こんにちわ、Pocolです。
今日は…
[Bitterli 2020] Benedikt Bitterli, Chris Wyman, Matt Pharr, Peter Shirley, Aaron Lefohon, Wojciech Jarosz, “Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting”, ACM Transactions on Graphics, Vol.39, No.4, 2020.
を読んでみようと思います。
いつもながら、誤字・誤訳があるかと思いますので,ご指摘いただける場合は正しい翻訳例とともに指摘していただけると幸いです。

モンテカルロ積分を用いて数百万個の動的光源からの直接光を効率的にレンダリングすることは、オフラインのレンダリングシステムにおいても依然として困難な問題です。本論文では、このような照明をインタラクティブに、高品質で、複雑なデータ構造を維持することなくレンダリングする新しいアルゴリズム―ReSTIR―を紹介します。このアルゴリズムでは、候補となるライトサンプルのセットを繰り返し再サンプリングし、さらに空間的および時間的な再サンプリングを適用して、関連する近傍のサンプルの情報を活用します。この手法のための不偏モンテカルロ推定量を導出し、最新の手法に比べて等しいエラーで6倍から60倍高速に達成することを示します。また、バイアスのかかった推定量では、ノイズがさらに減少し、35倍から65倍高速化されますが、エネルギー損失があります。我々はこの手法をGPUに実装し、最大340万個の動的エミッシブ三角形を含む複雑なシーンを、ピクセルあたり最大8本のレイをトレースしながら、フレームあたり50ミリ秒でレンダリングします。
1 INTRODUNCTION
近年、モンテカルロパストレーシングはオフラインレンダリングに広く採用され[Christensen and Jarosz 2016; Fasione et al. 2017]、レイ交差テストのための特別なハードウェアサポートの登場[Schied 2019]により、リアルタイムアプリケーションでの使用が増えてきています[Parker et al. 2010; Wyman et al. 2018]。オフラインレンダリングにおいても、リアルタイムの制約を受けずに、多くの放射性オブジェクトを直接照明することは、依然として困難です。
すべてのライトにシャドーレイをトレースすることは不可能であり,ある点で最も寄与するライトを見つけることは、その地点での各ライトの可視性、その地点での散乱関数(BSDFまたは位相関数)の分布、光源の強さと放射特性に依存します。
リアルタイムレンダリングは、さらに多くの課題があります。レンダリングされるシーンがダイナミックで、ユーザーの操作によってシーンがどのように変化するかについてはレンダラーは一般的に未来のことは分からないからです。現在、各ピクセルでトレースできるレイはわずかであるため、重要なライトを見つけることがより非常に重要になりますが、ライトのサンプリングを支援するデータ構造を構築・更新するための時間は限られています[Moreau et al. 2019]。これは、本論文で検討する、最初のカメラ頂点で直接照明する限定的な場合にも当てはまります。
このような制約から、ノイズの多い低サンプル数のレンダリング画像からのノイズ除去や画像再構成の研究に拍車がかかっています。この分野では、オフラインレンダリング[Vogels et al. 2018]とリアルタイムレンダリング[Schied et al. 2018]の両方で大きな進歩がありましたが、フィルタリングにかかる時間が利用可能なフレーム時間を奪うため、リアルタイムノイズ除去に使える処理時間には限りがあります。図2に示すように、デノイザーに供給されるサンプルの品質を向上させることで、その効果を大幅に高めることができます。

本稿では、完全にダイナミックシーンでのリアルタイムレイトレーシングに適した、多数の照明からワンバンスの直接光をサンプリングする方法を紹介します(図1参照)。我々のアプローチは、再サンプル済み重点サンプリング(RIS)[Talbot 2005]に基づいて構築されます。それは,ある分布からサンプルの集合を取り、被積分関数によりよく合致する別の分布を用いて、それらの重み付けされた部分集合を選択する技術です。RISの先行アプリケーションとは異なり、我々は小さな固定サイズのデータ構造、すなわち、受け入れられたサンプルのみを格納する「レゼバー」と、関連するサンプリングアルゴリズム(非グラフィックスアプリケーションで頻繁に使用される[Efraimidis and Spirakis 2006])を使用して、安定したリアルタイム性能を達成するのに役立てます。
本手法では、固定サイズの配列以上の複雑なデータ構造を用いることなく、時間的・空間的に隣接する画素の統計量を再利用して、各画素の直接光サンプリングするPDFを確率的・段階的・階層的に強化します。時間的・空間的な近傍領域で画素の色を再利用する最新のリアルタイムデノイジングアルゴリズムとは対照的に、我々の再利用はレンダラ内で使用されるサンプリング確率を通知し、その結果、偏りのないアルゴリズムを実現することが可能です。私たちの非バイアスモードはバイアスモードに変更することができ、幾何学的不連続面付近の過暗の代償として、さらにノイズを減らすことができます。我々は,数千から数百万のダイナミックライトを持つシーンにおいて,1つのGPU上で我々のアルゴリズムをインタラクティブに実行し,同じ誤差で,同じハードウェア上に実装された最新の手法と比較して1〜2桁のスピードアップを達成することを実証します。
セクション2では、この手法の数学的な前置きを説明し、以降のセクションでは、我々の研究を説明します。セクション7では、我々の結果と比較する際のより良い文脈のために、関連する研究について議論します。
2 PRELIMINARIES
直接照明による点\(y\)の方向\(\omega\)の反射放射輝度\(L\)は、面\(A\)上で放出される光すべてについての積分で与えられます。
\begin{eqnarray}
L(y, \omega) = \int_A \rho (y, {\vec {yx}} \leftrightarrow {\vec \omega}) L_e(x \leftrightarrow y) G(x \leftrightarrow y) V(x \leftrightarrow y) dA_x, \tag{1}
\end{eqnarray}
BSDF \(\rho\)、放出輝度\(L_e\)、\(x\)と\(y\)の相互可視性\(V\)、および逆二乗距離と余弦項を含むジオメトリ項\(G\)とします。簡略化のため、視線\({\vec \omega}\)とシェーディング点\(y\)を削除し、差分面積を\(dx\)とすると、次のように簡略化されます。
\begin{eqnarray}
L = \int_A f(x)dx, \quad {\rm where} \quad f(x) \equiv \rho(x) L_e(x) G(x) V(x) \tag{2}
\end{eqnarray}
Importance Sampling(IS). 標準的なモンテカルロ重点サンプリング(IS)は、ソースPDF \(p(x_i)\)から\(N\)個のサンプル\(x_i\)を選んで計算することで積分を推定します。
\begin{eqnarray}
\langle L \rangle^N_{\rm is} = \frac{1}{N} \sum_{i=1}^N \frac{f(x_i)}{p(x_i)} \approx L \tag{3}
\end{eqnarray}
ISは、\(f(x)\)がいつでも非ゼロで,\(p(x)\)が正の場合に不偏で,理想的には\(p(x)\)は\(f(x)\)に相関して分散を低減します。
Multiple Importance Sampling(MIS). 実際には、\(f(x)\)に比例したサンプリングを直接行うことは、視認性因子\(V(x)\)の関係もあり、実行不可能です。しかし、積分の個々の項(例えば、BSDF \(\rho\)や放射面\(L_e\)に比例したサンプルを取ることができることが多いです。このようなサンプリング戦略候補\(\rho_s\)が\(M\)個与えられると、MIS [Veach and Guibas 1995b]は各戦略\(s\)から\(N_s\)個のサンプルを抽出し、それらを結合して単一の重み付き推定量とします。
\begin{eqnarray}
\langle L \rangle^{M, N}_{\rm mis} = \sum_{s=1}^M \frac{1}{N_s} \sum_{i=1}^{N_s} w_s (x_i) \frac{f(x_i)}{p_s(x_i)} \tag{4}
\end{eqnarray}
重み\(w_s\)が単位元\(\sum_{s=1}^M w_s(x) = 1\)の部分を形成する限り、MISは不偏のままです。バランスヒューリスティック\(w_s\)は、非負の重みの場合[Kondapaneni 2019]、明らかに良い選択であり[Veach and Guibas 1995b]、\(M\)個の戦略の混合分布からサンプリングすることと等価です。
2.1 Resampled Importance Sampling (RIS)
MISを用いたシェーディング項の線形結合からサンプリングする代わりに、いくつかの項の積にほぼ比例してサンプリングする方法があります。Resampled importance sampling [Talbot et al. 2005]は準最適で,サンプルすることも容易なソース分布\(p\)から\(M \geq 1\)の候補サンプル\({\mathbf x} =\{x_1, \cdots, x_M\}\)を生成することによってこれを達成します(例. \(p \propto L_e\))。そして、この候補のプールからインデックス\({\mathbf z} \in \{1, \cdots , M\}\)を離散的な確率でランダムに選びます。
\begin{eqnarray}
p({\mathbf z} | {\mathbf x}) = \frac{{\rm w}(x_z)}{\sum_{i=1}^M {\rm w}(x_i)} \quad {\rm with} \quad {\rm w}(x) = \frac{{\hat p}(x)}{p(x)} \tag{5}
\end{eqnarray}
上式は、実用的なサンプリングアルゴリズムが存在しないかもしれない、所望のターゲットPDF\({\hat p}(x)\)によって導出されます(例えば、\({\hat p} \propto \rho \cdot L_e \cdot G\)など)。(MIS重み’\(w\)’と区別するために、RIS重みに’\({\rm w}\)’を使用することに注意してください)。サンプル\(y \equiv x_z\)を選択し、1サンプルRIS推定量に使用します。
\begin{eqnarray}
\langle L \rangle^{1, M}_{\rm ris} = \frac{f(y)}{ {\hat p}(y) } \cdot \left( \frac{1}{M} \sum_{j=1}^M {\rm w}(x_j) \right) \tag{6}
\end{eqnarray}
直感的には、推定器は\(y\)を\({\hat p}\)から取り出したかのように使用し、\(y\)の真の分布が\({\hat p}\)を近似しているという事実を補正するために括弧で囲まれた係数を使用します。
RISを複数回繰り返し、その結果を平均化すると、\(N\)-サンプルのRIS推定量となります:
\begin{eqnarray}
\langle L \rangle^{N, M}_{\rm ris} = \frac{1}{N} \sum_{i=1}^{N} \left( \frac{f(y_i)}{ {\hat p}(y_i) } \cdot \left( \frac{1}{M} \sum_{j=1}^M {\rm w}(x_{ij}) \right) \right) \tag{7}
\end{eqnarray}
RISは\(M,N \geq 1\)である限り不偏で,\(f\)がゼロであるときはいつでも関数\(p\)と\({\hat p}\)は正です。\(M\)と\(N\)は自由に選ぶことができますが、\({\hat p}\)と\(f\)[Talbot et al. 2005]の分散と相対コストで決まる\(M\)と\(N\)の最適な比率が存在します。実際には、この比率を事前に決定することは困難であり、サンプル\(y_i\)あたりの最適な候補サンプルの数\(M\)は、代わりに経験的に決定することができます。以下では、簡単のために\(N=1\)とします。我々の推定器は、それぞれ\(M\)個の独立した候補サンプルを持つ\(N\)個の独立した実行を平均化することにより、\(N \gt 1\)の場合にも自明な拡張が可能です。
一般に、画像内の各ピクセル\(q\)は、それ自身のユニークな被積分関数\(f_q\)と対応するターゲットPDF \({\hat p}_q\)を持つことになります。以下、この依存性を添え字で表します。Alg.1 に RIS の擬似コードを示します。

Combining RIS with MIS.。 上記では、単一のソースPDF \(p\) を仮定しましたが、多くの問題では、いくつかの合理的なサンプリング手法(例えば、BSDFやライトサンプリングなど)があります。\({\hat p}\) が正であればどこでも、\(y\) の分布は \(M \rightarrow \infty\) として \({\hat p}\) に近づきます[Talbot 2005]。さらに、ソースPDF \(p\) の形状は、\(y\)の有効PDFと\({\hat p}\)に収束する速度の両方に影響を及ぼします。実際には、ターゲットPDF \({\hat p}\) が2つの関数(例えば、照明 \(\times\)BSDF)の積である場合、\(y\)の有効PDFは、どちらの関数の提案(照明またはBSDF)から取り出すかによって異なります。
幸運にも,Talbot [2005]は,RISの中でMISを用いた複数の競合技術を活用して分散を減らす方法を示しました:MISを用いて提案のプールを生成し,RIS手順の残りの部分でソースPDFとして有効なMIS(混合)PDFを使用します.
