こんねねー。Pocolです。
今日は,
[Drobot 2017] Michal Drobot, “Improved Culling for Tiled and Clustered Rendering Call of Duty Infinite Warfare”, SIGGRAPH 2017 Advances in Real-time Rendering in Game course, 2017.
を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘頂ける場合は正しい翻訳例と共に指摘して頂けると有難いです。
また,特に断りが無い限り,図は[Drobot 2017]からの引用になります。


この講演では、『コール オブ デューティ インフィニット・ウォーフェア』のために開発された新しいカリング技術を紹介します。


近年,私たちは複数のForward+ / Deferred+メソッドに慣れ親しんできました。
最もポピュラーなものはライトカリング[JOH09]ですが,同様のアルゴリズムは,デカール[SOU16],反射プローブ[SOU16],ボリューメトリック[DRO17]など,他の多くのレンダリングエンティティに対しても実装に成功しています。
基本的な実装は次のように構成されます:
– レンダリングエンティティのリスト
– カリングされたエンティティリストを含む空間高速化機構
– サンプリングポイントごとに各エンティティに対して実行される実行アルゴリズム。データ構造をトラバースするだけでなく、個々のエンティティに対する操作(デカール貼付やライトシェーディングなど)を実行することもできます。
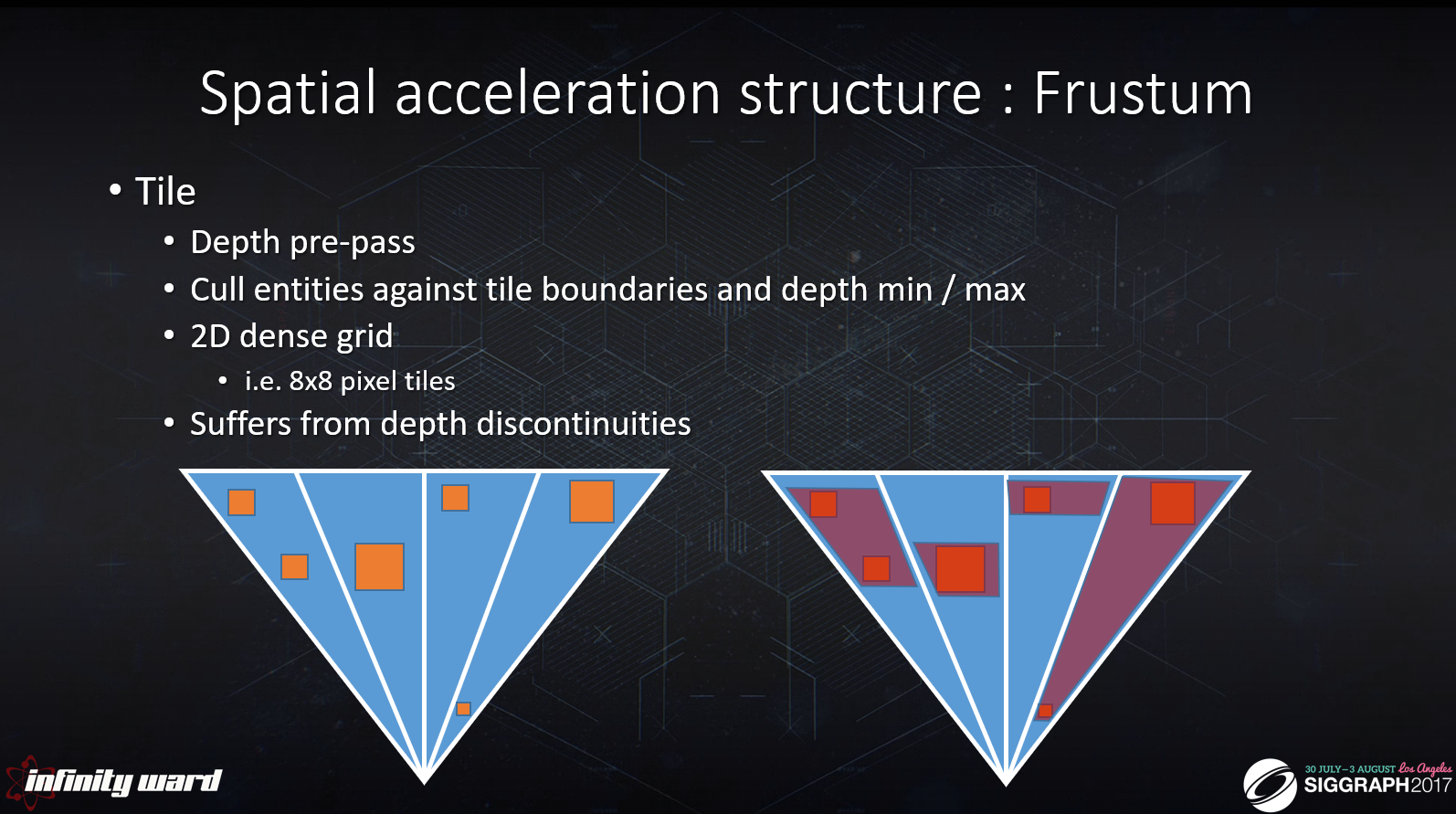
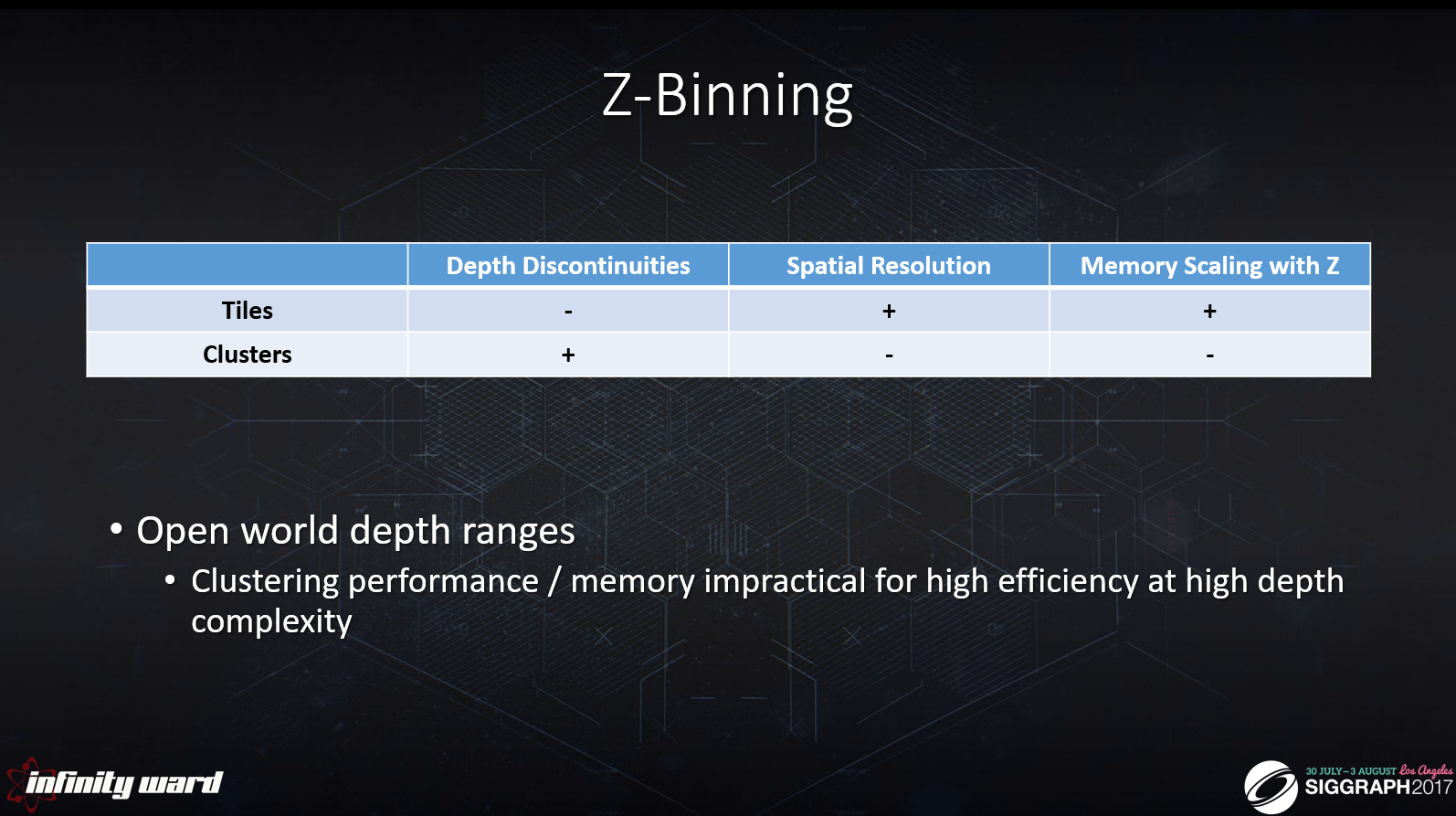
フラスタム空間は効率的で、解像度や複雑さを容易に拡張できることが知られています。
基本的な高速化機構は2Dタイルグリッドです。
効率的なカリングのために深度プリパスが必要です。
エンティティは、タイルの最小および最大Zプレーンに対してカリングされます(Z平面は、タイル内の深度バッファ値から導出されます)。
タイルアプローチは、メモリ消費量が少ないため、高解像度が可能です。
しかし残念ながら、深度の不連続性に悩まされます。1つのタイルに互いに離れた深度値が含まれる場合、最小Zと最大Zの間にある複数のエンティティがタイルに引き込まれてしまうため、カリング効率は最適ではなくなります。
これはまた、タイル内の個々の深度値のZ範囲内にないエンティティを引っ張る結果になることもあります。
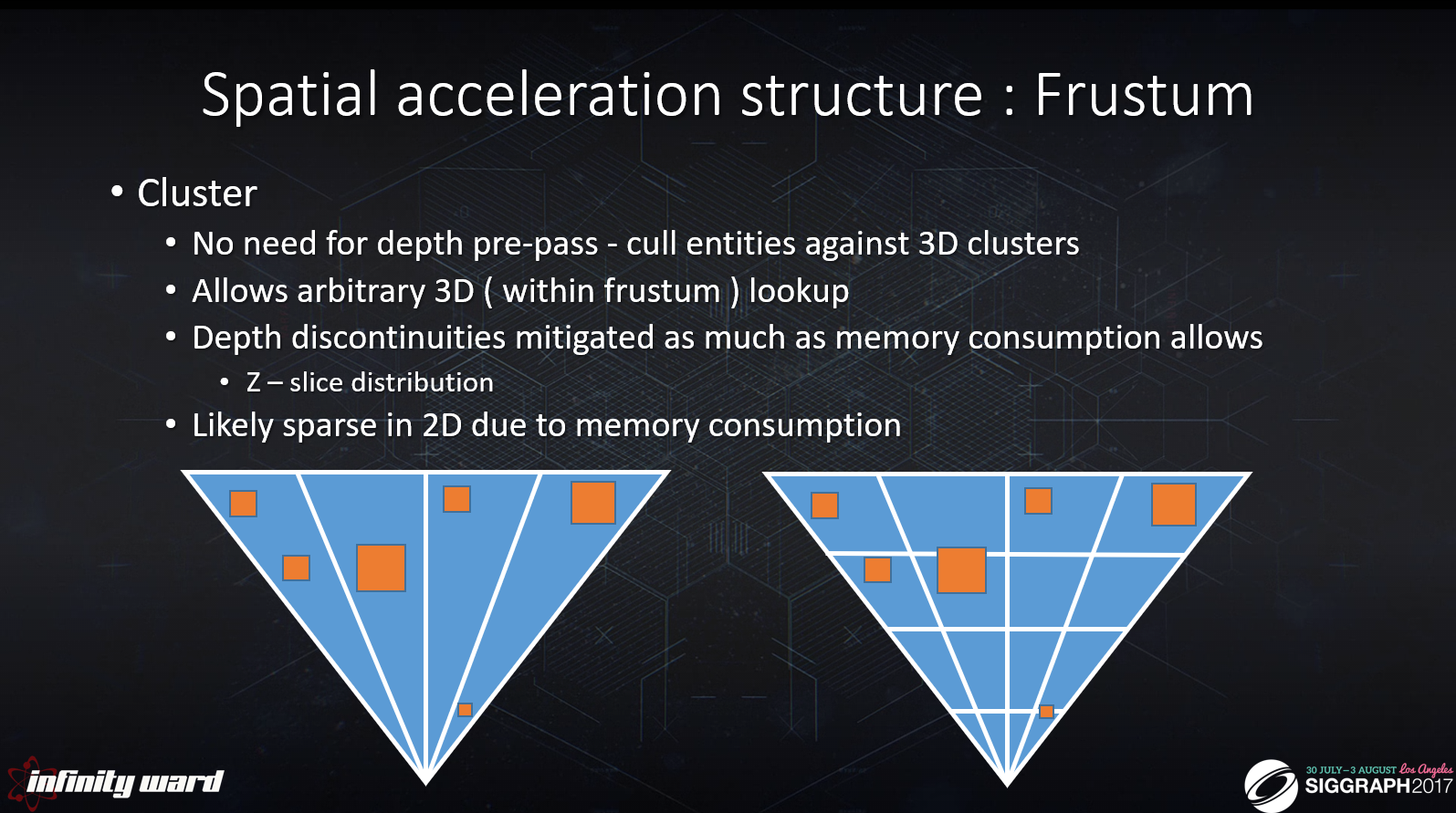
クラスターアプローチは完全に3Dで動作し、深度プリパスを必要としません。
その代わり、フラスタムはあらかじめ定義された量のクラスター(ミニ・フラスタ)に分割されます。
クラスタがビューフラスタムをカバーすると仮定すると、空間内の各点の値を調べるのは、フラスタム空間での些細な3Dルックアップになります。
また、(タイル・アプローチとは対照的に)Z次元で空間を断片化するため、奥行きの不連続性が部分的に緩和されます。
しかし、このような利点は、タイルの単一のスライスとは対照的に、クラスタの複数のZスライスを格納するコストを伴います。
したがって、クラスターバッファのX/Y解像度は、タイルバッファに比べてかなり低いようです。
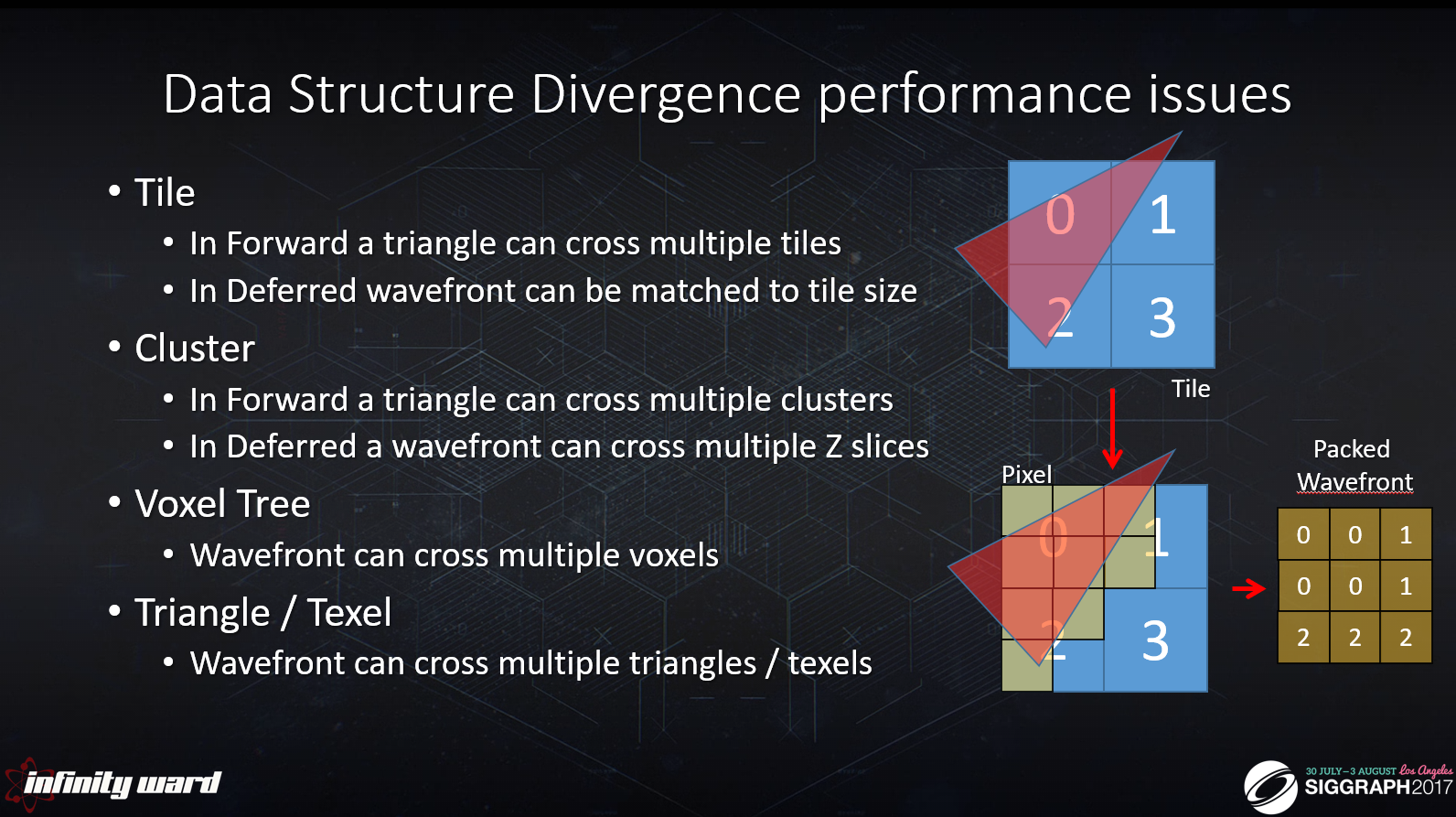
最新のGPUで処理する場合、前述の各構造はダイバージェンスの問題に悩まされる可能性があります。
ピクセルシェーダまたはコンピュートシェーダのウェイブフロントがデー タ構造を読み込んで処理するとき、内部ダイバージェンスが発生する可能性があります。
同じウェイブフロントが複数のタイル、クラスタ、ボクセル、三角形をクロスすることがあり、スレッ ドが複数のデータソースから読み込む原因になります。
データ構造によっては、ダイバージェンスを最小化することができます(つまり、遅延カーネルサイズとデータ構造のレイアウトを一致させる)が、最終的には、他の次元のためにダイバージェンスを回避することはできません。
ピクセルシェーダでは、ダイバージェンスの増加は、ヘルパースレッドとスキャンコンバータパターンが複数のピクセルを一緒にウェイブフロントに詰め込むことによって引き起こされる可能性があります。
データ構造のダイバージェンスにのみ焦点を当てますが、エンティティタイプのダイバージェンスなど、ダイバージェンスのポイントは他にもあります。



