私的メモ。
I think this 'Realistic Interactive Grass Shader' works now?! Only Y Position of Grass Blades; still need to add X and Z directional bending.#madewithunity #gamedev pic.twitter.com/9BPRamybMd
— Andy Touch (@andytouch) February 8, 2019
どうでもいい話。
私的メモ。
I think this 'Realistic Interactive Grass Shader' works now?! Only Y Position of Grass Blades; still need to add X and Z directional bending.#madewithunity #gamedev pic.twitter.com/9BPRamybMd
— Andy Touch (@andytouch) February 8, 2019
私的メモです。
Ray Tracing Gems Chapter6にセルフヒットの回避方法が書いてあります。
https://link.springer.com/chapter/10.1007/978-1-4842-4427-2_6
こんにちわ、Pocolです。
今回は予防線を先に張っておこうと思いまして,記事を投稿します。
頑張って執筆している書籍のタイトル名ですが、まだ正式タイトルが決まっていません。
一応仮で「基礎から学ぶ」というのが今現在入っていますが,基礎というのは全然優しくありません。
「簡単なんでしょ?」とか勘違いされている方がいると,「全然簡単じゃねぇ!」とか怒る人もいるかもしれませんので,予め言っておきます。『簡単じゃないです。』
「基礎から」と言ってるだけで「簡単である」とは書かないように気を付けています。
「基礎=簡単」と思っている方がいらしたら,それは大いなる間違いです。
今回の執筆の書籍は,かなりガチ目な路線を狙いました。勿論,「基礎から」と仮題がついているので基本から説明するように心がけましたが,残念ながら執筆者の技量もあるため,読んだ人全員に理解できるものは提供できないのではないかと考えています。
ここ大事なので,もう一回言います『読んだ人全員に理解できるものではないかもしれません。』
勿論,星1がつくのは覚悟です(寧ろ、昨今だと星1が付かない方があからさまにオカシイような気さえします)。
万人受けする書籍ではありませんが,なるべく受け入れられるように努力はしました。
クソだと言ってもらうには一向に構いません。
それよりも,この書籍が役に立ったと1人でも言ってくださる方がいらっしゃったら,自分はそちらの意見の方が大変ありがたいです。
もともと救えないと思っていたものが,救える。それだけで本を書いた価値があります。
わからないものが分かったとか,ふーんと思っていたことがちゃんと納得できるようになったとかのご意見・ご感想があれば,今後の励みになります。
特に欲しい意見としては,「〇〇〇までは分かったが×××は…という理由で,全く理解できなかった。難しすぎる」とか「〇〇〇の説明がイメージつかなくて,わからないとか」とか今後につながる具体的にわからなかった理由や改善点というがあれば是非頂戴したいです。
「この本クソ!」みたいな意見は既に分かりきった当たり前の内容でして,なんの改善にもつながりません。どのレベルに合わせて書くべきかなどの修正方針にもつながりませんし,そもそも万人受けできるように努力はしていますが,それを目標とはしていませんし、当然問答無用に「クソ!」などいう人は分かりきっていまして,わからない人も多かれ少なけれいるだろうと目算していますので,単なるdisりは承知の上でして何にもなりません。出来ればどこがクソなのか理由を書いていただけるだけでもありがたいです。「こうしろ!」という意見を持ったdisりの方が改善につながりますので,具体的にどこがダメなのか?どうすると良くなるのか?なぜそう思うのか?などの生の声が頂戴したいです。
何の理由もなく「クソ!」という人は一定数いるようですので理由がないものに対しては,こちらで改善が図れません。先ほども述べましたとおりに「具体的にどこがダメなのか?」できれば「こうするともっと良くなる」という意見がありましたら,是非頂きたいです。
…というわけで先に予防線を張っておきました。
出来れば購入する際も,本当は書店などで立ち読みして本当に、本当に買うべきもの値するかどうかをきちんと判断していただいた上でご購入頂きたいです。
立ち読み等でご自分の目でご確認いただいてから,購入していただくのが確実かと思います。
きちんと自分が望むものと一致しているかどうかをご判断頂いてから,ご購入頂きたいです。
もう一度言いますが,専門書ですので,万人受けする書籍の類ではございません。
ネット等で様々なご意見があると思いますが,ご自分の目でこれは買うべきなのか?買わないべきなのかをきちんと確認した上で,後悔が無いようにご購入いただくのを強く推奨いたします。
そのためには,書店等で実物を見ていただいた上で買うのが最善であり,これを強く強く推奨いたします。
こんにちわ,Pocolです。
最近、最適化の話とかを見るのがちょっとハマっています。
NVIDIAがthread-group ID swizzlingという最適化テクニックについての記事を投稿しています。
L2キャッシュを再利用できるようにアクセスパターンを変えることにより最適化を行うテクニックのようです。
2Dフルスクリーンのコンピュートシェーダを用いるものに重要となるテクニックだそうで,ポストプロセスやスクリーンスペース系の技法を実装する際には重宝しそうです。
上記のテクニックはGDC 2019で紹介されているもので,バトルフィールド5ではRTX 2080(1440p)で0.75msの改善があったと報告されています(SetStablePowerState(TRUE)での動作だそうです)。
また,GDC 2019で紹介したソースコードにバグがあり,X方向(N)に起動するスレッドグループの数の倍数である場合にのみ動作するものだったそうです。
修正したソースコードについても提示がされています。
上記の記事のHLSLコードが実際動くのか,コピってみて試したのがだめでした。
NVIDIAのWebページの方では,いくつかHTMLの変換ミスがあるっぽくてアスタリスク(*)が無くなったりしていて,そのままコピペしてもビルドエラーになるので注意してください。
そこで,D3D11で動くように実装を修正してみました。下記のような感じです。
// スレッドサイズ.
#define THREAD_SIZE (8)
// Shader Model 5系かどうか?
#define IS_SM5 (1)
///////////////////////////////////////////////////////////////////////////////
// ColorFilterParam structure
///////////////////////////////////////////////////////////////////////////////
cbuffer CbColorFilter : register(b0)
{
uint2 DipsatchArgs : packoffset(c0); // Dispatch()メソッドに渡した引数.
float4x4 ColorMatrix : packoffset(c1); // カラー変換行列.
};
//-----------------------------------------------------------------------------
// Resources.
//-----------------------------------------------------------------------------
Texture2D<float4> Input : register(t0);
RWTexture2D<float4> Output : register(u0);
//-----------------------------------------------------------------------------
//! @brief スレッドグループのタイリングを行う.
//!
//! @param[in] dispatchGridDim Dipatch(X, Y, Z)で渡した(X, Y)の値.
//! @param[in] groupId グループID
//! @param[in] groupTheradId グループスレッドID.
//! @return スレッドIDを返却する.
//-----------------------------------------------------------------------------
uint2 CalcSwizzledThreaId(uint2 dispatchDim, uint2 groupId, uint2 groupThreadId)
{
// "CTA" (Cooperative Thread Array) == Thread Group in DirectX terminology
const uint2 CTA_Dim = uint2(THREAD_SIZE, THREAD_SIZE);
const uint N = 16; // 16 スレッドグループで起動.
// 1タイル内のスレッドグループの総数.
uint number_of_CTAs_in_a_perfect_tile = N * (dispatchDim.y);
// 考えうる完全なタイルの数.
uint number_of_perfect_tiles = dispatchDim.x / N;
// 完全なタイルにおけるスレッドグループの総数.
uint total_CTAs_in_all_perfect_tiles = number_of_perfect_tiles * N * dispatchDim.y - 1;
uint threadGroupIDFlattened = dispatchDim.x * groupId.y + groupId.x;
// 現在のスレッドグループからタイルIDへのマッピング.
uint tile_ID_of_current_CTA = threadGroupIDFlattened / number_of_CTAs_in_a_perfect_tile;
uint local_CTA_ID_within_current_tile = threadGroupIDFlattened % number_of_CTAs_in_a_perfect_tile;
uint local_CTA_ID_y_within_current_tile = local_CTA_ID_within_current_tile / N;
uint local_CTA_ID_x_within_current_tile = local_CTA_ID_within_current_tile % N;
if (total_CTAs_in_all_perfect_tiles < threadGroupIDFlattened)
{
// 最後のタイルに不完全な次元があり、最後のタイルからのCTAが起動された場合にのみ実行されるパス.
uint x_dimension_of_last_tile = dispatchDim.x % N;
#if IS_SM5
// SM5.0だとコンパイルエラーになるので対策.