残念ながら、この形式のMISのコストは手法の数に対して二次関数的に増加します(各提案に対して重みを評価する必要があり、そのような重みはすべての提案のPDFを考慮する必要があるため)。これは、MISが2つの手法(例えば、照明とBSDF)だけで使用される場合は問題ありませんが、戦略の数が増えるとすぐに実行不可能となります。
RISは、それぞれ異なるソースPDFと積分領域を用いて、空間的・時間的に再利用することで候補数を飛躍的に増加させる方法で使用しています。セクション4では、このようなより一般的な設定においてRISを再導入し、計算上扱いやすい新しいMISアプローチを導入します。
2.2 Weighted Reservoir Sampling
重み付けレゼバーサンプリング (WRS) [Chao 1982] は,データについてシングルパスでストリーム{\(x_1, x_2, x_3, \cdots, x_M\)}から\(N\)個のランダムな要素をサンプリングするアルゴリズムの仲間です。各要素は、\(x_i\) が次の確率で選択されるように、関連する重み付け \({\rm w}(x_i)\) を持っています。
\begin{eqnarray}
P_i = \frac{{\rm w}(x_i)}{\sum_{j=1}^M {\rm w}(x_j)} \tag{8}
\end{eqnarray}
レゼバーサンプリングは各要素を正確に1回ずつ処理し、レゼバー内の\(N\)個のアイテムだけがメモリに残るようにしなければなりません。ストリームの長さ\(M\)は事前に知る必要はありません。
レゼバーサンプリングアルゴリズムは、要素 \(x_i\) が出力集合に複数回現れる可能性があるかどうかに基づいて分類されます。つまり、サンプルが置換あり,または置換なしかで選択されるということです。文献では、基本的により困難な問題であるため、置換なしのサンプリングに焦点が当てられています。幸い、我々はモンテカルロ積分のために独立した選択\(x_i\)が欲しいので、以下では置換ありの重み付きレゼバーサンプリングのみを検討します。
レゼバーサンプリングは、入力ストリームの要素を順番に処理し、\(N\)個のサンプルの レゼバー を保存します。ストリームの任意の点において、レゼバーサンプリングは、レゼバー内のサンプルは(これまでに処理されたすべての要素の)望ましい分布から取り出されているという不変性を維持します。ストリームが終了すると、レゼバーは返却されます。以下では、\(N=1\) の場合、つまり、レゼバーが1つのサンプルで構成されている場合に焦点を当てます。
新しいストリーム要素を処理するとき,レゼバーは不変量を維持するように更新されます。すなわち,\(m\)個のサンプルが処理された後,サンプル\(x_i\)が確率\(w(x_i)/ \sum_{j=1}^m {\rm w}(x_j)\)でレゼバーに出現します。更新規則は,次の確率でレゼバー内の\(x_i\)を次のサンプル\(x_{m+1}\)に置き換えます。
\begin{eqnarray}
\frac{{\rm w}(x_{m+1})}{ \sum_{j=1}^{m+1} {\rm w}(x_j)} \tag{9}
\end{eqnarray}
これは,\(x_{m+1}\)が所望の頻度でレゼバーに現れることを保証するものです。したがって、任意の前のサンプル\(x_i\)は、以下の確率でレゼバーにあります。
\begin{eqnarray}
\frac{{\rm w}(x_i)}{\sum_{j=1}^m {\rm w}(x_j)} \left( 1 – \frac{{\rm w}(x_{m+1})}{\sum_{j=1}^m {\rm w}(x_j)} \right) = \frac{{\rm w}(x_i)}{\sum_{j=1}^m {\rm w}(x_j)} \tag{10}
\end{eqnarray}
となり、不変量も維持されます。
このアルゴリズムは Chao [1982]によって紹介され、Alg.2 にその概要が示されています。レゼバーのサンプルと重みの実行和を保存するだけであり、非常に効率的です。

3 STREAMING RIS WITH SPATIOTEMPORAL REUSE
RISとWRSは我々のアルゴリズムの基礎を形成し、アルゴリズムとデータ構造を極めてシンプルに保ちながら、ランダムな候補をストリーミングで処理することを可能にします(セクション3.1)。このようなストリーミングアルゴリズムが与えられた場合、WRSの特性により、時空間的なリサンプリングを行い、隣接するピクセルや過去のフレームからの候補を効率的に組み合わせ、再利用する方法を示します(セクション3.2)。これにより、わずかな計算量の追加で、有効サンプル数を1桁増やすことができます(図3参照)。
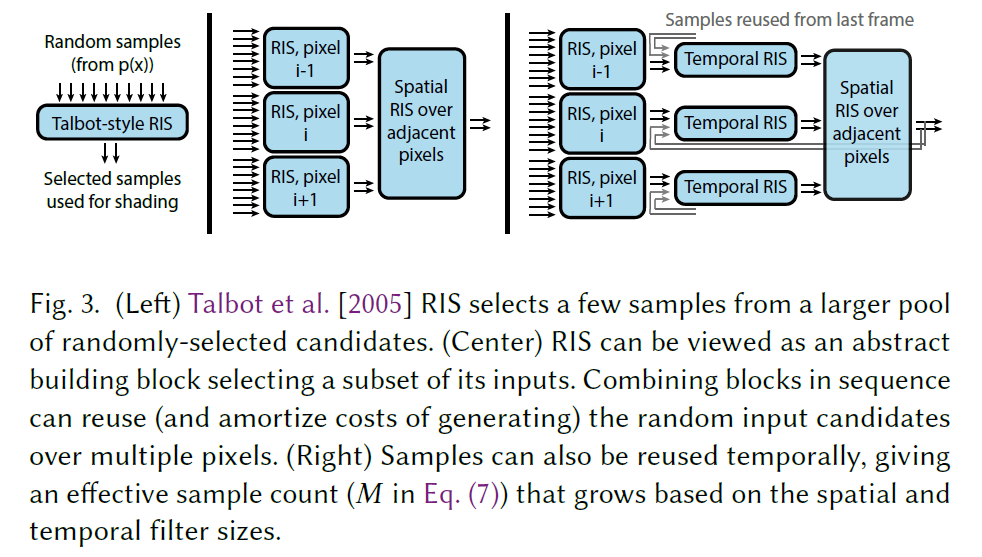
残念ながら、時空間リサンプリングへのネイティブなアプローチは、異なるピクセルが異なるBRDFとサーフェイスの向きに基づいてサンプルを選択するため、偏りが生じます。これは、ポストプロセスフィルタリングで典型的な問題と同様に、画像の幾何学的不連続点付近でのエネルギーロスにつながります。セクション4では、RISを一般化し、不偏性を維持するために変化するサンプルPDFのMIS再重み付けを使用する方法を示します。
3.1 Streaming RIS using reservoir sampling
WRSアルゴリズムをRISに適用し、順次生成される候補\(x_i\)とそれに対応する重みでレゼバーを更新することで、ストリーミングアルゴリズムに変換することは簡単です(Alg.3)。図4は、23,000個のエミッシブ三角形がある複雑なシーンの直接照明のためのストリーミングRISのGPU実装からの画像を示しています。エミッタの領域上に一様にサンプルを生成し、ターゲット分布として影のない経路寄与\({\hat p}(x) = \rho(x) L_e(x)G(x)\)を使用し、生き残った\(N\)個のRISサンプルに対してのみシャドウレイをトレースしています。我々は,候補数\(M\)を変化させたストリーミングRISを,参照だけでなく,ピクセルあたりのレイの数を等しくした最先端のリアルタイムlight BVH[Moreau et al. 2019]と比較します。
驚くべきことに、\(M\)が大きくなると、ストリーミングRISは、前処理や複雑なデータ構造に依存することなく、最先端のライトサンプリング技術さえも凌駕するのです。Alg.3はストレージの必要量を\(O(M)\)から一定にする一方、計算量は\(M\)に対して線形に保たれるため、良い結果を得るには大きな\(M\)が必要となります。


3.2 Spatiotemporal Reuse
3.1 節で述べたアプローチでは,各画素 \(q\) で独立に候補を生成し,ターゲット PDF \({\hat p}_q\) を用いて再サンプリングします。重要な観察は、一般に、隣接するピクセルのターゲットPDF間に有意な相関が存在することです。例えば,影がないライト(\({\hat p}(x) = \rho(x) L_e(x) G(x)\))を使用する場合,空間的な近接性により,隣接するピクセルでジオメトリとBSDFファクターが類似することがよくあります。”類似”ピクセル間の相関を活用する馬鹿正直な方法は、ピクセルごとの候補サンプルとその重みを生成(および保存)し、各ピクセルの候補をその隣接ピクセルと組み合わせることによって、隣接ピクセルで実行された計算を再利用するためにセカンドパスを使用することです。重みの計算は最初のパスで行われるため、近隣の候補を再利用することは、同数の新しい候補を生成するよりも計算量が少なくて済みます。(これはBekaertら[2002]の再利用と似ていますが、彼らは再利用された候補のために可視光線を辿っている)。
残念ながら、この方法は、再利用する候補者ごとにストレージが必要になるため、実用的ではありません。しかし、レゼバーサンプリングの重要な特性を利用することで、ストレージの必要性を回避することができ、入力ストリームにアクセスすることなく複数のレゼバーを結合することができます。
レゼバーの状態には、現在選択されているサンプル\(y\)と、これまでに見たすべての候補の重みの合計\({\rm w}_{\rm sum}\)の両方が含まれます。2つのレゼバーを結合するには、各レゼバーの \(y\) を重み \({\rm w}_{\rm sum}\) を持つ新しいサンプルとして扱い、新しいレゼバーへの入力として与えます。この結果は、2つのレゼバーの入力ストリームを結合してレゼバーサンプリングを行ったことと、数学的に等価です。しかし、重要なのは、この操作は一定時間しか必要とせず、どちらかの入力ストリームの要素を保存(または取得)する必要がなく、各レゼバーの現在の状態へのアクセスのみが必要であることです。任意の数のレゼバーの入力ストリームをこの方法で結合することができます。Alg.4は\(k\)個のレゼバーの入力ストリームを結合する擬似コードを示しており、\(O(k)\)時間で実行されます。隣接ピクセル\(q’\)からのサンプルが異なるターゲット分布\({\hat p}_{q’}\)に従って再サンプリングされるという事実を考慮し、現在のピクセルと比較して隣接でオーバーまたはアンダーサンプルされた領域を考慮するために、サンプルを係数\({\hat p}_q(r.y)/{\hat p}_{q’}(r.y)\cdot r.{\rm w}_{\rm sum}\)で再重み付けします。結果として得られる項\({\hat p}(r.y) \cdot r.W \cdot r.M\)は、Alg.3の8行目で既に計算された項を使用して、より簡潔に\({\hat p}_q(r.y) \cdot r.W \cdot r.M\)と書くことができます。
