こんにちわ,Pocolです。
今日は,
[Talbot 2005] Justin F. Talbot, Davit Cline, Parris Egbert, “Importance Resampling for Global Illumination”, EGSR’05, pp.139-146, 2005.
を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けると有難いです。
Abstract
本論文では、インポータンスリサンプリングをモンテカルロ積分の分散削減技法に発展させます。インポータンスリサンプリングは、重点サンプリングのために、より均等に重み付けされたサンプルを生成するために使用することができるサンプル生成技術です。これにより、一般的なレンダリング問題において、標準的な重点サンプリングよりも大幅に分散を削減することができます。最適に近い分散削減のためにインポータンスリサンプリングのパラメータを選択する方法を紹介します。一般的なグローバルイルミネーション問題でこの技術の堅牢性を実証し、直接照明の標準的な重点サンプリングと比較して10%~70%の分散削減を達成することができました。我々は、安価なサンプリング法を用いれば、さらなる分散削減が可能であると結論付けました。
1. Introduction
グローバルイルミネーションの目的は、仮想的なシーンの記述から物理的にリアルな画像を作成することです。Kajiya [Kaj86]は、この難問を再帰積分として初めて表現し、「レンダリング方程式」と名づけました。最近では、Veach [Vea97]がこの方程式を光路上の非再帰的積分として再定義しました。
これらの積分は一般的に解析的に解くことができないため、モンテカルロ積分[MU49]を用いて近似するのが一般的です。モンテカルロ積分は確率的な処理であり、レンダリング画像にノイズとして現れる分散の影響を受けます。この問題に対処するために、多くの分散低減技術が開発されています。グローバルイルミネーションで最も一般的なものの1つが重点サンプリングです。
重点サンプリングとは、モンテカルロ積分においてサンプリング分布を慎重に選択する一般的な手法のことです。確率密度関数(pdf)が積分対象の関数に比例するほど、モンテカルロ推定値の分散が小さくなることを示すことができます。
重点サンプリングを使うには、pdfで定義された分布を持つサンプルを生成できることが必要です。これらのサンプルを生成するために使用される2つの一般的な技術は、累積密度関数(CDF)逆変換法と棄却サンプリングです。最近、第3の手法であるメトロポリスサンプリングが研究されています。本論文では、4番目の手法であるインポータンスリサンプリングを使用します。
インポータンスリサンプリングは、他の手法と異なり、目的のpdfに従って近似的に分布しているだけのサンプルを生成します。したがって、不偏性を保つためにさらなる注意が必要です。重点サンプリングのためのサンプルを生成するためにインポータンスリサンプリングを使用すると、私たちがResampled Importance Sampling (RIS)と呼ぶ分散削減技術が生成されます。標準的な重点サンプリングはRISの特殊なケースです。RISは標準的な重点サンプリングよりも頑健であり、分散を大幅に削減することができます。
まず、セクション 2 で先行研究を説明します。セクション3では、インポータンスリサンプリングについて説明します。次に、一般的なRIS推定を開発し、セクション4でその数学的特性について議論します。推定値の分散を分析し、最適に近い分散削減を達成するためにロバストリサンプリングパラメータを選択します。セクション5では、グローバルイルミネーションにおけるRISを用いたいくつかのケーススタディを紹介します。インポータンスリサンプリングにより、モンテカルロ大域照明アルゴリズムの分散を減らし、頑健性を高めることができることを示します。結論として、セクション6でRISの将来的な改良の可能性について議論します。
