こんにちわ。Pocolです。
今日は,
[Anderson 2009] Johan Andersson, Daniel Johansson, “Shadows & Decals:D3D10 techniques from Frostbite”, GDC 2009
のシャドウマップに関するセクション部分を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けるとありがたいです。

私たちのシャドウマップレンダリング技術は、実際には複数の技術を組み合わせて拡張したもので、私はこれを…と呼んでいます。なぜかというと私が長いタイトルが好きなので。

ここでは、シャドウマップの部分について、高レベルの概要を説明します。
まず最初に、カスケードシャドウマップの基本的な部分を説明します。
次に、DX10 でシャドウマップを効率的にレンダリングする方法について詳しく説明します。
また、スタビライゼーションを使用してフリッカリングを低減する方法と、それをシーンレンダリングと組み合わせてシャドウマップを最大限に活用する方法について説明します。
セッションの最後には、両方のパートについて共通のQ&Aを行います。

カスケードシャドウマップとは何かを簡単に説明します。
最近の多くのゲームでは、太陽からの完全にダイナミックな影を、かなり大きな影の表示距離と多くのオブジェクトで表現したいと考えています。すべてのオブジェクトをカプセル化する単一のシャドウマップを使用すると、低解像度のシャドウになり、利用可能な複数の透視投影技術は、より一般的なシーンで動作させるのが難しく、フリッカリングに悩まされます。
単純なアプローチは、代わりにビューフラスタムを複数のスライスに分割し、各スライスに対して個別のシャドウマップを生成することです。これにより、シャドウマップの解像度がより良く分散され、調整や管理が容易になります。
カスケードシャドウマップの重要な部分は、スライス分割平面をどこに保持するかを選択することで、シャドウマップがどのように分散され、どれだけ高い効果的な解像度が得られるかが決まります。

