こんにちわ、Pocolです。
今日は,High Performance Graphics 2016で発表された…
[Hasselgren 2016] J.Hasselgren, M. Andersson, T. Akenine-Möller, “Masked Software Occlusion Culling”, High Performance Graphics 2016
を読んでみようと思います。
いつもながら,誤字・誤訳が多々あるかと思いますので,ご指摘いただける場合は正しい翻訳例と共に指摘していただけるとありがたいです。
Abstract
動的なシーンにおける効率的なオクルージョンカリングは、レンダリングを高速化するために、ゲームやリアルタイムグラフィックスのコミュニティにとって非常に重要なトピックです。我々は、最近のグラフィックスハードウェアのための深度カリングの進歩に触発されて、SIMD対応のCPUに適応して最適化された新しいアルゴリズムを紹介します。我々のアルゴリズムは、メモリオーバーヘッドが非常に低く、以前の研究よりも3倍高速であり、フル解像度の深度バッファアプローチによってカリングされたすべての三角形の98%をカリングします。また、オクルーダーラスタライズとオクルージョンクエリのインターリーブをペナルティなしでサポートしており、シーングラフのトラバーサルやレンダリングコードでの使用を容易にしています。
1. Introdcution
最近のゲームやリアルタイム・グラフィックス・アプリケーションの環境は着実にダイナミックになってきており、ユーザーはより自由に仮想世界と対話することができるようになっています。これにより、没入感が増し、仮想環境がより現実世界のように感じられるようになる一方で、データ構造やカリングアルゴリズムへの要求がこれまで以上に高くなっています。
その結果、ますます多くのゲームエンジンは、潜在的に見えるセット[ARB90, KCCo01, NBG02]のような従来の事前計算された可視性判定アルゴリズムを重視せず、重要なオクルーダーを階層的な深度バッファにラスタライズするアルゴリズム[GKM93]を好むようになっています。最近の例としては、Frostbiteエンジン[And09, Col11]、Umbraオクルージョンカリングエンジン(http://umbra3d.com/)、Intelのソフトウェアオクルージョンカリングフレームワーク[CMK*16]などがありますが、これらはすべてソフトウェアラスタライズに依存して階層的な深度バッファを作成します。このバッファは、GPUにドローコールを送信する前にCPUでオクルージョンクエリを実行するために使用されます。Haar and Aaltonen [HA15]は、同じコンポーネントを使用した同様のシステムを提案していますが、完全にGPU上で動作します。
正確なオクルージョンクエリは望ましいですが、ほとんどのシステムは性能と精度のバランスを取らざるを得ません。例えば、Andersson [And09]とCollin [Col11]の研究では、非常に低い解像度のデプスバッファを使用し、オクルージョンメッシュを内側に保守的にすることで補正しています。しかし,内部保存的なメッシュを作成するのは困難な作業です。メッシュは1ピクセルの面積だけ縮小されなければなりませんが、これは投影に依存しており、潜在的に拘束されない可能性があります。これは誤ったネガティブや誤ったカリングにつながる可能性があり、オクルージョンメッシュをモデリングするアーティストに高い要求を課すことになります。対照的に、インテルのオクルージョンカリングデモは、フル解像度のデプスバッファを使用しているので、同じ欠点はありません。しかし、パフォーマンスは低くなるでしょう。
これまでのアプローチと比較して、我々の主な貢献は、深度データとカバレッジデータを効率的に分離する階層的な深度表現です。これは、タイルの正確なカバレッジを非常に迅速に計算することができるため、パフォーマンスの鍵となります。これにより,高解像度の深度バッファを使用する利点を維持しつつ,低解像度[And09, Col11]やGPUで加速されたアプローチ[HA15]と同様の性能を達成することができます。
我々の研究は、グラフィックスハードウェアのためのマスクされた深度カリングに関するAnderssonら[AHAm15]の最近の研究に大きく影響を受けています。我々は,彼らのアルゴリズムをよりソフトウェア実装に適したものにするために,以下の4つの拡張を提案します。
- 少数のSIMD命令のみを用いて32×8ピクセルタイルのカバレッジマスクを並列に生成するアルゴリズム
- Anderssonら[AHAM15]のものに似た、新しい深度更新ヒューリスティックですが、パフォーマンスのために精度をトレードします。