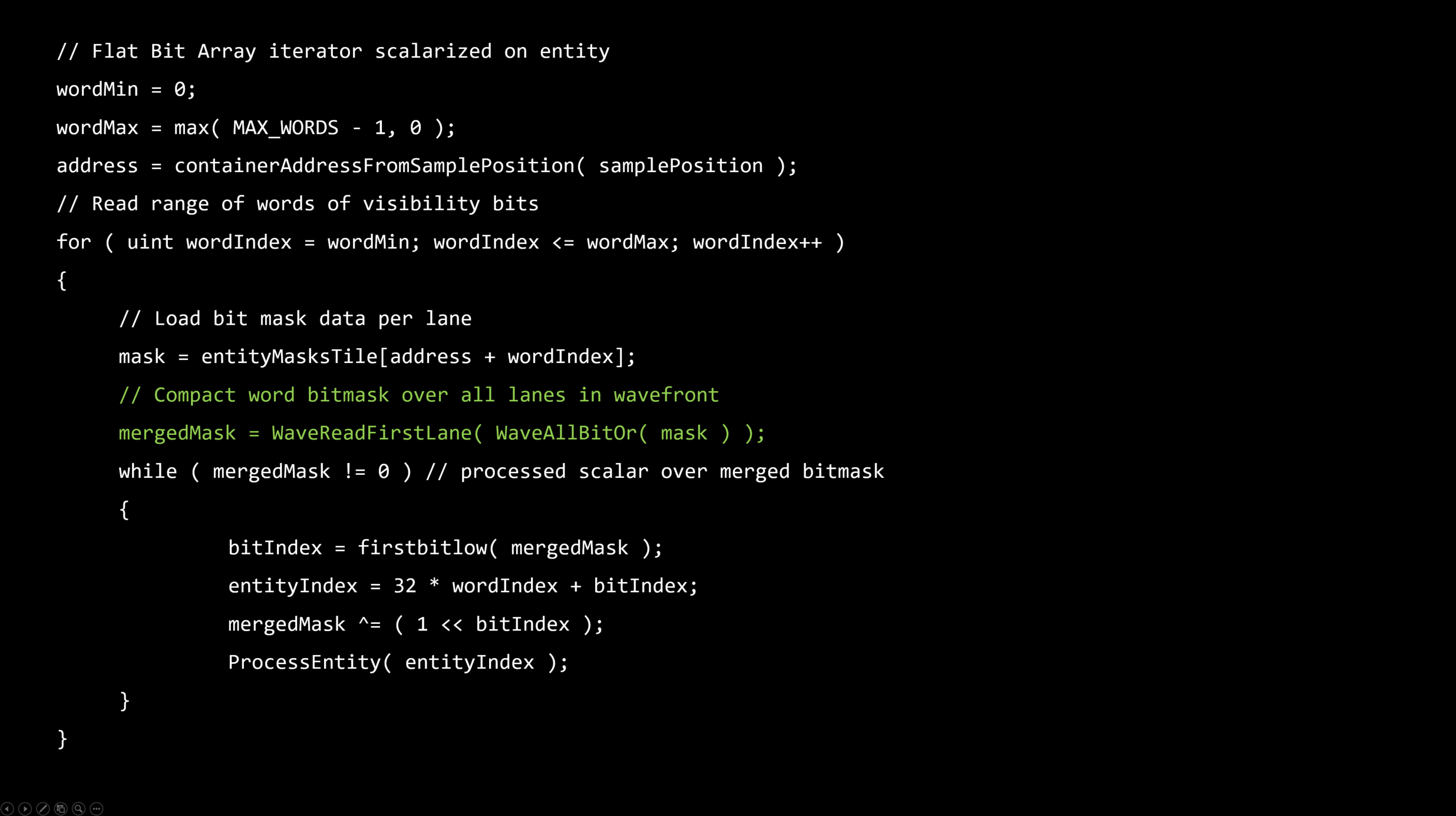
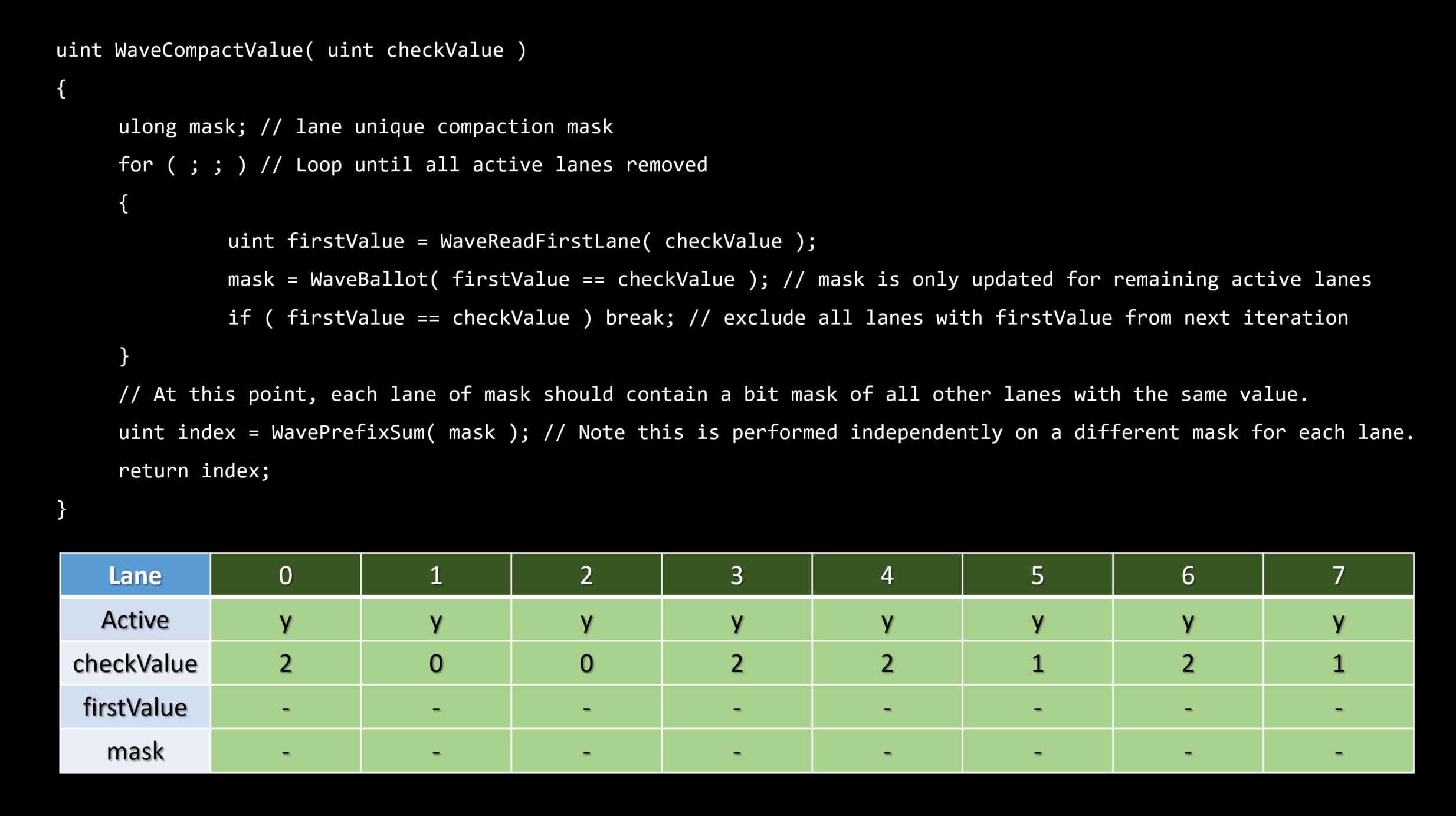
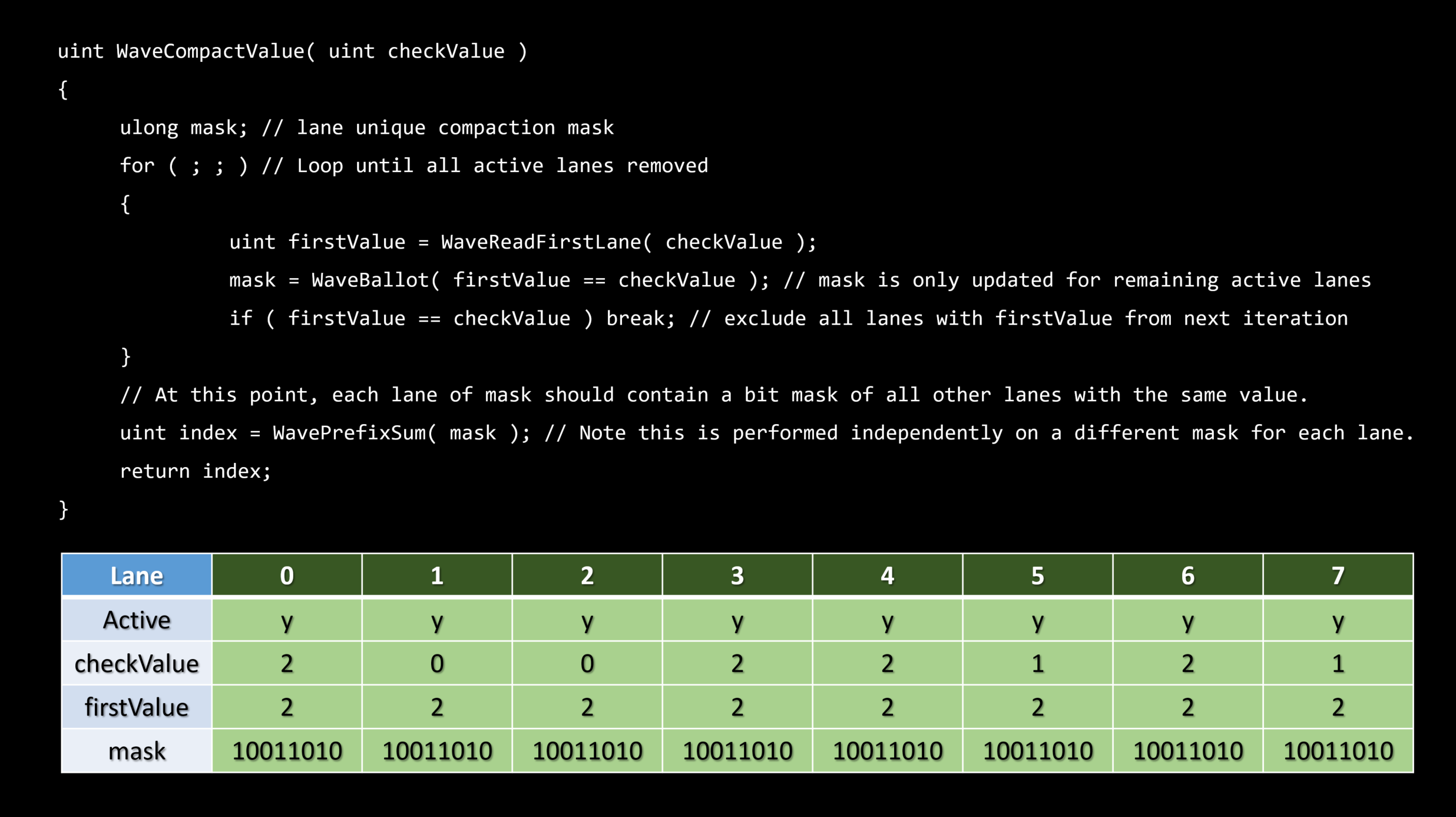
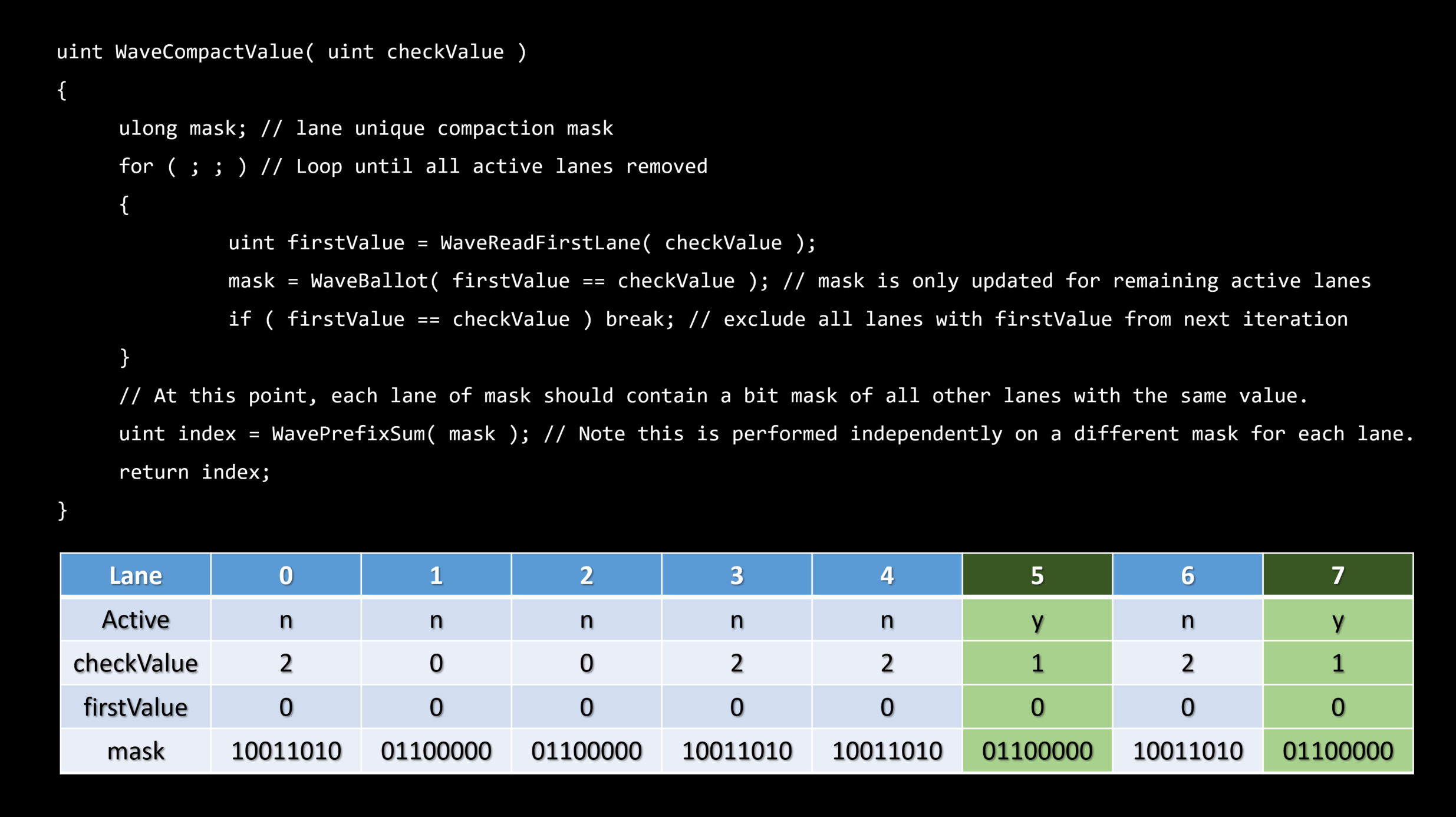
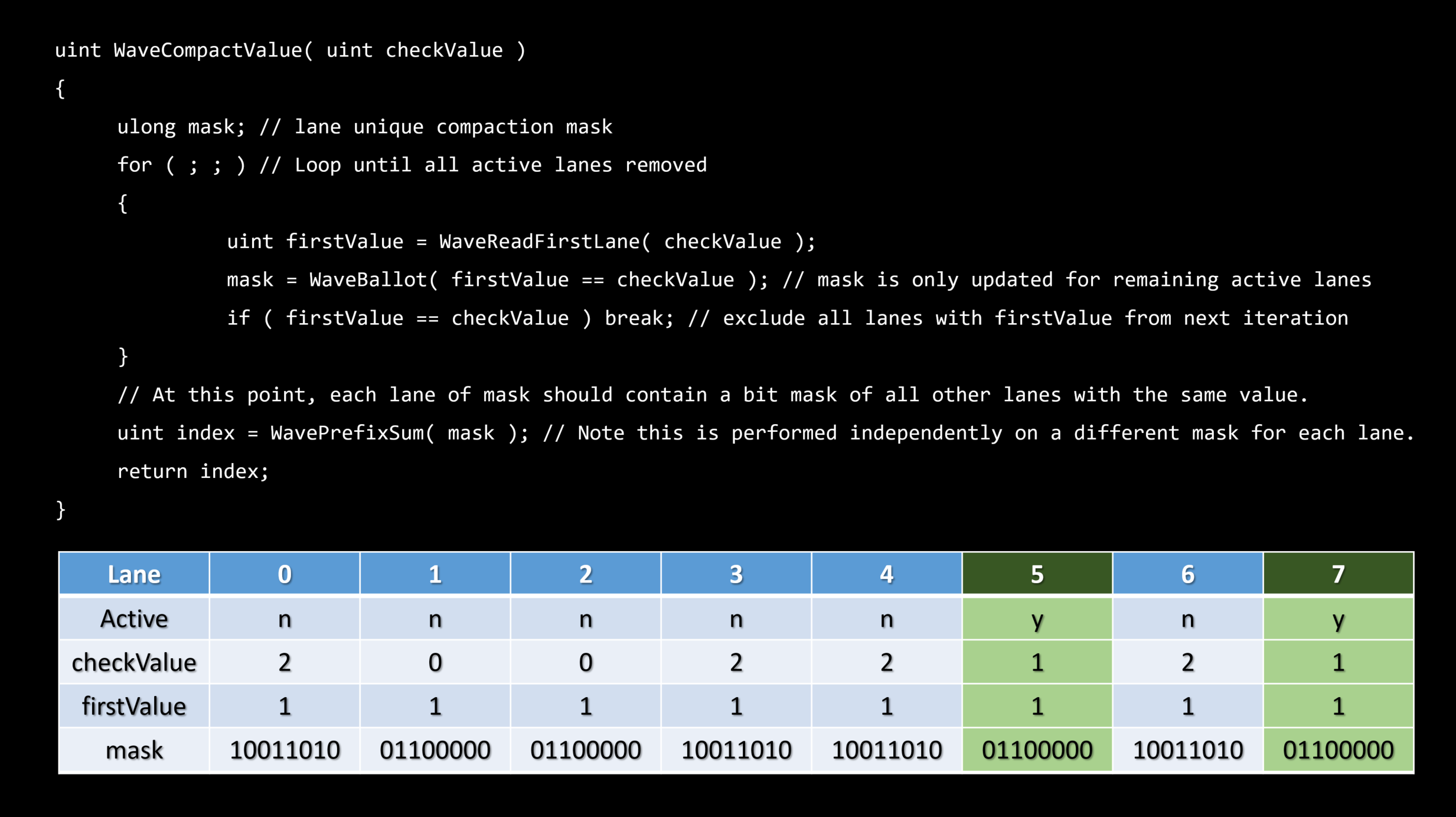
スカラライゼーションとは、ダイバージェントベクトル化されたアルゴリズムを直列化されたコヒーレントなものに変更するプロセスです。
シリアライゼーションは、スループットを向上させるだけでなく、コヒーレント実行のために予約されたいくつかのハードウェア機能を利用するために、アイテムについて発生します。
GCNの場合、GPUのウェイブフロント占有率とともに、スカラー・メモリ・ユニットとベクトル・メモリ・ユニットの意識的なバランス調整が可能になります。

