こんばんわ。Pocolです。
もうすぐSIGGRAPHですね。SIGGRAPHのコースで「なねぃと」についての話があるそうで,そのコースを受ける前にある程度は調査しておこうと思いました。Sさん、問題あればご連絡を。
個人的に知りたいこと
今回の調査では下記のようなことを知りたいなと思ったので,調査してみました。
- どんなレンダリングフローなのか?
- 実際にどんなシェーダ使っているの?
- どうやってストリーミングするものを決めてるの?
- ストリーミングデータはどうやって作るのか?
大雑把な流れ
なねぃとは仮想化マイクロポリゴンジオメトリシステムです。いわゆるVirtual Textureみたいなテクスチャストリーミングのメッシュ版という感じのやつです。細かいポリゴンを扱えるのが売りになっていて,ものすごくいい感じのディテールが表現できます。
なねぃとを実現するためのキーだと思っているものは次の通りです。
- GPU駆動描画
- 高速なソフトウェアラスタライズ
- Deferred Material(Visibility Buffer)
- トライアングルデータの圧縮
- 階層LODの構築
まずGPU駆動描画はその名の通り,GPU上で描画するかどうかを判定を行い,その結果で描画が駆動する手法のことを言ったりします。これはカプコンさんだったり,アサクリだったり,Trialsだったりと色々な会社さんがすでに取り組まれています。内容について知らない方がいたら下記の資料などを読むと良いと思います。
- 三嶋仁, 清水昭尋, “GPU駆動レンダリングへの取り組み”, Game Creaters Conference 2016
- Ulrich Harr, Sebastian Aaltonen, “GPU-Driven Rendering Pipelines”, SIGGRAPH 2015: Advances in Real-Time Rendering in Games
- Graham Wihlidal, “Optimizing the Graphics Pipeline with Compute”, GDC 2016
- Olksandr Drazhevskyi, “GPU Driven Rendering and Virtual Texturing in Trials Rising
UE5はバウンディングのスケールに応じてソフトウェアラスタライズとハードウェアラスタライズの分岐がコンピュートシェーダ上で決定されます。
