わしゃがな。Pocolです。
今日は, Ghost of Tsushimaの資料に載っていた
[Chen 2017] Jiawen Chen, Sylvain Paris, Fredo Durand, “Real-time Edge-Aware Image Processing with Bilateral Grid”, ACM SIGGRAPH 2017.
を読んでみようと思います。
いつもながら誤字・誤訳があるかと思いますので,ご指摘して頂ける場合は正しい翻訳例と共に指摘して頂けると有難いです。

Abstract
エッジを考慮した画像処理を高速に行うための新しいデータ構造「バイラテラル・グリッド」を紹介します。バイラテラル・グリッドを用いることで、バイラテラル・フィルタリング、エッジを考慮したペイント、ローカル・ヒストグラム・イコライゼーションなどのアルゴリズムが、局所的かつ独立したシンプルな操作になります。このアルゴリズムを最新のGPUで並列化することで、高精細映像のリアルタイムフレームレートを実現しています。本手法は、画像編集、フォトグラフィックな見た目の転写、医療画像のコントラスト強調など、さまざまなアプリケーションで実証されています。
1 Introduction
非線形フィルタは、強いエッジなどの画像構造を考慮した新しい画像補正・操作技術を可能にします。非線形フィルタは、意味のある画像成分や望ましい画像操作の多くが、純粋な帯域制限ではなく、区分的な平滑性を持つ傾向があるという観察に基づいています。例えば、照明は影の境界を除いて通常は滑らかであり[Oh et al. 2001]、トーンマッピングは、ローパスフィルタを使用して局所的な調整を行うとハローイングアーティファクトが発生しますが[Chiu et al. 1993]、この問題はノリニアフィルタで解決できます[Tumblin and Turk 199; Durand and Dorsey 2002]。
特に,バイラテラルフィルタは,強いエッジを除いて画像を滑らかにするシンプルな手法です[Aurich and Weule 1005; Tomasi and Manduchi 1998; Smith and Brady 1997]。バイラテラルフィルタは、画像を断片的に平滑な大規模ベース層と詳細層に分解し、トーンマッピング[Durand and Dorsey 2002]やフラッシュ/ノーフラッシュ画像融合[Petschnigg et al. 2004; Eisemann and Durand 2004]など、さまざまな場面で利用されています[Bennett and McMillan 2005; Xiao et al. 2006; Bae et al. 2006; Winnemoller et al. 2006]。非線形フィルタの一般的な欠点は速度です。バイラテラルフィルターを直接実装すると,1メガピクセルの画像に対して数分かかることがあります.しかし,最近の研究では,高速化が実証され,CPU上でメガピクセルあたり1秒のオーダーで良好な性能が得られるようになっています[Durand and Dorsey 2002; Pham and van Vliet 2005; Paris and Durand 2006; Weiss 2006].しかし、これらのアプローチでは、高精細なコンテンツのリアルタイム性を実現することはできません。
本研究では、バイラテラル・フィルターを劇的に高速化・汎用化し、高解像度の入力に対してリアルタイムで様々なエッジを意識した画像処理アプリケーションを実現します。ParisとDurand[2006]は高次元空間で線形フィルタリングを行うことで高速なバイラテラルフィルタリングを実現していますが,我々はこの高次元アプローチを拡張し,エッジを意識した様々な操作を可能にする新しいコンパクトなデータ構造であるバイラテラルグリッドを導入しました。また、これらの処理を最新のグラフィックスハードウェアを用いて並列化することで、HD解像度でのリアルタイム性能を実現しています。特に、GPUによるバイラテラルフィルタは、同等のCPU実装よりも2桁以上高速です。
この論文では、以下のような貢献をしています:
- バイラテラルグリッドは、画像のエッジを意識した操作を自然に行える新しいデータ構造です。
- 従来のCPU技術に比べて2桁以上高速なGPUによるリアルタイムバイラテラルフィルタリングにより、HDコンテンツのリアルタイム処理を実現。
- エッジアウェアアルゴリズム。エッジ保存ペイント、散乱データ補間、ローカルヒストグラムイコライゼーションなど、リアルタイムでエッジを意識したアルゴリズムを紹介します。
我々のアプローチは、この分野の研究を促進するために、オープンソースで配布される柔軟なライブラリとして実装されています。このコードは、http://groups.csail.mit.edu/graphics/bilagrid/でご覧いただけます。バイラテラルグリッドのデータ構造は一般的なものであり、今後の研究で多くの新しいアプリケーションが開発されると考えています。
1.1 Related Work
バイラテラルフィルタ
バイラテラル・フィルターは、画像のエッジを維持しながら平滑化する非線形処理です[Aurich and Weule 1995; Smith and Brady 1997; Tomasi and Manduchi 1998]。画像\(I\)の位置\({\mathbf p}\)では,次のように定義されます.
\begin{eqnarray}
bf(I)_{\mathbf p} &=& \frac{1}{W_{\mathbf p}} \sum_{{\mathbf p} \in N({\mathbf p})} G_{\sigma_s} (||{\mathbf p} – {\mathbf q}||) G_{\sigma_r} (| I_{\mathbf p} – I_{\mathbf q}|) I_{\mathbf q} \tag{1a} \\
W_{\mathbf p} &=& \sum_{{\mathbf q} \in N({\mathbf p})} G_{\sigma_s} (|| {\mathbf p} – {\mathbf q}||) G_{\sigma_r} (| I_{\mathbf p} – I_{\mathbf q}|) \tag{1b}
\end{eqnarray}
出力は、空間距離のガウス(\(G_{\sigma_s}\))と画素値の差のガウス(\(G_{\sigma_r}\))の積である近傍領域の単純な加重平均で、範囲加重とも呼ばれます。範囲加重は、強いエッジの一方の側のピクセルが、もう一方の側のピクセルに異なる値を持つため、影響を与えることを防ぎます。また,画素値の差に対するガウスは任意の次元を持つことができるため,RGBなどのマルチチャンネル画像のエッジを考慮することも容易です.
バイラテラル・フィルターを近似する高速な数値スキームは、大規模な画像を1秒以下で処理することができます。Phamら[2005]は,分離可能な近似法について述べています.この近似法は,ノイズ除去に用いられる小さなカーネルではうまく機能しますが,その他のアプリケーションで用いられる大きなカーネルではアーティファクトが発生します.Weiss[2006]は,局所的な画像ヒストグラムを維持していますが,残念ながら,このアプローチは滑らかなガウスカーネルではなく,ボックス空間カーネルに限定されます.