if (x_dimension_of_last_tile > 0)
{
local_CTA_ID_y_within_current_tile = local_CTA_ID_within_current_tile / x_dimension_of_last_tile;
local_CTA_ID_x_within_current_tile = local_CTA_ID_within_current_tile % x_dimension_of_last_tile;
}
#else
local_CTA_ID_y_within_current_tile = local_CTA_ID_within_current_tile / x_dimension_of_last_tile;
local_CTA_ID_x_within_current_tile = local_CTA_ID_within_current_tile % x_dimension_of_last_tile;
#endif
}
uint swizzledThreadGroupIDFlattened = tile_ID_of_current_CTA * N
+ local_CTA_ID_y_within_current_tile * dispatchDim.x
+ local_CTA_ID_x_within_current_tile;
uint2 swizzledThreadGroupID;
swizzledThreadGroupID.y = swizzledThreadGroupIDFlattened / dispatchDim.x;
swizzledThreadGroupID.x = swizzledThreadGroupIDFlattened % dispatchDim.x;
uint2 swizzledThreadID;
swizzledThreadID.x = CTA_Dim.x * swizzledThreadGroupID.x + groupThreadId.x;
swizzledThreadID.y = CTA_Dim.y * swizzledThreadGroupID.y + groupThreadId.y;
return swizzledThreadID;
}
//-----------------------------------------------------------------------------
// メインエントリーポイントです.
//-----------------------------------------------------------------------------
[numthreads(THREAD_SIZE, THREAD_SIZE, 1)]
void main
(
uint3 groupId : SV_GroupID,
uint3 groupThreadId : SV_GroupThreadID
)
{
uint2 id = CalcSwizzledThreaId(DipsatchArgs, groupId.xy, groupThreadId.xy);
Output[id] = mul(ColorMatrix, Input[id]);
}
基本的には,いったんフラットなID(つまり通し番号)にして,そこから再算出するみたいな計算しているみたいです。
cpp側は下記のような感じです。
// カラーフィルタ実行.
{