- オクルージョンカリングのために調整された、メモリオーバーヘッドの少ないSIMDフレンドリーな階層型深度バッファ表現
- 低コストのオクルーダーレンダリングとオクルージョンクエリのインターリーブにより、シンプルで効率的なシーングラフトラバーサルアルゴリズムを実現します
さらに、アルゴリズムの最適化された実装を提供します。図1に、複雑なオクルージョンを持つシーンに適用したアルゴリズムの例を示します。

2. Previous Work
静的なシーンについては、例えば、潜在的に見えるセット(PVS)[ARB90]を事前に計算したり、ポータルやミラー[LG95]を使用したりすることができ、このトピックに関する研究が豊富に行われています。しかし、アプリケーションの大部分は非静的なものであるため、ここでは動的なオクルージョンカリングの方法に焦点を当てます。
Greeneら[GKM93, Gre96]は、階層的な深度ベースのデータ構造を用いた最初のアルゴリズムを発表し、グラフィックスハードウェアに大きな影響を与えました。Zhangら[ZMHH97]は、階層的なオクルージョンマップを導入し、その(完全な)階層が作成された方法により、近似的なオクルージョンテストを提供しました。Morein [Mor00]は、階層内に1つのレベルだけを持つ階層的Z (HiZ)アルゴリズムを記述しており、ハードウェア実装の面で多くの利点を与えています。ほとんどのグラフィックプロセッサは、パフォーマンスを向上させるために、HiZオクルージョンカリングの何らかのバリエーションを持っていると思われます。
AilaとMiettinen [AM04]は、多数のカリング手法を、動的オブジェクトを持つ大規模なシーンを扱えるシステムに統一しました。このシステムはdPVS(dynamic potentially visible set)と呼ばれ、10年以上前にUmbraの基礎となっていたようです。しばらくの間、UmbraはGPUとCPUの両方のオクルージョンカリングをサポートしていましたが[SSMT11]、現在はソフトウェアのみのエンジンです。Bittnerら[BWPP04]は、ハードウェアオクルージョンクエリに基づいたシステムを構築しました。このシステムでは、シーンを前後に横断することで、以前に表示されていたオブジェクトやクエリのレンダリングをインターリーブしながら、より良いカリングが可能になりました。ハードウェアオクルージョンクエリの分野は、予測されたレンダリング(オクルージョンクエリが成功した場合にのみドローコールを実行し、GPUとCPU間のコストのかかる通信を避ける)、近似クエリ(GPUのHiZバッファを使用する可能性がある)、および「any fragments」(最初に見えるフラグメントが見つかったらすぐにクエリを終了することができる最適化)を提供することで、それ自体が成熟してきました。序章で紹介したソフトウェアオクルージョンカリングの作業に加えて、Valient [Val11]はフル解像度のデプスバッファをレンダリングし、オクルージョンテストを加速するために保守的にスケールダウンしました。また、ダウンサンプリングと前のフレームからのGPUのデプスバッファの再投影に依存する代替的な近似アルゴリズム[KSS11, HA15]もあり、欠落したデータを埋めるために穴埋め戦略を使用します。これらのアルゴリズムは、誤って可視オブジェクトをカリングしてしまい、フレーム間の可視性の比較的小さな変化に依存しています。動きの速いダイナミックオブジェクトを持つシーンは、再投影によってうまく処理されないため、特に厄介です。
3. Algorithm and Implementation
我々は最初にインテルのソフトウェアオクルージョンカリングフレームワーク[CMK*16]に我々のアルゴリズムを実装したので、彼らのシステムの簡単な説明から始めます。彼らのオクルージョンカリングは,主に2つのパスに分かれています。最初のパスでは、重要で大きなオクルーダーメッシュのセットを識別し、基本的なビューフラスタムと背面のカリングを実行し、カリングされていないすべての三角形をフル解像度のデプスバッファに変換してラスタライズします。その後、深度バッファは、各8×8ピクセルタイルの最大深度を計算することで縮小され、1レベルの階層的な深度バッファが作成されます[GKM93, Mor00]。第2のパスでは、どのオブジェクトが見えるかを決定するために、ソフトウェアでオクルージョンクエリを実行します。各潜在的オクルージョンのバウンディングボックスは、最初にビューフラスタムをカリングし、次にスクリーン空間に変換して、最小深度\(Z_{min}^{box}\)を有するバウンディング矩形を形成します。オクルージョンクエリは、バウンディング矩形を素早くトラバースし、最小深度\(Z_{min}^{box}\)を、階層的な深度バッファ\(Z_{max}^{tile}\)に格納されている関連深度と比較することによって実行されます。オブジェクトは、外接矩形に重なっているすべてのタイルに対して,\(Z_{min}^{box} > Z_{max}^{tile}\)の場合にのみ、オクルージョンと分類されます。