Spatial Reuse. このレゼバーサンプリングの特性により、RISにおける計算の再利用のための実用的なアルゴリズムが可能となります。まず、RIS(\(q\)) (Alg.3) を用いて各画素\(q\)に対して\(M\)個の候補を生成し、得られたレゼバーを画像サイズのバッファに格納します。次に、各画素は隣接する\(k\)個の画素を選択し、Alg.4によりその画素のレゼバーと自身のレゼバーを結合します。ピクセルあたりの定数は\(O(k+M)\)ですが、各ピクセルは\(k \cdot M\)個の候補を効率的に探索します。重要なことは、空間再利用は、前の再利用パスの出力を入力として、繰り返し行うことができることです。\(n\)回の繰り返しには\(O(nk+M)\)の計算が必要ですが、各ステップで近傍のピクセルが使用されると仮定すると、ピクセルごとに\(k^nM\)個の候補が効果的に得られます。
図5は、SUBWAYのシーンにおける空間再利用の様子です。各反復はほとんど追加計算を必要としませんが、画質は劇的に向上します。ただし、この効果は無限ではなく、再利用を繰り返すうちに近傍画素の候補がすべて取り込まれ、画質の向上が止まってしまいます。


Temporal Reuses. 画像は単独でレンダリングされるのではなく、アニメーションの一部であることが多いです。この場合、前のフレームから再利用の候補を追加することができます。フレームをレンダリングした後、次のフレームで再利用するために、各ピクセルの最終的なレゼバーを保存します。フレームを順次レンダリングし、そのレゼバーをフィードフォワードすれば、フレームは前のフレームの候補だけでなく、シーケンス内のすべての前のフレームと結合し、画質を劇的に向上させることができます。図6は、再びSUBWAYのシーンで、空間のみの再利用と時空間の再利用を比較したものです。

Visibility Reuses. 残念ながら、RISは無限の候補があっても、ノイズのないレンダリングを実現することはできません。\(M\)が無限大に近づくとサンプルの分布は目標PDF \({\hat p}\)に近づきますが、\({\hat p}\)は被積分関数\(f\)を完全にサンプリングしているわけではありません。実際には、\({\hat p}\)は通常、影のないパスの寄与に設定され、\(M\)が大きくなると、視認性によるノイズが支配的になり始めることを意味します。残念ながら、視認性ノイズは大きなシーンで影響を受ける可能性があります。この問題を解決するために、我々は視認性の再利用も行います。空間的あるいは時間的再利用を行う前に、各ピクセルのレゼバーに対して、選択されたサンプル\(y\)の視認性を評価します。\(y\)がオクルードされている場合、我々はレゼバーを破棄します。つまり、オクルードされたサンプルは近隣のピクセルに伝搬せず、可視性が局所的にコヒーレントであれば、空間再サンプリングによって生成される最終サンプルはオクルードされない可能性が高いということです。
Alg.5 は、我々の完全なアルゴリズムの擬似コードです。まず,\(M\)個の独立したピクセルごとの光源候補から生成し,再サンプリングします。このステップで選択されたサンプルは、可視性に関してテストが実行され、オクルードされたサンプルは破棄されます。次に、各ピクセルのレゼバーにある選択されたサンプルを、バックプロジェクションを使って決定された前のフレームの出力と結合します。ピクセルの近隣からの情報を活用するために、空間的再利用を\(n\)回行います。最後に、画像をシェーディングし、最終的なレゼバーを次のフレームに転送します。

4 (ELIMINATING) BIAS IN MULTI-DISTRIBUTION RIS
前節では、低いオーバーヘッドでRISの品質を劇的に向上させる、空間的・時間的に計算を再利用する実用的なアルゴリズムを紹介しました。しかし、我々は一つの重要な点を無視していました。各画素は異なる積分領域とターゲット分布を使用しており、隣接する画素の候補を再利用すると、バイアスが発生する可能性があります。これは、ターゲット分布の違いにより、リサンプリング後のサンプルのPDFが画素ごとに異なるためです。標準的なRISは、再利用時に行うような異なるPDFからの候補サンプルの混合に対応するように設計されておらず、この事実を無視すると、ノイズやバイアスが発生する可能性があります。
本節の残りの部分は、以下のような構成になっています。4.1節~4.3節では、異なるPDFから生成された候補が存在する場合のRISの再解析と理論解析を行い、この偏りの原因と、不偏性を保つための簡単な解決法を明らかにします。理論にあまり興味のない読者は、セクション4.4に直接飛ぶことができ、そこでは、我々の理論に対応するために必要なアルゴリズムの実用的な変更を詳述しています。
4.1 Analyzing the RIS Weight
RISのバイアスの原因を説明するために、まず式(6)を以下のように再整理します:
\begin{eqnarray}
\langle L \rangle_{\rm ris}^{1, M} = f(y) \cdot \left( \frac{1}{{\hat p}(y)} \frac{1}{M} \sum_{j=1}^M {\rm w}(x_j) \right) = f(y) W({\mathbf x}, z) \tag{11}
\end{eqnarray}
ここで、\(W\)は生成されたサンプル\(y \equiv x_z\)の確率的な重みです:
\begin{eqnarray}
W({\mathbf x}, z) = \frac{1}{{\hat p}(x_z)} \left[ \frac{1}{M} \sum_{i=1}^M {\rm w}_i(x_i) \right] \tag{12}
\end{eqnarray}
\(W\)の役割は何でしょうか?通常、モンテカルロ推定量は\(f(y)/p(y)\)からとります。我々は \(p(y)\) を知らないので(実際、私たちはそれを閉形式で計算することができないことを後で示します) \(W({\mathbf x},z)\) が式(11)の代わりになっています。したがって、\(W({\mathbf x},z)\)は逆数PDF \(1/p(y)\)の役割を担っているのだろうと推測されます。しかし、\(W({\mathbf x},z)\)は確率変数です。与えられた出力サンプル\(y\)に対して、それを生成しうる多くの\(\{{\mathbf x},z\}\)があり、どの値のセット(したがって、\(W({\mathbf x},z)\)のどの値)がRISによって返されるかはランダムです。
式(6)が不偏であるためには、\(W({\mathbf x},z)\)の期待値が\(1/p(y)\)に等しいことが必要です。以下では、バイアスの原因となる近傍画素のサンプルを組み合わせた場合、必ずしもそうならないことを示します。
Explanation of Reweighting Factor. Alg.4 では、近傍からのサンプルに重み\({\hat p}_q(r.y) \cdot r.W \cdot r.M\) を付与しています。3.2 節でこの重みの直感的な正当性を示しましたが、この項にもわかりやすい説明がつきました。\({\hat p}_q(r.y) \cdot r.W\)は単に\({\hat p}_q(r.y) / p(r.y)\)の標準RISの重みを表しています。ただし、正確なPDF \(p(r.y)\)を知らないので、代わりに逆PDFの推定値である\(r.W\)(式(12))を用いています。\(r.y\)は複数のサンプルを組み合わせた結果を表しているので、重みはさらに\(r.y\)を生成した候補\(r.M\)の数でスケーリングされます。
4.2 Biased
ここで、RISによって生成されたサンプルの有効PDF \(p(y)\)を導出することにします。標準的なRIS [Talbot et al. 2005] (Section 2.1) は、すべての候補サンプルがサンプルPDF \(p\)によって生成されると仮定しています。これらの提案の結合PDFは、単純にそれらのPDFの積となります。
\begin{eqnarray}
p({\mathbf x}) = \left[ \prod_{i=1}^M p_i(x_i) \right] \tag{13}
\end{eqnarray}
RISアルゴリズムの第2状態では、離散インデックス\(z \in \{1, \cdots, M\}\)を選びますが、選択確率と重みはこの候補者固有のPDFによって導出されます(式(5)を参照)。
\begin{eqnarray}
p(z | {\mathbf x}) = \frac{{\rm w}_z(x_z)}{\sum_{i=1}^M {\rm w}_i(x_i)} \quad {\rm where} \quad {\rm w}_i(x) = \frac{{\hat p}(x)}{p_i(x)} \tag{14}
\end{eqnarray}
\(p({\mathbf x})\)と\(p(z|{\mathbf x})\)があるので、候補\({\mathbf x}\)と選択インデックス\(z\)の結合PDFを積として簡単に書き下すことができます。
\begin{eqnarray}
p({\mathbf x}, z) = p({\mathbf x}) p(z | {\mathbf x}) = \left[ \prod_{i=1}^M p_i(x_i) \right] \frac{{\rm w}_z(x_z)}{\sum_{i=1}^M {\rm w}_i(x_i)} \tag{15}
\end{eqnarray}
