こんにちわ、Pocolです。
今日は,
[Xie 2020] Tiantian Xie, Marc Olano, Brian Karis, Krzysztof Narkowicz, “Real-time subsurface scattering with single pass variance-guided adaptive importance sampling”, I3D 2020.
を読んでみることにします。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳と共に指摘していただけると幸いです。
ABSTRACT
リアルタイムでの応用では、半透明度の異なるリアルな表面下散乱をシミュレーションすることは困難です。Burleyの反射率近似は、経験的に拡散プロファイルを全体的にフィッティングすることで、スクリーン空間において異なる半透明材質に対してリアルな表面下散乱を実現することができます。しかし、物理的に正しい結果を得るには、フレームごととピクセルごとに解析的重要度関数をリアルタイムでモンテカルロサンプリングする必要があり、その実現は困難であると思われます。本論文では、リアルタイムに評価可能な重要度関数の近似を提案します。また,光勾配の変化など特定の領域で表面下散乱が顕著になるため,時間分散に基づく適応的なサンプリング手法を提案し,必要なサンプル数を低減させます。不偏的で、動きや照明によるシーンの変化に適応できる1フェーズの適応的サンプリングパスを提案します。さらに品質を向上させるために、最終的な時間アンチエイリアス(TAA)段階の前のガイドパスによる時間的再利用を検討し、さらに品質を向上させます。我々のローカルガイドパスは、TAAの実装を制約せず、フレーム間で渡される追加のテクスチャを1つだけ必要とします。提案する分散ガイドアルゴリズムは、ストキャスティックサンプリングアルゴリズムをリアルタイムレンダリングに有効なものにする可能性を持っています。
1 INTRODUCTION
表面下散乱は、リアルタイムアプリケーションで要求される機能です。特にゲームでは、半透明のマテリアル(肌、ヒスイ、ワックス、果物、大理石など)の外観を作り出し、現実世界のマテリアルを模倣したり、想像上のマテリアルを作り出したりするために使用されます。表面下散乱の完全な評価は、表面下散乱イベントの高価なモンテカルロ(MC)シミュレー ションに依存しています[Phar and Hanrahan 2000]。ダイポール拡散近似 [Jensen et al. 2001] は、効率的な表面下のレンダリングを可能にする主な要因でした。テクスチャスペース[d’Eon and Luebke 2007],事前積分[Penner and Borshukov 2011],スクリーンスペース表面下散乱[Jimenez et al.2009, 2015]などの方法は,リアルタイムアプリケーションのためのダイポールモデルの高速近似を提供しようとするものです.より最近では,Burleyが2つの単純な解析方程式の和をモンテカルロデータに直接適合させました[Burley 2015; Christensen and Burley 2015]。彼の定式化は、単純な重要度サンプリング関数を提供しますが、密度関数として、ゼロ散乱半径の近くで無限大になるので、他のリアルタイムモデルで使用される直接の畳み込みには問題があります。最近の優れた研究[Golubev 2018]は、事前に計算されたサンプリングとパターン回転の妥協で、スクリーン空間にこのメソッドをもたらしました。
本研究では、事前に計算されたサンプリングを用いず、Burleyの近似式を用いて、スクリーン空間におけるピクセル単位のリアルタイム確率的MCサンプリングを導入します。主な実現手段は、我々が提案する近似重要度関数と、フレーム間で1つの時間的再利用テクスチャを維持したまま、各フレームにサンプルを分配することができる新しいシングルパス分散ガイド適応型サンプリングアルゴリズム(SPVG)です。適応サンプリングが表面下散乱に役立つ主な理由は、サンプル数の要件にスパース性があることであり、これは既に素晴らしい事前積分表面下散乱法へとつながっています。とはいえ、本論文では、解決すべき3つの難題があります。
1) オンラインで効率的にサンプルを作成すること。 Burleyの近似でサンプリングするための累積密度関数は、反復ソルバー(ニュートンやヘイリー法など)、2つの重要度関数の多重点サンプリング、各サブサーフェイスプロファイルのLUT、またはリアルタイムレンダリングに望むより高価な解析的逆関数のいずれかを必要とします。我々は、オンラインで評価するのが簡単な逆関数の近似を提示します。
2) 1パス適応型サンプリングアルゴリズムを設計する。 古典的な適応型サンプリングアルゴリズムは、2つのフェーズで構成されており、サンプル棄却はリアルタイムアプリケーションには非効率的であり、最初のフェーズでサンプル数が少ないためにバイアスが発生する可能性があります。通常、最初のフェーズでは、分散を決定するためにサンプルを収集し、その後、バイアスを避けるために棄却されます。第二段階では、分散を減らすために適応的なサンプル数を使用します。最近の研究では、2つのサンプルセットを多重点サンプリング問題として提起することで、すべてのサンプルを使用しようとしています[Grittmann et al.2019]。本論文では、個々のサンプルを利用する表面下散乱のための1つの適応的なサンプリングガイドパスとします。具体的には、各フレームでのサンプル分散を指数移動分散に基づいて時間バッファに連続的に更新します。この分散は、時間的再利用により、前フレームの画素状態を反映し、確率的サンプリングのための目に見える偏りなしに、次フレームのサンプル数を制御することが可能です。
3) アルゴリズムを汎用化する。 リアルタイムレンダリングではフレームあたりのサンプル数が多すぎて困るので、最近1サンプル/ピクセルパストレーシングの品質向上のために検討されているテンポラルリユースを利用します[Schied et al.2017]。ただし、この処理は既存のレンダリングエンジンに変更を加えています。テンポラルアンチエイリアシング(TAA)のような既存のテンポラルリユースパスがあることを仮定して、しかしそのテンポラルリユースパスの実装に関する仮定なしに、時間情報を利用し、ゴースト、ブラーリング、ラグ、フリッカーなどのアーティファクトを解決しようとする限り、表面下散乱を導くためのパスを追加して異なる方法で探求しています。
我々の貢献は次を含みます:
- Burley重要度関数を近似し、表面下散乱をリアルタイムでサンプリングします。
- 我々は、リアルタイムで表面下散乱を高速化するために適した1パス適応サンプリング法を提示します。この方法は、要求される領域に適応的にサンプルを集中させ、不要な部分はサンプルを削減します。また、既存のTAAプロセスを活用して品質を向上させますが、そのTAAの実装には制約がありません。その結果、最大で91.07倍の高速化を実現しました。すべてのテストシーンにおいて、適応的サンプリングは、固定サンプリングと比較して2倍から6倍の高速化を実現しました。
- 確率的サンプリングプロセス(表面下散乱)用の分散ガイドパスは、ピクセル単位のフレーム品質管理を可能にするために、1つのテクスチャを追加するだけで済みます。我々のアルゴリズムは一般的であり、他のアルゴリズムにも容易に実装することができます。また、オフラインの適応的重要度サンプリングにも応用できる可能性があると思われます。
2 RELATED WORK
私たちの研究は、リアルタイムの表面下散乱、適応型レンダリング、テンポラルリユースに重点を置いています。オフラインレンダリングのためのサブサーフェススキャッタリングは、本論文の範囲外です。
リアルタイムサブサーフェイススキャッタリング. 表面下散乱の初期のレンダリングアルゴリズムは、放射伝達方程式を解くためにモンテカルロパストレーシングを使用していました。双方向散乱-表面反射分布関数(BSSRDF)[Nicodemus et al. 1977]を導入してサーフェイス領域へのサブサーフェス積分を単純化しても,これらのアルゴリズムは当時のハードウェアでは画像生成に数時間かかっていました。Jensenは、BSSRDFの光拡散モデルとして、ダイポール近似[Jensen et al.2001]とマルチダイポール近似[Donner and Jensen 2005]を導入しました。より単純なダイポール法は、高散乱媒質における等方的な表面下散乱のみを考慮しますが、拡散反射率プロファイルを導入し、コンパクトな表現と効率的な評価を可能にしました。
拡散プロファイルを使用する場合、リアルタイムレンダリングの複雑さを軽減するために、オンラインサンプリングと事前積分という2つの異なる方向性があります。オンラインサンプリングは,表面下散乱がアーティストフレンドリーカーネルの加重和 [Borshukov and Lewis 2005] またはダイポールベースのガウスカーネル [d’Eon et al. 2007] によって近似できることを前提に設計されています。サンプル数は,ディファードレンダリング後にテクスチャ空間からシフトすることでさらに削減されます[Jimenez et al. 2009, 2015]。対照的に,事前積分法は,光勾配の変化があるときに表面下散乱が見えるという仮定[Penner and Borshukov 2011]と影への距離が正しく再構成されることができるという仮定に基づいて,ダイポール近似に基づくオンラインサンプリングをテクスチャルックアップにオフロードします。
物理的に正しいサブサーフェイスレンダリングの最近の進歩は、すでに近似であるダイポールモデルをフィットさせる代わりに、モンテカルロの結果に近似をフィットさせます[Christensen and Burley 2015]。この手法は,最近,事前計算済みサンプリングを用いてUnityゲームエンジンに取り入れられました[Golubev 2018]。本研究では,リアルタイムの表面下散乱に利用可能な重要度サンプリング関数の近似を提案します。
適応的レンダリング. 適応的レンダリングは、サンプリング密度やフィルタリングを調整し、効率を向上させます。疎な線形モデルと最適なサンプリングウィンドウが再帰的に更新され,隣接するピクセルを最適に再構成します[Moon et al.2015]。誤差推定器により,高分散領域へのサンプリングがガイドされます。適応的サンプリングアルゴリズムは,最適化関数を解くために,例えばパストレーシングのための勾配領域[Manzi et al.2016]では,しばしば大きなメモリと計算能力を必要とします。一般的に、2回のパスが必要とされます[Moon et al. 2014]。最初のフェーズでは、少数の均一なサンプルが誤差を収集するために割り当てられます。2回目のパスでは,1回目のパスでのエラーメトリクスに基づいて追加のサンプルが割り当てられます。我々は、フレーム間で1つの追加のテクスチャを格納する必要があるだけで、計算オーバーヘッドが少ないシングルパス適応型サンプリングモデルを提案します。提案された1パスモデルは、ダイナミックな光と動きの変化を拾い上げ、効果的にサンプルを調整することができます。
テンポラルリユース. リアルタイムレンダリングでは、高い時空間的なコヒーレンスを実証しています [Scherzer et al. 2012]。 このコヒーレンスは,テンポラルアンチエイリアシング [Karis 2014] (TAA) や,コストを償却してレンダリング品質を向上させるためにシェーディングやジオメトリ情報との累積に利用されてきました。文献で扱われている主な問題は,履歴を現在のフレームとブレンドする指数移動平均の使用と,それらが同じオブジェクトからのものかどうかを見分けるためのヒューリスティックによるブラー,ゴースト,ラグ,フリッカー[Iglesias-Guitian et al.2016; Patney et al.2016; Xiao et al.2018] です。