auto x = (m_TextureWidth + m_ThreadCountX - 1) / m_ThreadCountX; // m_ThreadCountX = THREAD_SIZE. シェーダリフレクションで取得.
auto y = (m_TextureHeight + m_ThreadCountY - 1) / m_ThreadCountY; // m_ThreadCountY = THREAD_SIZE. シェーダリフレクションで取得.
auto pCB = m_CB.GetBuffer();
CbColorFilter res = {};
res.ThreadX = x;
res.ThreadY = y;
res.ColorMatrix = asdx::Matrix::CreateIdentity();
m_pDeviceContext->UpdateSubresource(pCB, 0, nullptr, &res, 0, 0);
auto pSRV = m_Texture.GetSRV();
auto pUAV = m_ComputeUAV.GetPtr();
m_CS.Bind(m_pDeviceContext.GetPtr());
m_pDeviceContext->CSSetConstantBuffers(0, 1, &pCB);
m_pDeviceContext->CSSetShaderResources(0, 1, &pSRV);
m_pDeviceContext->CSSetUnorderedAccessViews(0, 1, &pUAV, nullptr);
m_pDeviceContext->Dispatch(x, y, 1);
ID3D11ShaderResourceView* pNullSRV[1] = {};
ID3D11UnorderedAccessView* pNullUAV[1] = {};
m_pDeviceContext->CSSetShaderResources(0, 1, pNullSRV);
m_pDeviceContext->CSSetUnorderedAccessViews(0, 1, pNullUAV, nullptr);
m_CS.UnBind(m_pDeviceContext.GetPtr());
}
たまに触らなくなると,すぐに忘れるので思い出せるようにメモしておきます。
前提として
// コンピュートシェーダ側.
[numthreads(dimX, dimY, dimZ)]
void main(...)
{
...
}
// cpp側 pCmdList->Dispatch(A, B, C);
としておく。
グループが A * B * C 出来上がる
例えば,Dispatch(3, 2, 1)とした場合は, 3 * 2 * 1 = 6個のグループになる。
(0, 0, 0), (1, 0, 0), (2, 0, 0)
(1, 1, 0), (1, 1, 0), (2, 1, 0)
という感じ。
上記のuint3型6つのものがSV_GroupIDとなる。
コンピュートシェーダでは,これらのグループごとにスレッドが生成される。
つまり,dimX * dimY * dimZ のグループスレッドができあがある。
例えば,[numthreads(2, 2, 1)]とした場合は,
(0, 0, 0), (1, 0, 0)
(0, 1, 0), (1, 1, 0)
と4つのグループスレッドが出来上がある。
上記のuint3型4つのものがSV_GroupThreadIDとなる。