では、\(p(y)\)とは何でしょうか?固定された出力サンプル\(y\)に対して、RISが\(y\)を返し始めるような多くの設定\({\mathbf x}\)と\(z\)が存在する可能性があります。例えば、\(x_1 = y\)と\(z=1\)があり、それ以外の\(x_2, \cdots , x_M\)は自由に選択できます。また、\(x_2 = y\)と\(z=2\)のような設定もありえます。もちろん、\(y\)は\(p_i(y) \gt 0\)の場合についてテクニックによってのみ生成されます。これらの技術を以下のような集合に集めてみましょう。
\begin{eqnarray}
Z(y) = \{ i|1 \leq i \leq M \land p_i(y) \gt 0 \} \tag{16}
\end{eqnarray}
出力サンプル\(y\)の全PDFを得るには、この\(y\)をもたらす可能性のあるすべての設定について、結合PDF (15) を単純に除外します。
\begin{eqnarray}
p(y) = \sum_{i \in Z(y)} \underbrace{\int \cdots \int}_{M -1 {\rm times}} p({\mathbf x}^{i \rightarrow y}, i) \underbrace{dx_1 \cdots dx_M }_{M – 1 {\rm time}} \tag{17}
\end{eqnarray}
ここで、\({\mathbf x}^{i \rightarrow y}= \{x_1, \cdots, x_{i-1}, y, x_{i+1}, \cdots, x_M \}\)は\(i\)番目の候補が\(y\)に固定されている候補の集合の略記です。積分は固定されていない\(M-1\)個の候補に対してのみ行われます。
Expected RIS Weights. RISのPDFが定義されたので、RISの重みの期待値\(W({\mathbf x},z)\)がPDFの逆数であるときのことを示しました。この値を計算するためには、条件付き期待値を取る必要があります。出力サンプルが\(y\)であるとすると、平均的な重みは何でしょうか?これは、\(x_z=y\)となる\({\mathbf x}\)と\(z\)の値についてのみ\(W({\mathbf x},z)\)の期待値をとり、\(x_z=y\)という事象の確率密度である\(p(y)\)で除算することです。これは次を得ます。
\begin{eqnarray}
\underset{x_z=y}{\mathbb E} [ W({\mathbf x}, z)] = \sum_{i \in Z(y)} \frac{ \int \cdots \int W({\mathbf x}^{i \rightarrow y}, i)p({\mathbf x}^{i \rightarrow y}, i) dx_i \cdots dx_M }{p(y)} \tag{18}
\end{eqnarray}
ここで、\({\mathbf x}^{i \rightarrow y}\)と積分境界は式(17)と同じです。
付録Aでは、この式が単純化されることを証明しています:
\begin{eqnarray}
\underset{x_z = y}{\mathbb E}[W({\mathbf x}, z)] = \frac{1}{p(y)} \frac{|Z(y)|}{M} \tag{19}
\end{eqnarray}
これは2つのことを示しています。ターゲット関数が非ゼロである場所ですべての候補PDFが非ゼロである場合、\(|Z(y)|=M\)、およびRIS重みは逆RIS PDFの不偏推定量となること。また一方、PDFの一部が積分の一部に対してゼロである場合、\(\frac{|Z(y)|}{M} \lt 1\)、および逆PDFは一貫して過小評価されます。これは、期待値が真の積分値よりも暗くなるようにバイアスがかかっていることを意味します。
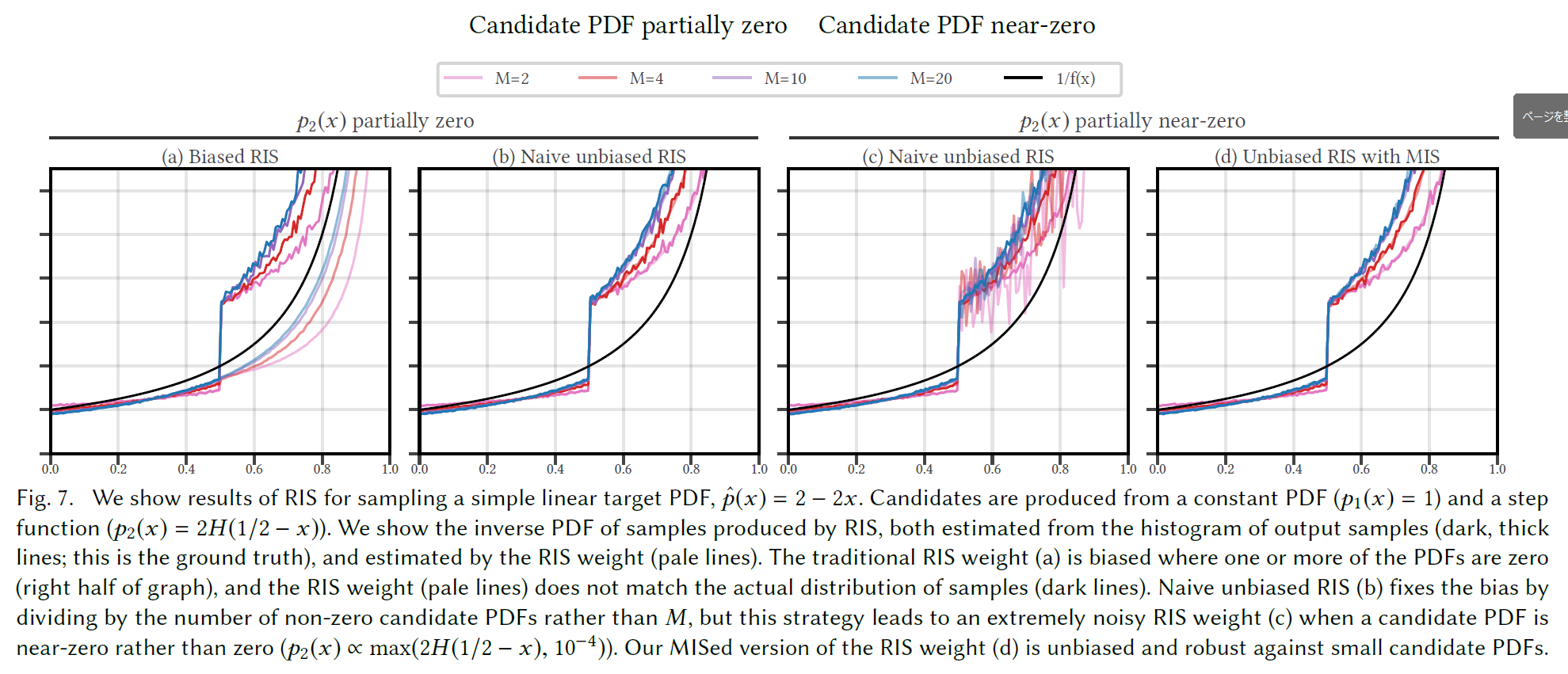
A 1D Example. このことを示すために、次の2つのPDFの候補を考えてみましょう:\(p_1(x) = 1\)と\(p_2(x) = 2H(1/2 – x)\)、ここで\(H(x)\)はHeavisideステップ関数です。これらのPDFは以下のように図示されています。
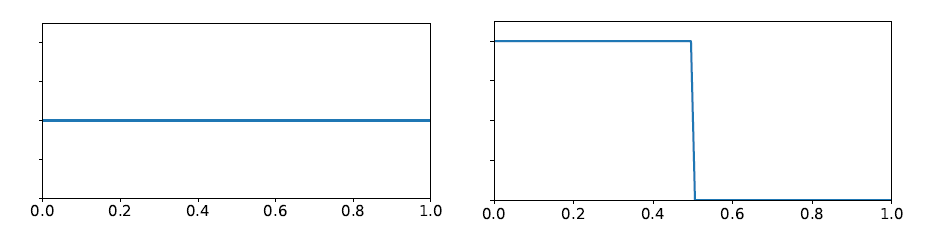
図7(a)では、この2つのPDF候補を用いて、\(M\)の値が増加するにつれて、\(p_1\)と\(p_2\)から生成される候補の半分で、線形ランプ\({\hat p}(x)=2 -2x\)のサンプリングを行いました。1つはサンプル位置のヒストグラムの逆数(実線で暗い曲線、これがグラウンドトゥルース)、もう一つは各位置でのRIS重量の平均(淡い透明曲線)としてプロットし、異なる方法で測定した\(1/p(y)\)を可視化しています。曲線は一致しませんが、もし標準RISが本当に逆PDFの推定量であるならば、一致するはずです。
4.3 Unbiased RIS
この偏りは、RISの重みを変更することで解消できることを示します。係数\(1/M\)を掛ける代わりに、ある(まだ特定されていない)重み\(m(x_z)\)を選べばよいです。
\begin{eqnarray}
W({\mathbf x}, x) = \frac{1}{{\hat p}(x_z)} \left[ m(x_z) \sum_{i=1}^M {\rm w}_i(x_i) \right] \tag{20}
\end{eqnarray}
\(W\)の期待値の導出を繰り返すと、次のようになります。
\begin{eqnarray}
\underset{x_z = y}{{\mathbb E}}[W({\mathbf x}, z)] = \frac{1}{p(y)} \sum_{i \in Z(y)} m(x_i) \tag{21}
\end{eqnarray}
上記は不偏推定量であることを示すため、\(\sum_{i \in Z(y)} m(x_i) = 1\)だけを必要とします。
Naive approach. \(m(x)\)の選び方は無限にあります。最も簡単な方法は一様な重みを使い、単純に\(m(x_z)=1/|Z(x_z)|\)を設定することです。つまり、\(M\)(候補の数)で割るのではなく、その位置でPDFが非ゼロの候補の数で割れば、不偏のRIS推定量となります(図7(b)参照)。
これでバイアスの問題は解決しましたが、この逆PDFの推定量には問題があります。\(p_2(x) \propto {\rm max}(H(1/2 – x), 10^{-4})\)のような、正確にはゼロではありませんが、ゼロに近いPDFの候補を考えてみましょう。候補PDFは決して0ではないので、元のRIS推定量でも不偏になります。しかし、逆RISのPDFの推定量は、図7(c)に示すように、非常にノイズが多くなってしまうのです。
Combining with Multiple Importance Sampling. 幸いなことに、例えば和が1になるような重み\(m(x_z)\)を任意に選ぶことができるのです。例えば,
\begin{eqnarray}
m(x_z) = \frac{p_z(x_z)}{\sum_{i=1}^M p_i(x_z)} \tag{22}
\end{eqnarray}
すなわち、候補PDFのバランスヒューリスティックです。これにより、図7(d)に示すように、RISを用いて多数の候補PDFを組み合わせる際の偏りやノイズの問題を解決することができます。
Comparison to Talbot et al.[2005]. Talbotらは、RISで複数の候補PDFを使用するための別の解決策を提案しています。我々が重みとして\(w_i(x)={\hat p}(x)/p_i(x)\)(式(14))を用いるところ、Talbotらは\(w_i(x)={\hat p}(x)/\sum p_i(x)\)を用いています。Talbotらは、個々のPDFを単一の平均PDFで置き換えることで、複数の候補PDFを混合した場合に発生するノイズやバイアスの問題を回避しています。また、候補PDFの合計が個々のPDFよりも目標分布に近い場合、Talbotらのアプローチは我々のアプローチと比較して、さらにノイズを減らすことができます。しかし、この2つのアプローチには決定的な違いがあります。Talbotらは各候補サンプルについてすべてのPDFを評価しています。もし各候補サンプルが異なるPDFを使用する場合、彼らのアプローチのコストは\(O(M^2)\)のPDF評価となります。一方、我々のアプローチでは、各候補のPDFのみを評価し、最終的なMIS重み(式(22))を計算する際にもう一度すべてのPDFを評価するため、コストは\(O(M)\)となります。これは、PDFの評価がレイの追跡を含む可能性がある我々のケースで特に重要です。Talbotらのアプローチの2次コストは、この使用例では完全に実行不可能であるのに対し、我々のアプローチの線形コストは手頃なコストで不偏性を提供します。補足資料では、この点をさらに実証するために、2つのアプローチのより詳細な議論と経験的な比較を行っています。
4.4 A Practical Algorithm for Unbiased Reuse
ここで、サンプルの再利用のためのアルゴリズムに、バイアス補正を適用することができます(Alg.5)。バイアスは,複数のレゼバーを結合する際に発生します(Alg.4)。ピクセル\(q\)は,その隣接ピクセルからレゼバー\(r_i\)を収集し,それぞれがサンプル\(r_i.y\)を寄与します。しかし,このサンプルのPDFは,\(q\)における被積分関数がゼロでありませんが,ゼロになることがあります。例えば、半球より下にある候補は、通常、棄却されます。しかし,隣接するピクセルのサーフェイス法線が異なる方向を向いている可能性があり,\(q\)において非ゼロの寄与を持つと思われるサンプルを破棄する可能性があります。同様に、我々のアルゴリズムは、再サンプリングの最初の巡回後にオクルージョンされたサンプルを破棄します(事実上PDFはゼロに設定されます)。しかし,あるピクセルで隠されたサンプルは,その隣のピクセルでは見えている可能性があり,それを破棄するとバイアスが発生します。