また、時間的な情報は他のシステムと統合し、サンプルコストの償却も行っています。最近の研究では,ゴーストやブラーが分散と深度に基づいて検出される場合,TAAの結果をレイトレーシングに置き換えます[Marrs et al. 2018]。時空間分散ガイドフィルタ(SVGF)法は、ジオメトリ情報と画像空間ウェーブレットフィルタを含み、ピクセルあたり1サンプルのリアルタイムパストレーシングを実現します[Schied et al.2017]。Schiedら[2018]は、SVGFを使用する際に、速い光の変化によるシーンの時間的安定性を向上させる(時間的なオーバーブラーを減らす)ために、時間的勾配に基づいて指数重みを適応的に変更しています。
本研究では、時間的に蓄積された分散と有効サンプル数によって、確率的サンプリングプロセスをガイドします。これにより、ピクセルあたりの品質要件と時間予算を満たすために、サンプル数を償却することができます。これは、既存のTAAプロセスを変更したり、その実装を制限したりすることなく、より安定で低分散な入力をTAAプロセスに提供し、フレーム間でサンプルを結合するためにTAAに依存したまま行うものです。線形モデルと逆共分散行列が分散情報を提供するために再帰的最小二乗法によって適合される既存の研究[Iglesias-Guitian et al. 2016]とは異なり、我々はフレーム間で渡される1つの追加のテクスチャのみを必要とする軽量のアルゴリズムを使用します。
3 BACKGROUND
リアルタイムレンダリングで使用される表面下散乱と時間的アンチエイリアシングについて簡単に説明します。
3.1 Subsurface scattering
サーフェイス点\(p\)において、方向\(\omega_o\)に対する出射照度は次のとおりです。
\begin{eqnarray}
L_o (p, \omega_o) = \int_{\partial \Omega} \int_{{\rm S}^2} L_i (q, \omega_i) S(q, \omega_i, p, \omega_o) d \omega_i dq, (q \in \partial \Omega) \tag{1}
\end{eqnarray}
ここで\(S\)は双方向散乱表面反射率分布関数(BSSRDF)です。均質な半無限平面媒質において半径方向に対称な\(S\)を仮定すると、式1は次のように簡略化されることが多いです。
\begin{eqnarray}
S(q, \omega_i, p, \omega_o) = C F_t (q, \omega_i) R(r_q) F_t(p, \omega_o) \tag{2}
\end{eqnarray}
ここで,\(r_q = || p – q ||\)で,\(F_t(\cdot)\)は方向フレネル透過項で\(C\)は定数項です。そして、\(p\)における光束反射方向\(\omega\)が与えられた場合、サーフェイス点\(p\)において対称な拡散プロファイルを持つ簡略化された表面下散乱関数は次のようになります。
\begin{eqnarray}
L_o(p, \omega) = \int_{\partial \Omega} 2 \pi r_q R(r_q) \cdot \int_{{\rm S}^2} CF_t(p, \omega) F_t(q, \omega_i) L_i(q, \omega_i) \langle \omega_i, n_q \rangle d \omega_i d r_q \tag{3}
\end{eqnarray}
この数式を使うには、例えば、ディファードレンダリングで、内部積分をすべてのライトの放射照度テクスチャに事前計算することができます。外側の積分は、ポストプロセッシングパスとして実装することができます。この論文では、我々の積分の効率的なサンプリングに焦点を当てます。
Burleyのプロファイル近似. 文献では、ほとんどの研究が\(S\)を単一散乱、多重散乱、および/または放射輝度減少項\(S = S^{(0)} + S^{(1)} + S_d\)に分解し、それらを別々に処理します[Hable et al. 2013]。
代わりに、Christensen and Burley [2015]は、すべての散乱項を含む経験的MCシミュレーションデータに基づいて拡散反射率プロファイル\(R(\cdot)\)を直接近似しています。\(R(\cdot)\)は、次のように距離\(r\)の観点から2つの指数関数の和でうまく近似することができます。
\begin{eqnarray}
R(r) = A \frac{e^{-r/d} + e^{-r/(3d)} }{ 8 \pi d r } \tag{4}
\end{eqnarray}
ここで、\(A\)は\(A = \int_0^{\infty} R(r) 2 \pi r dr\)によるサーフェイスアルベドです[Jensen and Buhler 2005]。\(d\)項は、コンフィギュレーション\(\Theta\)に基づく自由行程長パラメータ\(\ell\)に適合させます。
\begin{eqnarray}
d = \begin{cases} \ell / (1.85 – A + 7 |A – 0.8|^3) & \Theta = \Theta_1 \\
\ell / (1.9 – A + 3.5 (A – 0.8)^2) & \Theta = \Theta_2 \tag{5} \\
\ell / (3.5 + 100 (A – 0.33)^4) & \Theta = \Theta_3
\end{cases}
\end{eqnarray}
ここで,我々は次を得ます:
(1) サーチライト設定(\(\Theta = \Theta_1\))。光はサーフェイスに対して垂直にボリュームに入射します。\(\ell\)は体積平均自由行程です。
(2) 拡散表面透過(\(\Theta = \Theta_2\))。\(\ell\)は理想的な拡散透過後のラフマテリアルの体積平均自由行程です。
(3) パラメータとしての拡散平均自由経路(\(\Theta = \Theta_3\))。\(\ell\)はサーフェイス上の拡散平均自由行程です。
我々は一般的なゲーム用途のために、よりアーティストフレンドリーである\(\Theta_3\)を選択しました。
3.2 Temporal Anti-aliasing
テンポラルアンチエイリアシング (TAA) [Karis 2014] は、リアルタイムレンダリングエンジンにおけるアンチエイリアシングのデファクトスタンダードです。これは、ジッタリングされたピクセルごとに色空間の連続したフレームを蓄積するために、指数移動平均で時間にわたってサンプリングを償却します。オブジェクトが移動すると,TAAは蓄積された履歴バッファからピクセルごとの速度ベクトルに沿ってサンプルを再投影します。それを以下のようにまとめます
\begin{eqnarray}
\mu_i = (1 – \alpha) {\mathcal C}(x_i, \Lambda) + \alpha {\mathcal S}(p_i); \quad \alpha = {\mathcal M}(\alpha_0, \Lambda); \quad p_i = {\mathcal N}(x_i, f(i)), \tag{6}
\end{eqnarray}
ここで、\(\mu_i\) はフレーム \(i\) の画素 \(x_i \in {\mathbb R}^2\) における推定値です。\(\alpha\)は、クランプされた履歴コンテキスト項\(\mathcal C\)と現在のフレームのシェーディング項\(\mathcal S\)との間の指数関数的な重みです。 \(\alpha\)は、ユーザ定義の最大重みα\(\alpha_0\)と、速度、ジオメトリタイプ(例えば、透明か否か)、近隣などを含むコンテキスト\(\Lambda\)に基づいて重み更新関数\(\mathcal M\)によって計算されたピクセル単位の指数関数的な移動平均の重みです。\(\mathcal C\) は、\(x_i\) から投影された履歴を再サンプリングして棄却する演算子です。\(\mathcal C\)と\(\mathcal M\)の両方は,アンチエイリアシングの結果を維持しながら,アーティファクト(すなわち,ゴーストブラーリング,ラグ,フリッカー)を最小化するように設計されています[Karis 2014; Yang et al.2009]。
\(\mathcal S\)は\(p_i\)におけるシェーディング関数で、\(p_i\)はピクセル位置\(x_i\)とフィルタカーネル重要度サンプリングオフセット\(f\)から近傍サンプリング関数\(\mathcal N\)によって計算されたジッターされたピクセル位置です。
複数フレームに渡るMC結果を蓄積するために使用する場合、\(\mathcal C\)と\(\mathcal M\)が行うクランプとリジェクトは、MCプロセスを明示的に考慮するように修正するか、\(\mathcal S\)に入ってくる分散をそのリジェクトモデルに合うように減らす必要があります。最近のゲームエンジンでは、TAAは、光沢反射、アンビエントオクルージョン、シャドウイング、および表面下散乱を含む多くのMCプロセスからサンプルを蓄積するために使用されます。TAAによって実行される複数の種類の蓄積を考慮すると、単独で使用される1つのMC手法のためにクランピングと拒絶モデルを修正する方法は効果的ではありません。本論文では、既存のTAA処理に手を加えることはしません。その代わりに、式6から始まる1つの局所的な分散誘導フェーズを作成し、フレームごとにピクセルごとの適応的なサンプリングカウントを出力します。サンプリング結果は標準的なポストプロセスパイプラインに送られ、既存のTAAを使用してさらに品質を向上させます。
4 VARIANCE-GUIDED MC SAMPLING
MCサンプリングをリアルタイムで効率的に利用するためには、2つの課題があります。Ⅰ) 目標品質レベルに到達するための最小限のサンプル数、Ⅱ) 効率的なオンラインサンプル生成です。
4.1 Minimal sample count estimation
最小限のサンプル数を推定するためには、知覚可能なノイズが多く、少ないサンプル数で十分な場合に、適応的にサンプル数を増加させる指標が必要です。
4.1.1 Basic Metric
次の最小限のサンプル数を推定します。
\begin{eqnarray}
n_{(i)} = max \left( \sigma^2_{M_{(i-1)}} \cdot n_{(i-1)} / \sigma^2_o, \beta_{(i-1)} \right) \tag{7}
\end{eqnarray}
ここで、\(n_{(i-1)}\)は前のフレームで推定された最小サンプル数,\(\sigma^2_{M_{(i-1)}}\)は前のフレームで推定された分布平均のピクセル分散です。この式の目的は、分布の平均の分散を目標レベル\(\sigma^2_0\)まで小さくすることです。照明の関係や、サンプル数が少ないと細部を見落とす可能性があるため、必ず\(\beta_{(i-1)}\)以上のサンプルを使用します。
動きや照明の状態により、ピクセルごとの正確な分布はわかりませんが、中心極限定理により、有限の平均と分散の母集団が与えられると、平均のサンプリング分布\(\mu_M\)は、元の分布の形状にかかわらず、サンプルサイズが大きくなると\((\mu, \sigma^2/N)\)の正規分布となります。したがって、フレーム間で繰り返しサンプリングされる分布として、平均の分散を推定することができます。
このアルゴリズムを使用して,2つのフェーズで最小限のサンプル数を決定することは,やはり非効率です(つまり,最初のパスで,分散を収集するためにサンプルを収集し,2番目のパスでレンダリングのためにサンプル数を推定する)。そこで、TAAから時間的蓄積の考え方を採用し、1フレームあたりのサンプル数を減らし、1パス適応型サンプリング手法とします。