2. Background
重点サンプリングは、グローバルイルミネーションで見られる多くの問題に対して非常に効果的な分散削減手法です。この手法では、確率密度関数からサンプルを生成する必要があります。これらのサンプルは、CDF逆変換法、棄却サンプリング、メトロポリスサンプリング、またはインポータンスリサンプリングによって生成することができます。
CDF逆変換法は最も一般的なサンプリング手法です。可能であれば、pdfの正確なサンプリングが可能であり、分散を最大限に削減することができます。しかし,pdfを積分してCDFを逆変換させることができることが必要です.積分関数にほぼ比例し、かつCDF逆変換法が容易なpdfを見つけることは、非常に難しい問題です。グローバルイルミネーションにおけるいくつかの特殊なケースでは、逆変換可能なpdfが見つかっています。例えば,球面光源 [SWZ96] や任意のポリゴン [Arv95] からの直接照明をサンプリングするための分布や,Phong [LW94] や Ward [War92] 双方向反射率分布関数 (BRDFs) をサンプリングするための分布が開発されています.最近の研究では,環境マップのサンプリングに適したpdfを見つけることに焦点が当てられています [ARBJ03, KK03]。
棄却サンプリングは、CDFを求めたり逆変換させたりすることなく、サンプルを作成することができます。しかし、棄却サンプリングは層別サンプリングができないこと、サンプルを生成するための固定された時間的制約がないことから、しばしば避けられます。また、棄却サンプリングでは境界関数を求める必要があり、これが困難な場合もあります。
メトロポリスサンプリング[MU49]は、目的のサンプリング分布と等しい定常分布を持つマルコフ連鎖を生成します。メトロポリス・サンプリングの利点は、その一般性です。最も複雑な分布からもサンプルを生成することができます。しかし、不偏のサンプルが必要な場合、メトロポリス・サンプリングには大きなスタートアップ・コストがかかります。さらに、分散を減らすために必要な効率的な遷移関数を見つけることは、ドメイン固有であり、困難である可能性があります。メトロポリスサンプリングは、Veach と Guibas [VG97]によってグローバルイルミネーションで初めて使用されました。
インポータンスリサンプリングは、グローバルイルミネーションの文献で非公式に使用されています。Lafortuneら[LW95]は、双方向パストレーシングで必要な視認性テストの回数を減らすためにインポータンスリサンプリングを使用しました。Shirleyら[SWZ96]は、直接照明の計算を改善するために再サンプリングを使うことを提案しました。Burke [Bur04]は,PhongのBRDFモデルと照明環境マップの積の分布をサンプリングするためにインポータンスリサンプリングを使用しました。
その他、グローバルイルミネーション問題に対して重点サンプリングを一般化する試みも行われています。Veach [Vea97] によって開発された多重点サンプリング (MIS) は、慎重な重み付けによって複数のサンプリング分布を使用することができます。Weighted Importance Sampling [BSW00]は、RISと同様に、モンテカルロ推定値の分散を減らすために2つのpdfを使用します。しかし、重み付け重点サンプリングは一貫性があり、不偏ではなく、さらに分散を減らすために計算努力を最適化することができません。Combined Correlated and Importance Sampling [SSSK04]は、2つの分散削減技術を擬似的に最適に組み合わせて使用します。これは、積分関数の閉形式近似を計算する必要があり、一般性を制限しています。
3. Importance Resampling