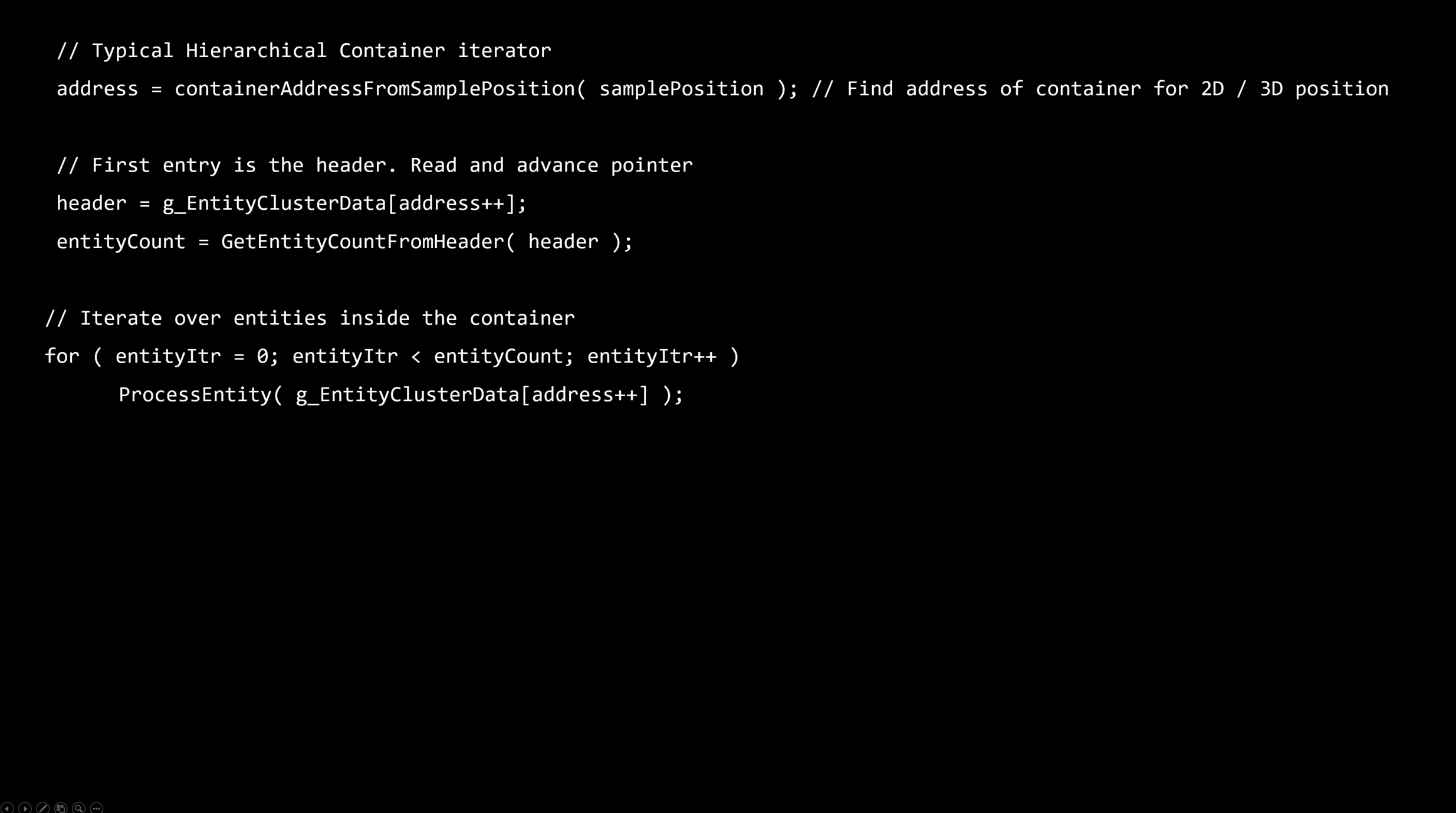
リーフクラスタへのポインタ。
・リーフクラスタは、各エントリ内に可視エンティティへのすべてのポインタを格納します。
・エンティティの数に縛られない。
・インダイレクトによる高価なトラバーサル
・可変メモリー・ストレージ・コスト

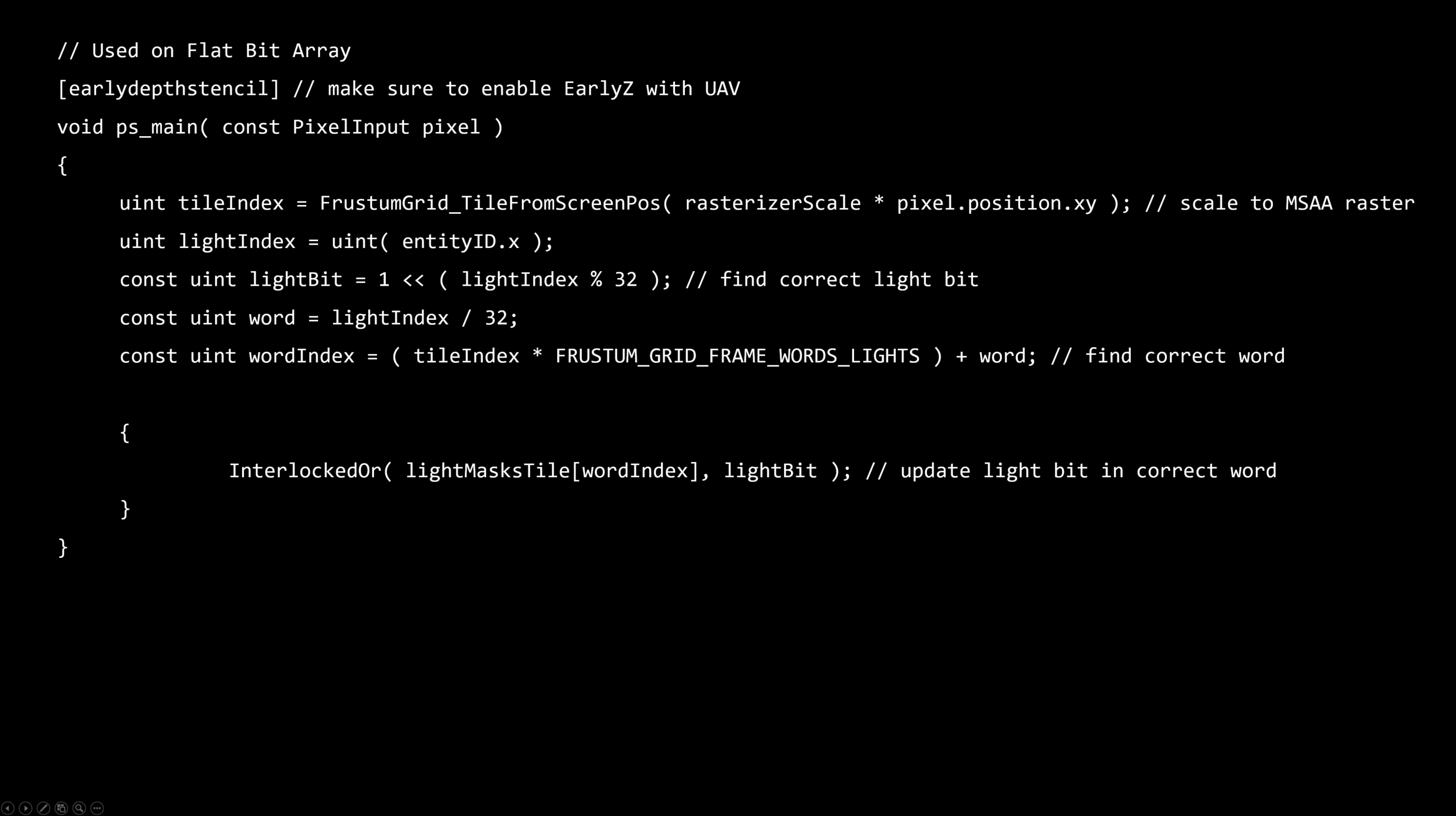
シェーダは完全にスカラライゼーションされました。
・VMEM/SMEMとVALU/SALUのバランスが良くなりました。
・低いVGRP使用です(フォワードコンスタントローディングと同様)
パフォーマンスの変動は激しい
・同じエンティティが異なるコンテナに存在する場合,ウェイブフロントは複数回エンティティを処理する可能性があります。
・データコヒーレンシーに依存します/冗長性により速度が低下する可能性があります。
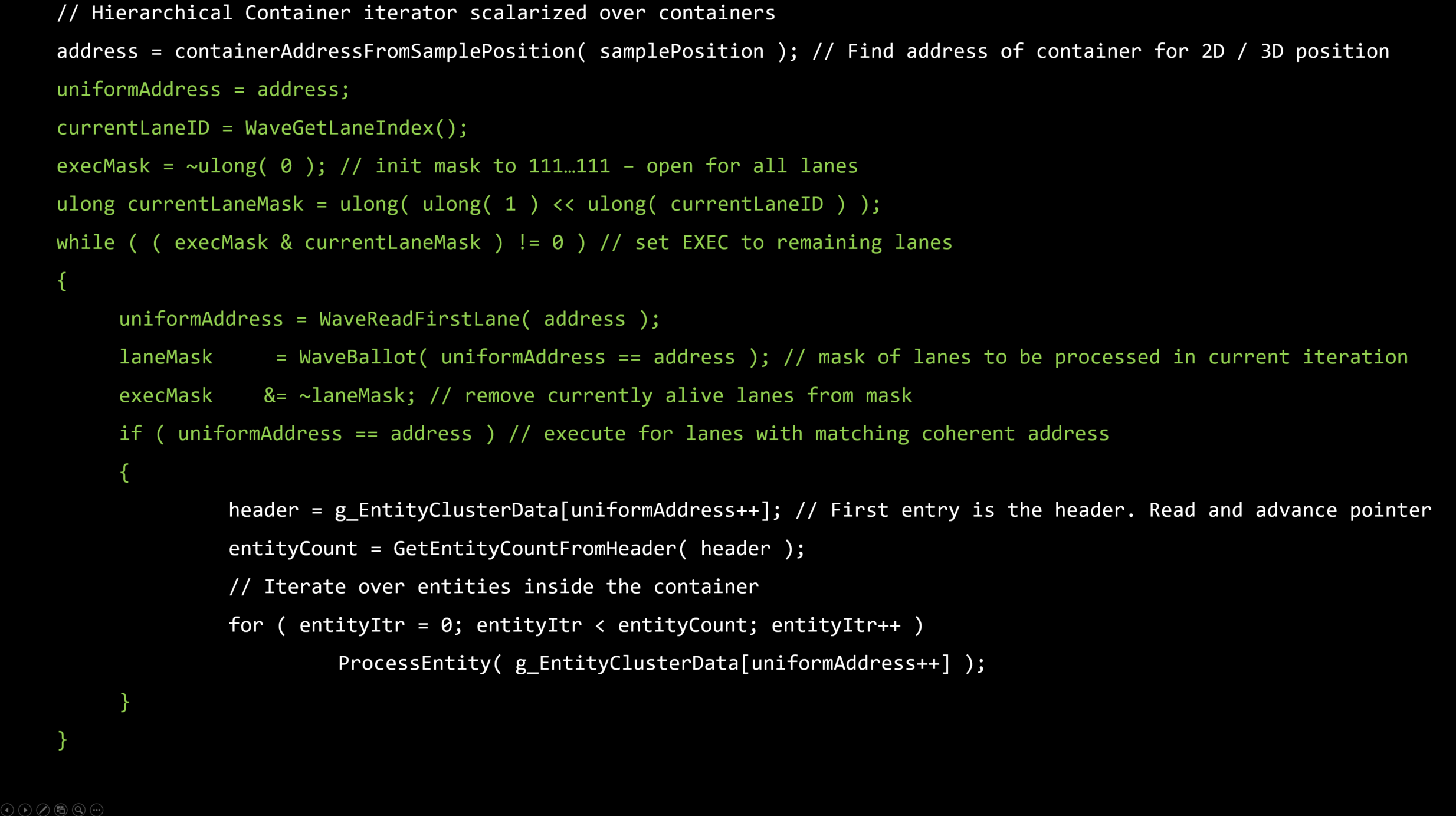
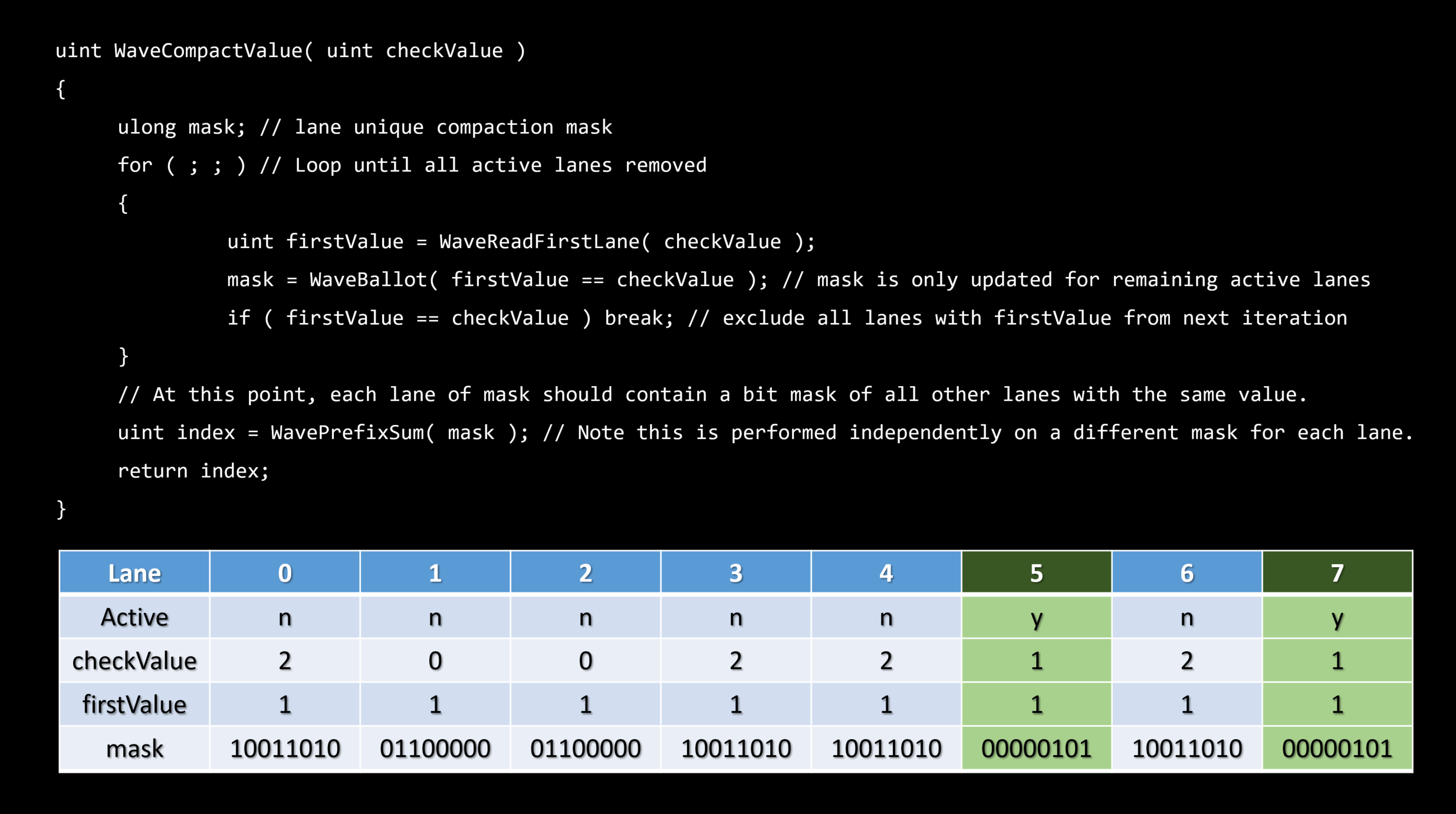
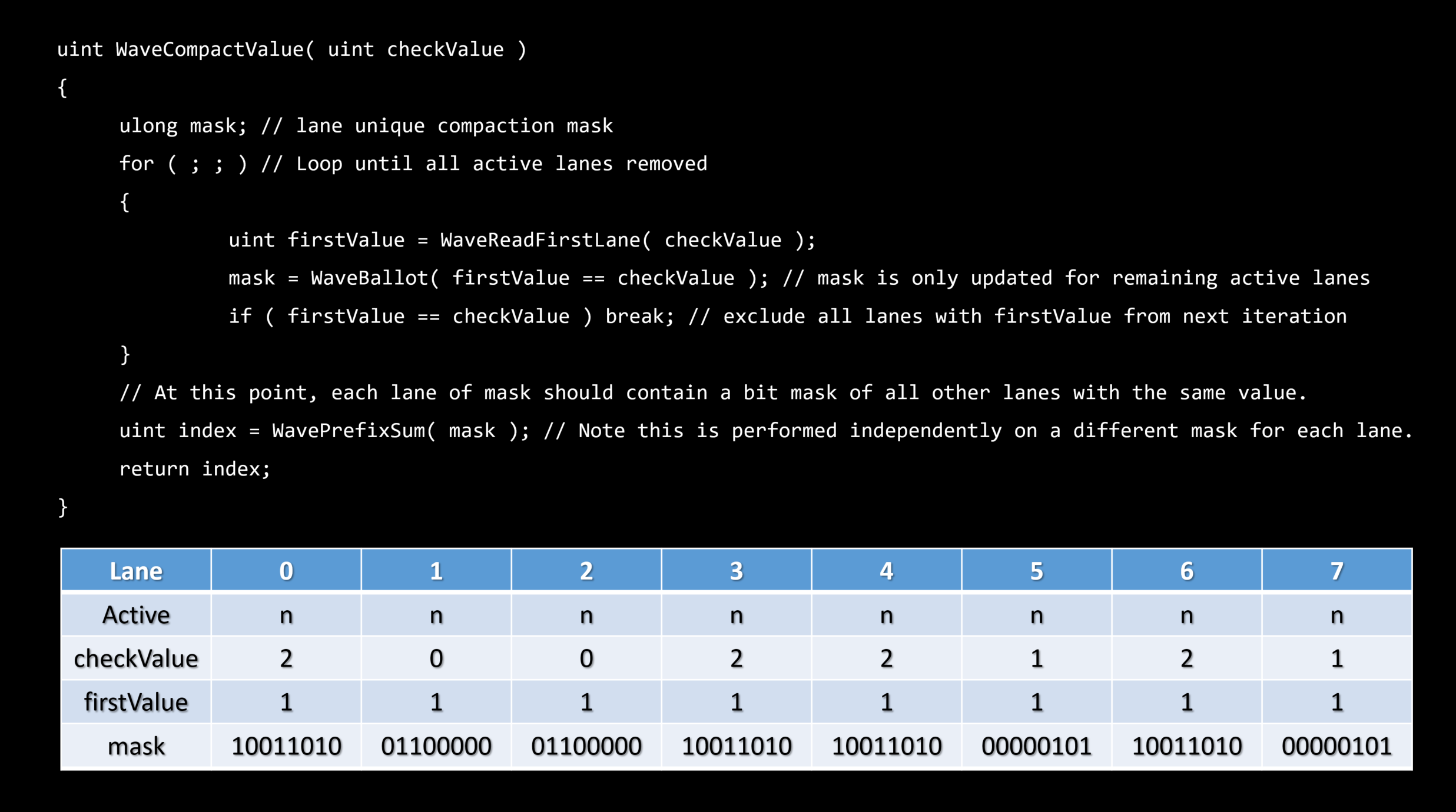
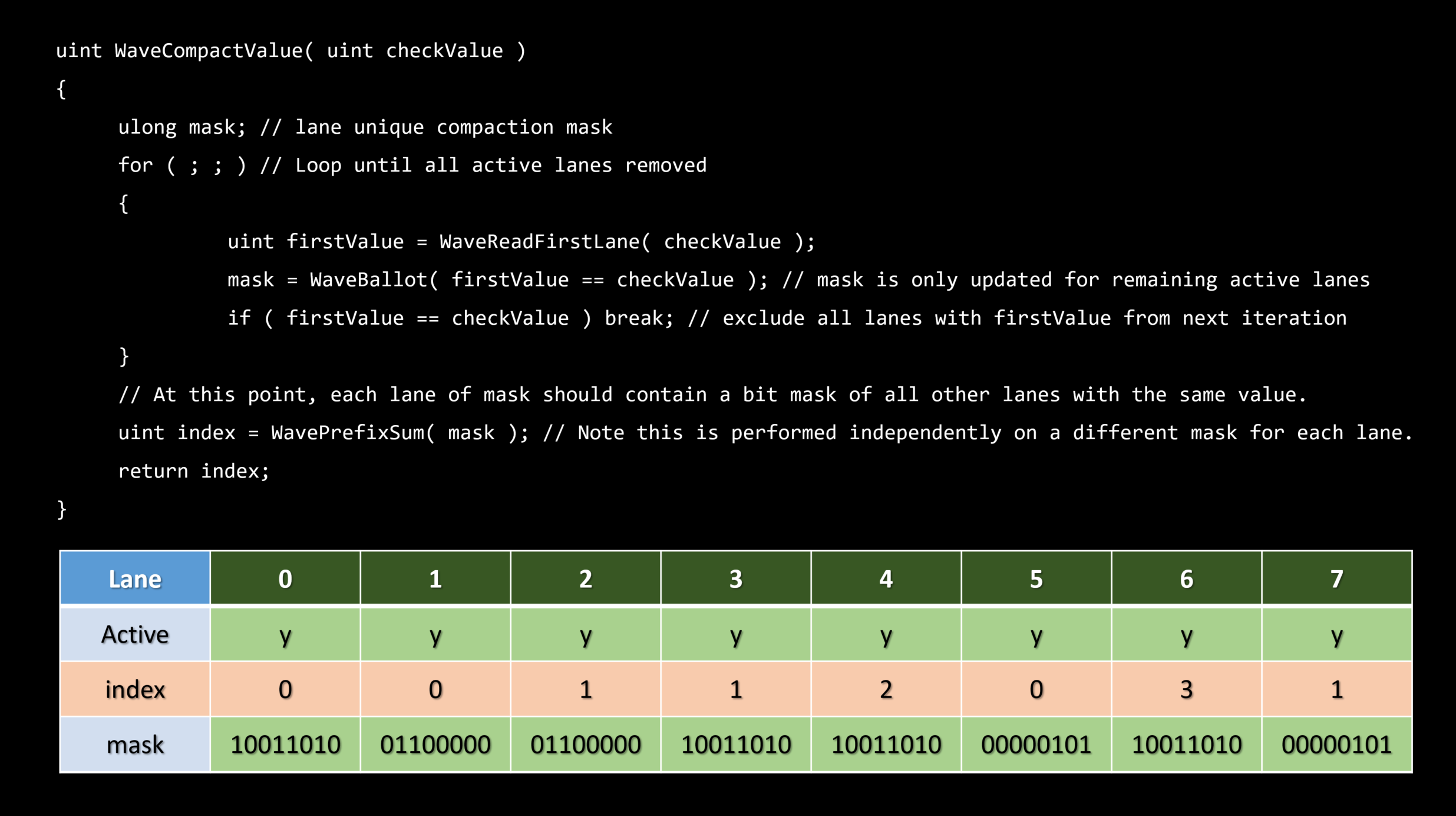
理想的にはエンティティレベルでスカラーライズする。
・これは順序付けられたコンテナを必要とします – フラットなビット配列