4.1.2 Metrics within Temporal Accumulation.
各フレームのサンプル数を減らすために、分散とサンプル数の推定をローカルフェーズで行います。式(6)を用いて、ジッタリングされたピクセル値に対する指数移動平均(EMA)を計算します。\(\alpha\)が十分に小さい場合、最終的に母平均である\(\mu_M = \mu\)に収束します[Karis 2014]。3チャンネル全てを記録するのではなく、人間の知覚を考慮し、ガンマ補正した輝度の移動平均を記録しています。フレーム\(i\)のサンプル数\(n_{(i)}\)がわかっているので、平均サンプル数\({\bar n}_{(i)}\)を次のように推定します。
\begin{eqnarray}
{\bar n}_{(i)} = (1 – \alpha) {\bar n}_{(i-1)} + \alpha n_{(i)} \tag{8}
\end{eqnarray}
そして、指数移動分散(EMV) [Finch 2009] での母分散 \(\sigma^2\)を次とします。
\begin{eqnarray}
\sigma^2_i = (1 – \alpha) \sigma^2_{i-1} + \alpha(1 – \alpha)({\mathcal S}(p_i) – {\mathcal C}(x_i, \Lambda))^2 \tag{9}
\end{eqnarray}
このように、サンプル数を蓄積していくことで、式(7)を解くことができます。ここで\(\beta_{(i-1)}\)は無視し、\(n_{(i)}\)を取得してから設定することができます。連続した\(k\)フレームを蓄積すると、式は次のようになります。
\begin{eqnarray}
\sum_{i-k+1}^{i} n_{(j)} = \frac{\sigma^2_{M_{(i-1)}} \sum_{i-k+1}^i n_{(j-1)} }{ \sigma^2_0} \tag{10}
\end{eqnarray}
このとき,現在のフレームの推定サンプル数は次のようになります。
\begin{eqnarray}
{\hat n}_{(i)} &=& \sum_{i-k+1}^i n_{(j)} – \sum_{i-k+1}^i n_{(j-1)} + n_{(i-k)} \tag{11} \\
& \approx & \frac{ (\sigma^2_{M_{(i-1)}} – \sigma^2_0) }{ \sigma^2_0} \cdot {\bar n}_{(i-1)} \cdot k + {\bar n}_{(i-1)} \tag{12} \\
&=& \frac{ (\sigma^2_{M_{(i-1)}} – \sigma^2_0) }{ \sigma^2_0 } \cdot {\bar n}_{(i-1)} \cdot (k-1) + E({\bar n}_{(i)}) \tag {13}
\end{eqnarray}
EMAやEMWを使っているため,\(n_{(i-k)}\)を維持できないので、\({\bar n}_{(i-1)}\)で近似しています。そして、金融データの分析において一般的なN-day EMAと単純移動平均の変換に基づいて、\(k\)を\(k = 2 / \alpha – 1\)として推定します[Bauer and Dahlquist 1998]。式13は、式10より導かれたフレーム\(i\)における期待標本平均\(E({\bar n}_{(i)}) = \sigma^2_{M_{(i-1)}} / \sigma^2_0 \cdot {\bar n}_{(i-1)}\)に補正項を加えたものです。\(| \sigma^2_{M_{(i-1)}} – \sigma^2_0 |\)が大きい場合、1フレームで積極的に分散を目標値まで減らすために、この補正項は非常に大きくなります。そこで、フレーム毎の補正を制限するために制御係数\(\kappa\)を加えます。このとき、式.13に基づく最終式は次のようになります。
\begin{eqnarray}
{\hat n}_{(i)} &=& \kappa \cdot \Delta (i) + E({\bar n}_{(i)}), \quad \kappa \in [0, 1] \tag{14} \\
\Delta (i) &=& \frac{ (\sigma^2_{M_{(i-1)}} – \sigma^2_0) }{ \sigma^2_0 } \cdot {\bar n}_{(i-1)} \cdot (k-1) \tag{15}
\end{eqnarray}
ここで、\(\Delta(i)\)は補正項です。\(\kappa=1\)では、フレームあたりの最大サンプルバジェットまで起動する代償として、より速い収束を優先し、\(\kappa=0\)では、十分なサンプルを蓄積するために時間を使用します。
4.1.3 Circle scenario.
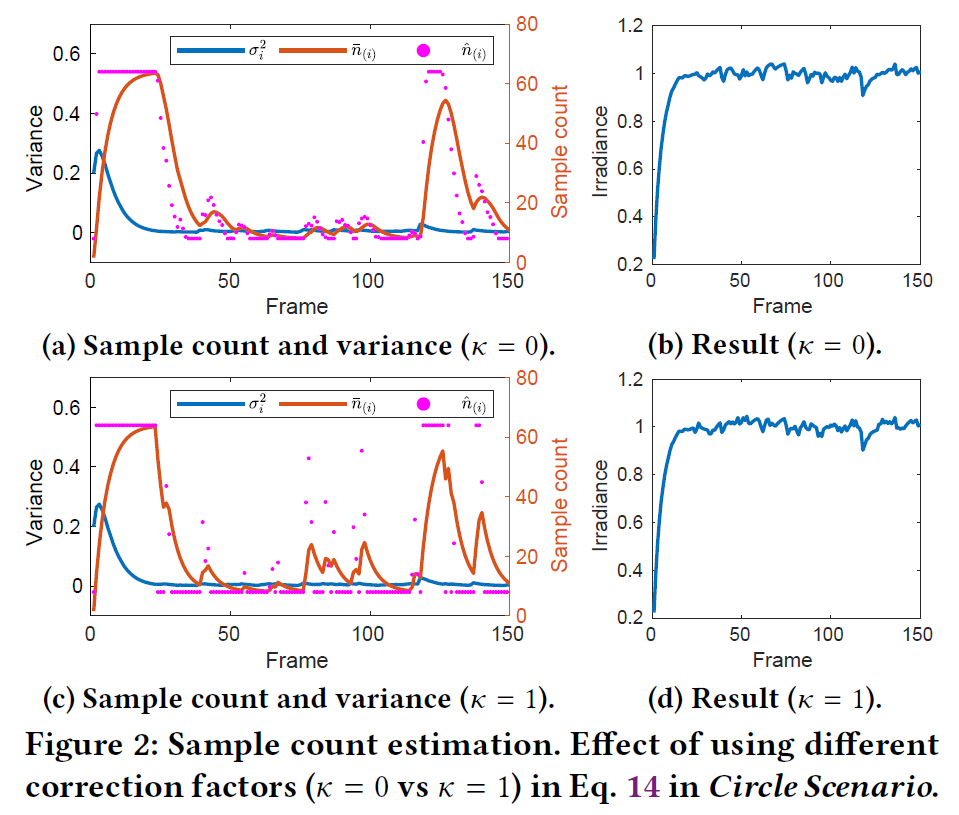
この推定を理解するために、簡略化した表面下散乱シナリオを作成します。表面下散乱シナリオのモデルを単純化し、(.5, .5)を中心とする半径0.5の円内の均一な放射照度をサンプリングすることにします。(Burleyの表面下散乱モデルを使用する代わりに)一様な2次元乱数\((\xi_1, \xi_2) \in[0, 1)^2\)でサンプリングします。累積放射照度は円内では\(4/\pi\)、円外では0となります。サンプルバジェットとして\(b_{min} = 8 \)sppと\(b_{max} = 64\)sppを与え、\(\alpha = 0.2\)を使用し、目標品質レベル\(\sigma^2_0 = 0.08^2\)を設定します。履歴タプル\({\mathcal H}_i = ({\bar n}_{(i)}, \mu_i, \sigma^2_i)\)は0に初期化されます。図2は、\(\kappa=0\)と\(\kappa=1\)の場合の150フレームにわたるサンプル数、分散、散乱の結果を示しています。コールドスタートセッションの後、両手法は与えられた品質レベル内で1に収束しようとします。図2aと2cの\({\hat n}_{(i)}\)は、\(\kappa\)が各フレームで使用される実際のサンプルにどのように影響するかを示しています。\(\kappa=1\)の場合、サンプル数のピークが高く、通常1フレームで終わるのに対し、\(\kappa=0\)ではサンプル数は少なくなりますが、サンプル数の増加は数フレームにわたって平滑化されます。
4.1.4 Disocclusion.
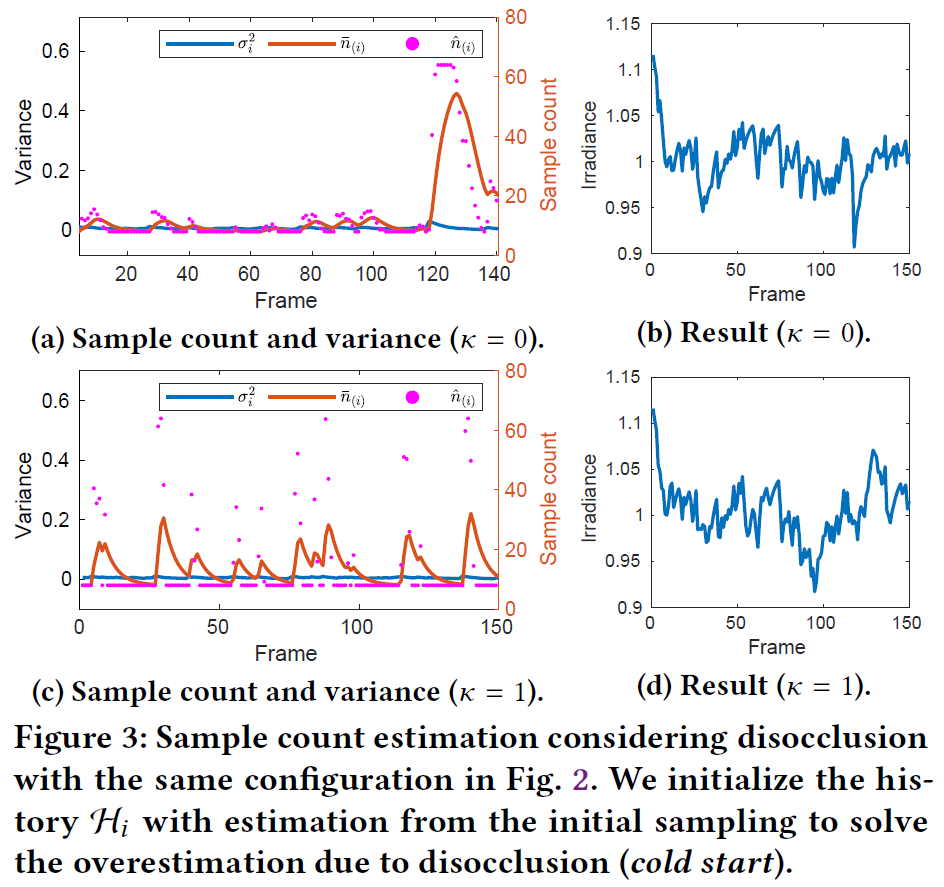
図2は、一般的なレンダリングシナリオでは稀なコールドスタート時のフレームごとのサンプル数です。履歴データの欠落がより一般的なケースは、オブジェクトの以前は隠されていた部分が見えるようになるディスオクルージョンです。そこで、ディスオクルージョンが発生したときの初期履歴を推定します。
\({\mathcal C}_s(\cdot)\)を、サブサーフェイスのマスク履歴に棄却されたポイントサンプリング演算子とします。前フレームでサブサーフェスマスク履歴が得られない場合,\({\mathcal C}_s(x_i, \Lambda) = 0\)です。このとき、新しい\({\mathcal M}\)は以下のようになります。
\begin{eqnarray}
{\mathcal M}'(\alpha_0, \Lambda) = \begin{cases} 1 & {\mathcal C}_s(x_i, \Lambda) = 0 \\
\alpha_0 & {\rm otherwise} \end{cases} \tag{16}
\end{eqnarray}
この演算子により、初期サンプル数\(n_{(i)} = max({\hat n}_{(i)}, \beta_{(i-1)})\)で初期サンプル値を\({\mathcal S}(p_i)\)として推定することができます。分散の履歴がないので、分散を次のように推定します。
\begin{eqnarray}
{\hat \sigma}^2_i (\alpha_0, \Lambda) = \begin{cases} \sigma^2_0 & {\mathcal C}_s(x_i, \Lambda) = 0 \\
\sigma^2_i & {\rm otherwise} \end{cases} \tag{17}
\end{eqnarray}
図3は、「円シナリオ」と同じ構成で、更新された重み関数\({\mathcal M}\)と分散推定がどのように働くかを示したものです。初期のサンプル数の多さは解消されています。