ParisとDurand[2006]は,DurandとDorsey[2002]で紹介された高速バイラテラル・フィルタを拡張し,その計算を高次元の線形畳み込みと,それに続く3次補間と除算に再構成しました.我々は彼らの高次元空間の背後にあるアイデアを、バイラテラル・グリッドというデータ構造に一般化し、バイラテラル・フィルター、エッジを考慮したペイントと補間、ローカル・ヒストグラム・イコライゼーションなど、多くの演算を可能にしました。
その他のエッジ保存技術としては,バイラテラル・フィルター[Durand and Dorsey 2002; Barash 2002]に関連した異方性拡散[Perona and Malik 1990; Tumblin and Turk 1999]があります.また、強いエッジを尊重しながら値を補間するために、最適化[Levin et al. 2004; Lischinski et al. 2006]を用いることもできます。本研究では、これらのアプローチに代わるものを紹介します。
高次の画像再表現
2次元の画像を高次元の構造として解釈することが注目されています。Sochenら[1998]は、画像を高次元空間に埋め込まれた2次元多様体と表現しています。例えば、カラー画像は5次元空間に埋め込まれています:XとYの2Dに加え、カラーの3D。これにより、PDFベースの画像処理を、曲率などの幾何学的特性の観点から解釈することができます。我々のバイラテラルグリッドは、このアプローチで高次元空間を利用することを共有しています。しかし、多様体上の値だけでなく、空間全体の値を考慮するという点では、大きく異なります。さらに、同種の値を保存しているので、重み付き関数や線形フィルタの正規化を扱うことができます。Sochenらが微分幾何学の観点からアプローチしているのに対し、我々のアプローチは主に信号処理からヒントを得ています。
Felsbergら[2006]は,バイラテラルグリッドに似た体積構造と見なせるチャンネルのスタックに基づくエッジ保存フィルタについて述べています.各チャンネルには,符号化された画像を表すスプライン係数が格納されています.エッジ保存フィルタは,各チャネル内のスプライン係数を平滑化し,フィルタリングされた係数からスプラインを再構成することで実現されます.これに対して、バイラテラルグリッドは、データをスプラインにエンコードせず、直接アクセスすることができます。これにより、高速な計算が可能となり、特に最新の並列アーキテクチャの計算能力を容易に活用することができます。
2 Bilateral Grid
バイラテラル・フィルターが強いエッジを尊重する効果があるのは、式1の重み付けされた組み合わせに範囲項\(G_{\sigma_r}(|I_{\mathbf \alpha} – I_{\mathbf q}|)\)が含まれているからです:エッジを挟んだ2つの画素は、空間的には近いのですが、フィルターから見ると、範囲的には値が大きく異なるため、離れていることになります。この原理をデータ構造に応用したのがバイラテラルグリッドです。これは、2次元の空間領域と1次元の範囲領域(画像の強度など)を組み合わせた3次元配列です。この3次元空間では、ユークリッド距離がエッジを意識した画像操作に有効となります。
バイラテラルグリッドは,ParisとDurandの高速バイラテラルフィルタ[2006]において,補助的なデータ構造として初めて登場しました.この研究では,バイラテラル・フィルタの方程式を代数的に再表現したものとして使用されています.我々は、バイラテラル・グリッドを、リアルタイムで様々なエッジを意識した操作を可能にする主要なデータ構造として捉えている点で、視点が異なります。
2.1 A Simple Illustration
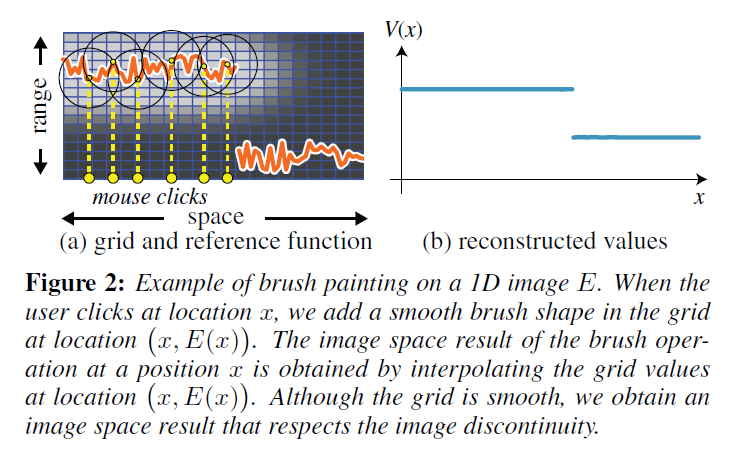
バイラテラルグリッドを正式に定義する前に、まずエッジを意識したブラシという簡単な例でコンセプトを説明します。エッジを意識したブラシは、従来の編集パッケージで提供されているブラシと似ていますが、ユーザーがエッジの近くをクリックしても、ブラシはエッジを越えて描かないという点が異なります。
ユーザーが画像\(E\)を位置\((x_{\rm u}, y_{\rm u})\)でクリックすると、エッジを意識したブラシが位置\((x_{\rm u}, y_{\rm u}, E(x_{\rm u}, y_{\rm u}))\)の3次元バイラテラルグリッドに直接ペイントします。空間座標はクリック位置で決まり、範囲座標はクリックした画素の強度です。エッジを意識したブラシは、3次元全てにおいて滑らかなフォールオフを実現しています。2つの空間次元に沿ったフォールオフは、古典的な2Dブラシと同じですが、範囲フォールオフは、私たちのブラシに特有のもので、強度値の限られた区間のみが影響を受けるようになっています。位置\((x, y)\)における画像空間でのペイント値\(V\)を取得するために、位置\((x, y, E(x, y))\)におけるバイラテラルグリッドの値を読み取ります。Paris and Durand [2006]と同じ項を使い、この操作をスライシングと呼んでいます。画像\(E\)がほぼ一定の領域では、エッジを考慮したブラシは、空間的に滑らかなフォールオフを持つ古典的なブラシのように動作します。範囲の変化が小さいので、範囲のフォールオフはほとんど影響しません。エッジでは、\(E\)は不連続であり、片側だけが塗られている場合、範囲フォールオフは、反対側が影響を受けないようにすることで、塗られた値\(V\)に不連続性を生み出します。グリッド値は滑らかですが、\(E\)に応じてスライスするため、出力値マップは断片的に滑らかであり、\(E\)の強いエッジを尊重しています。
このシンプルな例は、バイラテラル・グリッドのエッジを意識した特性を示すものです。スムーズな値だけを操作し、エッジの保存の問題は無視していますが、結果として得られた関数は、最後のスライス操作のおかげで画像を生成しています。さらに,バイラテラル・グリッドを用いた計算は,一般に独立しており,参照画像よりも粗い解像度を必要とします.さらに、バイラテラルグリッドを用いた計算は、一般的に独立しており、参照画像よりも粗い解像度を必要とします。
2.2 Definition