一番細かい単位は,実行するスレッド。つまりディスパッチされたスレッドで
グループIDとグループスレッドIDから決まるので24個のディスパッチスレッドIDが生成される。
例えば,
a : [0, A)
b : [0, B)
c : [0, C)
の半開区間を用いて、SV_GroupIDを(a, b, c)として表し,
x : [0, dimX)
y : [0, dimY)
z : [0, dimZ)
の半開区間を用いて,SV_GroupThreadIDを(x, y, z)として表したとする。
このとき,SV_DispatchThreadIDはuint3型であり、そのIDは
(a, b, c) * (dimX, dimY, dimZ) + (x, y, z) で表される。
グループ番号は,SV_GroupThreadIDとnumthredsから算出され
SV_GroupIndex = x + (A) * y + (A * B) * z;
で求まる。
例えば,
[numthreads(2, 2, 1)]とした場合は0~3までの4グループ
[numthreads(10, 8, 3)]とした場合は0~239までの240グループ
となる。
Microsoftのドキュメントに図が載っているので,以上を踏まえて読むと分かるはず。
https://docs.microsoft.com/ja-jp/windows/win32/direct3dhlsl/sv-dispatchthreadid
こんにちわ、Pocolです。
先日お伝えしたVisual Studioとの格闘についに勝ちました。
そんなわけで,DirectX ShaderCompiler用のカスタムビルドルールをGithubの方に公開しました(https://github.com/ProjectAsura/dxc_rule)
これで,GUIでポチポチしながらVisual Studioのみで完結して作業をすることが出来ます。
Githubにアップされている3ファイルが必要になります。これをプロジェクトファイルと同じディレクトリに配置してください。
まずは,ソリューションエクスプローラーから「ビルドの依存順序」>「ビルドのカスタマイズ」を選択し,「既存ファイルの検索」を選択し,dxc.targetsを指定します。これで,カスタムビルドルールが適用されるようになります。
あとは,HLSLファイルを作成し,ソリューションエクスプローラー上から右クリックで「プロパティ」を選択します。
先ほど設定した,dxc.targetsによって「DXCコンパイラ」が選択できるようになります。
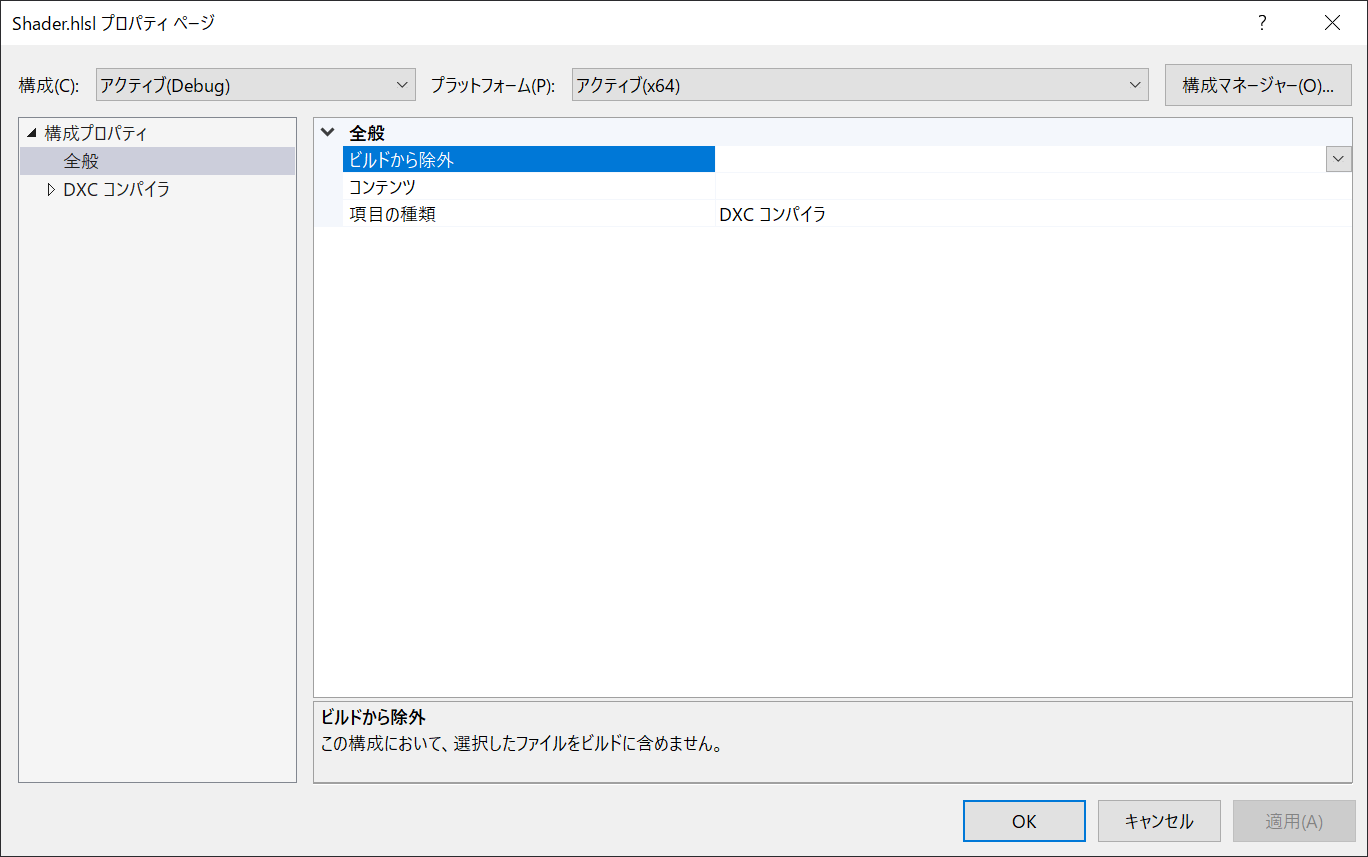
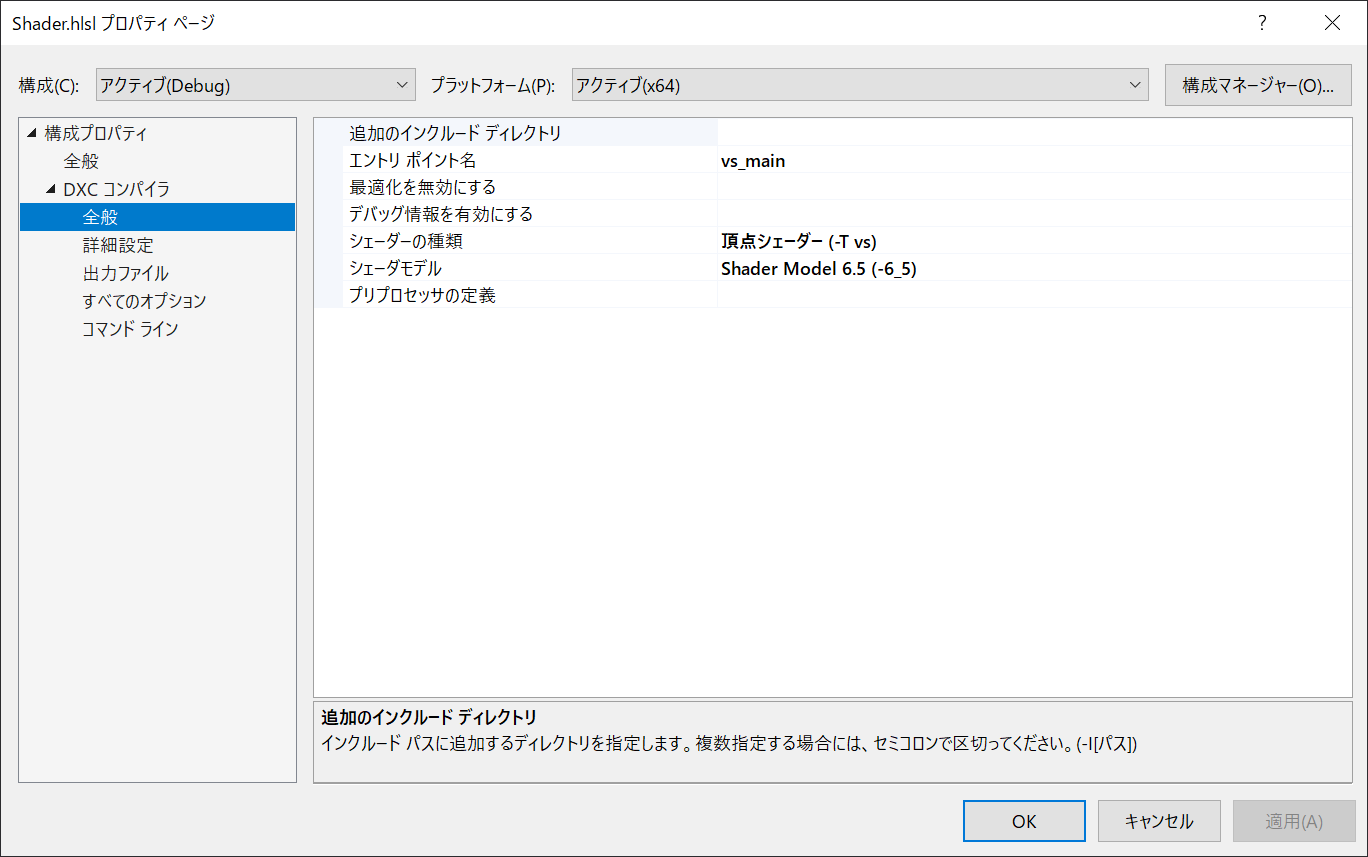
あとは,お好みでプロパティを設定してみてください。一応大体純正のやつ同じ感じにしています。
出力ファイルの項目にRootSignature出力やシェーダリフレクション出力を追加しています。
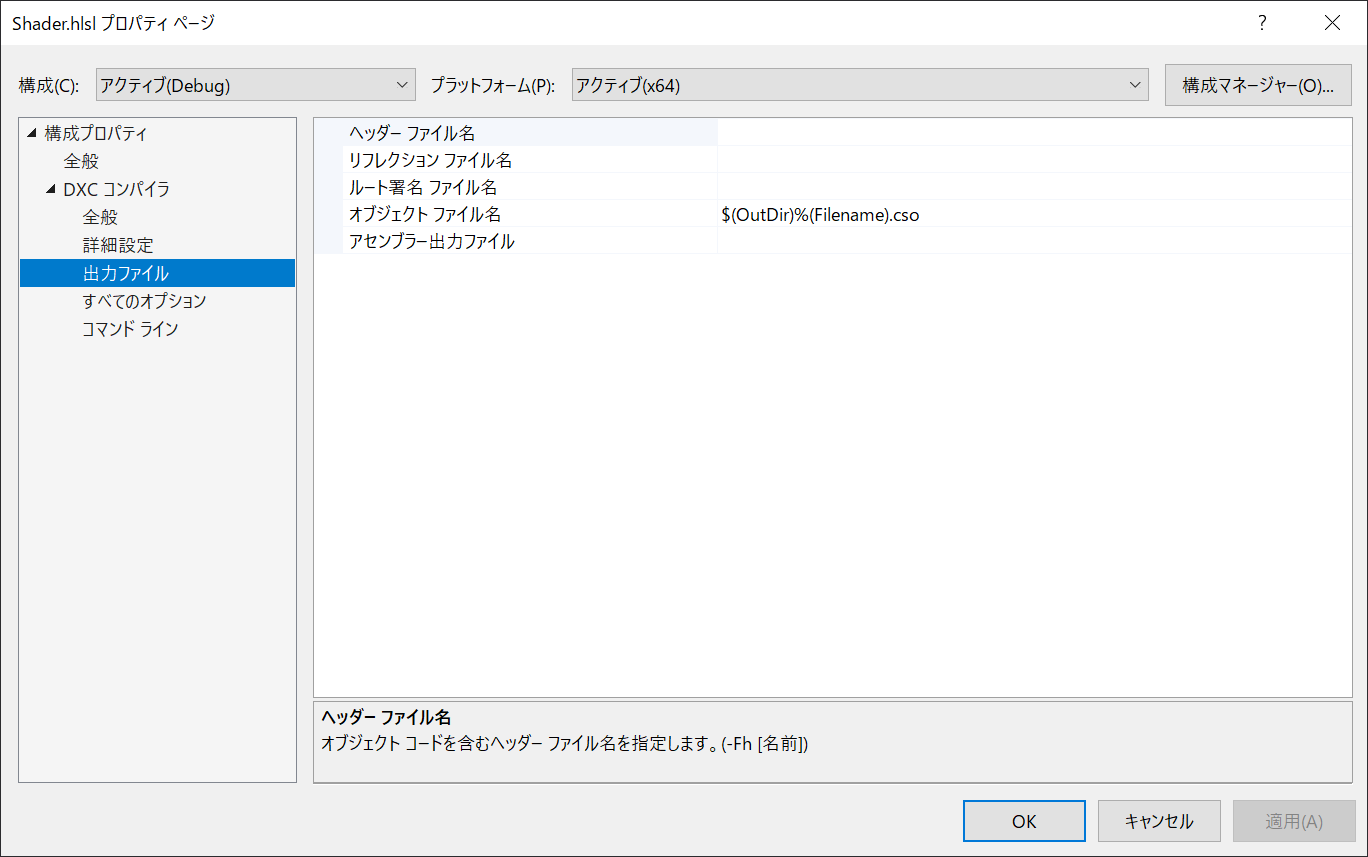
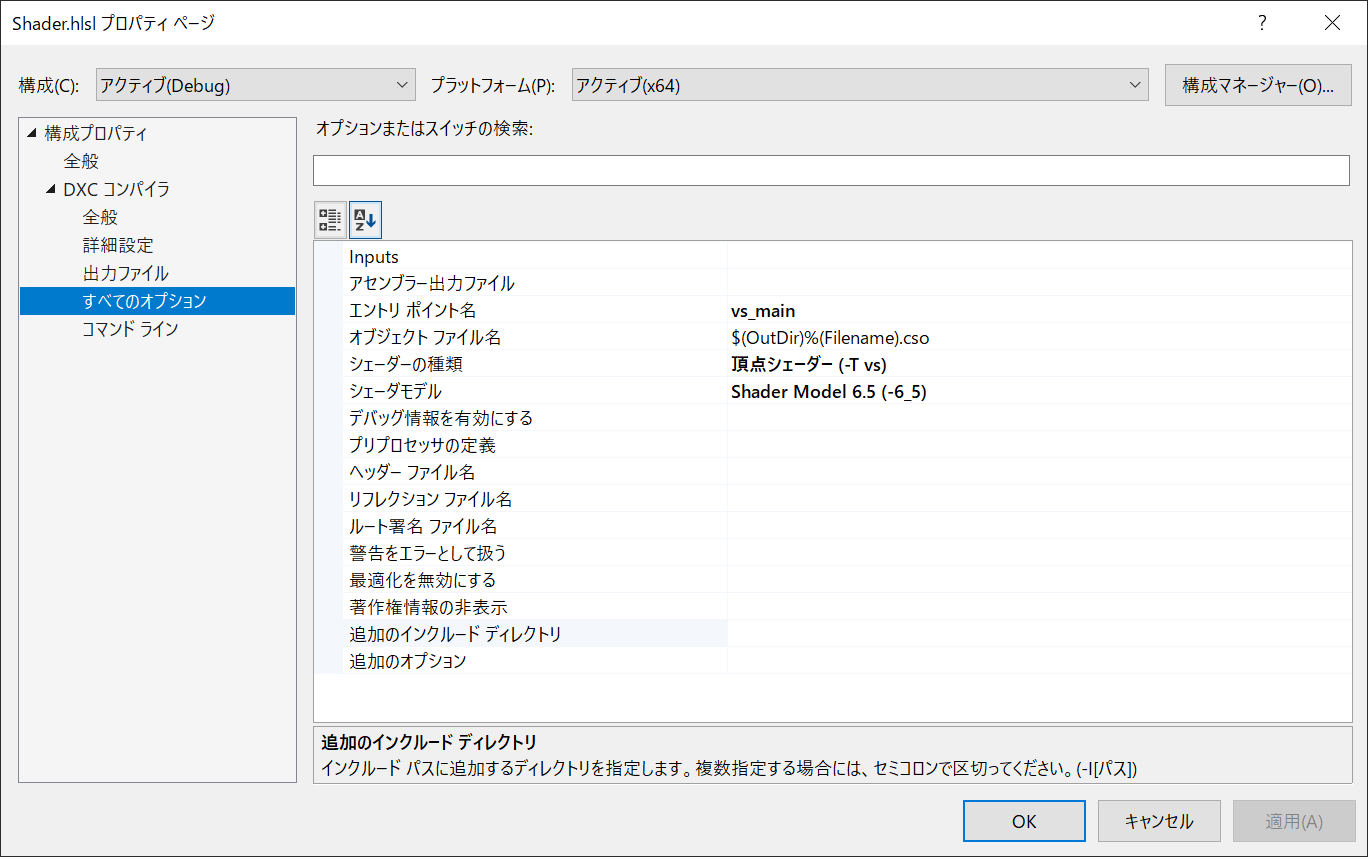
欲しかったメッシュシェーダ(Mesh Shader)や増幅シェーダ(Amplification Shader)も対応しています。
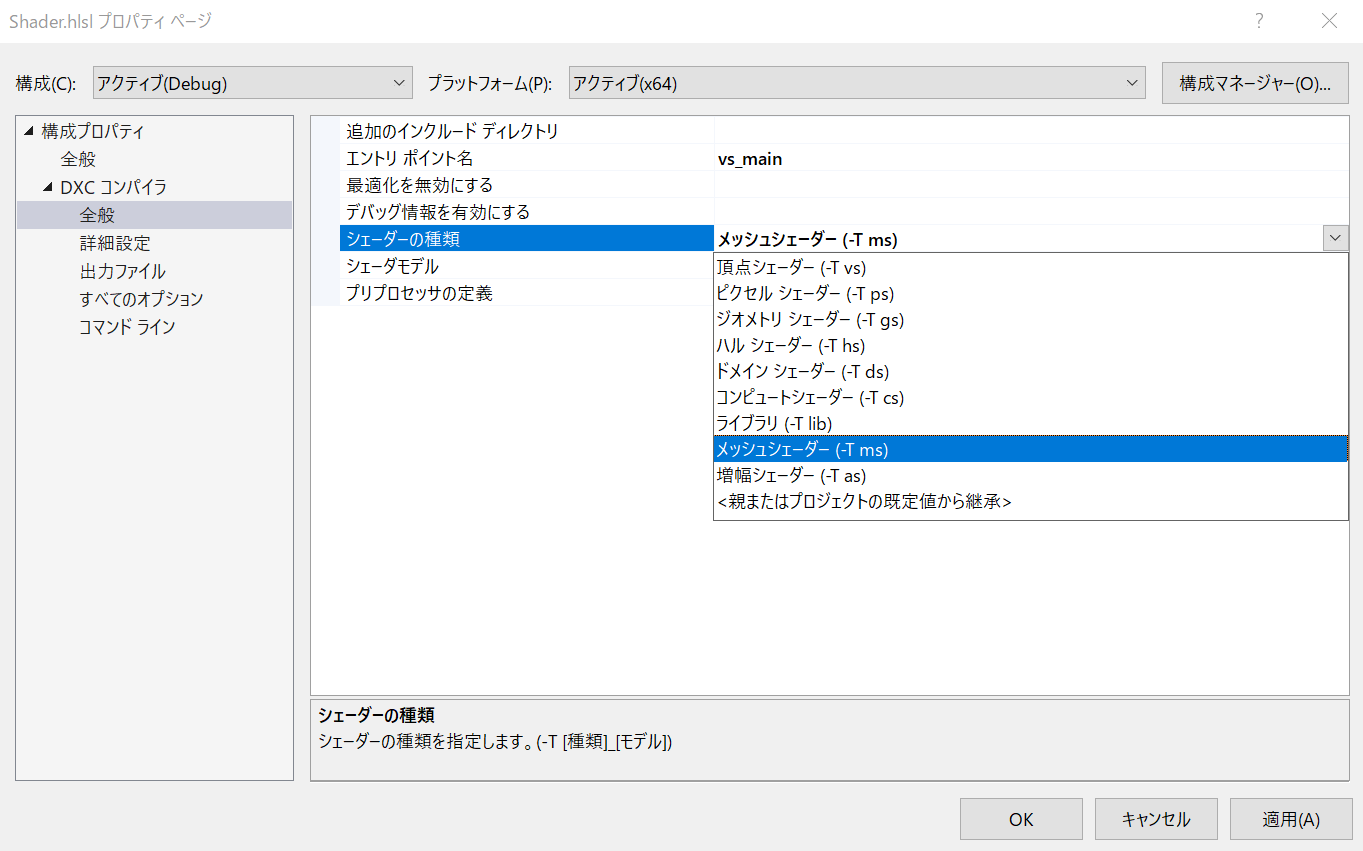
これで快適なメッシュシェーダプログラミングが楽しめるはずです!