4.1.5 Integration with Global TAA.
前節では、ローカル TAA とグローバル TAA が同じ構成(すなわち、\({\mathcal C}_l = {\mathcal C}_g\), \({\mathcal S}_l = {\mathcal S}_g\), \(\Lambda_l = \Lambda_g\), \({\mathcal M}_l = {\mathcal M}_g\)そして,\({\mathcal M}_l (\alpha_0, \Lambda_l) = \alpha_0\))を使用すると仮定して、分散誘導サンプリングがグローバル TAA の品質を誘導するように、各フレームのサンプルカウントを推定しました。しかし、リアルタイムレンダリングエンジンでは、これが保証されません。TAA のウェイトと関数は、主に表面下散乱以外のアーティファクトに対してチューニングされています。さらに、同じサブサーフェススキャッタリングピクセルが、オーバーレイされた透明オブジェクトのような他の寄与を持つ可能性もあります。
グローバルなTAAを前提としない表面下散乱の一般的な手法とするために、サブサーフェイスの品質に関する下限をターゲットにして、全体のTAA品質を向上させることを選択しました。空間\(\Gamma\)における解を\(\gamma = ({\mathcal C}, {\mathcal M}, {\mathcal N})\)とすると、\(\gamma \in \Gamma\)となります。あるピクセルのフレーム\(i\)における与えられたコンテキスト\(\Lambda_i\)の分散は\(\sigma^2_{i, \gamma} = \varsigma^2 (\gamma, \Lambda_i)\) を持ちます。 長さ\(N_b\)の任意のシーケンスに対して、\(\gamma=\gamma_0\)を選びました:
\begin{eqnarray}
\gamma_0 = \underset{\gamma_0 \neq \gamma_j, \gamma_0, \gamma_j \in \Gamma}{\rm argmax} \sum_{i=1}^{N_b} {\mathbb 1}_{\sigma^2_{i, \gamma_0}} \sigma^2_{i, \gamma_j} \tag{18}
\end{eqnarray}
ここで、指標関数は\(A<=B\)のとき\({\mathbb 1}_{A}(B) = 1\)、それ以外は\({\mathbb 1}_A(B)=0\)です。式(18)は、毎フレーム一貫して最も分散が小さくなる解を選択します。これを実現するために、\({\mathcal C}\)をヒストリーリジェクトのない最近傍サンプラーとし、\({\mathcal M}\)を\({\mathcal M}(\alpha_0, \Lambda) = \alpha_0\)のmaxオペレータ、\({\mathcal N}\)をTAA使用時のデフォルトサンプル位置(例えば、ガウス分布に従う位置)とします。実際には下限値であれば十分です。
この選択の効果を説明するために、シャドウピクセルとダイレクトライティングピクセルにおけるフレームごとの局所分散と全体分散のシーケンスを図4に示します。\(\alpha_l\)を\(0.2\)(これは我々のアルゴリズムを実装したUE4での最大の重みです)、\(\sigma^2_0 = {0.01}^2\)に固定します。この例では、グローバルピクセル標準導出の平均値が小さくなっています。さらに、高分散ピクセル\(P_1\)では、平均グローバル目標品質は、実際のローカル品質よりも\(11.19\)倍優れています。\(P_2\)は、最小許容サンプル数\(\beta_{i-1} =8\) spp.で、目標品質よりも分散が低く、2倍良いという結果になります。
最小限のサンプル数が決まると、レンダリングの条件を満たすために効率的なサンプリング方法が必要になります。
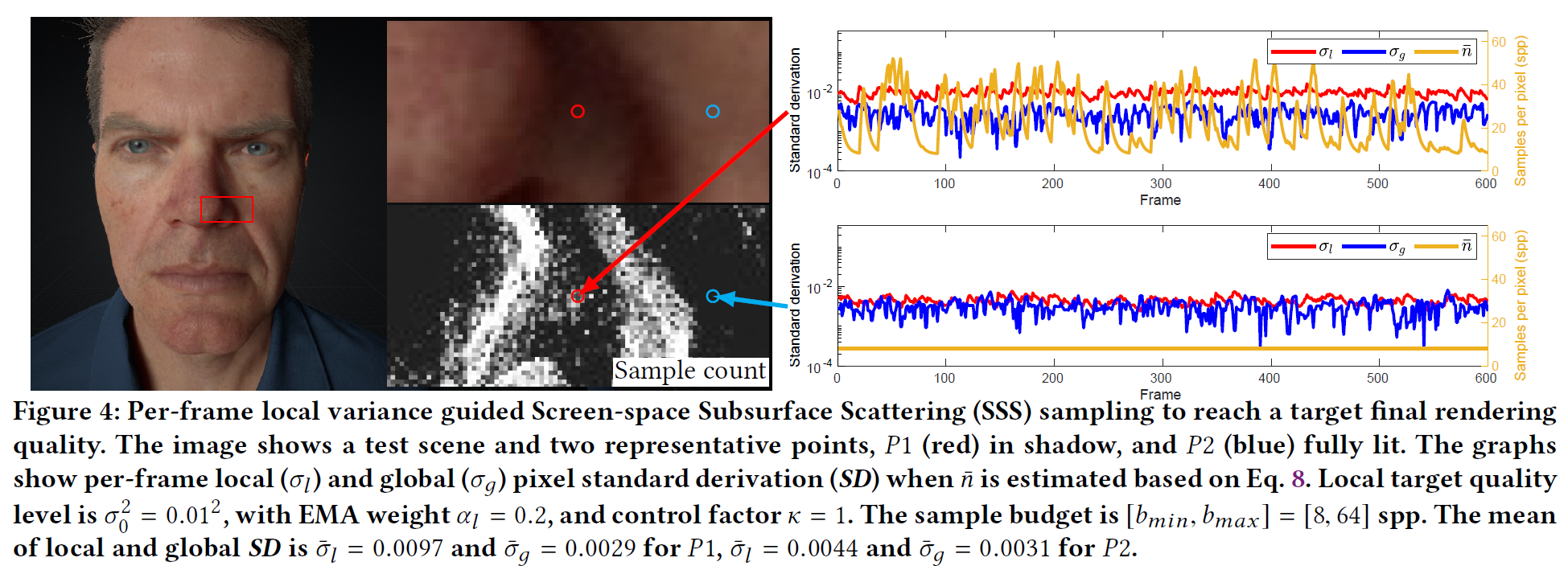
4.2. Efficient sample generation
\(p\)においてモンテカルロ・サンプリングを行う場合、式3を簡略化し、次のようにします。
\begin{eqnarray}
L_o = \frac{1}{n} \sum_{j=1}^n \frac{ 2\pi r_{q_j} R(r_{q_j}) \cdot L_{q_j} }{ pdf_{q_j} } \tag{19}
\end{eqnarray}
ここで、\(L_o\)は散乱結果、\(r_{q_j}\)と\(pdf_{q_j}\)は\(j\)番目のサンプルの中心\(p\)とPDFに対する半径です。\(L_{q_j}\) は \(q_j\) での累積拡散放射照度です。この式を解くには、効率的な2次元サンプリングシーケンス\((\xi_1, \xi_2)\)(これは本論文の範囲外である)とは別に、半径サンプリング用のCDFに基づく密度関数を重要視してサンプリングすることが必要です:
\begin{eqnarray}
cdf(r) = 1 – \frac{1}{4} e^{-r/d} – \frac{3}{4} e^{-r/(3d)} \tag{20}
\end{eqnarray}
Christensen [2015]は、2つの指数の多重点サンプリング(MIS)、ニュートン反復、またはルックアップテーブルを使用することを提案しています。Golubev [2019]は解析的な逆解を導出しました。その代わりに、\(cdf^{-1}\)を近似するより単純な関数\(g(\xi)\)を次のように使うことを提案します:
\begin{eqnarray}
g(\xi) = d((2-c) \xi – 2) log(1 – \xi); \tag{21}
\end{eqnarray}
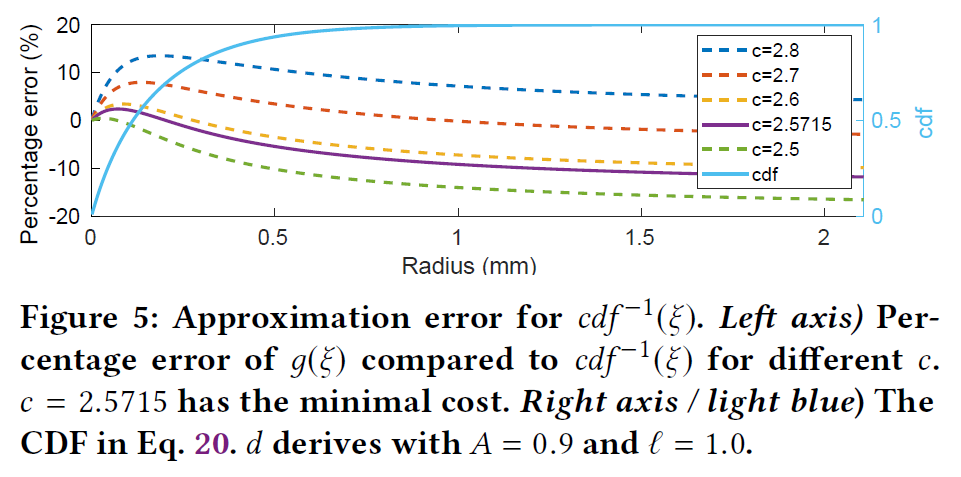
ここで、\(c\) は関数の減衰を制御するためのパラメータです。我々は、\(c = 2.5715\) のとき、最小二乗非線形カーブフィッティング [Coleman and Li 1996] を用いて最適化した \(cdf(g(\xi|c))\) vs \(\xi\) の平均二乗誤差が許容誤差 \(10^{-6}\) で最小となることを見いだしました。図5はCDF関数と近似誤差を示したものです。
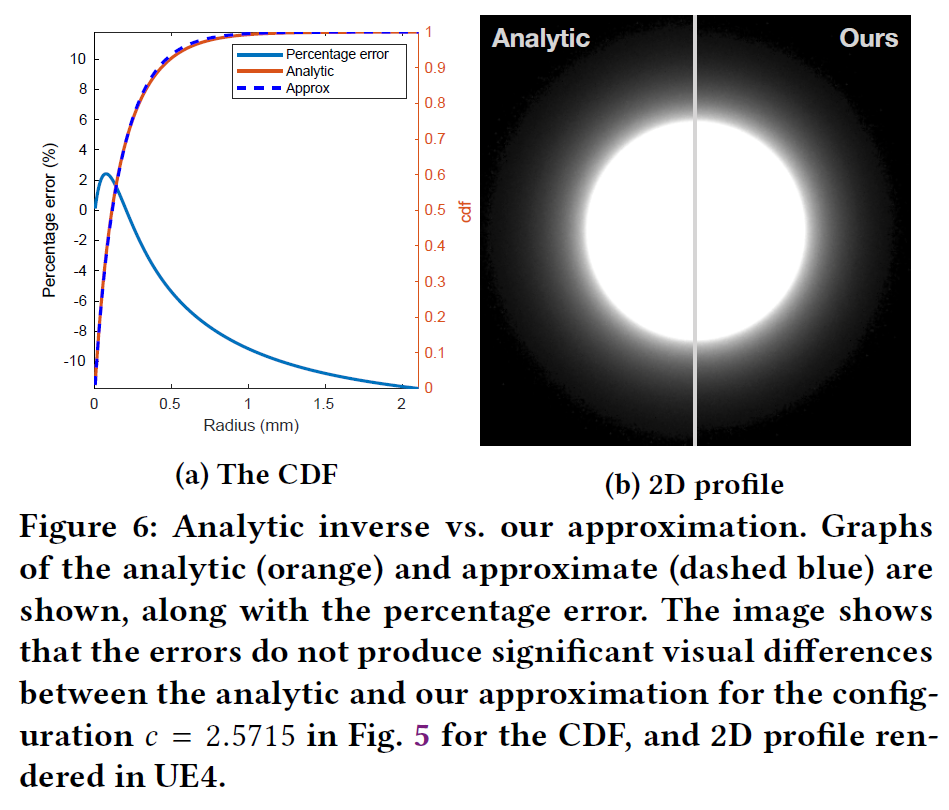
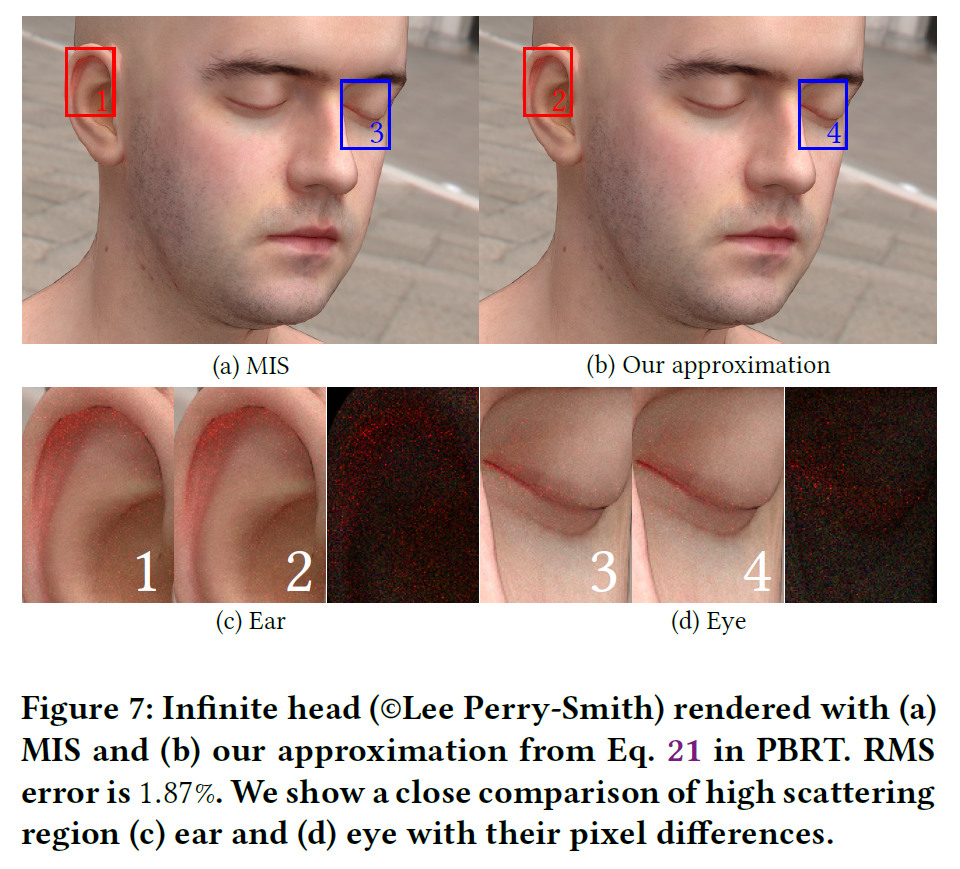
これは逆CDFの近似であるため、これを用いて生成されたサンプルはBurley PDFの(近い)近似でしかありません。その品質を評価するために、図6は解析的逆行列と我々の近似がどれだけ近いかを示しています。ビームライトシナリオ(図6b)では、円形ライト(10フラックス)の半径は1cmです。図にズームインすると、散乱距離の小さな縮小が観察されますが、通常の視距離では無視できる程度です。さらに、我々の近似をPBRT [Pharr et al. 2016]に実装し、ビルトインのMIS法と比較しました。図7は、頭部シーンを用いたPBRT内のレンダリング比較です。dmfpパラメータはJensenら[2001]のskin1設定に由来するものです。我々の近似は,2k spp.のマルチインポータンスサンプリングと比較して,RMS誤差が1.87%と小さいです。
5 IMPLEMENTATION
UE4では、最終的なTAAパスを変更することなく、サブサーフェススキャッタリングを単一のスクリーン空間適応型サンプリングポストプロセッシングパスとして実装しています。図8は、サブサーフェススキャッタリングパスの概要を示しています。シーンカラーは、拡散放射照度と非表面放射照度に分割されます。次に、放射照度をインコヒーレントにサンプリングする際のキャッシュヒットを高速化するために、拡散放射照度マップをプレフィルタリングします。スクリーン空間での表面下散乱では、重要度近似式(式21)を用いて、ビュー方向に対して垂直なサブサーフェイス平面でサンプリングを行います。サンプル数は分散ガイドの段階で推定します。隣接するサブサーフェスが異なる可能性があるため、8ビットプロファイルIDテクスチャをキャッシュし、プロファイル間のブリードカラーがどのように混合されるかを解決します。サンプリング後、その結果を使用して、ピクセルごとに \({\mathcal H}_i\) を格納する履歴テクスチャを更新します \(\alpha_0 = 0.2\) (UE4 の非透過オブジェクトの最大ウェイト)。最後に、散乱結果をサーフェイスアルベドおよび非サブサーフェス部分と組み合わせて、最終出力を形成します。リアルタイムでリアルなレンダリング結果を得るために、2つの既存のテクニックを私たちのニーズに応じて調整しました。

Pre-filtering. プレフィルタリングは環境マップの重点サンプリングでよく使われています[Křivánek and Colbert 2008]。我々は、スクリーン空間散乱放射照度のサンプリングにこれを使用します。具体的には、以下のようなミップレベルを生成します。
\begin{eqnarray}
m = \frac{1}{2} \cdot max \left(-log_2 \left( \frac{a \cdot pdf \cdot {\hat n}_{(i)} }{ \ell^2_{max} \cdot t } \right), 0 \right) \tag{22} \\
t = \frac{w}{D} \frac{w \cdot AspectRatio}{D} = (\frac{w}{D})^2 \cdot AspectRatio \tag{23}
\end{eqnarray}
ここで,\(\ell_{max}\) は 3 チャンネルサブサーフェイスプロファイルの最大拡散平均自由行程,\(a\) はミップレベルをスケーリングする定数係数,\(t\) はワールド単位スケール \(w\) を考慮した画面空間でのテクセルサイズ,\(D\) は中心サンプルでのシーン深度です。我々は、\(a = \frac{1}{16}\)が品質と性能の良いバランスを与えることを発見しました。
Bilateral filtering. 異なる散乱面間のブリーディング問題を解決するために、深度ベースのバイラテラルフィルタリング[Golubev 2018]を採用します。式19を次のように拡張しました。
\begin{eqnarray}
L_o = \frac{ \sum_{j=1}^{n_{(i)}} {\mathbb 1}_s (q_j) \cdot r’_{q_j} R(r’_{q_j})/ pdf_{q_j} \cdot L_{q_j} }{ \sum_{j=1}^{n_{(i)}} {\mathbb 1}_s (q_j) \cdot r’_{q_j} R(r’_{q_j}) / pdf_{q_j} } \tag{24}
\end{eqnarray}