小さな三角形はコンピュートシェーダを用いたソフトウェアラスタライズが実行され,大きな三角形に対してハードウェアラスタライザが実行されます。
ソフトウェアラスタライザですが,小さな三角形に対しては平均で3倍高速化したと「Nanite | Inside Unreal」の動画でKarisが言っていました。恐るべき速度ですね。

あとは,この高速なソフトウェアラスタライズを支える技術として,Deferred Materialを使用しています。いわゆるVisibility Bufferというやつです。
これの何が良いかというと,深度とマテリアルインデックスをバッファに出力してしまい,マテリアル評価を遅延実行できるというメリットがあります。つまり,いちいちシェーダの切り替えをしなくて良いということです。これによりUE5は不透明物体の描画を1ドローで実現しています。

さらにNaniteを見ていてがんばっているなーと思うのがデータの圧縮です。1トライアングルにつき平均14.4Byteだそうです。一応自分でもソースコードを追ってみて,確かにそうだなということを確認しました。

どんなレンダリングフローなのか?
まずは,レンダラーの流れをつかみ大雑把にどんなことをやっているのかを把握してみました。
レンダラーの実装は,Engine/Source/Runtime/Renderer/Private/DeferredShadingRenderer.cppにあります。これがディファードレンダリングの実装になっており,Render()メソッドに実装があるので,これを地味に読み解いていきました。なんとこの関数1600行ほどあります。
この関数をところどころを端折った疑似コードが下記のような感じになります。
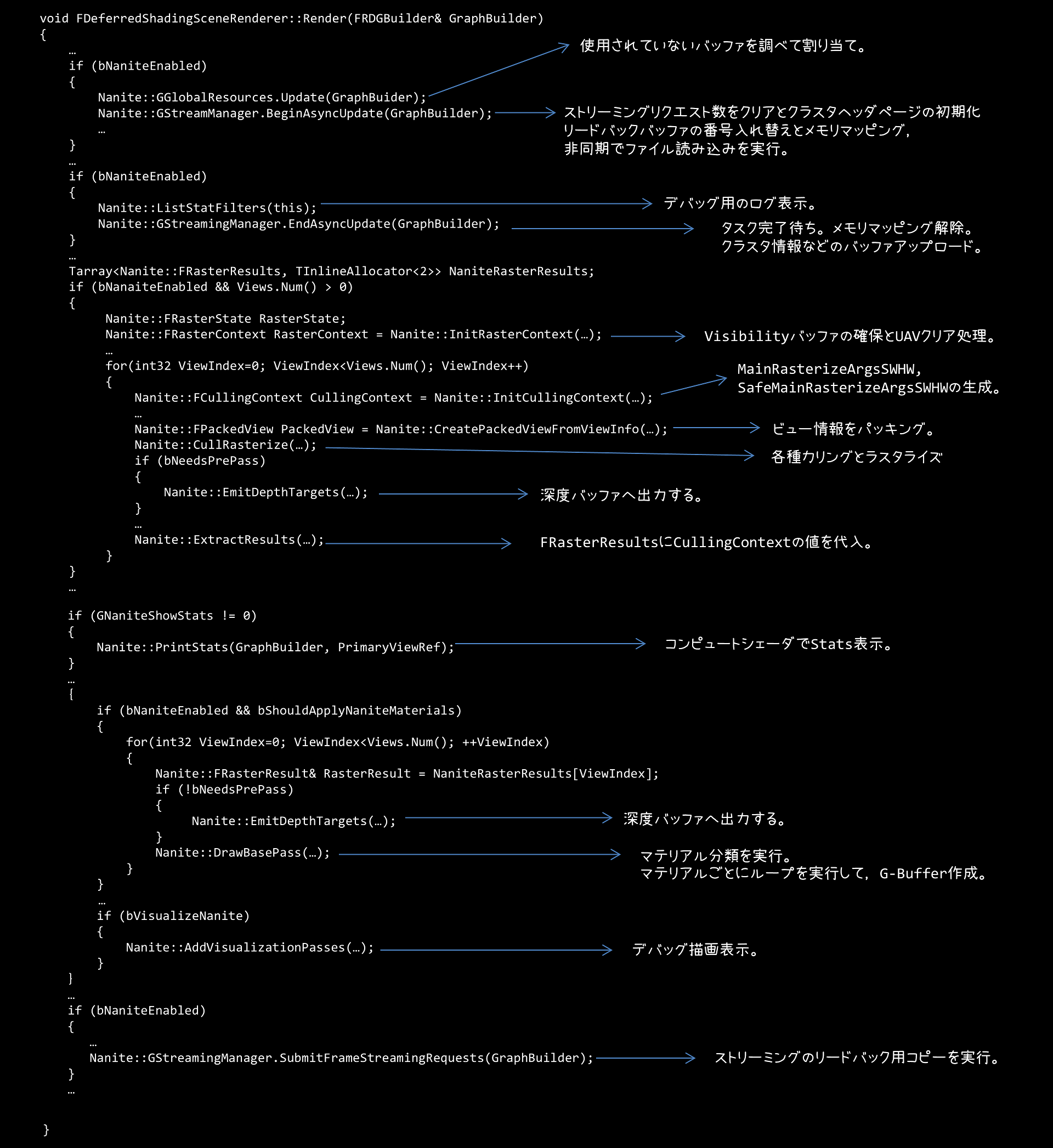
ざっくりですが,処理をまとめておくと
- グローバルリソースを更新
- 非同期でファイル読み込みを開始
- 読み込みタスクの完了待ちをして,GPUにデータを転送
- Visibility Bufferをクリア
- ビュー情報をパッキングしてカリングとラスタライズを実行
- 深度バッファに出力
- マテリアルごとにドローコールを発行して,タイル描画を行うことによりG-Bufferを構築
…という感じです。
実際にどんなシェーダ使っているの?