そんなわけで,今回はカスタムビルドルールについて紹介しました。では ノシ
久しぶりホームページを更新するために,サンプルプログラムを作っているのですが…
あれ?Visual Studio 2019で設定できなくね?
…と思ったので,DXC用のカスタムビルドターゲットを作ることにしました。
とりえあず,UI構築ぐらいまではザックリやりました。
ここまで、順調。
で,いざビルドしようとさせてみたら…何かコンパイルが走っていない。
何故だ?(まぁ設定がオカシイのですが,どこがオカシイのか分からな過ぎて見当がつかんのです)。
こういうVisual Studioを拡張するとか魔改造する的なブログ記事が日本語だと全然ヒットしないんですよね~。
皆お行儀よくVisual Studioを使っているということなのかしら。
そんなわけで苦戦中です。メッシュシェーダのビルドが走るのはいつになることやら…。
まぁ、batに逃げる手もあるのですが,何か負けた気がするのでもうちょい粘ってみます。
一応、https://ventspace.wordpress.com/2019/03/08/fully-featured-custom-build-targets-in-visual-c/を参考にして対応進めています。
より良い参考ページとかがあれば是非教えてください。
※追記
どうやら下記のMSBuildのリファレンスを参考に実装すると良さそう。
https://docs.microsoft.com/ja-jp/visualstudio/msbuild/msbuild-reference?view=vs-2019
忘れないようにメモ。
昨日ぐらいまで普通にGitでフェッチできていたのだが,突然
「SSL cerficatte problem: certificate has expired」
が出るようになった。
で,設定に問題があるな!と分かったのは同じリポジトリをcloneしているはずなのに,片方はアクセス出来て,片方はアクセスできない。
よってサーバー側のエラーじゃないとわかる。
最終的にどこが間違っていたかというと,リポジトリをhttps始まりで設定していたのがだめだった。
git@XXXXX
を指定するようにしたら無事に接続できるになった。
接続できない場合は,指定が間違っていないかどうかチェックすること。
※2020/06/13 Dual Shock4 Emulationモードの入力不具合を修正しました。
https://github.com/ProjectAsura/RdpGamepad/releases/tag/DS4_7
※2020/11/20 Dual Senseからの入力を試験的にサポートすることにしました。
https://github.com/ProjectAsura/RdpGamepad/releases/tag/DS5_1
こんにちわ,Pocolです。
今回はテレワークお役立ち情報の続編です。
前回はWindows 10 HomeがRemote Fx USBリダイレクト使えなくて,リモートデスクトップでパッドが使えなくて困って,リモートデスクトップでゲームパッドが扱えない場合にゲームパッドを使えるようにするプラグインを紹介したのですが…
今回はそのプラグインを改造して,少し扱いやすくしました!というお話です。
前回紹介した、https://github.com/microsoft/RdpGamepadはXInput対応のゲームを開発する際にはとても役に立つのですが,残念ながらDual Shock 4にしか対応していないゲームを開発する際にはリモート越しで操作出来なくてこまってしまうという場面に出くわします(※まぁ開発者の人ならわかりますよね)。
「無いなら作ろう!」というわけで,作ってみました。
https://github.com/ProjectAsura/RdpGamepad/releases/tag/DS4_6
基本的には
という処理を付け足しました。
使い方は簡単で,本家の代わりにこちらで改造した版のインストーラーを使ってインストールしてください。
転送先のPCで右下に常駐する「Microsoft Remote Desktop Gamepad Receiver」を右クリックして,転送先で振る舞うコントローラータイプを選択してください。
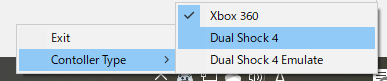
Xbox 360を選択すると,
[ローカルPC:XInput] → [リモートPC:XInput]として動作します。
Xbox 360 Emulationを選択すると,
[ローカルPC:Dual Shock 4] → [リモートPC:XInput]として動作します。
Dual Shock 4を選択すると,
[ローカルPC:Dual Shock 4] → [リモートPC:Dual Shock 4]として動作します。
Dual Shock 4 Emulationを選択すると,
[ローカルPC : XInput] → [リモートPC: Dual Shock 4]として動作します。
XInputでDual Shock 4をエミュレーションする場合にはボタン数が足らないため,PSボタンとタッチパッドボタンが効かない仕様です。
また,サブモジュールとして使用しているViGEmClientがジャイロなどに対応していない関係で,Dual Shock 4のジャイロは非サポートです。
また,Bluetoothを使った接続に関しても非サポートです。
ちなみに分かっている情報として,Xbox OneゲームパッドをRemote FX USBリダイレクトでつなぐとリモート先のPCがブルースクリーンになるなどの問題が報告されています。
現在所属会社の方では,Remote FX USBリダイレクトでブルースクリーンが発生する問題を避ける方法としてRdpGamepadの使用が推奨されています。
そんなわけで,転送先PCでDual Shock 4として認識してくれないと開発に困る!という方たちにはもしかしたら有益な情報かもしれませんし,ブルースクリーンで悩んでいる方に有益な情報かもしれません。
テレワークでの開発にお役に立てば幸いです。
※追記ですが,ViGEmBusのドライバー側にバグがあるようで,入力を受け付けなくなってBSODになったりするみたいです。DirectInputやXInputの初期化処理で関数から帰ってこなくなったら,このバグが発生している可能性あります。この状態でリモート接続を切断してしまうと,再接続できなくなるようなので,バグが発生したらリモート側のPCをいったん再起動して対処するほかないようです(再起動にも20分とか時間がかかるようです)。現在,Issueが発行されています。1日以上PCを起動しっぱなしにするとバグを踏む確率が高くなるので,対処として1日に1回PCの再起動かけると良いかと思います。
この記事は Graphics Advent Calender 2017(https://qiita.com/advent-calendar/2017/graphics) の9日目の記事です。
さて,昨年作った資料(https://speakerdeck.com/projectasura/zhong-ji-gurahuitukusuru-men-siyadoumatupinguzong-matome) の反響が良かったので,シャドウについて捕捉を書いてみようと思いました。特に資料後半で適当に書いてしまったPCSSと,最適化について話が抜けているので加筆してみます。