ここで、\(r’_{q_j} = \sqrt{r^2_{q_j} + \Delta D^2_{q_j}}\)で,\(\Delta D_{q_j}\)は\(q_j\)と中央のサンプリング点との深度差であり、指標関数\({\mathbb 1}_s(q_j)\)は\(q_j\)にサブサーフェイスの場合は1、そうではない場合は0となります。
6 RESULT
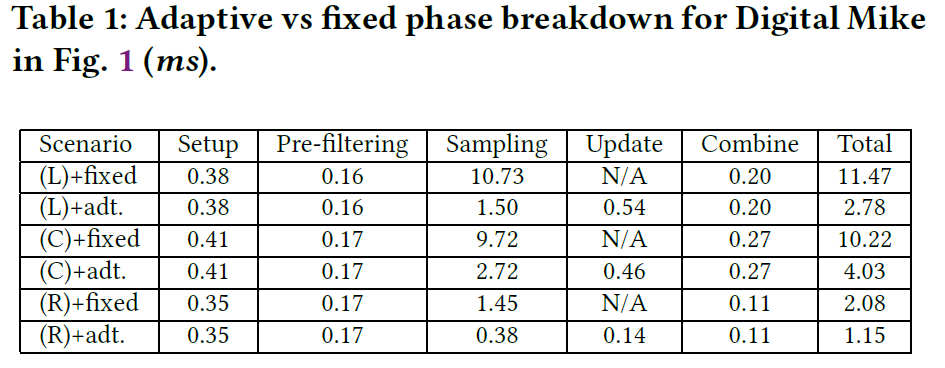
私たちの適応型サンプリングアルゴリズムの品質と速度を評価するための比較も含まれています。品質については、二乗平均平方根誤差(RMSE)とグレースケールのピーク信号対雑音比(PSNR)を比較します。リアルタイム性能については、適応サンプリングなしのBurleyの方法と、UE4の標準実装である分離可能なスクリーンスペース法と、速度と品質を比較します。Dipoleの代わりにBurleyのモデルを近似するように修正しました。この近似のアプローチと検証の詳細については、付録 A.1 を参照してください。特に指定がない限り、すべての性能数値は、NVIDIA Quadro P4000 で解像度 1366×1024 で測定されています。サブサーフェイス処理だけの時間を \(ms\) 単位で測定しています。
6.1 Quality comparisons
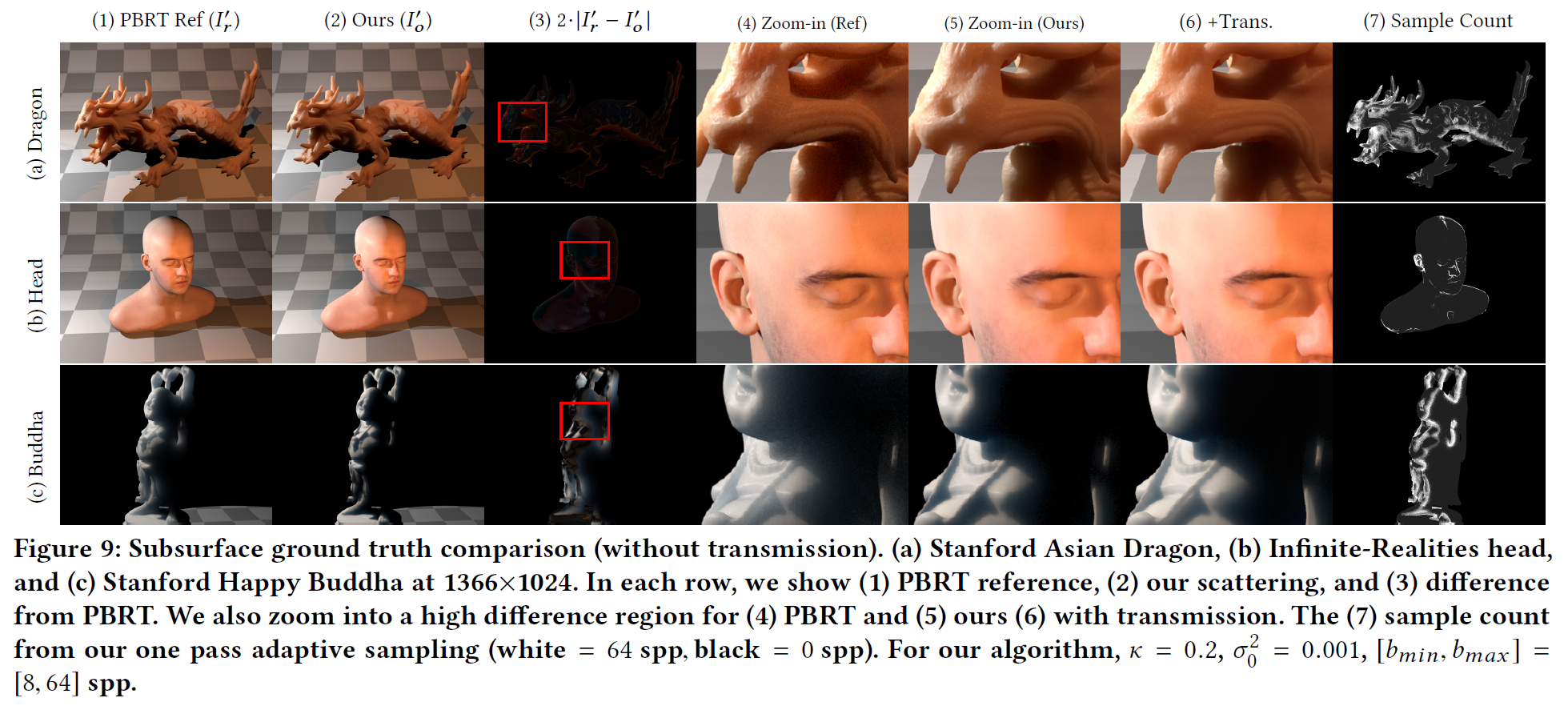
図9は、3つのシーンについて、PBRTのグランドトゥルースと比較したものです:Dragon, Infinte-Realities head, そして Happy Buddha。我々のスクリーン空間での表面下散乱(透過なし)と、\(maxdepth = 1\)のディズニーマテリアルでのPBRTパスインテグレータを比較します。サブサーフェスに焦点を当て、ライトとトーンマッピングの実装の違いによる差異を最小化するため、ポイントライトのみを使用し、UE4レンダリングのシャドウ解像度を最大にしています。グランドトゥルースの比較のため、いずれのレンダラーでもトーンマッピングは適用されていません。その結果、いくつかの違いは見られるものの、定性的には低いレベルに留まっていることがわかりました。最も大きな違いは、PBRTレンダリングが透過パスを含むのに対し、拡散モデルではそれができないことに起因すると推測しています。UE4 には、個別の半透明オブジェクト透過モデルが含まれています。そこで、UE4 の透過率プロファイルを Burley のモデルに置き換えたところ、図 9(6)のようになりました。この結果、より近い一致が得られました(まだ完全ではありませんが)。我々は、より優れたリアルタイム伝送モデルがあれば、この差をさらに縮めることができると考えています。
6.2 Adaptive sampling quality
リアルタイムのタイミング評価として、Burleyモデルの固定サンプル数のインタラクティブな実装と、UEの分離可能なスクリーンスペース拡散モデルを比較し、UE4内のピクセルあたり2kサンプルのグランドトゥルースと比較して、ほぼ同等の品質になるようにそれぞれチューニングしています。サンプリングモデルの性能は、視聴距離が近い場合にテクスチャアクセスのコヒーレント性が最も低くなるため、キャッシュミスが大きな性能低下を引き起こすため、最悪となります。そこで、通常の視距離とサーフェスに近い視距離の両方で、アダプティブサンプリングの品質とパフォーマンスを評価します。
Regular distance. タイミングとしては、Buddhaとチェッカーボードベースのプレーンの両方が、PSNRはBuddhaのピクセルに対してのみ計算されますが、サブサーフェスマテリアルを使用します。図10は、BuddhaとサブサーフェスタイムのPSNRを示したものです。我々のアルゴリズムは、ローカルターゲット品質\(\sigma^2_0 = 0.0001\)(PSNR=40.00dB)の場合、無視できる品質差(40.51-40.2=.31dB)でより速く(1.97x)実行されます。さらに、本アルゴリズムはTAAを利用することで、小さな品質劣化で性能を向上させることが可能です。例えば、ローカルターゲット品質\(\sigma^2_0 = 0.001\) (PSNR = 30.00dB)の場合、最終品質は38.36dBに達し、2.12倍の2.07msで高速化されることが確認されました。図9(c)の最後の列は、この構成でのBuddhaのサンプル数を示しています。

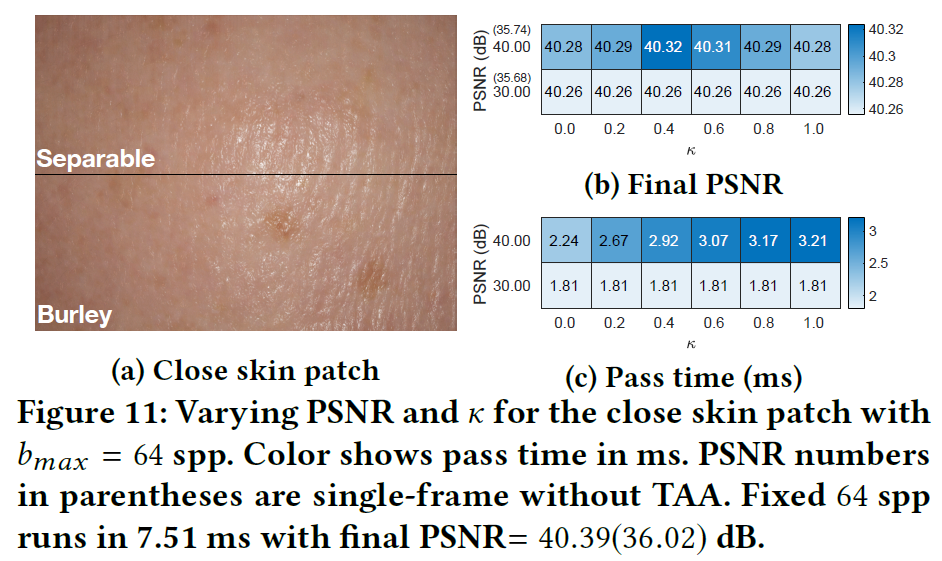
Close distance. そこで、デジタルマイクロモデルのうち、紫外線空間での散乱距離が長い額の皮膚パッチを用いて、このケースを検討しました。図11に最終的なPSNRとサブサーフェスタイムを示します。特に、ローカルターゲット品質\(\sigma^2_0 = 0.001\) (PSNR=30dB) の場合、本アルゴリズムはすべての\(\kappa\)について適応的にサンプル数を\(b_{min}=8 {\rm spp}\)に減らし、固定\(64 {\rm spp}\)と比較してほぼ同等の品質(30.26 dB vs 40.39 dB)、4.15 x (7.51msから1.81ms) の高速化を達成することができました。アダプティブサンプリングは、インコヒーレントな非キャッシュテクスチャのアクセス数を減らすため、これらのケースでは、固定サンプリングと比較して、より良いパフォーマンスを期待することができます。