インポータンスリサンプリングは、困難な分布からサンプルを生成するための計算統計学の一般的な方法です。逐次重点サンプリングやパーティクルフィルタリングでよく使われます[DdFG00].また、ベイズの事後分布からサンプルを生成するのにも使われます[GCSR04]。
インポータンスリサンプリングはRubin [Rub87]によって初めて記述されました。ここでは,インポータンスリサンプリングについて簡単に説明し、なぜそれが機能するのかについて直感的な説明を試みます。
pdfが\(g\)のサンプリング分布からサンプルを生成したいが,\(g\)が解析的な閉形式を持たないか,積分や逆変換を行うには複雑すぎるため,直接(例えばCDF逆変換法を用いて)それを行うことができないと仮定します。その代わりに,ある分布\(p\)からサンプルの集合を生成し,これらのサンプルに適切な重み付けを行い,その重み付けに比例した確率でサンプルから1つのサンプルを抽出して,サンプルを再サンプルすることができます。
インポータンスリサンプリング:
1. 入力分布\(p\)から\(M\)個のサンプル(\(M \geq 1\))を生成し、\({\mathbf X} = \langle X_1, \cdots, X_M \rangle\)とする。
2. 各サンプルに対して重み\(w_j\)を計算する。
3. \({\mathbf X}\)から、\(\langle w_1, \cdots, w_M \rangle \)に比例した確率で、1つのサンプル\(Y\)を引く。
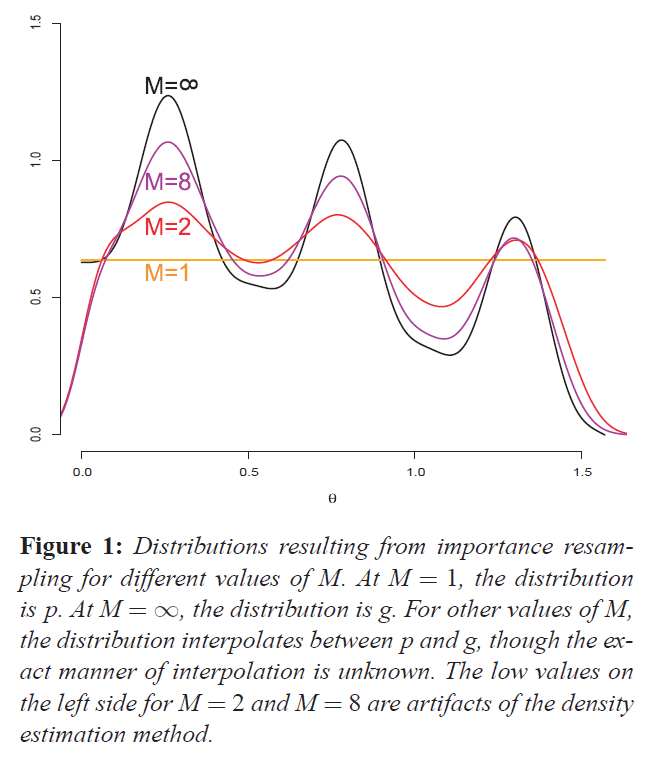
もし\(w_j = \frac{g(X_j)}{p(X_j)}\)を選ぶと、結果のサンプル\(Y\)は\(g\)に近似した分布になります。再サンプリングステップの効果は、入力の密度\(p\)からサンプルを取り、それらを「フィルタリング」することで、結果のサンプル\(Y\)が\(g\)に近似した分布になるようにすることです。
サンプル数である\(M\)を分布補間変数として捉えることができる。\(M=1\)のとき、\(Y\)は\(p\)に従って分布し、\(M \rightarrow \infty\)となるにつれて、\(Y\)の分布は\(g\)に近づいていきます。一般的に、有限の\(M\)の近似によってもたらされるバイアスを無視できるようにするためには、\(M\)を非常に大きくする必要があります。
例として、図1は、\(p\)が一様で\(g \propto \cos(\theta) + \sin^4 (6\theta)\)のとき、\(M\)のさまざまな値に対する\(Y\)の分布を示します。
4. Resampled Importance Sampling
インポータンスリサンプリングと重点サンプリングを組み合わせることで、リサンプルドインポータンスサンプリング(RIS)と呼ばれる分散削減技術が生まれます。
関数\(f(x)\)の積分値\(I\)を求めるとします:
\begin{eqnarray}
I = \int_{\Omega} f(x) d\mu (x)
\end{eqnarray}
また、2つの確率密度関数を用意しました。サンプリングpdfである\(p\)は、容易にサンプリングできるが、\(f\)の近似が悪い可能性があります。サンプリングpdfである\(g\)は、\(f\)の近似が良いが、正規化されておらずサンプリングが困難かもしれません。標準的な重点サンプリングでは、\(p\)のみを使用するように制限されています。重点サンプリングを一般化し、\(g\)も使用して推定値を向上させたいと思います。RISでは、インポータンスリサンプリングを用いて\(g\)から近似的にサンプルを抽出することで、不偏的な方法で\(g\)を使用することができます。
インポータンスリサンプリング処理によるサンプル\({\mathbf X}\)、\(Y\)が与えられたとき、重み付け重点サンプリングの一形態としてRIS推定器を開発します:
\begin{eqnarray}
{\hat I}_{ris} = \frac{1}{N} \sum_{i=1}^N w({\mathbf X}_i, Y_i) \frac{f(Y_i)}{g(Y_i)}
