こんにちわ。Pocolです。
今日は,タイルシェーディングについての実装メモを書くことにします。
ナイーブなディファードレンダリングの実装では次のよう疑似コードのようにライトループを実装してポイントライトなどのライティングを行うことになるかと思います。
for(auto i=0; i<lightCount; ++i)
{
// ライトデータ取得.
auto lightData = GetLightData(i);
// G-Buffer設定.
bindGBuffer(commandList);
// ライトデータ設定.
bindLight(commandList, lightData);
// フルスクリーンで矩形を描画.
DrawTriangle(commandList);
}
この実装は,ライト毎にG-Bufferにアクセスする必要があります。また,ライティングに関係のないピクセルまで起動する恐れがあるため,無駄な処理が発生することになります。
そこで,考えられたのがタイルシェーディングです。スクリーンをタイルに区切って,そのタイルに影響を及ぼすライトを求めて,タイルに対してシェーディング処理を行います。
G-Bufferなどを持つディファードレンダラーに対して,タイルシェーディングを適用するものをTile Deferred Shadingと言ったりします。一方,フォーワードレンダラーに対して,タイルシェーディングを適用するものとしてTile Forward Shadingや,Forward+ Shadingといったものがあります。
Tile Deferred Shadingの実装の助けになりそうなサンプルとしては,Intelのサンプル[Lauritzen 2010]があります。このサンプルコードでは,\(16 \times 16\)のタイルに分割して最大1024ライトを扱う実装がされています。実際の実装は[Lauritzen 2010]を参照してもらうとして,ここでは,疑似コードを書いておくことにします。基本的には,groupsharedにライトインデックスを格納していきます。groupsharedはAPIで使用可能な上限値が決まっているので,注意してください。
#define TILE_WIDTH (16)
#define TILE_HEIGHT (16)
#define TILE_SIZE (TILE_WIDTH * TILE_HEIGHT)
#define MAX_LIGHTS (1024)
groupshared uint LightIndices[MAX_LIGHTS];
groupshared uint LightCount;
groupshared uint MinZ;
groupshared uint MaxZ;
[numthreads(TILE_WIDTH, TILE_HEIGHT, 1)]
void main
(
uint3 groupId : SV_GroupID,
uint3 dispatchId : SV_DispatchThreadID,
uint3 groupThreadId : SV_GroupThreadID
)
{
// タイル番号を求める.
uint tileIndex = groupThreadId.y * TILE_GROUP_DIM + groupThreadId.y;
float minZSample = ...; // ビュー空間での最小zを求める.
float maxZSample = ...; // ビュー空間での最大zを求める.
if (tileIndex == 0)
{
LightCount = 0;
MinZ = 0x7F7FFFFF; // float最大値.
MaxZ = 0;
}
// 初期化の同期をとる.
GroupMemoryBarrierWithGroupSync();
// floatで計算できないため,uintにキャストしてタイル内の深度の最大・最小を求める.
InterlockedMin(MinZ, asuint(minZSample);
InterlockedMax(MaxZ, asuint(minZSample);
// 並列実行されるため,ここで同期をとる.
GroupMemoryBarrierWithGroupSync();
// floatに戻す.
float minTileZ = asfloat(MinZ);
float maxTileZ = asfloat(MaxZ);
// タイル錐台を求める.
float4 planes[6];
CalcTileFrustum(planes);
// タイルに関してカリングを行う.
for(uint i=tileIndex; i<pointLightCount; i+=TILE_SIZE)
{
PointLight light = PointLightData[i];
// ビュー空間に変換.
light.Position = mul(light.Position, ViewMatrix);
// タイル内に含まれるかどうかチェック.
if (Contains(planes, light))
{
// visible なライトをカウントアップ.
uint listIndex;
InterlockedAdd(LightCount, 1, listIndex);
// ライト番号リストに追加.
LightIndices[listIndex] = i;
}
}
// LightIndicesの同期をとる.
GroupMemoryBarrierWithGroupSync();
// 画面内であればライティング処理.
if (all(CheckScreen(dispatchId.xy) && LightCount > 0)
{
// G-Bufferからサーフェイスデータを取得. dispatchIdはピクセル単位.
