは、各ピクセルのライトサブセット\(S_j\)を計算することです。レンダリングの際、各ピクセルは対応するサブセットから候補を選択します。これにより、式5による完全な層別化RISが得られます。しかし,この方法では性能は向上せず,ピクセルごとのサンプリングからフレームごとのプリプロセスに移行するため,同じような不整合が生じてしまいます。
分解サンプリングの威力は、これらの方法が連続体の端点であることです; 我々はフレームごとに1つの事前計算セットやピクセルごとに1つのセットを使用する必要はありません。\(|P|\)がピクセル数である場合、\({\mathbb S}\)のライトサブセット\(S_j\)を予め計算することができます。ここで\(1 \ll {\mathbb S} \ll |P|\)(図8cを参照)。これは式5及び式13を混合する、部分的に層化されたRISをもたらします。これにより、(\({\mathbb S} \ll |P|\)のように)非整合性が低減され、内部ループから除去されます。
5.2. Coherent Initial Candidate Generation
この原理を前提に、初期のピクセル単位の光源候補を選択するアルゴリズムを定義します。主要なパラメータは、各フレームで生成されるライトサブセットの数\({\mathbb S}\)、各サブセットのサイズ\(|S_j|\)、ピクセルがサンプリングするライトサブセット\(S_j\)を選択する方法、\(S_j\)からの事前計算とサンプリング時に使用するpdfです。
pdfは式10で落とし込まれます。グローバルライトからライト\(S_j\)をプリサンプリングする場合、ソースpdf \(q(\omega)\)を使用して\(L\)をサンプリングします。すなわち、Bitterliら[BWP*20]が初期候補生成に使用したのと同じpdfを使用します。\(S_j\)からピクセルごとの候補を選択するとき,サブセット\(S_j\)はすでに\(q(\omega)\)に従って分布しているので,一様に選択します。
ワープ内のまとまりを最大化するため、ピクセルのタイルはすべて同じサブセット\(S_j\)をサンプリングします。\(8 \times 8\)ピクセルのタイルは、時空間再利用によってマスクされない顕著な相関を導入することなく、コヒーレンスを最大化することを発見しました。
これにより、初期候補を選択する新しいアルゴリズムが完成しました:

経験的に、\({\mathbb S}=128\)と\(|S_j| = 1024\)が、幅広いシーンでアーティファクトを発生させずにコストを最小化できることを発見しました。より小さなシーンでは、これらの値はやり過ぎですが、起動のオーバーヘッドが計算あたりのコストを支配するので、より低い値では利点がないのです。大規模なシーンでは、作業セット\({\mathbb S} \times |S_j|\)が完全にキャッシュに収まり、各サブセット\(S_j\)が(数)キャッシュラインに収まることが前提になります。
5.3. Other Implications of Presampling Lights
サブセット\(S_j\)のライトの事前ランダム化には、キャッシュの向上以外にもメリットがあります。特に、サンプリング性能を高度に最適化することはあまり重要ではありません。\(1920 \times 1080\)の画像でピクセルあたり32個の初期候補があると,Bitterliら[BWP*20]はフレームあたり6400万個のライトを非干渉的にサンプリングします; \({\mathbb S}=128\)と\(|S_j|=1024\)の場合,解像度に依存せず,128,000個のインコヒーレントルックアップを必要とするだけです。
これにより、異なるサンプリングアルゴリズムを採用する柔軟性を持たせています。例えば、プリランダム化により、三角形、球体、カプセル、パッチなどのエミッシブプリミティブを簡単に混在させることができます。それぞれ独自のサンプリングコードを持っているため、ピクセル単位で混在させると、データと実行の分岐が発生します。しかし、退化したRISは、このダイバージェンスを内側のピクセル単位のループから引き離します。各フレームは、プリミティブの種類ごとに新しいサンプルを選択することから始まります:三角形のサンプルは\(S_t\)セット、球は\(S_s\)セット、カプセルは\(S_c\)セット、など。次に,結合された集合\(\{S_t, S_s, S_c, \cdots \}\)を適切なpdf(例えば,各プリミティブタイプからの総発光量に比例する)でサンプリングして,フレームごとのライトセット\(S_j\)を作成します。
さらに、Bitterliら[BWP*20]はエイリアステーブル[Wal77]を使って、パワーに比例するライトを選んでいます。エイリアステーブルは\(O(1)\)の安価なサンプリングを可能にし、1フレーム6400万サンプルの場合、重要な役割を果たします。しかし、最適なテーブルの構築には\(O(N)\)[Vos91]のコストがかかり、GPUでは些細なことでは並列化できません。中程度の複雑さのシーンではCPUによるビルドは0.5ms以下ですが、大きな環境マップではビルドコストが200msを超えます。
ダイナミックライトプローブについては、別のアプローチで代用することが可能です。Binder と Keller [BK19]は、カットポイント法[FM84]でサンプリングするためのradix forestを素早く構築するという選択肢を提案しています。カットポイント法はワーストケースで\(O({\rm log}N)\)のルックアップが必要ですが、radix forestによる検索は平均ケースで\(O(1)\)の複雑さになります。