\end{eqnarray}
重み付け関数\(w\)は、\(g\)が正規化されていないという事実と、\(Y\)の密度が\(g\)に近似しているという事実の両方を補正するために選択されなければなりません。それは、再サンプリングステップで計算された重みの平均です:
\begin{eqnarray}
w({\mathbf X}_i Y_i) = \frac{1}{M} \sum_{j=1}^M w_{ij}
\end{eqnarray}
この2つの式を組み合わせることで、RISの推定値が得られます:
\begin{eqnarray}
{\hat I}_{ris} = \frac{1}{N} \sum_{i=1}^N \left( \frac{f(Y_i)}{g(Y_i)} \cdot \frac{1}{M} \sum_{j=1}^M \frac{g(X_{ij})}{p(X_{ij})} \right) \tag{1}
\end{eqnarray}
\(M=1\)のとき、RISは標準的な重点度サンプリングに還元されます。
RISの推定値が不偏であるためには、2つの条件が成立する必要があります。まず、\(g\)と\(p\)は\(f\)が非ゼロである限り、どこでもゼロより大きくなければならない[Tal05]。第二に、\(M\)と\(N\)はゼロより大きくなければなりません。
4.1. Variance Analysis
RIS推定器は不偏であるため、推定値の誤差は分散によるものだけです:
\begin{eqnarray}
V({\hat I}_{ris}) = \frac{1}{N} \left[ \frac{1}{M} (e_3 – e_2) + (e_2 – e_1) \right] \tag{2}
\end{eqnarray}
ここで,
\begin{eqnarray}
e_1 &=& E \left( \frac{f}{p} \right)^2 \\
e_2 &=& E \left( \frac{f^2}{gp} \right) E \left( \frac{g}{p} \right)
\end{eqnarray}
そして,
\begin{eqnarray}
e_3 = E \left( \frac{f^2}{p^2} \right)
\end{eqnarray}
この式の導出は、Talbot [Tal05]によって与えられています。
グローバルイルミネーションでは、\(f\)の範囲は通常n成分のスペクトル値であるため、分散はn成分のベクトルとなることに注意してください。
式(2)は、標準的な重点サンプリングの分散と比較することで最もよく理解できます:
\begin{eqnarray}
V({\hat I}_{ris}) = \frac{1}{N}( e_3 – e_1)
\end{eqnarray}
標準的な重点サンプリングの分散は、ベクトル \(e_3 – e_1\) です。より多くのサンプルを取ることは、このベクトルを逆スケールします(つまり、分散を減少させます)。
RISはこのベクトルを、\(e_2 – e_1\)と\(e_3 – e_2\)の2つのベクトルの和に分割します(図2参照)。ベクトルの相対的な長さは対象分布\(g\)に依存し、\(g \propto p\)の場合、\(e_3 – e_2\)の長さは0となる。\(g \propto f\)の場合、\(e_2 – e_1\)の長さはゼロである。
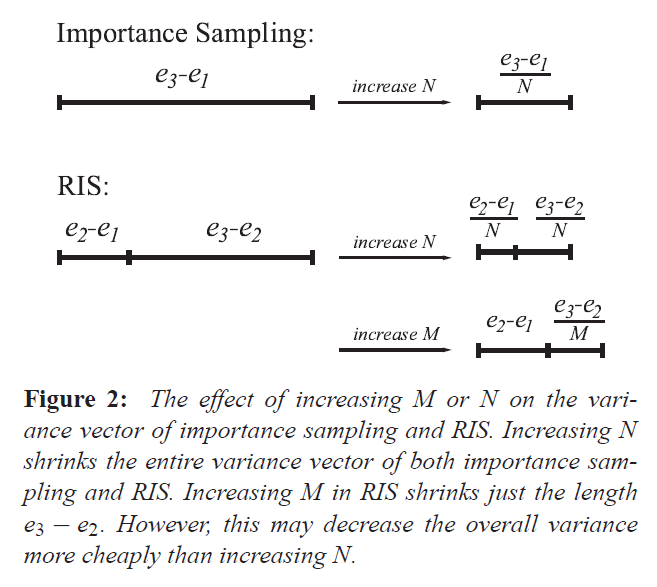
RISでは、\(N\)を大きくすると両ベクトルの長さが短くなります。しかし、\(M\)を増加させると、\(e_3 – e_2\)だけの長さが減少する。どちらを増やすかは、2つのベクトルの相対的な長さと、\(M\)と\(N\)を増やした場合の相対的な計算量に依存することは明らかです。
図3は、直接光下で使用した場合の\(M\)と\(N\)を変化させた場合の効果です。