各サンプル \(r_i.y\) はリサンプリングの結果であり,その真のPDFはわかりません(式(17)は閉形式で評価できないからです)。しかし,真のPDFがゼロであるときはいつでもゼロであるこのPDFの近似形式を知っている限り,不偏の重みを計算するためにそれを代わりに使用することができます。ピクセル\(q_i\)について,\(q_i\)におけるサンプルの真のPDFがどこにあってもゼロであるため,\({\hat p}_{q_i}(x)\)を真のPDFの近似として使用します。可視性再利用が採用される場合,\(x\)が\(q_i\)でオクルードされているかどうかを追加でチェックし,オクルードされている場合はPDFをゼロに設定します(そのようなサンプルは破棄されるため)。
Alg.6では、不偏のレゼバー結合(一様な重みを持つ)の擬似コードを示します。残念ながら、不偏バージョンは著しく高価になります:可視性の再利用を採用する場合、\({\hat p}_{q_i}\)は可視性を含み、それを評価すると、追加のシャドーレイをトレースする必要があります。例えば、空間再利用の場合、これは\(k\)本の追加レイを追跡することを意味します(隣接するピクセルごとに1本)。
そのため、このアルゴリズムでは、バイアスとノンバイアスの両方を実装しています。バイアスドアルゴリズムでは,近傍(時間的・空間的)なオクルージョンやサーフェイスの向きが異なる場合に,ダーケニングを導入する。この偏りは近傍を注意深く選択することで部分的に回避することができるが,これについては次のセクションで述べます。残りの偏りがまだ許容できない場合、追加のレイを追跡する代償として、我々の偏ったアルゴリズムが使用される可能性があります。

5 DESIGN AND IMPLEMENTATION CHOICES
我々は、GPUベースのリアルタイムレンダリングシステムに、本アルゴリズムのバイアス付きとバイアス無しの両方のバリエーションを実装しました。我々は、堅牢性と性能を向上させ、また、バイアスの影響を制限するために、様々な設計上の選択を行いました。このセクションで詳述します。また、我々の実装で使用されるパラメータを指定します。一般に、非バイアスアルゴリズムは計算コストが高く、我々は、バイアスと非バイアスのバリエーションについて、ほぼ同等のコストとなるように異なるパラメータを選択します。
Candidate Generation. エミッシブ三角形をその強さに基づいて重要度サンプリングし、選択された三角形上の点\(x\)を一様に生成することで\(M=32\)個の初期候補を抽出します(すなわち、\(p(x) \propto L_e(x)\))。シーンに環境マップが存在する場合は、代わりに25%の候補が環境マップの重要度サンプリングによって生成されます。三角形と環境マップの双方に対する重点サンプリングはエイリアステーブル[Walker 1974]を用いて高速化されます。また、エミッシブ三角形のVPLのリストを事前に生成する実験も行いました。この方法は、いくつかの視覚的アーティファクトを犠牲にして、より高い性能をもたらし、レンダリング時間が限られたリアルタイムアプリケーションのためのオプションになるかもしれません。また,Moreauら[2019]のデータ構造によって生成されるような,より高品質のサンプル初期候補を使用することも可能でしょうが,これは我々の予備テストにおいて大幅に実行時間を増加させることが証明されました。
Target PDF. 我々のアルゴリズムにおける各再サンプリングステップにおいて、我々はターゲットPDFに基づいてサンプルを重み付けします。我々は、各ピクセルでのターゲットPDFとして、影になっていない経路寄与度\({\hat p} \propto \rho \cdot L_e \cdot G\)を使用します。我々は、シーン内の全てのジオメトリに対して、拡散ランバーシアンサーフェイスの上に誘電体GGXマイクロファセット層からなる統一された材質モデルを使用します。より洗練された材質モデルが使用され、各候補のBRDFを評価することが高価すぎる場合、BRDFの近似値が使用されることがあります。
Neighbor selection. 空間的再利用については、決定論的に近傍点(例. 現在のピクセルの周りの小さなボックスで表示します)を選択するとアーチファクトが気になることがわかったので、代わりに現在の画素の周囲30画素の半径で、低ディスクレパンシーシーケンスからサンプリングした\(k=5\)個(我々のアンバイスドなアルゴリズムについては\(k=3\))のランダムな点をサンプリングしています。代替案として,階層的なÀ-Trousサンプリングスキーム[Dammertz et al. 2010; Schied et al. 2017]を使用することも,いくつかのアーティファクトを犠牲にして有望な結果をもたらし,将来の仕事のために興味深いかもしれません。時間的再利用のために,現在のピクセルの位置を前のフレームに投影するためにモーションベクトルを計算し,そのピクセルを時間的再利用のために使用します。
我々のバイアスドなアルゴリズムでは,形状や材質が大きく異なる隣接画素の候補を再利用するとバイアスが大きくなるため,単純なヒューリスティックを用いてそのような画素を棄却しています。カメラ内距離と,現在の画素と隣接画素の法線間の角度を比較し,どちらかがある閾値を超えた場合(それぞれ現在の画素深さの10%と25%)隣接画素を棄却しています。この戦略はリアルタイムデノイジングの選択的ブラーで使用されるものと類似しており、我々はこれがバイアスを大幅に減少させることを見出しました。我々は\(n=2\)(我々の非バイアスアルゴリズムでは\(n=1\))の空間的再利用パスを使用します。
Evaluated Sample Count. 我々のAlg.5では、\(N=1\)、つまりフレームの最後に1つのサンプルが評価されることを想定しています。それ以上のサンプル数では、このアルゴリズムを単純に繰り返し、その結果を平均化することができます。我々の非バイアスアルゴリズムでは、インタラクティブフレームレートのために\(N=1\)を使用し、我々のバイアスアルゴリズムは、代わりに\(N=4\)を使用します。すなわち、各ピクセルに4つのレゼバーを格納します。非インタラクティブなレンダリング時間については、我々のアルゴリズムの独立した実行の画像を単純に平均化します。
Reservoir storage and temporal weighting. それぞれで、ピクセルのレゼバーの情報のみを保存します。\(N \gt 1\)の場合、複数のサンプル\(y\)と重み\(W\)を各ピクセルに保存し、複数のレゼバーを収容します。時間的再利用では、各フレームが常に前のフレームのレゼバーと結合するため、ピクセルに寄与する候補\(M\)の数は理論上無限に増加することが可能です。このため、再サンプリング時に(古くなった可能性のある)時間的サンプルが不釣り合いに高く重み付けされることになります。これを解決するために、我々は単純に前のフレームの\(M\)を現在のフレームのレゼバーの\(M\)の最大\(20\times\)にクランプし、\(M\)の無限の成長を止め、時間情報の影響を制限することができます。
6 RESULT
ハードウェアアクセラレーションによるレイトレーシングを適用できるように、オープンソースのFalcorレンダリングフレームワーク[Benty et al. 2019]で本手法を試作しました。我々は、我々のアルゴリズムをReservoir-based Spatio-Temporal Importance Resampling,あるいは略してReSTIRと呼びます。我々は、数千から数百万のエミッシブ三角形を含む様々なシーンで我々の技法をテストしました。レンダリングとタイミングはGeForece RTX 2080 Ti GPUで得ましたが、AMUSEMENT PARKシーンはメモリ要件が高いため、Titan RTXを使用する必要がありました。
私たちが報告するレンダリング時間には、サンプル生成、レイトレーシング、シェーディングのコストが含まれています。G-バッファのラスタライズコストは、すべてのレンダリング手法で共有されるため、含まれていません(平均1~2ms)。高サンプル数でレンダリングした非バイアスのリファレンスと比較した各手法の画像誤差を報告します。誤差は相対的平均絶対誤差(RMAE)として報告され,平均二乗誤差(MSE)よりも孤立した外れ値に対する感度が低いことがわかっています。
時間的再利用の方法については、高速なカメラ移動を伴う20フレームアニメーションの最終フレームを図に示します。これにより、ウォームアップ期間中に予想される低品質を回避し、単一ビューを時間的にスーパーサンプリングすることによる人為的な利点を提供することができます。このシーケンス内の各フレームは、最終フレームと同じ計算バジェットを使用しています。
図1と図9は、我々のバイアスドな時空間再利用と、最先端のリアルタイムライトサンプリング技術[Moreau et al. 2019]との等時間比較です。我々の技術は、MoreauらのBVHベースのアプローチよりも大幅に低い誤差を持っています。我々は、light BVHは一般的に我々のストリーミングRISアルゴリズム(再利用なし)よりも性能不足であることを発見し、すべてのさらなる結果において、我々は比較のためのベースラインとしてストリーミングRISを使用します。
補足動画では、AMUSEMENT PART、SUBWAY、BISTRO、ZERO DAYのアニメーションのリアルタイムキャプチャを、均一サンプリング、Moreauら[2019]のアプローチ、我々のバイアスドな方法とアンバイアスドな方法、オフラインレンダリングの参照アニメーションの様々な組み合わせの等時間比較で紹介しています。