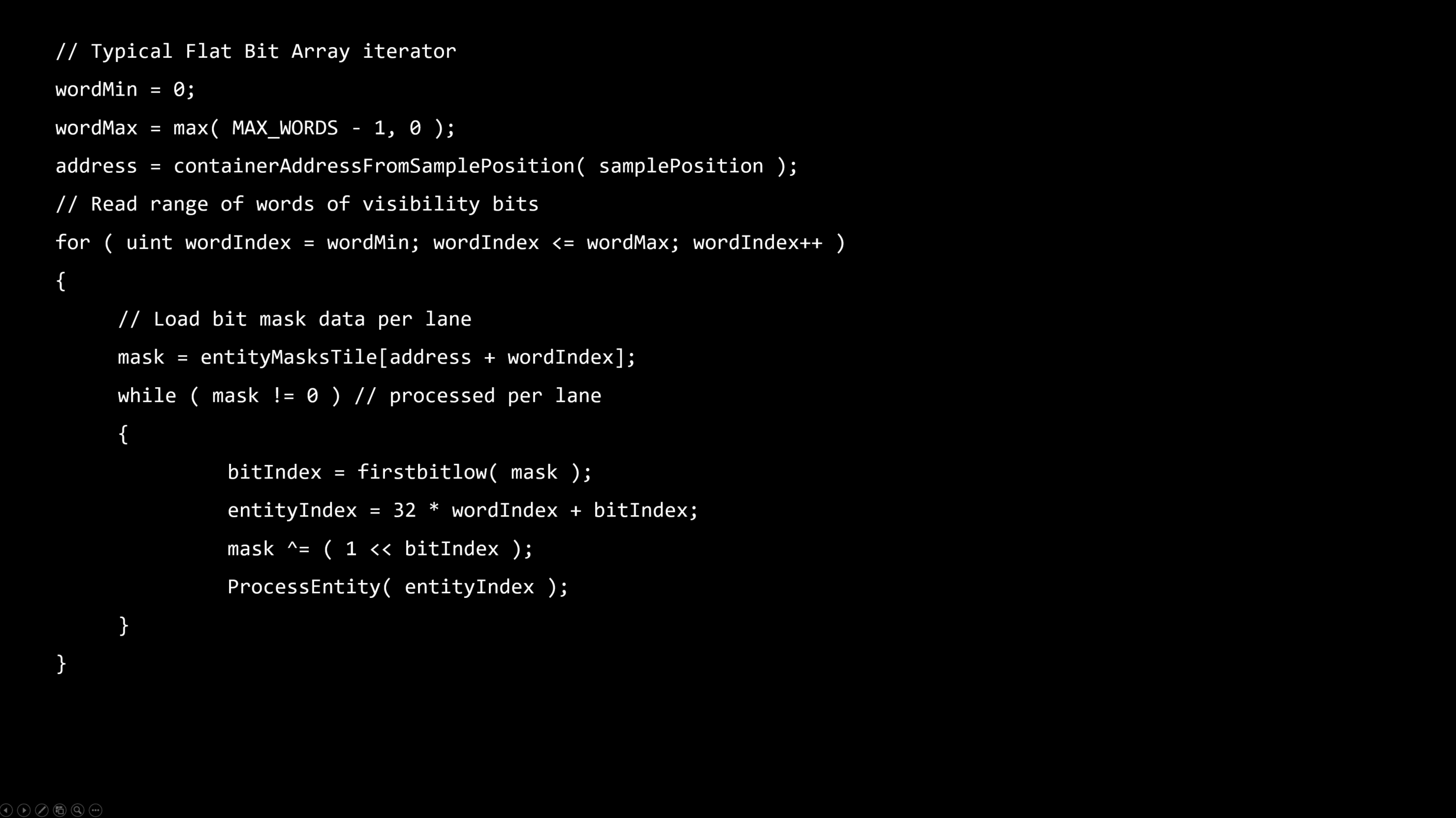
フラットなビット配列
・ビットの集合 - N番目のビットはグローバルリストからのN番目のエンティティの可視性を表現します。
・シンプルなトラバーサル – ビットに沿って反復する
・メモリ/エンティティバウンド - フラスタムごとのコンテキスト上で多く場合使われます。

合成テストシェーダーは、Sponzaアトリウムのシーンを使用し、128個のシャドウライトを使用しました。


異なるデータ構造には異なる長所と短所があります。
メモリ制約のため、ほとんどのアプリケーションは、エンティティ高速化機構をビュー空間(フラスタム空間)で再計算することにしています。
そのため、最も使用される構造はタイルとクラスタです。

大きな奥行きスパンを持つ典型的なシーンを見てみましょう。
このシーンでは、256個のライトが表示されており,Zは4マイルに亘ります。

このビューは、同じXY座標のZ内のすべてのクラスターのライトの合計を示しています。
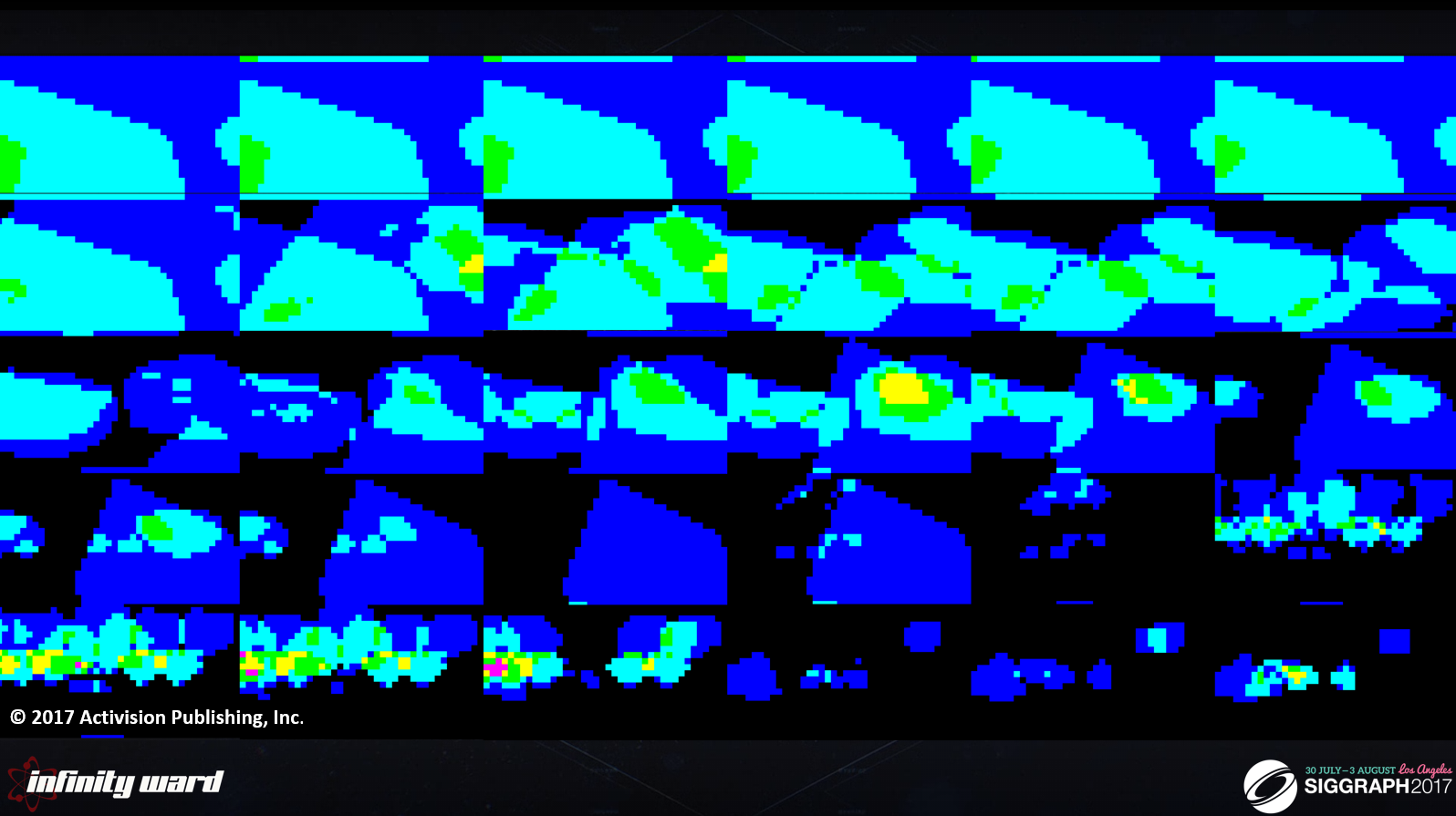
クラスター化したバッファーの各Zスライスからのライトカウントを個別に示しています。

