Frostbiteの”Optimizing the Graphics Pipeline with Compute”を今まで見ていなかったので,資料見たら感銘を受けました。ただ,実際に実装するの怠いな~と思っていたのですが,ふと思い出して,ジオメトリシェーダでカリングを実装してみました。
下記のような感じ。
///////////////////////////////////////////////////////////////////////////////
// CbCulling constant buffer.
///////////////////////////////////////////////////////////////////////////////
cbuffer CbCulling : register(b0)
{
float4 Viewport : packoffset(c0); // xy:(width, height), zw:(topLeftX, topLeftY).
};
//-----------------------------------------------------------------------------
// メインエントリーポイントです.
//------------------------------------------------------------------
[maxvertexcount(3)]
void main
(
triangle VSOutput input[3],
inout TriangleStream< VSOutput > output
)
{
// Orientation Culling.
// ※ラスタライザーステートで時計回りを正とするため,マイナス倍になっていることに注意!
float det = -determinant(float3x3(
input[0].Position.xyw,
input[1].Position.xyw,
input[2].Position.xyw));
if (det <= 0.0f)
{ return; }
// 正規化デバイス座標系(NDC)に変換.
float3 pos0 = input[0].Position.xyz / input[0].Position.w;
float3 pos1 = input[1].Position.xyz / input[1].Position.w;
float3 pos2 = input[2].Position.xyz / input[2].Position.w;
// Frustum Culling.
float3 mini = min(pos0, min(pos1, pos2));
float3 maxi = max(pos0, max(pos1, pos2));
if (any(maxi.xy < -1.0f) || any(mini.xy > 1.0f) || maxi.z < 0.0f || mini.z > 1.0f)
{ return; }
// Small Primitive Culling.
float2 vmin = mini.xy * Viewport.xy + Viewport.zw;
float2 vmax = maxi.xy * Viewport.xy + Viewport.zw;
if (any(round(vmin) == round(vmax)))
{ return; }
// カリングを通過したものだけラスタライザーに流す.
[unroll]
for (uint i=0; i<3; i++)
{ output.Append(input[i]); }
}
RenderDocでキャプチャして,ジオメトリシェーダの出力をチェックしてみました。
正面から見た図。
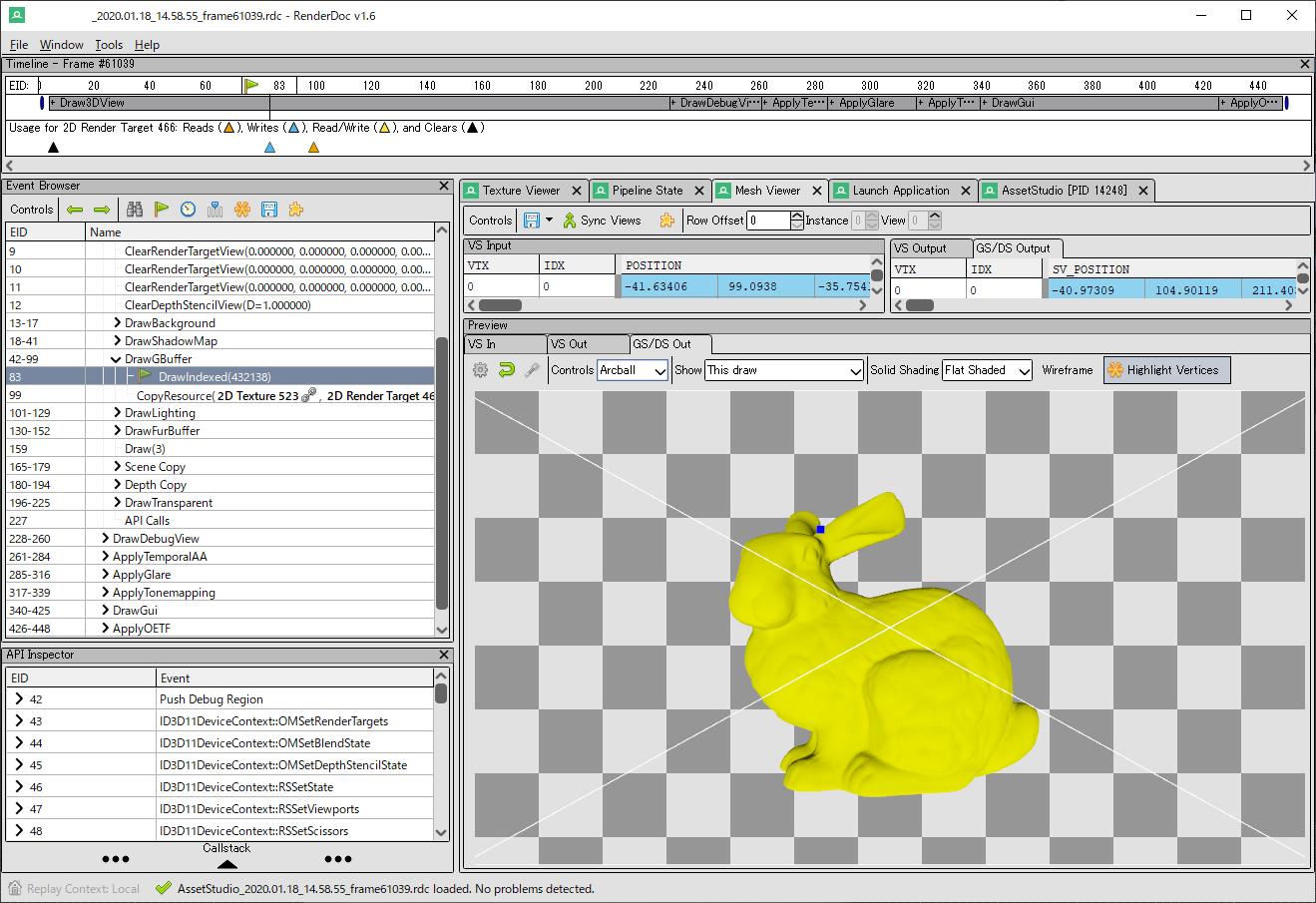
回り込んで横から見た図。

一応ちゃんとカリングされているようです。
コンピュートシェーダで実装するのが怠い人は,プラットホームによっては全然違いますが,ジオメトリシェーダでパフォーマンス向上するモードがなにかしらあると思うので,そちらで動作させると幸せになれるかもしれません。
※ちなみに手元の環境で計測もしてみたんですが,あまり高速化は見られず処理が格段に重くなりました。環境やシーンにもよると思いますが、暴力的な数のポリゴン数が投入されるシーンでは使わない方が良さそうだなと実感しました。手元のシーンでやってみた感じだと,GSカリングを入れた処理が+3msほど重くなっていて,シーン全体で+12ms程度負荷が増えました。