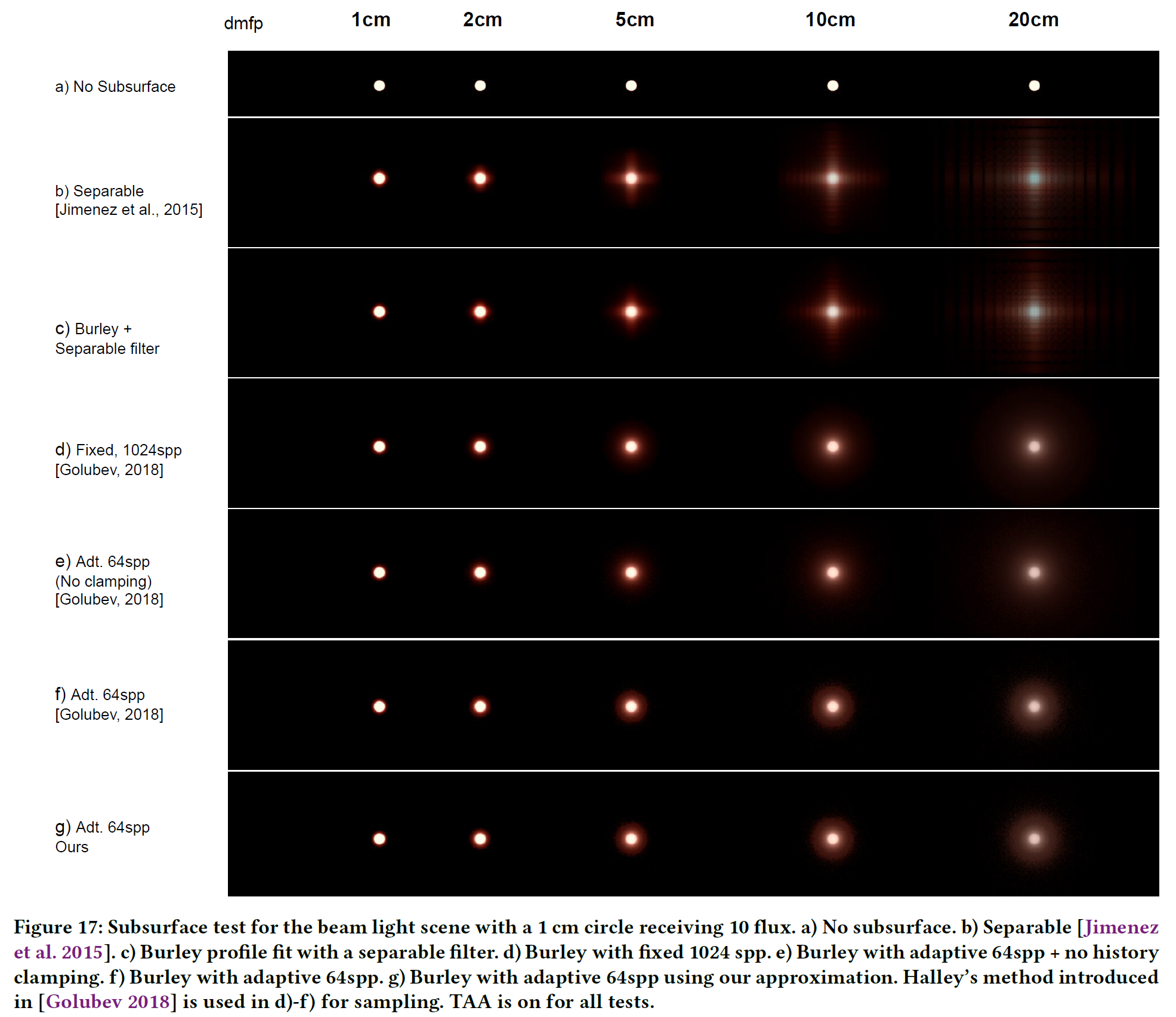
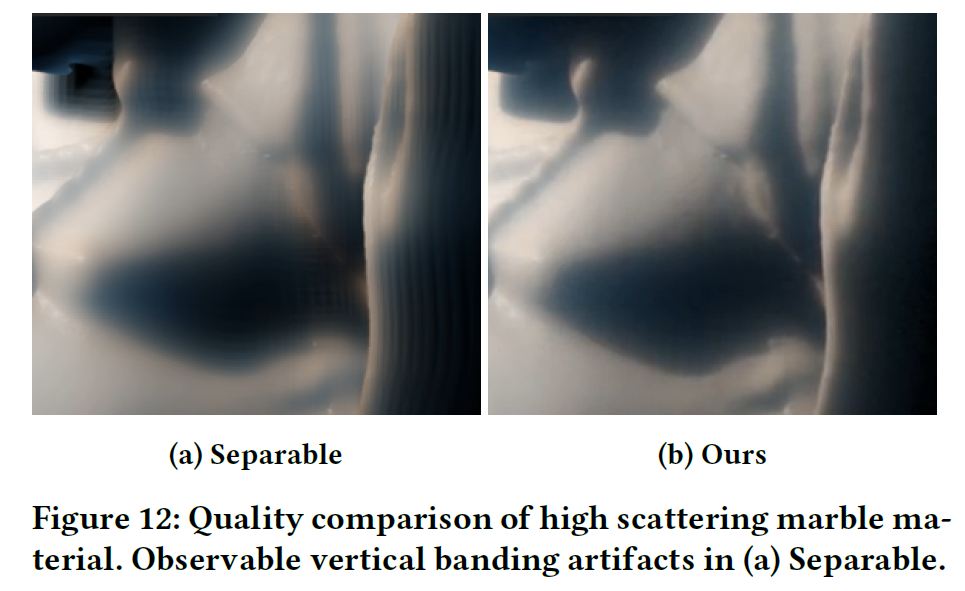
クローズビューのサンプリング帯域がボトルネックとなる中、8ビットキャッシュされたプロファイルIDテクスチャはパフォーマンスにとって非常に重要です。フレームごとに計算されますが、プロファイルIDテクスチャの生成はコヒーレントであり、サンプルごとに16バイトから1バイトにインコヒーレントアクセスを減らすことができます。このテクスチャを使用しない場合、品質レベル 0.001 では 4.23ms (6.13x) 、固定 64 spp では 25.94ms を要しました。Separableと比較すると、この場合のレンダリング時間は3.06msと我々のモデルより速いですが、Separable近似はクローズビューで著しいバンディングアーティファクトを示し、PSNR=39.95dBと悪い結果になりました。図12に,このアーティファクトを我々のものと比較したものを示します。
※図は,[Xie 2020]より引用
6.3 Equal quality comparison
図13は、ほぼ同じ実行時間で、本適応サンプリングアルゴリズムと固定サンプリングによる1フレームのBuddhaシーンの画質を比較したものです。Buddhaシーンでは、\(b_{min} = 8\), \(b_{max} = 64\)を固定し、最高の品質につながる2種類の\(\sigma^2_0\), \(\kappa\)設定としました(\(\sigma^2_0 = 0.001\), \(\kappa = 0.2\), そして\(\sigma^2_0 = 0.0001\), \(\kappa = 0.6\))。2k-sppのグランドトゥルースと比較すると、我々の適応的サンプリングアルゴリズムを用いて品質が向上していることがわかります。

図1(a)、(c)/左は、本適応サンプリングアルゴリズムと、ベースラインとしてプレフィルタとプロファイルキャッシングを行わない固定サンプリングアルゴリズムとで、デジタルマイクモデルの品質を等時間で比較したものです。また、同じ設定による他の2つのビュー(中央と右)も示しています。図1 (d) は、同じビューに対する分離可能なスクリーンスペースフィルタリングアルゴリズムを示します。図1(e)は、各ビューにおける我々の適応的アルゴリズムのサンプル数を可視化したものである。この結果から、我々のアルゴリズムは、単一の設定でSeparableと同等かそれ以上の動作をする最高の品質を目標としていることがわかります。
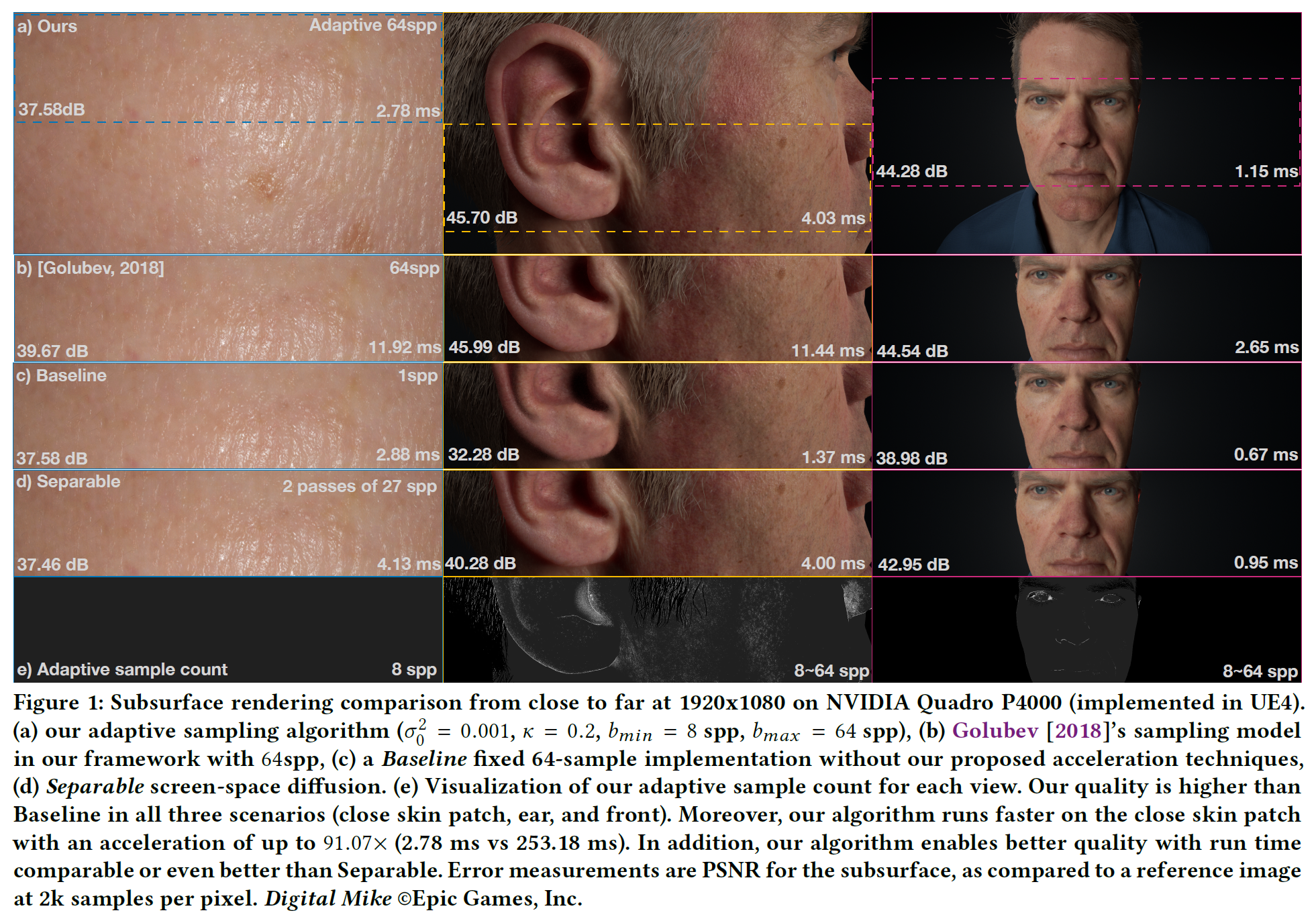
6.4 Real-time counterpart comparison
また、我々の近似の代わりにBurley拡散プロファイルを用いた固定64サンプルのグランドトゥルースとして、最先端のスクリーンスペース表面下散乱Golubev[2018]のサンプリングを我々のフレームワークに実装しました。その結果を図1(b)に示します。図6の近似比較から、バイアスは小さいです。Burleyのモデルと我々の近似値との差は、耳(0.29dB)と前面(0.26dB)のシナリオで小さい。しかし、スキンパッチのシナリオでは、これらの差は比較的大きくなっています(2.09dB)。図1(e)の適応的サンプリング数をさらに調べると、目標品質を満たすために1ピクセルあたり8サンプルしか使用されていないことがわかります。わずかな品質劣化はあるものの、我々のサンプリングアルゴリズムは、リアルタイムレンダリングのために品質がすでに満たされている場合に、オーバーサンプリングを防止する良いメカニズムです。わずかな品質低下にもかかわらず、2.3 倍から 4.3 倍の大幅な性能向上が得られています。
6.5 Performance breakdown
分散ガイド段階のコストを理解するために、図8の更新パスは、時間計測のためのサンプル推定とサンプリング処理から分離されています。また、本手法を利用した技術が異なるハードウェアでどのように機能するかを説明するために、固定および適応的な 64 spp コストを比較しました。その結果を表1に示します。性能は、図1の左(L)近傍パッチ、中央(C)耳、右(R)正面画像における中央値時間(単位:ms)として測定されます。
6.6 Discussion and Limitations
この分散誘導型アルゴリズムでは、サンプリングが最もインコヒーレントな場合に、帯域幅の削減が最も重要となるため、最大の高速化を実現します。したがって、高速化は、遠距離サンプリング(近景または大きな平均自由行程)、または疎なサンプリングに最適です。
また、ピクセルの分散を過大評価し、必要以上のサンプル数になってしまう可能性もあります。TAAジッターによる分散とサンプリング不足による分散を区別していないためです。サブサーフェスでは、すべてが拡散されるため、これは良いことかもしれません。
最終的な品質は、ローカルな目標品質で区切られます。一度満たせば、それ以上のサンプルは追加されません。とはいえ、我々のアルゴリズムは近似値です。レンダリング結果の観点からは無視できる程度の偏りであっても、フレームごとに偏ったサンプルカウントを作成している可能性があります。\(\kappa=1\) の場合,サンプリングの寄与が最終的なレンダリングに正しく反映されないことがあります。なぜかというと,最終的なTAAの重みによって,各フレームの寄与が制限されるからです。