4.2. Choosing Parameters for RIS
RISを使用する場合、\(p\)、\(g\)、\(M\)、\(N\)を第4節で与えられた不偏性制約の範囲内で自由に選択することができます。明らかに、ある選択は他の選択よりも分散を低くすることになる。本節では、\(g\)と\(p\)の選択について簡単に説明し、\(g\)と\(p\)の固定された選択に対して、\(M\)と\(N\)の最適値を求める方法を正式に示します。
式(2)は\(g\)と\(p\)を選択するための3つのガイドラインを示唆しています。 第一に、\(p\)が\(f\)に比例するよりも\(g\)が\(f\)に比例すべきです。もしこれが正しくなければ、標準的な重点サンプリングはRISと同等かそれより低い分散を持つことになります。第二に、\(g\)と\(p\)はできるだけ\(f\)に比例するようにすることです。これは分散を直接的に減少させます。第三に,\(g\)と\(p\)は(\(f\)と比較して)サンプリングと評価は計算上安価であるべきです。RISは、各サンプルに対して\(g\)と\(p\)を何度も評価する必要があります。\(g\)と\(p\)が高価であれば、標準的な重点サンプリングがより効率的となります。
この値は、一定の計算時間の制約の下、\(p\)と\(g\)を固定的に選択した場合に、RIS推定値の全体的な分散を最小化するように選択されるもので、\(M\)と\(N\)の最適値に近い値を選ぶための発見的手法を導き出します。
\begin{eqnarray}
T = MNT_X + N(r(M) + T_Y)
\end{eqnarray}
ここで,ここで、\(T_X\)は\(p\)からサンプルを抽出し、その重みを計算するのに必要な時間である。関数\(r\)は、再サンプリングステップを実行するのに必要な時間です。\(T_Y\)は、再サンプリングがすでに行われていることを前提に、式(1)を計算するのに必要な時間です。
離散分布からサンプルを抽出するための極めて効率的な手法が数多く存在するため、実際には\(r(M)\)は無視できるほど小さくなります。\(r(M)\)を無視すると、以下の制約が得られる:
\begin{eqnarray}
T = MNT_X + NT_Y
\end{eqnarray}
先に述べたように、式(2)の結果得られる分散はn成分のベクトルとなる。分散を最小化するためには、スペクトルベクトルに対する実数値の長さ関数を選択しなければなりません。ここでは\(l^2\)-normを使用します。また、知覚に基づく尺度も使用することができます。
この制約を利用して、式(2)を代入で最小化し、\(M\)の最適値に近い値を求めます:
\begin{eqnarray}
M = \sqrt{ \frac{ |e_3-e_2| T_Y }{ |e_2 – e_1| T_X } } \tag{3}
\end{eqnarray}
ここで、縦棒は選択した長さ関数を表します。
再サンプリング処理に必要な\(M \geq 1\)、\(N \geq 1\)を確保するために、まず、得られた\(M \geq 1\)をクランプします。次に、\(N\)について解きます。
\begin{eqnarray}
N = \frac{T}{MT_X + T_Y}
\end{eqnarray}
そして、出来上がった\(N \geq 1\)をクランプします。クランプした\(N\)を用いて\(M\)について再度解きます:
\begin{eqnarray}
M = \frac{ \frac{T}{N} – T_Y }{T_X}
\end{eqnarray}
最後に、サンプリングの際には、期待値が変わらないように、\(M\)と\(N\)のfloorやceilingを確率的に取ることにしています。
予想されるように、\(M\)と\(N\)の最適値は、推定の2つの部分の分散と実行時間の関数です。図3は、直接照明のアプリケーションにおいて、式(3)を用いて計算された最適値\(M\)と\(N\)を示します。