その代わりに、既存のGPUの強みを活かして、ミップマップチェーンを用いて階層的にcdf反転[PJH16]を実行します。各環境マップのテクセルに対して、輝度(立体角の倍)を保存したテクスチャを作成し、ミップチェーンを構築します。サンプリングの際には、2番目に粗いミップレベルから開始し、4つのテクセルすべてを読み込みます。4要素のcdfを作成し、(確率\(p_{n-1}\)で)1つをサンプリングします。サンプルの4つの子を次のミップレベルでロードし、再び新しい4要素cdfからサンプリングします(確率は\(p_i\))。最も細かいレベルに到達すると、pdf \(p_{n-1} p_{n-2} \cdot p_0\)でサンプリングされたランダムテクセルが得られます。この階層の構築には、\(2048 \times 1024\)のライトプローブで約\(60 {\rm \mu s}\)のコストがかかります。ルックアップは\(O({\rm log}N)\)ですが、プリサンプリングにより、内部ループの外側で行われます。これにより、例えば\(360^{\circ}\)カメラからライブ配信されるライトプローブのような、真にダイナミックなテクスチャーのエミッシブが可能になります。
6. Improved Efficiency for Sampling
セクション5では、ReSTIRが複雑化するとスケールが小さくなる点を指摘しました。しかし、より深く調査した結果、他の隠れた非効率や冗長性が見つかり、以下にコスト削減と柔軟性向上のために対処します。
6.1. Ideal Ray Budget
Bitterliら[BWP*20]は、1画素あたり5本のレイを使用することを提案しています。絶対的な規模では、これは数百万個のライトを動的にシャドウイングするのに非常に安価です。しかし、開発者は、品質設定にもよりますが、現在では1ピクセルあたり\(\frac{1}{4}\)、\(\frac{1}{2}\)、1レイしか予算を割けません。従って、レイカウントのスケーリングは広く採用されるために不可欠であり、現在の予算の20倍を要求するのはハードルが高いのです。
セクション3.4の分散分析が、この5本のレイバジェットを動機づけます;ReSTIRは可視性の再利用をほとんどスキップしており、ピクセルあたりのシェード数である\(N\)が可視性の分散を制御することを意味します。Talbotら[TCE05]は、複雑なコスト分析によって、\(N\)と\(M\)のバランスをとることを提案しています。ハイエンド GPU では、\(N=4\) シャドウレイはミリ秒のコストがかかり、可視性の分散を減らすための小さな代償と思われます。
しかし、これを見直すことは、コストのスケールダウンに不可欠です。そのため、\(N=4\)を1に変えた場合の影響を分析したところ、意外な結果が出ました。より多くのレイがノイズを減らします。しかし、フレームレートを上げると視覚系のフリッカー融合により知覚品質も向上するため、その差はかなり小さく、(議論の余地なく)費用対効果が低いのです[ANS*19]。
レイの数の増加による分散の改善を制限するものは何でしょうか?ReSTIRは相関関係を利用して、近隣のサンプリング品質を向上させます。しかし、複数のサンプルをシェーディングする場合、相関関係が問題になります; 1ピクセルあたり4つの光源サンプルがある場合、ReSTIRは同じサンプルを複数回選択する可能性があります。
図9は、アミューズメントパーク内の重複したサンプルを可視化したものです。各シーンにおいて、1ピクセルあたり4サンプルをシェーディングした場合、1/2から2/3のピクセルが重複していることがわかります。また、20%の画素が同じ光源を4回選んでいます。さらに悪いことに、重複は影の近くで最も頻繁に発生します;これはまさに、サンプル数を増やすことで分散を減らすことができると期待される場所です!
幸い、研究者やエンジニアは、非常に少ないサンプルで頻繁に可視性をフィルタリングしています[JWPJ16, MML12, SKW*17, EHDR11]。\(N\)は視認性ノイズを制御し、\(N\)を増加させることはコストがかかり、やや効果がなく、このノイズをフィルタリングすることは、ピクセルあたり1サンプルで実現可能であることがわかっていることから、\(N=4\)は過剰で無駄があると判断しました。
本論文の残りの部分では、\(N=1\)を固定する。これにより、ReSTIRのレイの数は1画素あたり5本から2本に減少します。特に静止画の場合、影のある領域で品質が多少低下します。しかし、他の改良により、この品質低下を補うことができます。

6.2. Removing Per-frame Global Synchronization
図2のパイプラインを考えてみましょう。この構造はグローバルバリアに依存しており、空間的な再利用の前に、近傍が候補を選択し、時間的に再利用する必要があります。このため、複数のカーネルを使用するなど、特定の実装を選択する必要があります。
理論的には、同期を取り除くことで、図2のすべてのステップを含むReSTIRの単一カーネル変種が可能になります。これにより、最適化、償却、中間データのための帯域幅の削減の機会が増えます。実際には、ハードウェアの制約により、別々のコンポーネントの方が効率的な場合があります(例えば、レイトレーシング用に1つのカーネル、他の計算用に別のカーネル)。強制的な同期がなければ、これらの再定義のテストは著しく容易になります。
ReSTIRは、空間的・時間的に再利用することで時空間的な名前を得ています。しかし、真の時空間再利用、つまり時間的バッファの近傍を再利用することを避ける必要はありません。実際、すべての空間的なサンプルを時空間的なサンプルに置き換えることで、些細なことで同期がとれます。すべての再利用されたサンプルは最後のフレームに由来します。
一般的に、この変化は知覚できないものです。しかし、動きの速いジオメトリでは、前のフレームが現在のフレームと近似していないため、大きな不一致が発生します。この場合、時空間サンプルを使用すると、収束が実質的に1フレーム遅れることになります。このような遅延が好ましくない場合、現在のサンプルを再利用するために同期することが望ましい場合があります。