分割した平面をどこに配置すべきかを選択するために、実際によく機能することがわかった1つの方法は、論理的に名付けられた平行分割シャドウマップ論文の「実用分割スキーム」です。
これは、線形分布と対数分布の間の補間に基づいていますが、どちらも個別にはそれほどうまく機能しません。しかし、それらの間の単純なブレンドを得ると、レンダリングしているゲームやカメラシーンの種類に応じて、それを調整することが非常に簡単になります。
ここではweight=0.8を使用しています(経験的に)。
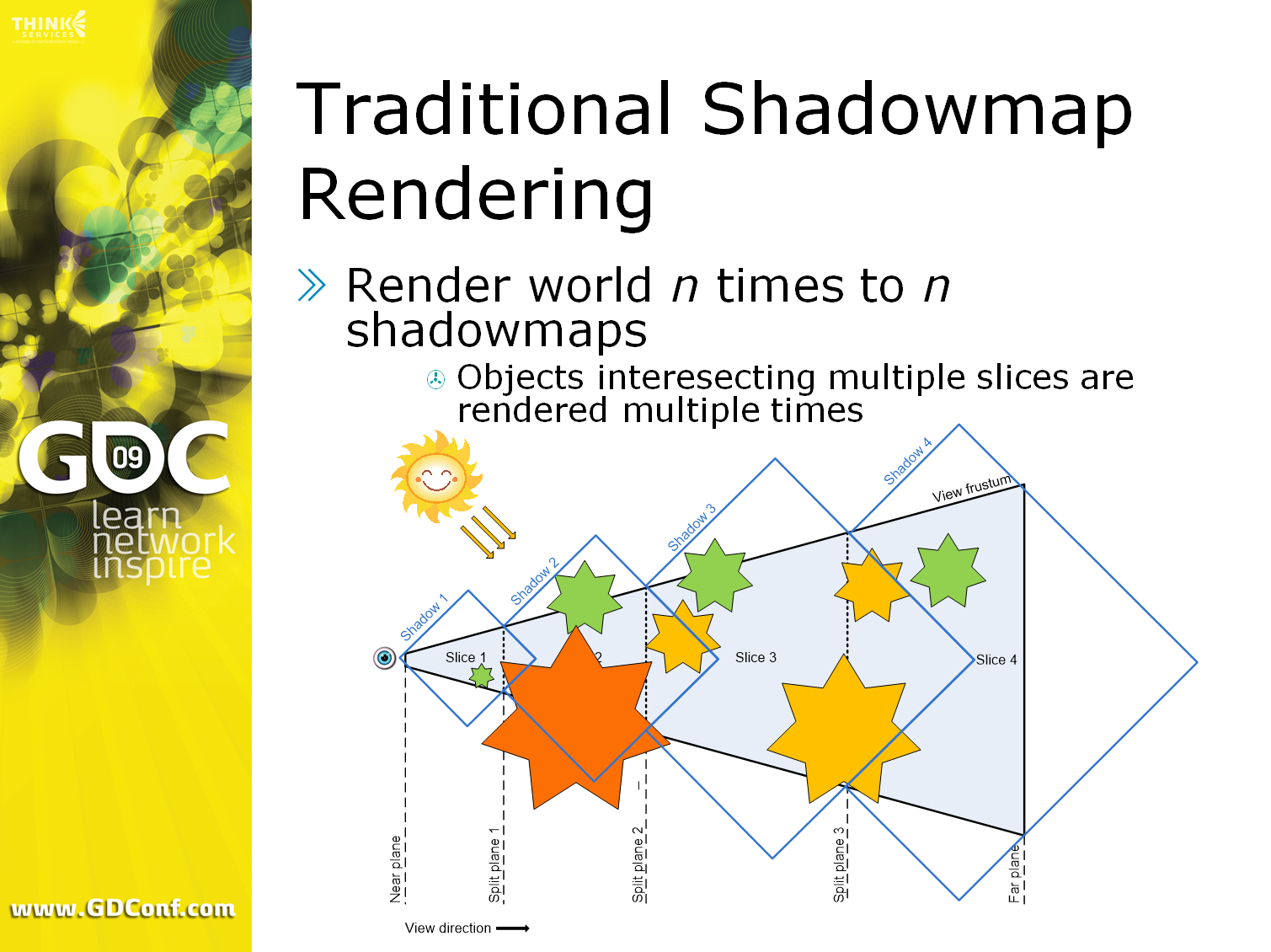
個々のシャドウマップがカスケードされたシャドウマップで典型的にレンダリングされる方法についての続きです。
緑は1つのスライスと交差しているオブジェクト
黄色は2スライス
赤は3スライス
オブジェクト数やスライス数が多いほど、レンダリングは重くなります。
シャドウビューの距離を長くしたり、影を落とすオブジェクトの数を増やしたりすると、この問題がどんどん大きくなっていきました。

もちろん、これはCPUとGPUの両方の問題です。
PCでは、主にCPUのオーバーヘッドを減らすことに関心がありました。DX10では、追加のドローコールやステートの設定によるオーバーヘッドがまだかなり大きいためです。また、シャドウキャストオブジェクトの数を増やし、より高品質なシャドウを得るためにスライス数を増やし、同時にシャドウの表示距離を長くしたいと考えました。

DX10 パスでは、シャドウマップレンダリングの CPU オーバーヘッドを軽減するために、シャドウのドローコールをスライスごとに発行するのではなく、複数のシャドウマップスライスに同時にレンダリングする方法を開発しました。
これは、シャドウマップスライスを個別のテクスチャではなくテクスチャアレイに格納し、深度ステンシルアレイビューにレンダリングするとともに、特別なSV_RenderTargetArrayIndex出力を使用して、ドローコールの各プリミティブがどのスライスにレンダリングされるべきかを選択するジオメトリシェーダで行います。
これにより、複数のスライスと交差するオブジェクトのための余分なCPUレンダリングコストが発生しません。
この実装には複数の方法がありますが、ここでは素朴な実装と効率的な実装の例を示し、どちらを使用するかはご自身で選択してください。
しかし、実装方法の詳細を説明する前に、コアとなる要件をもう少し詳しく見てみたいと思います。

DX10のテクスチャ配列の問題点として、HW-PCFフィルタリングのためのSampleCmp関数が10.1(およびそれ以上)でしか動作しないことが挙げられます。そのため10.0では、予備としてシェーダ内で手動のPCFフィルタリングを行うことができます。