4.3. Robust Approximations of \(M\) and \(N\)
実際には、式(3)は未知の\(e_1\)、\(e_2\)、\(e_3\)、\(T_X\)、\(T_Y\)に依存しているため、\(M\)と\(N\)の真の最適値を計算することはできません。未知のパラメータを推定すれば、\(M\)と\(N\)の近似値を計算することができます。残念ながら、すべての未知のパラメータを計算することは困難であり、非常に時間がかかります。本節では、\(T_X\)と\(T_Y\)の推定のみを必要とする式(3)のロバストな近似を紹介します。これらの値は、グローバルイルミネーションのアプリケーションでは、非常に簡単に計算することができます。
\(T_X\)と\(T_Y\)のみを推定する場合、\(M\)と\(N\)を選択するための証明可能なロバストなヒューリスティックは、再サンプリングプロセスの両段階に等しい時間を割り当てることです:
\begin{eqnarray}
MNT_X = NT_Y
\end{eqnarray}
これをは次を使用することと同じです:
\begin{eqnarray}
M = \frac{T_Y}{T_X} \tag{4}
\end{eqnarray}
上式を前節の式(3)に置き換えてください。式(4)から得られるロバスト値を表すために、\(M_r\)と\(N_r\)を使用します。
全体の時間的制約の中で、他の\(MN\)が\(M_r N_r\)の2倍以上になることはありません。また、他の\(N\)は\(N_r\)の2倍以上にはなり得ません。式(2)により、\(M_r\)と\(N_r\)を使用するRISは、\(M\)と\(N\)の真の最適値を使用するRISの2倍以上の分散を持たないことを意味します。
結果として得られる分散の境界は貧弱ですが、この近似が実際には非常によく機能することがわかりました。これは非常に安価に計算でき、\(e_1\)、\(e_2\)、\(e_3\)のモンテカルロ推定に関連する、時に激しいノイズやアーチファクトを回避することができます。
最後に、\(T_X\)と\(T_Y\)を推定できない場合、ロバストなデフォルトの選択は\(T_X\) = \(T_Y\)であることに注意してください。これを式(4)に代入すると\(M=1\)となり、標準的な重点サンプリングとなります。
5. Applications
このセクションでは、グローバルイルミネーションにおけるさまざまな問題に適用した場合のRISの特性のいくつかを示します。
5.1. Sampling the Direct Lighting
RISを使った直接照明の計算は、Shirleyら[SWZ96]とBurke[Bur04]によって、非公式ながら既に取り組まれています。ここでは、彼らのアプローチを一般化し、直接照明のための\(M\)と\(N\)の最適値を近似的に求める方法を示します。
直接照明の方程式は
\begin{eqnarray}
f = F_s G V L_e
\end{eqnarray}
ここで,\(F_s\)はBRDF項で,\(G\)は幾何項,\(V\)はバイナリの可視項,そして\(L_e\)は放射される光です。
\(f\)を近似し、計算が容易な密度\(g\)を選択する必要があります。ShirleyらとBurkeは、以下のように選びました。
\begin{eqnarray}
g = F_s G L_e
\end{eqnarray}
照明計算の中で最もコストがかかる視認性の項を削除しています。
RISのフレームワークでは、他の方法で\(f\)を近似することも同様に有効であることがわかります。例えば、より物理的にリアルなサーフェイスモデルや、複雑なシェーダプログラムでこれらの項を計算することにより、\(F_s\)や\(L_e\)の評価にかかる計算量が増加すると、\(g=GV\)を使用する方が効率的となる場合があります。また、ドロップされた項のいずれかが効率的に近似できる場合は、その近似を使用して\(g\)を改善する必要があります。我々の実装では、可視性の計算は依然として最も高価な操作であるため、ShirleyらとBurkeに従い、\(g =F_s G L_e\)としました。