図8は、RIS [Talbot et al. 2005]による時空間再利用のバイアスドバージョンとアンバイアスドバージョンを等時間で比較したものです。公平なベースライン比較を可能にするために、我々のRISのストリーミングバージョンと比較しています。これは、非ストリーミング実装よりも一貫して高速(20%〜30%のスピードアップ)であることがわかったからです。我々の方法は、空間的、視覚的、そして誤差の観点から採用しました。いくつかのシーン(例:SUBWAY)では、ベースライン画像はほとんど認識できませんが、我々の時空間的再利用画像はほぼ収束しています。全てのシーンにおいて、我々のバイアスドな方法は、多少のエネルギー損失と画像の暗さを代償に、かなり分散が少なくなっています。エネルギー損失は、影の境界、鋭いハイライト、樹木のような複雑な形状など、照明が困難な領域で最も顕著に見られます。

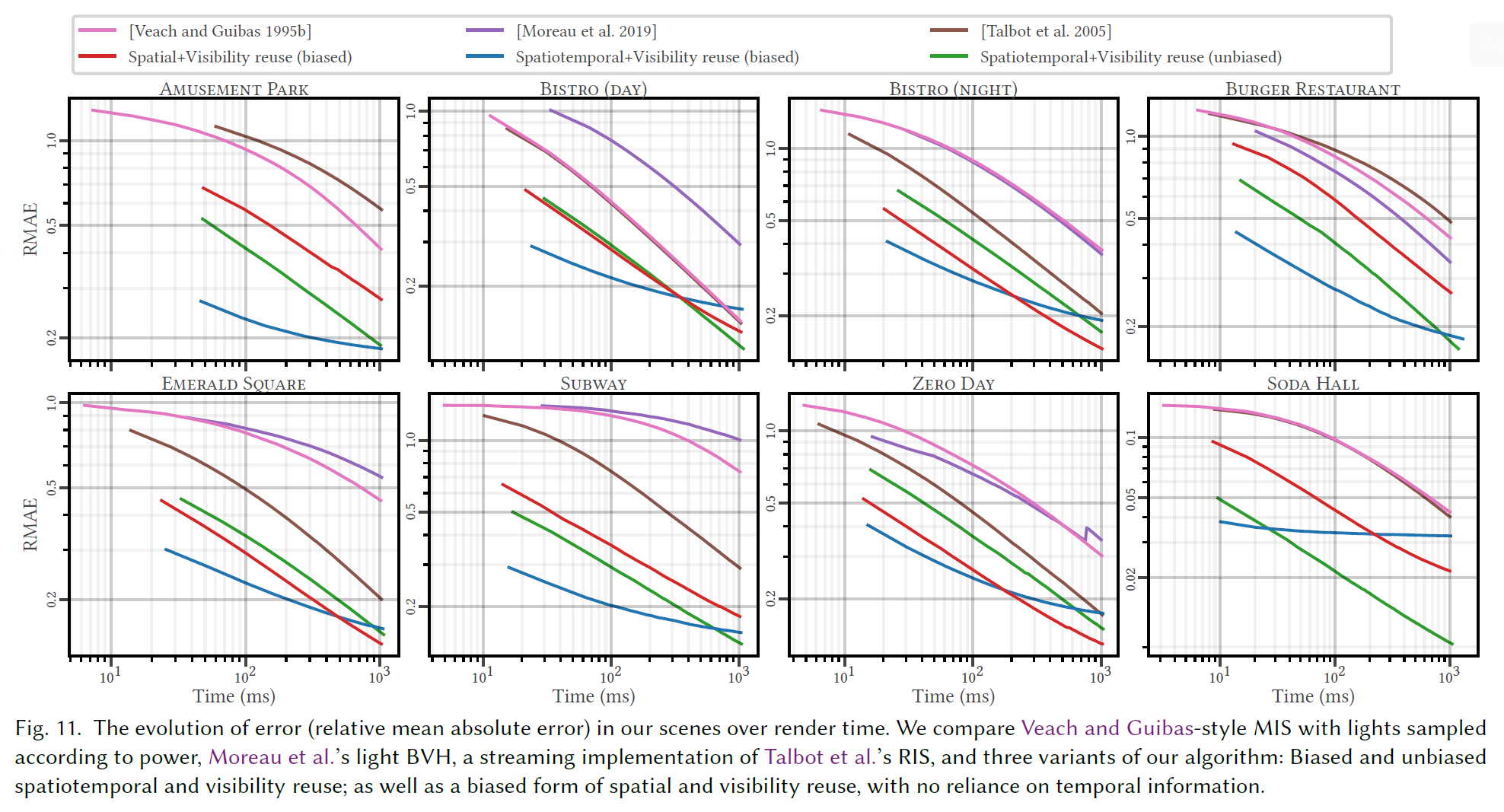
図11は、6種類の方式について、レンダリング時間の増加とともにRMAEがどのように変化するかを示したものです:強さに応じた照明のサンプリングを行い、BRDFと面積加重サンプリングによるMIS[Veach and Guibas 1995b]を適用する; Moreauら[2019]のlight BVH; ストリーミングRISと、我々のアルゴリズムの3つのバージョン: バイアスド時空間再利用とアンバイアスド時空間再利用、そして時間的再利用を伴わないバイアスド空間再利用。最後のバリエーションは、静止画像に対する我々のアルゴリズムを評価することを可能にします。すべてのシーンで、バイアスのかかった時空間再利用は、インタラクティブレンダリング時間において最も誤差が少なく、大抵かなりのマージンをもっています。しかし、レンダリング時間が長くなると、バイアスによる誤差が支配的になり、バイアスのない時空間再利用の方が最終的に誤差が小さくなります(通常1秒程度)。ほとんどのシーンで、バイアス付き空間再利用は、前のフレームからの知識に依存することなく、競争力のある性能を提供します。また,時間履歴がないため,バイアスの伝搬が制限され,レンダリング時間が長くなると,バイアスの減少により,この方法はバイアスのある時空間再利用を追い越すことができます。すべてのシーンにおいて、我々は先行研究を大幅に上回る性能を示しました。
非インタラクティブなレンダリング時間における本手法の性能を実証するため,図10では,レンダリング時間1秒のAMUSEMENT PARKシーンにおいて,ストリーミングRISと本手法を比較しています。レンダリング時間が比較的長い場合でも、ベースラインと比較して有意に高いパフォーマンスを示しています。バイアスのかかった時空間再利用はほぼノイズフリーですが、バイアスは明らかです。問題がある場合は、バイアスのかかっていない時空間再利用がわずかに高い分散で同様の性能を提供します。

7 RELATED WORK
レンダリングにおけるライトサンプリングやサンプルの再利用については、さまざまな先行研究があり、私たちの研究に関連する数学的ツールも開発されています。
Many-light sampling. 特に、複雑なエミッターを大量に集めたシーンでは、直接照明だけでは難しい場合があります。Ward [1994]とShirleyら[1996]はこの分野の先駆者で、期待される寄与に基づいてライトを「重要」と「非重要」に分類しています。今日,多くのエミッターを持つシーンを対象とするレンダラは,ライト階層[Estevez and Kulla 2018; Yuksel 2019]を使用して,リニアに準する時間で多くのライトから重要度サンプリングを行うことによって,この考えを拡張しています。最近の研究は,階層がリアルタイムレンダリングに有効であることを実証しています[Moreau et al. 2019]が,リアルタイムレンダラーは多くの少数のレイを追跡するので,これらの階層を構築し維持するコストは,レンダリングに費やした時間に対して高くなります。Lin と Yuksel [2020]による同時進行の仕事は,階層を維持するコストを下げるために低品質の高速化機構を使用しますが,それでもデータ構造のトラバーサルを必要とし,我々とは対照的に,BRDFを取り込みません。我々のアプローチは、複雑なデータ構造を維持するコストを排除し、BSDFとライトの可視性の両方を考慮することにより、ライト階層よりも高品質なライトサンプルを生成します。
また、レンダリング時に直接照明をサンプリングするために、PDfを適応的に構築する手法もいろいろとあります。Donikianら[2006]は,プログレッシブレンダラーにおけるライトサンプリングのために,固定画像ブロック上の集約的なPDFを構築します。彼らのアプローチは,正確なPDFを見つけるために,各ピクセルで多くのレイをトレースする必要があります。より最近では,Vevodaら[2018]は最適なライトクラスタを作成するためにベイズオンライン回帰を適用しました。彼らのアプローチは,事前に構築された階層的なライトカット [Walter et al. 2005]を必要とし,これは動的なライトを持つシーンでの適用を複雑にしています。どちらも、またはこれらは、ライトサンプルのBSDFを考慮していません。これらの技術に解放されたのは、一般的な照明のためのサンプリングPDFを学習し、直接照明にも適用できる経路ガイディングアプローチ[Hey and Purgathofer 2002; Jensen 1995; Muller et al.2017; Vorba et al.2014] です。これらの技術のいずれも、低いピクセルあたりのサンプリング密度でリアルタイムレートにスケールすることは示されていません。
インタラクティブな文脈では,タイルシェーディング [Olsson and Assarsson 2011] は重要なライトのタイごとのグループを作成し,これらの入力からのピクセルごとの寄与のみを蓄積します。商業的に広く使用されている一方で,これらの方法は,すべてのライトを効率的に集約するのではなく,各ピクセルに影響を与えるライトの数を減らすことを目的としています。これは結果にバイアスをかけ,典型的には各ライトの寄与を限られた領域に制限しますが,いくつかの確率的なバリエーション[Tokuyoshi and Harada 2016]はこのバイアスを軽減させます。
Exploiting path reuse and spatial correlation. 光を輸送するパス間の情報を再利用することは、レンダリングにおいて長い歴史があります。仮想点光源(VPL)に基づくアルゴリズムは,環境内の照明を近似する多数の点光源エミッターを生成し,次に,予想される寄与に従ってそれらからサンプリングします[Dachsbacher et al.2014; Davidovic et al.2010; Keller 1997; Ou and Pellacini 2011; Sbert et al.2004; Segovia et al.2006; Walter et al.2006, 2005]。ネイティブにサンプリングした場合,VPLは高品質の結果を得るために1ピクセルあたり多くのレイを必要とします。あるいは,VPL を正確にサンプリングするためのデータ構造を維持するためのコストは,リアルタイムのフレームレートでは困難です。
経路を再利用するアルゴリズムの別のファミリーは、入射照明をキャッシュし、近くのポイントでそれを補間します。このアプローチは、フォトンマッピング[Dengら、2019;Jaroszら、2011、2008b;Jensen 1996、2001]とラディアンスキャッシュ(イラディアンスキャッシュ)[Jaroszら、2008a、2012、2008c;Krivanekら、2006、2005;Schwarzhauptら、2012;WardとHeckbert 1992;Wardら、1988]で採用されています。これらのアルゴリズムは、ゆっくりと変化する照明に対してはうまく機能しますが、ディレクショナルライトによく見られるような急激な視界の変化に対しては苦労することになります。
双方向パストレーシングでは,光を運ぶパス全体を再利用します.初期のバージョンでは,カメラとライトのサブパスのペアで1つの頂点を接続し,そのプレフィックスを再利用しました [Lafortune and Willems 1993; Veach and Guibas 1995a]。より最近では,経路の再利用は効率向上を可能にし,経路接続の賢明な選択を可能にしました[Chaitanya et al. 2018; Pajot et al. 2011; Popov et al. 2015; Tokuyoshi and Harada 2019]。密接に関連するのは、一方向の光輸送アルゴリズムにおける経路の再利用に関する研究で、以前にサンプリングされた経路が保存され、その後新しい経路に接続されます[Bauszat et al.2017; Bekaert et al.2002; Castro et al.2008; Xu and Sbert 2007]。これらの手法は効率性の向上をもたしますが,経路を再利用するたびに可視光線を追跡する必要があり,これに対して我々の手法は少数のサンプルについて光線を追跡するだけであるため,より多くのサンプルを再利用することができます。
