こんにちわ、前回に引き続き[Xie 2021]を読んでいきます。
Chapter 3: Heterogeneous Real-Time Rendering
すべての真理は、一度発見すれば容易に理解できるものである。
― Galileo Galilei
フォトリアリスティックレンダリングは、確率的サンプリングに大きく依存することで、知覚的なリアルさを実現しています。しかし、物理ベースのレンダリングをリアルタイムで行うことは、インコヒーレントキャッシュの要求が高く、大きな課題となっています。各インタラクションは、レンダリングに必要な複雑なマテリアルのサンプリングを引き起こします。さらに、現在の GPU アーキテクチャが持つ高い時間的・空間的コヒーレンスを前提としたアクセスには、必ずしも従いません。たとえば、画面空間でより物理的に正しい表面下散乱を行うには、現在の GPU アーキテクチャ設計に反して、放射輝度テクスチャを確率的にサンプリングする必要があります。一方、ピクセルごとに異なる表面下をどのようにブレンドすべきかを解決するために、ユーティリティテクスチャ(例えば、ピクセル表面下プロファイルや法線)に同じ確率的方法でアクセスする必要があり、キャッシュ非干渉性と帯域幅の要求をさらに誇張しています。
現代および次世代のハードウェアで高品質なリアルタイムレンダリングを実現するために、どのような新規かつスケーラブルな技術を用いることができるでしょうか。この研究課題をもとに、本論文では、新たな解決策を探っていきます。私たちは、キャッシュと帯域幅を考慮したアルゴリズムを開発し、限られた帯域幅とキャッシュ予算で最高のレンダリング品質を実現することに努めています。しかし、我々のアルゴリズムの設計を助け、潜在的なレンダリングに対する重要性を明確に示すために、文献で参照できる分類法はありません。このような動機から、我々はそのような分類法を開発します。フォトリアリスティックリアルタイムレンダリングにおける非干渉性の原因である、基本的なGPUキャッシュアーキテクチャとその帯域幅について概説します。そして、リアルタイムレンダリングにおける技術の分類学を作成し、その枠組みの中で我々の研究を紹介します。
3.1 GPU Cache
現在のGPUアーキテクチャ設計では、時間的・空間的なコヒーレンスを前提にしています。1) 空間的コヒーレンスとは、次に訪れるアドレスが、すでに埋まっているキャッシュライン内にある確率が高いことを示します。例えば、配列の要素は、連続してアクセスされれば、高い空間的コヒーレンスを持ちます。2) 時間的コヒーレンスは、最近訪問したコンテキストが再び訪問される可能性が高いことを示します。例えば、データの合計を格納する変数は、時間的コヒーレンスが高いです。この2つの仮定に従ったアルゴリズムの実装は、キャッシュヒット率を高め、帯域幅の小さいキャッシュへのトラフィックを減らし、性能向上に貢献します。
この設計前提に基づき、NVIDIA、AMD、Intelなどから、さまざまな効率的なメモリアーキテクチャが提案されています。すべてのGPUアーキテクチャの情報がオンラインで公開されているわけではありませんが、NVIDIA TuringとAMD RDNAの間で2つの類似したGPUキャッシュアーキテクチャを見つけることができます[Jia et al., 2019, NVIDIA, 2018, AMD, 2019]。
3.1.1 Simplified GPU Data Cache Architecture
現代のGPU(Volta V100、Turing T4 GPU、RX 5700 XTなど)には、基本的に4種類のデータキャッシュが存在します[Jia et al, 2019, NVIDIA, 2018, AMD, 2019]。また、図 3.1 では、各タイプの性能の参考として、公開されている帯域幅が示されています。
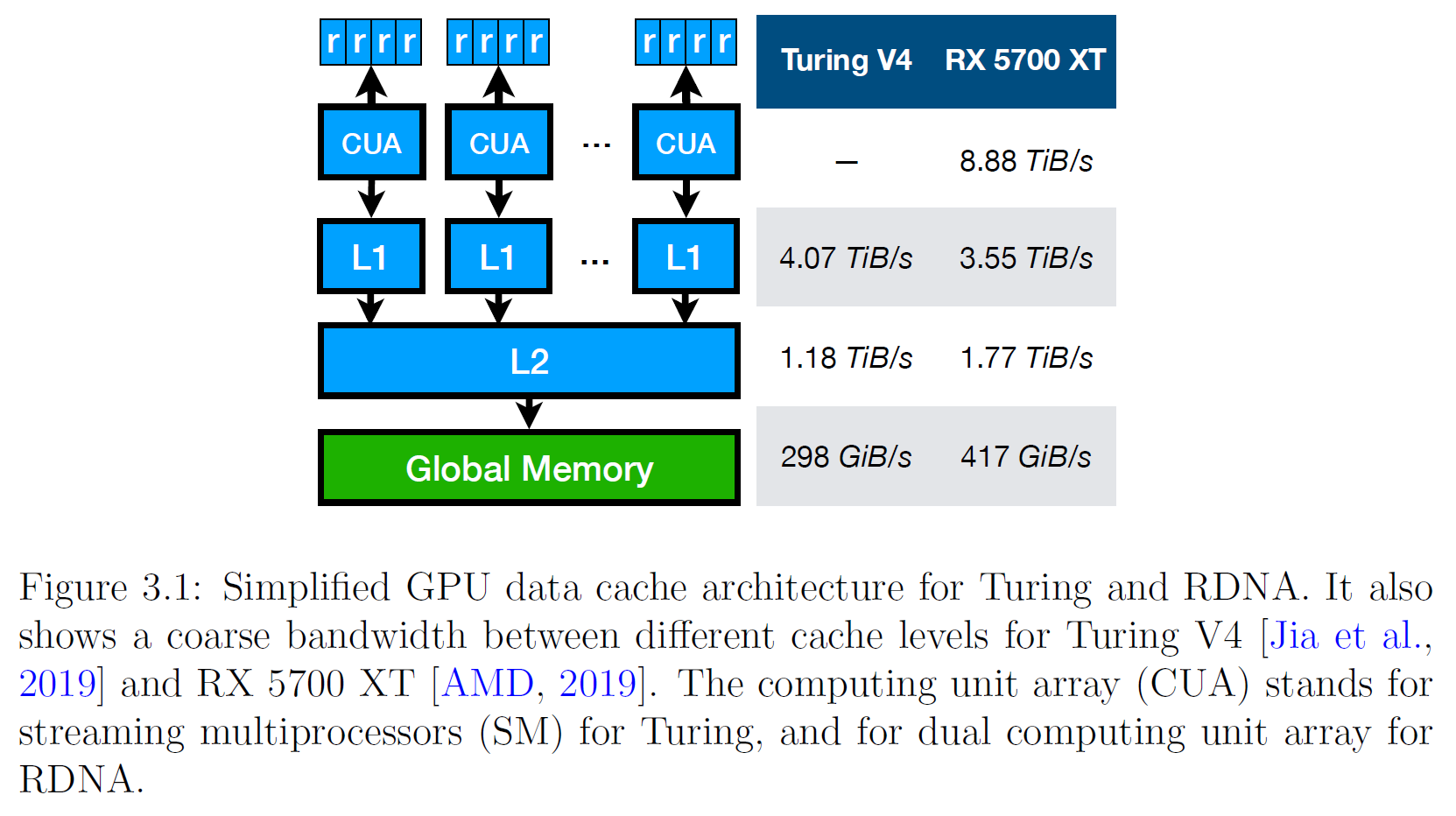
- L0/レジスタ. ストリーミングマルチプロセッサの4つの処理ブロックのそれぞれに対して、\(64 KiB\)の高速アクセスレジスタが存在します[Jia et al, 2019]。各デュアルコンピューティングユニットに対して、独立して動作する4つのSIMDが存在します。既知のキャッシュには、ベクトルおよびスカラーレジスタ、ローカルデータ共有(LDS)、2つの\(16 KiB\) L0ベクトル、および1つの\(16 KiB\) L0スカラーキャッシュがあります。これらは最も高い帯域幅を持っています。RDNAのホワイトペーパーでは、RX 5700 XTのL0キャッシュのバンド幅は8.88TiB/秒とされています。
- L1/共有データキャッシュ. TuringとVoltaアーキテクチャでは、L1データキャッシュと共有メモリを組み合わせて、ヒットレイテンシの短縮と帯域幅の改善を図っています。SMでは複数のスレッドで共有されます。しかし、スループットを最大化するために、異なるSM間でインコヒーレントになっています。Turing T4 GPUでは、ヒットレイテンシは32クロックで、負荷スループットは\(4.07 TiB/s\)でした。RDNAアーキテクチャでは、まず、\(128 KiB\)のL1キャッシュをデュアルコンピューティングユニットの各arrayに導入しました。L1バンド幅はRX 5700 XTで\(3.55 TiB/s/)となります。
- L2 データキャッシュ. L2データキャッシュはGPU内で統一され、コヒーレントになっています(命令メモリと定数メモリはTuring Architectureで同じ)。Turing T4 GPUでは、レイテンシが約188クロックサイクル、ロードスループットが\(1.18 GiB/s\)となっています。RX 5700 XTでは、\(1.77 TiB/s\)となります。
- グローバルメモリー. GPUに固有の大きなメモリチャンクです。グローバルメモリからフェッチされたデータは自動的に L1 と L2 にキャッシュされますが、GDDR6 メモリは、Turing T4 GPU の 296 \(GiB/s\) の理論バンド幅というハードリミットを生み出します。RX 5700 XT の帯域幅は 417 \(GiB/s\)と報告されています。
AMDは最近、RX 6800でL3キャッシュであるAMD Infinity Cacheをリリースし[AMD、2020]、グローバルメモリへの帯域幅の要求を低減しています。すべてのデータを L3 にキャッシュできたとしても、すべてのコンピューティング・ユニットからの要求の高いアクセスにより、異なるキャッシュ・レベル間でキャッシュの非干渉性が存在します。レンダリングタスクが帯域幅によって制限されている場合、対応するキャッシュおよび帯域幅を意識したレンダリングアルゴリズムは、データが低いキャッシュレベルに存在し、高いキャッシュレベルから帯域幅の要求をできる限り減らすように設計されています。これは、L0 の LDS のような異なるレジスタにデータを効率的に格納できるため、現在のほとんどのアルゴリズムで一般に達成可能です。しかし、ゲーム業界では、高ネイティブ解像度の要求が高まっており(例:1K から 4K)、一部のアルゴリズム(例:確率的サンプリングに基づく)では、高いキャッシュレベルへの帯域幅の要求が本質的に高くなっています。現在の帯域幅ではニーズを完全に満たすことができず、多くのキャッシュミスが発生しています。