6.3. Importance of Temporal versus Spatial Reuse
ReSTIRは空間的サンプルと時間的サンプルの両方を再利用するため、それらの相対的重要性を理解することで、限られた予算の中で計算の優先順位を決めることができます。どちらの再利用にも、他の再利用の問題点を補う利点がありますが、同じように重要というわけではありません。
図10は、パリのオペラ座を様々な再利用で比較したものです。基本的なRISは、ピクセルごとに数個の候補ライトをテストしますが、複雑な環境では極めて不十分なものです。空間再利用では、有効サンプル数に定数(例えば、5回のタップで5倍)を掛けます。これにより、品質は顕著に向上しますが、基準には程遠いままです。時間的再利用は、以前のすべてのフレームから蓄積され、有効サンプル数をより大幅に増加させます。
しかし、時間的な再利用だけでは、2つの問題が出てきます。動きによって、テンポラルヒストリーのない除外された領域が明らかになります。また、レゼバーには明確な補間演算がない離散的なサンプルが含まれているため、バックプロジェクションによって最近傍の時間的サンプルを特定することができます。モーションでは、隣接するピクセル間に顕著な相関が加わります。このようなアーティファクトは、例えば図10のような画像では見えにくいです。空間的サンプルと時間的サンプルを組み合わせることで、これらの問題を解決することができます。
空間的なサンプルを1つでも追加することで、離散的なバックプロジェクションによる問題が解消されます。ここでは、空間的再利用が確率的フィルターとして機能し、相関のある時間的サンプルとランダムな空間的サンプルの間で選択されます。各ピクセルは異なる近傍を選択するため、空間再利用は時間的相関を確率的にディザリングする。
理想的な空間サンプル数を決定するためには、どのように離散的サンプルのディスオクルージョンによるノイズを減らすかがポイントになります。定義上、ディスオクルージョンとは時間的再利用がないことを意味します。品質は空間サンプルにのみ依存し、サンプル数が多いほど直線的に向上する。時間的再利用に匹敵する品質を得るには、数百の空間サンプルが必要であり、限られた予算の中では実現不可能です。

6.4. Target Spatial Sample Count at Disocclusion
重要なのは、ゲームフレームレートにおいて、目立たなくするためにどれくらいの空間サンプルが必要なのか、ということです。これは複雑で、ユーザーの好み、使用できる予算、フレームレート、そしてデノイザーに依存します。フレームレートが非常に低い場合、高速な動きによって大きなディスオクルージョンが発生し、それがかなりの時間残ります。Bitterliら[BWP*20]のプロトタイプも同様の特性を持っています。このような場合、彼らのパラメータは非常に合理的です:それぞれ5つの空間タップを持つ2つの空間再利用パスです。
しかし、60Hzでは、時空間的な再利用がすぐに不鮮明な部分を埋めてしまいます。図11は、5120×1440のレンダリングで、素早く水平方向のストレフィングを行ったものです。時空間再利用だけでは、20フレーム以上にわたって不鮮明さが残っています。1つの空間的サンプルと1つの時間的サンプルを使用すると、有意な変動は3、4フレーム続き、ノイズの上昇の跡が長く続きますが、デノイザーで簡単に修正することができます。1つの空間サンプルと5つの空間サンプルを使用すると、2フレームはノイズが増加しますが、その後はフレーム全体の平均的な分散にほぼ再変換されます。
これは、時空間再利用の指数関数的な増加によるもので、4フレームにわたって1つの空間的・時間的タップを組み合わせると\(2^4\)ピクセルから借用し、5つの空間的タップを使うと\(6^4\)ピクセルから再利用します。どちらの場合も、空間的再利用は有効なテンポラルヒストリーを持つ隣接を見つける可能性があり、品質をさらに向上させます。
様々なシーンで図11と同じようなディスオクルージョンノイズを見たところ、最新のデノイザー[NV120]では、1回の空間タップでほとんどのディスクロージョンノイズに対応できる場合が多いことがわかりました。より高い品質や30Hzのフレームレートをターゲットとする開発者は、2つか3つの時空間的なサンプルを必要とするかもしれません。2つ以上使用する場合、時空間サンプルは、除外された領域だけに適応的に使用されるべきです。これは、これらの計算が品質に実際に影響を与える場所で、追加コストをターゲットにします。

7. Decoupling Shading and Reuse
ReSTIRのもう一つの特徴は、シェーディングと再利用を両立していることです。フレーム\(N\)でシェーディングされたサンプルは、フレーム\(N+1\)をリサンプリングする際にも再利用されます。しかし、シェーディングと再利用の目的は全く異なります。
シェーディングについては、すぐに表示できるように最高の品質を求めます。リサンプリングは、将来のフレームで品質を最適化するためにサンプルを転送する必要があります。両方の目標が同じサンプルで最適化されるとは限りません。実際、シェーディングと再利用を明示的に切り離すことで、現在のフレームのレンダリング品質を向上させる新たな機会が開かれることがわかりました。
どのようにでしょうか?リサンプリングは、より最適な分布に従って、多くのサンプルから1つのサンプルを選んで再利用しシェーディングします。つまり、サンプルを選択的に棄却します(棄却サンプリング)。しかし、なぜシェーディングの前にサンプルを棄却するのでしょうか?なぜ、シェーディングを改善するために、すべてのサンプルを活用しないのでしょうか?デカップリングにより、各フレームで実行するサンプルの異なるサブセットをシェーディングとリサンプリングすることができます。