現在所属するプロジェクトでもそうなのですが,シャドウマップは処理が重く最適化をしないとどうしようもありません。そこで通常は,シャドウマップ用の軽量メッシュを用意する,不要なオブジェクトを書かないカリング処理を行うといった措置を取ります。軽量メッシュはアーティストに作成をお願いしなくてはいけませんが,カリング処理はエンジニアのみで対応可能ですのでカリング処理について説明してみます。
通常の描画であれば,視錘台カリングを使っておけば良いでしょう。
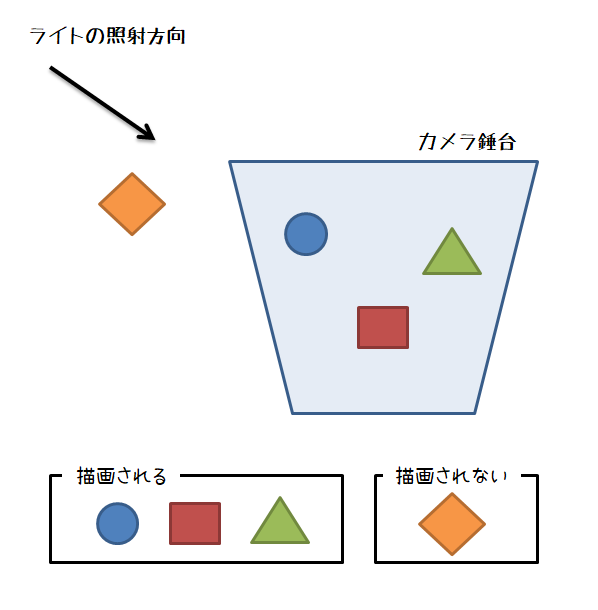
しかしシャドウマップの場合,単なる視錘台カリングだとまずい場合があります。
例えば,視錘台の外にいるオブジェクトが視錘台の中に影を落とす場合です。
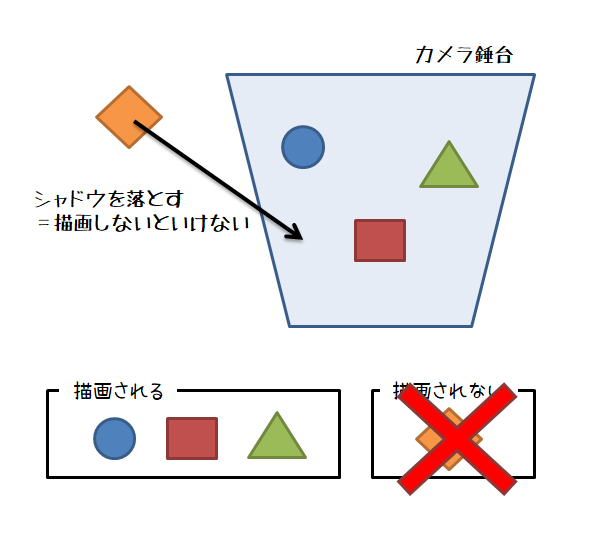
この場合に,単なる視錘台カリングを適用してしまうと,本来影が落ちて欲しいオブジェクトが錘台の外にいるために,カリングで消えてしまって影が出ないという見た目的におかしい状態が発生してしまいます。
そこで,シャドウマップを描画する際はカリングにはある程度工夫が必要となります。
シャドウマップ部分に移る余白部分が多いほど無駄になります。前述した資料にあるようにシャドウマップに移る領域を出来るだけタイトにして,無駄な領域をなくしてシャドウマップに割り当てられるピクセル数を増やすことによってシャドウマップの解像度は変えずにシャドウマップの品質を上げることが可能です。この品質をあげるために使われるテクニックが単位キューブクリッピングというテクニックです。
昔やっていた方法では,視錘台に引っかかるオブジェクトだけちゃんと描画するという割り切った最適化をやっていました。具体的には視錘台と交差するものを含めて単位キューブクリッピングに使用するAABBを作成するという方法です。当時やっていたプロジェクトでは,結構大きめのバウンディングボックス等があったので,単純に視錘台に引っかかるものだけを入れるという方法使うと,無駄な領域が増えてしまいシャドウマップの品質がかなり落ちるという状態になってしまいました。そこで,さらに判定を厳密化し,視錘台と交差するオブジェクトではなく,視錘台と交差する点のみを使ってタイトなAABBを作るという方法をやっていました。

実装としては,視錘台の8角から構成されるワイヤー錘台を作って,ワイヤーとオブジェクトの交差判定処理を行い,交差点をAABBを作成する点群に追加するといった感じです。
技術デモを作成した当時は,大抵のシーンでおおむね問題がありませんでしたが,やはり割り切った実装であるため,いくつかのシーンではシャドウが消えたり,急にシャドウが書かれたり”パカパカする”フリッカリングが発生してしまいました。
技術デモは品質が命ということで,このままではダメということになりました。
が,既にそのプロジェクトからは外れてしまっていたため,後任者の方に実装をお願いすることにしました。
当時思いついた方法は,視錘台のAABBを先に作っておき,判定対象のオブジェクト中心からレイを飛ばして,AABBにヒットしたら描画対象として加えるという方法です。
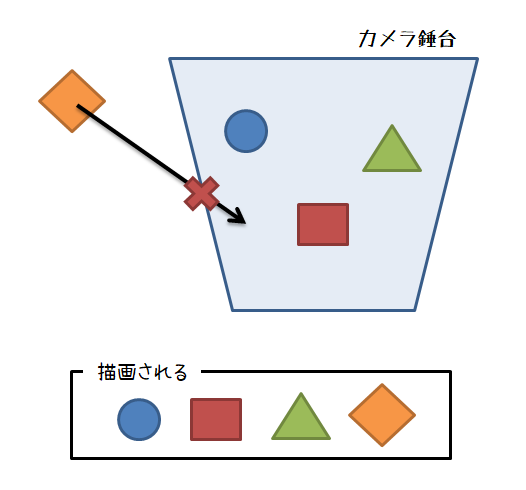
後任者の方がちゃんと実装したかどうかは定かではありませんが,最近になって自分で実装してみました。
レイを飛ばす方法のオブジェクトのサイズが適度に小さい場合は,これで大丈夫そうでした。
…が,高層ビルのような長いオブジェクトがあると誤判定されるケースが多くやっぱり駄目だということになりました。まぁ,当たり前っちゃ~当たり前ですよね…。
で,ダメだったので,もう少しだけ頑張って実装してみました。疑似コードは次のような感じです。
AABBの中心からレイを飛ばす
if (カメラ錘台にヒット)
{
描画対象に追加。
return;
}
AABBの8角の点を取得。
for(auto i=0; i<8; ++i)
{
点iからレイを飛ばす
if (カメラ錘台にヒット)
{
描画対象に追加。
return;
}
}
これで,多少マシになりました。ただレイを9本飛ばすので,若干処理負荷が増えます。
つい最近実装した方法は,まじめに判定をやる方法です。
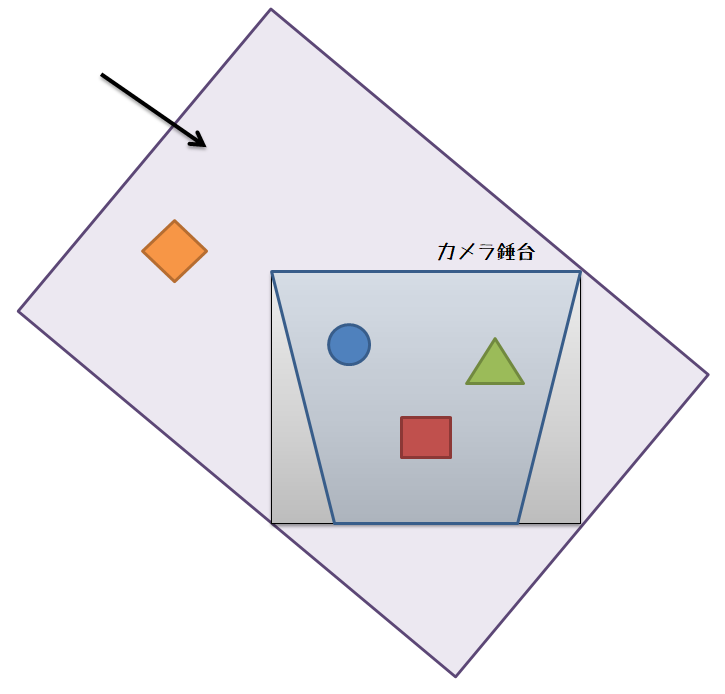
視錘台の8角からAABBを作り,これをライトの照射方向で作成されるライト空間にAABBを変換して,ライト空間上でのAABBのサイズを求めます。
次に,求めたサイズとライトの照射方向ベクトルからOBBを作成して,OBB内にオブジェクトが含まれるかどうか判定処理に持ち込みます。OBB内にオブジェクトが含まれていたら描画リストに追加するという方法です。とりあえず実験でためした実装では視錘台のAABBを使っていますが,視錘台のAABBではなく視錘台を8角を使った方がよりタイトになると思います。
DirectXCollisionが使える場合は,BoundingOrientedBoxを使うことで簡単に実装できます。BoundingOrientedBoxを作成する際のOrientationとなる四元数はライト空間の基底行列から求めることが出来ます。この基底行列はサイズを求める計算で作っているので,XMQuaternionRotationMatrix()メソッドの引数として渡せば求まります。
しかし,図をみると分かるようにこの方法は完璧でなく,視錘台の外側に不要な領域が生まれてしまいます。
一番良い方法としては,視錘台とライトの照射方向ベクトルから構成される厳密な凸包を作成して,GJKアルゴリズムなどによりオブジェクトが凸包に含まれるかどうかの判定を行う方法です。
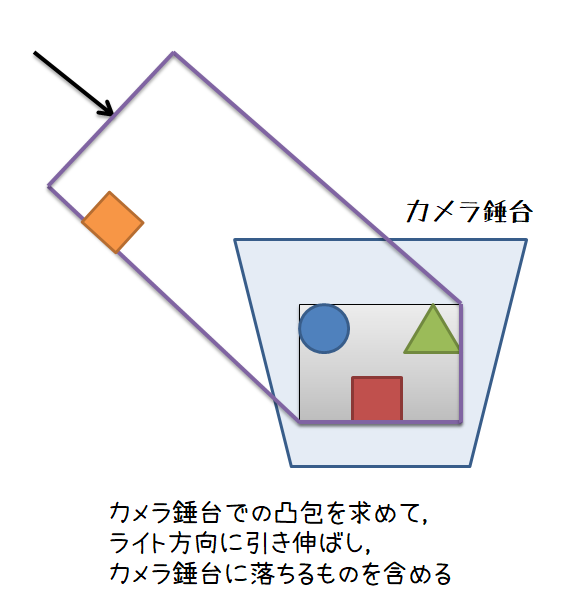
この方法まだ試してみていないです。判定としては一番厳密になるのですが,処理負荷的に大丈夫かどうかが不安材料で,実用に耐えられるかどうかという所でしょうか。だれか試したことがある方がいらっしゃったら,結果がどういう感じか教えて頂けると有難いです。あるいは,もっといい方法あれば教えてください…。
→ @holeさんに,”Sample Distribution Shadow Map”がいいよと教えていただきました。
確かに,おっしゃる通りですね。これに勝るものはありません。レンダリングバジェットがある程度確保できているのであれば,SDSMを使うのが良いでしょう。
(ただ,今仕事でやっているやつはSDSM実装できるだけのレンダリングバジェットが無いんですよね…。またシャドウの領域はバッチリとフィットするのですが,GPU上で錘台計算している実装などではCPUにデータをリードバックさせるとパフォーマンスが落ちます。そのため,GPU上で錘台カリングするような実装になると思うのですが,この場合ドローコールを減らすためのカリングを行うなど工夫していないとドローコールが増えるので,ドローコールや頂点シェーダがボトルネックである場合はパフォーマンスが出ません。)
さて,話は変わってPCSSの話です。
FarCryやアサシンズクリードなど,最近のAAAタイトルではPCSSを使った半影表現が行われています。
より現実的なシャドウを出したいというフェーズにシフトしたと考えても良いでしょう。これに遅れるわけにはいきません。
そんなわけでPCSSについて少し勉強をしておこうと思いました。

※図は,[Fernando 2005]より引用。