シングルパスシャドウマップレンダリング技術のもう一つの重要な要件は、ジオメトリシェーダの出力値SV_RenderTargetArrayIndexを使用することです。これは、プリミティブがラスタライズされるべきテクスチャ配列のスライスを指定するために、GSからプリミティブと一緒に出力されるシンプルなインデックスで、D3D10のすべてのバージョンで利用可能です。

ここでは、ナイーブな実装をご紹介します。
このシェーダはまず、サポートするスライスの最大数を固定し、それぞれにviewProjection行列を定義します。
複数のビュー射影行列を持つ理由は、各スライスが独自のビューフラスタムを持つため、頂点シェーダがクリップ空間の位置ではなくワールド空間の位置を出力するためです。
このシェーダの出力は、クリップ空間の位置、ピクセルシェーダに渡す必要のあるその他のデータ、そしてプリミティブをどのスライスにレンダリングするかを知るためにSV_RenderTargetArrayIndexを使用するこのスライスインデックスです。
シェーダから出力する頂点の最大数を指定する必要がありますが、この場合はかなり大きくなります。
次に、レンダリングしているオブジェクトが交差している各スライスを調べ、最適化のために各オブジェクトの最初と最後のスライスインデックスをアップロードすることができます。そして、スライス内の各頂点をスライスのviewProjection行列で単純に変換して出力します。

この実装の主な利点は、まさに私たちが求めていたもので、各オブジェクトが何枚のスライスと交差していても、1回のドローコールで済むため、CPUのレンダリングオーバーヘッドを削減することができます。
しかし、いくつかの欠点もあります。
– GSには高いmaxvertexcountアノテーションがあり、これはGSが重いデータ増幅を行うように最適化されていないため、レンダリングが非常に重くなります。
– また、同じオブジェクトの複数のコピーを異なるトランスフォームでレンダリングするようなインスタンス化には完全に対応していません。各オブジェクトは異なるスライスと交差することができるため、ドローコールごとに最初と最後のスライスインデックス定数をアップロードする必要があります。
– また、シェーダにハードコードされた固定のスライス数は、非効率的であり、効率的な管理をするのは困難です。

これらの欠点を改善するために、私たちはGSデータの増幅ではなく、インスタンス化に基づいた別の方法を導入しました。
つまり、複数のスライスと交差するオブジェクトに対して、交差するスライスごとにオブジェクトのダイナミックなインスタンスを追加でレンダリングするのです。これは、ダイナミックな「sliceIndex」を、例えばワールドトランスフォームやカラーなどの値と一緒に、追加のダイナミックなインスタンスデータとして保存することで、このインスタンス化を、すでにうまくいけば行っている通常のインスタンス化と組み合わせることができるからです。
この方法では、GSはよりシンプルで効率的になり、どの出力スライスにレンダリングするかを選択するためだけに使用されます。


このテクニックの主な利点は、通常のインスタンス化と一緒に機能することで、交差するシャドウのインスタンスごとに1回ではなく、固有のシャドウオブジェクトタイプごとに1回のドローコールを行うことができることです。いくつかのヘビーなシーンでは、インスタンス化のみを使用した場合と比較して、ドローコールの回数が40%、従来のシャドウマップレンダリングと比較して90%削減されました。
また、この手法では、サポートするスライスの数がハードコードされていないため、シーンやエリアによって任意に変更することができます。
ただし、この手法の欠点は、GPUシャドウレンダリングの時間に若干の影響があることです。Radeonカードではわずか1%程度でしたが、Geforceでは5%程度遅くなっているようです。ただし、今回テストしたドライバーでは、パフォーマンス測定がそれほど安定していなかったので、それほど心配はしていません。ドライバーはまだこの使用シナリオにあまり最適化されていないのでしょう。

さて、別の話題に移ります。多くのゲームで影に関する一般的な問題は、カメラや光源を動かしたときに発生する典型的なフリッカーやエイリアシングのアーティファクトです。
これは高品質のシャドウマップフィルタリングで解決できますが、通常は非常に広いフィルタを必要とするため、GPUに大きな負担がかかります。
しかし、いくつかの制限に耐えることができれば、ほとんどのゲームで最も重要な原因の1つである、プレイヤーがビューを移動または回転させたときの静的ジオメトリからのフリッカリングを修正することができます。
ここでは、BFBCのシャドウフリッカリングの例を紹介します。プロジェクターで見やすくするために、シャドウマップの解像度を1024ではなく512に下げています。