7.1. What Samples Are Examined?
図12は、セクション6の後に、よりシンプルなReSTIRパイプラインを示したものです。\(M\)個の候補がある場合、各ピクセルはちょうど\(M+2\)個のライトサンプルに触れます。複数のリサンプリングステップの後、\(M+1\)は破棄され、1つのサンプルだけがシェーディングされ、将来のフレームで再利用されます。
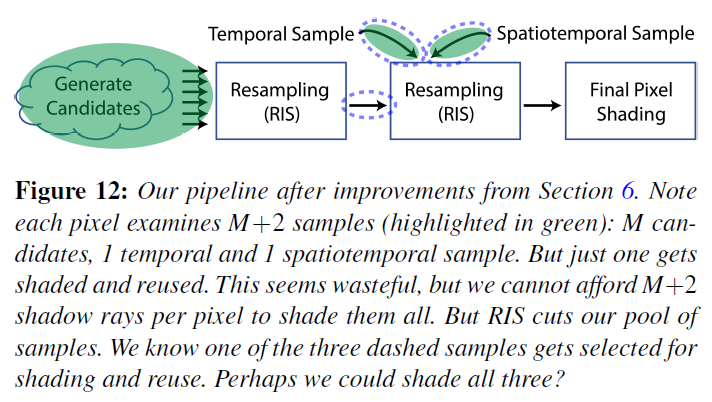
\(M+2\)サンプルすべてをシェードせず、1つだけテンポラルに再利用するのはどうでしょうか?問題はシャドウレイです。\(M+2\)個のサンプルをシェーディングするに<\(M+2\)本のシャドウレイが必要であり、セクション6.1では5本でも多すぎると断言しています。
しかし、ReSTIRの反復性により、サンプルを複数の方法でグループ化することができます。ピクセル単位の候補はリサンプリングされ、2回目のリサンプリングには3つの入力が残ります。ReSTIRは、この3つのサンプルの中から1つを選び、シェーディングと再利用を行います。
3つとも遮光しないのはなぜでしょうか?この場合、1ピクセルあたり2本ではなく3本と、より多くのシャドウレイが必要になります。しかし、シェードされるサンプル数が3倍になり、画質が向上します。これは良いトレードオフかもしれません。
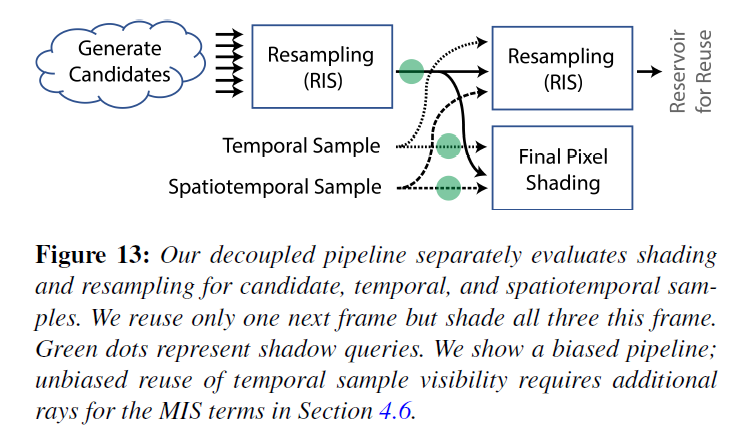
図13は、分離されたReSTIRパイプラインを示します。シェーディングパスの3つの入力は、それぞれシャドウレイをトレースしています。複数の時空間タップを使用する場合、最初にシェーディングに渡す1つだけを選択して再利用することができます(候補に使用する追加のRISステップのように)。
時空間サンプルの可視性を再利用すると、複合バイアス(セクション4.1)が発生するか、不偏性を保つために多重点散乱(セクション4.6)のためにシャドウレイを追加する必要があるので、シャドウレイ候補だけを転送することに注意してください。
シェーディングの際、3つのサンプルの寄与をリサンプリングに使用した確率で重み付けします。あるサンプルが95%の確率で再利用される場合、そのサンプルはピクセルカラーの95%に寄与します。これにより、フレームごとに追加される新しい低確率の候補によるノイズが多くなることを回避しています。図13ではシェーディングと再利用が論理的に分離して描かれていますが、私たちはこれらを単一のカーネルで同時に実行しています。
7.2. Reusing Visibility in Resampling
この分離型シェーディングパイプラインでは、重要な変更点として、ビジビリティレイがパイプラインステージではなく、明示的なサンプルに結び付けられるようになりました。これにより、サンプルに関する推論が可能になり、ピクセル内で重複したシャドウクエリが発生する可能性を回避できます。
図13は、シャドーレイを明示的に撹拌することで、ReSTIRにおける視認性の再利用を明確にしています。もし(時空間)サンプルの可視性がリサンプリングにパイプされると、将来のフレームの\({\hat p}\)に潜在的なゼロが導入されます(すなわち、セクション4.2のダーケニングバイアスです)。これは、式33の重みを介して、除去するための追加のレイを必要とします。
図15は、さまざまなタイプのバイアスドな視認性の再利用を示したものです。視認性のバイアスを取り除くMISの重みを計算するために、より多くのレイを発射することなく、図13のパイプラインが最適であることがわかりました。このパイプラインは,選択されたピクセル単位の候補に対して視認性をバイアスドに再利用し,これにより著しい品質向上が得られるからです(例えば,図15f対15b).他のシャドウレイはシェーディングにしか影響しませんが,これらのクエリは局所的なコンタクトシャドウにとって重要です(例えば,図15f対15c)。

7.3. Cheaper Visibility Reuse
悲しいことに,図13のパイプラインでは,セクション6.4で提案した2本のレイではなく,1ピクセルあたり3本のレイが必要です.しかし、可視性クエリが特定のサンプルに直接対応することで、可視性を決定するための安価な代替手段を検討することができます(図14参照)。
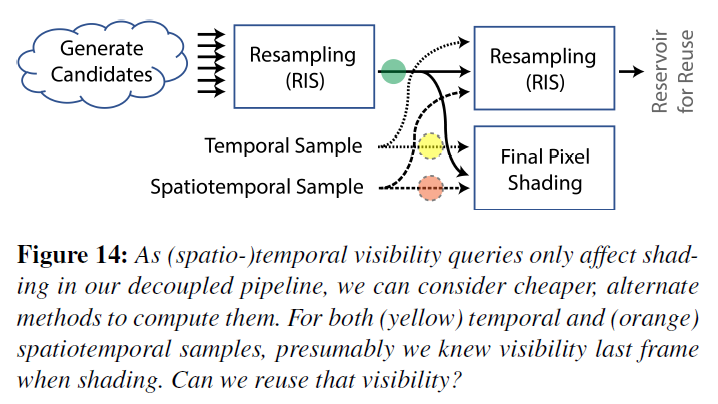
例えば、フレームはレンダリングのシーケンスから生まれます。リサンプリングの一環として可視性を再利用することはありませんが、以前はテンポラルサンプルをシェードするために可視性を計算しました。この可視性を再利用して、再度シェーディングを行うのはどうでしょうか?