SurfaceData surfaceData = GetSurfaceDataFromGBuffer(dispatchId);
// ライティング結果.
float4 result = 0;
// ライトループ.
for(uint i=0; i<LightCount; ++i)
{
uint index = LightIndices[i];
PointLight light = PointLightData[index];
result += CalculateLighting(light, surfaceData); // BRDF * light.
}
// フレームバッファに出力.
OutputFrameBuffer(result, dispatchId.xy);
}
}
CPU側からのコンピュートシェーダの起動は次のような感じ。
uint32_t threadX = (ScreenWidth + TILE_GROUP_DIM - 1) / TILE_GROUP_DIM; uint32_t threadY = (ScreenHeight + TILE_GROUP_DIM - 1) / TILE_GROUP_DIM; commandList->Dispatch(threadX, threadY, 1);
Intelのサンプルで注意すべき点は,左手座標系なのと不具合があるようです。こちらについては,もんしょさんとmomose_dさんのページ([monsho 2012], [momose_d 2014]を参照するとよいです。
カリングをタイトに行うためには,[Zhang 2018]に記載があります。コーンテストを使用することで,処理向上が見込めるようです。
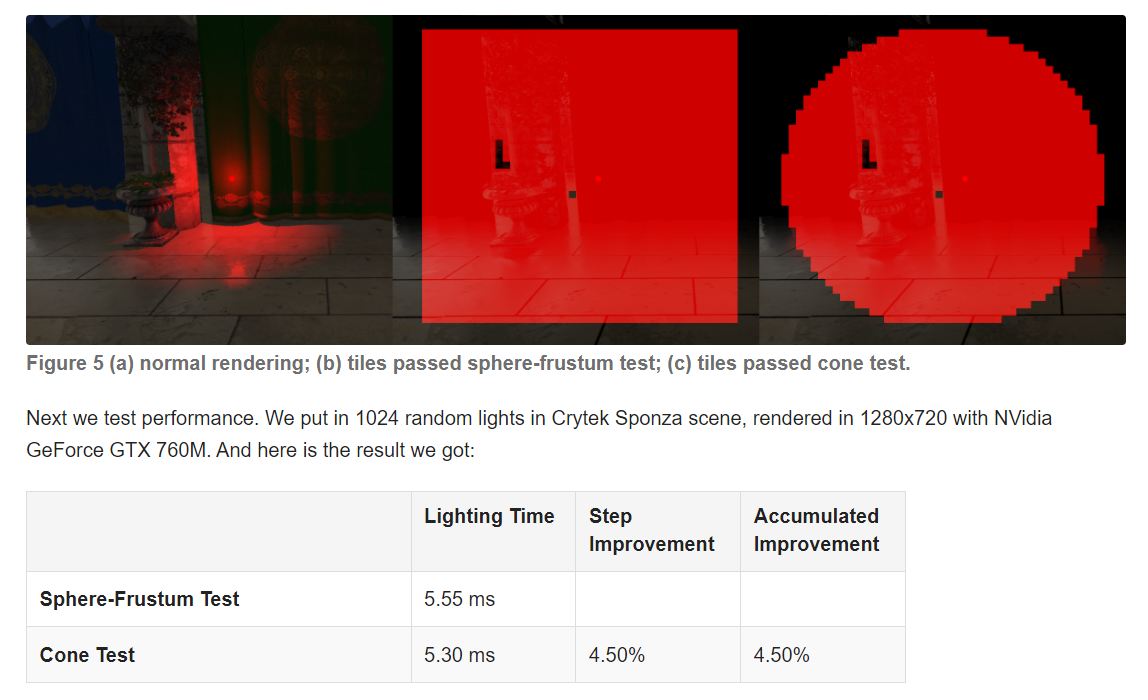
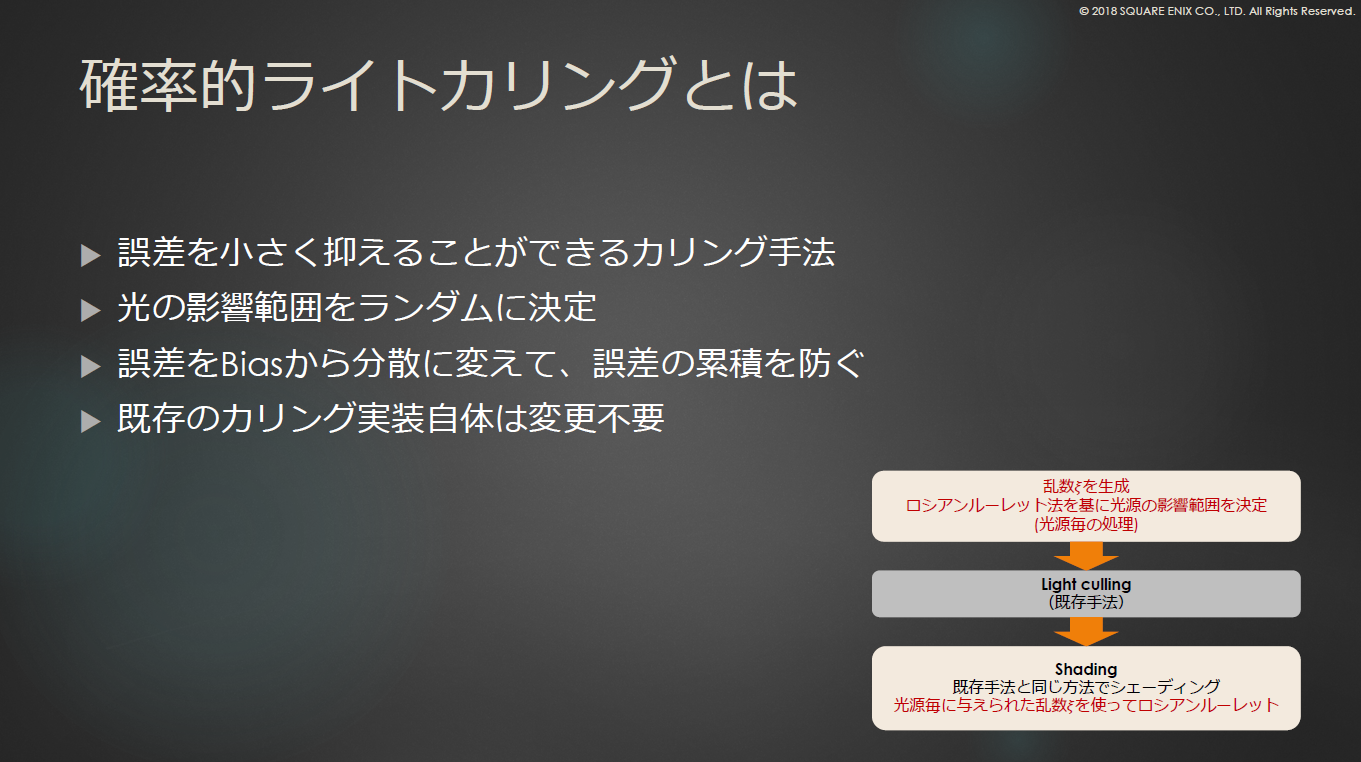
また、確率的ライトカリング[Tokuyoshi 2018]を併用することで,処理負荷を軽減できる可能性があります。

[Drobot 2017]では,Z-Binningを組み合わせることでクラスター化を実装できることが示されています。
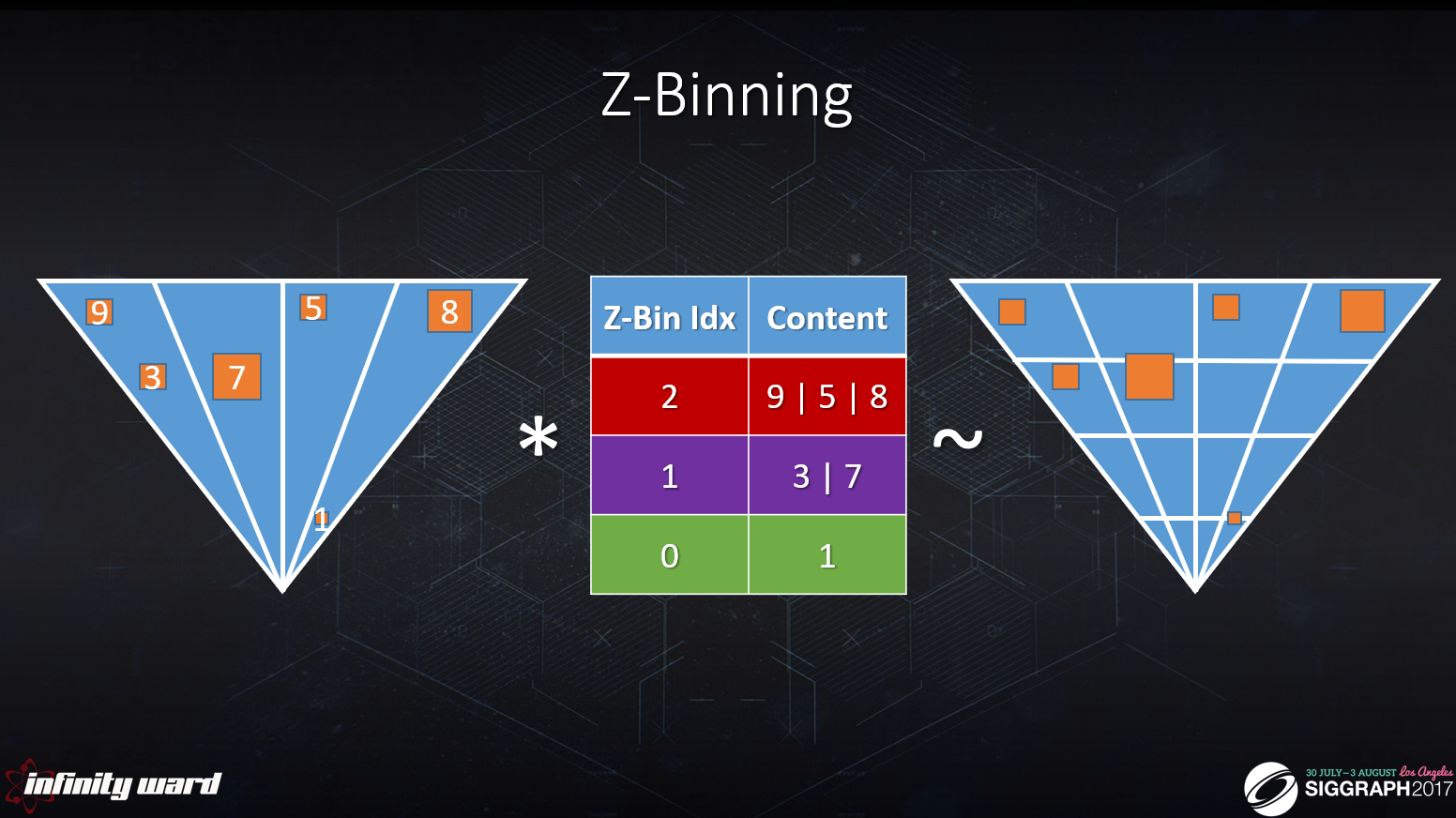
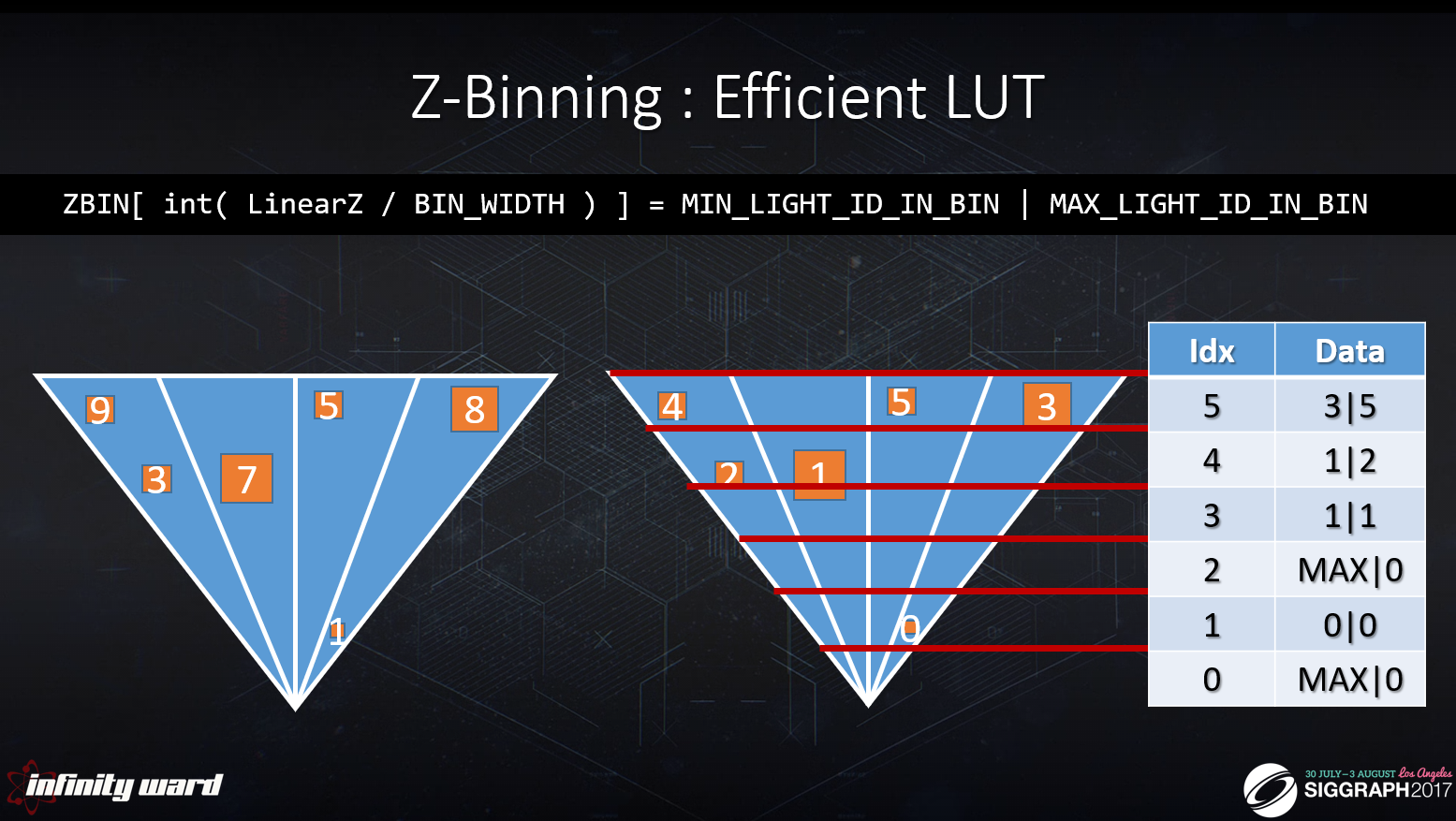
この手法は,通常のクラスターデータよりもメモリ量が少なくて済むというメリットがありますが,Z-Binningで番号管理する関係上でCPU上でライトをZソートしておく必要があります。

…ということで,タイルシェーディングについての実装メモでした。
参考文献