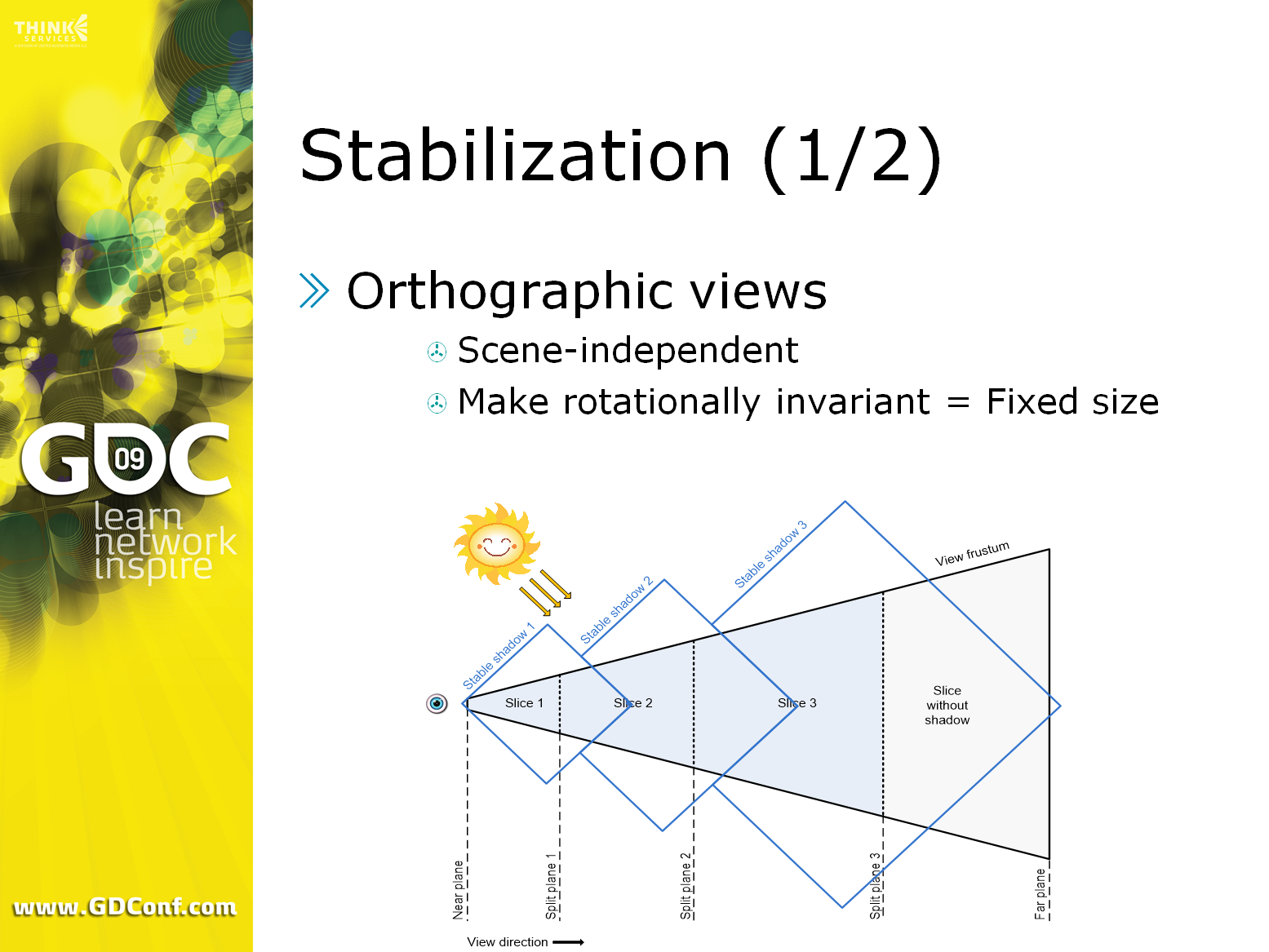
そこで、安定してちらつかないシャドウを作成する方法として、カスケード接続された各シャドウマップスライスに正射影を使用し、これらをシーンに依存せず、固定サイズにすることにしました。
シーンに依存しないことは完全には必要ではありませんが、管理が非常に容易になります。また、一般的には、特殊なケースやシャドウキャスターとレシーバーがどこにあるかに関わらず、シーン全体で一定のシャドウ品質を求めます。
固定サイズは、カメラの回転に伴って発生するライトスペースのスケーリングを排除するために重要であり、以前は各スライスフラスタムに対して最適なライト空間バウンディングボックスを取得しようとしていました。
これらの固定サイズのスタビライズされたシャドウビューは、最悪のケースを表現できる必要があるため、ベストフィット法よりも大きくなります。これには重要な意味がありますが、後で説明します。