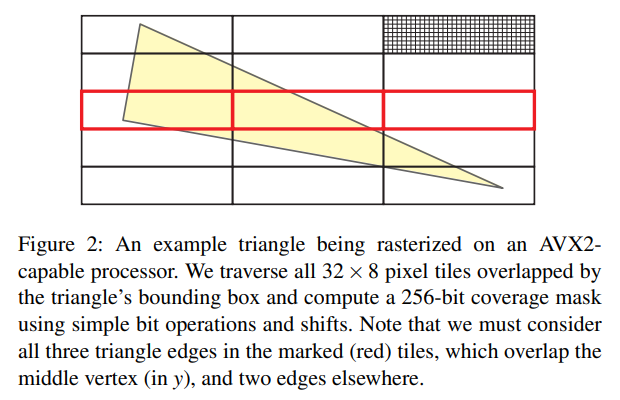
我々のラスタライズアルゴリズムは、標準的な2レベル階層ラスタライザ[MM00]と似ていますが、2つの主な例外があります。まず、タイル全体の三角形のエッジからカバレッジマスクを効率的に並列に計算します。AVX2は32ビットの精度で8幅のSIMDをサポートしているので、\(32 \times 8\)を好みのタイルサイズとして選択しました。見ての通り、これにより256ピクセルのカバレッジを非常に効率的に並列計算することができます。第二の違いは、階層的な深度バッファ表現で、フル解像度の深度バッファを必要とせず、深度データとカバレッジデータを分離しています。これにより、メモリ使用量を大幅に削減しています。
3.1. Efficient Triangle Coverage
我々のカバレッジ決定は、オリジナルのエッジフィルラスタライズアルゴリズム[AV80]と多くの類似点を持っていますが、少数の命令でSIMDレジスタ全体のカバレッジを生成するように最適化されています。
まず、スカラーの状況を見て、三角形のエッジが各スキャンラインと交差する左右のイベントを追跡することで、三角形をラスタライズします。これらのイベントは、各三角形のエッジに対して \(\Delta x /\Delta y\) スロープを計算し、新しいスキャンラインが通るたびに左右のイベントを対応するスロープでインクリメントすることで見つけることができます。左右のイベントの傾きは、スキャンラインが中央の頂点と一致したときに変化します。これは以前の研究で、例えば三角形を上下に分割することによってうまく処理されています[AJ88]。
スキャンラインの左右のイベントが与えられると、以下の擬似コードに示すように、すべてのビットが設定されたレジスタをプリロードし、シフト演算を使用して左右のイベントで定義された範囲外のビットをクリアすることにより、32ピクセル分の32ビットカバレッジマスクを並列に作成します。
// Compute coverage for the 32-pixels at pos. x,
// given the left and right triangle events
funtion coverage(x, left, right)
return (~0 >> max(0, left - x))
& ~(~0 >> max(0, right - x))
各SIMDレーンを異なるスキャンライン上で動作させ、\(32 \times 8\)ピクセルのカバレッジを効果的に並列計算します。これを行う上での主な課題は、個々のスキャンラインごとに2つのイベント(三角形に入ったり出たり)しかありませんが、そこにあるすべてのエッジがタイルのカバレッジに貢献する可能性があるということです。そのため、カバレッジテストを以下のように修正しなければなりません:
// Compute coverage for 32x8 pixel tile. Params
// are SIMD8 registers with 32 bits per lane
function coverageSIMD(x, e0, e1, e2, o0, o1, o2)
m0 = (~0 >> max(0, e0 - x)) ^ o0;
m1 = (~0 >> max(0, e1 - x)) ^ o1;
m2 = (~0 >> max(0, e2 - x)) ^ o2;
return m0 & m1 & m2;
エッジイベントであるe0 – e2は、スキャンライン版の左右イベントと同様であり、マスクo0 – o2は、エッジが右イベントとみなされた場合にはビットワイズnotを実行するために使用されます。つまり、左向きのエッジではo1は0、右向きのエッジでは~0となります。この処理は図3に可視化されています。
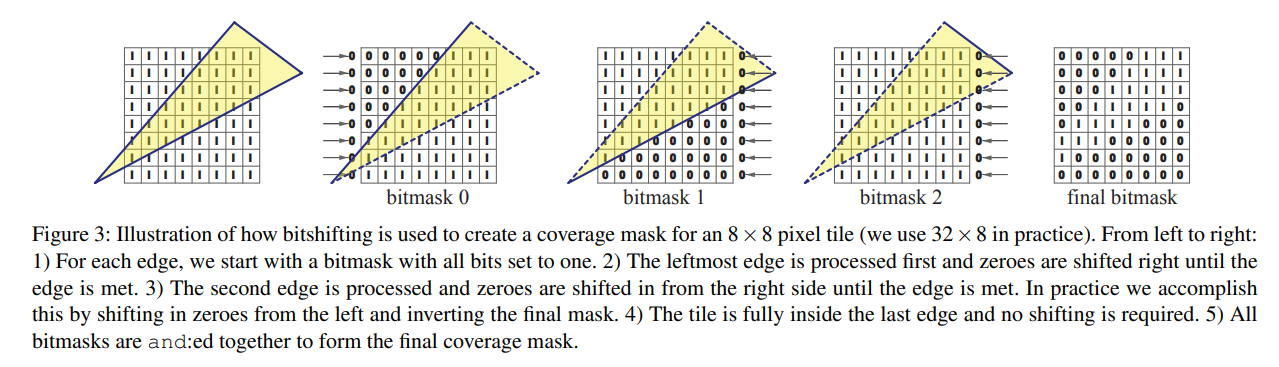
三角形は常に少なくとも1つの左向きの辺と1つの右向きの辺を持ち、最終的な辺は三角形の構成に基づいて左向きか右向きのどちらかになります。したがって、三角形の辺を並べ替えることで、上記の xor-operation のうち 2 つを取り除くことができます。実際には、我々の実装を最適化するためにこれよりも先に進みます。ビット反転は、残りのエッジの向きに基づいて三角形のセットアップ中に決定することができます。さらに、図 2 を参照して、中央の頂点(y)に重なるタイル内の 3 つのエッジをすべて考慮する必要があります。三角形を上、下、中間の各セグメントに分割し、上と下の部分に最適化された2つのエッジを使用して、中間のセグメントで3つの完全なエッジテストのみを実行します。