Data Structure
バイラテラルグリッドは3次元の配列で、最初の2次元\((x、y)\)は画像平面内の2次元位置と空間領域からの位置に対応し、3次元目の\(z\)は参照範囲に対応しています。一般的に、範囲軸は画像強度です。
Sampling
バイラテラルグリッドは、各次元で規則的にサンプリングされます。空間軸のサンプリングレートを\(s_s\)、範囲軸のサンプリングレートを\(s_r\)と呼びます。直感的には、\(s_s\)は平滑化の量を制御し、\(s_r\)はエッジ保存の程度を制御します。グリッドセルの数はサンプリングレートに反比例します。\(s_s\)や\(s_r\)を小さくすると、グリッドセルの数が多くなり、より多くのメモリを必要とします。実際には、グリッドに対するほとんどの操作は、グリッドセルの数が画像の画素数よりもはるかに小さい、粗い解像度しか必要としません。我々の実験では、2048から300万のグリッドセルが有用なパラメータ範囲として使用されています。必要な解像度は操作に依存するため、アプリケーションごとに議論することにします。
Data Type and Homogeneous Values
バイラテラルグリッドは、セルにスカラーやベクトルなど任意の種類のデータを格納することができます。バイラテラルグリッドに対する多くの演算では、各グリッドセルに対応する画素数(または重み\(w\))を記録しておくことが重要です。そこで、スカラー\(V\)の場合は\((wV, w)\)、RGBカラーを扱う場合は\((wG, wG, wB, w)\)のような同次量を格納することになります。この表現により、加重平均の計算が容易になります。同次座標 \((w_1 + w_2)\) で正規化すると、\(V_1\) と \(V_2\) を \(w_1\) と \(w_2\) で重み付けして平均化した結果が期待される \((w_1 V_1, w_1) + (w_2 V_2, w_2) = ((w_1 V_1 + w_2 + V_2), (w_1 + w_2))\)となります。直感的には,同次座標\(w\)は関連するデータ\(V\)の重要度を符号化したものであり,これは事前乗算済みアルファ色の同次的解釈にも似ています [Blinn 1996; Willis 2006]。
2.3 Basic Usage of a Bilateral Grid
バイラテラルグリッドはバイラテラルフィルタから着想を得ているため、グリッド操作の主要な例として使用しています。第4章では、一連の新しい操作について説明します。一般に、バイラテラルグリッドは3つのステップで使用されます。まず、画像やその他のユーザ入力からグリッドを作成します。次に、そのグリッドの内部で処理を行います。最後に、グリッドをスライスして、出力を再構成します(図3)。作成とスライスは、画像空間とグリッド空間を変換する対称的な操作です。
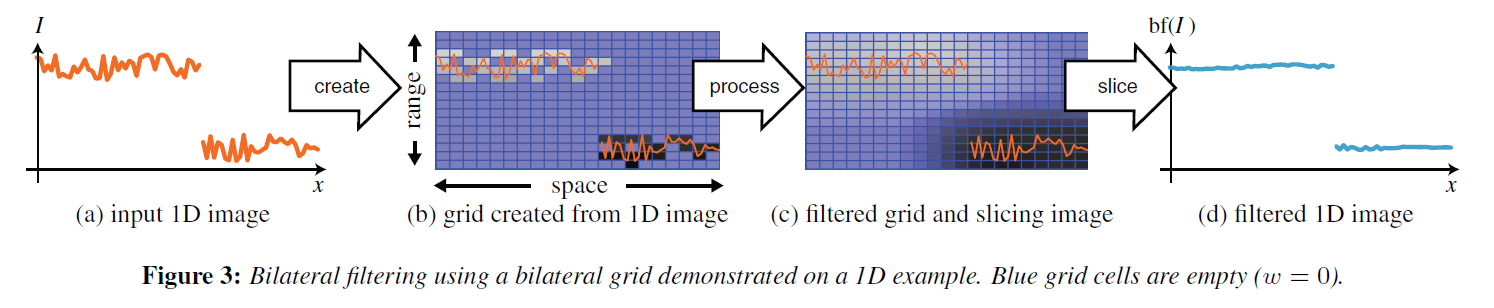
Grid Creation
\([0, 1]\)に正規化された画像\(I\)、空間サンプリング率\(s_s\)とレンジサンプリング率\(s_r\)が与えられたとき、以下のようにバイラテラルグリッド\(\Gamma\)を構築します。
- 初期化: すべてのグリッドノードについて\((i, j, k), \Gamma(i, j, k) = (0, 0)\).
- 充填:位置\((x, y)\)における各ピクセルについて:
\begin{eqnarray}
\Gamma ([x/s_s], [y/s_s], [I(x,y)/s_r]) += (I(x, y), 1)
\end{eqnarray}
ここで,\([\cdot]\)は最も近い整数への操作です。この構築に、\(\Gamma = c(I)\)という表記を使います。なお、各グリッドセルには、画像強度と画素数の両方を同次座標で積算します。
Processing
3次元関数を入力とする任意の関数\(f\)は,バイラテラルグリッド\(\Gamma\)に適用して新しいバイラテラルグリッド\({\tilde \Gamma} = f(\Gamma)\)を得ることができます。バイラテラルフィルタでは,\(f\)はガウスカーネルによる畳み込みで,領域と範囲次元に沿った分散はそれぞれ\(\sigma_s\)と\(\sigma_r\)です [Paris and Durand 2006].
Extracting a 2D Map by Slicing
スライシングは、区分的にスムーズな出力を得るための重要なバイラテラルグリッド操作です。バイラテラルグリッド\(\Gamma\)と参照画像\(E\)が与えられたとき、トライリニア補間を用いて\((x/s_s, y/s_s, E(x,y)/s_r)\)のグリッドにアクセスすることにより、2次元値マップ\(M\)を抽出します。ここでは、\(M=s_E(\Gamma)\)という表記を用います。グリッドに同次値が格納されている場合、まずグリッドを補間して同次ベクトルを取り出し、次に補間されたベクトルを除算して実際のデータにアクセスします。
スライシングは、画像からグリッドを作成するのと対称です。グリッドの解像度と量子化が画像と一致していれば、スライスしても同じ画像になりますが、実際にはグリッドは画像よりはるかに粗くなります。作成からスライスまでの間にグリッドで処理を行うことで、エッジを意識した演算が可能になります。また、このグリッド処理によって、必要なサンプリングレートが決定されます。
Recap: Bilateral Filtering
この表記法を用いると、Paris and Durand [2006]による式1のバイラテラルフィルタを近似するアルゴリズムは、(図3)のようになります:
\begin{eqnarray}
bf(I) = s_I (G_{\sigma_s, \sigma_r} \otimes c(I)) \tag{2}
\end{eqnarray}
画像\(I\)をバイラテラルグリッドに埋め込み、このグリッドを空間パラメータ\(s_s\)と範囲パラメータ\(s_r\)の3次元ガウシアンカーネルで畳み込み、入力画像と一緒にスライスします。本研究の貢献は、バイラテラルグリッドがバイラテラルフィルタリングにとどまらず、様々なエッジ保存処理を可能にすることを示すことです。