前ビューから見えるレベル内のライトをトップダウンで見ます。
前の一人称視点からのビューフラスタムです。
グローバルなZスライスにグループ化された複数のライトを簡単に見分けることができます。
さらに進むと、共通のZスライスを共有する別のライトのセットが見つかります。
さらに…
Zスライスでフラスタム全体を分割したことで、観察が可能になりました。
カメラの視点からは、異なるスライスのライトはXY座標で重なることができますが、Zスライスで分離されているため、Z座標では重なりません。
シーン調査による観察:
ほとんどのライトはX&Y&Zで同時に重ならない
XYライトカリングとZライトカリングを切り離す
ほとんどの人工的な環境は、カメラの視点からXYで重なる。あなたの判断は異なるかもしれません。
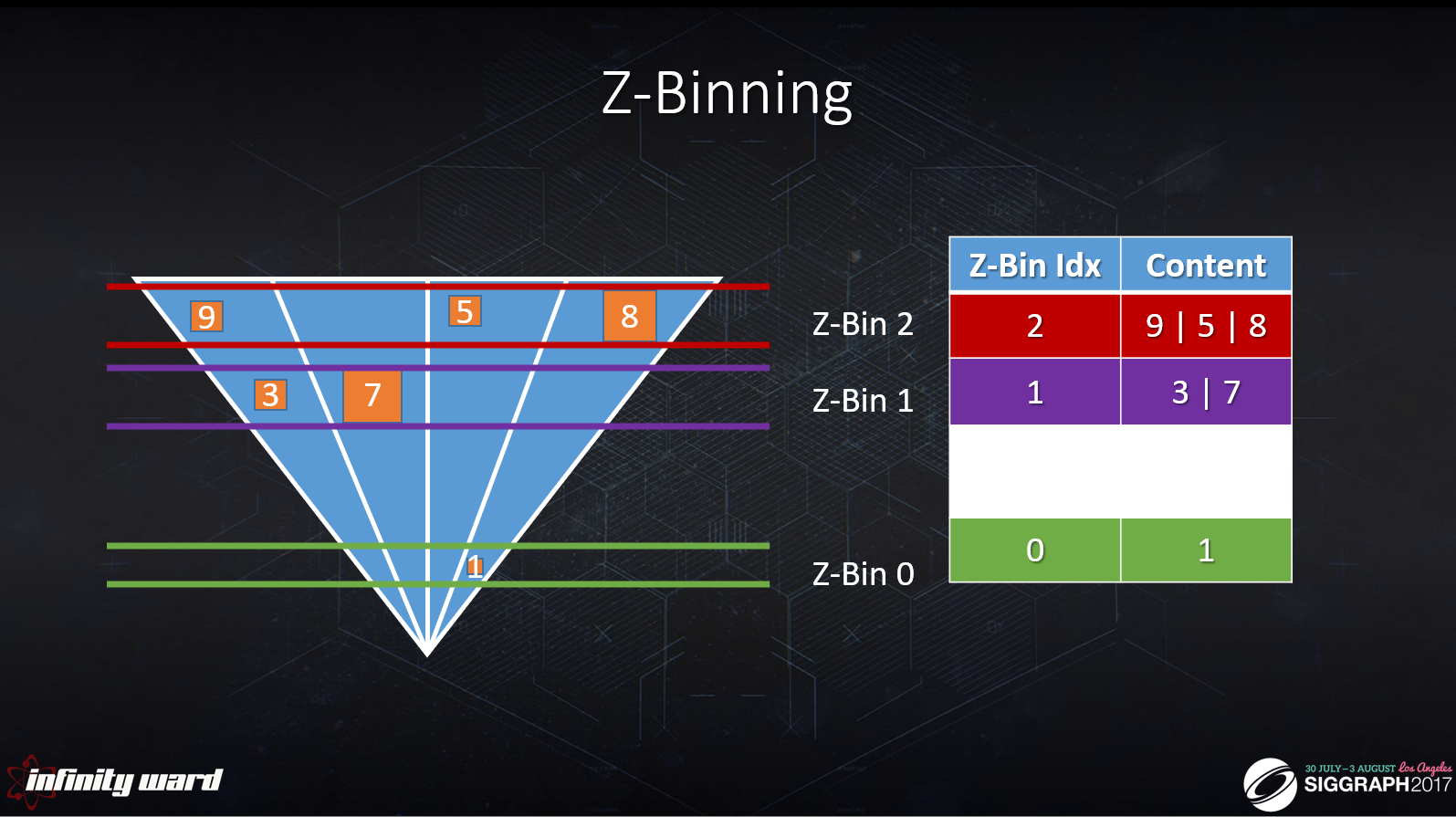
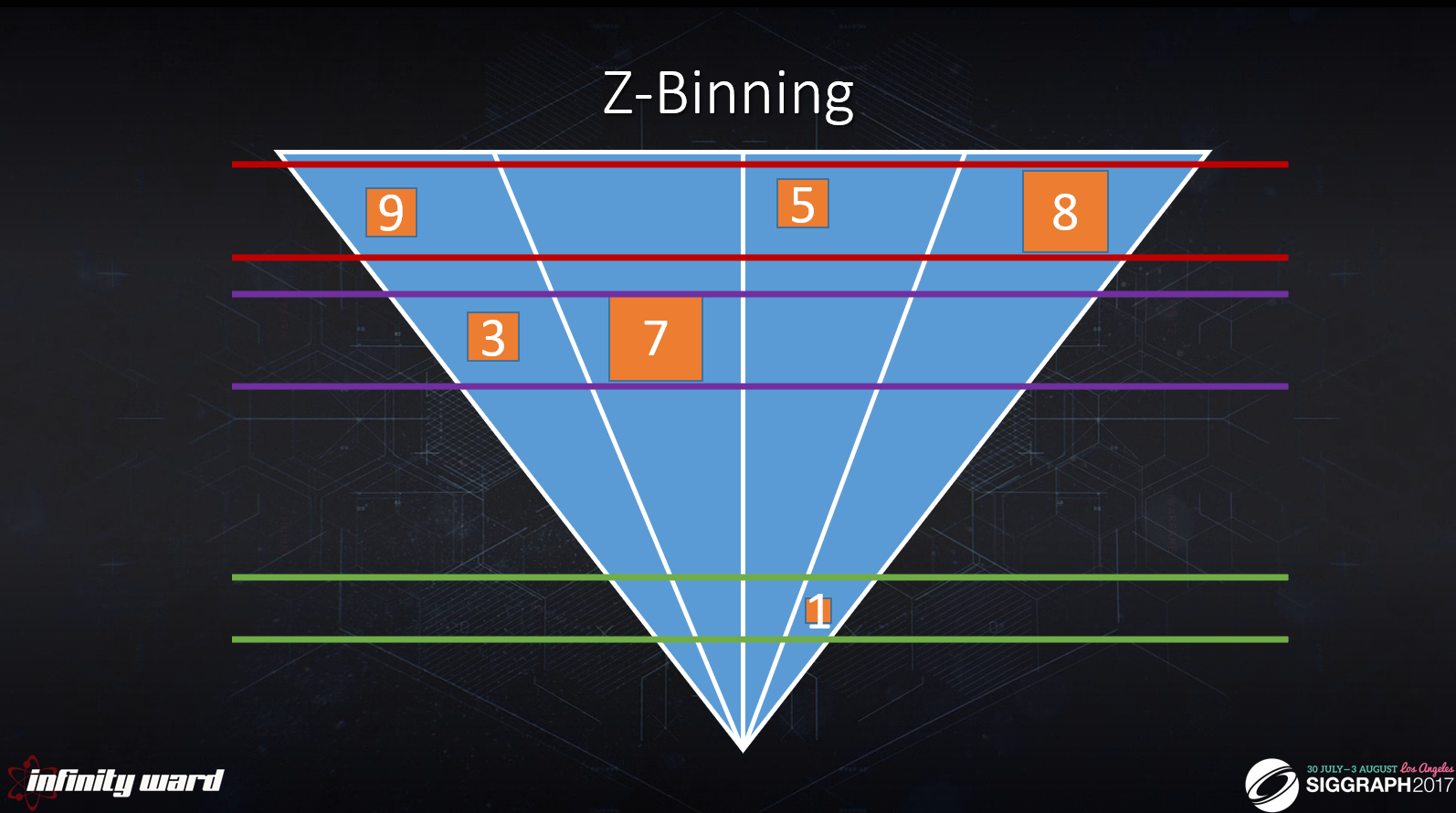
Z-ビニングは、3D高速化機構(クラスターバッファなど)をよりシンプルでコンパクトな構造に分解する技術です。
2つの構造を作成します:2Dタイル、1DのZビンです。
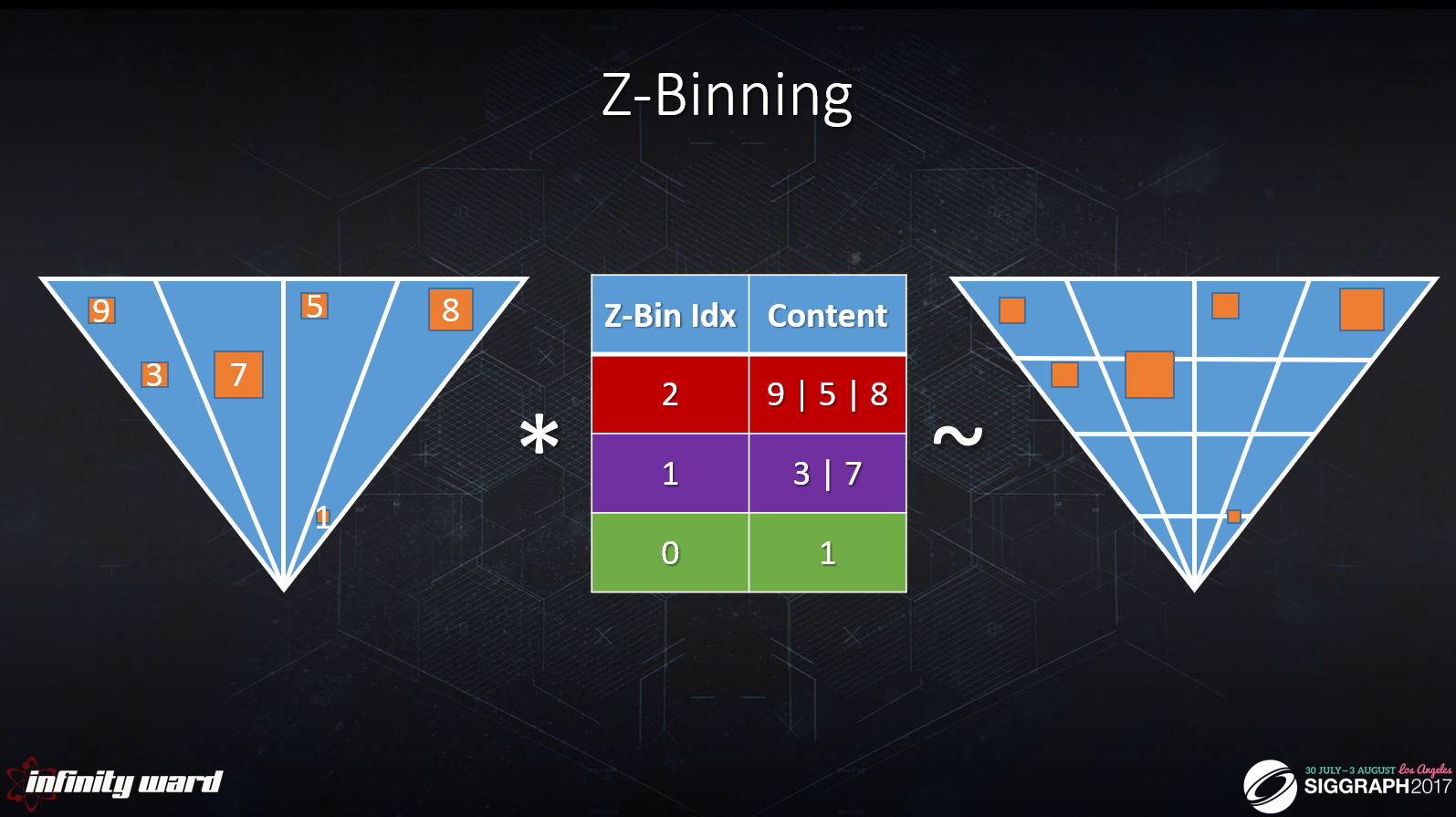
ルックアップ時に交点を評価します。
ライトが同時にXYとZに重ならない場合、タイルバッファとZ-Bin配列の交点はクラスター化されたバッファと等価です。
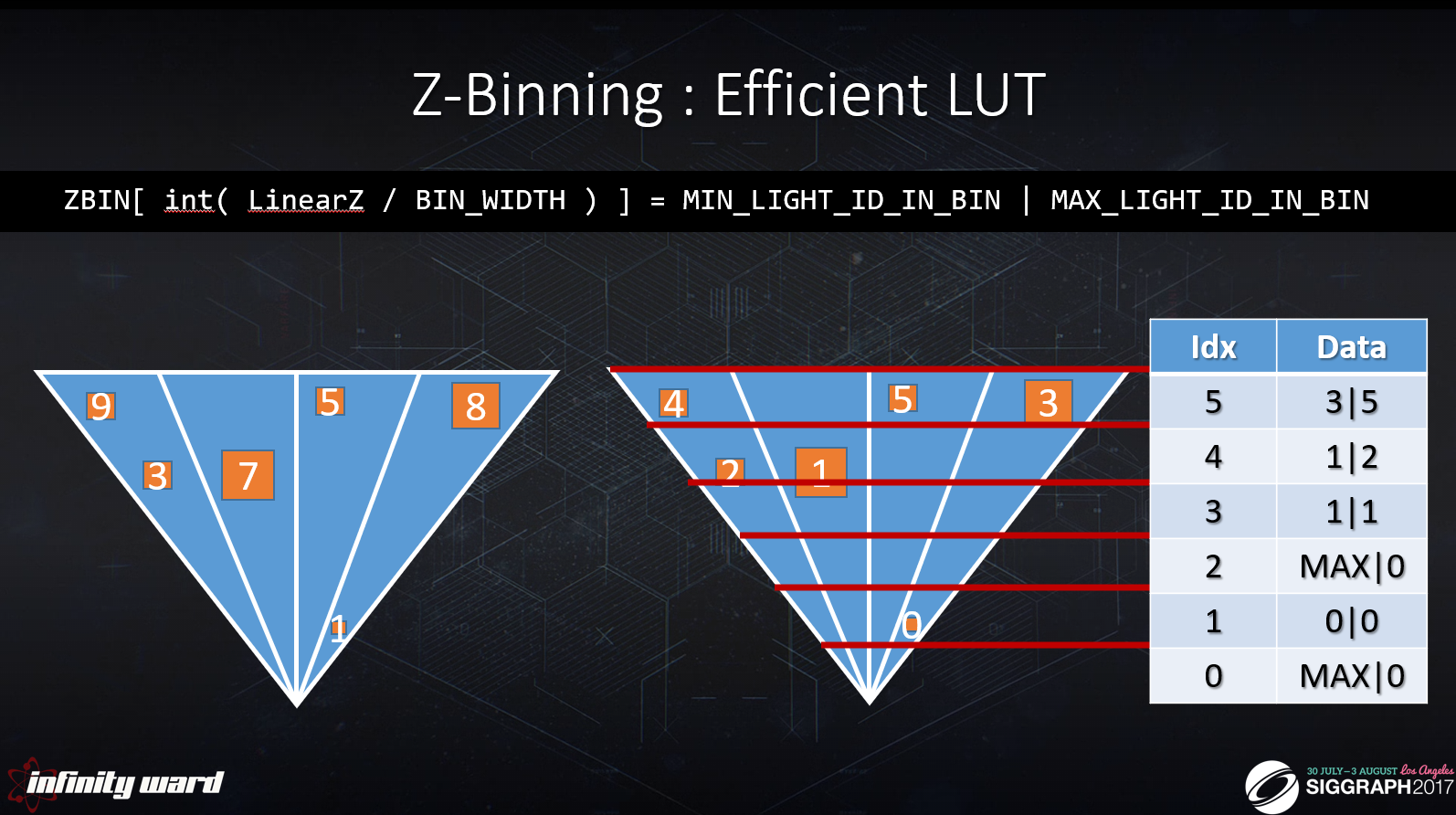
線形深度によるインデックス
ビンの幅は均一
カメラまでの距離でエンティティをソート
ビン内の範囲をMIN | MAX ID形式で保存可能
MAX | 0 の値は空のビンを示します。