Precision
我々のカバレッジアルゴリズムはエッジ関数[Pin88]に依存していないため、DirectXラスタライズルールに完全に準拠していることを保証するのは難しいです。例えば、左右のイベントをトラッキングするために \(\Delta x / \Delta y\) スロープを使用しており、結果として得られるスロープは、丸め誤差が発生するため、有限の精度に丸められなければなりません。また、分割操作は、水平に近いエッジの精度の問題につながる可能性があり、これはタイルサイズが大きいために、我々のアルゴリズムでは強調されています。不正確なラスタライズは誤検出を引き起こす可能性がありますが、リアルタイムアプリケーション用のほとんどのオクルージョンカリングアルゴリズムは、すでに小さな誤差を許容していることに注意してください。例えば、Intel [CMK*16]によるオクルージョンカリングのデモでは、エッジ関数が32ビットで表現できるように、すでに頂点位置を整数座標にクランプしています。
Bresenham補間[Bre65]を使用して、DirectXラスタライズルールを尊重する我々のアルゴリズムのバージョンを作成することが可能です。Bresenham補間は精度の損失を導入せず、エッジを正確に補間するために使用することができます[LKV90]。我々は実験的な実装を行い、それがランダムな三角形の大規模なセットに対してGPUのラスタライザと一致することを経験的に検証しました。しかし、SIMDに最適化された実装は将来の作業のために残っており、したがって、性能についての主張はできません。
3.2. Hierarchical Depth Buffer
前節の三角形カバレッジアルゴリズムでは、32ビットのSIMDレーンが\(32 \times 8\)タイルの\(32 \times 1\)ピクセルに対応する完全なAVXビットマスクを生成しています。我々は、各SIMDレーンがよりよく形成された8×4タイルにマップするようにマスクを再配置するために安価なシャッフルを使用しています。各8×4タイルに対して、階層的な深度バッファには、2つの浮動小数点型深度値\(Z_{max}^0\)と\(Z_{max}^1\)と、各ピクセルがどの深度値に関連付けられているかを示す32ビットのマスクが格納されています。これらの値を4×2タイル用の配列構造体(SoA)として格納することで、AVX2命令を使用して8つのタイルの深度テストと更新を効率的に並行して行うことができます。ポップアップされたタイルの例とその表現は、図4に示されています。

Depth Buffer Update
タイルを(部分的に)覆う三角形をラスタライズするたびに表現を保守的に更新する方法が必要です。Anderssonら[AHAM15]が提案しているアルゴリズムを直接利用することも可能であり,参考として実装しました。しかし、我々は、クアッドフラグメントマージ[FBH*10]にインスパイアされた、よりシンプルなアプローチを提案しています。我々のヒューリスティックは、オリジナルの研究よりも描画順序に敏感です。しかし、オクルージョンカリングエンジンでは、よくソートされたレンダリング順序を使用することが最善の方法であることが多く、実際にはそれがうまく機能することがわかりました。
function updateHiZBuffer(tile, tri)
// Discard working layer heuristic
dist1t = tile.zMax1 - tri.zMax
dist01 = tile.zMax0 - tile.zMax1
if (dist1t > dist01)
tile.zMax1 = 0
tile.mask = 0
// Merge current triangle into working layer
tile.zMax1 = max(tile.zMax1, tri.zMax)
tile.mask |= tri.coverageMask
// Overwrite ref. layer if working layer full
if (tile.mask == ~0)
tile.zMax0 = tile.zMax1
tile.zMax1 = 0
tile.mask = 0
疑似コードを参照して、\(Z_{max}^1\)の値を作業層、\(Z_{max}^0\)を参照層として割り当てます。三角形のカバレッジを決定した後、作業レイヤー\(Z_{max}^1 = {\rm max}(Z_{max}^1, Z_{max}^{tri})\)を更新しマスクを合成します,ここで,\(Z_{max}^{tri}\)はタイルの境界内での三角形の最大の深度です。結合されたマスクが一杯になるとタイルがカバーされるので、参照レイヤーを上書きして作業レイヤーをクリアすることができます。これを図5に示します。正確な三角形の深さの境界を計算する方法の詳細については、Akenine-Möllerらの著書[AMHH08]の856-857ページを参照してください。