3 GPU Parallelization
バイラテラルグリッドの開発では、グラフィックスハードウェアでの並列化を容易にすることが大きな目標の一つでした。ベンチマークを行った結果、CPUではスライスの段階でボトルネックとなり、トライリニア補間がコストに大きく影響することがわかりました。そこで、GPUのハードウェアテクスチャフィルタリングを活用し、スライス処理を効率的に行うことにしました。また、GPUのフラグメントプロセッサーは、ガウスブラーなどのグリッド処理にも最適なプロセッサーです。
3.1 Grid Creation
画像からバイラテラルグリッドを作成するために、各入力ピクセルの値を適切なグリッドボクセルに蓄積します。グリッドの位置は画素の値に依存するため、グリッドの作成は本質的に散乱操作となります。頂点プロセッサは真の散乱演算を行うことができる唯一のユニットであるため [Harris and Luebke 2004]、単一ピクセル点の頂点配列をラスタライズし、頂点シェーダを使用して出力位置を決定します。最近のハードウェアでは、頂点プロセッサーはテクスチャーメモリに効率的にアクセスすることができます。頂点配列は \((x, y)\) ピクセル位置からなり、頂点シェーダは対応する画像値 \(I(x, y)\) を調べて出力位置を計算します。しかし、古いハードウェアでは、頂点のテクスチャフェッチは遅い操作です。代わりに、入力画像を頂点カラー属性として保存します。各頂点はレコード\((x, y, r, g, b)\)であり、頂点テクスチャフェッチをバイパスすることができます。この方法の欠点は、入力画像をテクスチャとしてアクセスする必要があるスライス時に、データをコピーする必要があることです。これには、GPU メモリ内で高速コピーを行うために、ピクセルバッファオブジェクト拡張を使用します。
Data Layout
バイラテラルグリッドをテクスチャ平面上に\(z\)レベルを並べることで2次元テクスチャとして保存します。このレイアウトにより、スライス段階でハードウェアによるバイリニアテクスチャフィルタリングを使用し、テクスチャルックアップの数を8から2に減らすことができました。 同時座標をサポートするために、4成分、32ビット浮動小数点テクスチャを使用しています。このフォーマットでは、典型的な値である \(s_s=16\) と \(s_r=0.07\)(16 段階の強度)の場合、バイラテラルグリッドはメガピクセルあたり約 1 メガバイトのテクスチャメモリが必要です。極端なケースとして\(s_s=2\)の場合、ストレージコストはメガピクセルあたり約56メガバイトとなります。一般に、グリッドは \(16\times\) ピクセル数 \(/(s_s^2 \times s_r)\) バイトのテクスチャメモリを必要とします。同次座標を必要としないグリッドは、1成分の浮動小数点テクスチャとして保存され、1/4のメモリしか必要としません。我々の例では、50kBから40MBを使用しています。
3.2 Low-Pass Filtering
2.3 節で述べたように,バイラテラルフィルタのグリッド処理ステージは,3D ガウスカーネルによる畳み込みです。グリッドを構成する際,サンプリングレート\(s_s\)と\(s_r\)をガウシアン\(\sigma_s\)と\(\sigma_r\)のバンド幅に対応させることで,精度とストレージの良いトレードオフを実現しています [Paris and Durand 2006]。ガウスカーネルは分離可能であるため、フラグメントシェーダを用いて、各次元のグリッドを5タップの1次元カーネルで畳み込みます。
3.3 Slicing
バイラテラルグリッド処理後、入力画像\(I\)を用いてグリッドをスライスし、最終的な2次元出力を抽出します。GPU 上で \(I\) をテクスチャ付きの四辺形としてレンダリングし、フラグメントシェーダを使用して、テクスチャに保存されたグリッド値を検索することによって、スライスを行います。トリリニア補間を行うには、バイリニアテクスチャフィルタリングを有効にし、2つの最も近い\(z\)レベルをフェッチし、その結果間を補間します。ハードウェアのバイリニア補間を利用することで、各出力ピクセルに必要な間接的なテクスチャ参照は2回で済みます。
3.4 Performance
同じワークステーション上の3世代のGPUでグリッドベースバイラテラルフィルタのベンチマークを行いました。GPU は NVIDIA GeForce 8800 GTX(G80)、GeForce 7800 GT(G70)、GeForce 6800 GT(NV40) で構成され、ユニファイドシェーダを搭載しています。それぞれ2006年、2005年、2004年に発売されてます。CPUはIntel Core 2 Duo E6600(2.4GHz、キャッシュ4MB)です。
最初のベンチマークは、バイラテラルフィルタのパラメータを一定(\(\sigma_s=16\), \(\sigma_r=0.1\) )にしたまま、画像サイズを変化させたものです。同じ画像を様々な解像度でサブサンプリングし、1000回の繰り返しによる平均実行時間を報告します。図4は、我々のアルゴリズムが画像サイズに対して線形であることを示しており、G80では1メガピクセルの4.5ミリ秒から10メガピクセルの44.7ミリ秒までとなります。これは、頂点キャッシュのオーバーフローが原因であると思われます。比較のため、CPU の実装では、同じ入力で 0.2 秒から 1.9 秒の範囲になります。我々のGPU実装はWeissのCPUバイラテラルフィルタ[2006]を50倍上回る性能を持っています。
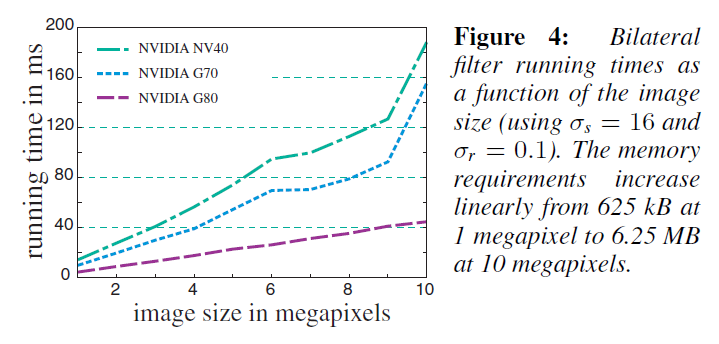
2つ目のベンチマークは、画像サイズを800万画素、範囲カーネルサイズ\(\sigma_r\)を0.1に保ち、空間カーネルサイズ\(\sigma_s\)を変化させたものです。最初のベンチマークと同様に、同じ画像を使用し、1000回の反復の平均実行時間を報告します。図5は、カーネルサイズの影響を示しています。\(\sigma_s=30\)と\(\sigma_s=60\)で、フレームバッファキャッシュの境界をヒットしたためと思われる曲線上のいくつかのバンプを除いて、我々のアルゴリズムは空間カーネルサイズに依存しません。これは,バイラテラルグリッドにおける3次元畳み込みカーネルが\(\sigma_s\)に依存しないことに起因しています。\(\sigma_s\)を増加させると、より積極的にダウンサンプリングするため、畳み込みカーネルは\(5 \times 5 \times 5\)のままです。比較のために、我々のCPU実装とWeissのアルゴリズムは、同じ値の\(\sigma_s\)で一貫して約1.6秒で実行されます。