3.1.2 Cache Miss Type
CPUでは、キャッシュはレイテンシーを減らすために設計されています。キャッシュミスの原因は、よく知られたモデルである\({\mathcal 3C}\)モデル [Hill and Smith, 1989]にまとめることができます:1)強制的なもの。初めてデータブロックにアクセスするため、キャッシュミスが発生するのはコールドスタートです。アーキテクチャ設計上、ブロックサイズを大きくすることで軽減できますが、キャッシュミスレートが増加するリスクがあります。2) 容量。キャッシュはすべてのデータブロックを格納できるほど大きくはありません。キャッシュサイズを大きくすることで解決できますが、アクセス時間が長くなるリスクがあります。また、ロードしたデータをより頻繁に再利用することで、例えば、離散データをシーケンシャルなデータブロックに前処理することで、解決できます。3)コンフリクト。限定的な連想または置換ポリシーにより、複数のメモリアドレスが同じキャッシュ位置にマッピングされます[Nugteren et al.、2014]。キャッシュサイズを大きくする、連想性を高める、置換ポリシーを改善することで緩和できますが、アクセス時間が増加するリスクがあります。
GPUも3Cモデルを考慮した設計になっています。ただし、GPUはレイテンシを減らすのではなく、オンチップメモリを利用して帯域制限のあるオフチップトラフィックを減らし、マルチスレッド化によって高いレイテンシを隠蔽する設計になっています[Nugteren et al., 2014]。GPU の並列能力をフルに引き出すには、オンチップメモリをフルに活用することが不可欠です。しかし,このアーキテクチャ設計は,偏ったサンプリングを妥協することなく,種類やサイズの異なる任意のレンダリングリソースにアクセスするピクセル単位のモンテカルロサンプリングによるフォトリアルなリアルタイムレンダリングには必ずしも有用ではありません.この隠蔽機構は、依然として帯域幅のボトルネックによって制限されることになります。
3.1.3 Source of Incoherence
現在のフォトリアリスティックレンダリング、特にオフラインレンダリングの中核はストキャスティックサンプリングであり、本質的にこのアーキテクチャ設計に則っていません。その支離滅裂さは、モンテカルロサンプリング、大きなデータ要素、レイ&パストレーシングに起因しています。
- フォトリアリスティックレンダリングでは、ある累積密度関数に基づくモンテカルロサンプリングにより、1ピクセルあたり多くのサンプルを必要とします。そのため、コンテンツの各アクセスは本質的に非干渉となります。アクセスされるコンテキストを効率的にオンチップに配置できない場合、性能上の障害となります。1 つの解決策は、ターゲットテクスチャの事前構築ミップマップ(たとえば、事前フィルタリングされた環境マップ [Krivanek and Colbert, 2008])を利用して、キャッシュヒット率を高めることです。
- しかし、シーンのマテリアルが複雑な細部を持つ場合、各インタラクションはミップマップチェーンを通過できない可能性のある大きなデータの塊にアクセスして評価しなければならず、特にSIMDアーキテクチャではキャッシュミスが増加する危険性があります。このデータには、ジオメトリ情報だけでなく、マテリアルやユーティリティバッファ、テクスチャのオーバーヘッドが含まれることがあります。
- また、近年リアルタイムレンダリングに導入されたレイトレーシングでは、1ピクセルあたり数本のレイが発射され、それぞれが任意の方向に数回バウンスして複雑なシーンになることがあります。
3.2 Framework
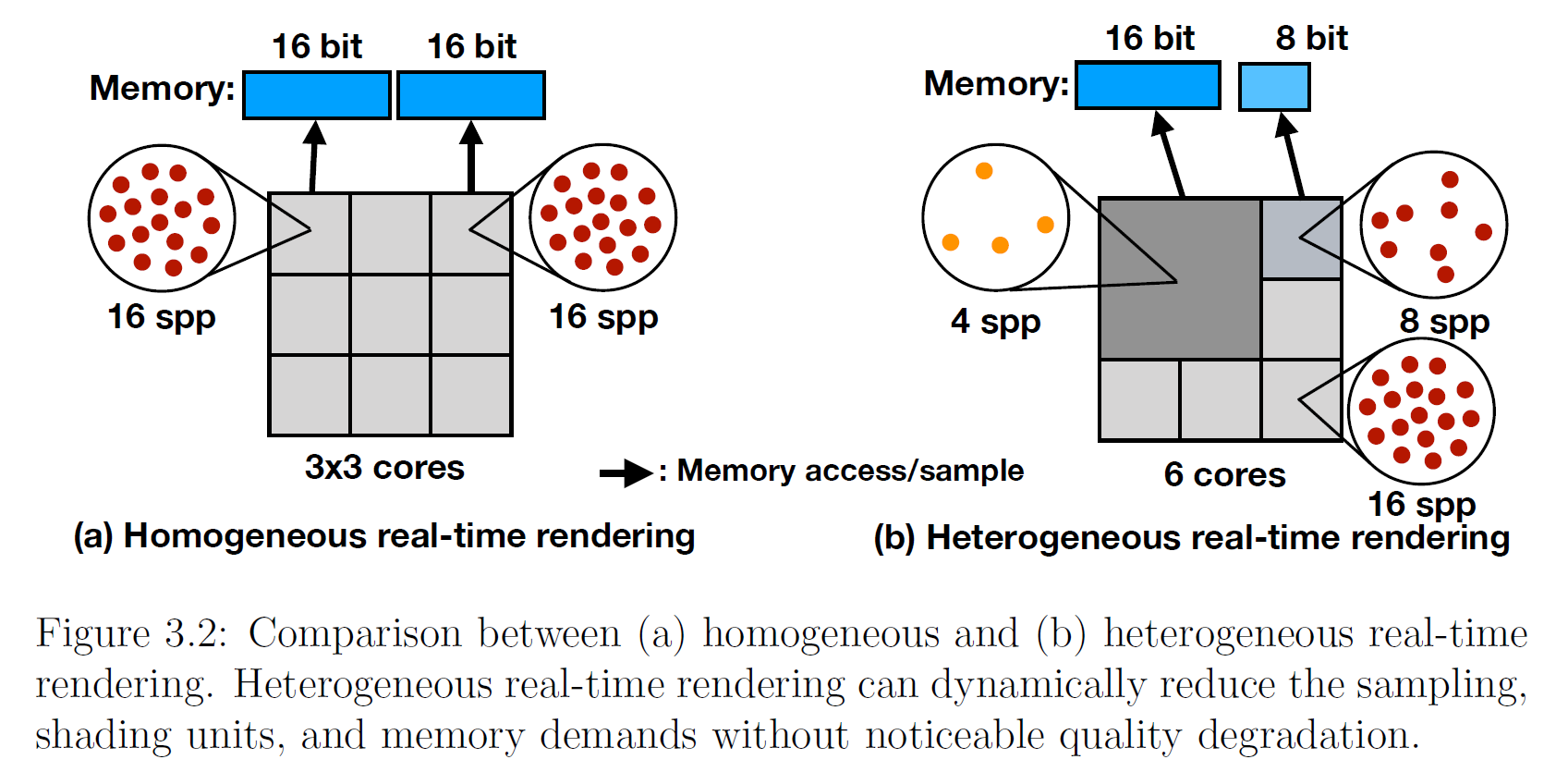
このメモリの非干渉性に対処する方法として、アーキテクチャやアルゴリズムレベルで様々な方法があります。本論文では、主にアルゴリズムレベルの手法に着目します。具体的には、アルゴリズムを分類し、アルゴリズム設計の指針とするために、既存のホモジニアス・リアルタイムレンダリングに代わるヘテロジニアス・リアルタイムレンダリングという新しい概念を提案しました。リアルタイムレンダリングの文献では、通常、レンダリングプロセスは、固定数のサンプルを単一または複数の固定数の出力に収集/散布するホモジニアスを仮定しています。計算がリソースの均質な使用とシェーディングを必要とする場合、オフチップトラフィックは重要な問題です。しかし、物理ベースのレンダリングで同じ品質を実現するためには、すべての出力に同じ数のリソースサンプルが必要なわけではありません。ヘテロジニアスサンプリングで十分です。さらに、隣接する結果は非常に似ているため、より少ない計算で十分な場合があります(例:可変レートシェーディング)。この観察は、観察された不均質性を探ることで、リアルタイムレンダリング研究に新たな機会と課題を生み出します。図3.2に、計算、サンプリング、メモリの要求から見た、ホモジニアスとヘテロジニアスのリアルタイムレンダリングの違いの一例を示します。なお、ここでは、CPU-GPU 間の帯域を扱う研究は除外し、GPU 内の帯域に着目しています。図 3.3 に、サブサーフェス散乱に関する分類法の概要と、この枠組 みにおける我々の新機能を示します。
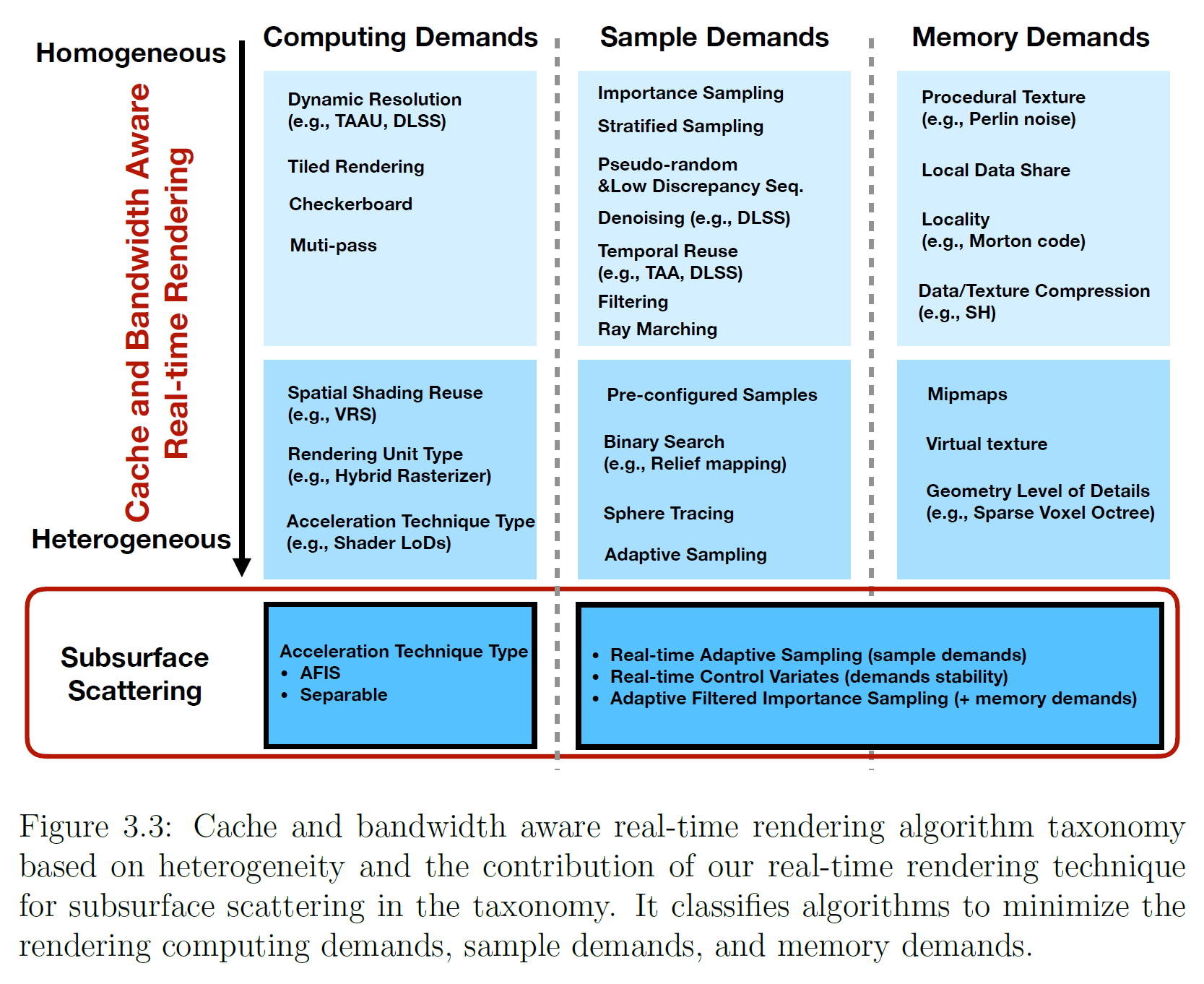
3.2.1 Heterogeneous Computing Demands
ホモジニアスレンダリングでは、すべてのコンピューティング/シェーディングユニットが同じタイプで、あるタスクに対して一様に使用されます。レンダリング効率を向上させる良い例が動的解像度であり、解像度とそれに対応する必要なユニット数を幅と高さで一様にスケーリングします。これは、一定のフレームタイムが最適化の目標である場合、多くのリアルタイムレンダリングエンジン(例えば、Unreal Engine [Engine, 2020] や Unity 3D [Unity, 2019] )やゲームに採用されています。その他、タイルレンダリング[Fuchs et al., 1989, Ribble, 2008]、チェッカーボード[Wihlidal, 2017]なども、同一フレームタイムでの演算ユニット数を減らすことで、帯域や演算能力、キャッシュの制限による失速を軽減する技術です。多くのGPGPUにおける基本的なデータ並列演算は、帯域幅に制限されるギャザーとスキャッター/スプラッターです。ランダムアクセスの低い局所性による性能劣化を緩和するために、Heら2[[7]はマルチパスを用いて、近い領域のデータの塊をそれぞれ一度に処理することで局所性の利用率を高めています。これは、基数ソート、ハッシュ化検索、スパース行列乗算などのアルゴリズムに対するキャッシュの有用性を高めるのに役立ちます。