今回のサンプル(図14の黄色い点)では、シーンアニメーションを変更しても、視認性は変わりません;再利用することで、1本のシャドウレイを簡単に消すことができます。アニメーションの下では、この可視性を再利用すると、ピクセルごとにシェーディングされた3つのサンプルのうちの1つに1フレームのシャドウラグが追加されます。しかし、このラグを知覚することができなかったので、ここで紹介します。
時空間サンプル(図14のオレンジの点)に対する同様の再利用は、それほど簡単ではありません。明らかに、現在のピクセルとその近傍のピクセルの間で視認性が異なる場合があるため、再利用によってさらにバイアスがかかります。このバイアスはどのように現れるのでしょうか?静止画像の場合、時空間視認性(オレンジのドット)を1にハードコーディングすると、図15cのような結果になります。レイを追跡すると、図15fのような結果になります。
このことから、時空間ビジビリティレイをスキップすると、品質が著しく低下することがわかります;しかし、レイをトレースする回数を減らすことができるのではないでしょうか?例えば、現在のピクセルから離れたところにある近傍ピクセルほど、その視認性が変化しやすいです。そこで、ユーザーが定義した閾値以内の近傍の視認性を再利用することができるかもしれません。
図16に、このパラメータの効果を示します。近傍からリサンプリングする場合は時空間視認性を再利用し、より遠方の近傍では従来通りビジビリティレイを発射しています。このように、品質と性能をトレードするためのパラメータが用意されています。ReSTIRでは近傍選択がランダムであるため、このパラメータは終点(すなわち、可視性を再利用しない場合と常に再利用する場合)の間で確率的に補間されます。

要約すると、我々の分離型シェーディングパイプラインは、図14の可視性クエリを計算するための柔軟性を提供します。我々は常に候補となるレイをトレースし(緑のドット)、時間的サンプルに対して常に可視性を再利用し(黄色のドット)、時空的サンプルに対して再利用をパラメータ化する(オレンジのドット)。これにより、希望する品質に応じて、ピクセルあたり1本から2本の光線をトレースすることで、ReSTIRベースのライティングが可能になります。
8. Results
私たちの実験的なプロトタイプはFalcor[BYC*20]を使用していますが、私たちのReSTIRライティングとサンプリングは、他の様々なレンダラーに組み込みされています。詳細な性能の数値や比較は、プロトタイプから得られたもので、私たちは慎重に計測し、パラメータスイープを行い、設定を検証するためのコントロールを持っています。Intel Core i7-5820を搭載したデスクトップのGeForce RTX 3090と、Intel Core i7-8750Hを搭載したラップトップのGeForce RTX 2080 Max-Qでプロファイルを作成しました。
よく文書化された模範的な実装のソースコードは、NVIDIAの無償RTXDIライブラリ[NV121]の一部として利用可能です。
8.1. Implementation Details
私たちは、プロトタイプのパフォーマンスプロファイルを作成するために大量の計測器を用意しました。その結果、3つのカーネルを実装することになりました。第1に、ピクセル単位の候補を選択してリサンプリングします。第2に、選択した候補と時空間サンプルに対してシャドウレイを発射します。第3に、次のフレームに対して(分離)シェーディングとリサンプリングを実行します。
フレーム内依存性がないため、これらを1つのメガカーネルに融合させることができます。しかし、融合によるカーネル間通信の減少は、単一の複雑なカーネル内でレイトレーシングと計算を混在させることによるレジスタ使用量の増加や発散によって相殺されることがわかりました。しかし、将来のAPIやハードウェアの改良に伴い、この決定を見直すことで、コンマ数ミリ秒を節約できる可能性があり、よりシンプルなシーンでは大きな改善となります。
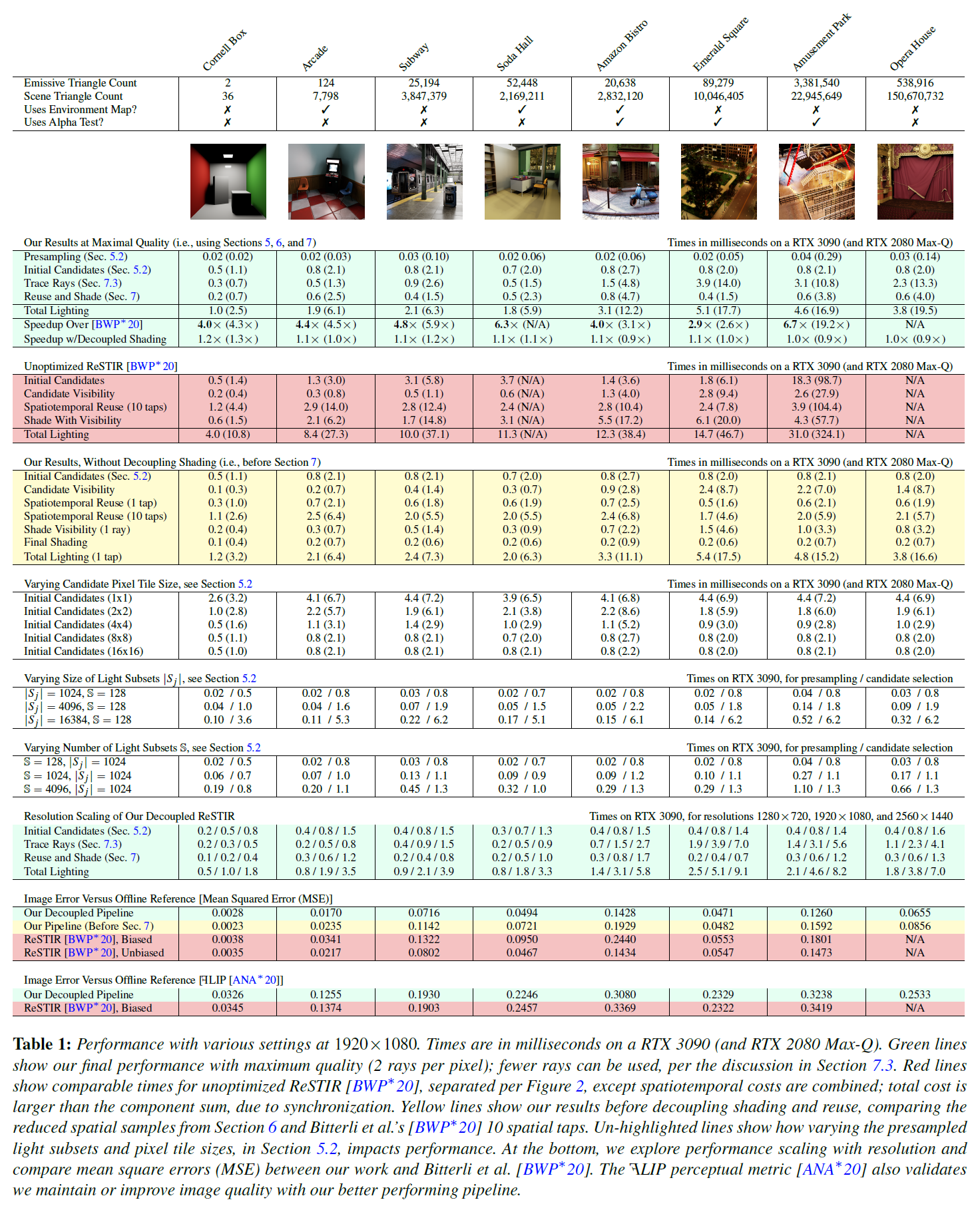
表1(その他)のシーンは、特に断りのない限り、すべて同じ設定になっています。これは、1ピクセルあたり\(M=32\)の候補、1つのテンポラルサンプルと1つの時空間的サンプル、1ピクセルあたり2つのビジビリティレイ、\({\mathbb S}=128\)、\(|S_j|=1024\)、初期候補の\(8 \times 8\)ピクセルタイルを含みます。Bitterliら[BWP*20]との比較では、彼らの論文のパラメータを、やはり全シーンで一律に使用しています。
ここでは重視しませんが、ノイズ除去にはNVIDIAのNRDライブラリ [NVI20] のReLAX [KC21] を使用しています。これは、spatiomteporal variance-guided denoiser [SKW*17, SPD18] からインスピレーションを得ながら、鏡面反射のノイズ除去、ファイアフライ抑制、時間的安定性、堅牢なディスオクルージョン処理、およびスピードを改善します。
8.2. Performance
表1は、コーネルボックスから1億5千万三角形のパリ・オペラ座まで、様々なシーンにおいて、我々の最適化とベースラインReSTIR [BWP*20]を比較した詳細なパフォーマンス測定値をまとめたものです。私たちのシーンには、最大340万個のエミッシブ三角形が含まれ、一部はテクスチャリングされています。我々のプロトタイプは、エミッシブ三角形と環境マップの2つのライトタイプを許容しますが、他のエンジン組み込みは、セクション5.3に従って、解析的なライトプリミティブ(図1参照)をサポートする。