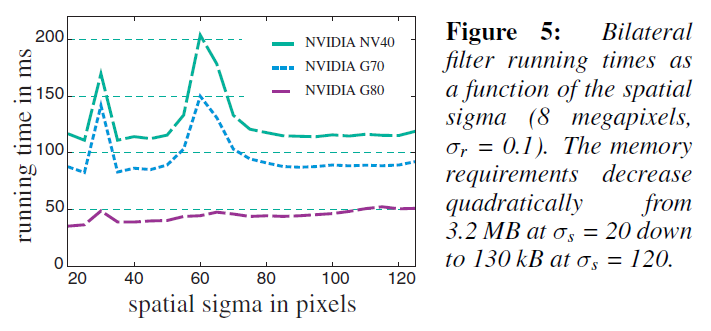
3世代とも、現在の1080p HDの解像度である200万画素でリアルタイム性能(30Hz)を実現しています。G80は700万画素で同程度のフレームレートを実現しています。すべての世代のハードウェアにおいて、本アルゴリズムのボトルネックはグリッド構築段階にあり、他の段階は基本的に自由である。OpenGL プロファイラを使用して検証したところ、固定数の頂点プロセッサを持つ古いハードウェアでは、アルゴリズムは頂点に制限され、パイプラインのリセットがデータ不足になることがわかりました。この状況は、現在のハードウェアではユニファイドシェーダを搭載しているため、ほぼ改善されています。そのときにボトルネックとなるのが、ラスター演算ユニットです。
3.5 Further Acceleration
現在のハードウェアでは、1080pのHDビデオに対して1フレームあたり複数のバイラテラルフィルターを実行できますが、古いハードウェアでは1フレームあたり1つのフィルターに制限されます。時間的にコヒーレントなデータに対しては、サブサンプリングに基づくアクセラレーションを提案します。グリッドのセルには多数のピクセルの加重平均が格納されており、それらのピクセルのサブセットだけで良好な推定値を得ることができる。\(\sigma_s \in [10, 50]\)と\(\sigma_r \in [0.05, 0.4]\)の典型的な値に対して、入力ピクセルの10%だけを使うことで、視覚的なアーティファクトのない出力が得られます。この10%の画素は,事前に計算されたポアソンディスクパターンのシーケンスを回転させながら選択することで,良好なカバレッジを得ることができます。時間的に変化するサンプリングパターンによって生じる「スイミング」アーティファクトに対処するため、5フレームの減衰定数を持つ時間指数フィルタを適用しています。これにより、ハードなシーン遷移を除いて、フルバイラテラルフィルタと視覚的に区別のつかない結果が得られます。
4 Image Manipulation with the Bilateral Grid
バイラテラルグリッドはバイラテラルフィルタリング以外にも様々な応用が可能です。以下では、バイラテラルグリッドの新しい作成方法、加工方法、スライス方法について紹介します。
4.1 Cross-Bilateral Filtering
バイラテラルフィルタを直接的に拡張したものとして,クロスバイラテラルフィルタ[Petschnigg et al.2004; Eisemann and Durand 2004]があり,画像データの概念は画像エッジから切り離されます。我々は、グリッド値を定義する画像\(I\)と、グリッド位置を決定するエッジ画像\(E\)の2つのパラメータを持つ新しいグリッド生成オペレータを定義すします。
\begin{eqnarray}
\Gamma \left( \left[ \frac{x}{s_s} \right], \left[ \frac{y}{s_s} \right], \left[ \frac{E(x, y)}{s_r} \right] \right) += (I(x, y), 1) \tag{3}
\end{eqnarray}
この演算子には\(\Gamma = c_E(I)\)という表記を用います。同様に、スライス演算子はエッジ画像 \(E\) を使ってグリッドをクエリし、結果を再構成します:
\begin{eqnarray}
cbf(I, E) = s_E(G_{\sigma_s, \sigma_r} \otimes c_E(I) ) \tag{4}
\end{eqnarray}
4.2 Grid Painting
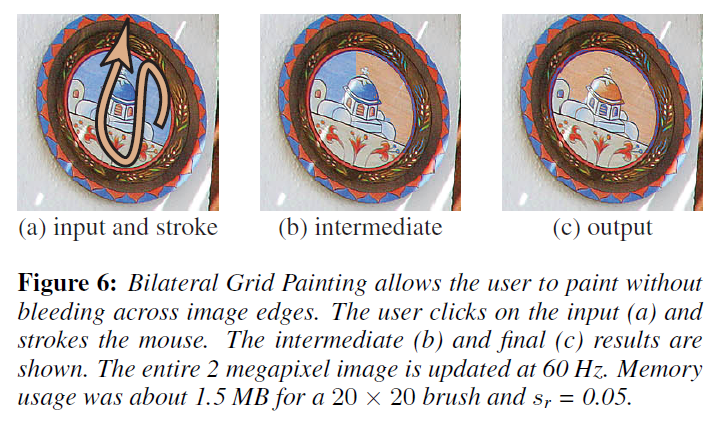
ここで、2.1節で述べたエッジ維持ブラシについて詳しく説明します。このブラシは、従来の2Dブラシのように、画像の明るさなどの特徴を局所的に「塗る」ことができ、さらに、画像の輪郭を「にじまない」ようにすることができます(図2)。我々は、バイラテラルグリッド\(\Gamma_{\rm brush}\)を使用して、適用される修正の強さを定義する2D影響マップ\(M\)を制御すします。スカラー(すなわち,非同次)グリッド\(\Gamma_{\rm brush}\)を0に初期化し,ユーザが画像画素\((x, y, I(x, y))\)をクリックすると,位置\((x/s_s, y/s_s, I(x, y)/s_r)\)を中心とする3Dブラシ(例えば,ガウス)をグリッド値に追加します。\(\Gamma_{\rm brush}\)を画像\(I\)でスライスして\(M\)を得ます:\(M=s_I(\Gamma_{\rm brush})\).
GPU Implementation
\(\Gamma_{\rm brush}\)を単一成分の2Dテクスチャとしてタイル化します。ユーザがマウスをクリックすると、フラグメントシェーダがブレンドを使ってブラシの形状をレンダリングします。スライシングはバイラテラルフィルタの場合と同じです。最新の GPU は、非常に大きな画像に対してバイラテラルグリッドペインティングをサポートすることができます。\(s_r=0.05\) の \(2 \times 2\) ブラシの場合、グリッドはメガピクセルあたり 20MB のテクスチャメモリを必要とし、\(5 \times 5\) ブラシの場合はメガピクセルあたり 1MB 未満の消費で済みます。
Results
図6では、マスクを作成せずに、画像の色相チャンネルを操作しています。最初のマウスクリックでグリッド内の\((x_0, y_0, z_0)\)が決定されます。その後のマウス操作では、\(x\) と \(y\) は変化しますが、\(z_0\) は固定されます。したがって、ブラシは選択された強度レイヤーにのみ作用し、画像エッジを越えることはありません。