異なるカテゴリーのシェーディングユニットを使用したり、組み合わせたり(例えば、計算および/またはレイトレーシング、ソフトウェアおよび/またはハードウェア)して、異質性を利用し、効率をさらに向上させることも可能です。例えば、数百万の小さな三角形のラスタライゼーションは、大きな三角形に最適なハードウェア対応物よりも、ソフトウェアベースのラスタライザでより効率的である可能性があります。この組み合わせは、より良い性能につながります [Battaglia, 2020]。レイトレーシングの結果は、ラスタライザユニットからのシェーディングバイアスを修正することができます[Marrs et al., 2018]。さらに,シェーダーレベルオブディテールのような異なるリアルタイムアクセラレーション技術の種類によって計算需要を減らすことができます[Olano et al.,2003]。異なるアクセラレーションアルゴリズムは、異なる条件下で異なるコンピューティングユニットのために呼び出されます。この論文では、このカテゴリの別の、サブサーフェス散乱のためのリアルタイムアクセラレーションに貢献します。セクション5.3.2において,表面下散乱は,分離可能な近似または我々の提案アルゴリズム適応的フィルタード重要度サンプリングのいずれかを用いて同じフレームで加速することができます.その種類はあらかじめ決めておくことも、オンザフライでカスタム処理することも可能です。
さらに、最近では、空間シェーディングの再利用も盛んになってきています。出力が高い確率で低頻度であると予測される場合、帯域幅と演算需要をさらに削減するために、複数の出力を作成するようにユニットを構成することができます。例としては,ソフトウェアとハードウェアのアダプティブ/可変レートシェーディング[He et al., 2014, NVIDIA, 2018, Drobot, 2020]と階層的なサブディビジョン戦略[Mallett and Yuksel, 2018]があります。アイトラッキングが可能なレンダリング、あるいはバーチャルリアリティ(VR)においては、非線形変換を使用して(例えば、カーネルフォベーテッドレンダリング[Mengら、2018])コンピューティングユニット密度を再分配することが可能です。
3.2.2. Heterogeneous Sample Demands
ホモジニアスレンダリングでは、与えられたアルゴリズムに対して、各計算ユニット内部ですべてのサンプルカウントが固定されます。リアルタイムレンダリングでは、固定サンプル数で品質を向上させる(または分散を減らす)ために、さまざまな技術が利用されてきました。例えば,重点サンプリング,層化サンプリング,擬似ランダム・低不一致シーケンス,ノイズ除去,可分・低ランク近似,フィルタリング,時間再利用(例えば,TAA[Karis, 2014] と DLSS[Liu, 2020] )があります。通常,これらの技術のいくつかのサブセットは,異なる実装のために異なって組み合わされます。リアルタイムレンダリングでは,分散を最小化できるのであれば,多少の偏りも許容される。例えば、レイマーチングアルゴリズムは、均一なボリュームトレーシングのために、各サンプルを均一に配置します。それはゼロ分散に収束しますが,バイアスがあります[Novak et al., 2014]。SVGF [Schied et al., 2017]は、空間的および時間的フィルタリングを適用して、1サンプル/ピクセル(spp)ノイジーなパストレーシング結果をデノイズします。
効率化のために異質性を持たせる方法として広く採用されているのが、経路やマテリアルごとに異なるサンプル数構成にすることです。そして、品質や性能のバランスを考慮して、ユーザーや開発者が設定することができます。研究者たちは,スフィアトレーシング [Bastos and Celes, 2008],レリーフマッピングにおけるバイナリサーチ [Policarpo et al., 2005],リアルタイムレンダリングにおける適応サンプリング技術などの数値探索加速技術で異質性を追求しようと試みてきました。例えば、符号付き距離場(SDF)トレーシングは、次のレイの交点を決定するためにSDFを使用し、均一レイマーチングよりも少ない交点評価しか必要としません。適応型サンプリングは,局所勾配及び/又は近傍領域に基づく分散メトリックを用いて,コンピューティングユニットあたりのサンプル数を決定しようとします[Boksansky et al.,2019]。それらの方法は,分散が局所的に束縛されている場合(例えば,アンチエイリアシング),効率的に実行されます。しかし,それらの領域にアクセスすることは,より多くの領域を必要とする場合,ピクセルあたりのメモリ要求を増加させる可能性があります。さらに、近隣のピクセルを相関させるという利害関係で分散を減らします。
3.2.3 Heterogeneous Memory Demands
ホモジニアスレンダリングのために、各メモリ要求は同じ大きさのテクセルまたはバッファにアクセスします。データは、レジスタの帯域幅の制限、ローカルデータの共有、または局所性の高いアクセスパターンを持つキャッシュレベル(例えば、モートンコード[Lauterbachら、2009、NocentinoとRhodes、2010]、およびレイソーティング[Meisterら、2020、Kellerら、2019])によるストールの数を減らすためにキャッシュすることが好ましいです。異なるフォーマットは、転送されるバイト数が最小になるように、その場で圧縮または解凍(ソフトウェアまたはハードウェアベースのいずれか)します。実際には,拡散放射照度は,最初の9つの球面調和関数係数[Ramamoorthi and Hanraha, 2001]またはコーントレーシング[Crassin et al., 2011]のためのアンビエントオクルージョンのモデル化に当初使用されたコーン表現[Zeng et al.] 帯域幅を減少させる代替的な方法は、計算機需要の増加の代償として、各アクセスをその場で直接評価することができる手続き的手法を用いることです(例えば、Perlein noise [Perlin, 1985] )。しばしば、帯域幅と計算能力のバランスをとるために、それらの技術を組み合わせて使用します。さらに、アクセスパターン(モートンコード)により、帯域幅の要求を減らすことも可能です。