なお、表1では、ReSTIR固有のライティングコストのみを評価しています。Gバッファの生成、トーンマッピング、デノイジング、その他のポストプロセスパスは含んでいません。Gバッファは数ミリ秒、デノイザーはRTX 3090の1920 x 1080で1.8ミリ秒で実行されます。
主な結果:我々の最適化されたReSTIRパイプラインは、レイトレーシングによって制限されない限り、Bitterliら[BWP*20]より4倍以上高速です(例:Emerald Square)。以前は候補選択時にインコヒーレントなメモリが支配的だったシーンでは、我々のパイプラインは最大で7倍速く動作します。シーンの複雑さやデバイスの制限によってメモリが制約される場合、我々の分離型パイプラインは最大20倍高速に動作します。すべてのシーンがラップトップ上でインタラクティブに実行されるようになりました。
重要なのは、シェーディングを分離する前の結果(表1の黄色い線)と最適化されていないReSTIR(赤い線)を比較することです。特に複雑なシーンでは、すべてのコストが減少していることがわかります。これは、メモリコヒーレンスの改善による効果が継続しているためです。候補選択後にキャッシュがスラッシュされることはなく、選択されたサンプルはおそらく近傍のサンプルである。また、ライティングの複雑さが増すと、「再利用とシェード」コストが上昇します(多くのエミッシブまたは環境マップを持つシーン)。
私たちが開発したReSTIRでは、画面の解像度やライトプールの数・サイズ(\({\mathbb S}\)と\(|S_j|\))など、ほとんどの重要なパラメータで性能がリニアに変化します。候補者選択コストは、ライトプールのパラメータ\({\mathbb S}\)と\(|S_j|\)を変更すると非線形に変化しますが、これはこれらの値がキャッシュ動作に影響するからです。一般に,ライトプールのサイズ \(|S_j|\) を大きくすると,コヒーレンスに対する影響が大きくなります.より大きなプールはより多くのキャッシュラインを使用し,ワープ間のメモリ競合を増加させます。
Bitterliら[BWP*20]と同様に、良い品質のためにコストが妥当であるとして、シーン全体で\(M=32\)の候補を使用しました。ReSTIRは有効サンプル数を指数関数的に増加させ、これは一般的に\(M\)による線形増加よりも優先されます。しかし、\(M\)を小さくすることで、シーンごとに設定を調整することを厭わないユーザーにとっては、より単純なシーン(例えば、コーネルボックスは\(M=1\)でも同じように見える)において、性能の向上が期待できます。
この新しい分離型パイプラインは、ほぼ同等の性能を維持しながら、後述するように品質を向上させます。RTX 3090では、シェーディングを切り離すことで常にコストが削減されますが、これは主に、起動オーバーヘッドと中間バッファが少ないカーネルを使用するためです。しかし,分離シェーディングは,レイをピクセルごとに同じサンプルに2回トレースしないので,低速のハードウェアではレイトレーシングのコストが増加する可能性があります。
8.3. Image Quality of Decoupled Shading
大幅な性能向上を実現する一方で、画質が低下しないことを確認する必要があります。
図17は、シェーディングと再利用を分離する前と後(すなわち、セクション7を使用する場合と使用しない場合)の品質を比較するために、シーンの興味深い領域をズームアップしています。つまり、唯一の違いは、分離型パイプラインが1ピクセルあたり1サンプルではなく、3サンプルをシェーディングしていることです。特にシャドウの品質が向上します。これは、分離型シェーディングにより、ライティングに貢献できる3つのサンプルが得られるためです。これにより、ライティングがゼロの黒いピクセルの数を減らすことができます。

一般的に、分離型再利用は知覚品質と画像メトリクスを向上させます。しかし、図17は、ReSTIRがうまく収束する影のない領域では、分離型シェーディングはわずかにノイズを増加させる可能性があることを示します。これはコーネルボックスにも現れています(表1のエラーメトリクスを参照)。問題は、品質が大きく異なる1ピクセルあたり3つのライトサンプルのシェーディングです。具体的には、候補となるライトサンプルは\(M=32\)、収束した(空間的)テンポラルサンプルは有効な\(M\)が数千になります。MISウェイトを使用して色をブレンドすると、この問題は軽減されますが、完全に除去されるわけではありません。
サンプルのうち2つだけを選択的にシェーディングすることで、常に品質を向上させる分離型パイプラインを設計できる可能性がありますが、これについては調査しませんでした。我々のデノイザーは、うまく収束した領域でわずかに増加したノイズを簡単に処理します。重要な問題は、サンプリングが不十分な領域でのノイズを減らすことであり、これは分離型シェーディングによって実現されます。
8.4. Quality Impact of Reduced Sampling Frequency
セクション6では、空間的、時間的、視認性のサンプリングの方法を大幅に変更しました。意外なことに、この変更により画質が向上することが多いです。主な画質低下は視認性クエリの減少ですが、図9に示すように、最終的なシェーディングのために4本のビジビリティレイをトレースすることは、多くの作業を無駄にすることになります。実際、これらの領域では、分離型シェーディングの方がより優れたノイズ低減を実現しています(表1参照)。