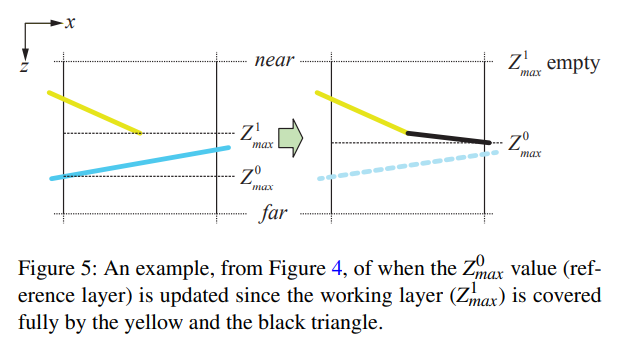
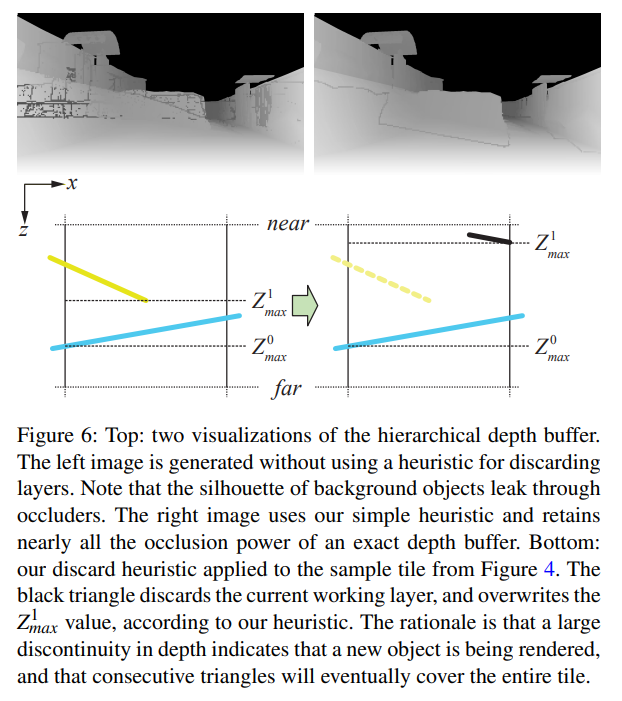
上記のルールに加えて、作業層を破棄する場合のヒューリスティックが必要です。これは、図6に示すように、前景のオクルーダーからシルエットが漏れるのを防ぐのに役立ちます。上述の updateHiZBuffer() 関数のように、三角形までの距離が作業レイヤーと参照レイヤー間の距離よりも大きい場合、作業レイヤーを破棄します。我々の更新手順は \(Z_{max}^0 \geq Z_{max}^1\) を保証するように設計されているので、現在の三角形の方が遠い場合に作業レイヤを破棄することはないので、より高速なテストのために符号付き距離を使用することができます。なお、作業レイヤーを破棄するときにはマスクと \(Z_{max}^1\) の値を 0 にクリアしますが、これは直感的ではないように思われるかもしれません。しかし、\(Z_{max}^1\)は\(Z_{max}^1\)と\(Z_{max}^{tri}\)の最大値を使って更新されるので、0に初期化するのが正しいです。
Hierarchical Depth Test
オクルーダーをラスタライズしている間に,\(Z_{max}^{tri} \geq Z_{max}^0\)のタイルをすべて破棄することで、階層的な深さのテストを行うこともできます。この場合の目的は、オクルージョンクエリを実行することではなく、ラスタライザを最適化することです。廃棄されたすべてのタイルについて、カバレッジテストをスキップし、階層的な深度バッファを更新することができます。これらの関数は非常に最適化されているにもかかわらず、階層的深度テストは全体的なパフォーマンスを大幅に向上させるのに十分に単純です。我々の更新では、\(Z_{max}^0 \geq Z_{max}^1\)が保証されているので、\(Z_{max}^0\)との比較だけで十分です。これにより、我々のカリングテストは、Anderssonら[AHAM15]によって記述されたものよりもわずかに安価になります。
階層的な深度テストを使用するのは自然なことのようですが、このオプションはほとんどのCPUベースのカリングフレームワーク[And09, CMK*16]では利用できないことに注意してください。これらのアルゴリズムは、各タイルの最大深度を見つけることによって、完全な解像度の深度バッファから階層的深度バッファを計算することを忘れないでください。オクルーダーをラスタライズしながらこれを行うと、法外なコストがかかります。対照的に、このオプションは、マスクされた深度表現の軽量な更新操作のために利用可能です。
Discussion
我々の階層的深さ表現はAnderssonら[AHAM15]によって提案されたものに似ていますが、オクルージョンクエリには必要ないため、\(Z_{min}\)値は省略しています。これは、階層的なカリングシステムにおいて、オブジェクトのグループ全体が完全に見えるかどうかを判断するのに有用であり、それによって、さらなるオクルージョンクエリをスキップすることができます。しかし,オクルージョンクエリは,最初に見えるピクセルが見つかるたびに終了するため,可視オブジェクトに対しては一般的に安価です.したがって、\(Z_{min}\)値を維持する価値があるかどうかを判断するために、将来の作業のためにそれを残します。
4. Results
このセクションでは、我々のアルゴリズム(Mask)を評価し、階層型Zバッファアルゴリズム[GKM93] (HiZ)との性能比較を行う。また、参考のために、大まかな前から後ろの順にドローコールを送信した単純な視錐台カリング(Frustum)も含めています。これは、ピクセルシェーダのコストを過度に強調することなく、GPUの階層的な深度テストがオクルージョン領域での不必要なシェーディングを回避するため、GPUの限られた作業負荷を表しています。
すべての測定は、レンダリングとオクルージョンバッファの両方で\(1920 \times 1080\)の解像度で実行され、Intel Core i7-4770プロセッサとGeForce 760 GTXを搭載したマシン上で行われました。私たちは、マルチスレッドではなく純粋なアルゴリズムの性能に焦点を当てたかったので、私たちのアルゴリズムは通常、シングルコアでリアルタイムレートで実行されます。ゲームエンジンは、残りのスレッドをAI、衝突検出、物理学などの他の仕事に割り当てることができるので、これは大きな強みだと考えています。スレッディングに関しては、我々のアルゴリズムが他のラスタライズベースのアプローチよりもスケーリングが悪くなる理由は見当たりませんが、この評価は今後の作業のために残しておきます。