各スライスのライト空間スケーリングが同一であることを確認した後に必要なもう 1 つのステップは、シャドウマップビューのライト空間変換を偶数テクセル増分に丸めることです。これにより、サブピクセルオフセットのためにカメラの移動に伴ってオブジェクトのラスタライズが変更されるのを防ぐことができます。
これらの安定化手順を実行しても、FOVの変更時や太陽の回転時に静的ジオメトリの影がちらつくことがありますが、多くのゲームでは、単に変更しないことで回避できます。
高品質のシャドウマップフィルタリングであっても、シャドウを安定させることは、最も一般的なちらつきの原因のいくつかを取り除くことになるので、良いアイデアであると言えます。

シーンをレンダリングする際には、各ピクセルに対して、そのピクセルがある領域をカバーする適切なシャドウマップスライスをサンプリングする必要があります。
これには複数の方法がありますが、最も簡単な方法の1つは、ビューフラスタムをより小さなフラスタムに分割するスライス平面を使用することで、それぞれにシャドウマップを生成します。
シェーダは、ビューポートZを使ってスライスシャドウマップを選択するか、クリップ平面を使ってシーンをレンダリングするかを選択できます。しかし、この方法はスタビライズ処理とは完全に互換性がなく、シャドウマップビューがスライスフラスタム上のベストフィットを使用するので、影がちらつくことになります。
より良い結果が得られ、スタビリゼーションと互換性のある別の方法は、各シャドウマップスライスに境界球の比較を使用することです。これは『Killzone2』で使用されており、見た目は素晴らしいですが、バウンディングスフィアを正射影フラスタム(実際にはバウンディングボックスに過ぎない)内にフィットさせようとしているため、バウンディングスフィア間に若干のオーバーラップが発生します。この重なりにより、各スライスで得られる効果的な解像度が低下します。
BFBC/Frostbiteで使用しているこの第3の方法は、シャドウスライスビューのバウンディングボックスを直接使用するもので、どのスライスを使用するかを正確に決定するために複数のピクセルごとのバウンディングボックステストを行います。これはバウンディングスフィア法ほどオーバーラップしないので、より高い効果的な解像度が得られますが、シェーダーがより複雑になるという代償を伴います。
バウンディング・スフィアはバウンディング・ボックスとほぼ同じ範囲ですが、バウンディング・ボックス法に比べてスライス内の解像度が低くなります。
バウンディングボックスは、バウンディングボックスが拡大され、より多くの領域をカバーするため、スタビライゼーションとの相性が特に良いです。フィット感と解像度の利用率が格段に向上します。




パフォーマンスのためテクスチャ座標は[-0.5, +0.5]の範囲内です。

この部分の話の締めくくりとして:
シャドウマップ・ビューの移動と回転を安定させることで、静的なジオメトリからのフリッカーを低減します。
これには、シャドウマップビューを拡大するという副次効果がありますが、これは、シェーダのバウンディングボックステストを使用して、どのシャドウマップスライスを使用するかをピクセルごとに選択することで、有利になります。このバウンディングボックステストにより、長方形のシャドウマップの利用率が最大化され、より高い実効解像度と長い実効シャドウビュー 距離が得られます。
シャドウマップレンダリングの CPU コストを削減するために、シャドウマップテクスチャ配列に直接レンダリングし、インスタンス化と GS を併用することで、シャドウキャストオブジェクトの数にかかわらず CPU のレンダリングコストを一定にし、GPU コストを小さくしています。