図18は、再利用に使用する空間サンプルの数を変化させた場合の品質を比較したものです。Bitterliら[BWP*20]は、それぞれ5タップで2つの空間反復を使用しており、図18に示す最も高いMSEを実現しています。空間サンプルは、単に現在のピクセルを推定するだけで、(有効な)時間的推定よりも悪いです。図11によると、空間サンプルは不連続面(または他の時間的不連続面)のノイズを素早く減らすのに役立ちますが、他の場所では品質を悪化させることがあります。
バイアスドなReSTIRの場合、誤差の増大の一部は、各空間サンプルによってもたらされる追加のバイアスに起因します。しかし、バイアスのかかっていないReSTIRのMSEを測定すると、大きさは小さいものの、同様の誤差の増加が見られます(すなわち、空間サンプル数が1つから5つに増えるにつれて、0.0770から0.0829になります)。
このことから、空間サンプルは有効サンプル数\(M\)の指数関数的な増加を可能にし、したがってReSTIRには不可欠であるという、やや矛盾した結論が導かれます。また、空間サンプルは、時間サンプルが無効化されたときに、不連続性を埋めるのに役立ちます。しかし、空間サンプルの使用量が多すぎると、誤差が大きくなります。ディスオクルージョンされた領域だけ空間サンプル数を適応的に変更することで、再利用の増加を注意深く狙うことができます。

8.5. Quality Impact of Prerandomized Light Samples
1ピクセルあたり32個の独立したライトサンプル(\(1920 \times 1080\)の画像では6400万個の独立したサンプル)を、フレームごとに1回独立にランダム化された少数の、より小さなサブセットに置き換えることを提案しています。我々は経験的に\(|S_j|=1024\)の大きさの\({\mathbb S}=128\)の部分集合を選びました。もちろん、この削減により、図7と表1に示す性能向上の多くが可能になります。
サンプルサイズを小さくすると、明らかに相関が生じます。しかし、ReSTIRは基本的に相関性のあるサンプリングを利用して画質を向上させるものであることを忘れてはいけません。私たちは、相関を利用してコストを削減することを提案しているだけです。
図19は、異なるサイズのスクリーンタイルを使用して、初期候補を直接(再利用前に)照明した場合の相関を示しています。タイル内の各ピクセルは、\(|S_j|=1024\)個のライトサンプルの同じプールから32個の独立したサンプルを選びます。相関は\(8 \times 8\)以上のタイルで明らかに発生し、アニメーションではより顕著になります。

ReSTIRは、ピクセルがより大きな30ピクセルの近傍から時空間的にサンプリングするため、\(8 \times 8\)タイル内の限られた相関を処理します。これらのサンプルは、フレームごとに再ランダム化されるため、異なるライトプールからのものです;これにより、シェーディングと再利用の前に近傍を非相関化することができます。
また、あまり目立ちませんが、あらかじめランダム化されたライトセットにも問題があります。異なるスクリーンタイルが同じライトプールを使用します。このため、画像の離れた部分に相関があります。しかし、これは相関関係が目に見える場合や、リサンプリング品質に影響を与える場合にのみ問題となります。幸い、これらの相関は、妥当な大きさの\({\mathbb S}\)と\(|S_j|\)では知覚できません(ですが,\({\mathbb S}=4\)と\(|S_j|=32\)では明らかになります)。
また、時空間的な近傍関係を限られた領域から抽出するため、長距離の相関関係はReSTIRに影響を与えません。近傍にあるサンプルが比較的無相関であればよいのです。半径30ピクセルの近傍には、ピクセルが\(M=32\)個の候補を使用する場合、\(30 \times 30 \times \pi \times 32 \approx 90,000\)個のサンプルが含まれます。そして、この30ピクセルのフィルタは、\(8 \times 8\)ピクセルのタイルの45-50個に触れることになります。このことから、経験的に決定された\({\mathbb S}\)と\(|S_j|\)は妥当であり、ReSTIRの30ピクセルの検索半径の中で、おそらく4万個の独立したサンプルが得られると思われます。これは、独立したサンプリングに必要な9万個に近い値です。興味深いことに、このロジックはシーンの複雑さとは無関係です。
9. Discussion
上記のような品質や性能の問題だけでなく、我々の探求は様々な興味深い見解を浮き彫りにしました。
Numerical precision. 加重レゼバーサンプリングで多数のフレームに渡ってサンプルを合計すると、壊滅的なキャンセルによる問題が発生する可能性があるようです。幸いなことに、各ピクセルは32+2個の値を合計するだけで、我々の候補と1つの時空間サンプルと1つの時空間サンプルを合計します。レゼバーは、Bitterliらの[BWP*20]により、\(M\)を現在のレゼバーの\(M\)の\(20 \times\)にクランプすることで、フレーム間で再正規化(すなわち、合計が平均になる)されています。
