実装用の資料として,THE LAST OF US PARTⅡのスクショを張っておきます。動画も上げようと思ったのですが,サイズが大きくて上げられませんでした。
























ゲーム関係の話
実装用の資料として,THE LAST OF US PARTⅡのスクショを張っておきます。動画も上げようと思ったのですが,サイズが大きくて上げられませんでした。
こんにちわ。
Pocolです。
たまには生活お役立ち情報としてテレワークに役立つリモートデスクトップでゲームパッドを使う方法を紹介します。
役立つ場面としては,リモートデスクトップで自宅PCから会社PCに接続し,ゲームタイトルを開発する状況などを想定しています。
皆さん,ご存知のようにWindows 10 Proであれば,ゲームパッドはリモートデスクトップでも問題なく使えると思います。なので,Proの場合は適切に設定すればOK。
困るのがWindows 10 Homeとかの場合です。デフォルトだとリモートデスクトップでゲームパッド入力が受け付けない状態です。自分もこれに当てはまります。
ちょっと前にMicrosoftがリモートデスクトップでXBox GamePadを使える様にするプラグインをGithub上で公開しました(https://github.com/microsoft/RdpGamepad)
これを使えば,Windows 10 Homeでもゲームパッドが使えるようになります。
※Dual Shock 4を使いたい場合は,こちらを参照してください。
順に説明していきます。
まずは,Githubページの上にあるReleaseタブをクリックしましょう。
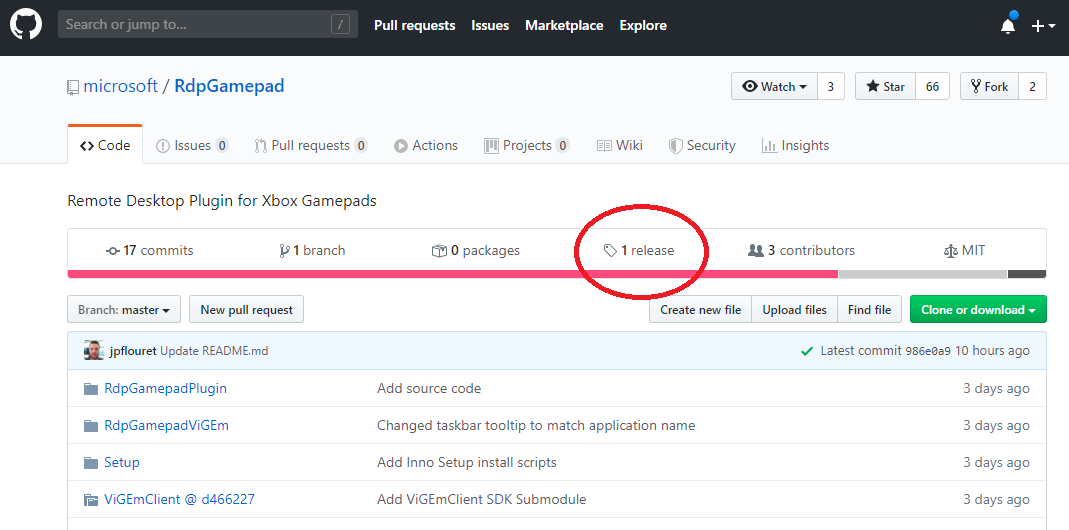
あとはリリースページに書いてある手順に従ってexeをインストールしていくだけです。
リモートワークをする前提なので,転送元PCを「自宅PC」,転送先PCを「会社PC」と想定します。
まずクライアント側(転送元)の設定です。
(1) リリースページから,「dpGamepadClientInstall-1.0.0.exe」をダウンロードし,インストールします。
(2) インストールが終わったら,リモートデスクトップセッションを切断して,転送元のPCを差起動します。
(3) 起動後に転送元PCにXboxコントローラーを指します。
以上で,転送元PCの設定は完了です。
(1) https://github.com/ViGEm/ViGEmBus/releasesのページに飛び,
の3つを順に転送先PCにインストールします。
(2) 3つインストールしたら,ページを戻り「RdpGamepadReceiverInstall-1.0.0.exe」を転送先PCにインストールします。
(3) インストールが完了したら,「Microsoft Remote Desktop Gamepad Receiver」が起動していることを確認します。転送先PCの画面右下から「隠れているインジケータ」を表示すると確認できるはずです。
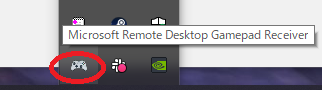
これで転送先PCの設定は終了です。
会社さんによってはインストールできるソフトウェアに制限があると思うので,情報管理部門の方とかに許可取るのを忘れないようにしてください。
あとは普通に転送元のPCに刺さっているXboxコントローラーを使えば,リモート先で動くようになるはずです。
そんなわけで,リモートデスクトップでゲームパッドを使えるようにする方法を紹介してみました。是非テレワークでの開発にお役立てください。
ではでは~

いよいよ明日からCEDEC 2014ですね。
今年も残念ながら,自分は参加できそうにないです。どうにかならんですかね?
今年は,というか今年もグラフィックス関係のセッションは少ないようです。
そんなわけで,自分だったらこれ見たいな~というセッションを上げておきたいと思います。
9/2
・13:30 ~ “次世代のライティング“実用的速度で動作するボクセルコーントレースライティング解説
・14:50 ~ 「deep down」のグラフィックス表現の技術解説
・16:30 ~ PlayStation®4のGPGPUを活用した剛体シミュレーション最適化事例
・17:50 ~ Unity 5からその先の話
9/3
・11:20 ~ モンテカルロレイトレーシングの基礎からOpenCLによる実装まで(実装編)
・13:30 ~ アンリアル・エンジン4を技術者が活用するための最新ノウハウ
・14:50 ~ アンリアル・エンジン4でのコンテンツ制作の深~いお話
・16:30 ~ リアルタイムレンダリングにおけるPtex手法について
9/4
・11:20 ~ カメラ的に正しいフォトリアルグラフィック制作ワークフロー
・13:30 ~ Second Son Particle System Architecture (Second Son パーティクル・システム・アーキテクチャ)
・16:30 ~ 西川善司のゲーム開発マニアックス「グラフィックス編」2014
この中で特に聞いておきたいのは9/4のInfamousの話でしょうか。次はdeep downかなって思います。その次はVoxel Cone Tracing。残りのセッションは資料があればどうにかなりそうな気がするので,別に聞きに行かなくてもよいかなって気がしています。
今年も参加できないので,CEDECに行く方がいらっしゃいましたら,ぜひブログ等にて報告書いてほしいですね。