マルコフ連鎖モンテカルロ(MCMC)光輸送アルゴリズム[Cline et al. 2005; Hachisuka et al. 2014; Kelemen et al. 2002; Lai et al. 2007; Li et al. 2015; Otsu et al. 2018; Veach and Guibas 1997] は1つ以上の光を運ぶパスを維持し、重み付け経路の分布がシーン内の平衡放射輝度分布に近づくようにそれらを摂動させることによって経路を再利用します。これらの方法は、有効なライトキャリングパスの空間を局所的に探索するため、効率が改善される。多くの場合,挑戦的な光輸送経路をサンプリングするのに非常に効果的ですが,これらのアルゴリズムは収束する前にピクセルごとに多くのサンプルを必要とし,典型的な光輸送に対して従来のモンテカルロ技術に劣ることが多いです[Bitterli and Jarosz 2019]。さらに,サンプル間の相関に起因する構造化された画像アーティファクトに悩まされます。
すべての経路再利用アルゴリズムは、経路再利用による効率向上と画素相関の間でトレードオフの関係にあります。経路の再利用回数が多すぎると、レンダリング画像にアーティファクトが現れることがあります。一般に、人間の視覚系は、構造化されたアーティファクトよりも高周波のノイズに寛容です [Cook 1986]。このことは,エラーを画像全体にブルーノイズとして分散させる作業を動機付けました[Georgiev and Fajardo 2016; Heitz and Belcour 2019; Heitz et al.2019]。我々は画像全体の空間的な相関と広範なサンプルの再利用を利用する一方で,我々のレンダリングは無相関モンテカルロに典型的な高周波ノイズを含んでいます。
Resampling. Resampled importance sampling は,レンダリングにおいて様々な応用がなされています [Burke et al.2004, 2005; Rubin 1987; Talbot 2005; Talbot et al. 2005]。また,逐次モンテカルロ法(SMC)も関連しており,既存のサンプルに摂動を与え,ランダムに受け入れて目的の分布に近づけることができます [Ghosh et al.2006; Pegoraro et al.2008]。我々はRISを基に、GPU実装に適したストリーミングアルゴリズムに変換し、異なる分布からサンプリングしても不偏推定値を維持できるようにし、時空間的にサンプルを再利用できるようにし、MISを組み込んでいます。
Ratio & weighted estimators. 本手法を含むリサンプリング技術は、少なくとも1950年代から標本調査に用いられてきた比率推定量と関係があります。同様の推定量は,モンテカルロ法の文献で重み付き一様サンプリング(WUS)[Powell and Swann 1966]という名称で独自に開発され,Spanier[1979]とSpanier and Maize[1994]によってランダムウォーク問題に適用されました。これらはBekaertら[2000]によって重み付き重点サンプリング(WIS)という名前でグラフィックスに導入され、後にStachowiak[2015]とHeitzら[2018]によって比率推定量として再導入されました。WUS、WIS、比率推定量について付録Bで詳述しますが、本質的には、3つとも、各モンテカルロ標本を被積分関数と相関のある選ばれた分布で重み付け(または比率を取る)することによって分散を減らします。
これに対し、重点サンプリング(3)では、分布による評価・重み付けだけでなく、この分布からサンプルを生成する必要があります。基本的な形として,比率推定量には偏りがあるが,整合性を保ちつつ,より低い分散をもたらすことができるため,よく好まれています。これらの推定量を完全に不偏にすることについては,かなり研究がなされていますが [Hadscomb 1964; Hartley and Ross 1954; Mickey 1959; Rao and Beegle 1967; Worthley 1967], 我々の知る限り,このテーマはまだグラフィックスでは検討されていません。付録Bでは,WUSとWISが比率推定量の特殊なケースに過ぎないこと,そしてRIS [Talbot et al.2005]がこれらの推定量を不偏にする方法と見なすことができることを証明します。
(Weighted) reservoir sampling. RISなどの再サンプリングに基づくサンプリングアルゴリズムの実装では、通常、1つ以上のサンプルが選択されるまで、すべての候補サンプルを保存しておく必要があります。これはメモリを大量に消費し、GPUのような高度に並列化されたアーキテクチャでは、しばしば法外なメモリ消費量となります。この課題は、数十年にわたり、さまざまな文脈で存在してきました。一般に、ストリーミングアルゴリズムでは、未知の長さのリストから確率的に選択する必要があることが多いです。レゼバーサンプリング[Chao 1982; Vitter 1985]は、テープドライブに保存されたデータを、ランダムアクセス、巻き戻しによる再読込、メモリへの全保存なしにランダムに選択する方法として1980年代初頭に出現しました。重み付き変数は様々な確率でアイテムを選択することができ、多くのドメイン(例えば、ネットワーキング)で適用されており、アルゴリズムの複雑さと統計的特性の改善を求める研究が続いています(例えば、Efraimidis [2015]; Efraimidis and Spirakis [2006] )。グラフィックスではほとんど知られていないが,最近,このアルゴリズムは確率的順序非依存透明化[Wyman 2016]とVPLの階層からの照明[Lin and Yuksel 2019]のために再発明されています。我々はストリーミングRISアルゴリズムにレゼバーサンプリングを使用し,高性能なGPU実装を可能にしている。
Denosing/reconstruction. ノイズ除去や再構成では、パスやサンプルの再利用が頻繁に行われます。高次元サンプルから再構成するアプローチもありますが [Hachisuka et al. 2005]またはバイラテラル[Tomasi and Manduchi 1998]などの従来の画像ノイズ除去フィルタに依存し、補助バッファによって導かれ、しばしば何らかの回帰アプローチによって画像特徴からMCノイズを曖昧にします[Bitterlie et al.2016; Hachisuka et al.2008; Kalantari et al.2015; Lehtinen et al.2011, 2013; Moon et al.2014,2015,2016; Rousselle et al.2016,2011,2012, 2013]。Zwickerら[2015]の最近の調査は、これらをより深くカバーしています。デノイジングは、MCの遅い収束のテールを短絡させる能力により、大部分は映画におけるオフラインのパストレーシングへの移行を可能にしました [Christensen and Jarosz 2016]。
インタラクティブなMCノイズ除去の研究は最近加速しており、フィルターのシーケンス[Mara et al. 2017]に加えて、マルチスケール[Dammertz et al. 2010]、深層学習[Chaitanya et al. 2017; NVIDIA Reserach 2017]、ガイド付き[Bauszat et al. 2011; He et al. 2010] 時空フィルタ[Schied et al. 2017, 2018] 、ブロックワイズ回帰フィルター [Koskela et al. 2019]が探索されています。これらのアプローチは我々の研究とほぼ直交しており、収束のために十分なサンプルがとれない場合に我々の技術の出力を改善するために適用することができます(図2参照)。
8 CONCLUSION
我々は、再サンプル重点サンプリングの一般化に基づいて、直接照明のための新しいモンテカルロ手法を導入しました。これは、近傍のサンプルの不偏の空間的・時間的再利用を可能にし、さらに効率的なバイアス付き変種を導くものです。我々のアルゴリズムは、従来のアプローチと比較して、1~2桁の誤差の減少を実現し、また、単純な画像空間のデータ構造のみを必要とします。我々は、このアルゴリズムが高性能GPU実装に適していることを示し、数千から数百万の動的光源を持つシーンのリアルタイムレンダリングを導くを示します。
この技術は、フィルタリングやノイズ除去をレンダリング終了後のポストプロセスとして残す必要がないことを示したと言えます。つまり、ノイズ除去をレンダリングの中核に据え、色ではなくPDFをフィルタリングしているのです。このことは、これまで特殊な(そしてしばしば注意深く手作業で調整された)ポストプロセスであり続けたノイズ除去アルゴリズムの今後の開発に拍車をかける重要な洞察であると考えています。また,本アルゴリズムの出力の特徴に適応した,あるいは,個々の可視性候補値のような本アルゴリズムが提供できるユニークな特徴を利用した新しいポストプロセス・デノイジング・アプローチを開発することも価値があると思われます。
8.1 Limitations and Future Work
サンプルの再利用に依存する他のアルゴリズムと同様に、本手法は画素間の補正を利用して画質を向上させることに依存しています。このような機会がない場合、例えば、ディスオクルージョンの近く、ライティングの不連続性、高い幾何学的複雑性、速く動くライトなどは、我々の方法の品質は低下し、入力サンプルと比較してノイズ除去は控えめになる。このような困難なケースでも、我々の方法は先行研究よりも良いパフォーマンスを示していますが、再利用が不可能なケースに対して我々の方法をより堅牢にすることは、今後の研究にとって実りある方向性です。また、ノイズ除去などの後処理と異なり、本手法には追加サンプルを追跡する機会が残されており、本手法がどこで失敗したかを判断し、その領域に追加サンプルを割り当てるような指標を模索することも興味深いです。