物理的に測定された大きなテクスチャを避けることができず、出力面が大きい場合(例えば、4K解像度)、ミップマップ [Williams, 1983] を使用することができ、ほとんどのデータアクセスが高レベルの詳細データに向けられる場合、小さいメモリ要求は、例えば、レジスタやGPUキャッシュに格納することができます。これらは、詳細レベルを決定するための正確な方法を必要とします。Mipmap の詳細レベルは、テクスチャサンプリングのための局所微分に基づいています。重点サンプリングのような、より複雑な使用法では、サンプリング密度を使用することができます。Virtual texture [Mittring and GmbH, 2008] はさらに大きなテクスチャをサポートするために、仮想メモリのアイデアを持ち込みました。適応型符号付き距離場[Frisken et al., 200]、スパースボクセルオクツリー[Kampe et al., 2013]、GVDB[Hoetzlein, 2016]、およびSSVDAG[Villanueva et al., 2016]などを含む、シーンの帯域幅要求を減らすために異なる詳細なジオメトリレベルも使用することが可能です。
3.3 Formulation
キャッシュと帯域を意識したリアルタイムレンダリングのための記述的な帯域要求アルゴリズムを提案する。計算需要については、与えられたレンダリングタスクの総帯域幅需要を以下のようにモデル化します。
\begin{eqnarray}
T(n) &=& k T’_k (n/k) + O(n) \tag{3.1} \\
T'(n) &=& \sum_{i=1}^n \sum_{a \in {\mathcal A}, r \in {\mathcal R}} w_{i, a, r} S_{i, a, r} + O(n) \tag{3.2}
\end{eqnarray}
ここで、\(n\)は最終的なレンダリングピクセル数、\(k\)はパス数、\({\mathcal A}\)はテクニックセット、\(R\)はレンダリングユニットタイプ、\(S\)はサンプル要求、\(w\)は計算要求の重みを示します。式3.1は、\(k\) パスの帯域幅需要に、ピクセルごとの追加帯域幅を加えたものです。式3.2は、各ピクセル/技術/計算ユニットの計算要求重みとサンプル数の、使用ピクセル、パス技術、計算ユニットの種類に関する合計であり、さらにピクセルあたりの帯域幅を追加したものです。例えば、可変レートシェーディングでは、\(2 \times 2\)ピクセルが同じ演算ユニット出力を共有する場合、\(w_{i, a, r}=0.25\)となります。動的解像度やチェッカーボードレンダリングでは一定の重みとなります。この帯域幅需要関数は、実際のバイト数ではなく、コスト関数であることに注意してください。
与えられたサンプルカウントバジェット\(m\)に対応する帯域幅の需要は次のとおりです。
\begin{eqnarray}
S(m) &=& sum_{j=1}^{m’} M(d_j) + O(m’) \tag{3.3} \\
m’ &=& f(m, \sigma^2_0), \quad m’ \leq m \tag{3.4}
\end{eqnarray}
ここで、\(m\)はサンプルバジェット、\(m’\)はある分散基準\(\sigma^2_0\)を適応的または事前に満たそうとするテクニック関数\(f\)から得られる対応する演算ユニットに実際に使用されるサンプル数です。この技法関数は、図3.3に示すような様々な選択技法に基づいて、必要なサンプル数を減らし、サンプル要求を最小にしようとするものです。通常、この関数は自動的に決定されるのではなく、アルゴリズム設計者が手動で実験して決定します。\(d\)は各サンプルの生のメモリ需要で、\(M\)は特定のメモリ需要削減技術\(R\)を用いた場合の実際のメモリ需要です。
\begin{eqnarray}
M(d) = R(d) + O(d) \tag{3.5}
\end{eqnarray}
この定式化により、各提案アルゴリズムが総帯域幅需要の最小化にどの程度役立つかを推論するための良いスタート地点が得られます。たとえば、DLSS は動的解像度を使用して、式 3.2 の計算要求重み \(w_{i, a, r}\) を最小にします。また、サンプルの要求を最小化するために、式.3.4の時間履歴とディープラーニングによるノイズ除去を再利用し、\(m’\)を低く抑えます。推論中、重みは一定であるため、効率的にキャッシュすることができます。テンソルコアを用いて推論ステップを高速化することで、ボトルネックが演算装置でないことを保証しています。ここから、DLSSはメモリ需要最小化のための革新的な技術を提供しないことがわかります。
この論文では、サンプル要求の最小化に関する研究が主な内容となっています。我々はまず第4章において、与えられた分散\(\sigma^2_0\)に基づいて\(m’\)をその場で最小化する、式3.4に対する新しい統計的に最適なリアルタイム適応型サンプリング技術を紹介します。第6章では、時間分散を用いて演算ユニットあたりのサンプル数を推定しているため、動的照明による時間的不安定性の問題を解決しています。これらは、サンプル要求を最小化するための基礎となるため、一貫して総帯域幅の要求を減らすことができます。これらの2つの章で紹介した技術は汎用的なものであり、モンテカルロサンプリングをリアルタイムレンダリングで使用する際の性能を向上させるために、他のレンダリングタスクにも使用することができます。第5章では、一般的な同種のサンプル需要最小化技法(重要度サンプリングと低不一致シーケンス)を紹介します。また,直接散乱のため過剰に減衰されるため遠く離れた散乱の分散をトラックするために遠方の表面下散乱からディフューズを分離します。
5.2節では、ミップマップを利用したAdaptive Filtered Important Sampling (AFIS) という手法を提案し、メモリ使用量の最小化を図っています。この手法は、既存の手法[Krivanek and Colbert, 2008]とは異なるものです。我々のアルゴリズムでは、全ユニットに対して一定のサンプル数ではなく、ユニットごとに変化する\(m’\)を計算することにより、MIPレベルに影響を与えます。
要求の最小化を計算するために、我々は5節で表面下散乱に関する2つの異なる技術を組み合わせることを提案しました。分離可能な近似はサンプル数と帯域幅の需要が一定であるのに対し、AFISは一部の領域が低分散の滑らかな画像を生成するために少数のサンプルしか必要としないという仮定に基づいて帯域幅を最小化するためです。どこでも高周波の照明の場合、分散は目に見えるものの、分離可能な近似の方がまだ良い性能を発揮します。
3.4 Summary
本章では、均質性から不均質性までの帯域幅問題に対処するために使用される、キャッシュと帯域幅を考慮したリアルタイムレンダリング技術の分類学を紹介しました。また、アルゴリズムレベルで帯域幅をモデル化するための記述的アルゴリズムを提案しました。我々は、分類学と性能モデルを通じて、新しいレンダリング技術を分析します。