PCSS[Fernando 2005]は半影表現を行うアルゴリズムの1つです。オブジェクトとの距離が近いほどハードシャドウ気味になり,距離が遠いほどソフトシャドウ気味になります。
このアルゴリズムの基となるアイデアは,PCFフィルタのカーネルサイズを制御しようというものです。

※図は, [Fernando 2005]より引用。
PCFフィルタのカーネルサイズの推定には次の情報が必要となります。
これらの情報を元に次式によって,カーネルサイズを決定します。
\begin{eqnarray}
W_{Penumbra} = \frac{d_{Receiver} – d_{Blocker}}{d_{Blocker}} w_{Light} \tag{1}
\end{eqnarray}
\(W_{Penumbra}\)は推定によって得られるPCFのカーネルサイズです。

ライトのサイズは,シーン側で分かるはずなのでシェーダ側に定数バッファとして渡します。レシーバーの深度は,ライト空間に変換してZ値を求めればよいので,計算により求まります。必要な3つの情報のうち,2つがあっさりと計算により求まります。残る1つはブロッカーをシャドウマップ上で探し出して,ブロッカーの深度を求めます。
NVIDIAによる実装がGithubに上がっているので,これをもとに実装方法を勉強してみます。
リポジトリは下記です。
https://github.com/NVIDIAGameWorks/D3DSamples/tree/master/samples/SoftShadows
mediaフォルダ内にシェーダがあります。
SoftShadows.fxにピクセルシェーダのメインエントリーポイントがあり,下記のように実装されています。
float4 EyeRender_PS (uniform int shadowTechnique, Geometry_VSOut IN) : SV_Target
{
float2 uv = IN.LightPos.xy / IN.LightPos.w;
float z = IN.LightPos.z / IN.LightPos.w;
// Compute gradient using ddx/ddy before any branching
float2 dz_duv = DepthGradient(uv, z);
float4 color = Shade(IN.WorldPos, IN.Normal);
if (IsBlack(color.rgb)) return color;
// Eye-space z from the light's point of view
float zEye = mul(IN.WorldPos, g_lightView).z;
float shadow = 1.0f;
switch (shadowTechnique)
{
case 1:
shadow = PCSS_Shadow(uv, z, dz_duv, zEye);
break;
case 2:
shadow = PCF_Shadow(uv, z, dz_duv, zEye);
break;
}
return color * shadow;
}
PCSS_Shadow()という部分が肝心な部分です。このメソッドはPercentageCloserSoftShadows.fxhというファイルに実装されています。実装は下記のようになっています。
float PCSS_Shadow(float2 uv, float z, float2 dz_duv, float zEye)
{
// ------------------------
// STEP 1: blocker search
// ------------------------
float accumBlockerDepth = 0;
float numBlockers = 0;
float2 searchRegionRadiusUV = SearchRegionRadiusUV(zEye);
FindBlocker(accumBlockerDepth, numBlockers, g_shadowMap, uv, z, dz_duv, searchRegionRadiusUV);
// Early out if not in the penumbra
if (numBlockers == 0)
return 1.0;
else if (numBlockers == BLOCKER_SEARCH_COUNT)
return 0.0;
// ------------------------
// STEP 2: penumbra size
// ------------------------
float avgBlockerDepth = accumBlockerDepth / numBlockers;
float avgBlockerDepthWorld = ZClipToZEye(avgBlockerDepth);
float2 penumbraRadiusUV = PenumbraRadiusUV(zEye, avgBlockerDepthWorld);
float2 filterRadiusUV = ProjectToLightUV(penumbraRadiusUV, zEye);
// ------------------------
// STEP 3: filtering
// ------------------------
return PCF_Filter(uv, z, dz_duv, filterRadiusUV);
}
ブロッカーを探索(STEP 1)して,その結果からカーネルサイズを決定して(STEP 2),PCFフィルタを適用する(STEP 3)という実装です。探索した結果,ブロッカーがゼロである場合は,影ではないので処理を打ち切ります。また,全てのピクセルがブロッカーだった場合は,半影になる可能性はなくなるので,影と判定して半影処理はスキップして終わりにしています。探索領域は上記の実装からみると,SearchRegionRadiusUV()というメソッドで決定しているようです。このメソッドの実装は次のようになっています。
// Using similar triangles from the surface point to the area light
float2 SearchRegionRadiusUV(float zWorld)
{
return g_lightRadiusUV * (zWorld - g_lightZNear) / zWorld;
}
上記で出てくるg_lightRadiusUVとg_lightZNearは,SoftShadowRenderer.cppのSoftShadowsRenderer::updateLightCamera()メソッドのあたりで設定が行われています。
実装を見ると,g_lightRadiusUVはワールド空間でのライト半径をライト錘台で見たときのUV座標の大きさに変換を掛けているようです。g_lightZNearはライト錘台のニアクリップ平面までの距離を設定しているようです。
続いて,FindBlocker()メソッドを追ってみましょう。
// Returns accumulated blocker depth in the search region, as well as the number of found blockers.