我々のアルゴリズムは、Intelのソフトウェアオクルージョンカリングフレームワーク[CMK*16]に組み込みされており、また、性能のベースラインとして使用するHiZの最適化された実装も同フレームワークから取得しています。これについては、セクション4.1でさらに説明します。我々はまた、我々のオクルージョンカリングアルゴリズムの強みを生かしたスタンドアロンのフレームワークも使用しており、これについてはセクション4.2で説明します。
4.1. Intel Software Occlusion Culling Framework
2016年1月版のフレームワークでは、マーケットプレイスのシーンに2Mの三角形を使用し、49Kの三角形のオクルージョンメッシュを採用しています。AVX2に最適化された階層Zバッファアルゴリズムを使用し、2段階のプロセスでオクルージョンカリングを実行します。オクルーダーメッシュは最初にフル解像度のデプスバッファにラスタライズされ、デプスバッファは各\(8 \times 8\)ピクセルタイルの最大深度を計算して縮小され、最後にオクルーダーオブジェクトは低解像度の階層的デプスバッファに対してオクルージョンクエリされます。
私たちはフレームワークに2つの一般的な最適化を行いました。まず、正確なバウンディングボックスオクルージョンクエリを削除しました。これは、各オブジェクトの変換されたバウンディングボックスを三角測量し、ピクセル精度でラスタライズするものです。我々は、オブジェクトのスクリーン空間のバウンディング矩形をトラバースし、階層的な深度バッファに対するテストを行う粗いテストだけを残しました。我々の2番目の最適化は、オクルーディのために軸を揃えたバウンディングボックス(AABB)ツリーを導入し、階層的なオクルージョンクエリを実行することです。シーン内の多くのオクルーディは非常に小さく、各オクルージョンクエリはほんの一握りの三角形しか表現できません。シーンを修正するのではなく、このような小さなオブジェクトが多数存在するワークロードでは、ツリー構造を使用することが合理的であると考えました。これらの最適化により、カリングテストはより保守的になり、シーンの三角形の1%を可視として分類しますが、総フレーム時間は大幅に短縮されました。
表1は、従来の階層型Zバッファアルゴリズムと我々のアルゴリズムのタイミングの内訳を示しています。表からわかるように、我々のアルゴリズムは、我々のアルゴリズム最適化のターゲットであるラスタライズパスの実行時間を4倍近く短縮しています。さらに、我々は階層的な深度表現を直接操作するため、通常の深度バッファから階層的な深度バッファを生成するためのパスを完全にスキップすることができます。通常、これはタイル内の全ピクセルの最大深度を計算することで行われますが、保守的な最大値として \(Z_{max}^0\) を直接使用することができます。同様に、階層的な表現では、全解像度の深度バッファのストレージの10%程度を使用するため、深度バッファをクリアするコストが大幅に削減されます。

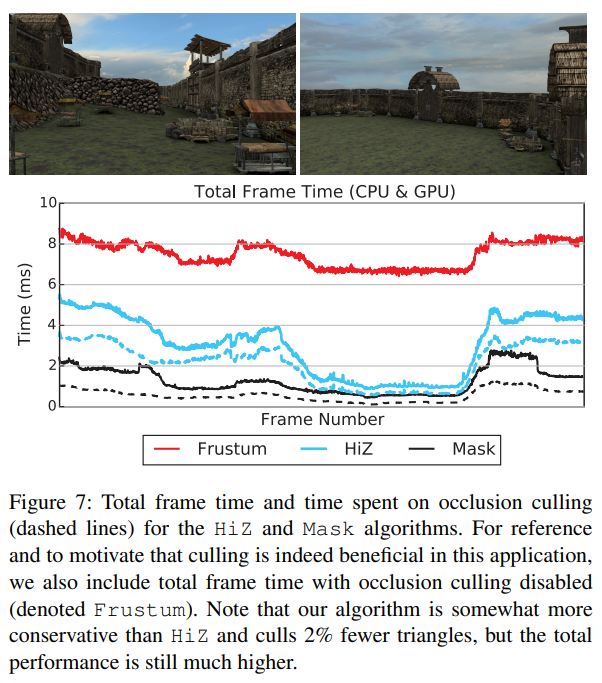
図7は、短いカメラアニメーション中のフレーム時間の内訳を示す図です。この図から分かるように、オクルージョンカリングでは、ビューフラスタム内のすべてのオブジェクトをレンダリングする場合と比較して、総フレーム時間が大幅に短縮されています。これは、GPUの負荷が軽減されたこともありますが、レンダリングコードに費やすCPU時間が大幅に短縮されています。オクルージョンカリングを有効にした場合の総フレーム時間は、ほとんどがCPU性能に制限されており、したがって、我々のアルゴリズムのために非常によくスケーリングされます。より複雑なレンダリングを行うアプリケーションでは、GPU性能によって制限される可能性があり、これはより高速なカリングの利点を減少させます。しかし、CPU時間は、オクルージョンカリングアルゴリズムが他の多くのタスクと共有しなければならない希少なリソースであることが多いことに注目しています。
4.2. Interleaved Rasterization and Queries
また、我々のアルゴリズムをスタンドアロンのフレームワークに実装し、トラバーサルとカリングのアルゴリズムを我々のラスタライザの強みに合わせて調整しました。リスト1に示すように、シーンをAABBツリーに格納し、ヒープを使用してノードを前から後へ順序を近似してトラバースします。トラバーサル中に、我々のコードは錐台とオクルージョンクエリを実行して、トラバーサルを早期に終了させます。