Chapter 4: Real-time Adaptive Sampling
目の前のことをやり終える前に,冒険的企てを計画してはいけない。
― Euripides
リアルタイムレンダリングにおいて、物理的に正しいシェーディング結果を得るためには、フレームごとにピクセル単位でリアルタイムにモンテカルロサンプリングする必要があり、その実現は困難と思われます。オフラインレンダリングでは、アダプティブサンプリングでは領域によってサンプル数の要求が不均一になることが既に確認されているため、時間分散に基づくリアルタイムアダプティブサンプリング手法を提案し、サンプル数の要求量を下げることを提案します。
特に本章では、動きや照明によるシーンの変化に適応できる不偏の一段階適応型サンプリングパスを提案します。さらに品質を向上させるために、最終的な時間的蓄積フェーズの前に、ガイドパスによる時間的再利用を検討します。図4.1は、このガイディングパスに基づくサンプル数を可視化したものです。我々のローカルガイドパスは、グローバルな時間的蓄積の実装を制約しないので、時間的アンチエイリアシング(TAA)やディープラーニングサッパーサンプリング(DLSS)のような深層学習ベースのアルゴリズムなど、異なる時間的蓄積アルゴリズムをサポートすることができます。さらに、フレーム間で渡すテクスチャを1つだけ追加する必要があります。私たちが提案する分散誘導型アルゴリズムは、ストキャスティックサンプリングアルゴリズムをリアルタイムレンダリングに有効なものにする可能性を持っています。この章は、私たちのI3Dカンファレンス(PACMCGIT)publication[Xie et al., 2020]から拡張されたものです。

4.1 Introduction
古典的な適応サンプリングアルゴリズムは、2つのフェーズから構成される。通常、最初のフェーズでは、分散を決定するためにサンプルが集められ、その後、バイアスを避けるために捨てられます。第二段階では、分散を減らすために適応的なサンプル数が使用されます。しかし、サンプル廃棄のためにリアルタイムアプリケーションには非効率的であり、第一段階のサンプル数が少ないためにノイズが発生する可能性があります。最近の研究では、2つのサンプルセットを多重点サンプリング問題として提起することで、すべてのサンプルを使用しようとしています[Gittmann et al.,2019]。本章では、個々のサンプルを利用する表面下散乱のための単一の適応的サンプリングガイドパスとする。具体的には、各フレームにおけるサンプル分散を、指数移動分散に基づいて時間的バッファに連続的に更新します。時間的再利用により、各フレームにおけるこの分散は、前の隣接するフレームにおける画素の状態を反映します。これにより、リアルタイム確率的サンプリングのための可視ノイズのない次のフレームのサンプルカウントを制御することができます。
リアルタイムレンダリングではフレームあたりのサンプル数が多すぎて困るので、最近1サンプル/ピクセルパストレーシングの品質向上のために検討されている時間的再利用を模索します[Schied et al.,2017]。しかし、この研究は、既存のレンダリングエンジンにうまく適合しない、既存の時間的再利用アルゴリズムを変更します。我々は,Temporary Anti-Aliasing(TAA)のような既存の時間的再利用パスがあることを仮定し,しかしその時間的再利用パスの実装については仮定せず,時間情報を利用しゴースト,ブラーリング,ラグ,フリッカーなどのアーティファクトを解決しようとする限り,表面下散乱を導くためのパスを追加して異なるアプローチを模索します。
4.2 Basic Metrics
最小限のサンプル数を推定するためには、知覚可能なノイズが多いときはサンプル数を増やし、少ないサンプル数で十分なときは減らすという適応的な指標が必要です。
最小限のサンプル数を推定します。
\begin{eqnarray}
n_{(i)} = {\rm max}( \sigma^2_{M_{(i-1)}} \cdot n_{(i-1)} / \sigma^2_0, \beta_{(i-1)}) \tag{4.1}
\end{eqnarray}
ここで、\(n_{(i-1)}\)は前のフレームで推定された最小サンプル数、\(\sigma^2_{M_{(i-1)}}\)は前のフレームで推定された分布平均のピクセル分散です。この式の目的は、分布平均の分散を目標レベル\(\sigma^2_0\)まで減少させることです。照明の関係や、サンプル数が少なすぎると細部を見逃す可能性があるという変化から、常に少なくとも\(\beta_{(i-1)}\)個のサンプルを使用します。
モーションやライティングの状態により、ピクセルごとの正確な分布はわかりませんが、中心極限定理により、有限の平均と分散の母集団が与えられると、平均\(\mu_M\)のサンプリング分布は、元の分布の形状にかかわらず、サンプルサイズが大きくなると、\((\mu, \sigma^2/N)\)の正規分布となります。したがって、フレーム間で繰り返しサンプリングされる分布として、平均の分散を推定することができます。
このアルゴリズムを使用して、2つのフェーズで最小限のサンプル数を決定することは、まだ非効率的です(つまり、最初のパスで、分散を収集するためにサンプルを収集し、2番目のパスでレンダリングのためのサンプル数を推定します)。そこで、TAAから時間的蓄積の考え方を採用し、1フレームあたりのサンプル数を減らし、1パス適応型サンプリング手法とします。
4.3 Temporal Anti-aliasing
Temporal anti-aliasing (TAA) [Karis, 2014] は、リアルタイムレンダリングエンジンにおけるアンチエイリアシングのデファクトスタンダードです。これは、ジッタリングされたピクセルごとに色空間の連続したフレームを蓄積するために、指数移動平均で時間にわたってサンプリングを償却します。オブジェクトが移動するとき,TAAは蓄積された履歴バッファからのサンプルをピクセルごとの速度ベクトルに沿って投影します。それを以下のようにまとめます。
\begin{eqnarray}
\mu_i = (1 – \alpha) {\mathcal C}(x_i, \Lambda) + \alpha {\mathcal S}(p_i); \quad \alpha = {\mathcal M}(\alpha_0, \Lambda); \quad p_i = {\mathcal N}(x_i, f(i)) \tag{4.2}
\end{eqnarray}