// Blockers are defined as shadow-map samples between the surface point and the light.
void FindBlocker
(
out float accumBlockerDepth,
out float numBlockers,
Texture2D<float> g_shadowMap,
float2 uv,
float z0,
float2 dz_duv,
float2 searchRegionRadiusUV
)
{
accumBlockerDepth = 0;
numBlockers = 0;
#ifdef USE_POISSON
for (int i = 0; i < SEARCH_POISSON_COUNT; ++i)
{
float2 offset = SEARCH_POISSON[i] * searchRegionRadiusUV;
float shadowMapDepth = g_shadowMap.SampleLevel(PointSampler, uv + offset, 0);
float z = BiasedZ(z0, dz_duv, offset);
if (shadowMapDepth < z)
{
accumBlockerDepth += shadowMapDepth;
numBlockers++;
}
}
#else
float2 stepUV = searchRegionRadiusUV / BLOCKER_SEARCH_STEP_COUNT;
for(float x = -BLOCKER_SEARCH_STEP_COUNT; x <= BLOCKER_SEARCH_STEP_COUNT; ++x)
for(float y = -BLOCKER_SEARCH_STEP_COUNT; y <= BLOCKER_SEARCH_STEP_COUNT; ++y)
{
float2 offset = float2(x, y) * stepUV;
float shadowMapDepth = g_shadowMap.SampleLevel(PointSampler, uv + offset, 0);
float z = BiasedZ(z0, dz_duv, offset);
if (shadowMapDepth < z)
{
accumBlockerDepth += shadowMapDepth;
numBlockers++;
}
}
#endif
}
やっていることとしては,探索半径から探索範囲の各テクセルをなめてシャドウであるかどうかの判定を行い,シャドウと判定されたら,その時のシャドウマップの深度とヒット数をカウントアップするということをやっているようです。結構素直な処理ですが,見ると分かるように各テクセルを調べる際にテクスチャフェッチが必要になるため,それなりに重たい処理です。
これで,ブロッカー深度を求めることができるので,必要な情報が揃います。後はそろった情報を使ってPCFフィルタを適用すれば終わりです。PCFフィルタについては見ればわかると思うので,説明は省略します。
[Fernando 2005]はライト空間(シャドウマップ空間)で計算を行うアルゴリズムでした。これをライト空間ではなくスクリーン空間で行うものが,”Screen-Space Percentage-Closer Soft Shadows”[MohammadBagher 2010]です。
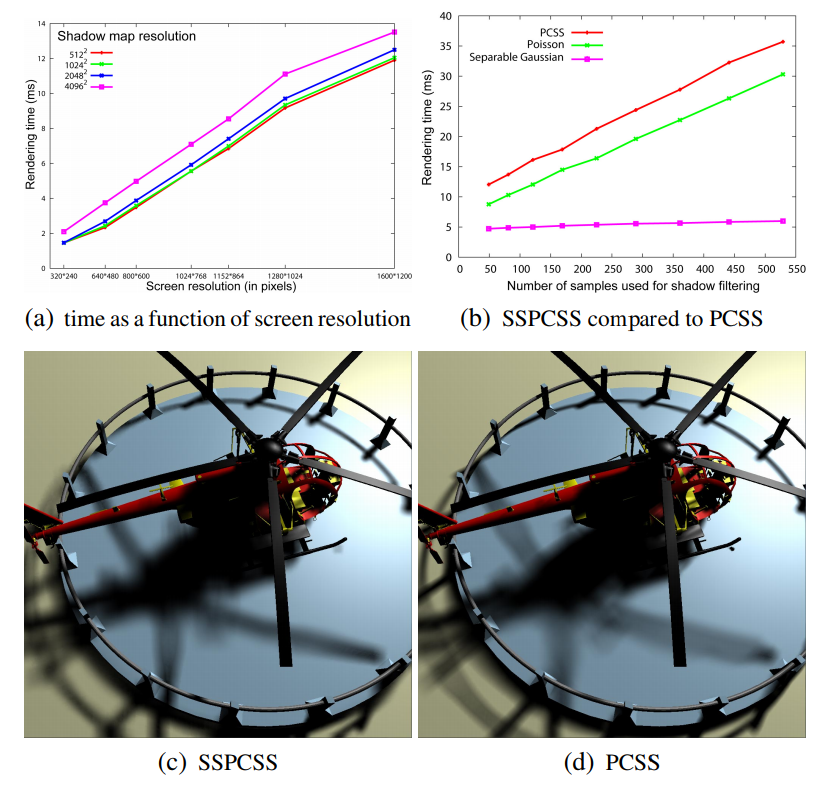
※図は[MohammadBagher 2010]より引用
アルゴリズムは以下の手順で行われます。
[MohammadBagher 2010]のアルゴリズムでは4つのバッファを使用する様です。
* Scene depth map : シーンの深度マップ
* Shadow map : 普通のシャドウマップ
* Hard shadow map : スクリーン空間においてシャドウであるかを示す点群
* Projected shadow map : スクリーン空間上の各点に対して最も近いブロッカー距離が格納される
スクリーン空間上の各ピクセルに対してProjected Shadow mapをスキャンし,光源をブロックするオブジェクトの距離平均を求めます。
ブロッカーが無い点については,計算は省略します。
このステップでブロッカーの深度の平均が求まることになります。
前のステップで計算されたブロッカーの平均深度を用いて,各ピクセルに対する半影サイズを推定します。
スクリーン空間上での半影サイズは式(2)により計算します。
前ステップで求めた半影サイズの直径から,Hard shadow mapを可変サイズフィルタでフィルタリングします。
さて,上記で出てきた式(2)は以下のようになります。
\begin{eqnarray}
W_{screen\,penumbra} \equiv \frac{W_{penumbra} d_{screen}}{d_{eye}} \tag{2}
\end{eqnarray}
ただし,上式における\(d_{screen}\)と\(W_{penumbra}\)は,
\begin{eqnarray}
d_{screen} & \equiv & \frac{1}{2 \tan \frac{fov}{2}} \\
w_{penumbra} & \equiv & \frac{d_{receiver} – d_{blocker}}{d_{blocker}} W_{light}
\end{eqnarray}
とします。
[Fernando 2005]とは違って,一旦シャドウマップを射影してしまって,スクリーン空間上で処理を行うというのがミソです。この手法はスクリーン空間で処理する際にエッジ情報が失われるため,クロスバイラテラルフィルタなどを使っているようです。
SSPCSSを改良した手法というのが提案されています。
その手法というのが,”Screen Space Anisotropic Blurred Soft Shadows”[Zheng 2011]です。

※図は[Zheng 2011]より引用。
SSABSSは,ビューイング角度を考慮して半影を出すようです。
アルゴリズムの詳細が[Zheng 2014]に載っています。
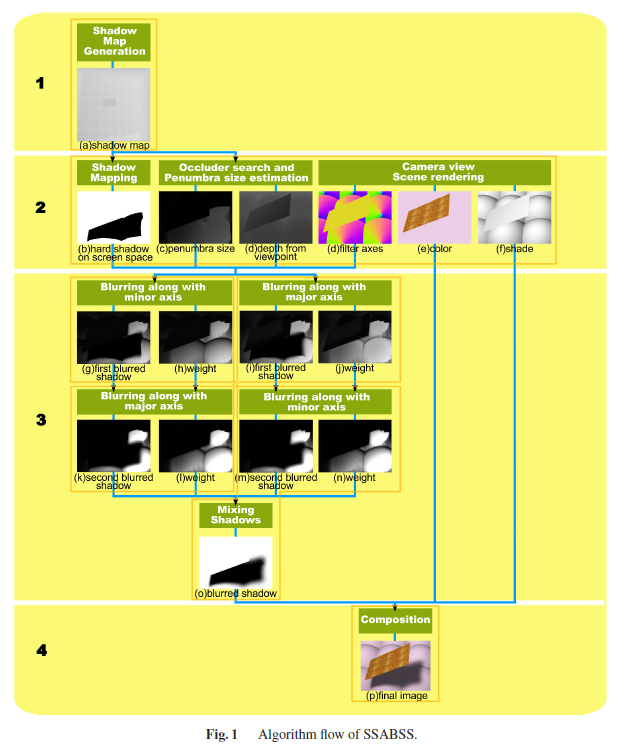
※図は[Zheng 2014]より引用。
SSPCSSと違う所は,法線を考慮したAnisotropic Gaussian Filterを適用するという所のようです。
[Zheng 2014]はちゃんと読んでいないのですが,[Zheng 2011]を見た感じだと,通常のガウスブラーを適用する際に円の半径の使う代わりに,次式によって算出される楕円半径を用いてガウスブラー処理を行えば良い様です。
\begin{eqnarray}
A_{minor} & = & {\rm{normalize}}(n_x, n_y, 0) \\
A_{major} & = & A_{minor} \times N_v \\
r_{minor} & = & N_v \cdot N_s \\
r_{major} & = & 1
\end{eqnarray}
上式における\(N_v = (n_x, n_y, n_z)\)はサーフェイスの法線ベクトルとし,\(N_s = (0, 0, 1)\)はスクリーンの法線ベクトルとします。
シャドウマップについて資料ですっ飛ばしたところをいくつか補足説明してみました。
論文の特許等については調べていないので,会社で実装する際は各社法務とご相談ください。
“Adaptive Depth Bias for Shadow Maps”はまだきちんと読めていないので,後日また書きます。
(※追記:http://project-asura.com/blog/archives/4271 に記事を書きました。)