4.3 Edge-Aware Scattered Data Interpolation
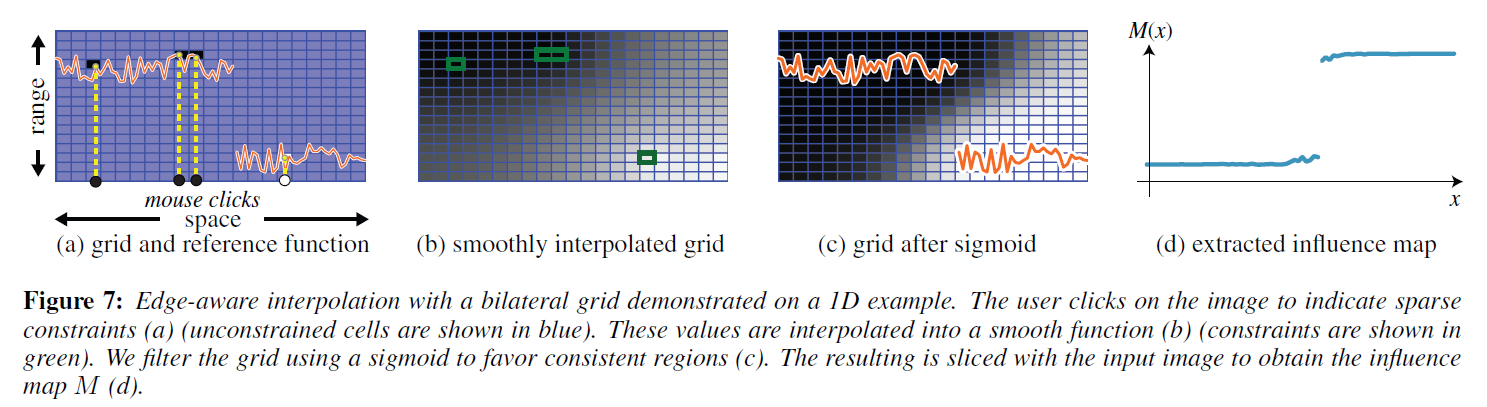
Lischinski ら [2006]は,Levin ら [2004]に触発されて,画像 \(I\) 上で影響マップ \(M\) を作成するためのらくがきインタフェースを導入しました。2次元マップ\(M\)は、基礎となる画像\(I\)のエッジを尊重しながら、ユーザが提供する制約\(\{M(x_i, y_i) = m_i\}\)(スクリブル)のセットを補間します。我々は、スカラーバイラテラルグリッド\(\Gamma_{\rm int}\)を使用して、同様の結果を得ることができます:画像領域で区分的な平滑補間を解く代わりに、グリッド領域で平滑補間を解いてからスライスします。
ユーザが提供した制約を3次元領域に持ち出します:\(\{\Gamma_{\rm int}([x/s_s], [y/s_s], [I(x, y)/s_r] ) = m_i\}\)で、グリッド値の変動を最小化します。
\begin{eqnarray}
{\rm argmin} \int || {\rm gard}(\Gamma_{\rm int}) ||^2 \tag{5} \\
{\rm under} \, {\rm the} \, {\rm constraints}: \left\{ \Gamma_{\rm int} \left( \left[ \frac{x}{s_s} \right], \left[\frac{y}{s_s} \right], \left[ \frac{I(x, y)}{s_r} \right] \right) = m_i \right\}
\end{eqnarray}
2次元の影響マップは、スライスすることで得られます。最後に、Levin et al. [2007]と同様に、影響マップを 0 と 1 に偏らせる。これは、グリッド値にシグモイド関数を適用することで達成されます。図7はこの処理をまとめたものであり、図8は結果の一例です。
Discussion
画像ベースのアプローチ[Levin et al. 2004; Lischinski et al. 2006]と比較すると、我々の手法はピクセルレベルで動作しないため、場合によっては精度が制限されるかもしれませんが、我々の実験では大きな問題は発見されませんでした。一方、バイラテラルグリッドは、画像に依存した非同次2次元最適化を、より単純な滑らかで同次3次元補間に変換するものです。さらに、グリッドの解像度は画像の解像度から切り離されているため、画像の解像度に応じて複雑さが増すことを防ぐことができます。
また、画像ベースの技術は画像多様体上の「測地的距離」の概念を用いるのに対し、我々は高次元空間のユークリッド距離を考慮するという違いもあります。この2つの尺度の比較はさらなる調査に値するものであり、どちらの方法が最も適切かはアプリケーションに依存する選択であると考えます。
GPU Implementation
グリッドペインティングと同様に、フラグメントシェーダを使って、バイラテラルグリッドへとらくがき制約をラスタライズします。制約を尊重したグローバルに滑らかなバイラテラルグリッドを得るために、GPUマルチグリッドアルゴリズム[Goodnight et al.2003]を拡張して不規則な3Dドメインを扱うことにより、ラプラス方程式を解きます。この領域は、ユーザが指定したハード制約によって追加の境界が作られるため、穴があります。
Results
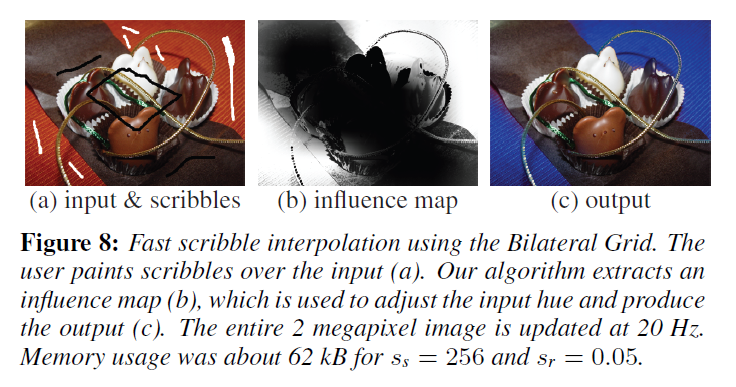
簡単な色調整アプリケーションを用いたリアルタイムらくがき補間のデモを行います。ユーザは画像上に走り書きをする。白い走り書きは色相を調整すべき領域を表し、黒い走り書きは画像領域を保護します。実際には、\(\Gamma_{\rm int}\)のサンプリングレートは非常に粗くても、良好な影響マップを得ることができます。図8 の例では,約 600 個の変数を含む粗いグリッドを 使用しており,GPU ソルバーによるリアルタイム(40Hz) のインフルエンスマップ生成を可能にしています。また,微調整が必要な場合は,50 万以上の変数を含む細かくサンプリングされたグリッドでインタラクティブレート(1Hz)を達成することができます。編集セッションの画面キャプチャは、補足ビデオを参照してください。
4.4 Local Histogram Equalization
ヒストグラム均等化は、画像のコントラストを強調するための標準的な手法です[Gonzales and Woods 2002]。しかし、X線画像やCT画像など、ダイナミックレンジの広い入力画像では、ヒストグラム均等化によって、限られた強度範囲にある小さなディテールが不明瞭になる場合があります。このような場合は、画像ウィンドウに対して局所的にヒストグラム均等化を実行する方が有効です。本論文では、バイラテラルグリッドを用いて局所的なヒストグラム均等化を効率的に行い、GPUを用いたリアルタイム処理を実現します。
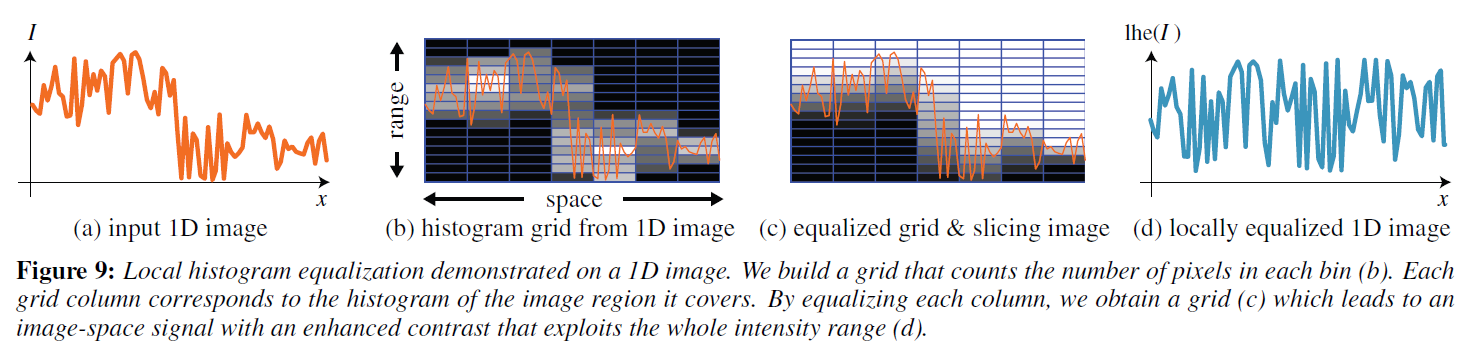
入力画像\(I\)が与えられたら、スカラーバイラテラルグリッド\(\Gamma_{\rm hist}\)を構築します。\(\Gamma_{\rm hist} = 0\)で初期化し、それを埋める。
\begin{eqnarray}
\Gamma_{\rm hist} \left( \left[ \frac{x}{s_s} \right], \left[ \frac{y}{s_s} \right], \left[ \frac{I(x, y)}{s_r} \right] \right) += 1 \tag{6}
\end{eqnarray}