- [Lauritzen 2010] Andrew Lauritzen, “Deferred Rendering for Current and Future Rendering Pipelines”, Intel, 2010, https://www.intel.com/content/www/us/en/developer/articles/technical/deferred-rendering-for-current-and-future-rendering-pipelines.html
- [Zhang 2018] Eric Zhang, “Improved Tile-based Light Culling with Spherical-sliced Cone”, Eric’s Blog, 2018, https://lxjk.github.io/2018/03/25/Improve-Tile-based-Light-Culling-with-Spherical-sliced-Cone.html
- [Tokuyoshi 2018] 徳吉雄介, “確率的ライトカリング―基礎から動的コースティクスの描画まで―”, CEDEC 2018, https://cedil.cesa.or.jp/cedil_sessions/view/1815
- [Drobot 2017] Michal Drobot, “Improved Culling for Tile and Clustered Rendering: Call of Duty Infinite Warfare”, SIGGRAPH 2017 Advanced in Real-Time Rendering Courses, https://research.activision.com/publications/archives/improved-culling-for-tiled-and-clustered-rendering-in-call-of-dutyinfinite-warfare
- [monsho 2012] もんしょ, “Tile-based Rendering”, https://sites.google.com/site/monshonosuana/directx%E3%81%AE%E8%A9%B1/directx%E3%81%AE%E8%A9%B1-%E7%AC%AC125%E5%9B%9E?authuser=0, もんしょの巣穴 ver.2.0, 2012.
- [momose_d 2014] momose_d, “タイルベースポイントライトカリングでのタイルフラスタム計算メモ”, http://momose-d.cocolog-nifty.com/blog/2014/03/post-a593.html, momose_d blog, 2014.