ここで、\(\mu_i\)はフレーム\(i\)のピクセル\(x_i \in {\mathbf R}^2\)における推定値です。\(\alpha\)は、クランプされた履歴コンテキスト項\({\mathcal C}\)と現在のフレームのシェーディング項\({\mathcal S}\)との間の指数関数的重みです。\(\alpha\)は、ユーザ定義の最大重み\(\alpha_0\)および速度、ジオメトリタイプ(例えば、透明か否か)、隣接などを含むコンテキスト\(\Lambda\)に基づいて重み更新関数\({\mathcal M}\)によって計算されたピクセルごとの指数関数的移動平均の重みです。\({\mathcal C}\) は、\(x_i\) から投影された履歴を再サンプリングして棄却する演算子です。\({\mathcal C}\)と\({\mathcal M}\)の両方は,アンチエイリアシングの結果を維持しながら,アーティファクト(すなわち,ゴースト,ブラーリング,ラグ,フリッカー)を最小限に抑えるように設計されています[Karis,2014,Yangら,2009]。
\({\mathcal S}\)は\(p_i\)におけるシェーディング関数で、\(p_i\)はピクセル位置\(x_i\)とフィルタカーネル重点サンプリングオフセット\(f\)から近傍サンプリング関数\({\mathcal N}\)によって計算されたジッターされたピクセル位置です。
複数フレームに渡るMC結果を蓄積するために使用する場合、\({\mathcal C}\)と\({\mathcal M}\)が行うクランプとリジェクトは、MCプロセスを明示的に考慮するように修正するか、\({\mathcal S}\)に入ってくる分散をリジェクトモデルに合うように減らす必要があります。最近のゲームエンジンでは、TAAは、光沢反射、アンビエントオクルージョン、シャドウイング、および表面下散乱を含む多くのMCプロセスからサンプルを蓄積するために使用されています。TAAによって実行される複数のタイプの蓄積を考慮すると、単独で使用されるMCメソッドに対してクランピングおよび棄却モデルを修正する方法は効果的ではありません。本章では、既存のTAA処理に手を加えることはしません。その代わりに、式4.2から始まる1つの局所的な分散誘導フェーズを作成し、フレームごとにピクセルごとの適応的なサンプリングカウントを出力させます。サンプリング結果は標準的なポストプロセスパイプラインに送られ、既存のTAAを使用してさらに品質を向上させます。
4.4 Metrics within Temporal Accumulation
各フレームのサンプル数を減らすために、分散とサンプル数の推定をローカルフェーズで行います。式4.2を用いて、ジッタリングされたピクセル値に対して指数移動平均(EMA)を計算します。\(\alpha\)が十分に小さい場合、最終的に母平均である\(\mu_M = \mu\)に収束します[Karis, 2014]。3チャンネル全てを記録するのではなく、人間の知覚を考慮し、ガンマ補正された輝度の移動平均を記録します。フレーム\(i\)のサンプル数\(n_{(i)}\)を知ることで、平均サンプル数\({\bar n}_{(i)}\)を次のように推定します。
\begin{eqnarray}
{\bar n}_{(i)} = (1 – \alpha) {\bar n}_{(i-1)} + \alpha n_{(i)} \tag{4.3}
\end{eqnarray}
とし、母分散 \(\sigma^2\) を指数移動分散 (EMV) [Finch, 2009] とします。
\begin{eqnarray}
\sigma^2_i = (1 – \alpha) \sigma^2_{i-1} + \alpha (1 – \alpha) ({\mathcal S}(p_i) – {\mathcal C}(x_i, \Lambda))^2 \tag{4.4}
\end{eqnarray}
このようにして、サンプルカウントを蓄積し、式4.1を解くことができます。ここで、\(\beta_{(i-1)}\) は無視する。\(n_{(i)}\) を取得した後に設定すればよいです。連続した \(k\) フレームが蓄積されると、式は次のようになります。
\begin{eqnarray}
\sum_{i-k+1}^i n_{(j)} = \frac{ \sigma^2_{M_{(i-1)}} \sum_{i-k+1}^i n_{(j-1)} }{ \sigma^2_0 } \tag{4.5}
\end{eqnarray}
現在のフレームのサンプル数の推定値は
\begin{eqnarray}
{\hat n}_{(i)} &=& \sum_{i-k+1}^i n_{(j)} – \sum_{i-k+1}^i n_{(j-1)} + n_{(i-k)} \tag{4.6} \\
& \approx & \frac{ (\sigma^2_{M_{(i-1)}} – \sigma^2_0 ) }{ \sigma^2_0} \cdot {\bar n}_{(i-1)} \cdot k + {\bar n}_{(i-1)} \tag{4.7} \\
&=& \frac{ (\sigma^2_{M_{(i-1)}} – \sigma^2_0) }{ \sigma^2_0 } \cdot {\bar n}_{(i-1)} \cdot (k-1) + E[{\bar n}_{(i)}] \tag{4.8}
\end{eqnarray}
EMAやEMVを使用しているため、\(n_{(i-k)}\)を維持できないので、\(n_{(i-1)}\)で近似しています。そして、金融データの分析で一般的な\(N\)-day EMAと単純移動平均の変換に基づいて、\(k\)を\(k=2/\alpha-1\)と推定します[Bauer and Dahlquist, 1998]。4.8式は4.5式から導かれるフレーム\(i\) における標本平均の期待値\(E[{\bar n}_{(i)}] = \sigma^2_{M_{(i-1)}} / \sigma^2_0 \cdot {\bar n}_{(i-1)}\) に補正項を加えたものです。\(|\sigma^2_{M_{(i-1)}} – \sigma^2_0|\)が大きい場合、この補正項は非常に大きくなり、1フレームで目標レベルまで積極的に分散を減らすことができます。そこで、フレーム単位の補正を制限するために制御係数\(\kappa\)を追加します。そうすると,式4.8をもとにした最終式は
\begin{eqnarray}
{\hat n}_{(i)} &=& \kappa \cdot \Delta (i) + E[{\bar n}_{(i)}], \kappa \in [0, 1] \tag{4.9} \\
\Delta (i) &=& \frac{ (\sigma^2_{M_{(i-1)}} – \sigma^2_0) }{ \sigma^2_0 } \cdot {\bar n}_{(i-1)} \cdot (k-1) \tag{4.10}