これは,\(b_{min}\) を 1 spp に設定した場合,サンプル数の少なさと TAA 履歴の除去によるノイズのために,サンプル数の推定系列が振動したりちらついたりする可能性があるためです。\(b_{min} = 4\) spp でもこのちらつきを抑えることが観察されており,特にタイムクリティカルな使用では良い選択となる可能性があります。しかし,我々は,アダプティブ・サンプリングの利点を生かしつつ,TAA のフリッカ ーアーチファクトをすべて除去するために,\(b_{min} = 8\) spp を選択しました。
7 CONCLUSION
我々は、表面下散乱のMCサンプリングをガイドするシングルパス適応アルゴリズムSPVGを発表し、uv空間におけるインコヒーレントなリソースアクセスでも実時間性能を可能にします。また、オンラインサンプル生成に適した表面下散乱の重点サンプリング近似を提示しました。我々は、このアルゴリズムは、サンプル配布をガイドするためにオフラインレンダリングにも使用できる可能性があると信じています。
ACKNOWLEDGEMENTS
和訳省略
A APPENDIX
A1. Separable approximation to the Burley model
可分なフィルタの実装が有効であり、我々の手法と比較できることを確認するために、ガウスカーネルのパラメータ化[Jimenez et al. 2015]から非線形最小二乗フィッティングに基づくバーリーへのフィルタリング、さらにこれらの異なる手法間の比較も提供しています。Burleyモデルへの分離可能なフィットを持つことは、分離可能なモデルがすでに展開されているレンダリングのアップグレードを容易にしますが、既存のガウシアンカーネルパラメータがBurleyのものとどのように相互作用するかについての洞察も提供します。
なお、このフィッティングは、可分モデルとBurleyモデルが視覚的にできるだけ同じように見えるようにするためのものです。この処理自体に物理的な意味はありません。元の可分カーネルはダイポールモデルの近似であり、これはすでに実際のプロファイルの近似です。それを実際のプロファイルの直接の近似であるBurleyのプロファイルに当てはめようとしているのです。
A.1.1 Fitting
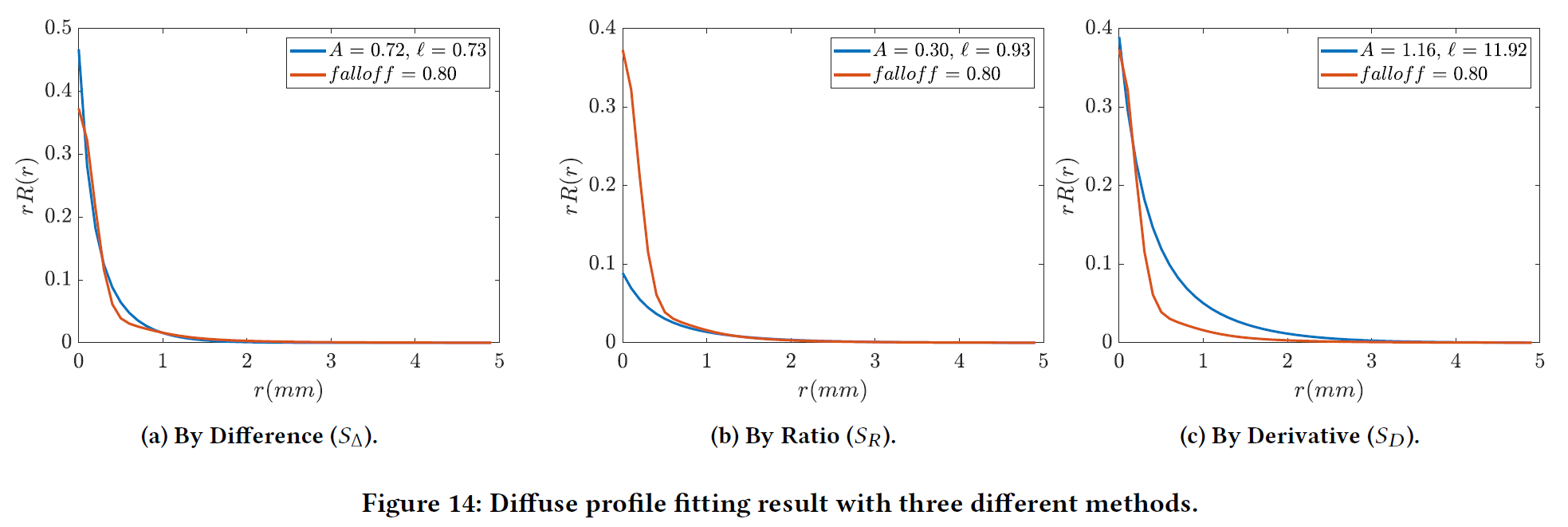
フィッティング問題は、Burley \(R_B(r, \theta_B)\)と可分な\(R_s(r, \theta_S)\)の拡散プロファイルの間で、\(\theta_B = \{A, \ell\}\)、および\(\theta_S = \{falloff\}\)の最適なパラメータフィッティングを見つけることです。これを達成するために、我々は3つの誤差関数を探索します:
(1) 差分. Burleyカーブと可分カーブの直接的な違い。最小化誤差関数は
\begin{eqnarray}
S_{\Delta} = \sum (R_B(r, \theta_B) – R_S(r, \theta_S))^2 \tag{25}
\end{eqnarray}
(2) 比率. Burleyカーブと可分カーブの比率が1に近いことが望ましいです。 最小化誤差関数は次の通りです。
\begin{eqnarray}
S_R = \sum (R_B(r, \theta_B) / R_S(r, \theta_S) – 1)^2 \tag{26}
\end{eqnarray}
(3) 微分. 両曲線のrに関する一次導関数は、最も類似性が高いはずです。最小化誤差関数は次の通りです 。
\begin{eqnarray}
S_D = \sum (R’_B(r, \theta_B) – R’_S(r, \theta_S))^2 \tag{27}
\end{eqnarray}
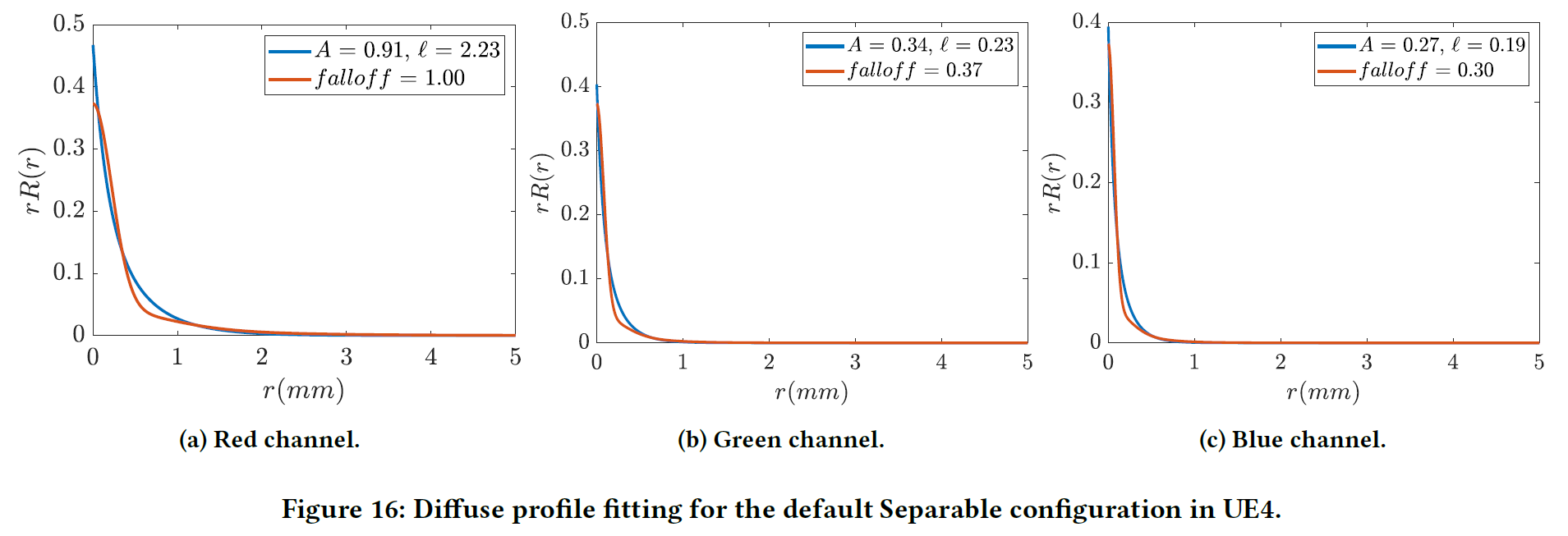
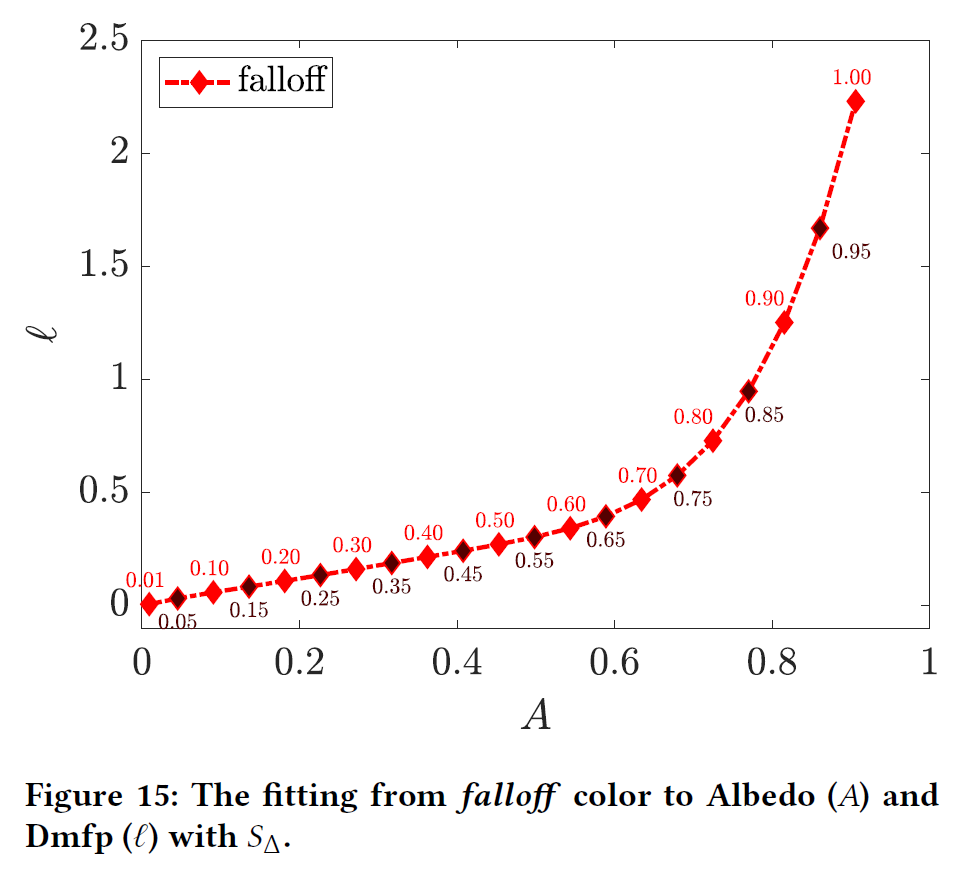
\(S_{\Delta}\)は非線形最小二乗フィッティングに最適な誤差関数であることが確認されました。図14は\(falloff=0.8\)で誤差関数を変えて計算した結果の例です。また、図15に\(\theta_B\)と\(\theta_S\)の対応関係を示します。この図は、デフォルトの可分パラメタリゼーションとBurleyのもので表現できる値の範囲を明確に示しています。エンジン内でオンザフライでフィッティングを行うには、LUTや線形フィッティング関数を導入することができます。
A.1.2 Validation
半径1cmの円形面に10本の光束が入るビームライトシーンを作成しました。サブサーフェイスプロファイル構成は、図16に示すようなフィッティングに基づいています。可分モデル[Jimenez et al. 2015]のサブサーフェスカラーは1に設定されています。トーンマッピング、ブルーム、眼球適応、スペキュラ、自動露出などのサブサーフェイス以外の処理はオフになっています。その結果を図17に示します。可分モデルとBurleyモデルを異なる構成で、異なる拡散平均自由行程(\(\ell\))で比較しました。サンプリング数が少ないため、\(\ell\) が大きくなると separable モデルと Burley モデルは異なるアーティファクトを持ちます。可分モデルではバンディングアーティファクトが、BurleyモデルではTAAクランプによるエネルギーロスが発生しています。TAAのクランピングを改善することで、エネルギー損失をさらに低減できると考えています。