CullRasterize()
下記のシェーダが実行されるようです。
- InstanceCull :パス Engine/Private/Nanite/InstanceCulling.usf
- InitArgs :パス Engine/Private/Nanite/ClusterCulling.usf
- InstanceCullVSM :パス Engine/Private/Nanite/InstanceCulling.usf
- PersistentClusterCull : パス Engine/Private/Nanite/ClusterCulling.usf
- CalculateSafeRasterizerArgs : パス Engine/Private/Nanite/ClusterCulling.usf
- HWRasterizerVS : パス Engine/Private/Nanite/Rasterizer.usf
- HWRasterizerPS : パス Engine/Private/Nanite/Rasterizer.usf
- MicropolyRasterize : パス Engine/Private/Nanite/Rasterizer.usf
左側は実行される関数で,右側はその関数が実装されているファイルパスを表します。
PersistentCull()がおそらく一番巨大なシェーダコードになると思うのですが,クラスタ階層のトラバーサルとかカリング,あとはソフトウェアラスタライズかハードウェアラスタライズかどうかの切り分けなんかも行っています。
MicroPolyRasterize()がソフトウェアラスタライズを行っているのですが,R32G32のバッファに書き込みをします。Rチャンネルの25bit分がVisibleIndexで,残りの7bitがTriangleIDになっています。GチャンネルはDepthに割り当てられているようです。
EmitDepthTargets()
下記のシェーダが実行されるようです。
- DepthExport : パス Engine/Private/Nanite/DepthExport.usf
- EmitSceneDepthStencilPS : パス Engine/Private/Nanite/ExportGBuffer.usf
- EmitSceneSStencilPS : パス Engine/Private/Nanite/ExportGBuffer.usf
名前通りの処理っぽいです。
DrawBasePass()
下記のシェーダが実行されるようです。
- ClassifyMaterials : パス Engine/Private/Nanite/MaterialCulling.usf
- FullScreenVS : パス Engine/Private/Nanite/ExportGBuffer.usf
ClassifyMaterials()の中では,VisibleなMaterialとMaterial Rangeを決定するようです。Material Rangeにはマテリアルのマスクビットが格納されています。
大雑把な理解として,描画対象となるマテリアルの矩形範囲を決めているようです。
FullScreenVS()では,決定したマテリアルの矩形範囲にあるタイルで,本当にそのマテリアルの描画必要かどうかを判定して,要らないところはNaNを頂点シェーダで設定して,タイルをカリングするという処理を行うようです。タイルカリングには5つのモードがあるようです。
ストリーミングの仕組みは?
ストリーミングの管理はFStreamingManagerというクラスで管理されているようです。
Engine/Source/Runtime/Engine/Public/Rendering/NaniteStreamingManager.hにクラスの宣言があります。
・クラスタページデータ
・クラスタページヘッダ
・クラスタ修正更新バッファ
・ストリーミングリクエストバッファ
・ストリーミングリクエストリードバックバッファ
・ペンディングページ
・リクエストハッシュテーブル
などを保持しているようですが,まだ理解しきれていないので,理解できるようになったら別の記事として書くことにします。
ページリクエストは,PersistentClusterCull()というシェーダが実行されてRequestPageRange()という関数内でリクエストが書き込まれるようです。
このシェーダで書き込んだページリクエストの取得はディファードレンダラー内のAsyncUpdate()内でバッファをmapすることでCPU側で取得されるようです。
リクエストハッシュテーブルにGPUから取得したものを登録して,被るものがあるかどうかをチェック。チェックにヒットしたらストリーミングするページとしてプッシュし,優先度でソートして,LRUを更新しています。
一方,検索にヒットしない場合は,優先度付きリクエストヒープにいったんプッシュするようです。その後、このヒープからポップしてストリーミングするページを選択しています。
ストリーミングするものは読み込みされている状態なので,送ればいいのですが,これから読み込みしないといけないペンディング状態のものについては,ペンディング状態のページを収集し,ランタイムリソースIDがコンピュートシェーダで書き込まれるので,これを利用してFbyteBulkDataを取得するようです。取得したデータをFIORequestTaskに登録し,ParallelFor文を用いて,ファイルの非同期読み込みが実行さるようです。
ストリーミングマネージャのEndAsyncUpdate()という関数で,読み込み完了待ちをしてからResourceUplodTo()関数を使ってGPUに転送しているみたいです。
ストリーミングデータはどうやってつくるのか?
メッシュデータの構築
FStaticMeshBuilder::Build()経由でBuildNaniteFromHiResourceModel()が呼び出されて,データが作成されるようです。
BuildDAG(), ReduceDAG(), FindDAGCut()などの内部の処理がまだ全然理解できていないので,鋭意調査中です。
エンコード
ジオメトリデータはEncodeGeometryData()という関数でエンコードされるようです。
Positionデータは63bitに。
法線ベクトルはOctrahedronで表現し,XYで18bitに。
テクスチャ座標はXYで32bitに。
ここまで合計14byteになるので,確かにKarisが言っていた平均14.4Bという数字は納得できます。
ちなみに頂点カラーやUV数を増やす場合はさらにデータ容量が増えていく感じです。
おわりに
今回は,えらくざっくりですが,どんな感じで動くのかについて調査しました。
レンダリングフローについては理解できたのですが,実際のストリーミングの詳しい処理内容や,階層LODの作成方法など,まだまだわからない箇所もあるので次回調査してみたいと思います。
ピンバック: UE5 Nanite まとめ - Tech Branch