これはオクルージョンカリングシステムの教科書的な例に見えるかもしれませんが、トラバーサルとオクルージョンカリングをこのように密接に統合することには従来から問題があったことを指摘しています。HiZのようなソフトウェアアルゴリズムでは、階層的な深度バッファを生成するためのオーバーヘッドが一般的に非常に大きく(表1参照)、ラスタライズとオクルージョンクエリを統合することは現実的ではありません。同様に、GPUアルゴリズムの場合、ノードごとの詳細なトラバーサル決定をガイドするためにハードウェアオクルージョンクエリを使用するにはレイテンシが非常に大きく、これは一般的に同期化の問題や失速につながるからです。
我々のアルゴリズムは、オクルーダーをラスタライズし、階層的な深度バッファに直接オクルージョンクエリを実行します。このため、2つの演算をインターリーブすることによるペナルティが発生せず、より詳細なトラバーサルアルゴリズムの実装が容易になります。このことは、我々の結果で示すようにオクルージョンされていない三角形の数に比例した作業を行うだけで済むため、有益です。
Listing 1: Traverse and cull in approximate frot-to-back order
function traverseSceneTree(worldToClip)
heap = rootNode
while !heap.empty():
node = heap.pop()
if node.isLeaf():
rasterizeOccluders(node.triangles)
node.visibile = true
else:
for c in node.children:
culled = frustumCull(c.AABB)
clipBB = transform(worldToClip, c.AABB)
rect = screenSpaceRect(clipBB)
culled |= isOccluded(rect, clipBB.minZ)
if !culled:
heap.push(c, clipBB.minZ)
最初のテストシーンを図8に示し、オクルージョンカリング性能と短いカメラアニメーションのトータルレンダリング時間を示します。このシーンには合計73Mの三角形が含まれていますが、オクルージョンのために143Kの三角形を持つアーキテクチャーメッシュのみを使用しています。このシーンはIntelのデモで使用されたものよりもかなり複雑で、オクルーダーメッシュには大きな三角形が多く含まれていますが、一般的には大きなスクリーンスペースに囲まれた長方形を持つため、効率的にラスタライズすることは困難です。それでも、我々のアルゴリズムは非常によく機能しており、ワーストケースのフレームタイムは断然最高で、非常に高いフレームレートで動作している非常に稀なケースでは、錐台カリングよりも効率が良いことが分かります。
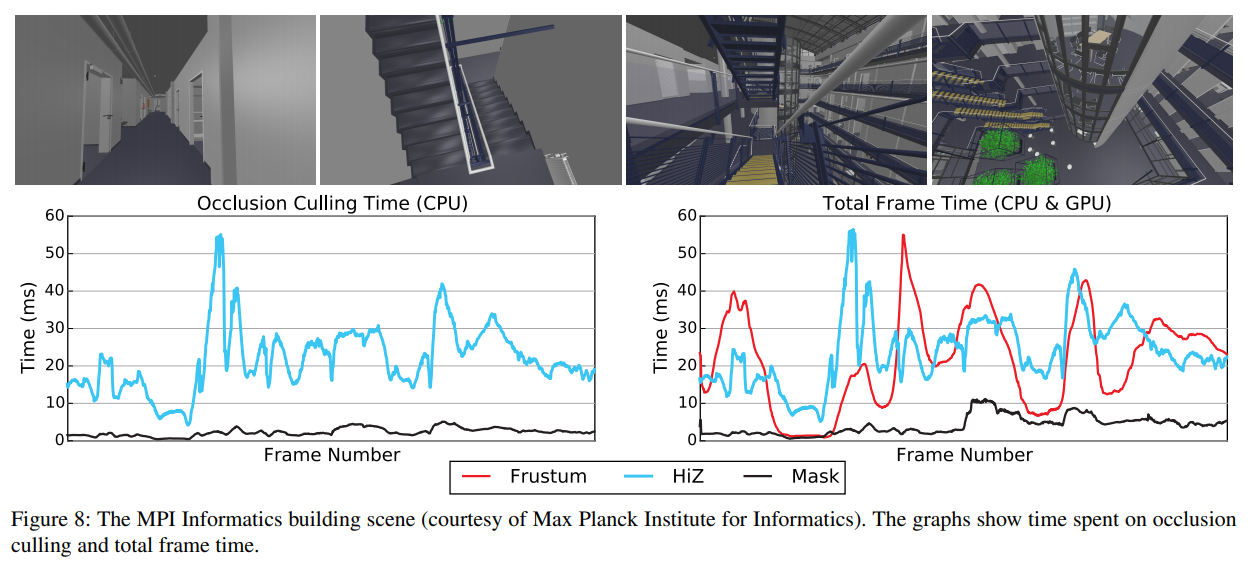
参考のためにHiZアルゴリズムを含むことに注意してください。この比較は、階層型デプスバッファを生成するコストと、微細なオクルージョンカリングを実行することで得られる利益のバランスをとる必要があったため、特に困難でした(Listinig 1を参照)。我々はHiZを可能な限りオリジナルの実装に近づけたかったので、\(N=100\)でラスタライズされたリーフごとに階層型デプスバッファを再生成することにしました。我々のアルゴリズムの10倍のスピードアップを主張するのはフェアではないかもしれませんが、複雑なオクルーダーメッシュに対して非常にロバストであり、インターリーブドトラバーサルアルゴリズムはこのシーンにおいて非常に有益であると結論付けています。
2番目のシーンである図9のRungholtは、レンダリングとオクルージョンカリングの両方に7Mトライアングルメッシュ全体を使用しており、オクルージョンカリングの観点から最も幾何学的に複雑なシーンとなっています。このシーンでは、単純な錐台カリングの生のGPU性能に対抗するのは非常に困難です。シンプルなサーフェスシェーダを使用し、シーンには1つのマテリアルとテクスチャしか含まれていないため、シェーダ/テクスチャ/ステートを変更することなく、すべてをGPUに投入することが可能になりました。我々のアルゴリズムは、シングルコア上での実行では通常5ms以下と非常に良好なパフォーマンスを発揮しますが、いくつかの困難なカメラ位置では錐台カリングよりも優れていることに注意してください。これらの結果は、同じアセットを使用しており、1つのCPUコアのみを使用したディスクリートGPUで基本的に均等なステップを維持しているため、励みになると考えられます。ピクセルシェーダや頂点シェーダをより高価なものにしたり(例えば、より多くの光源を追加することで)、ステート変更を追加することで、このシーンのバランスを変更することが可能で、より説得力のある結果を得るために簡単に微調整することができますが、公平性のために無修正のままにしておくことを選択しました。