CPU
・Zによってライトをソートする
・可能な全深度範囲にわたって一様に分布したビンを設定する。
・各ビンの領域内の MIN/MAXライトIDで 2x16bit LUTを生成する。
GPU
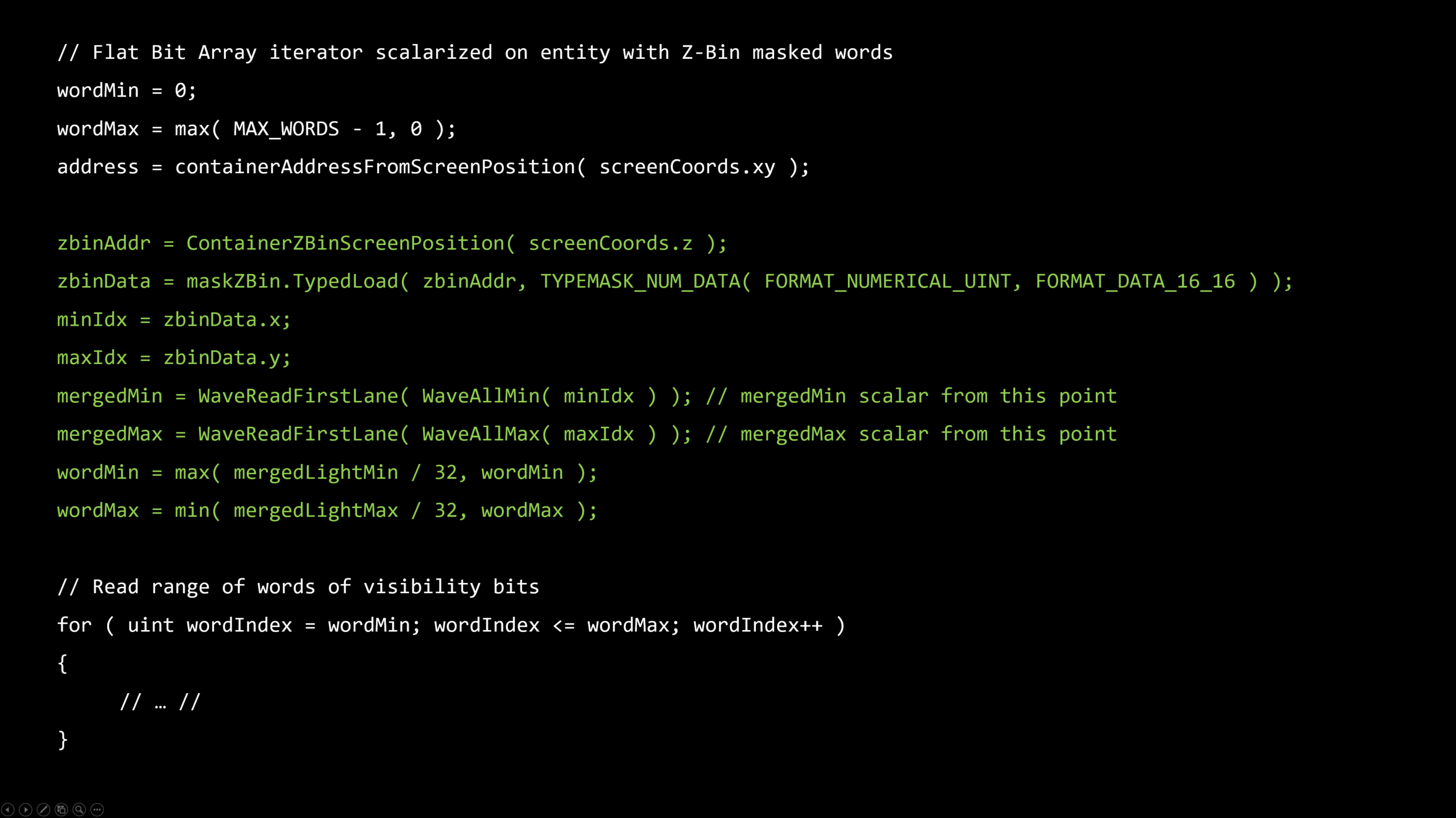
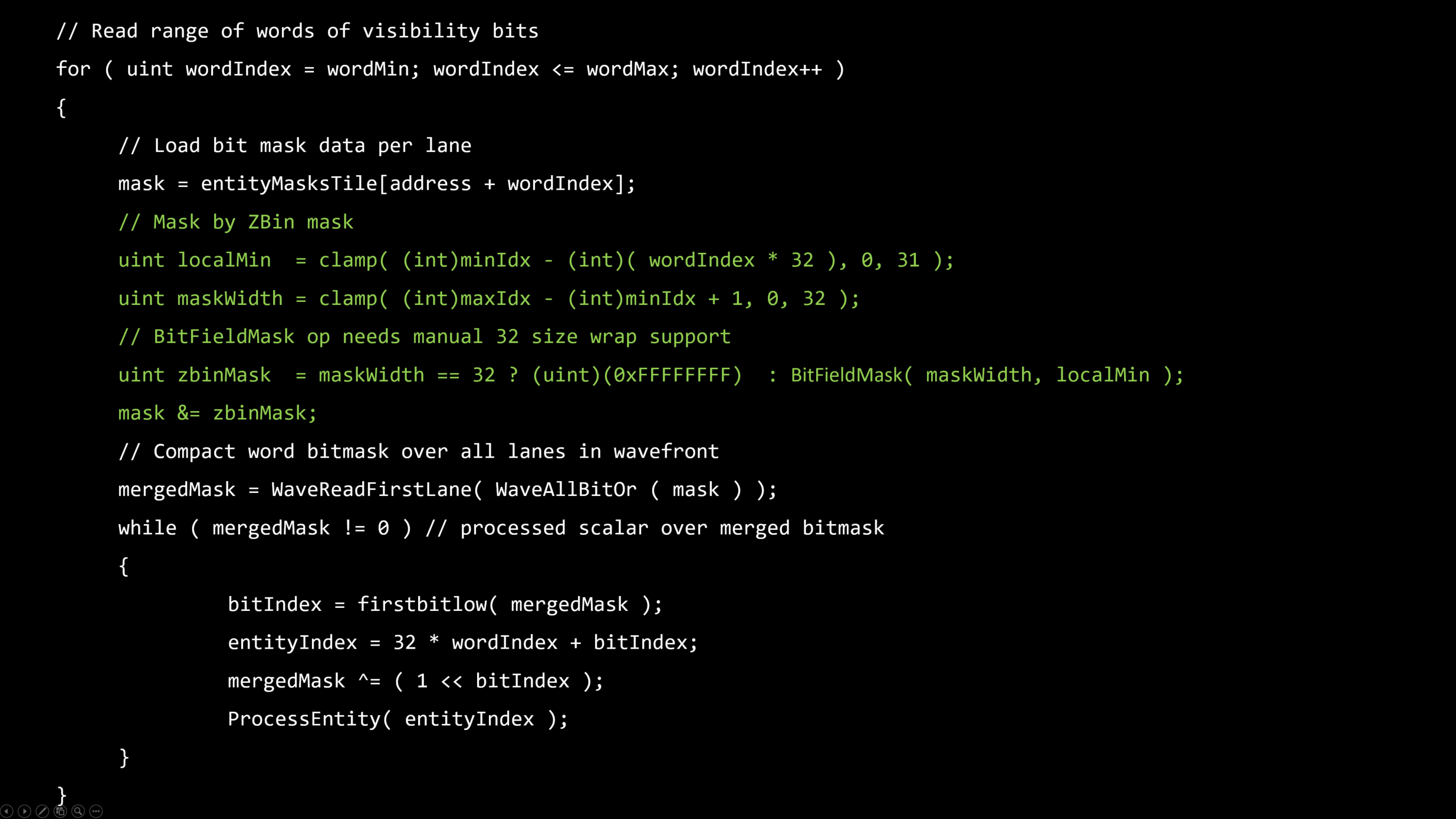
・ZBINをベクトルロード
・LIGHT MIN/MAX IDが同じウェイブを同一化
・MIN/MAX範囲からのライトビットのワードのロードが同じウェイブを同一化
・LIGHT MIN/MAX IDからのベクトルビットマスクを作成
・ベクトルZ-Binマスクによってユニフォームなライトをマスク
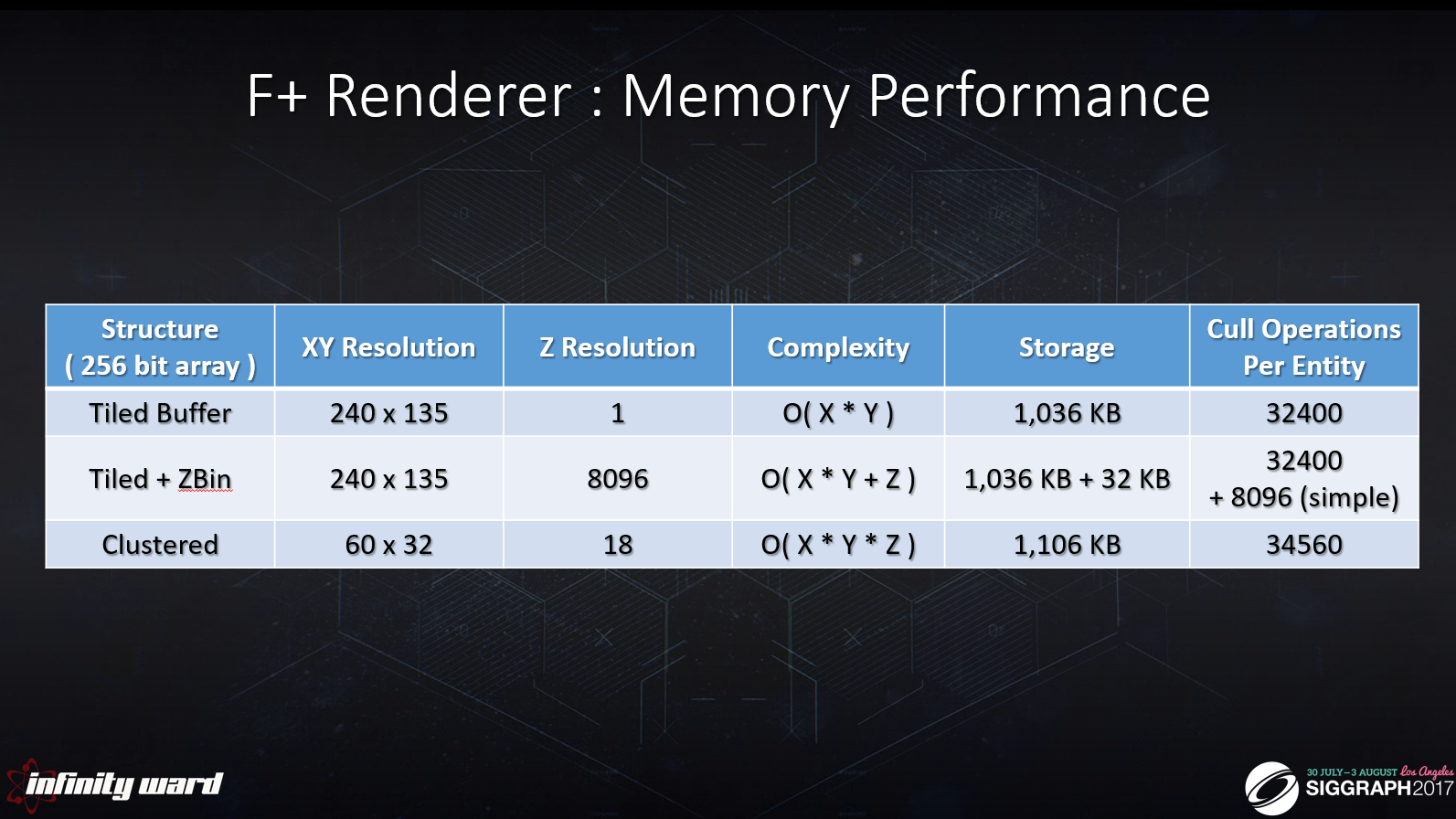
Zビン幅:32|Zビン数:8k
Zの32インチ精度で4.13マイルの範囲をカバー
XY解像度:タイル=8×8ピクセル
ZBin は 8096 x ( UINT32 ) として保存されます: MIN|MAX
最大フラスタムエンティティ数 = 2^16 = 65536
クラスタ化された解像度は、タイル化されたバッファとZbinバッファのメモリ消費量にほぼ一致するように選択されました。

深度が著しく不連続な、重厚な映画のようなシーン。

Z距離の異なる複数のライト。


Forward+では、ヘルパーレーンとラスタライズパターンが、深度不連続面付近のウェイブフロントのライト数を高くしていることに注目してください。

Z-ビニングを有効にすると、深度の不連続面付近で完璧に近いピクセルカリングが行われます。

ZBin LUTは常にL1/L2キャッシュにある
限られたビット配列ワード数でVMEMバンド幅を低減
最適なカリングに近い
クラスター化バッファの細かいカリングレベルにも使用可能
ボリューメトリクスに使用
再現可能なパフォーマンス向上
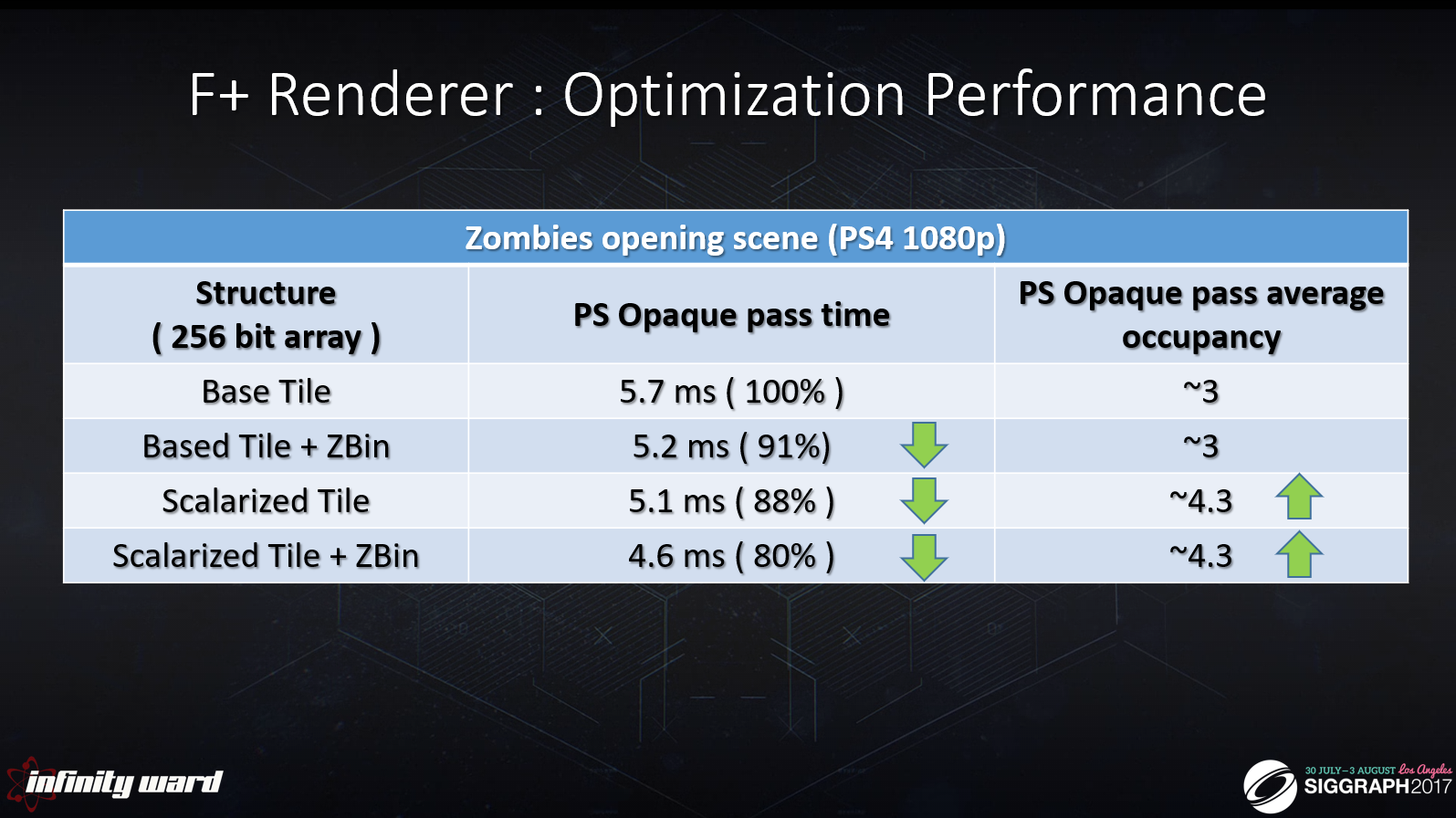
プロダクション・マップでの計測
シェーダーは完全に「出荷」品質に最適化
イテレータ/スカラライズ/ZBinningに分離された比較
64個の反射プローブ
ビュー内の256個のライト
F+シェーダーがすべてのレンダリングを行います:ライト、プローブ、SSR、シャドウ、デカール


古典的なコンピュート・カリングには複数の問題があります。
パフォーマンスを犠牲にすることなく、良い精度を得るのは難しい。複雑な形状、特に投影空間ではさらに難しくなります。
解析的な形状に制限されるため、ジオメトリの影によるオクルージョンを処理するロバストな方法がありません。
最近の複雑なエリアライトはさらに複雑です。現在、ライトは任意のポリゴンから構築できるため、解析形状は過度に保守的になるか、ポリゴンで終わるかのどちらかになります。
解決策は?
10年前のラスタライザーベースのディファード・シェーディングの時代に戻りましょう。そこでは、三角メッシュの使い方や明示的な三角メッシュによって、これらの問題をすべて解決することができました。

ライトは三角形のメッシュで表現され、周囲のジオメトリに密着するようにカットされています。

同じビューで、現在は直接光の寄与のみを表示し、影響を受けた領域をタイトにカリングして表示しています。

我々のライトはすべてメッシュです。私たちはこれをライト・プロキシと呼んでいます。
それぞれのプロキシは、ラスタライズ中に、オーバーラップするタイルに書き込みます。
書き込みは、保守的な結果を得るためにAtomicORオペレーションで行われます。
タイルには、カリングされたライトのフラットビット配列が格納されます。
我々の出荷ターゲットは、保守的なラスタライズをサポートしていないコンソールです。
そのため、スピードアップのためにMSAAを使ってフル解像度でラスタライズしています。
これにより、古典的な遅延レンダリングのためによく研究された、すべての固定ハードウェア最適化を使用することもできます。

カメラがライト包内にある場合、1パス法で最適なカリングが行われます。
カメラ対ライトメッシュのチェックでは、最も近いライト三角形に対して完全なハーフプレーントライアングルチェックを行います。
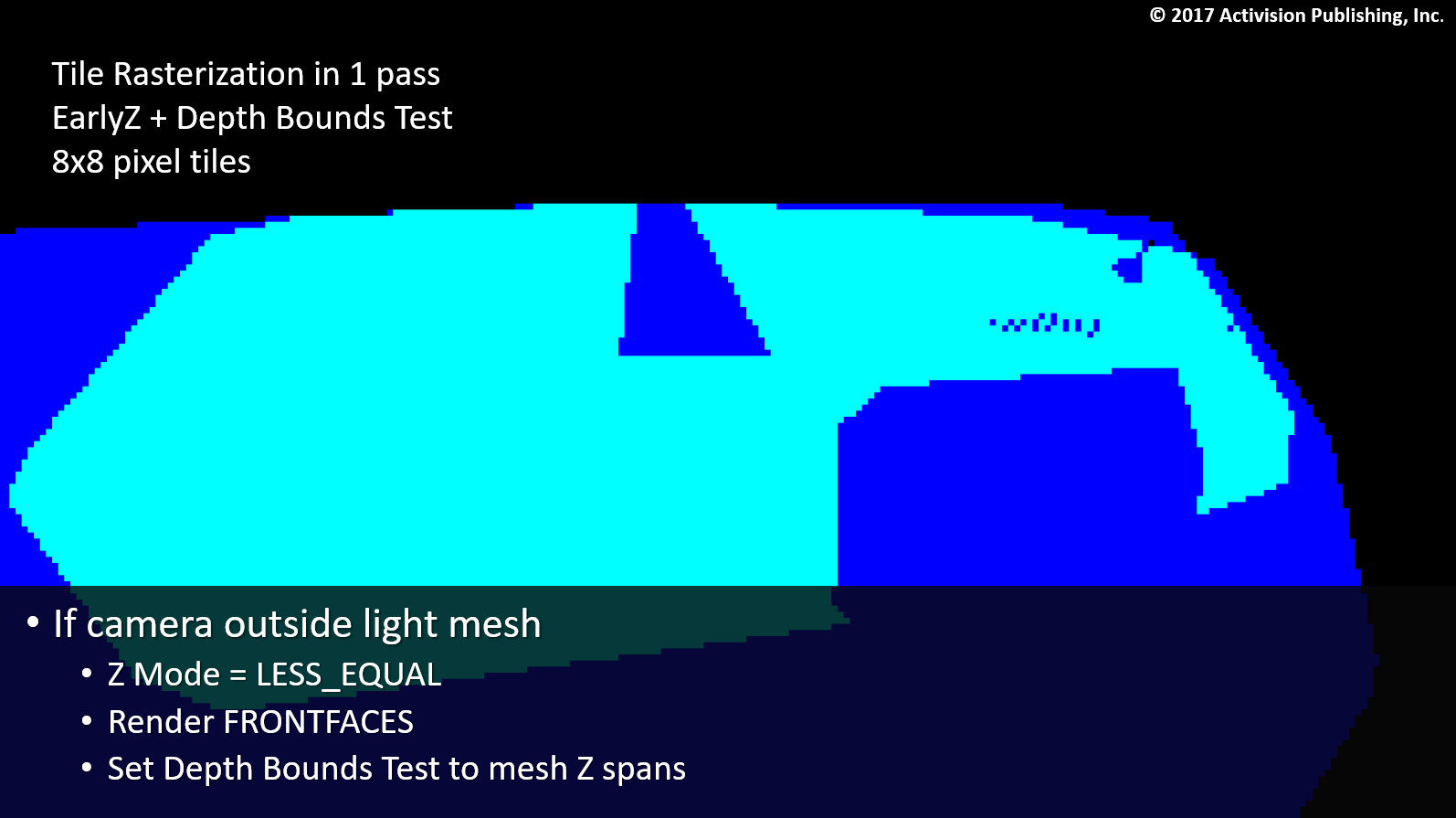
カメラがライトメッシュの外側にある場合、シングルパス方式では、過度に保守的なカリングになります。
効率は、Depth Bound Testで設定された大きな深度スパンをもたらす不均一な形状で低下します。