Ray coherence. ピクセル単位の候補のシャドウレイは、設計上、極めてインコヒーレントです。しかし、リサンプリング処理によって、選択したサンプルの相関性が高まり、その結果、よりコヒーレントなものになるのです。表1の黄色くハイライトされた行をご覧ください。ここでは、1つのシェードビジビリティレイが1つの候補ビジビリティレイより大幅に安くなっています。このことは、分離型パイプラインの相対的な性能に影響すると思われ、コヒーレンスの改善による恩恵はやや少ないです。
Expensive materials. ReSTIRでは、再利用時にターゲット関数\({\hat p}_i\)を計算するために、ピクセルごとに複数回マテリアルを評価します。複雑なレイヤーやプロシージャルなマテリアルモデルを持つレンダラーに統合する場合、これは心配なことかもしれません。もしマテリアルがピクセルごとに1回評価され、遅延シェーディングのためにGバッファにベイクされるなら、ReSTIRはこのGバッファデータを単純に消費します。あるいは、ターゲット関数\({\hat p}_i\)は、ノイズの増加という代償を払って、簡素化されたマテリアルモデルを使用することができます。
Alternate forms of visibility. セクション7.3では,各サンプルの視認性を正確に知ることなく,もっともらしい結果が得られることを示し,品質をパラメータ化する簡単なノブを提案します。また,スクリーン空間レイトレーシング[MM14]やスクリーン空間方向性オクルージョン[RGS09]など,他の高速な視認性近似を使用することも考えられます。このような使用は、おそらくその制限を継承しますが、分離型パイプラインでは、シェーディング時にのみ適用することになります。
Scaling performance lower. 性能や品質を調整するために導入したノブも、今日の低価格帯のハードウェアでは不十分な場合があります。我々のパイプラインは、チェッカーボードレンダリング[Wih17]や同様の手法とうまく連携しています。
MIS and BRDF rays. ソースpdf \(q(\omega)\)はライトをサンプルするだけでなく,BRDFレイも含むことが可能です。BRDFレイとReSTIRの結果を組み合わせないことをお勧めします。これは、BRDFレイが再利用によって近くのピクセルに与える可能性のある利益を無視することになります。さらに、ReSTIRは何千ものサンプルを組み合わせますが、BRDFサンプリングはほんの数個のサンプルしか提供しません。再利用が発生した後に適切な重み付けを決定することは、より困難です。
10. Limitations
ReSTIRの制限の根底には、完全鏡面マテリアル、アンダーサンプリング、相関の3つの重要な問題があります。
完璧なスペキュラサーフェスの場合、リフレクションレイを発射することで簡単に正しいライティングが計算できます。鏡面に近い表面では、BRDFサンプリングはReSTIRよりも性能が良く、主に狭いスペキュラーローブが有用な近傍の集合を根本的に制限するためです。このため、これらのマテリアルでは再利用の利点が制限されます。
ReSTIRは、限られたサンプリング予算を倍増させるものですが、制限もあります。図20は、20万個以上の発光する、主に小さなトーチがある非常に大きなMinecraftの世界を示しています。これらのトーチの範囲は比較的限られているため、ピクセルは近くにある重要なトーチを1つだけ見つける必要があります。1ピクセルあたり32個の候補があり、有効なM値がおそらく1万であるため、小さな発光体を毎フレームサンプリングするには不十分である。このため、トーチライトは時間的にちらつくことになります。
相関サンプリングは、ReSTIRの動力ですが、同時に問題点もあります。基本的に、ReSTIRは重要なサンプルを特定し、それを保持し、近くのピクセルに対して重み付けをし直します。重要なサンプルが少なすぎると、すべてのピクセルが同じサンプルを再利用することになり、VPLのようなにじみのあるアーティファクトが発生します。ReSTIRは、過去の多くのフレームから再利用することで、一般的に良いサンプルを見つけることができます。しかし、にじみは、スペキュラーサーフェイス連動して悪化するかアンダーサンプリングとなります。つまり、高いスペキュラーサーフェイスや、大きく照らされたシーンのまばらな照明領域でより顕著に現れます。
11. Conclusion
多光源シーンにおける直接照明の時空間リサンプリングの性能と品質を飛躍的に向上させるための、数々のアルゴリズムの改良を発表しました。リサンプリングを利用して計算を再形成することで、内側のレンダリングループから多くの非干渉的なメモリアクセスを取り除くことができることを示しました。また、シェーディングとサンプルの再利用を切り離すことで、無視できるコストでシェーディングの品質を向上させる、棄却された処理を特定しました。また、ReSTIRのパラメータ空間を経験的に探索し、空間サンプリングが当初想像していたよりも有用でないことを発見しました;これにより、驚くほど遥かに画質を落とすことなく、品質設定を断ることができるようになりました。
これらの組み合わせにより、画質の向上と最大7倍の性能向上を実現し、メモリに制約のある低性能のハードウェアで複雑なシーンを撮影する場合には、さらに大きな効果を発揮します。また、新しいパフォーマンスノブを公開し、コンタクトシャドウをより明確にする代わりにレイのコストを縮小することができます。
今回の改良を踏まえ、より複雑なリアルタイム輸送、例えばグローバルイルミネーション[OLK*21]での品質向上のために相関を活用したReSTIRベースのサンプリング技術が今後も開発されることを期待します。
Acknowledgements
和訳省略
References