この操作を\(\Gamma_{\rm hist}=c_{\rm hist}(I)\)とします。\(\Gamma_{\rm hist}\)はグリッドセル内の画素数を格納し,ローカルヒストグラムの集合とみなすことができます。各\((x, y)\)に対して、対応する列は\(s_s \times s_s\)のカバーピクセルをサイズ\(s_r\)の強度区間に分割しています。\(\Gamma_{\rm hist}\) を構築する際に最も近い整数にする演算子を用いることで、空間的にボックスフィルタを実行します。より滑らかな空間カーネルが必要な場合は、グリッドの各\(z\)レベルを空間カーネル(例えば、ガウシアン)でぼかします。各列に標準的なヒストグラム均等化を適用し,得られたグリッドを入力画像\(I\)でスライスすることにより,局所的なヒストグラム均等化を行います。
GPU Implementation
画像データを無視できることを除けば、バイラテラルフィルタリングと同じ方法でバイラテラルグリッドを構築します。次に、バイラテラルグリッドの各列\((x, y)\)上で累積するフラグメントシェーダを実行します。これにより、各\((x, y)\)列が非正規化累積分布関数である新しいグリッドが生成されます。最終的なbin値を除算することで、グリッドを0と1の間に正規化するために、もう1つのパスを実行します。最後に、入力画像を用いてグリッドをスライスします。
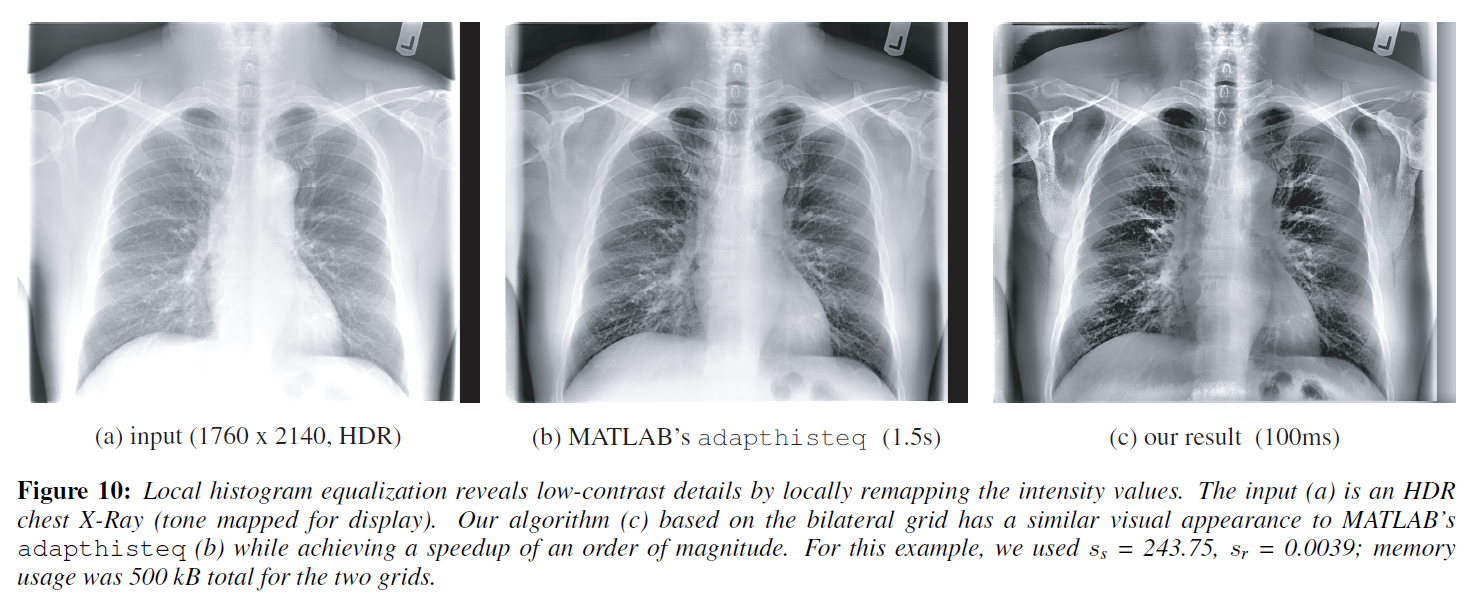
Results
本アルゴリズムは、MATLABのadapthisteqと視覚的に類似した結果を達成しています(図10)。どちらの場合も、臓器の形状を維持したまま、低コントラストの詳細が明らかにされています。バイラテラルグリッドに基づく我々の手法は、270万画素のHDR画像において、1.5秒に対して100秒と、1桁の高速化を達成しました。
5 Applications and Results
本項では、バイラテラルグリッドを用いた画像処理を活用した様々なアプリケーションについて説明します。また、本成果のデモンストレーションを補足ビデオでご覧いただけます。動画アプリケーションでは、デコードはCPU上でGPUと並列に実行される別スレッドで行われます。タイミングは、パイプライン全体の平均スループットを測定しています。CPUでは、最大の入力ビデオ(H.264コーデックを使用した解像度1080p)の場合、各フレームのデコードに約25msかかります。これは、多くの場合、デコードがエッジアウェア演算子よりも高く、パイプラインのボトルネックとなることを意味します。
5.1 High Resolution Video Abstraction
Winnemollerら[2006]は,映像をリアルタイムで定型化・抽象化する技術を示しました。彼らの手法の大きなボトルネックはバイラテラルフィルタで、映像はDVD解像度(0.3メガピクセル)、フレームレートは9〜16Hzに制限されていました。このフレームレートを達成するために、彼らは小さなカーネルサイズを持つバイラテラルフィルタの分離可能な近似を使用し、十分に大きな空間サポートを得るために近似を繰り返しました[Pham and van Vliet 2005]。バイラテラルグリッドを我々のGPUアクセラレーション技術と組み合わせることで,1080p HDビデオ(1.5メガピクセル)に対して42Hzでビデオ抽象化を行うことができます(セクション3.5で説明する追加アクセラレーションを使用しない場合)。
Progressive Abstraction
さらに、この技術を強化するために、DeCarloら[2002]によるスタイライゼーション技術の精神に則り、フォーカスポイントの近くのディテールは遠くのディテールよりも抽象化されにくいという漸進的抽象化コンポーネントを組み込ました。本手法では、4レベルのバイラテラルピラミッド(基底\(s_s\)と\(s_r\)の倍数で計算されるバイラテラルグリッド)を構築する。入力フレームを抽象化するために、まず、ユーザのフォーカスポイントから落ちる距離マップを計算します。この距離マップを参照画像とクロスバイラテラルフィルタリングして重要度マップを得ることで、画像のエッジを尊重することを保証します。この重要度マップを用いて、入力フレーム(フォーカスポイント)とマルチスケールバイラテラルグリッドのレベル間の線形補間を行います。この結果をビデオ抽象化パイプラインの残りの部分への入力として使用します。我々は、最初のピラミッドレベルから線を抽出することで、より首尾一貫した出力が得られることを発見しました。4レベルのピラミッドでは、1080pのビデオで20Hzを維持することができます。
5.2 Transfer of Photographic Look
Baeら[2006]は,モデル写真の “表情 “を入力写真に転写する方法を紹介しました。我々は、彼らの研究をリアルタイムで動画に適用しました。動画に特有の制約を扱うために,2つの改良を行います。本論文では,動画像に特有な制約を克服するために,簡略化されたパイプラインを用い,元の処理の効果をほとんど保持しつつリアルタイム性を実現します。また、DVDや民生用カメラで撮影された動画などのソースに対応するため、ノイズや圧縮アーティファクトに特化した処理を行います。
Processing Pipeline
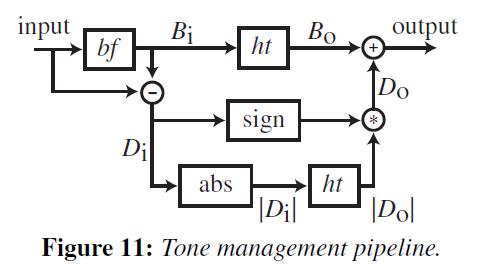
Baeらと同様に、各入力フレーム\(I\)に対してバイラテラルフィルタを用い、その結果をベース層\(B_i = bf(I)\)、その残差をディテール層\(D_i = I -B_i\)と命名します。モデル画像\(M\)に対しても同様の分解を行い、\(B_m\)と\(D_M\)を得ます。ヒストグラム転送を利用して、入力ベース\(B_i\)が\(B_m\)のヒストグラムと一致するように変換します。ここでは、ヒストグラム転送演算子を\(ht\)、ベース出力を\(B_o = ht_{B_m} (B_i)\)と表記します。詳細層については、振幅のヒストグラムに一致する:\(|D_o|=ht_{|D_m|}(|D_i|)\)とします。入力の詳細の符号を用いて、出力の詳細層を得る。\(Do={\rm sign}(D_i)|D_o|\)とします。出力フレーム\(O\)は、ベース層とディテール層を加算することで再構成されます:\(O=B_o + D_o\)。
Denoising