さらに、ピクセルパーフェクトなカリング精度を得るために、2パスステンシルアルゴリズムを許可します。
これは、深度の複雑性が高いシーンで最も近いライトにのみ使用されます。
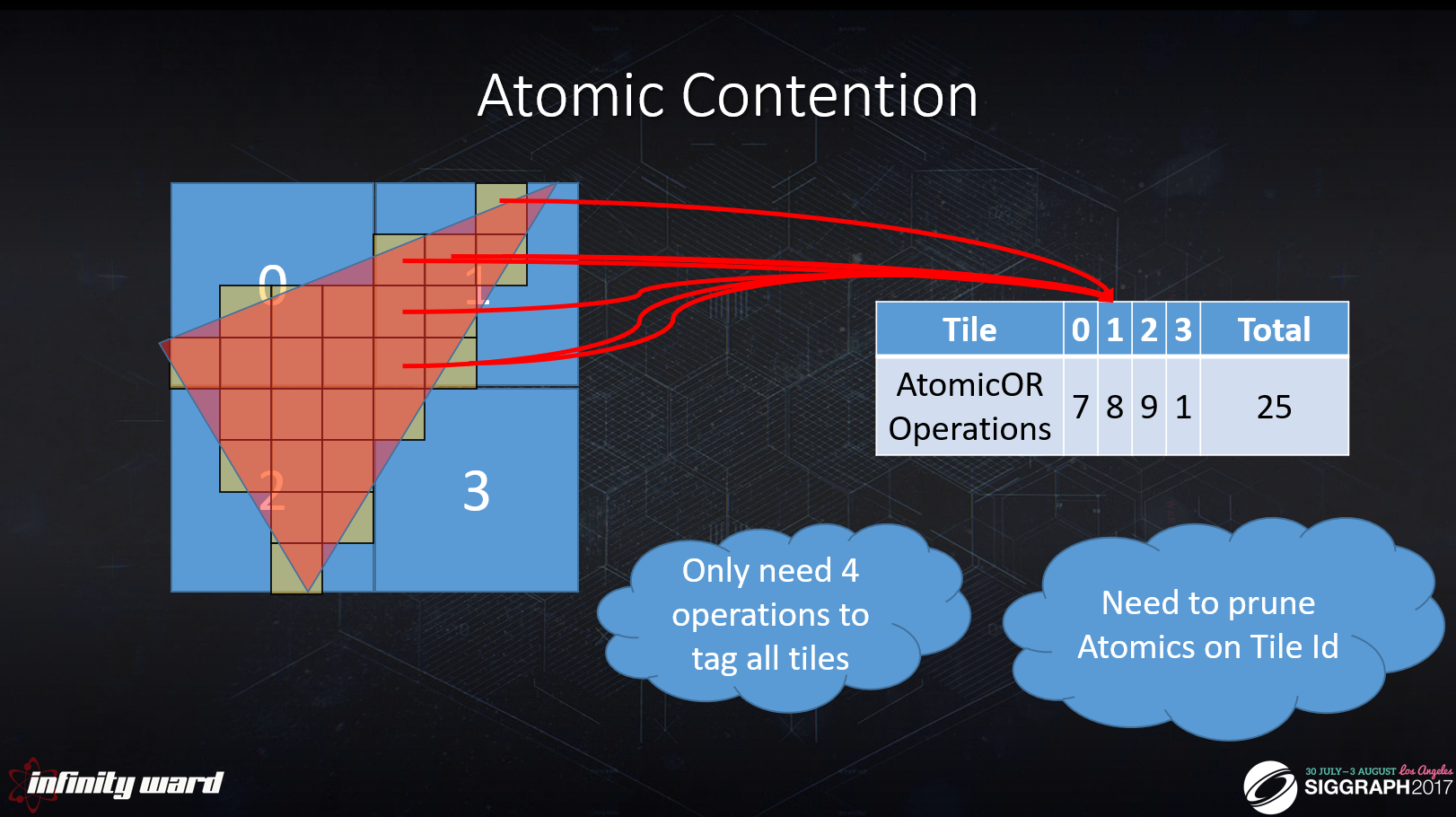


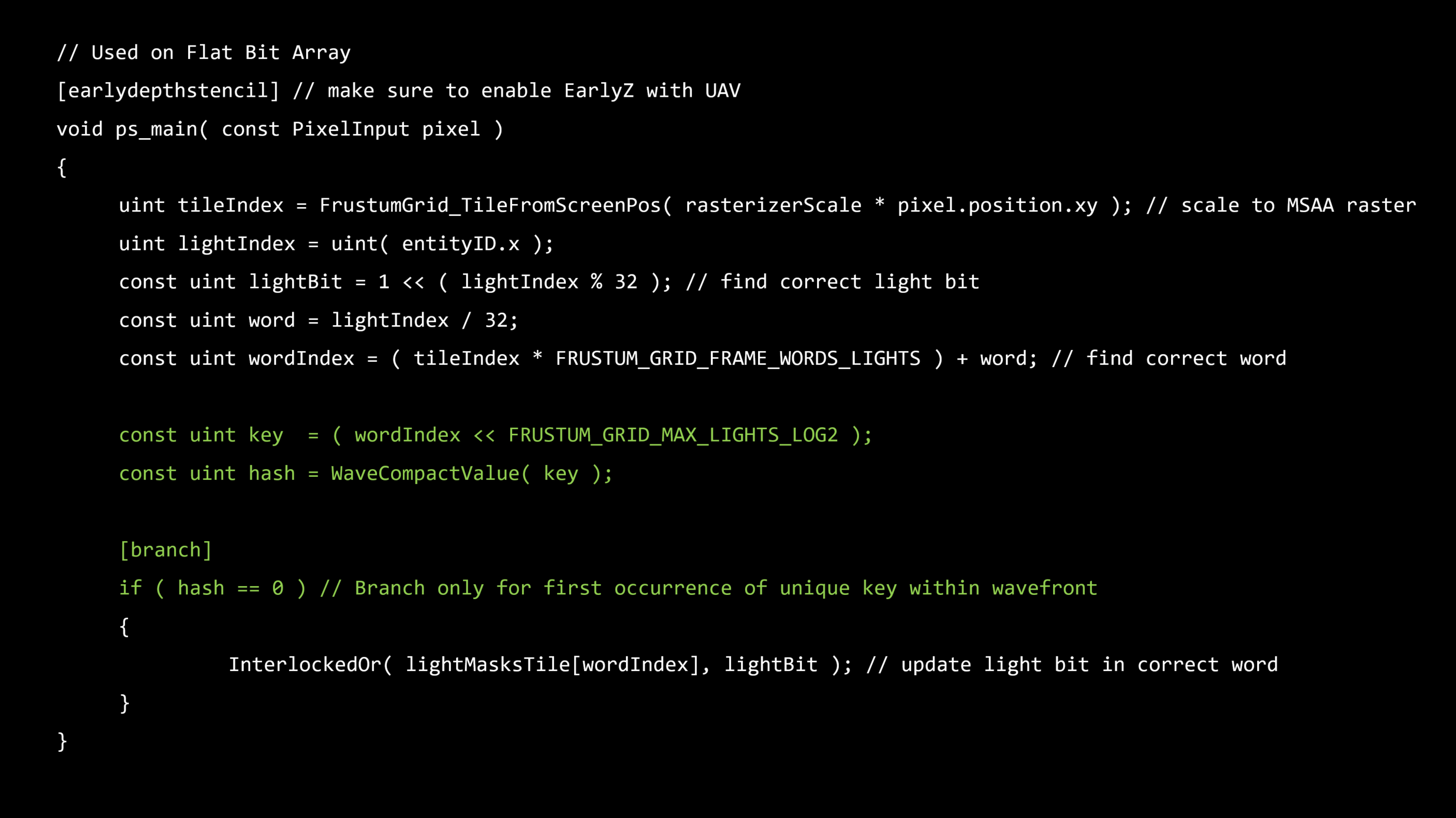
これで、冗長なアトミック演算の刈り込みによって、以前のカリングPSを改善することができます。
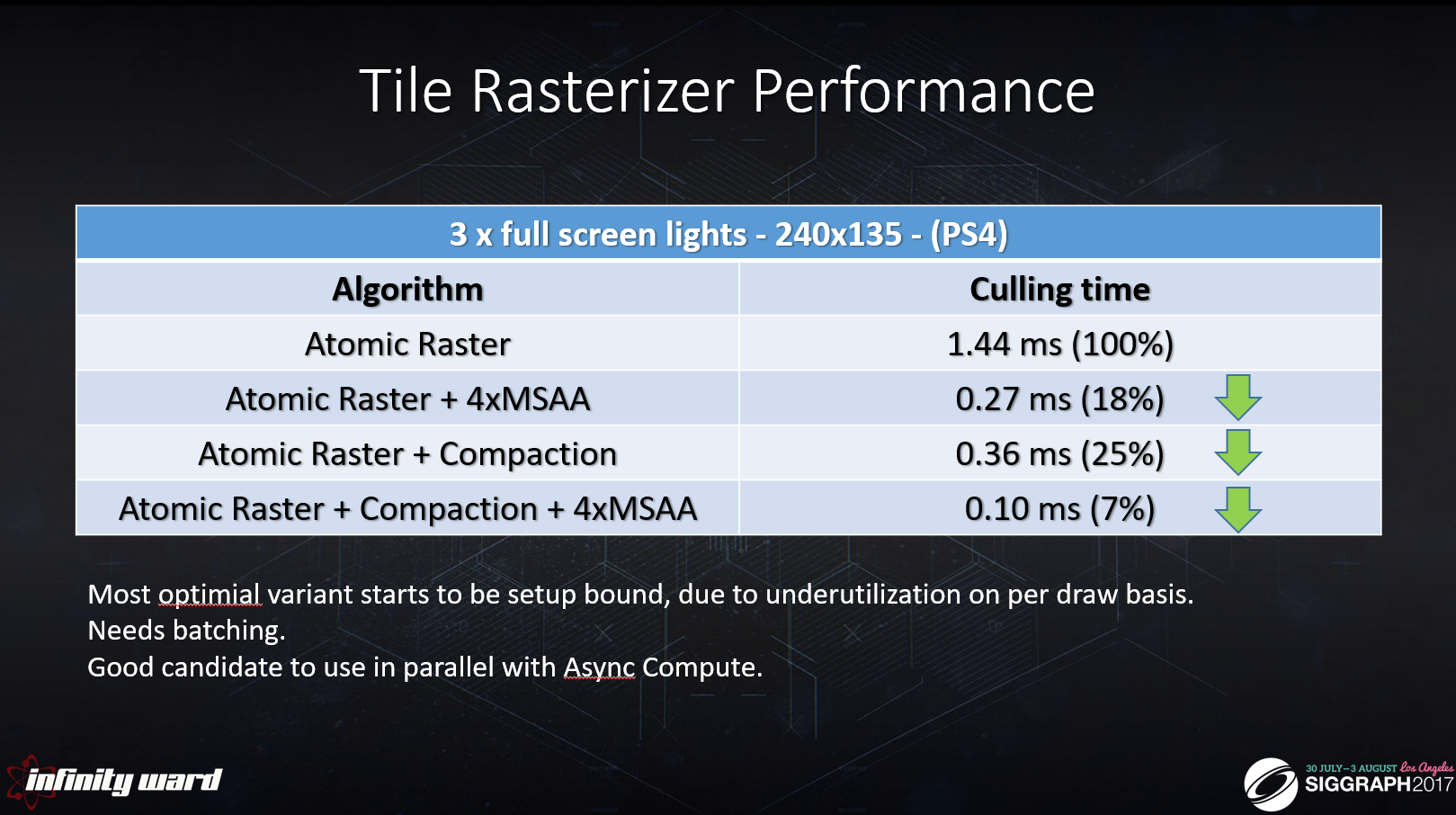
さらに改善しました。
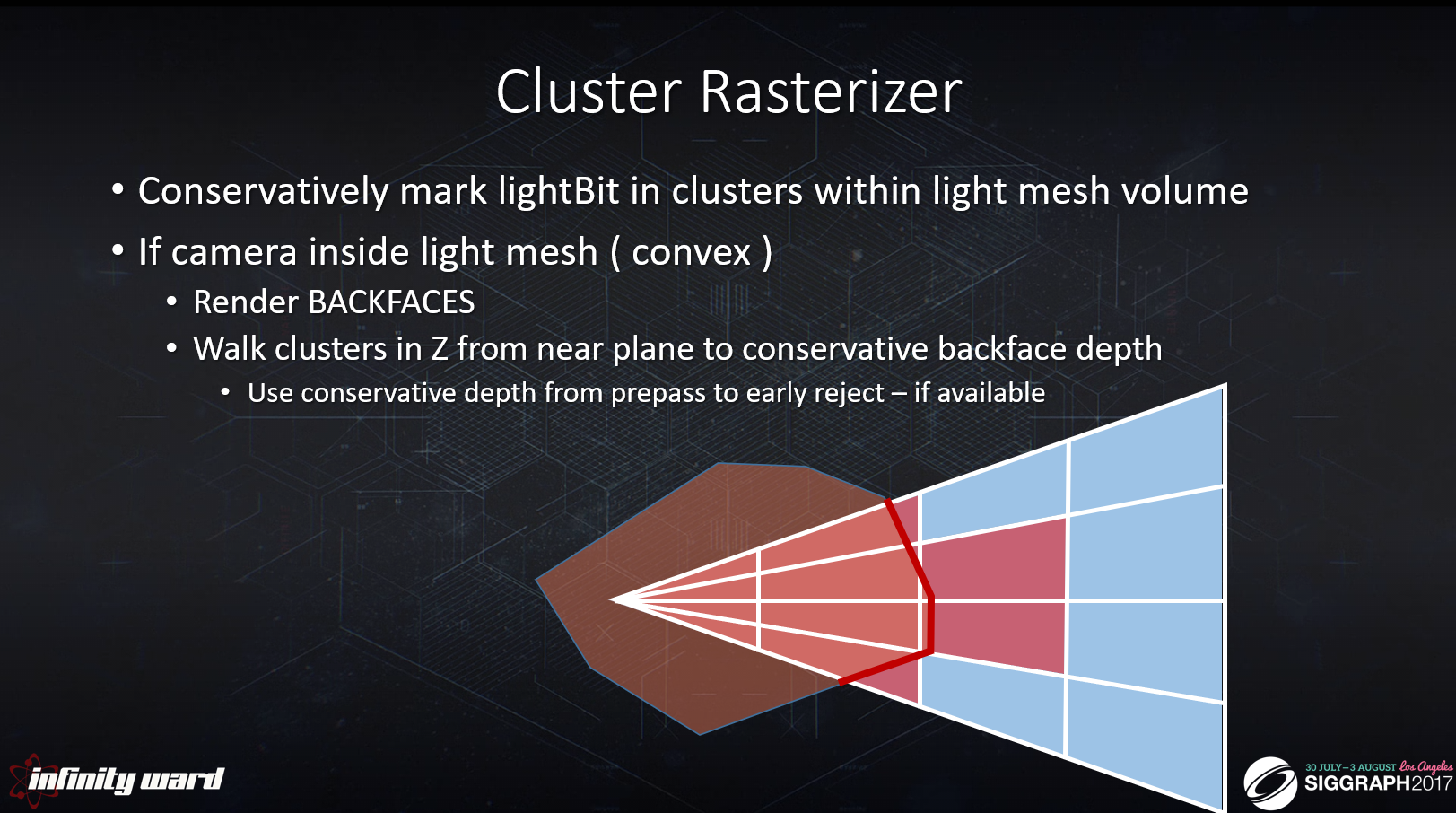
・ライトメッシュボリューム内のクラスターにライトビットを保守的にマークします。
・ライトメッシュ(凸包)がカメラの中の場合
・BACKFACESを描画
・ニアプレーンから保守的なバックフェースの深度まで、Z方向にクラスターをウォーク。
・プリパスから早期棄却までのユーザーの保守的な深度 – 利用可能な場合
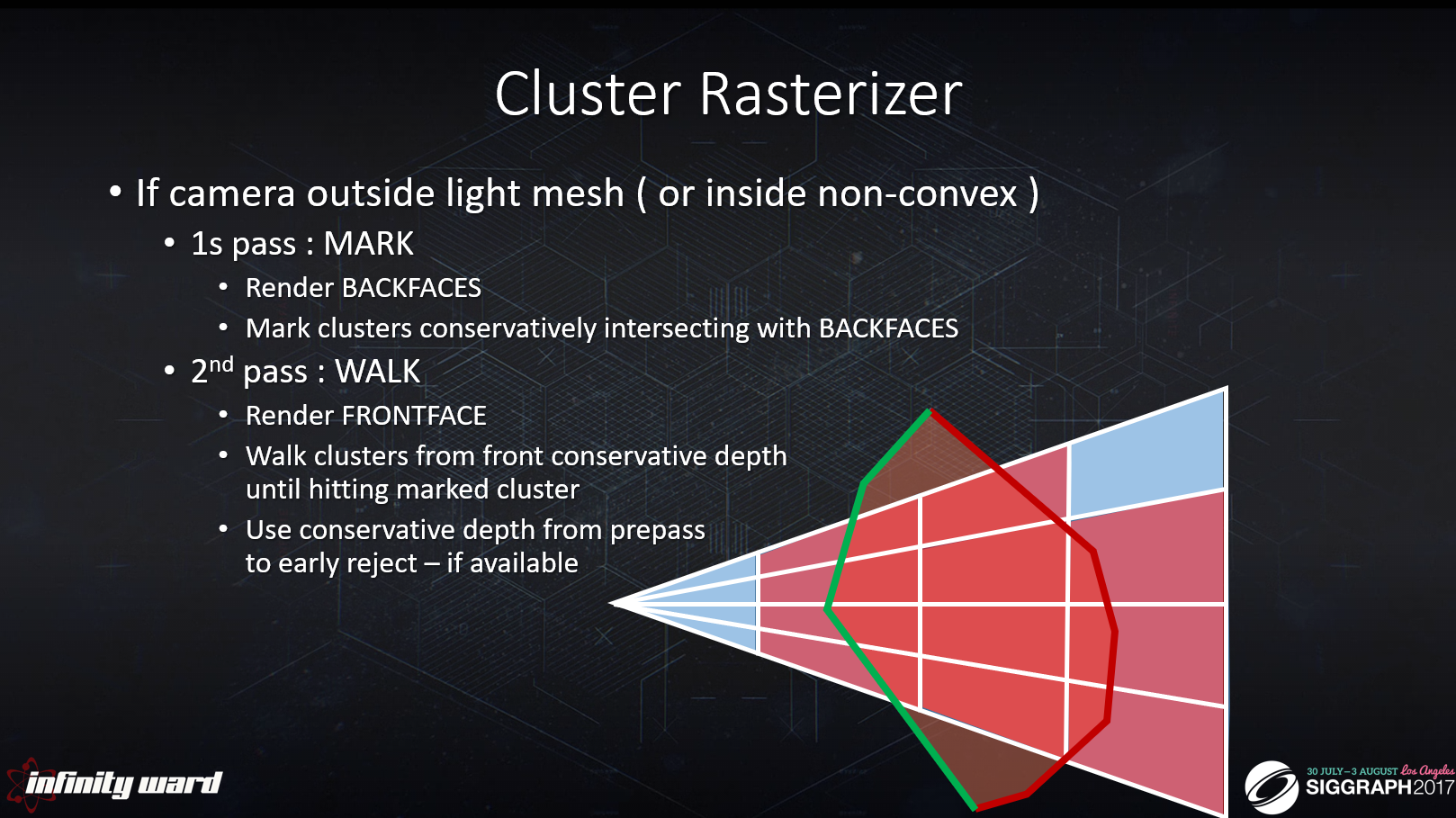
カメラがライトメッシュの外側の場合(あるいは非凸包内)
・1stパス:MARK
・BACKFACESを描画
・BACKFACESと保守的に交差するクラスターをマーク
・2ndパス」WALK
・FONTFACEを描画
・マークされたクラスターとヒットするまでフロントコンサバティブデプスからのクラスターをウォークする
・早期棄却するためにプリパスからのコンサバティブデプスを使用する – 利用可能である場合