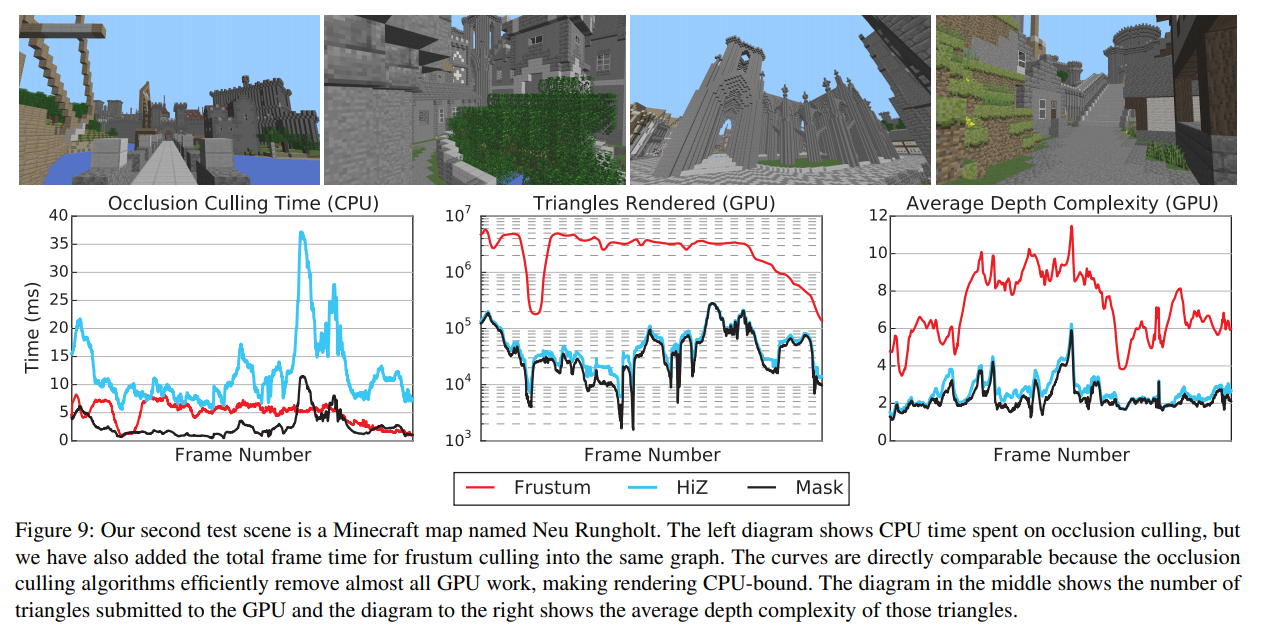
図7に示すように、シェーダ/テクスチャ/状態の変化とシーンアセットの管理に関連するすべてのCPUオーバーヘッドをカリングできるような複雑なゲームエンジンでは、オクルージョンカリングの利益はより大きくなると考えられます。したがって、ワークロードの指標として、GPUに投入された三角形の数も提示します(図9を参照)。この値はアルゴリズムの効果に過ぎず、実行時間とは無関係であることに注意してください。HiZ は定期的に階層的な深度バッファを再生成しているだけであり、このシーンのために我々のアルゴリズムがより多くの三角形を選択している理由を説明していることを思い出してください。
Limited Time Budget
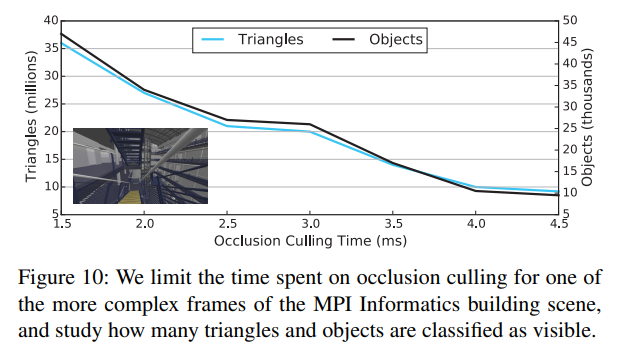
オクルージョンカリングは、いくつかのヒューリスティックなアプローチを用いて有意なオクルーダーを選択することで加速されることが多いです。我々の探索は前から後の順にソートされているので、最も重要なオクルーダーが最初にラスタライズされると仮定するのが妥当である。もし、カリングに費やせるCPU時間が一定量しかない場合は、システムクロックを定期的にポーリングし、ある閾値を超えた場合はラスタライズを停止します。オクルージョンクエリは依然として実行されるので、オクルージョンカリングに費やされた時間の合計を保証することは難しいですが、CPUとGPUのワークロードのコストバランスを取るための強力な方法であることには変わりありません。図10は、MPI Informaticsのビルシーンにおけるオクルージョンカリングに費やした時間とカリング効率の相関関係を示しています。
4.3. Scaling
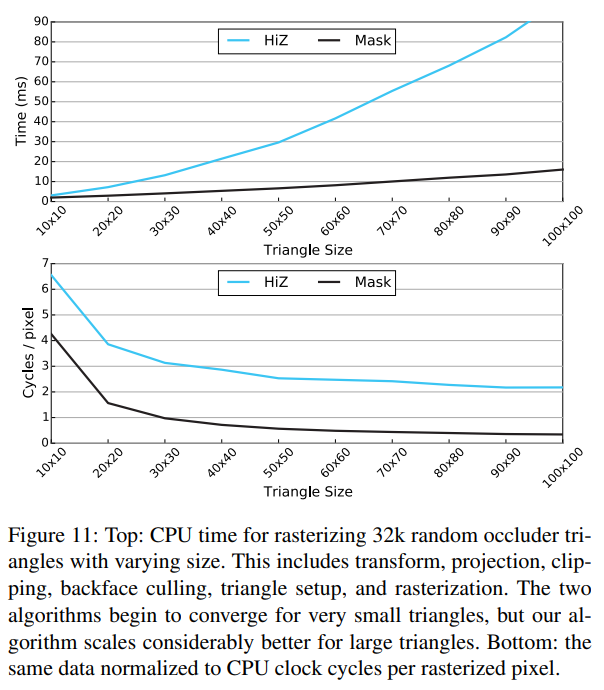
位置と向きをランダムにした32Kの直角二等辺三角形をラスタライズした合成ベンチマークを使用して、様々な三角形サイズに対して我々のアルゴリズムがどのようにスケーリングするかを評価しています。HiZとの比較を簡単にするために、初期の深度テストで断片がカリングされていないことを確認するために、三角形を裏返してレンダリングしています。図11に示すように、我々のアルゴリズムは大きな三角形に対しては良好にスケーリングし、非常に小さな三角形に対してはHiZの性能に近づいています。これは予想通りであり、オクルージョンカリングのための良いトレードオフであると主張しています。低ポリゴンメッシュを作成し、最も重要なオクルーダーのみを選択することは比較的容易であり、ほとんどのゲームエンジンはすでに最適化としてこれを行っています。対照的に、低解像度のレンダリングターゲットを使用している場合、正確性を保証することははるかに困難です。図の2番目の図は、ラスタライズされたピクセルあたりのCPUサイクルを示しています。
5. Conclusion
マスクされた深度カリングアルゴリズム[AHAM15]が、最新のCPUで効率的に動作するように適応できることを示しました。評価の結果、我々のアルゴリズムは性能とカリング精度の両面で非常に効率的であることが示されており、将来のレンダリングエンジンを刺激することを期待しています。我々のアルゴリズムは、フル解像度のデプスバッファをレンダリングする際の利点のほとんどを提供しています。同時に、AVX2対応のマシン上で256ピクセル分のカバレッジの計算と階層型デプスバッファの更新を並行して行うことができるため、低解像度デプスバッファを使用するアルゴリズムの性能特性の多くを保持しています。
私たちは、この研究が将来、正確なアルゴリズムの効率の大部分を保持する保守的でありながら損失の少ないカリングアルゴリズムの研究に刺激を与えることを願っています。将来の研究では、性能に大きな影響を与えずに深度バッファの品質が向上するかどうかを評価するために、階層的深度バッファ更新ヒューリスティックをさらに改良するかもしれません。同様に、\(Z_{max}^i\)参照値を表現するために完全な32ビット浮動小数点精度が本当に必要かどうかは疑問であり、代わりに2つの16ビット値としてパッキングすることで性能をさらに向上させることができるかもしれません。また、GPU実装の有用性を評価するのも興味深いです。Laine and Karras [LK11]は、固定関数ラスタライザに対抗するのは非常に難しいことを示しました。しかし,コンピュートシェーダ[HA15]を用いてカリングと可視サーフェイス決定を行うシステムでは,オクルージョンカリングを同一カーネル内に保持しておくメリットがあるかもしれません。
Acknowledgements
和訳省略。