\end{eqnarray}
ここで、\(\Delta(i)\)は補正項である。\(\kappa=1\)では、フレームあたりの最大サンプルバジェットまで発射する代償として、より速い収束を優先し、\(\kappa=0\)では、十分なサンプルを蓄積するために時間を使用します。
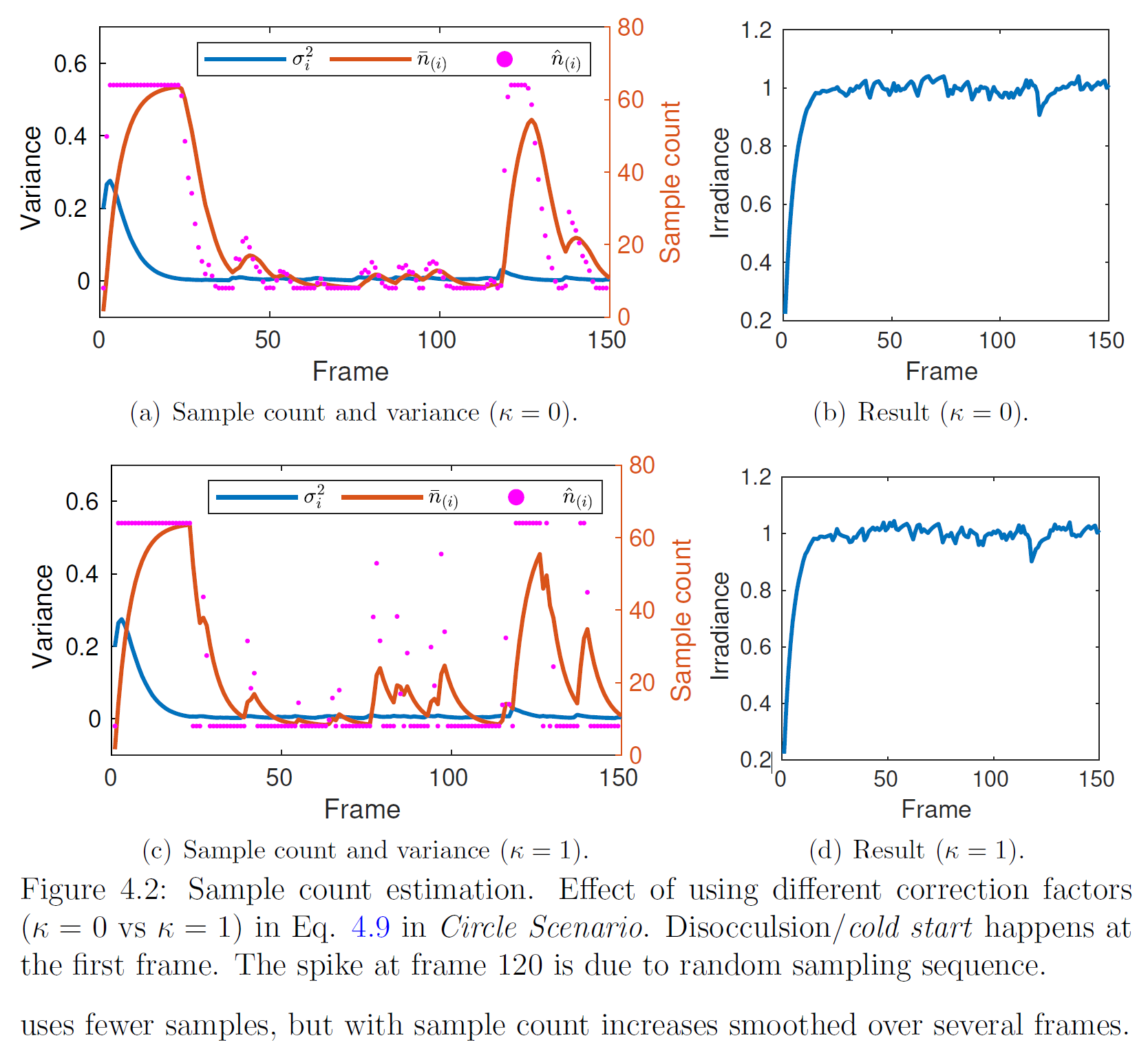
4.4.1 Circle Scenario
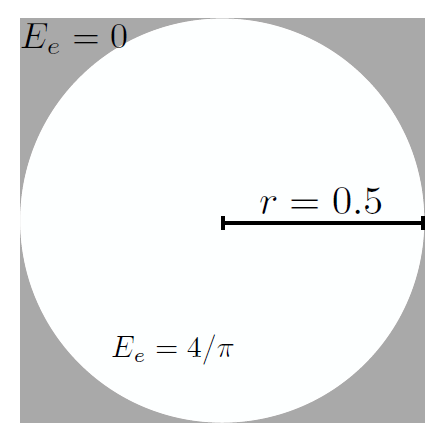
この推定を理解するために、簡略化した表面下散乱シナリオを作成します。ここでは、表面下散乱シナリオのモデルを単純化し、(.5, .5)を中心とする半径0.5の円内の均一な放射照度をサンプリングすることにします。Burleyの表面下散乱モデルを使用する代わりに)一様な2D乱数\(\eta_1, \eta_2) \in [0, 1)^2\)でサンプリングします。累積放射照度は円内では\(4/\pi\)、円外では0となります。サンプルバジェットとして\(b_{\rm min} = 8 \)sppと\(b_{\rm max} = 64\)sppを与え、\(\alpha = 0.2\)を使用し、目標品質レベル\(\sigma^2_0 = 0.08^2\)を設定します。この履歴タプル\({\mathcal H}_i = ({\bar n}_{(i)}, \mu_i, \sigma^2_i)\)は0に初期化されます。図4.2.は\(\kappa=0\)と\(\kappa=1\)の場合の150フレームにわたるサンプル数,分散,散乱の結果です。図4.2(a)と図4.2(c)の\({\hat n}_{(i)}\)は、\(\kappa\)が各フレームで使用される実際のサンプルにどのような影響を与えるかを示しています。\(\kappa=1\)の場合はサンプル数のピークが高く、通常1フレームで終わるのに対し、\(\kappa=0\)の場合はサンプル数は少ないですが、サンプル数の増加は数フレームに渡って平滑化されます。
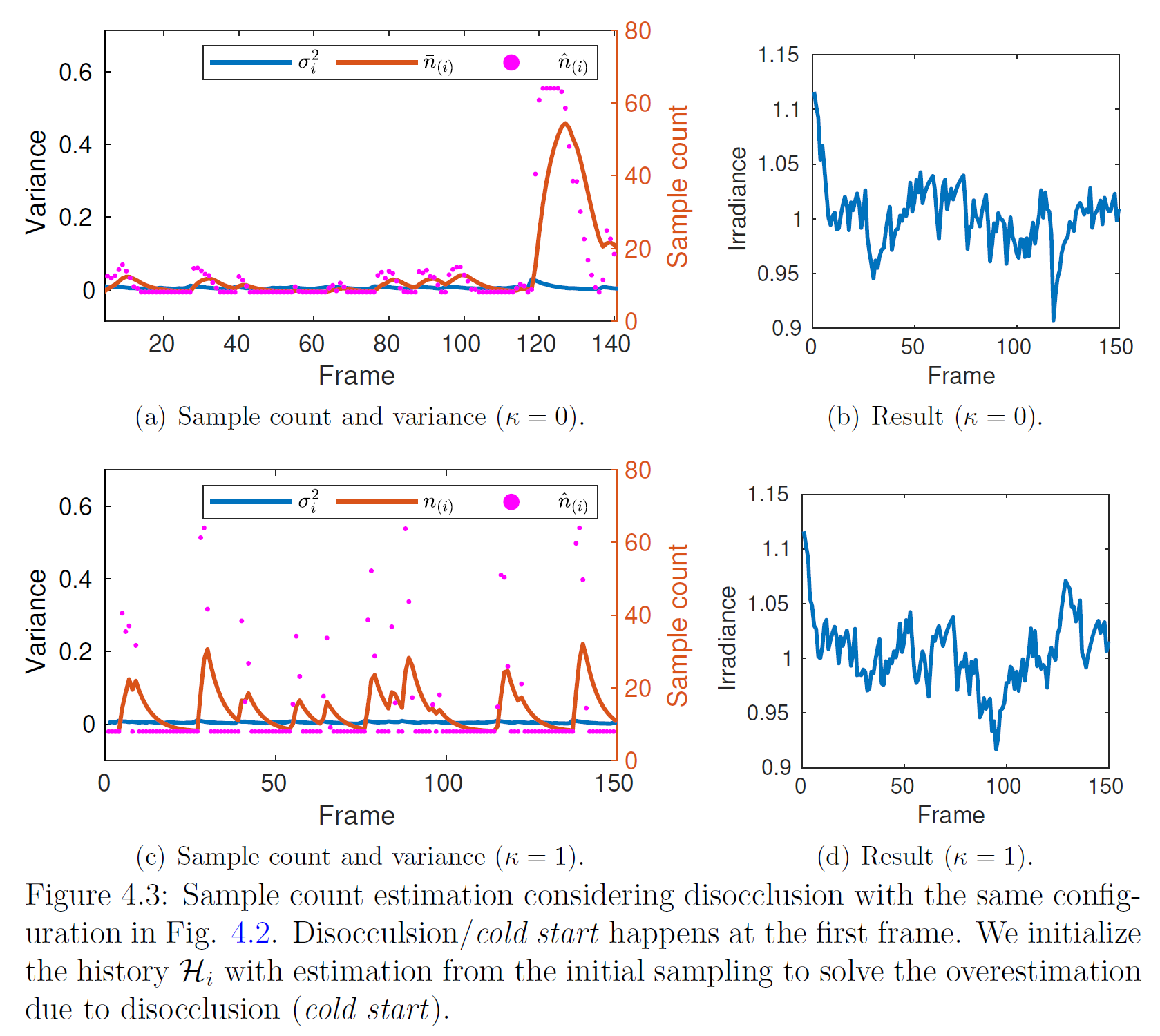
4.4.2 Disocclusion
図 4.2.は,一般的なレンダリングシナリオではまれなコールドスタート時のフレームあたりのサンプル数です。履歴データの欠落がより一般的なケースは、オブジェクトの以前は隠されていた部分が見えるようになるディスオクルージョンです。ディスオクルージョンが発生したときの初期履歴を推定すします。
\({\mathcal C}_s(\cdot)\)を、サブサーフェイスマスク履歴に拒否反応を示さないポイントサンプリング演算子とします。前フレームでサブサーフェスマスク履歴がない場合は\({\mathcal C}_s(x_i, \Lambda)=0\)とします。このとき、新しい\({\mathcal M}\)は
\begin{eqnarray}
{\mathcal M}'(\alpha_0, \Lambda) = \begin{cases} 1 & {\mathcal C}_s(x_i, \Lambda) = 0 \\ \alpha_0 & {\rm otherwise} \end{cases} \tag{4.11}
\end{eqnarray}
となります。この演算子により、初期サンプル数を\(n_{(i)} = {\rm max}({\hat n}_{(i)}, \beta_{(i-1)})\)として、初期サンプル値を\({\mathcal S}(p_i)\)と推定することができます。分散の履歴がないので、分散を次のように推定します。
\begin{eqnarray}
{\hat \sigma}^2_i (\alpha_0, \Lambda) = \begin{cases} \sigma^2_0 & {\mathcal C}_s(x_i, \Lambda) = 0 \\ \sigma^2_i & {\rm otherwise} \end{cases} \tag{4.12}
\end{eqnarray}
図4.3は、サークルシナリオと同じ構成で、更新された重み関数\({\mathcal M}\)と分散推定がどのように働くかを示したものです。初期のサンプル数の多さは解消されています。
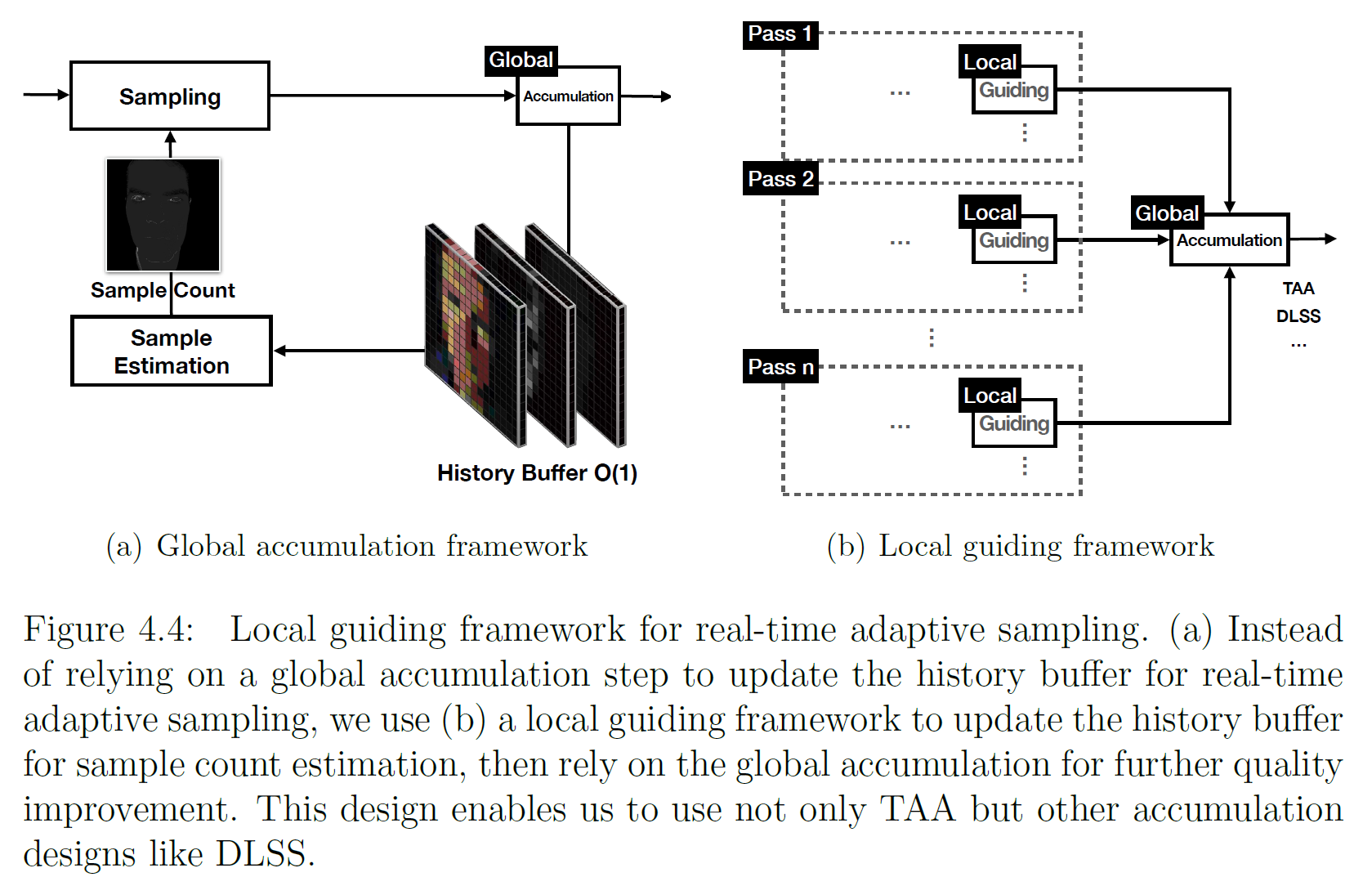
4.5 Local Guiding Integration
現在の適応型サンプリング・アーキテクチャを図4.4(a)に示します。これは、履歴バッファを更新するために、グローバルな時間的蓄積パス(TAA)に依存しています。この設計では、既存のグローバルな時間的蓄積パスに依存することになり、これには欠点があります。また、履歴を出力するために、大域的な時間的蓄積の修正が必要です。第二に、ガイドパスがオーバーレイ透明度のような他のパスの影響を受ける可能性があります。最後に、グローバルな時間的蓄積のパラメータセットは、単一のパスではなく、全体の品質を向上させるように設計される可能性があります。
この問題を解決するために、図4.4(b)に適応サンプリングのためのローカルパスガイドを提案します。これをSPVG(Single Pass Variance Guiding)と名付けます。この設計では、グローバルな時間的蓄積を切り離します。この設計では、グローバルな時間的蓄積の修正が不要であり、カスタムなローカル品質制御が可能であり、グローバル蓄積パスへのより良い品質入力が得られる可能性があります。この設計により、グローバルTAAだけでなく、他の時間的蓄積アルゴリズムも検討することができます。1つの有望な方向性は、蓄積にDeep Learningを使用することです。また、あるタスク(例えば、表面下散乱)に的を絞らず、ある程度の蓄積を行うように設計されたDLSSでさえも、役に立つことが分かっています。
4.5.1 Global TAA
前節では、ローカルTAAとグローバルTAAが同じ構成(\({\mathcal C}_l = {\mathcal C}_g\),\({\mathcal S}_l = {\mathcal S}_g\), \(\Lambda_l = \Lambda_g\),\({\mathcal M}_l = {\mathcal M}_g\)そして\({\mathcal M}_l(\alpha_0, \Lambda_l) = \alpha_0\))を使うという仮定で、分散ガイドサンプリングがグローバルTAA品質をガイドするように、各フレームのサンプルカウントを推定しました。しかし、リアルタイムレンダリングエンジンでは、これは保証されません。TAA のウェイトと関数は、主に表面下散乱以外のアーティファクト用にチューニングされています。さらに,同じ表面下散乱ピクセルが,オーバーレイされた透明なオブジェクトのような他の寄与を持つ可能性があります。