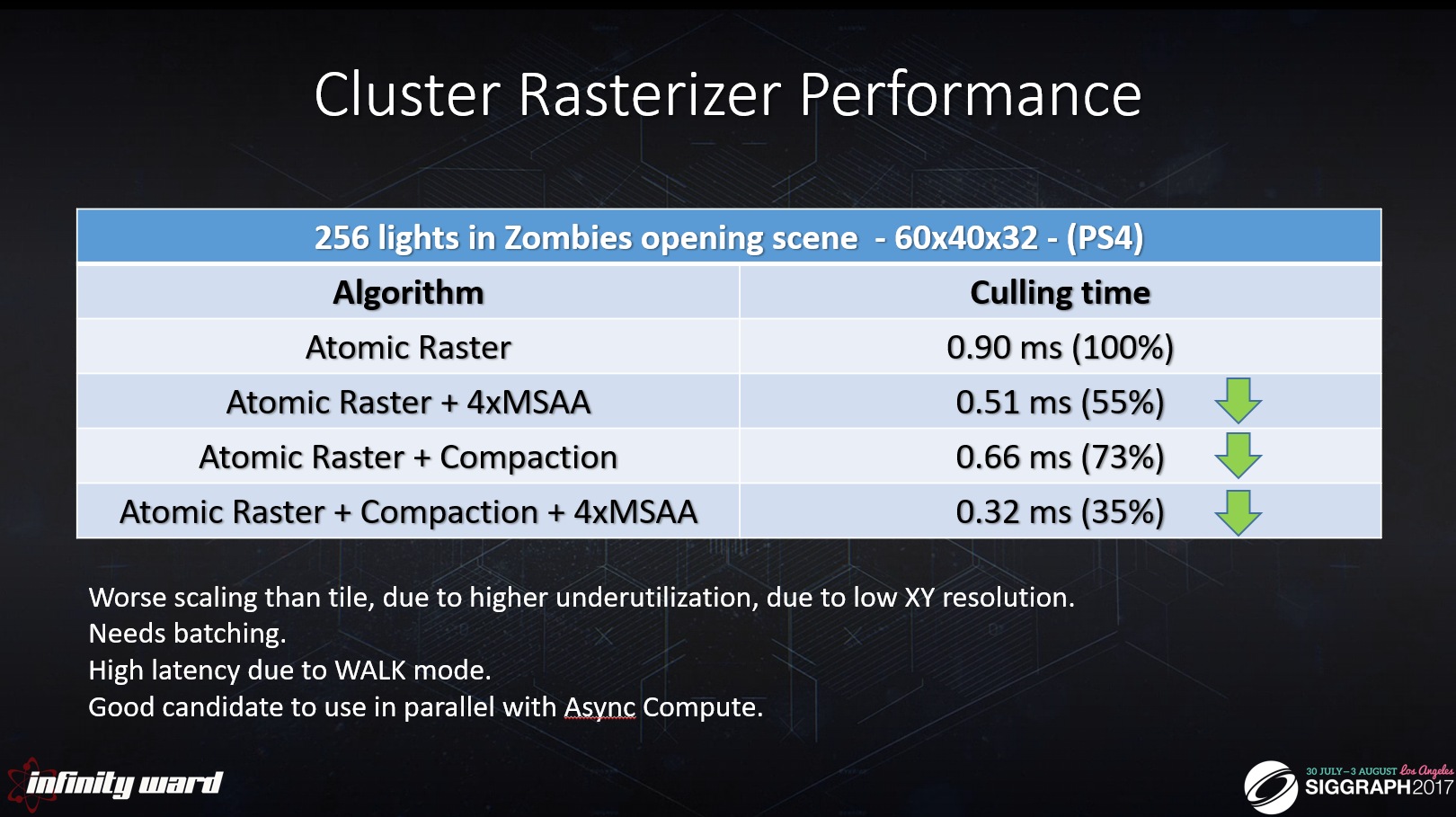


典型的な解析的なエリアライトを見てみましょう。


ライトプロキシジオメトリは、レベルジオメトリ(~300トリ)にタイトにカットされます。
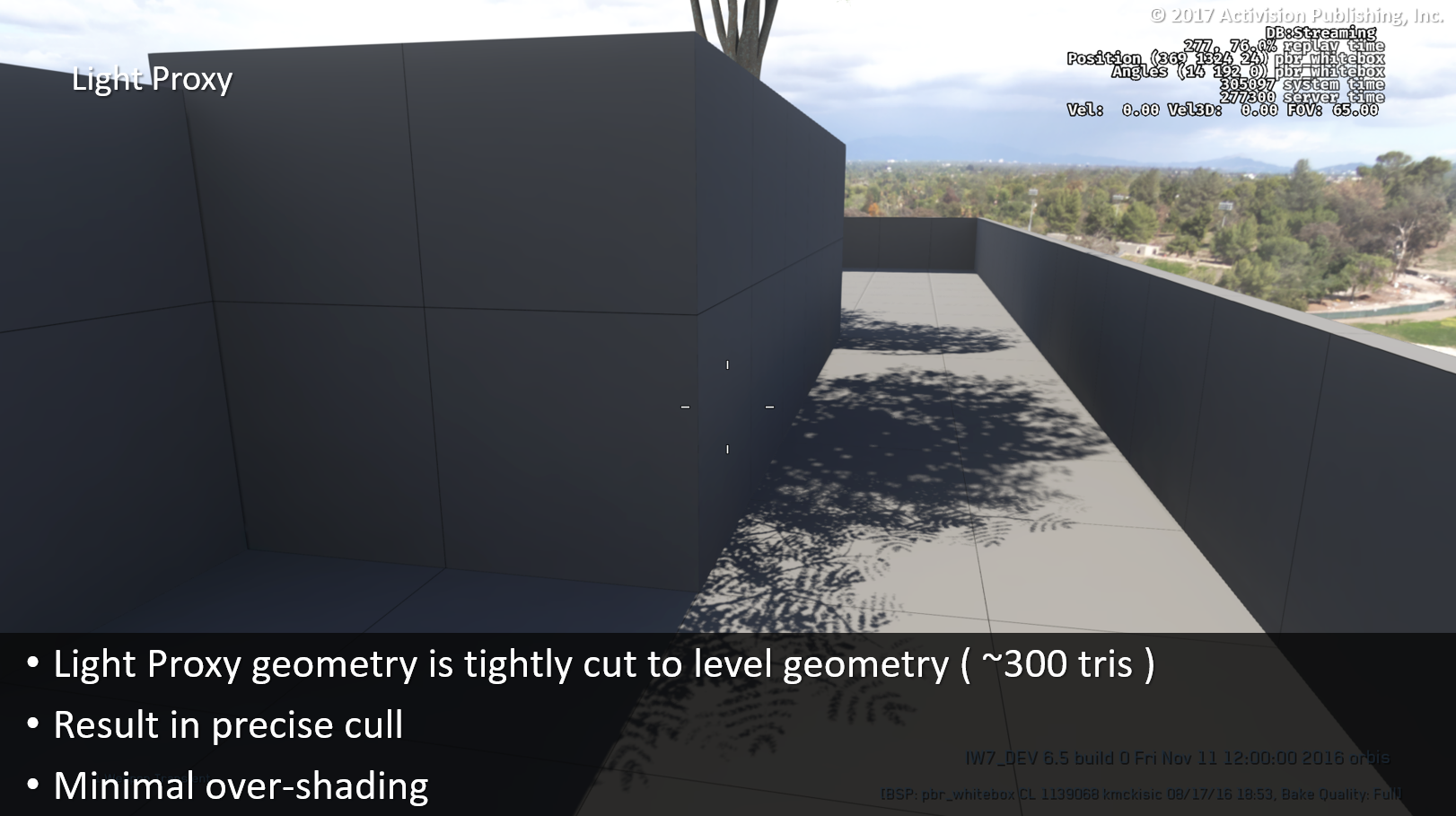


ライトプロキシを使ってもオーバーシェーディングは存在します。
部分的には三角形の数が少ないためで、部分的には我々が使っている粗いシェーディング方法のためです。

ご覧のように、プロキシメッシュは壁のジオメトリをわずかに「突き抜けて」います。また、地面の三角形に部分的に重なっています。

メッシュは8×8ピクセルのタイルにコンサバティブにラスタライズするために使用されるため(さらに、ウェイブフロントの境界で動作するように強制する)、ライトとシャドウのエッジは同じ粒度でレンダリングされます。
したがって、すべてのライトのシャドウマップを持つことが重要です。これは、静的シャドウマップ・キャッシュ・システムによってカバーされます。
すべてのライトは、最低限、すべての静的ジオメトリのシャドウマップを持つことになります – プロキシ生成に使用されるものと同じです。

直射光のみでの別のビューです。

アーティファクトを示す直射光のみの別のビューです。
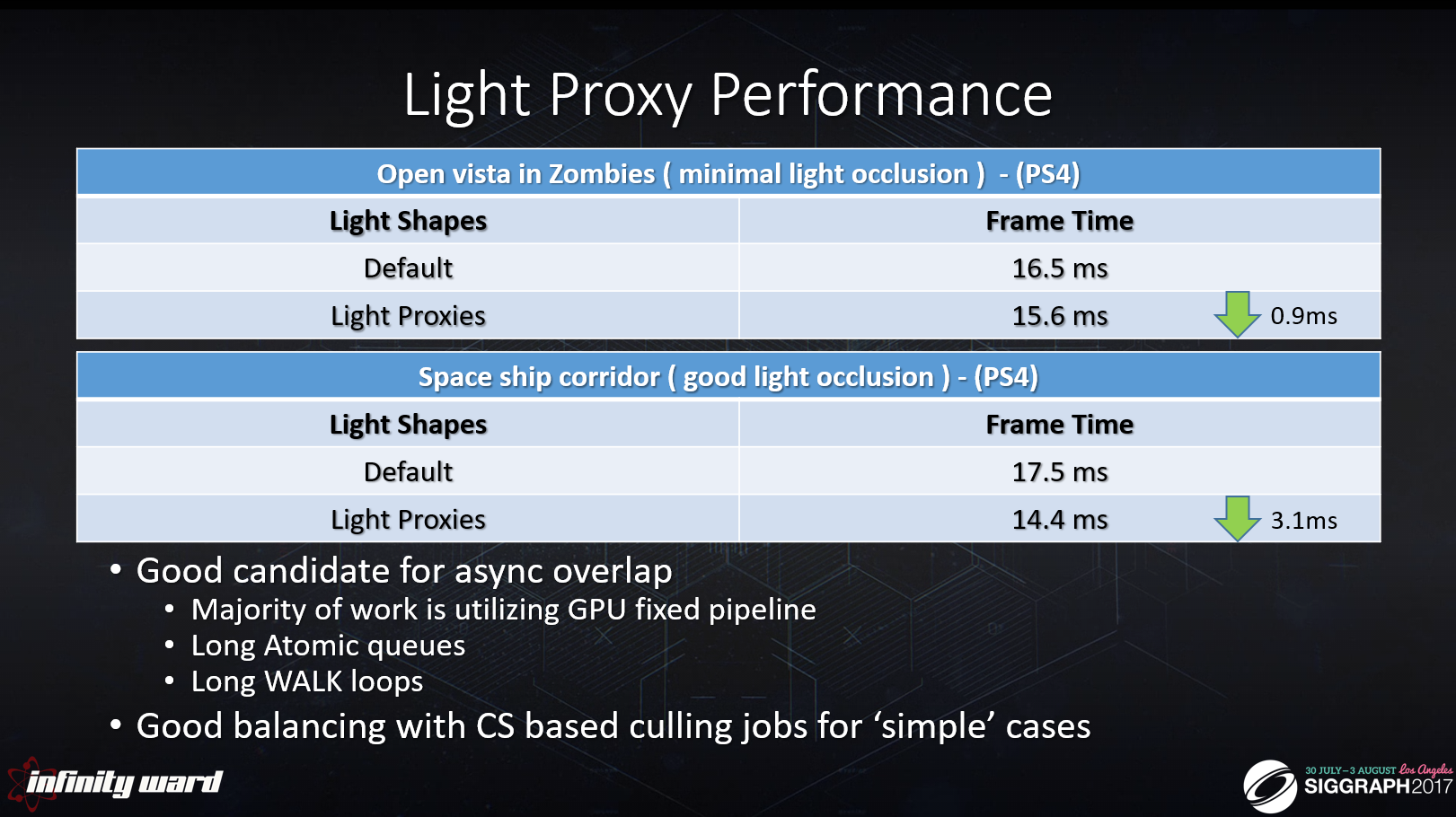
ライトプロキシーの性能は、コンテンツに大きく依存します。
よくオーサリングされたライトは、オクルージョンが最小限の場合、あまり恩恵を受けません。
都市環境、通路、人工構造物は、自然なオクルージョンのため、最も恩恵を受けます。









IW7では、動的反射プローブのライト、動的ライトマップされたパーティクルのライト、四面体のグローバルイルミネーションライトグリッドのためのフラスタム外の3Dルックアップに使用されます。
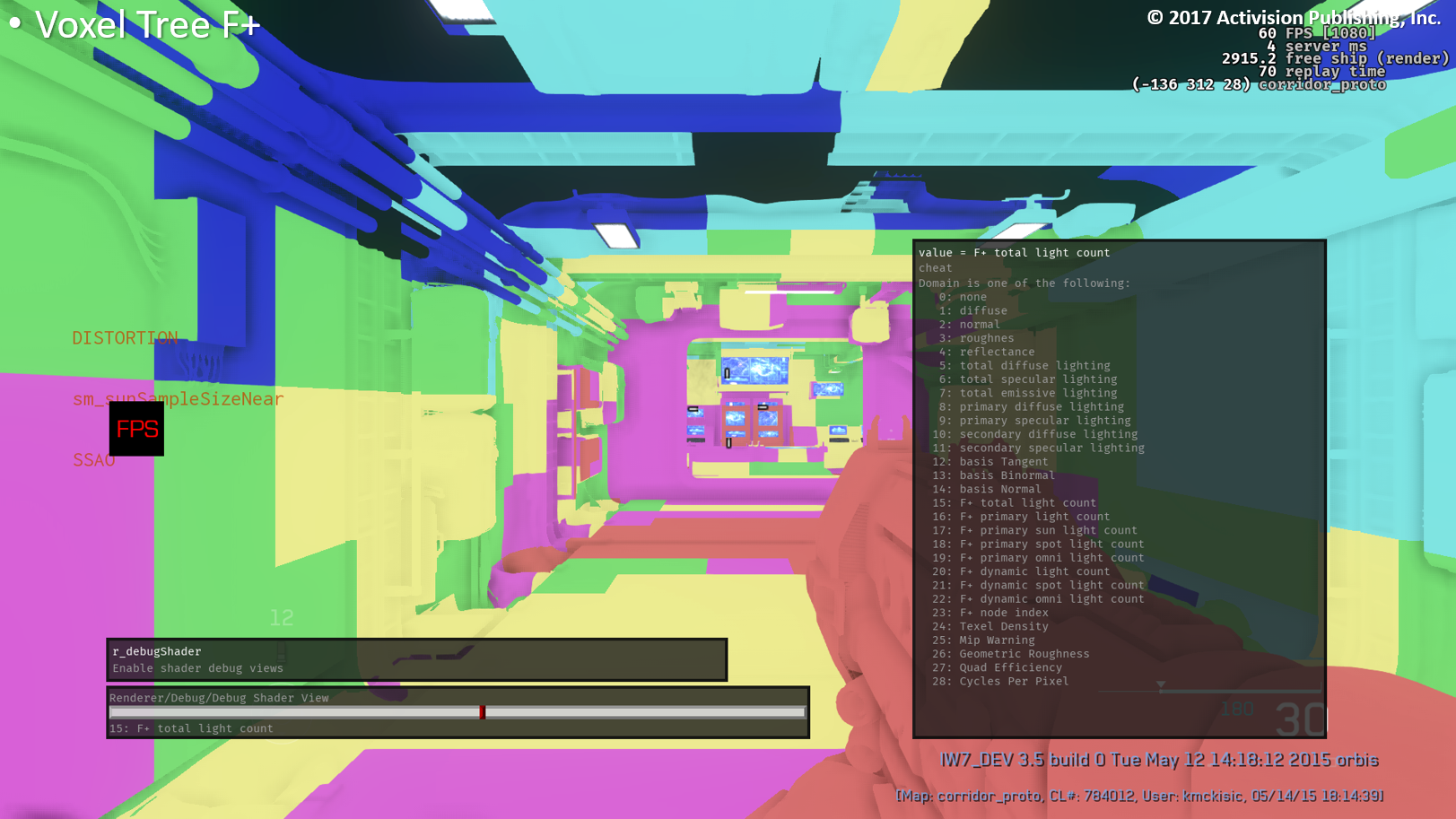
色は各ピクセルに当たっている光の量を表します。各ボクセルにはpreculledされたライトが保存されます。
ここでは、ワールド空間のボクセルがサーフェス上でどのように視覚化されるかを示すために示されています(実際のシーンライティングには使用されません)。


標準的なClustered F+ライティングの結果。16のZスライス(エッジにおける深度不連続性には、より多くのスライスが有効)。
色はピクセルごとに処理されたライトの量を表します。[青から赤、白]→[0…128]。
色が明るいほど、処理されたライトの数が多いです。

サーフェスキャッシング有効。
各トライアングルはライトに対してシャドウとバックフェイスカリングされます。アルゴリズムの三角形単位の性質により、深度不連続性は当然存在しません。
パフォーマンス向上の大部分は、非サーフェスベースの手法では実行できないバックフェイスカリングによるものです。
シャドーカリングは、性能/品質は異なるものの、他の手法でも実装可能。
6msを超える素晴らしいパフォーマンスの勝利 – いくつかの大きな三角形は、あまりにも多くのライトを処理する傾向がありますが。テッセレーションを改善するか、あるいは、テクセルごとのアプローチに切り替えることが助けになるでしょう。
色はピクセルごとに処理されるライトの量を表しています。[青~赤~白]→[0…128]。
色が明るいほど、より多くのライトが処理されます。