ShirleyらとBurkeは、直接照明において再サンプリングが有効であることを既に示しているので、このセクションの残りは、\(M\)と\(N\)の最適値を近似的に求める方法を示します。これらの近似値を用いることで、標準的な重点サンプリングだけでは不可能な分散を減らすことができることを示します。
式(3)を使うために、\(e_1\)、\(e_2\)、\(e_3\)を推定するのは計算量が多すぎます。4.3節で説明したように、まず\(T_X\)と\(T_Y\)を近似する必要があるため、式(4)で与えられる近似を用いて、\(M\)と\(N\)のロバスト値を計算します。これを行うために、数千本の一次光線を投射する。そして、最初のヒットポイントでの直接照明を計算するのに必要な時間を追跡する。\(T_X\)は光源をサンプリングして\(g\)を計算するのに必要な平均時間、\(T_Y\)は視認性を確認するのに必要な平均時間です。これらの値を推定するのに必要な時間はごくわずかです。
同じような複雑度のシーンでは、\(T_X\)と\(T_Y\)の値はおそらく非常に安定しているはずです。したがって、これらの値は、特定のレンダラー実装のために事前に計算することができます。もし事前に計算されていれば、ロバストRISは、標準的な重点サンプリングに比べて、全く余分な計算時間を必要としないでしょう。
図4の画像は、2つのポリゴン光源と環境マップによって照らされるドラゴンを表現しています。左の画像は、標準的な重点サンプリングを使用しています。右の画像は、推定\(T_X\)と\(T_Y\)の値から計算された\(M\)と\(N\)のロバスト値を使用しています。このシーンでは、標準的な重点サンプリングを使用した場合と比較して、全体の分散を70%削減することに成功しています。

この分散の低減はシーンに依存します。環境マップがシーンから取り除かれた場合、RISは10%の分散削減しかできません。この差は、環境マップが\(L_e\)項に多くの分散を導入していることが大きな原因です。この項は\(g\)に含まれるため、RISはその分散を低減することができます。環境マップがなければ、分散の多くは視認性に起因するものです。視認性は\(g\)に含まれないので、RISはその分散を減らすことができません。
5.2. Robust Sampling of BRDFs
前節では、RISが標準的な重点サンプリングより良い結果を出せることを示しました。本節では、RISが重点サンプリングよりもロバストであることを実証します。具体的には、RISが幅広いクラスの積分問題にそのまま適用できることを示します。一方、重点サンプリングは、特定の問題ごとに特別なケースを必要とする。双方向反射率分布関数(BRDF)サンプリングの例を用いて実証します。
BRDFは、サーフェイスにおける入射光と出射光の関係を表しています。従来、BRDFは、特定のBRDFモデルごとに開発された特殊なケース分布でサンプリングされてきました。これらをすべてグローバルイルミネーションレンダラーに実装するのは、非常に時間がかかります。また、BRDFのパラメータを空間的に変化させる場合(Bidirectional Texture Distribution Functionsのように)、このアプローチは非広範囲になることがあります。さらに、BRDFがシェーディング言語を用いて指定される場合、分布を自動的に作成することは困難です。
より強固な解決策を見出したいと思っています。理想的には、重点サンプリングに適した分布が利用できるかどうかにかかわらず、あらゆるBRDFモデルのサンプリングを改善することです。リサンプルド・インポータンス・サンプリングはこれを可能にします。
BRDFをサンプリングする場合、サンプリングしたいのは
\begin{eqnarray}