グローバルなTAAを前提としない表面下散乱の一般的な手法とするために、サブサーフェイスの品質に関する下限をターゲットにして、全体のTAA品質を向上させることを選択しました。\(\gamma = ({\mathcal C},{\mathcal M}, {\mathcal N})\)を空間\(\Gamma, \gamma in \Gamma\)の解とすると、あるピクセルのフレーム \(i\) における任意のコンテキスト \(\Lambda_i\) の分散は \(\sigma^2_{i, \gamma} = \varsigma^2(\gamma, \Lambda_i)\) となります。我々は、長さ\(N_b\)の任意の与えられたそのようなシーケンスに対して、\(\gamma = \gamma_0\)を選択しました。
\begin{eqnarray}
\gamma_0 = \underset{\gamma \neq \gamma_j, \gamma_0, \gamma_j \in \Gamma}{\rm argmax} \sum_{i=1}^{N_b} {\mathbb 1}_{\sigma^2_{i, \gamma_0}} \sigma^2_{i, \gamma_j} \tag{4.13}
\end{eqnarray}
ここで、指標関数は\(A<=B\)のとき\({\mathbb 1}_A(B) = 1\)、それ以外のとき\({\mathbb 1}_A(B)=0\)となります。式(4.13)は,毎フレーム一貫して最も分散が小さくなる解を選択します。これを実現するために,\({\mathcal C}\)をヒストリーリジェクトのない最近傍サンプラーとし,\({\mathcal M}\)を\({\mathcal M}(\alpha_0, \Lambda) = \alpha_0\)の最大演算子とし,\({\mathcal N}\)をTAA使用時のデフォルトサンプル位置(例えば,ガウス分布に従う位置)とします。実際には、下限であれば十分です。
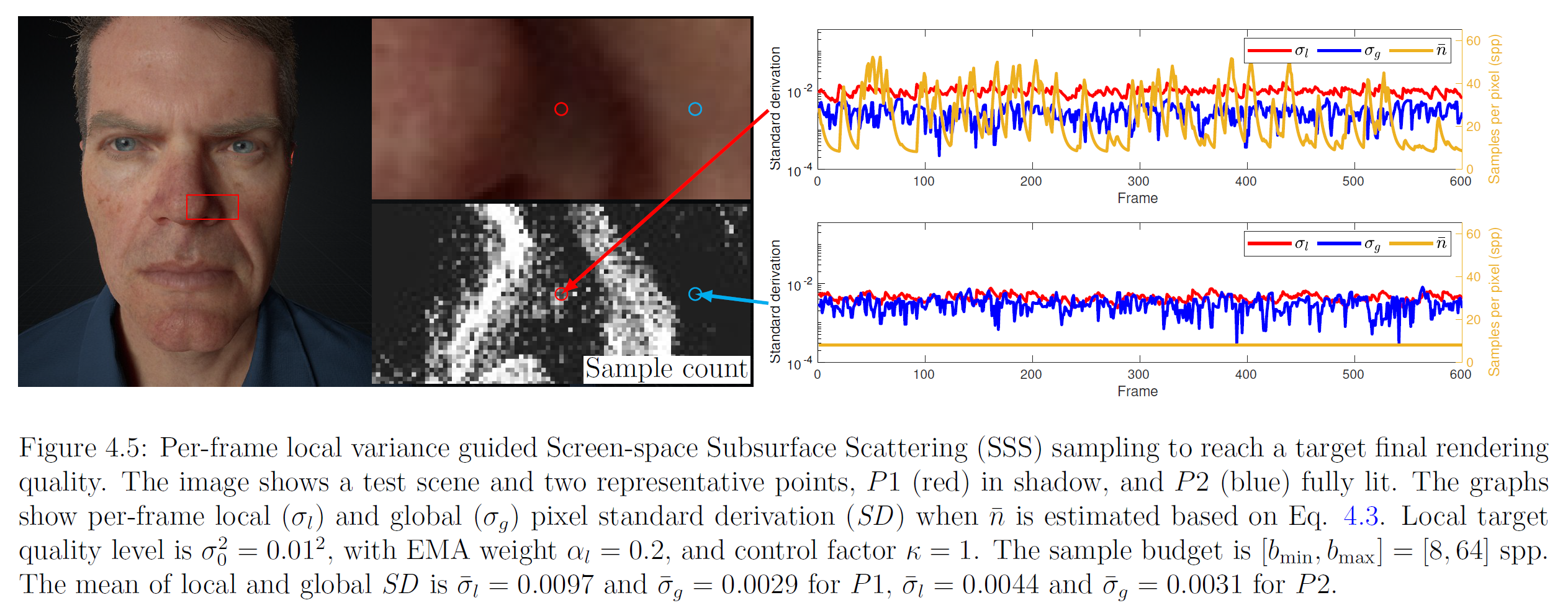
この選択の効果を説明するために,図4.5にシャドウピクセルとダイレクトライティングピクセルにおけるフレームごとの局所分散と全体分散のシーケンスを示します。\(alpha_l\) を 0.2 に固定し(これは我々のアルゴリズムを実装した UE4 の最大ウェイト),\(\sigma^2_0 = 0.01^2\) とします。この例では、グローバルピクセル標準導出の平均値が小さくなっています。さらに、高分散画素\(P1\)では、平均グローバル目標品質は、実際のローカル品質よりも11.19倍優れています。\(P2\)は、許容サンプル数\(\beta_{i-1} = 8\)sppの最小値において、目標品質よりも分散が小さく、2倍良いという結果になります。
4.5.2 Deep Learning Super Sampling(DLSS)
ローカルガイドができることで、TAAの変形だけでなく、さまざまな時間的蓄積技術をサポートし、積分品質を向上させることができます。その蓄積アルゴリズムも、異なるマテリアルに合わせて設計することが可能です。最近のディープラーニングの進歩は、コンピューターグラフィックスやリアルタイムレンダリングの機会をもたらしています。
NVIDIAは最近、リアルタイムスーパーサンプリングのための一般的な深層学習技術、深層学習スーパーサンプリング(DLSS)を提案しました[Liu, 2020]。この技術は、リアルタイムエンジンでレンダリングされた低解像度の画像を、より高い解像度にスケーリングするためのものです。こうすることで、演算能力の低いGPUでも4K解像度(3840×2160)のゲームを高フレームレートでプレイできるようになります。
DLSS2.0は、特定のゲームのためのトレーニングを必要としない、汎用的な技術になります。また、オートエンコーダーにより時間フレームを再利用し、品質を向上させます。この機能により、特化したディープラーニングのニューラルネットワークから何が出てくるかを予見することができます。図4.6は、高品質なDLSSと、表面に垂直にスポットライトを1つ当てたTAAの品質比較です。1024 sppのグランドトゥルースと比較した場合、DLSSはGlobal TAAよりも一貫して高品質です。 高輝度設定では、TAAではクランプによるエネルギー損失が見受けられます。しかし、DLSSによるレンダリングでは、このようなエネルギーロスがありません。これは、DLSSが表面下散乱の時間的蓄積をターゲットとして設計されておらず、アップスケーリングの一般的な手法であることから、非常に興味深いことです。また、表面下散乱をターゲットにした指定のニューラルネットワークを用意すれば、品質向上の可能性を示唆しています。

4.6 Discussion and Limitations
この分散ガイド型アルゴリズムでは、サンプリングが最もインコヒーレントな場合に、帯域幅の削減が最も重要となるため、最大の高速化を実現します。したがって、高速化は、遠距離サンプリング(近景または大きな平均自由行程)、またはスパースサンプリングに最適です。しかし、パス全体の周辺領域の周波数が高いために分散が非常に大きい場合は、性能向上は見込めません。
また、ピクセルの分散を過大評価し、必要以上のサンプル数になってしまう可能性もあります。TAAジッターによる分散とサンプリング不足による分散を区別していないためです。サブサーフェスでは、すべてが拡散されるため、これは良いことかもしれません。この偏ったサンプル数により、不要なパフォーマンスコストが発生する可能性があることに注意してください。
最終的な品質は、ローカルな目標品質で区切られます。一度満たせば、それ以上のサンプルは追加されません。これは表 7.2 のヘッド例 \(err_2\) に反映されています。最大サンプル数が多くても、すでに条件を満たしている領域での分散は改善されません。\(\kappa=1\) の場合,サンプリングの寄与を最終的なレンダリングに正しく反映できないことがあります。なぜかというと,最終的な TAA のウェイトが,各フレームの寄与を制限してしまうからです。
これは、\(b_{\rm min}\) を 1 spp に設定すると、サンプル数が少ない場合や TAA 履歴の除去によるノイズのために、サンプル数の推定系列が振動したりちらついたりすることがあるからである。\(b_{\rm min} = 4\)spp はこれらのちらつきをも抑えることが確認されており、特に時間的に厳しい用途には良い選択かもしれません。しかし、我々は、アダプティブ・サンプリングの恩恵を受けつつ、すべてのTAAフリッカ・アーティファクトを除去するのに十分な\(b_{\rm min} = 8\)sppを選択しました。
目標分散\(\sigma^2_0\)は、我々の実験では経験によって設定されている。しかし、式(2.28)からも統計的に求めることができます。