多くのビデオは、ノイズが多かったり、アーティファクトを導入する圧縮アルゴリズムを使用しています。これらの欠陥は、元の映像では目立たないことが多いのですが、コントラストやディテールのレベルを上げると、明らかになることがあります。ナイーブな解決策としては、入力フレームを処理する前にノイズ除去することが考えられますが、これでは「きれいすぎる」画像が生成され、非現実的に見えてしまいます。そこで、処理後にノイズ除去の残差を加えることで、より現実的な外観の優れた結果が得られることを発見しました。実際には、ノイズの振幅はシーンのエッジに比べて小さいため、シグマが小さいバイラテラルフィルタを使用しています。
Discussion
Baeらの処理と比較すると、我々の方法は、フレームのテクスチャのレベルを推定するために、直接ディテール振幅に依存しています。Baeらによって提案されたtextureness指標はより洗練された効果を捉えるが、3つの追加的なバイラテラルフィルタリングステップを含み、その計算コストは我々のアルゴリズムがHDシーケンス上でリアルタイムに実行することを阻んでいます。我々の結果は、ディテール振幅が満足のいく近似値であることを示しています。さらに、可能な入力の範囲を広げるノイズ除去ステップを含めるための十分な余裕を与えています。
5.2 Local Tone Mapping
グリッドペインティングに基づき、HDR画像を局所的にトーンマッピングするユーザー主導型の手法を説明します。Durand と Dorseyのトーンマッピングアルゴリズム[2002]をベースに、画像の対数輝度\(L\)をベース層\(B = bf(L)\)とディテール層\(D = L-B\)に分解し、ベース層のコントラストを単純な線形リマッピング\(B’ = \alpha B + \beta\)で下げ、ディテール層\(D\)は影響を受けないようにしたものです。これにより、局所的なディテールを失うことなく、全体的なダイナミックレンジを縮小することができます。最終的な出力は、\(B’+D\)の指数を取り、色比を保存することで得られます。
本手法では、このベースレイヤーのグローバルリマッピングを拡張し、エッジを意識したブラシを用いてリマッピング関数を局所的に変更することができるようにしました。リマッピング関数は、線形ランプで初期化されたグリッド\(\Gamma_{\rm TM}\)で表現します:
\begin{eqnarray}
\Gamma_{\rm TM}(x, y, z) = \alpha z + \beta \tag{7}
\end{eqnarray}
\(\Gamma_{\rm TM}\)が未編集の場合、\(\Gamma_{\rm TM}\)を\(B\)でスライスすると、DurandとDorseyのオペレータと同じリマップされたベースレイヤーが得られます:\(B’=s_B(\Gamma_{\rm TM})\)。
ユーザーが\(\Gamma_{\rm TM}\)をエッジアウェアブラシで編集し、局所的にグリッド値を変更します。位置\((x, y)\)のピクセル上で左ボタンをクリックすると、グリッド値に \((x/s_s, y/s_s, L(x, y)/s_r)\)を中心とした 3D ガウシアンが追加されます。
実際には、ユーザー指定の振幅\(A\)、パラメータ\(\sigma_s\)、\(\sigma_r\)を持つガウシアンカーネルを使用します。空間サンプリング\(s_s\)はブラシの大きさを、範囲サンプリング\(s_r\)はエッジに対する感度を制御します。また,マウスボタンを押し続けると,\(z\) 座標が最初のクリックの値 \(L(x_0, y_0)/s_r\) に固定されるため,異なる強度の特徴に影響を与えることなく描画することが可能です。
ベースレイヤーを作成するバイラテラルフィルターとグリッドペインティングにGPUアルゴリズムを用い、15メガピクセルの画像を50Hzでトーンマッピングした(図1)。ローカルトーンマッピングの画面キャプチャは動画をご参照ください。
6 Discussion and Limitations
Memory Requirements
この手法は、2次元画像と比較して、より粗い解像度のバイラテラルグリッドを用いることで効率を高めています。しかし、空間カーネルが小さいバイラテラルフィルタのような演算では、細かいサンプリングが必要であり、その結果、本技術ではメモリと計算コストが大きくなってしまう。この場合、Weissのアプローチの方がより適切です[2006]。それでも、計算写真アプリケーションで用いられる大きなカーネルに対しては、我々の手法は従来の手法よりも大幅に高速です。
メモリの制約上、バイラテラルグリッドは画像強度を格納する1次元の範囲に限定され、孤立したエッジで問題が発生することがあります。その結果、多くの場合、\(z\)を7~20段階とすることで、良好な結果が得られることがわかりました。今後の研究の方向性としては、より高次元のバイラテラルグリッド:カラーエッジを扱える5次元グリッド、さらには動画用の6次元グリッドを効率的に格納する方法を検討することです。また、メモリの制限を軽減するために、高速な次元削減技術を検討することも考えられます。
Interpolation
スライスの際にトライリニア補間を行うことで、最適なパフォーマンスを実現します。高次のアプローチは、より高品質な再構成をもたらす可能性があります。これらのフィルタを使用した場合の品質とコストのトレードオフを調査したいです。
Thin Features
バイラテラルグリッドに基づく技術は、薄い画像特徴においてバイラテラルフィルタと同じ特性を持ちます。例えば、窓枠越しに見える空の画像では、エッジ認識ブラシは枠とは無関係に空に作用します。つまり、枠に手を加えることなく枠を越えて描画される。このように、薄い特徴でフィルターを止めるかどうかが、バイラテラルフィルタリングと拡散技術の根本的な違いです。用途によっては、どちらの挙動も有用だと考えています。
7 Conclusion
我々は、リアルタイムでエッジを保持した画像操作を可能にする新しいデータ構造、バイラテラルグリッドを提案しました。画像処理を高次元空間に持ち上げることで、画像中の強いエッジを自然に尊重するアルゴリズムを設計することができます。この手法は、最新のグラフィックスハードウェアにうまく対応し、高精細映像のリアルタイム処理を可能にします。
Acknowledgements
和訳省略。
References