f = F_s (x, x’, x”) \cos(\theta) L_i(x’, x”)
\end{eqnarray}
ここで,\(F_s\)は点\(x’\)におけるBRDFの値で,\(\theta\)は\(x’\)における法線と間の角度で,\({\vec x’x”}\)と\(L_i\)は\(x”\)方から点\(x’\)状の入射光を表します。以降の議論では、これらの関数のパラメータを落とすことにします。
RISを使うには、\(f\)に比例し、かつ計算が安価な関数\(g\)を選ぶ必要があります。ここでは、一般的なアプローチで選ぶことにする:
\begin{eqnarray}
g = F_s \cos(\theta)
\end{eqnarray}
この選択は、モンテカルロ積分に必要なBRDFを評価できることを想定しているだけなので、非常に一般的です。この\(g\)の選択はどのようなBRDFに対しても有効であるため、すべてのBRDFサンプリングに対してRISを一度実装することができます。
以下の例では、標準的な重点サンプリングは、私たちが示す結果よりもはるかに優れた性能を発揮できることを認識しています。しかし、その場合、それぞれのケースに特化したサンプリング分布が必要になります。私たちの目標は、1つの実装で非常に異なるBRDFモデルのサンプリングを劇的に改善できるため、RISがより堅牢であることを示すことです。
図5は、半球上の一様分布に等しい\(p\)でサンプリングされた2組の球体です。最初の2つの球は、拡散したBRDFを持っています。私たちが選んだ\(p\)はBRDFに正確に一致しますが、法線との角度の余弦は考慮されていません。RISは分散を著しく減少させます。2番目の2つの球は、クック・トーランスBRDFを持ちます。この場合、\(\)pは非常に悪いサンプリング密度です。それでも、RISはサンプリング品質を劇的に向上させることに成功しています。どちらのBRDFでも、RISの実装に変更はないことを強調しておきます。
これらの例では、簡単のために\(p\)を一様分布としました。実際には、反射方向と再帰反射方向にローブを持つコサイン加重の半球が、より良いデフォルトの密度になるでしょう。BRDFモデルに特化した分布が利用できる場合は、デフォルトの密度の代わりにそれを使用することができます。

6. Conclusion and Future Work
インポータンスリサンプリングの簡単な説明を紹介しました。重点サンプリングのサンプル生成手法として、インポータンスリサンプリングを使用する方法を紹介しました。その結果、分散削減技術であるリサンプルドインポータンスサンプリングは、標準的な重点サンプリングの一般化です。
最適な再サンプリングパラメータである\(M\)と\(N\)を計算する方法と、計算時間を大幅に短縮できる\(M\)と\(N\)のロバストな近似値を選択する方法を紹介しました。RISをいくつかのグローバルイルミネーション問題に用いた場合、重点サンプリングのロバスト性が向上することを示し、複雑なシーンにおける直接照明の分散を10%〜70%削減することを達成しました。
\(g\)と\(p\)の良い選択を見つけるにはもっと研究が必要です。意外なことに、\(p\)からのサンプリングが\(T_X\)の大部分を占めています。追跡する光線の高速化には多くの研究がなされていますが [Wal04]、高速なサンプル生成技術を見つけることにはあまり研究がなされていません。RISは一度に\(M\)個のサンプルを使用するので、サンプルを並列に生成する技術(おそらくSSEを使用)は非常に有用です。
式(3)では、\(e_3 – e_2\) と \(e_2 – e_1\) のユークリッド長を使用しました。これを改善するために、知覚的な距離の尺度を使用することができます。
Burke [Bur04]は、RISとMISの組み合わせについて、いくつかの初期研究を行いました。この研究は、より一般的なアプローチに拡張される必要があります。
References