我々のアルゴリズムの主なデータ構造は、画像バッファで構成されています。このため、本手法は高速かつシンプルでメモリ効率に優れていますが、カメラパスの最初の頂点(すなわち、プライマリヒットポイント)に対する操作に使用が制限され、最初のヒットを超える直接照明やグローバル照明に容易に拡張することができません。プライマリーヒットにおける直接照明はインタラクティブなアプリケーションにおいて重要な問題ですが、我々のアルゴリズムをスクリーン空間を越えて拡張することは、今後の重要な研究分野です。特に興味深いのは、我々の空間的、時間的リサンプリングアルゴリズムをワールド空間データ構造に適用することです。パス空間ハッシュ[Binder et al. 2019]などのアルゴリズムは、この文脈で有用である可能性があります。もう一つの可能性は、我々の再サンプリングアプローチと、Bekaertら[2002]やその後の研究で開発されたようなパス再利用アルゴリズムとの組み合わせを検討することです。
最後に、今回のGPU実装はインタラクティブなレンダリングを対象としていますが、このアルゴリズムはオフラインのレンダリングにも同様に適用できます。単一の静止画をレンダリングするとき、または、多くのコンピュータ上でフレームのシーケンスを並列化するときに、時間的な情報が利用できないかもしれませんが、途中でいくつかの可視性チェックを実行する空間再サンプリングの追加のラウンドは、我々の時空間再利用と同様の品質のサンプルを提供すると推定されます。さらに、レゼバーを維持する粒度を調査する価値があります。ピクセルの画像サンプルが互いに遠く離れたシーンの部分と交差する場合、複雑なジオメトリではピクセル粒度は最適でないと思われますが、個々の画像サンプルの粒度は法外なメモリコストを持っているかもしれません。これらの2つの考慮事項のバランスを取るクラスタリングアプローチが効果的である可能性があります。
A EXPECTED RIS WEIGHT
式(18)を展開すると、(分子と分母の重みの和がキャンセルされる)以下のようになります。
\begin{eqnarray}
\frac{1}{p(y)} \sum_{i \in Z(y)} \int \cdots \int \frac{1}{{\hat p}(x_i)} \left[ \frac{\sum_{j=1}^M {\rm w}_j(x_j)}{M} \right] \left[ \frac{{\rm w}_i(x_i)}{\sum_{j=1}^M {\rm w}_j(x_j)} \right] \left[ \prod_{j=1}^M p_j(x_j) \right] dx_1 \cdots dx_M \tag{23}
\end{eqnarray}
積分変数に依存しないすべての項を外側に出すと、次のようになります。
\begin{eqnarray}
= \frac{1}{p(y)} \sum_{i \in Z(y)} \frac{p_i(x_i)}{{\hat p}(x_i)} \frac{{\rm w}_i(x_i)}{M} \underbrace{ \int \cdots \int \prod_{x_j \in x \ x_i} p_j(x_j) dx_1 \cdots dx_M }_{1} \tag{24}
\end{eqnarray}
すべてのPDF候補の残りの積分(\(y\)に固定される\(x_i\)を除く)は、単純に1です。これで単純化して \({\rm w}_i(x) = {\hat p}(x)/p_i(x)\) とすることができます。
\begin{eqnarray}
= \frac{1}{p(y)} \sum_{i \in Z(y)} \frac{p_i(x_i)}{{\hat p}(x_i)} \frac{{\rm w}_i(x_i)}{M} = \frac{1}{p(y)} \sum_{i \in Z(y)} \frac{1}{M} = \frac{1}{p(y)} \frac{|Z(y)|}{M} \tag{25}
\end{eqnarray}
B WEIGHTED, RATIO AND RESAMPLING ESTIMATORS
あるリソースPDF \(p\)からサンプルを抽出する重点サンプリング(3)に対して、重み付き一様サンプリング(WUS)[Powell and Swann 1966]はサンプル\(x_i\)を一様に抽出し、計算するものです。
\begin{eqnarray}
\langle L \rangle_{\rm wus}^N = \sum_{i=1}^N f(x_i) / \sum_{i=1}^N {\hat p}(x_i) \approx F, \tag{26}
\end{eqnarray}
ここで \({\hat p}(x)\) は理想的には \(f\) と相関のある正規化 PDF です(ただし、サンプル \(x_i\) は一様に生成されることに注意)。
重みづけ重点サンプリング (WIS) [Bekaert et al. 2000] は、ISとWUSを組み合わせたものです。
\begin{eqnarray}
\langle L \rangle_{\rm wis}^N &=& \sum_{i=1} w_i, \quad {\rm with} \quad w_i = \frac{w(x_i)}{\sum_{j=1}^N w(x_j)}, \quad w(x) = \frac{{\hat p}(x)}{p(x)} \tag{27} \\
&=& \sum_{i=1}^N \frac{f(x_i)}{p(x_i)} / \sum_{i=1}^N \frac{{\hat p}(x_i)}{p(x_i)} \approx F, \tag{28}
\end{eqnarray}
ここで,サンプルはサンプリングが容易なソースPDF \(p(x_i)\) から抽出され(ただし,定数倍までしか知る必要がない),ターゲットPDF \({\hat p(x)\) は,適切に正規化されている限り,実用的なサンプリングアルゴリズムが存在しないPDFでもかまいません.重み付き一様サンプリングは、\(p\)が定数PDFである場合に対応します。式(27)は,\(N\)の有限な値に対して偏りがありますが,\(N \rightarrow \infty\)として偏りと分散がゼロになることを意味し,整合的です。
比率推定[Hartley and Ross 1954; Heitz et al. 2018]では、期待値\({\bar Z}\)が既知である正相関の確率変数\(Z\)を活用して、確率変数\(Y\)の期待値\({\bar Y}\)を推定することが目標です。古典的な、偏った、比率推定器は、N個のサンプルペア\((y_i,z_i)\)を引き、計算します。
\begin{eqnarray}
\langle {\bar Y} \rangle_{\rm rat}^N = {\bar Z} \sum_{i=1}^N y_i / \sum_{i=1}^N z_i \approx {\bar Y} \tag{29}
\end{eqnarray}
Equivalence of ratio estimation and WIS. 確率変数\(Y=f(x)/p(x)\)と\(Z={\hat p}(x)/p(x)\)を定義すると、WIS(28)は次のように書くことができます。
\begin{eqnarray}
\langle L \rangle_{rm wis}^N = \sum_{i=1}^N y_i / \sum_{i=1}^N z_i, \tag{30}
\end{eqnarray}
これは、WIS では \({\hat p}\) が正規化されていると仮定しているため、比率推定量 (29) と等価です。
\begin{eqnarray}
{\bar Z} = \int_D \frac{{\hat p}(x)}{p(x)} p(x) dx = \int_D {\hat p}(x) dx = 1 \tag{31}
\end{eqnarray}
Relation of RIS to WIS. WIS (27) では、\(N=1\) とするか、\(N \gt 1\) の場合は、\(w_i\) で決まる確率で一つのサンプル \(y \in \{x_1, \cdots, x_N\}\) を選択し、一つの総和のみを確率的に評価することを考えます。その結果、1標本のWIS推定量は、RIS (6)と驚くほど似てくるので、便宜上、再掲する。
\begin{eqnarray}
\langle L \rangle_{\rm wis}^{1} = \frac{f(y)}{{\hat p}(y)}, \quad {\rm whereas} \quad \langle L \rangle_{\rm ris}^{1, M} = \frac{f(y)}{{\hat p}(y)} \cdot \left( \frac{1}{M} \sum_{j=1}^M {\rm w}(x_j) \right) \tag{32}
\end{eqnarray}
この2つの推定量を比較すると、WISは単純に重みの平均項\(\langle w \rangle^M \equiv \frac{1}{M} \sum_{j=1}^M w(x_j) = \frac{1}{M} \sum_{j=1}^M {\hat p}(x_j) / p(x_j)\)を除いたRISであることがわかる。これは、式(31)における対象分布の正規化係数の不偏MC推定量に過ぎない。RIS(6)が不偏であることがわかるので、この因子がバイアス補正項として作用することがわかる。
本質的には,\(f(y)/{\hat p}(y)\)を評価することによって,RISは最初にターゲット分布\({\hat p}\)由来の\(y\)場合のように,標準MC推定器(3)を形成します。RISは次に\(\langle w \rangle^M\)を用いて、この近似分布と\({\hat p}\)の正規化を補正します。重要なことは、\(f(y)/{\hat p}(y)\)と相関のあるサンプル\(x_j\)を用いてこれを行うことです。 このRISの相関再正規化は、WISを不偏にする方法と見なすことができます。